内存管理
1. 基础概念
-
虚拟地址 和 物理地址 空间
虚拟地址(VA, Virtual Address)由指令中的 地址字段 给出,进程看到的都是虚拟地址。物理地址是内存单元在 实际内存硬件 中的真实位置。
-
地址翻译
地址翻译指的是在程序执行的过程中 将虚拟地址翻译为物理地址 ,地址变换由 内存管理单元(MMU, Memory Management Unit) 在硬件中完成,速度非常快。
-
内存共享
共享内存(Shared Memory)是多个 进程 共享的 内存区域 。它是最快的 IPC (进程间通信)机制之一,因为进程直接读写内存,无需进入内核态。但是,因为多个进程可以同时访问这些内存,所以可能需要某种 同步机制(如信号量)来防止竞态条件。
-
内存保护
内存保护是现代操作系统中的一个 核心功能 ,用于防止一个进程访问另一个进程的 内存空间。这不仅保障了系统的稳定性,而且提高了安全性,因为它可以防止恶意软件损害其他进程或篡改其数据。
可以通过如下机制实现内存保护机制:
- 分段 与 分页 :
- 分段 :内存被划分为不同的 段,每个段都有其起始地址和长度。段常常用于表示高级的数据结构,如函数或对象。
- 分页 :内存被划分为固定大小的 页面 ,例如 4KB。操作系统为每个进程维护一个 页表 ,来映射其虚拟地址到物理地址。
- 访问权限:每个段或页面都有与之相关的访问权限。例如,一个页面可能被标记为只读,这意味着任何尝试写入该页面的操作都会引发一个异常。
