一、背景介绍
在 AI 应用开发中,调用云端 API 虽然方便,但存在数据隐私、网络延迟和调用成本等顾虑。有没有一种方案,既能享受大模型的能力,又能把数据完全留在本地?
Ollama 正是为解决这个问题而生的。它是一个开源的、专为在本地运行和管理大型语言模型(LLM)而设计的轻量级工具。简单来说,它的核心作用是:让你能像运行一个普通程序一样,在自己的电脑上轻松下载、运行和试验各种开源大模型(如 Llama 3、Qwen、Gemma、DeepSeek-R1 等),而无需了解复杂的模型部署、环境配置或依赖管理。
本文将完整演示:从 Ollama 的安装、模型下载,到使用 LangChain 1.0 的新语法调用本地模型的全过程。
二、方案分析:本地部署 vs 云端 API
| 维度 | 本地部署(Ollama) | 云端 API |
|---|---|---|
| 数据隐私 | 数据不离本机,适合敏感场景 | 数据需上传至服务商 |
| 网络依赖 | 离线可用 | 必须联网 |
| 调用成本 | 仅需硬件电费 | 按 Token 计费 |
| 模型选择 | 受限于本地硬件和 Ollama 支持的模型库 | 取决于服务商提供的模型 |
| 响应速度 | 受本地 GPU/CPU 性能限制 | 通常更快(尤其高并发) |
| 适用场景 | 开发调试、隐私敏感、离线环境 | 生产环境、需要最新模型 |
选型建议:开发阶段用 Ollama 本地调试,降低成本并保护数据隐私;生产环境根据需求选择云端 API 或自建服务。
三、实操步骤
3.1 第一步:安装 Ollama
macOS 用户(最省事)
直接前往 Ollama 官网 下载 .dmg 安装包,拖进 Applications 即可。安装完成后,菜单栏会多出一个小羊驼图标,那就是后台常驻的服务进程。
Linux 用户(脚本安装)
执行以下命令,脚本会自动检测 GPU(NVIDIA / AMD),把对应的运行时一并装好:
bash
curl -fsSL https://ollama.com/install.sh | sh安装完成后,服务通常以 systemd 单元的形式注册,可用以下命令查看状态:
bash
systemctl status ollama3.2 第二步:拉取并运行模型
Ollama 的模型库非常丰富,从通用对话模型到代码专用模型应有尽有。以 DeepSeek-R1 为例(当前热门的中文开源推理模型):
bash
# 拉取模型(首次需要下载,根据网络情况可能需要几分钟到几十分钟)
ollama pull deepseek-r1:latest
# 运行模型,进入交互式对话
ollama run deepseek-r1:latest运行后会进入交互式终端,可以直接与模型对话。比如:
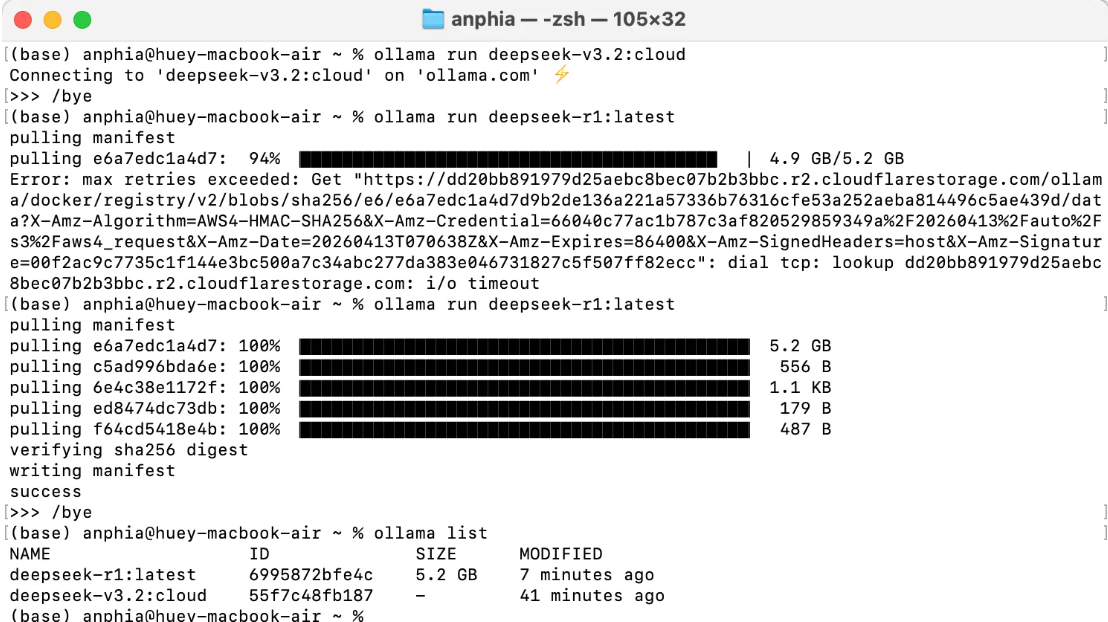

按退出用 /bye,查看可用指令用 /?退出交互模式。此时模型已下载到本地,Ollama 服务在后台运行,默认监听 http://localhost:11434。
3.3 第三步:LangChain 集成
确保已安装 LangChain 1.0 及 Ollama 适配包:
bash
# 使用 uv(推荐)
uv add langchain langchain-ollama
# 或使用 pip
pip install langchain langchain-ollama3.4 第四步:编写调用代码
LangChain 1.0 推荐使用 init_chat_model 统一接口,相比 0.x 版本更加简洁通用。
新版代码(LangChain 1.x 推荐写法)
python
"""
使用 LangChain 1.x 访问 Ollama 本地大模型
"""
from langchain.chat_models import init_chat_model
# 初始化模型:通过 ollama: 前缀指定本地 Ollama 服务
model = init_chat_model(
model="ollama:deepseek-r1:latest", # ollama:前缀 + 模型名称
base_url="http://localhost:11434", # Ollama 默认服务地址
temperature=0.1, # 控制输出随机性
timeout=30, # 请求超时时间
