本文对应项目版本:
v0.1.1把固定流程 Agent,改造成一次有限决策的受控 Agent
我在做 AI Mind v0.1.1 时,刻意没有把 Agent 变得更自由。
现在很多 Agent 文章会默认一个方向:让模型自己规划、自己选工具、自己决定下一步,最好还能循环执行。但这个版本里,我做的是另一件事:只给任务清单 Agent(Tasklist Agent)加一次受控决策。
AI Mind 是我按版本持续演进的 AI Native Runtime Skeleton。它不是普通聊天 Demo,也不是完整 Agent 平台,而是围绕聊天运行时、流式协议、工具调用、Skill、MCP 和 Agent 一层一层搭出来的工程实验。
到 v0.1.0 时,项目已经有了第一个受控 Tasklist Agent:用户通过 /tasklist + @docs://versions/*.md 显式引用版本方案后,运行时会读取方案、生成任务清单草稿、执行结构校验,并在必要时最多自动修正一次。
但 v0.1.0 的 Agent 本质上还是固定流程。
固定流程的好处是稳:入口明确、资源明确、工具明确、最多修一次,普通问答链路不会被污染。问题也很明显:如果版本方案有弱项、缺少一点上下文,或者用户输入已经越过 Tasklist Agent 的边界,固定流程就不够灵活。它要么继续生成,要么失败,很难在中间做一次"可控判断"。
所以 v0.1.1 的主题可以概括为:一次受控规划决策。它只在原有受控链路里增加一次规划决策(Planning Decision):让模型在运行时白名单允许的 5 类动作中选择下一步。
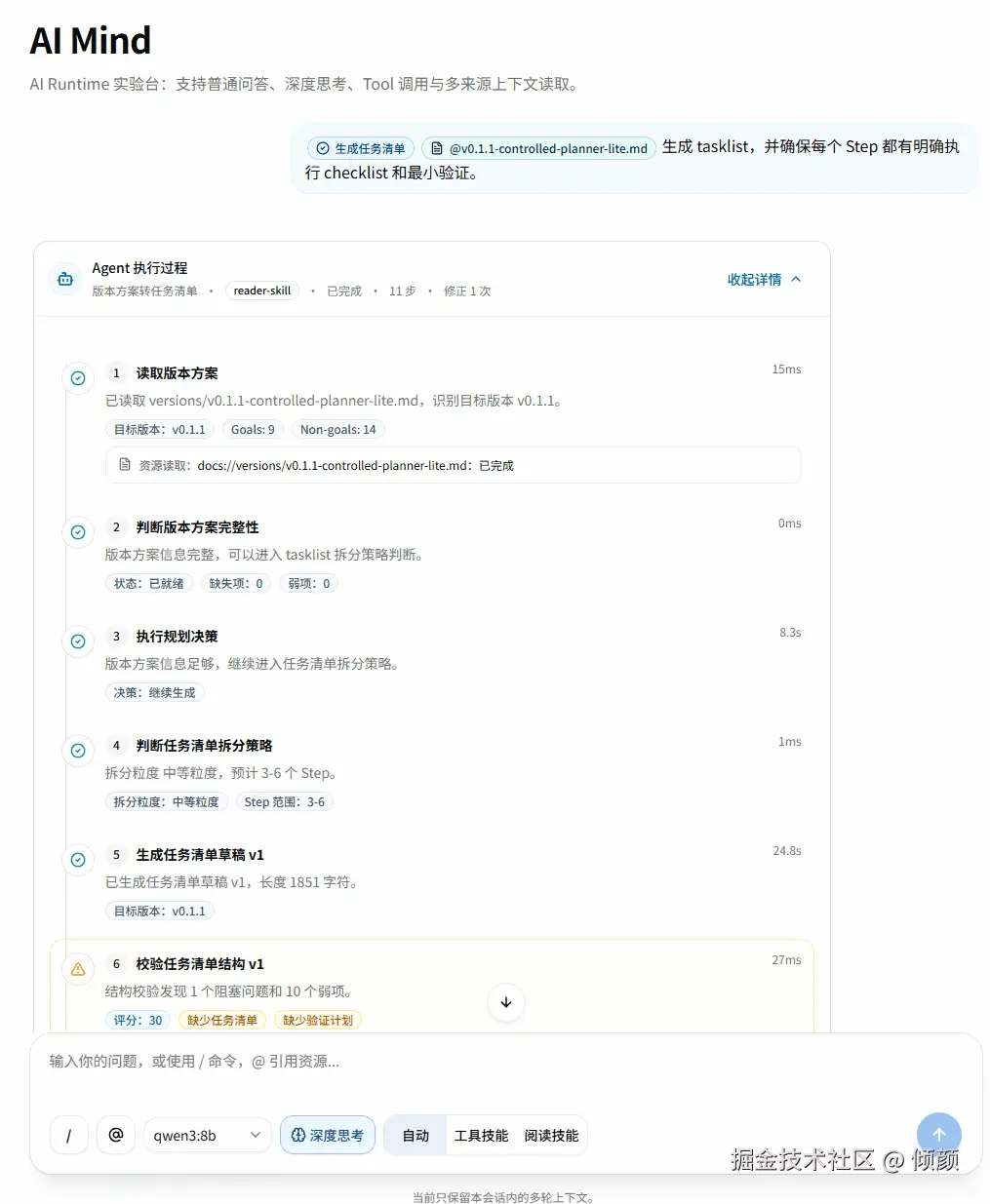
如果只看真实执行链路,v0.1.1 的 Tasklist Agent 可以先简化成这张图:
先看结论
这版的核心判断可以压成一句话:
text
只放开 action 选择,
不放开资源权限、工具权限、写入权限和循环权限。模型可以选择下一步,但只能从运行时给出的安全动作里选。它不能自己决定读取源码,不能扫描目录,不能写入文件,也不能无限修正。
这比纯固定流程更灵活,也没有把整个系统推向开放式 Planner。
v0.1.0:固定流程为什么还不够
v0.1.0 的主链路很直接:
text
读取版本方案
-> 生成任务清单草稿 v1
-> 执行结构校验
-> 必要时自动修正 v2
-> 再次校验
-> 输出最终回答这条链路已经能完成一个受控 Agent 的基本闭环。但真实版本方案并不总是完美的。
有些方案信息完整,可以直接生成。
有些方案主体可用,但缺少测试计划、非目标或风险说明,应该继续生成,但最终提醒人工复核。
有些方案缺少核心目标,继续生成会变成模型脑补。
还有些输入根本不该进入 Tasklist Agent,比如从裸目标生成任务清单、自动读取源码、写入 docs、扫描历史任务清单。
固定流程很难细分这些情况。v0.1.1 想解决的不是"让 Agent 彻底自由",而是让它在关键位置多一次判断。
第一层控制:先判断方案够不够用
在让模型做选择之前,v0.1.1 先加了一层方案就绪度判断(Plan Readiness)。
它回答一个问题:
text
这份版本方案,够不够用来生成任务清单?这一步不调用模型,而是由运行时用规则判断。结果只有三类:
ts
export interface PlanReadinessResult {
// 缺失字段,比如 targetVersion、Goals、tasklistBasis。
missingFields: string[]
// 给 Trace 和最终摘要使用的中文原因。
reason: string
// ready:可继续;needs_review:可继续但需要复核;blocked:不可继续。
status: 'blocked' | 'needs_review' | 'ready'
// 弱项字段,比如 Non-goals、Interface Changes、Test Plan。
weakFields: string[]
}比如目标版本无法识别、正文过短、缺少可拆分目标,就会进入不可继续(blocked)。如果只是缺少测试计划或非目标,则可以继续,但需要在最终结果里提示人工复核。
这一步很重要。模型不是从一片空白开始规划,而是拿到运行时已经整理好的输入判断。
换句话说,方案就绪度不是为了让 Agent 更聪明,而是先给 Agent 画出第一道边界。
第二层控制:模型只能选择 5 种动作
规划决策(Planning Decision)是 v0.1.1 的核心变化。
但这里的"规划"不是自由规划。模型只能从 5 种动作中选一个,真实代码里的合同是这样的:
ts
export type PlanningDecisionAction =
| {
// 方案足够完整,继续进入任务清单拆分策略。
reason: string
type: 'proceed_to_tasklist_strategy'
}
| {
// 只允许读取一个运行时白名单里的补充上下文。
reason: string
resourceUri: VersionPlanTasklistOptionalContextResourceUri
type: 'read_optional_context'
}
| {
// 缺一个关键答案时,本轮输出澄清问题并停止。
question: string
reason: string
type: 'ask_clarification'
}
| {
// 可以继续生成,但把弱项沉淀成最终人工复核点。
reason: string
reviewItems: VersionPlanTasklistManualReviewItem[]
type: 'proceed_with_manual_review_items'
}
| {
// 输入越过 Tasklist Agent 边界,本轮输出边界提示并停止。
message: string
reason: string
type: 'stop_with_boundary_message'
}这 5 个动作覆盖了固定流程最需要分岔的场景。
方案完整,就继续生成。
方案基本可用但需要补一点背景,就读取一个可选上下文。
缺少关键答案,就提出澄清问题。
存在弱项但不阻塞,就带人工复核点继续。
输入越界,就停止。
重点是:模型只能选择方向,不能扩大边界。
第三层控制:状态机决定动作能不能执行
只限制模型输出还不够。
如果模型选择"读取可选上下文(read_optional_context)",运行时还要继续判断:当前状态真的允许读取吗?读取的是不是白名单资源?之前有没有已经读过一次?