- 隔离 :由于每个进程都有其独立的地址空间,所以一个进程不能直接访问另一个进程的内存。这为每个进程提供了一种形式的 隔离,确保了一个出错的进程不会影响其他进程。
2. 管理方式
2.1. 管理方式分类
在现代操作系统中,内存管理方式 大体可以归纳为两类:连续分配 和 离散分配 。
所谓 连续分配 ,是指操作系统为进程分配一整段连续 的内存区域。
相比之下,离散分配 方式允许进程占用的内存空间是 不连续 的,这使得内存利用率和管理灵活性显著提高。
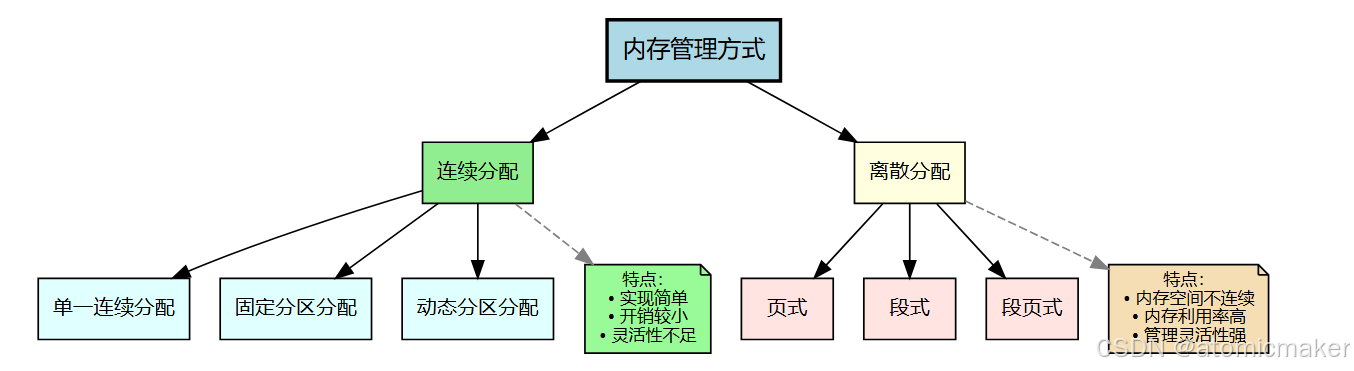
2.2. 连续分配管理方式
-
单一连续分配
内存在此方式下分为 系统区 和 用户区 ,系统区仅供操作系统使用,通常在高地址部分;在用户区内存中,仅有一道用户程序,即整个内存的用户空间都由该程序独占(只能用于 单用户 、单任务)。
-
固定分区分配
固定分区分配是最简单的一种 多道程序存储管理 方式,它将用户内存空间划分为若干 固定大小的区域,每个分区只装入一道作业。当有空闲分区时,便可再从外存的后备作业队列中选择适当大小的作业装入该内存,如此循环。
-
动态分区分配
在 固定分区分配 中,内存被预先划分为若干大小固定的区域。 这种方式实现简单,但也带来了一个明显问题:分区大小是静态的,而作业大小是动态的。
为了解决固定分区"尺寸僵化、内存利用率低"的问题,操作系统引入了 动态分区分配 。
动态分区分配的基本思想是: 不再事先划分固定大小的分区 ,而是将整个用户内存空间视为一块 连续的可分配区域 ,在程序装入时才根据其实际需要动态地划分内存。