max_tokens=2000, # 最大生成 Token 数
)
# 流式调用:逐块获取响应
for chunk in model.stream("来一段唐诗"):
print(chunk.content, end="", flush=True)关键配置解析:
| 参数 | 说明 | 注意事项 |
|---|---|---|
model="ollama:deepseek-r1:latest" |
模型标识,ollama: 前缀告诉 LangChain 走本地 Ollama 适配器 |
名称必须与 ollama list 显示的完全一致 |
base_url |
Ollama 服务地址 | 默认 http://localhost:11434,若改端口需同步调整 |
temperature |
输出随机性,0-2 之间 | 创意任务取 0.7+,确定性任务取 0-0.3 |
timeout |
本地模型首次加载较慢,建议设长一些 | 首次运行可能需要 30-60 秒加载模型到内存 |
max_tokens |
限制单次响应长度 | 根据本地显存调整,避免 OOM |
旧版代码(LangChain 0.x 写法,仅供对比)
python
"""
LangChain 0.x 的语法(已废弃,仅供对比)
"""
from langchain_ollama import ChatOllama
def main():
# 直接导入特定 provider 的模型类
llm = ChatOllama(
model="deepseek-r1:latest", # 模型名称
base_url="http://localhost:11434", # 服务地址
temperature=0.1, # 温度
num_predict=512, # 最大生成 token 数(参数名不同)
)
messages = [
(
"system",
"You are a helpful assistant that translates English to French. "
"Translate the user sentence.",
),
("human", "I love programming."),
]
# 支持传入消息列表或纯字符串
response1 = llm.stream(messages)
response2 = llm.stream("来一段宋词")
for chunk in response1:
print(chunk.content, end="", flush=True)
for chunk in response2:
print(chunk.content, end="", flush=True)
if __name__ == "__main__":
main()四、验证效果:新旧语法对比
4.1 核心差异总结
| 维度 | LangChain 0.x | LangChain 1.x |
|---|---|---|
| 导入方式 | from langchain_ollama import ChatOllama |
from langchain.chat_models import init_chat_model |
| 模型标识 | model="deepseek-r1:latest" |
model="ollama:deepseek-r1:latest"(需加 ollama: 前缀) |
| 最大 Token 参数 | num_predict=512(Ollama 专属参数名) |
max_tokens=2000(统一参数名) |
| 接口通用性 | 每个 provider 独立的类 | 统一 init_chat_model,切换 provider 只需改前缀 |
| 代码可维护性 | 多模型场景代码冗余 | 一套 API 适配所有 provider |
4.2 为什么推荐 1.x 写法?
- 统一抽象 :无论底层是 Ollama 本地模型、DeepSeek API 还是 OpenAI,
init_chat_model的调用方式完全一致,仅需修改model字符串; - 参数标准化 :
max_tokens、timeout等参数名统一,不再记忆各 provider 的专属命名; - 生态一致性:LangChain 社区的新功能(如工具调用、结构化输出)优先在统一接口上支持。