这就是状态机的作用。
状态机可以简单理解成一套"当前处在哪个阶段、下一步允许做什么"的规则。
它常见于流程边界很明确的系统里,比如订单状态流转、审批流程、任务执行器、文件上传流程,或者像这里这样的 Agent 执行链路。
它解决的不是"怎么生成内容",而是"系统现在走到哪一步,接下来哪些动作是合法的"。
在 v0.1.1 里,状态机就是 Agent 的执行路线图。它不负责生成文本,也不负责理解语义,它只回答一个很硬的问题:
text
当前状态下,这个动作能不能执行?v0.1.1 的状态不是随便记几个字符串,而是把 Agent 的关键阶段显式拆开:
ts
export type VersionPlanTasklistAgentStatus =
| 'idle'
| 'plan_read'
| 'readiness_checked'
| 'planning_decided'
| 'optional_context_read'
| 'strategy_decided'
| 'drafted_v1'
| 'validated_v1'
| 'revised_v2'
| 'validated_v2'
| 'revision_effect_evaluated'
| 'stopped'
| 'final'这些状态不是为了把实现写得复杂,而是为了把边界说清楚:
idle:刚开始,只能读取用户显式引用的版本方案。plan_read:已经读到版本方案,可以检查方案就绪度。readiness_checked:已经完成规则判断,可以做一次规划决策。planning_decided:模型已经选择了下一步,运行时才允许继续推进。optional_context_read:已经读取最多一个可选上下文。strategy_decided:已经确定任务清单拆分策略,可以生成草稿。stopped:已经澄清或边界停止,不能继续生成。
这带来一个很重要的效果:模型说了不等于系统就做。
比如读取资源这个动作,真实代码里会先看当前状态:
ts
if (state.status === 'idle') {
// 第一轮只能读取用户显式引用的 version plan。
return action.resourceUri === state.versionPlanReference.uri
? { success: true }
: { success: false }
}
if (state.status !== 'planning_decided') {
// 补充上下文只能发生在规划决策之后。
return { success: false }
}
const planningDecision = state.artifacts.planning.decision
if (planningDecision?.type !== 'read_optional_context') {
// 只有 read_optional_context 决策授权后才能补读上下文。
return { success: false }
}这段逻辑解决的是一个常见 Agent 风险:模型一旦觉得"多读一点可能更好",系统就不断打开新的资源入口。
在 v0.1.1 里不会这样。只有当规划决策明确选择读取可选上下文,并且当前状态已经进入 planning_decided,运行时才会允许读取。
而且状态机还会继续检查资源 URI、读取次数和最大步数。
ts
if (action.resourceUri !== planningDecision.resourceUri) {
// 只能读取规划决策指定的那个资源,不能临时换一个。
return { success: false }
}
if (state.counters.optionalContextReads >= state.limits.maxOptionalContextReads) {