当进程请求内存时,操作系统从当前的空闲内存中划出一块连续区域分配给该进程 ; 当进程结束或释放内存时,该区域重新成为空闲内存 ,可供后续进程再次使用。
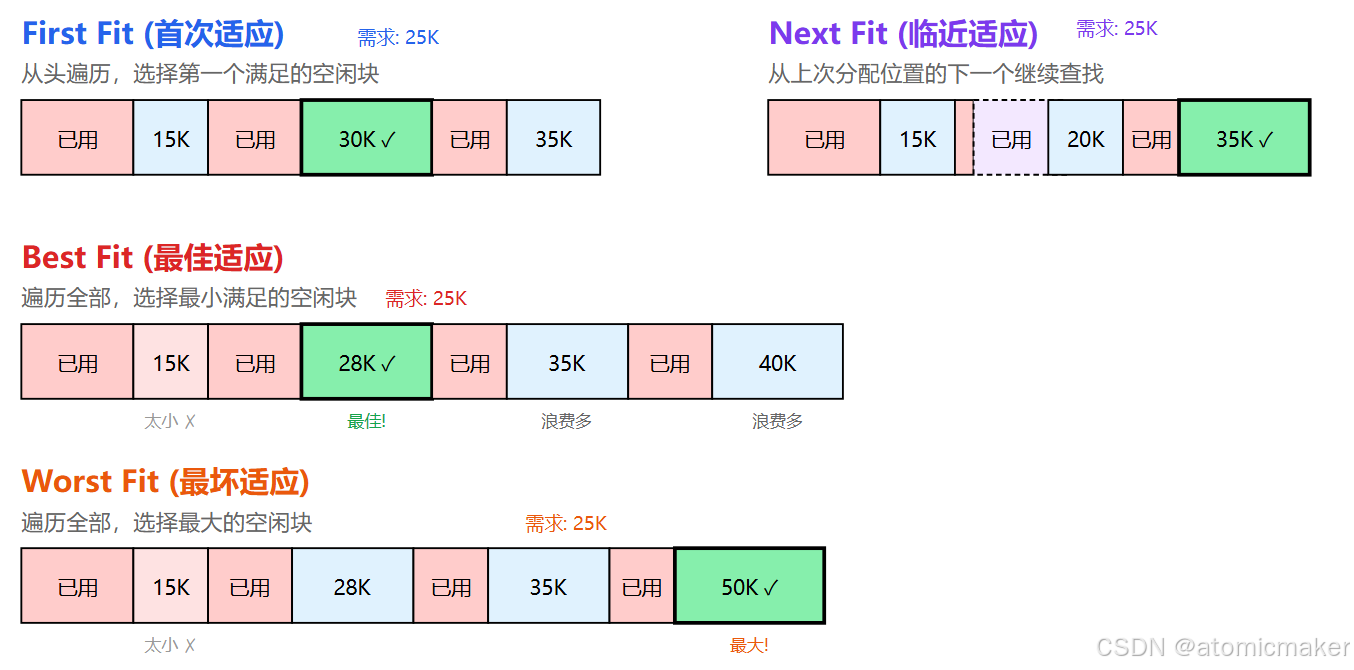
动态分区的分配策略主要包含四种算法:首次适应 (First Fit)、临近适应 (Next Fit)、最佳适应 (Best Fit)、最坏适应 (Worst Fit)。
下面来试一题,进程调度 + 内存分配:
如果还不熟悉进程调度的可以去看看:处理器管理
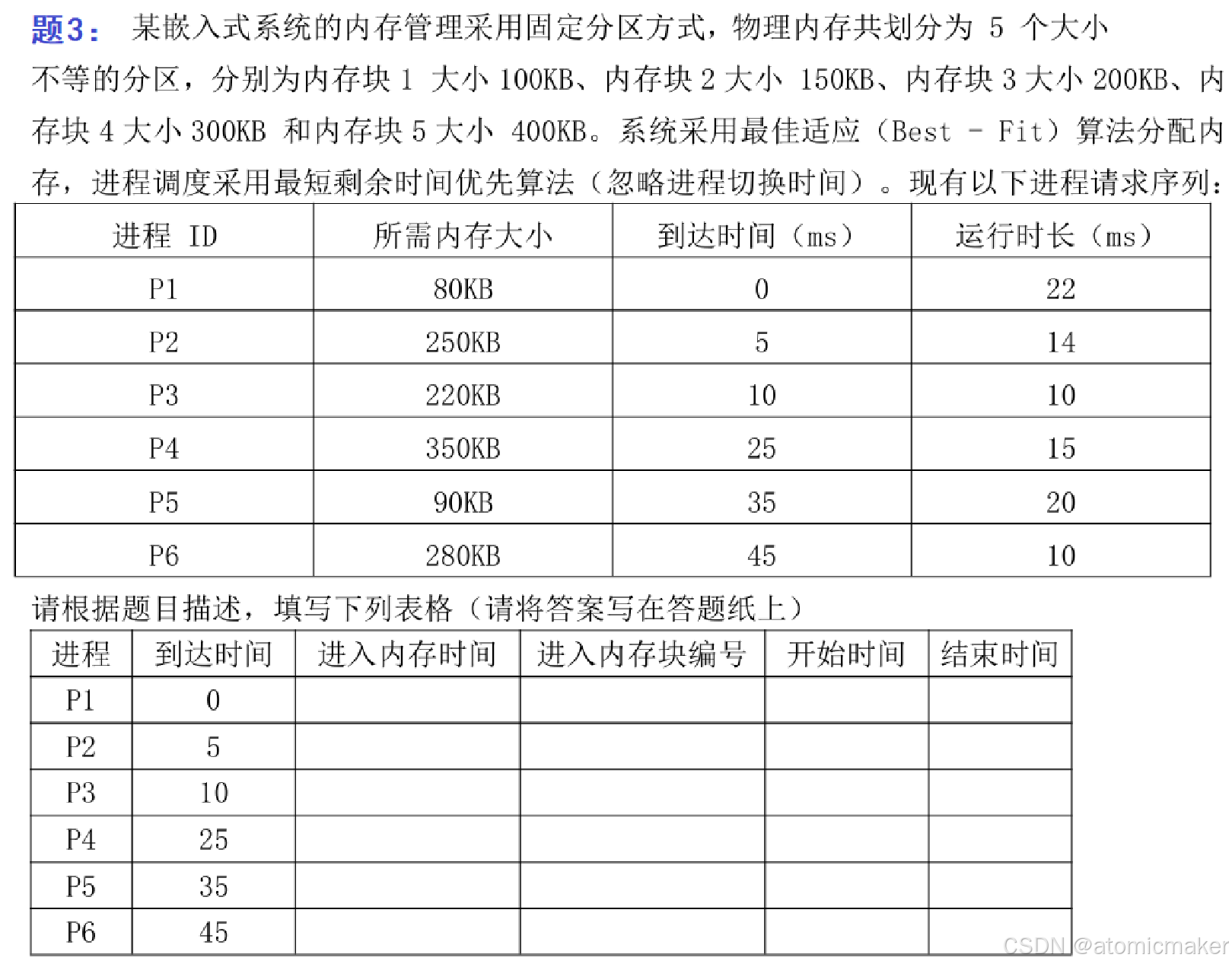
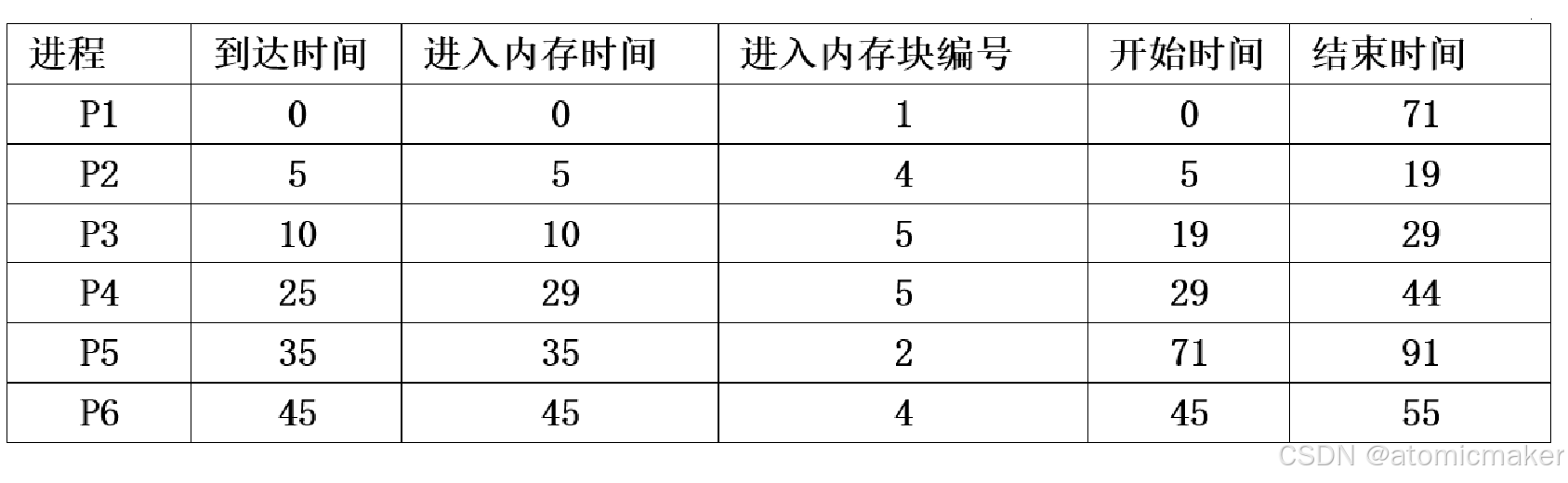
答案:
ps:进入内存时间可以看成到达时间,但是要注意,内存是否够用,
像下面的 P4(350KB)就是需要等待 P3 完成释放内存后才能进入内存块5,否则内存不够用。
2.3. 离散分配管理方式
-
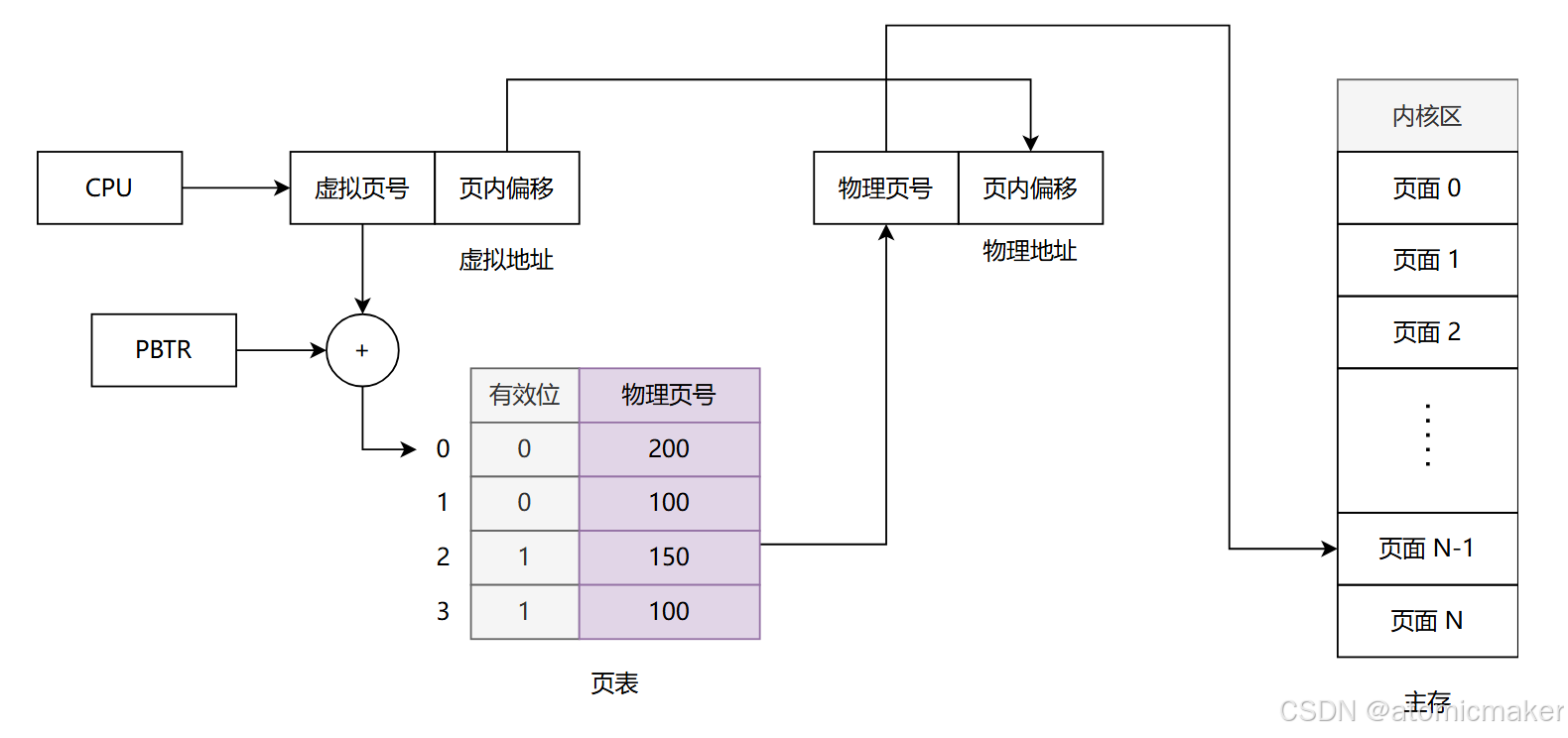
页式管理
页式内存管理的基本思想是将 虚拟内存 和 物理内存 分为若干个大小固定的 页面 ,然后通过 页表 建立从虚拟页面到物理页面的映射,这样进程就可以离散地使用物理内存中的不同页面。
- 页(页面) :被划分的 逻辑块。
- 页框 :页映射到内存中的 物理块 ,即一个页对应的唯一物理块,或者说是物理页面。
- 页表:每生成一个进程,操作系统就要为这个进程生成一张页表,用来记录进程每一页在内存中对应的物理块号(即页框)。
- 页表项 :页表项是页表的基本构成单元,一个页表项相当于页表的一条记录。页表项由 页号 和 内存物理块号 构成。
- 虚拟(物理)页号:当前地址所在的页在虚拟(物理)内存对应的所有页中的下标;
- 页内偏移 :地址在页面内的偏移。页内偏移量 = 逻辑地址 % 页面大小 (页内偏移位数 = log2(页面大小))
- 逻辑地址 :页号 与 页内偏移(也叫页内地址)构成。
- 物理地址 :物理块号 * 页面大小 + 页内偏移量 。
Tip:
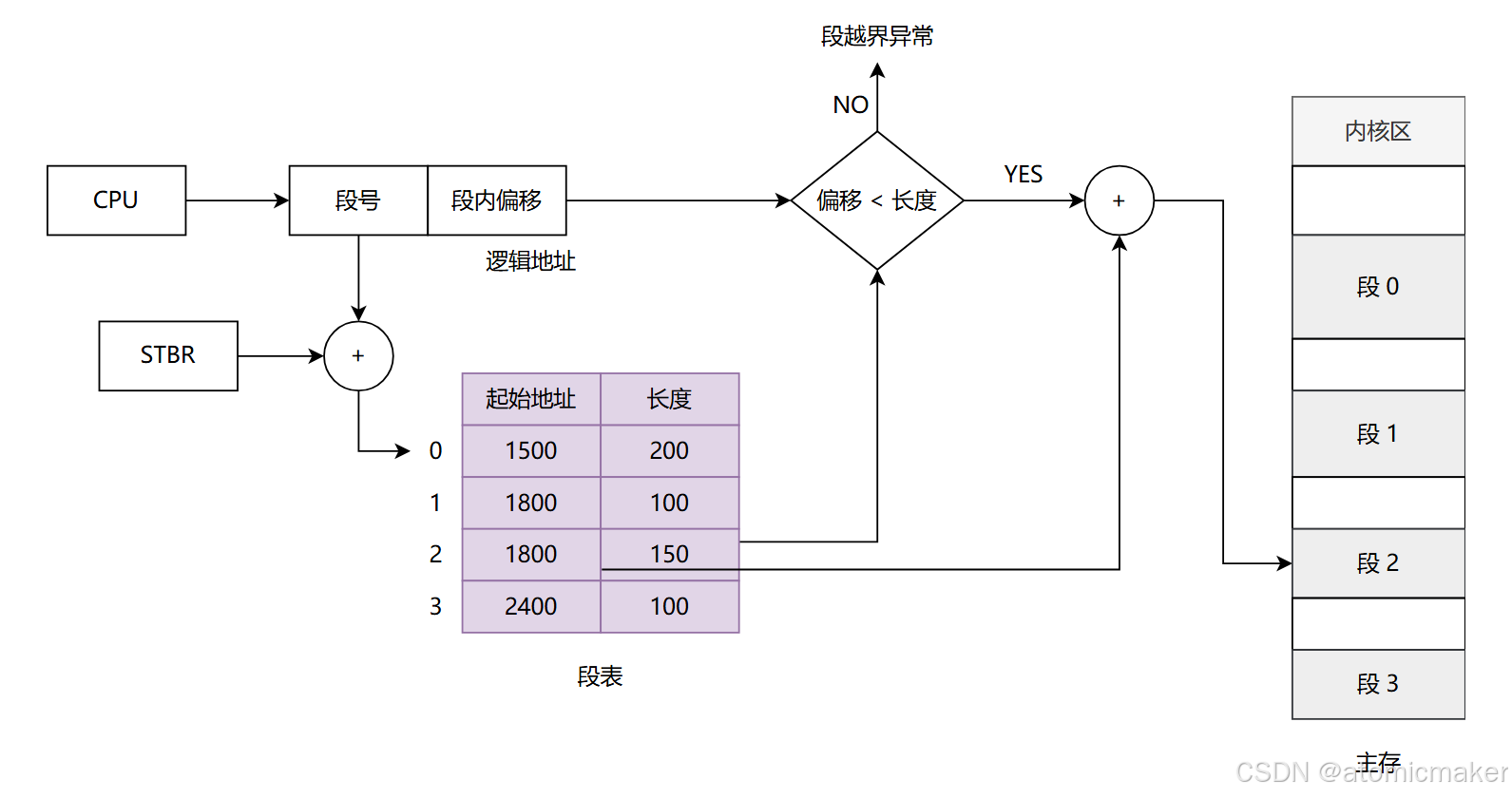
STBR (segment table base register) 指的是 段表基址寄存器 ,其中存储的内容是段表在内存中的地址。
PTBR (page table base register)指的是 页表基址寄存器 ,其中存储的内容是页表在内存中的地址。
通过 表基址寄存器 加上一个偏移,可以访问到表中的某个表项。
-
段式管理
段式内存管理将程序的不同部分(例如 代码、数据和堆栈 )划分为不同的 段 (segments)。每个段在物理内存中可以不连续,但在逻辑上都被视为连续的。
- 段
- 每个段都有一个明确的角色,例如 代码段、数据段 或 堆栈段。
- 每个段都有一个 起始地址 和 长度。
- 段内的地址是连续的,但不同段之间的地址可以不连续。
- 段表
- 段表是一种数据结构,用于存储每个段的 基地址 (在物理内存中的起始地址)和 限制(段的长度或末尾地址)。
- 当一个程序需要访问其内存段时,会使用 段号 和 段内偏移 作为地址。这个地址被称为 逻辑地址 或 段地址。