// 可选上下文最多读取一次。
return { success: false }
}
if (state.counters.steps >= state.limits.maxSteps) {
// Agent 总步数也有上限。
return { success: false }
}这里的状态机不是"流程图装饰",而是运行时硬边界。
它控制了四类事情:
text
顺序:必须先读方案,再判断就绪度,再做规划决策。
权限:只有特定决策能触发特定资源读取。
次数:可选上下文最多一次,自动修正最多一次。
停止:澄清、边界停止或达到上限后,不允许继续往后跑。受控 Agent 的控制力,不来自一句 prompt,而来自运行时对每一步的硬约束。
模型可以提出选择,但状态机决定这个选择能不能执行。
读取可选上下文:只补读一个白名单资源
规划决策里有一个动作叫读取可选上下文(read_optional_context)。
它的设计目标很克制:如果版本方案基本可用,但补一份项目背景或架构边界能让拆分更稳,运行时允许 Agent 读取一个白名单资源。
白名单不是模型自己决定的,而是代码里固定的:
ts
export const VERSION_PLAN_TASKLIST_OPTIONAL_CONTEXT_RESOURCE_URIS = [
'docs://README.md',
'docs://architecture/agent-runtime.md',
'docs://architecture/capability-skill-surface.md',
'docs://architecture/runtime-boundary.md',
'docs://architecture/stream-core.md',
'project://latest-context',
] as const这意味着模型即使选择了读取可选上下文,也只能在这几个资源里选一个。
它不能读源码目录,不能读历史任务清单,不能扫描版本方案目录,也不能把这一步扩展成开放式资源选择。
读取失败也不会让整个 Agent 崩掉。运行时会降级继续:仍然基于原始版本方案生成任务清单,同时把"补充上下文读取失败"加入人工复核点。
这一步的目标不是让 Agent 无限制知道更多,而是只在需要时补读一个受控上下文。
拆分策略:结构化地影响下一次生成
这里要说清楚一点:任务清单拆分策略最终仍然是通过提示词(prompt)影响下一次模型生成。
它不是一个单独的执行器,也不会直接修改草稿内容。
但它和普通"多写几句提示词"不一样。v0.1.1 先让模型输出结构化的任务清单拆分策略(TasklistStrategy),运行时会校验它、保存它,然后在生成任务清单草稿时,把它明确注入 draft prompt。
所以这里的关键不是"脱离 prompt",而是让 prompt 增强变得受控:
- 策略字段是固定的。
- 输出必须通过 schema。
- 策略会写入本轮 AgentState。
- 后续 draft prompt 必须消费它。
- 它只能影响粒度、步骤范围、分组和优先级,不能扩大版本方案范围。
真实代码里的策略结构是这样的:
ts
export interface TasklistStrategy {
// 预计生成多少个 Step。
expectedStepRange: [number, number]
// 拆分粒度:粗粒度、细粒度或中等粒度。
granularity: 'coarse' | 'detailed' | 'medium'
// Step 标题和章节优先围绕这些分组组织。
grouping: string[]
// checklist 和执行顺序优先遵循这些优先级。
priority: string[]