- 逻辑地址通过段表转换为 物理地址。
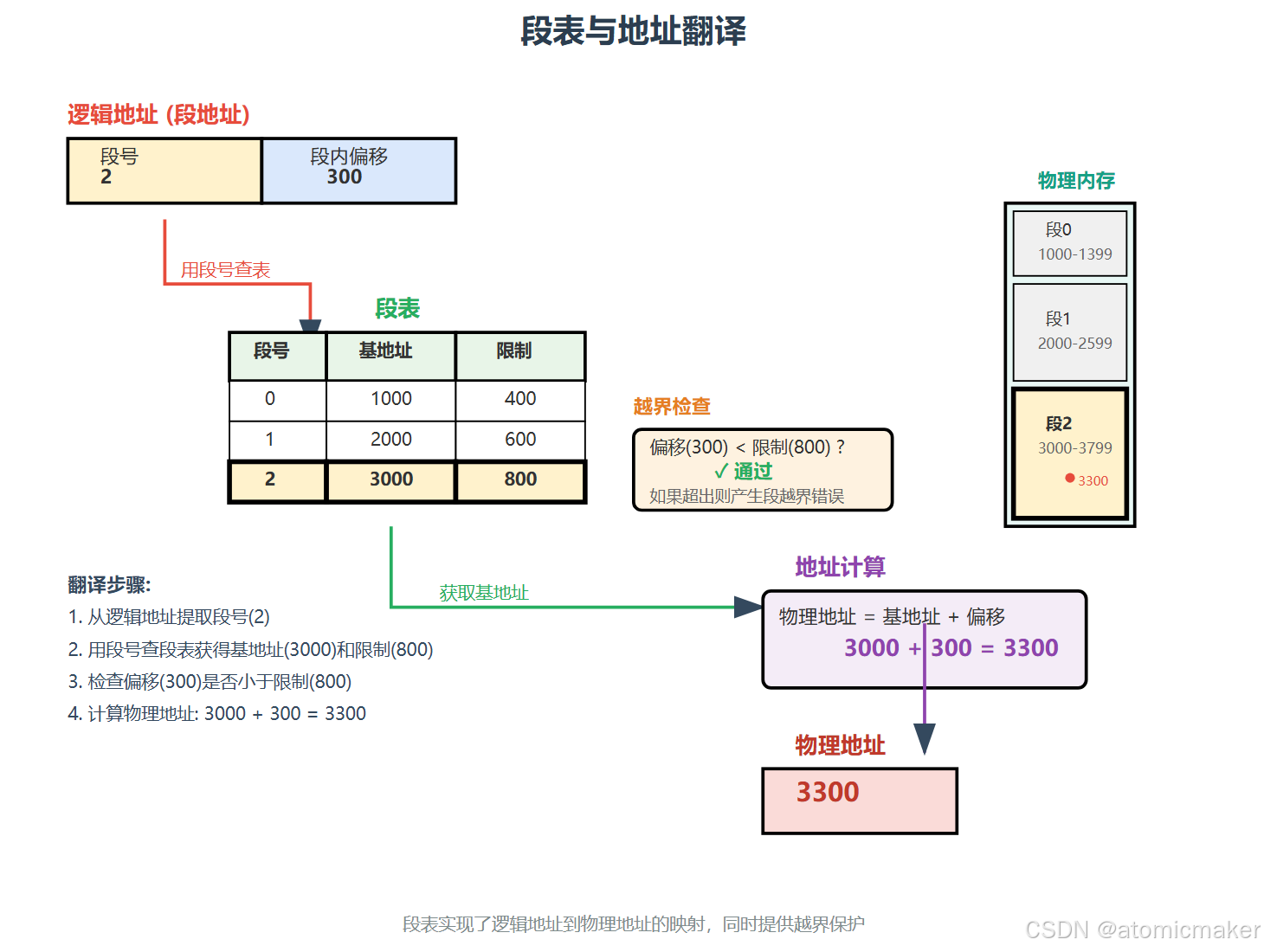
- 地址翻译
- 为了从逻辑地址获取物理地址,首先需要从逻辑地址中提取 段号,然后使用段号在段表中查找相应的基地址和限制。
- 然后,检查逻辑地址中的 偏移量 是否小于该段的限制。如果偏移量超出限制,则产生 段越界错误。
- 如果偏移量有效,则将偏移量加到段的基地址上,得到 物理地址 。
- 段
-
段页式管理
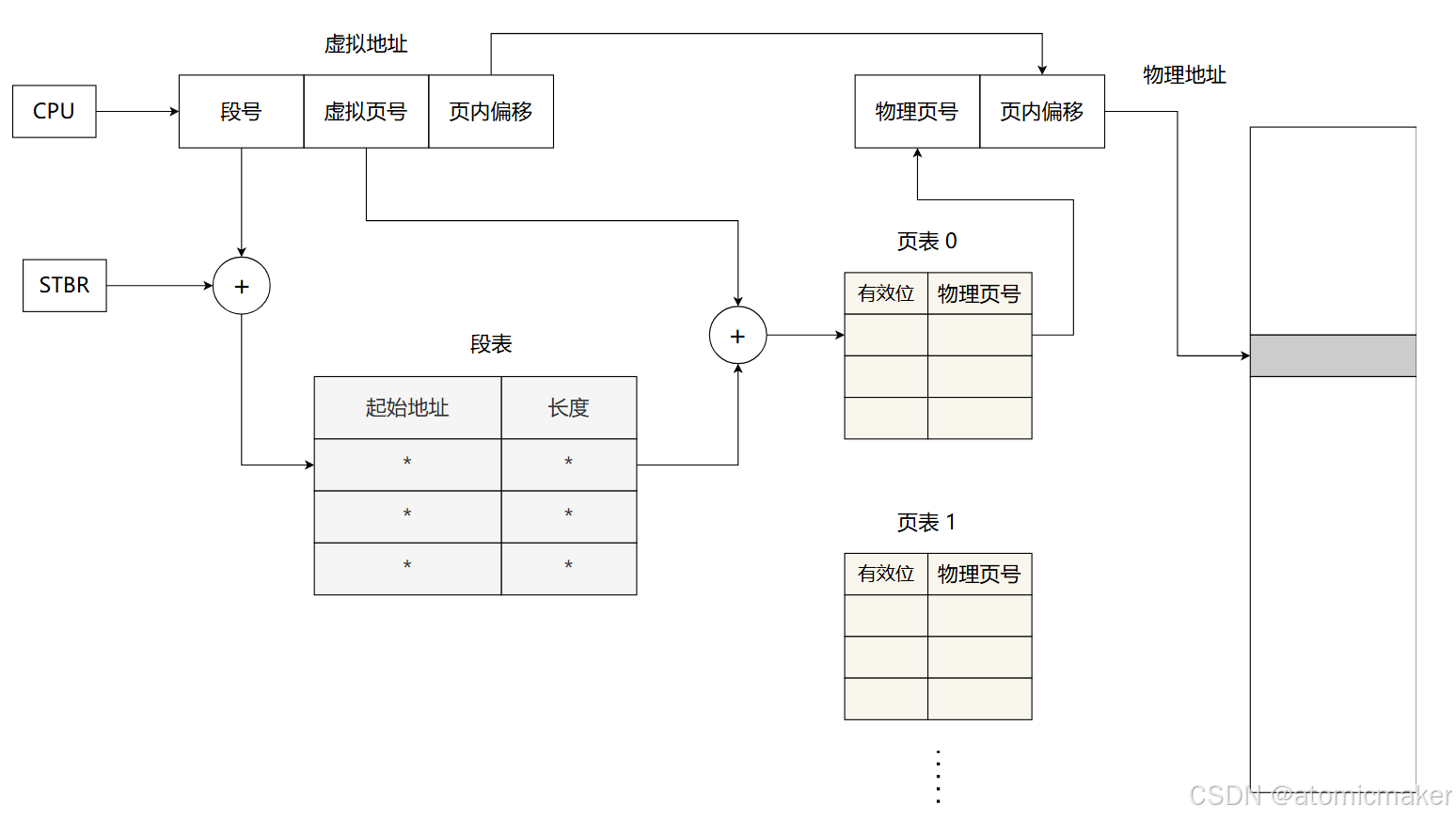
段页式管理(paged segmentation)是一种将 段式内存管理 与 分页式内存管理 相结合的策略。
在段页式管理中,程序首先被划分为逻辑上的 段 ,然后每个段进一步被划分为固定大小的 页 。
(虚拟地址可以拆分为三个部分:段号 (Segment No)、页号 (Page No)、页内偏移 (Offset))
首先,操作系统通过 段表 对不同的段进行管理。
在每一个段的内部,采用 分页 的方式将段分为不同的页,实现虚拟页面到物理页面的映射。
在地址翻译的过程中,首先通过虚拟地址中的 段号 在段表中找到 页表的起始地址 ,接下来再通过 页号 在页表中找到该地址对应的 物理页面号 。
下面来一题段页式管理:

答案:
(1)最多16项页,页大小为 2KB,因此每段最大尺寸为 32KB
(2)最多可被划分8个段,每段最大尺寸为 32KB
(3)
- 段号(8个段 - 23 - 3位);
- 页号(16项页 - 24 - 4位);
- 页内偏移(剩余位数);
- 物理地址(按字节编址):物理块号(5) * 页面大小(2K) + 页内偏移量

3. 虚拟内存管理
3.1. 页框分配
在 虚拟内存管理 中,页框分配 是操作系统为进程分配 物理内存(页框) 的过程。
它直接影响着系统的性能,因为分配的页框数量会影响进程的 缺页率(访问页面失败次数与总访问次数的比率) 和系统的整体吞吐量。
3.2. 页置换算法
在操作系统中,进程运行时,如果它要 访问的页面不在内存中 ,就会产生 缺页中断 。这时,操作系统需要从磁盘中将该页面调入内存。但如果此时内存已满,操作系统就需要选择一个页面将其移出内存,以便为新页面腾出空间。这个选择要移出哪个页面的算法,就叫做 页面置换算法。
-
FIFO
FIFO (First-In-First-Out)页面置换算这是最简单的页面置换算法。它总是 淘汰最先进入内存的页面 ,即选择在内存中驻留时间最久的页面。
FIFO 的实现方法是把调入内存的页面按先后顺序放入队列中,当需要置换页面时,选择队头的页面即可。
Belady 异常
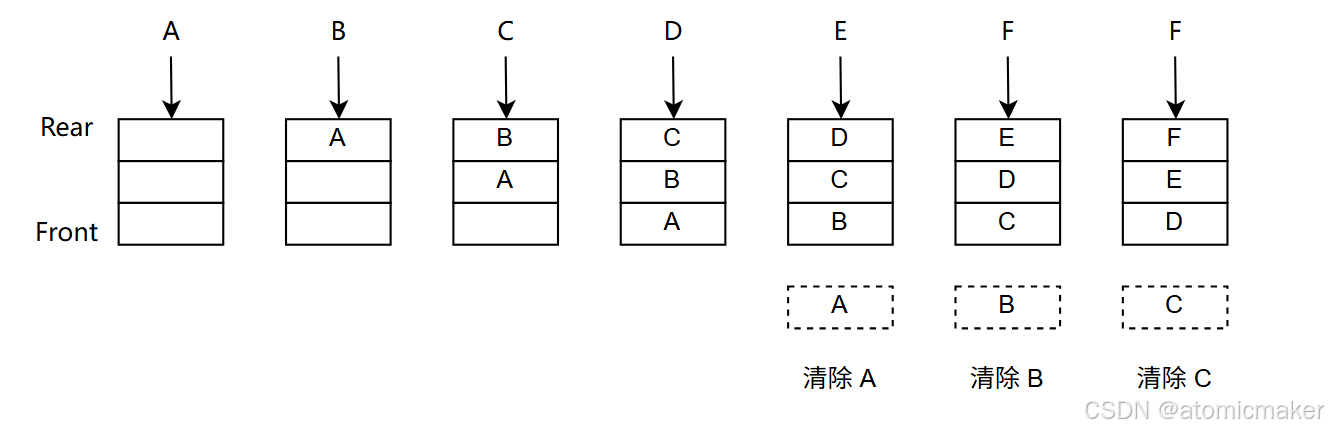
在某些页面置换算法(特别是 FIFO ,先入先出算法)中,增加页面的数量反而导致 页面错误次数(或者说缺页次数)增加 ,这种情况违背了直觉,因为通常认为更多的内存框架应该减少页面错误,这种异常情况叫做 Belady 异常 。