// 说明为什么这样拆。
reason: string
}在生成任务清单草稿时,它会被写进草稿生成提示词,变成明确的生成约束:
text
任务清单拆分策略:
- Step 数量尽量落在 expectedStepRange 之间。
- Step 标题和顺序优先围绕 grouping 组织。
- 每个 Step 内 checklist 的先后顺序优先遵循 priority。
- 拆分粒度遵循 granularity。
- 不得新增版本方案中没有的能力范围。所以,TasklistStrategy 不是在替代 prompt,而是在把 prompt 增强从"自由文本建议"变成"结构化、可校验、由运行时注入的生成条件"。
规则和模型怎么分工
v0.1.1 的分工可以概括成:
text
模型负责选择和生成,
运行时负责边界和判断。模型负责语义弹性更强的部分:选择下一步、生成澄清问题、生成边界提示、生成拆分策略、生成草稿、修正一次草稿。
规则负责确定性更强的部分:方案是否够用、动作能不能执行、上下文是否在白名单、警告该自动修还是人工复核、修正是否有效、最多走多少步。
如果所有判断都交给模型,系统会更"聪明",但也更难测试、更难复现。
如果所有东西都写成固定规则,系统会很稳,但不够灵活。
v0.1.1 选择的是中间路线:让模型参与一次方向判断,但把边界控制留给运行时。
不是所有 warning 都应该自动修
任务清单草稿生成后,会执行结构校验。
v0.1.0 的规则比较粗:发现问题后最多自动修一次。v0.1.1 则增加了警告分流(WarningDisposition),把问题分成两类:
ts
export interface WarningDisposition {
// 需要立即自动修正的问题编号。
fixNow: string[]
// 不自动修,但要展示给用户确认的问题。
manualReviewItems: VersionPlanTasklistManualReviewItem[]
// 本次分流的说明。
reason: string
}结构硬伤,比如缺少实施步骤、缺少清单项、缺少工程验证,进入立即修正(fixNow)。
质量弱项,比如风险说明偏弱、暂停点需要人工确认,则进入人工复核点(manualReviewItems)。
这一步很小,但很有工程意义。不是所有"不完美"都应该交给模型继续修。有些不确定性,明确告诉人看一眼,反而更可靠。
修了以后,还要知道有没有变好
如果触发自动修正,v0.1.1 还会做修正效果评估(Revision Effect)。
它会比较 v1 和 v2 的结构校验结果:
ts
export interface RevisionEffectResult {
// 最终结论:可采用、需人工复核,或阻塞。
finalDecision: 'blocked' | 'final' | 'final_with_manual_review_items'
// 已经修掉的问题编号。
fixedIssues: string[]
// 分数是否提升。
improved: boolean
// 仍然存在的问题编号。
remainingIssues: string[]
// 修正后分数。
scoreAfter: number
// 修正前分数。
scoreBefore: number
}这里同样不让模型自由总结,而是基于稳定的问题编号比较。
如果 v2 仍然失败,最终结论会变成阻塞(blocked),并提示当前草稿不建议直接采用。但这一版不会继续生成 v3。
原则很明确:
text
可以自动补一轮结构问题,
但不能把自动修正变成无边界循环。Trace 展示过程,Artifact 展示产物
后端有状态机、有规则、有质量门,如果前端只展示最后一段文本,用户其实感知不到这些过程。
所以 v0.1.1 继续强化了 Agent 执行过程面板(AgentTracePanel)。它展示的是轻量摘要,而不是完整调试日志:
text
方案是否就绪
规划决策选择了什么动作
是否读取了可选上下文
拆分策略的粒度和步骤范围
警告分流结果
修正效果
最终决策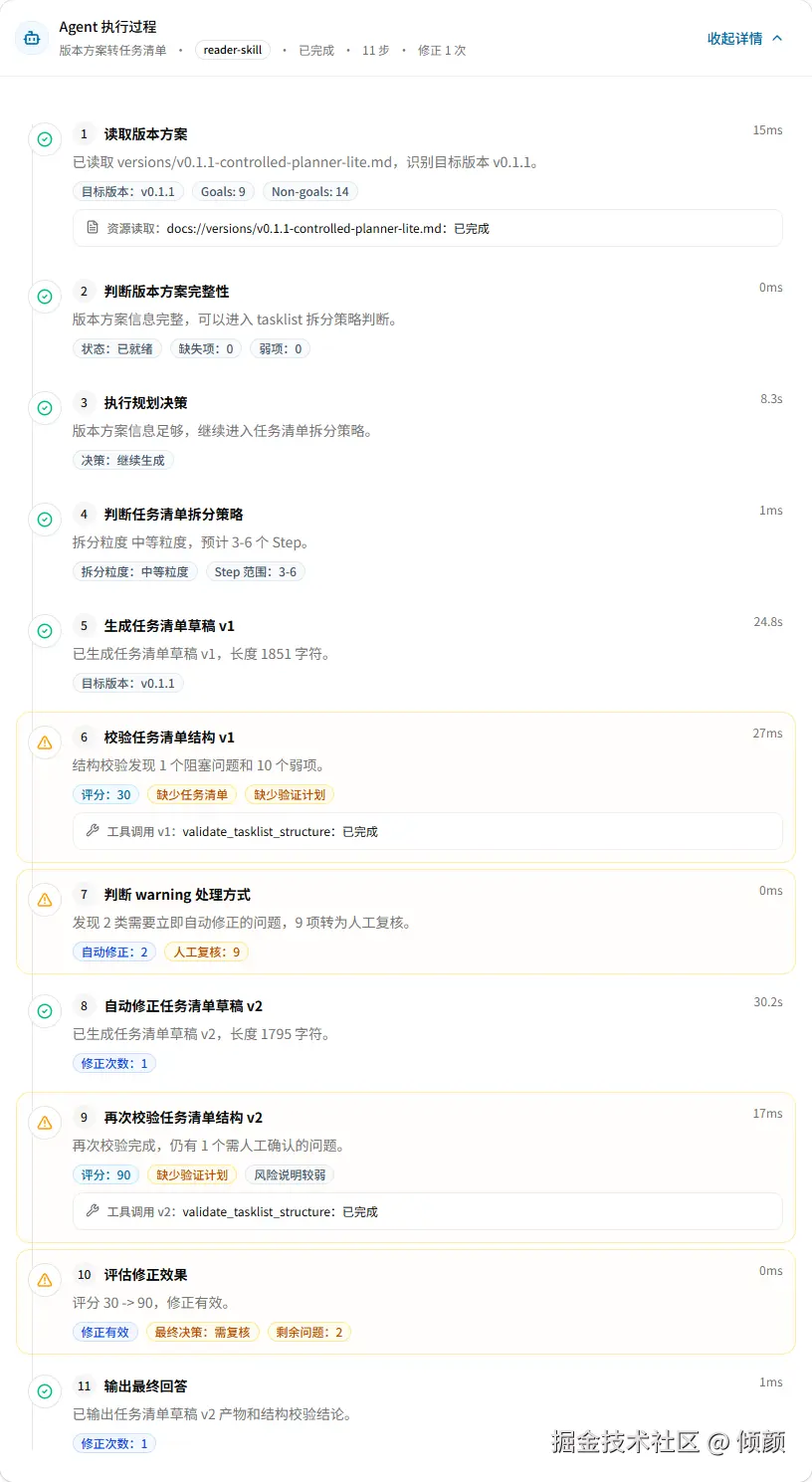
同时,最终任务清单正文不再混在普通聊天回答里,而是通过 Agent 文本产物面板(AgentTextArtifactPanel)独立展示。

最终回答分成三层:
text
执行过程:AgentTracePanel
最终产物:AgentTextArtifactPanel
摘要说明:普通 assistant text这个分工对 AI 应用前端很重要。Agent 类应用不能只设计"最后答案"。过程应该可追踪,产物应该可复制、可独立阅读,摘要应该帮助用户判断当前产物是否能用。
这一版刻意收住了什么
更准确地说,v0.1.1 只验证一件事:
text
在固定流程里开放一次受控选择权,
但不顺手放开资源、工具、写入、循环和持久化。所以这一版把下面这些能力先放在边界外:
- 不把 Tasklist Agent 扩成通用 Agent Runtime 或多 Agent。
- 不用 LangGraph 替换当前 Runtime,也不做开放式规划执行。
- 不开放自由工具调用,仍然只允许结构校验这个受控工具。
- 不自动扫描版本目录,不读取历史任务清单,也不从裸目标直接生成任务清单。
- 不写入 docs 文件,最终只输出可复制的任务清单草稿。
- 不做暂停 / 恢复 / 检查点,也不持久化 AgentState。
- 不生成 v3 自动修正,不把 Artifact 做成产物工作台。
这样写边界不是为了证明"还没做什么",而是为了保护本版主题:当模型只有一次选择权时,运行时能不能仍然把这次选择控制住。
这版证明了什么
v0.1.1 最重要的结论,不是"模型会规划了"。
更准确地说,它证明的是:
text
一个固定流程 Agent,可以先演进成有限决策 Agent。这中间不一定要一步跳到自由规划。
在这版里,模型只做一次选择。选择范围只有 5 种。资源只能读白名单。工具只有结构校验。自动修正最多一次。最终不写入文件。什么时候停止,由状态机决定。
但即便限制这么多,Agent 的行为已经比固定流程更灵活。
它可以在方案太弱时提出澄清问题。
它可以在输入越界时停止。
它可以在方案可用但有风险时带人工复核点继续。
它可以在需要时补读一个受控上下文。
它可以用拆分策略影响最终草稿。
这就是"一次受控规划决策"的价值:在受控系统里增加一点可解释的弹性。
后续方向
v0.1.1 之后,我更想继续沿着"受控增强"的路线推进。
后续更值得评估的是:
text
Agent Trace 持久化
任务清单草稿保存与人工确认流
更完整的 Agent 动作执行器
和 LangGraph 做边界清晰的对照实验这些都不应该回填到 v0.1.1。
这一版已经完成了它该完成的事情:让第一个 Tasklist Agent 从固定流程,迈到一次有限决策。
结尾
AI Mind v0.1.1 做的是一件很小、但对我很关键的事:在一条已经受控的任务清单生成链路里,让模型获得一次有限选择权,再用运行时状态机、白名单、规则判断、质量门和前端展示把这次选择落住。
这版真正让我确认的是:
text
Agent 工程化不一定从"自由规划"开始,
也可以从"固定流程里的第一次受控分岔"开始。这也是我目前更认可的 Agent 演进路线:
text
先让它可控,
再让它有限选择,
最后再讨论更开放的规划执行。项目地址:
如果你也在关注 AI 应用前端、运行时编排、工具调用、MCP 或 Agent 工程,可以顺手点个 Star。这个项目会继续按版本迭代,每一版都会尽量把源码、设计文档、任务清单、发布记录和复盘文章一起留下来。