举个实际例子,假设页面访问序列为:1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
- 使用 3 个页面框架,FIFO 算法可能产生 9 次页面错误。
- 使用 4 个页面框架,FIFO 算法可能产生 10 次页面错误。 这种页面错误次数随着框架增加而增加的现象就是 Belady 异常 。
-
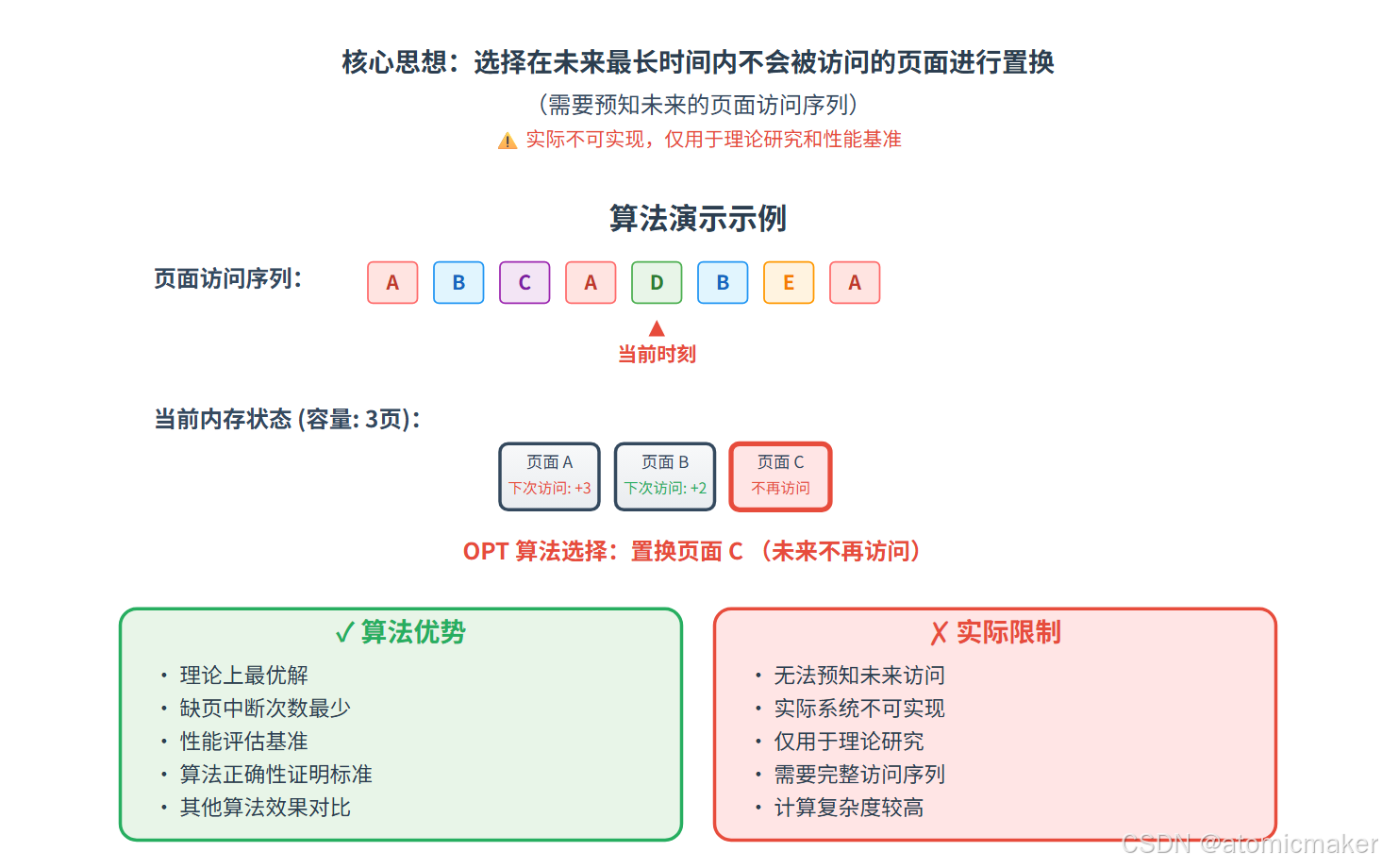
OPT
OPT (Optimal)页面置换算法,也称为最佳页面置换算法,是一种理论上的页面置换算法,其目标是选择最佳的页面来置换,以最大程度地减少未来的页面访问次数。
那么什么叫做最佳的置换页面呢?OPT 算法假设你可以预知未来,即你可以知道当前进程驻留集中的哪个页面是在将来最早会被替换的(在驻留集中停留的时间最短),也就是说,你 需要知道未来的页面访问序列 。
-
LRU
LRU (Least Recently Used)基于最近的页面访问历史来决定哪个页面应该被置换出内存。
LRU 算法是基于时间局部性思想:如果一个页面在最近被使用的话,那么这个页面在将来很可能被再次使用。
所以 LRU 算法会选择 最近一直没有被使用的页面 进行替换。
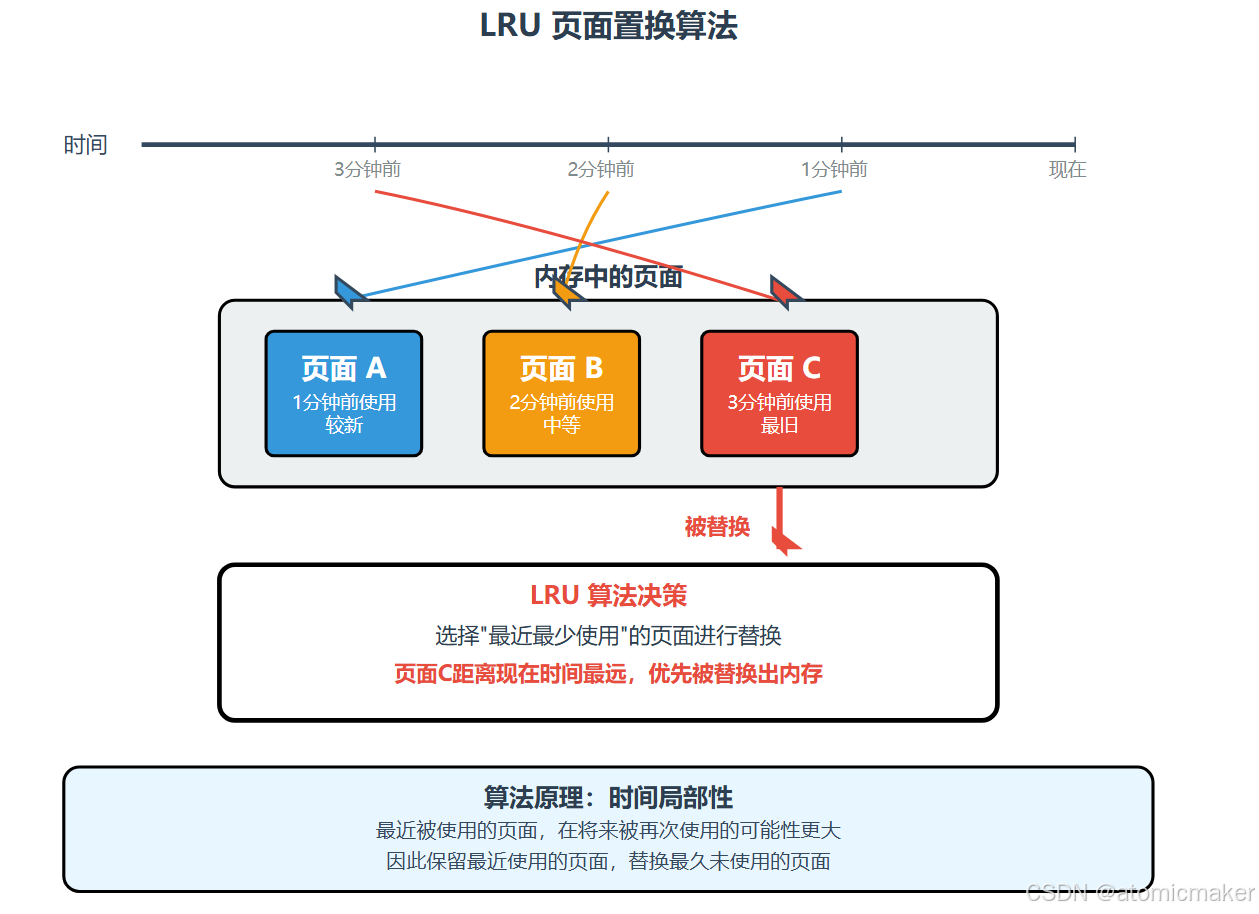
LRU算法例子:
加入内存系统中有 3 个页框,页面引用序列为
7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 2,则置换页面如下:页面引用 引用后内存状态 置换页面 7 7 0 7, 0 1 7, 0, 1 2 0, 1, 2 7 0 1, 2, 0 3 2, 0, 3 1 0 2, 3, 0 4 3, 0, 4 2 2 0, 4, 2 3 3 4, 2, 3 0 0 2, 3, 0 4 2 3, 0 ,2 -
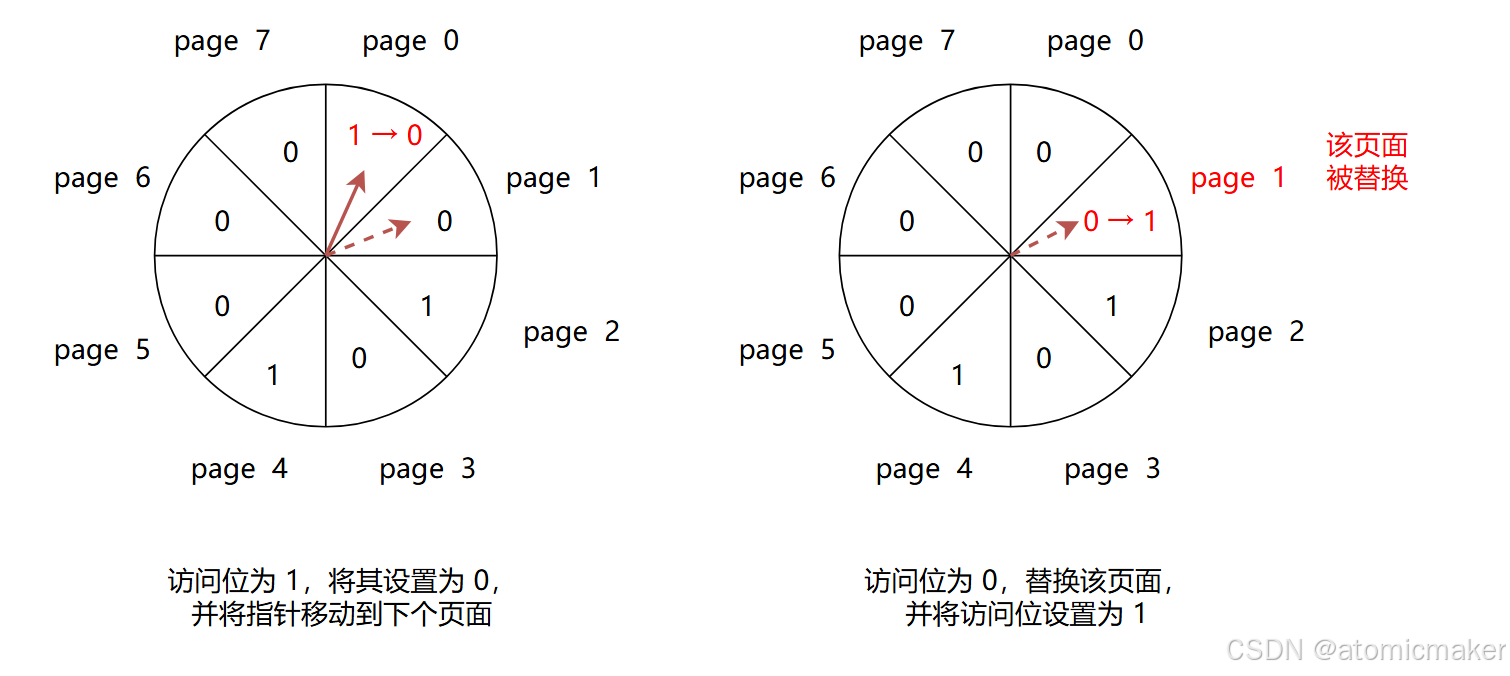
Clock
Clock 算法的提出是为了解决 LRU 算法在硬件实现上的复杂性,该算法流程相比 LRU 更加简单,可以更高效地使用硬件电路进行实现。
此外,Clock 算法的目的与 LRU 算法类似:保证最近刚访问过的页面可以在将来尽量晚被淘汰。
CLOCK 算法的核心思想是使用一个类似时钟的数据结构,以跟踪每个页面的访问状态。
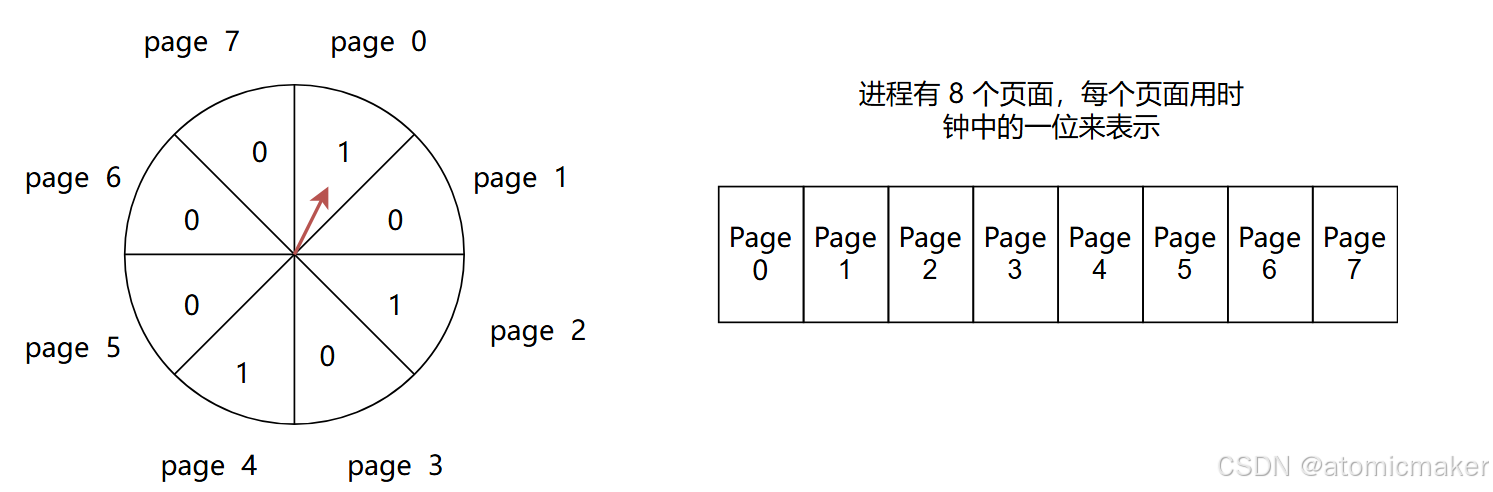
页面的访问状态用一个比特位(访问位)来表示:
- 0 表示该页面 未分配 或者 已分配但可以被替换
- 1 表示该页面 已分配 但 不可被替换
初始 情况下进程的所有页面都未被分配,所有页面的访问位都为 0。
当一个新页面被添加时,时钟中的指针会不断旋转,直到 找到一个访问位为 0 的页面将其替换。若 当前页面的访问位为 1,则将其设置为 0,并移动到下一个位置进行查找 。
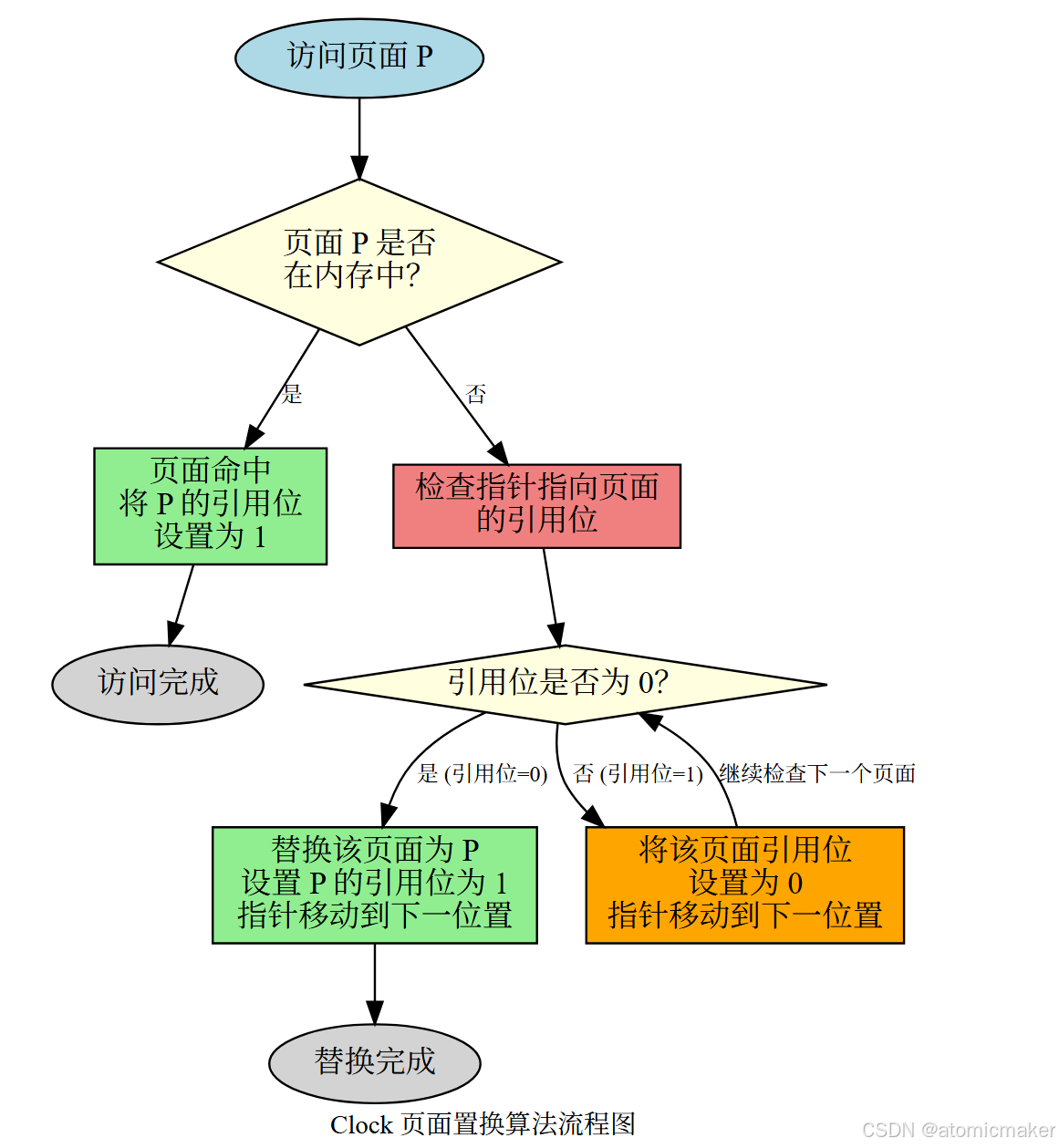
Clock 算法的流程图:
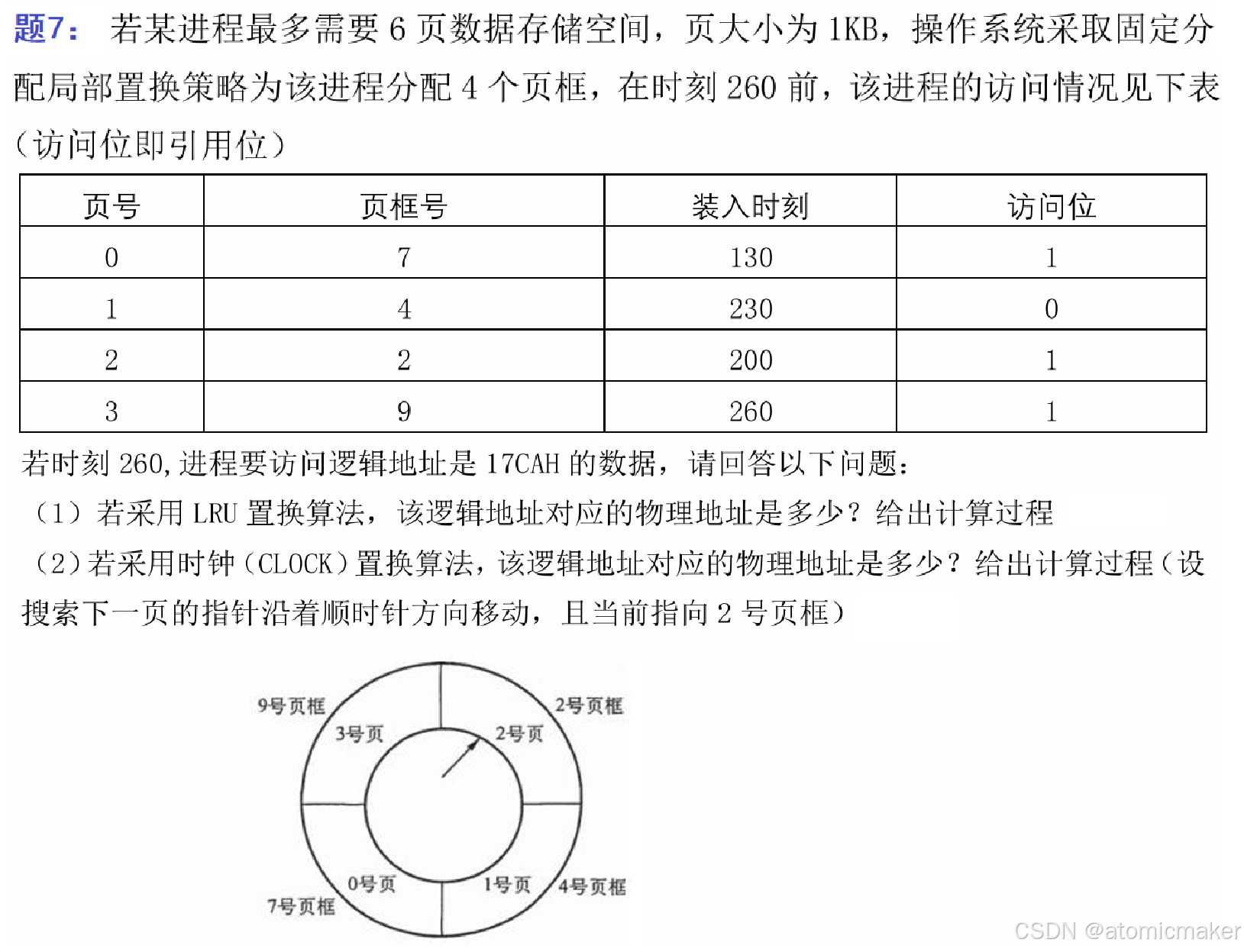
下面是用LRU和CLOCK的题目:
答案:
