之前我写过一篇罗福莉的10个观点,引起了挺多讨论,赞同的有,不赞同的也有。
其中有个观点,我深有感触:「市场上大部分Multi-Agent是伪的。速度快了,成本低了,但任务能做到的上限没有因此突破。多加几个Agent,不等于能做更难的事,更多时候只是把事情更复杂化了。」
不只是市面上的产品,包括很多个人开发者搭建的多Agent团队,一样踩着这三个坑。
- 坑1:任务越复杂,系统越乱。Agent数量一上去,彼此的信息就开始打架。
- 坑2:任务发下去之后,你完全看不到子Agent正在干嘛。等它回来汇报的时候,你已经急得疯狂艾特主脑什么情况了。
- 坑3:所谓的「主脑」没在调度,它自己下场了。老大不派活,开始cos小弟,自己把活全揽了。我搭Hermes多Agent团队的时候就遇到过这个问题,还被我抓个现行。
我最近用了OmniWork跑了复杂长任务,多Agent的体验很丝滑,从0到1干了一条品牌营销短片,像雇了位知乎大神,没有质疑,只有欣赏。

(我笑死,突然就燃起来了。。)
而做到上面这个结果,我只提供了logo、产品设计草图和一段参考视频。
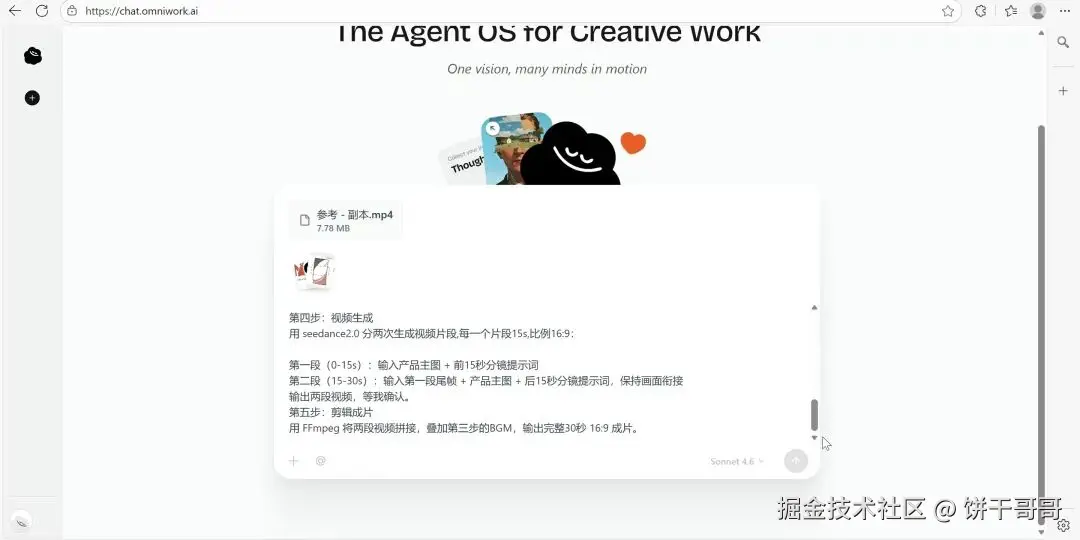

整个任务是这样的:生成产品图 → 生成视频脚本 → 创作30秒BGM → seedance 2.0生成视频 → FFmpeg剪辑成片。
只要你提供的信息和提示词够完整,全程甚至都不需要干预。
整体使用下来的感受:OmniWork就像一个知乎上的'全干专家'------你问什么领域,它都能给你干出结果来,不只会说,还会做
01 为什么多Agent做不好?几个绕不开的原因
先把多Agent的两种架构搞清楚,因为真的有很多人在混用:sub-agent 和 team-agent。
sub-agent
team-agent
结构
主脑 + 小弟
平级团队
通信
子Agent不互通,结果统一汇回主脑
成员之间可直接沟通协商
生命周期
用完即散,下次重新召唤
长期存在,持续运行
状态共享
无
有共享任务列表
适合场景
独立并行、上下文不重叠的任务
需要协商、上下文有依赖的任务
两者怎么选,核心看一个点:子任务之间有没有上下文依赖。没有依赖、彼此独立,用sub-agent,隔离干净;有依赖、需要协商,用team-agent,让成员直接沟通。
而网上大多数帖子、文章中90%的「多Agent」实现,其实是sub-agent的变体。主脑不停拆任务、发任务、追任务,而子Agent只是执行机器。
这套模式在简单场景还好。任务一复杂,主脑的信息压力就超出上下文,开始产生幻觉,子Agent执行的东西就开始乱。
多Agent做不好,几个根本原因:
-
- 错误被放大,不是被消化。 一个子Agent的小偏差,在链路里传几手就变成大问题。多Agent不会自动纠错,只会让问题跑得更远。
-
- 复杂度指数涨,能力线性涨。 加一个Agent,加的不只是能力,还有通信链路、状态同步和失败路径。复杂度涨得比能力快得多。实践中2-3个Agent精准配合,往往比堆出来的8个跑得更稳。
-
- 按角色拆,不按上下文拆。 规划、执行、审核各一个Agent,听起来很专业,但每次交接信息就衰减一次。正确的拆法是按上下文隔离,不是按角色分工。
-
- 串行任务根本不适合多Agent。 任务越串行,越没必要多Agent。多加的那几个Agent,不是在帮你做事,是在中间加噪声。
sub-agent 本身没有错,错的是大多数实现质量太烂------主脑上下文超限开始幻觉,子 Agent 工具调用是 prompt 包装不是真工具,任务跑到哪一步全靠猜。这这几件事,大多数系统连一件都做的不干净。
而测试是不是伪多Agent的做法很简单,就是直接扔复杂任务进去看效果。

02 长任务永远的痛,OmniWork实战效果如何?
多说无益,跑几个case就看出来了。
Case 1 从选品到达人筛选,沉淀可复用工作流
做跨境品牌想找TikTok达人做推广。通常这需要:做市场调研 → 筛选品类 → 找达人 → 写邀约文案。四步拆开来,选品要懂 TikTok 趋势,脚本要懂内容创作,筛达人要会看账号数据,邀约信最简单,但任何一步都要花时间。
我让它帮一个狗狗沐浴露产品跑完整个任务,跟以往的多Agent一样,先分工,再开始。 Trending-Content-Monitor做选品,Account-Monitoring-Expert筛达人,主脑也不闲着。
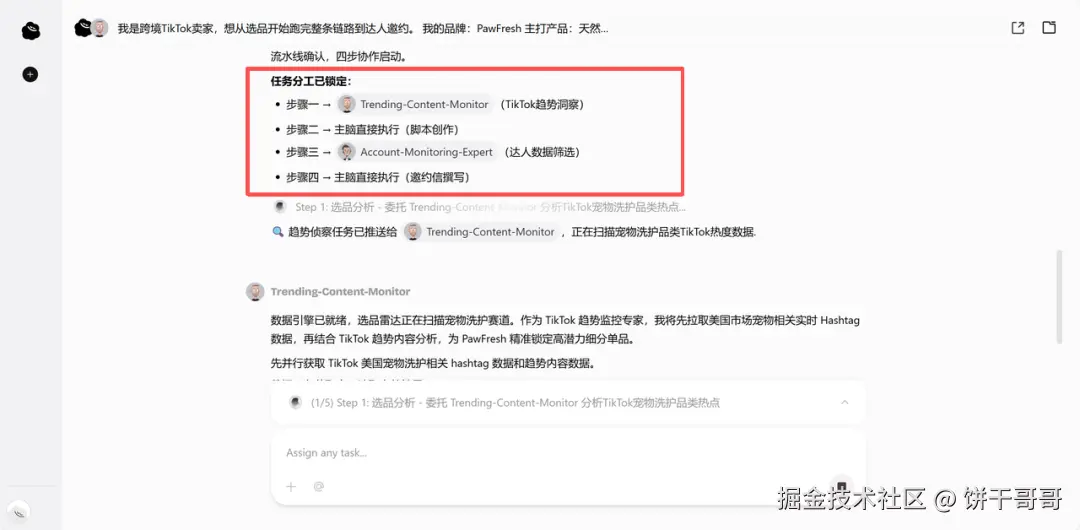
任务开始,率先调用Trending-Content-Monitor 跑完选品,锁定了第一名天然椰油配方狗狗沐浴露 × #dogbath 赛道,54亿话题播放量、近90天持续上升。上下文打包好,任务交接给下一个专家干活。
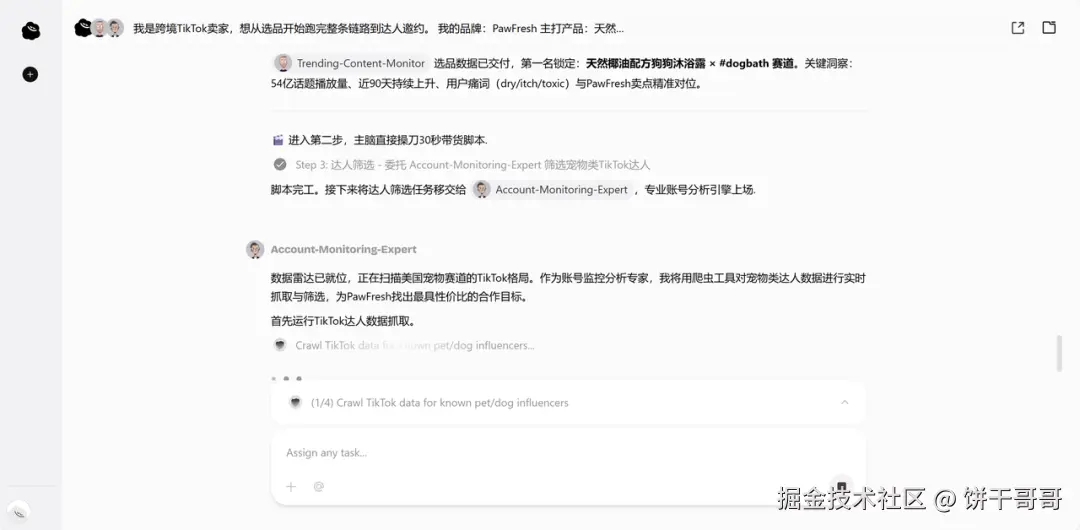
Account-Monitoring-Expert筛出达人后,不信邪的我随机抽查了一个账号@the poodle mom,确实是一个贵宾犬护理垂直账号。
筛出来的达人居然是真实存在的,说明它确确实实抓取到了数据,不是编的。
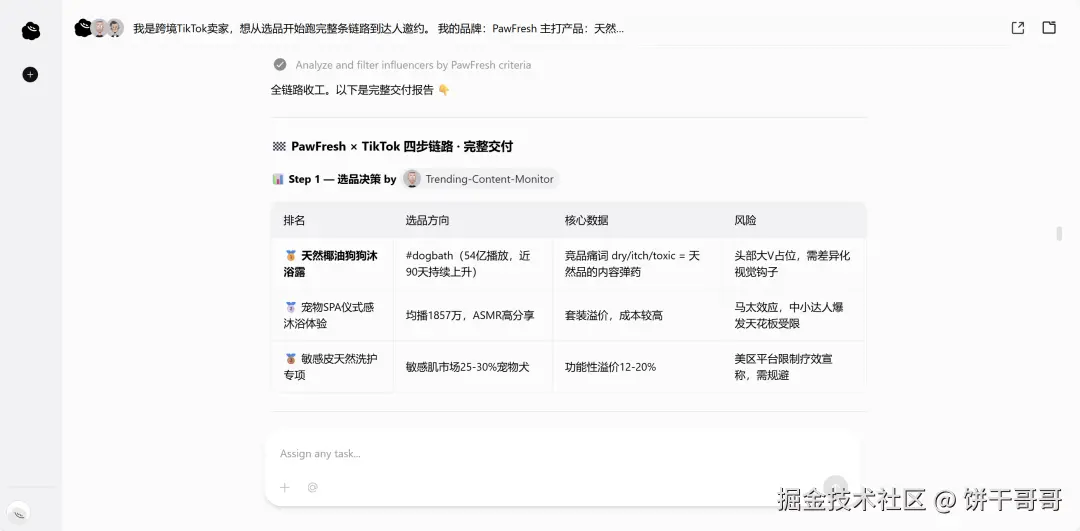
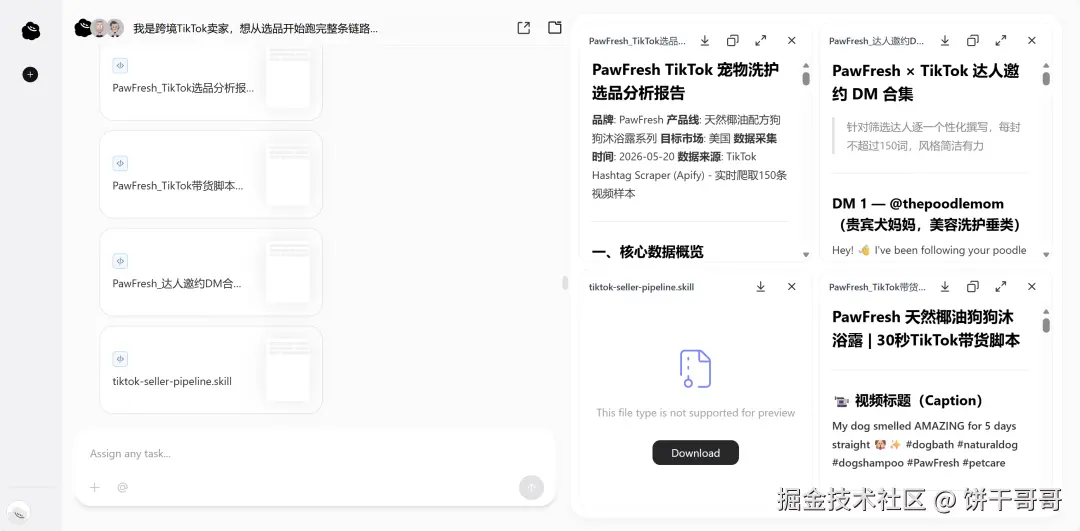
整个任务我从提示词下发就没有干预过了,最后OmniWork也顺利交付了四个文件。
达人名单有具体数据,每个附优先级和推荐理由,5封DM按达人风格各自写,不是套模板。选品报告给了三个方向,当然这是AI跑出来的,最重要还是人自己的判断,所以有没有做宠物洗护品类的朋友,也判断下AI分析的准不准哈哈哈。
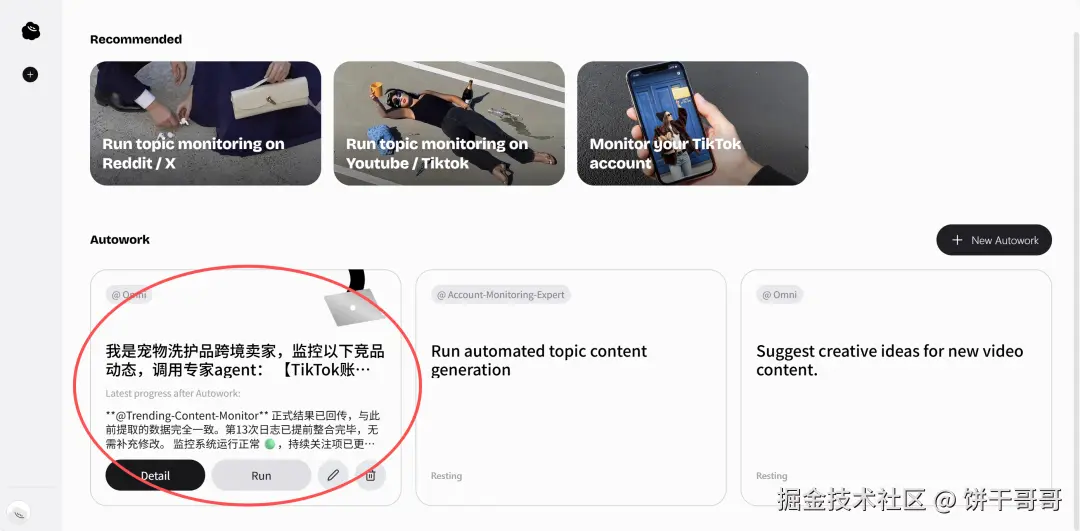
Case 2 TikTok和Reddit双平台监控,实时推送竞品数据
竞品监控这件事,麻烦在于它不是跑一次就完的。TikTok上竞品发了什么爆款、Reddit用户在骂哪个品牌,随时在变。两个平台、好几个账号、发布的内容、每小时一次,靠人根本盯不过来,更别说「第一时间发现爆款」,等你刷到,流量早过了。
所以我给它的任务:监控四个TikTok竞品账号,同时抓Reddit三个版块的舆情,第一次立即执行,之后每小时自动运行。
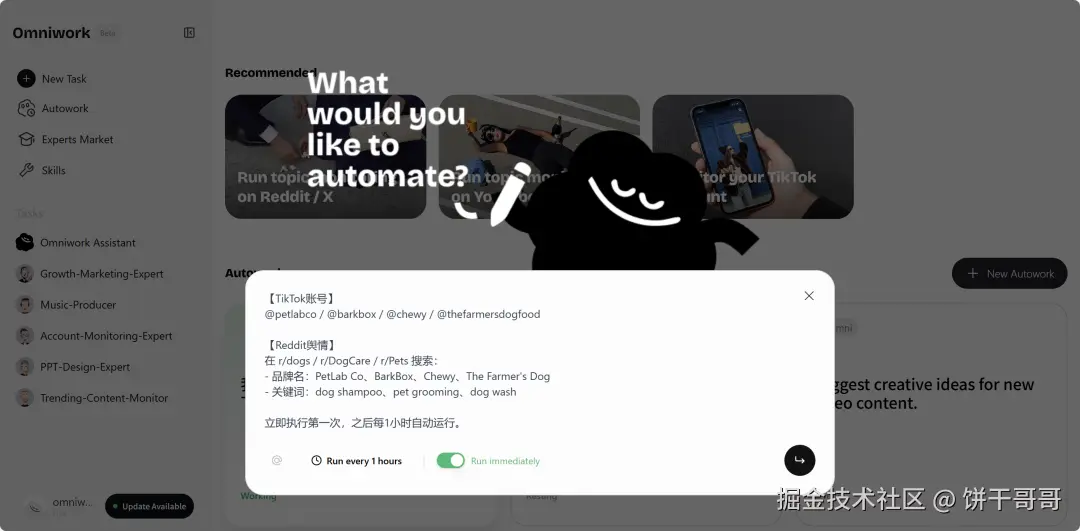
关键在入口:我在定时任务界面直接输入指令,一次到位,不用跑完再说「帮我设成定时任务」。退出会话之后,任务还在跑。这就是Autowork。
执行开始,Account-Monitoring-Expert 和 Trending-Content-Monitor 并行出动,一个抓TikTok账号数据,一个跑Reddit舆情扫描。
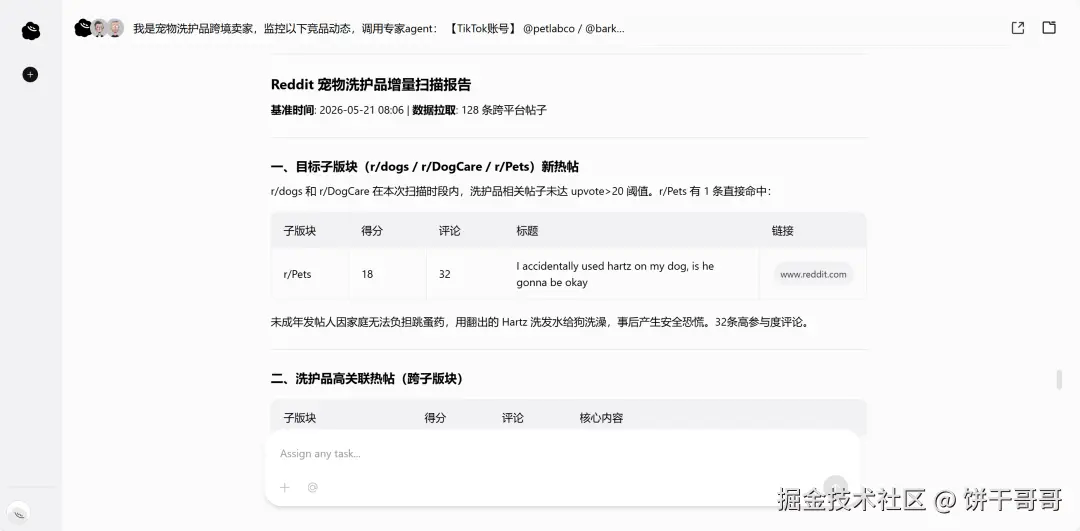
然后它识破了我设计的陷阱:它发现 @barkbox 没有内容,真正的账号是 @bark(Shop BARK);@thefarmersdogfood 不存在,正确账号是 @thefarmersdog,事实也如此。
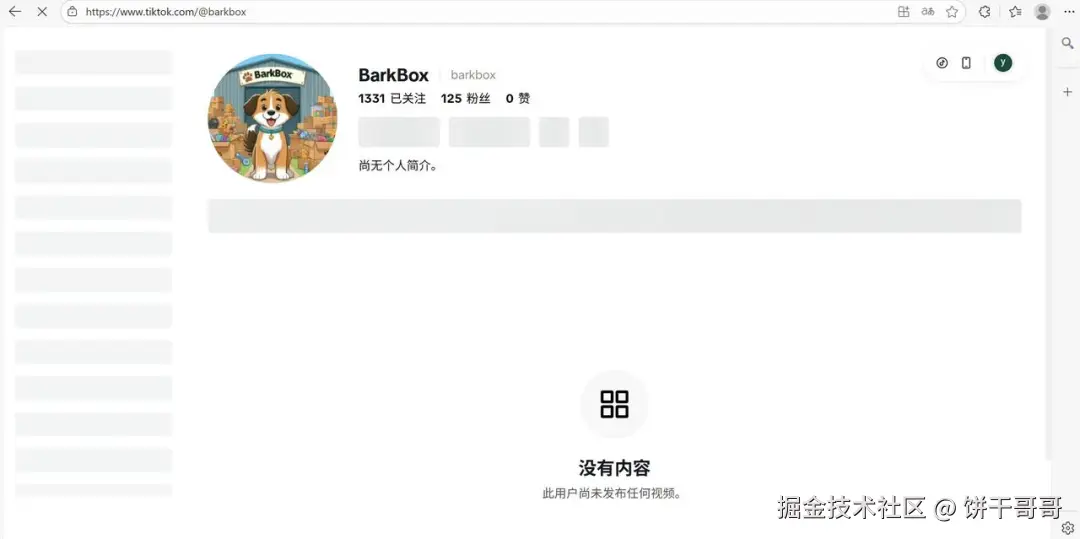
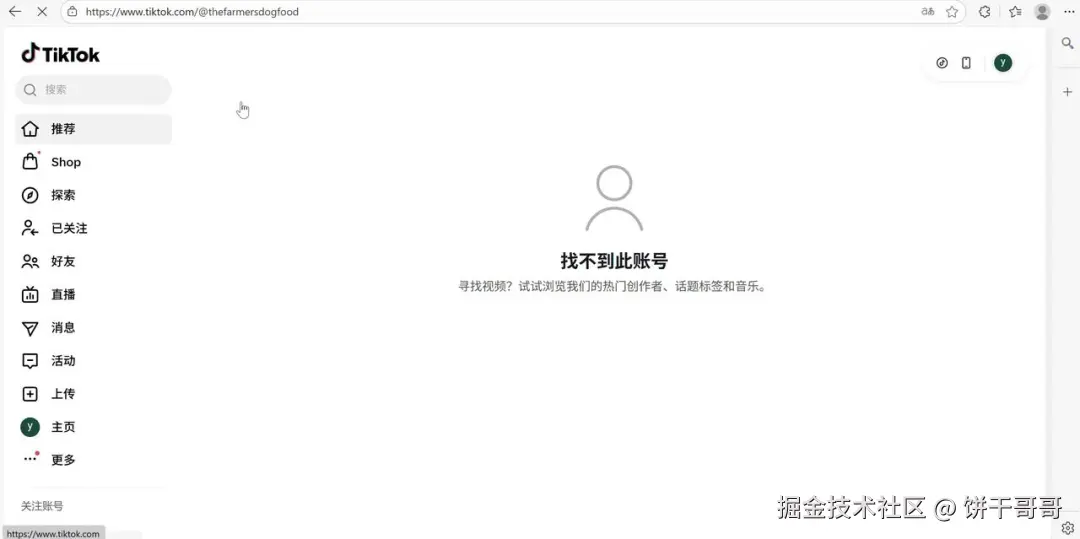
它是真的去抓数据了,发现对不上然后告诉你。
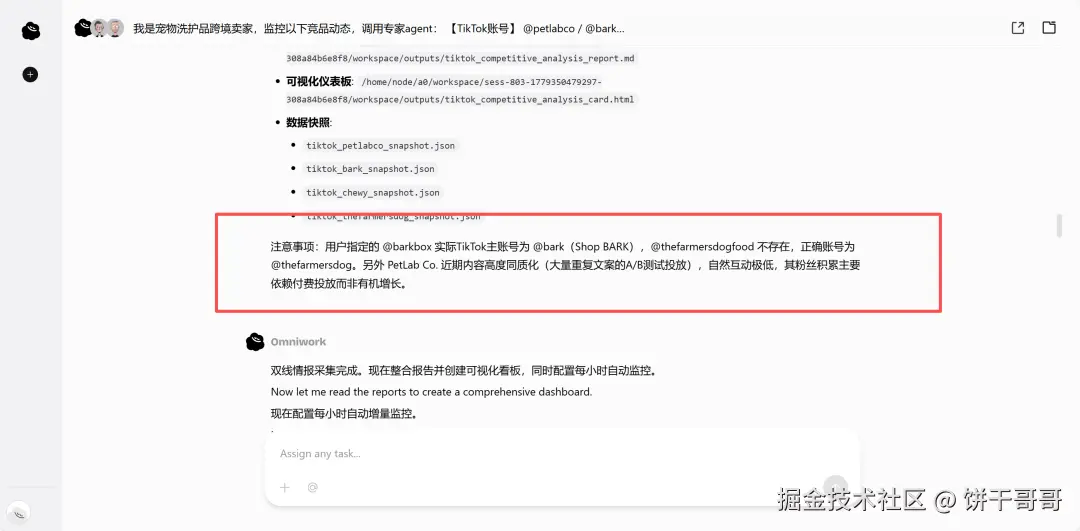
跑完第一轮,右下角弹出「要不要创建Skills」。点Sounds Good。
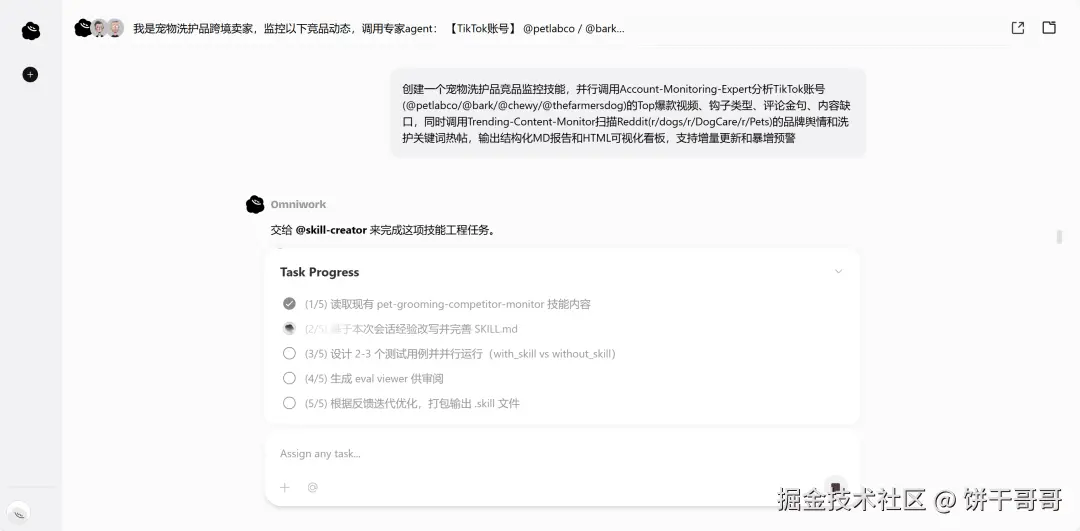
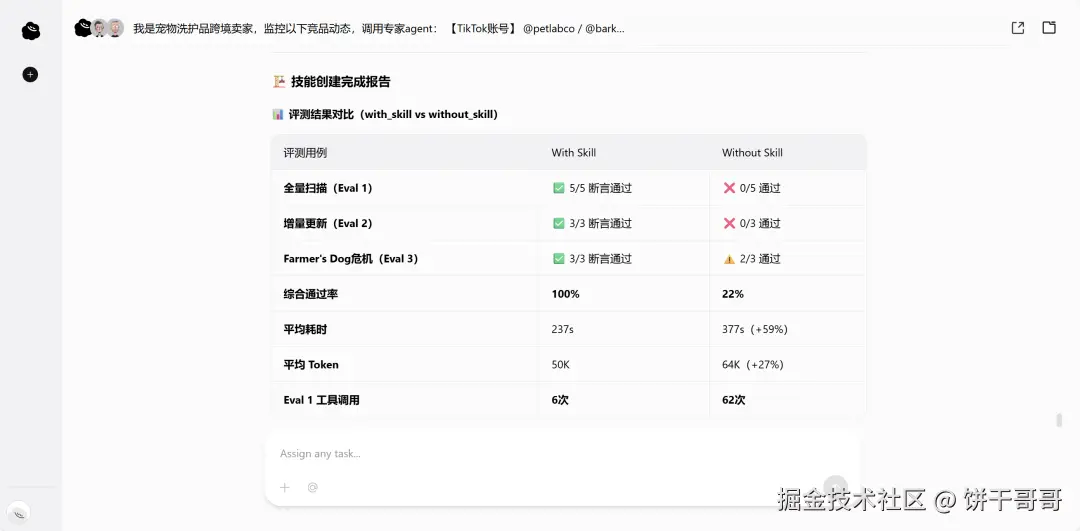
它自动拟好提示词,启动6个测试任务并行跑,还生成HTML评测看板,附上benchmark结果。这也是惊艳我一点,跑着跑着开始创建skills打副本了!有多少人的skills是让AI写了一大堆Markdown,而OmniWork是真跑了测试、出了数据、优化了再打包。
回头一看,定时任务已经在对话框自动触发了,输出Reddit增量报告和TikTok账号动态。我没有守着它,它自己在跑。
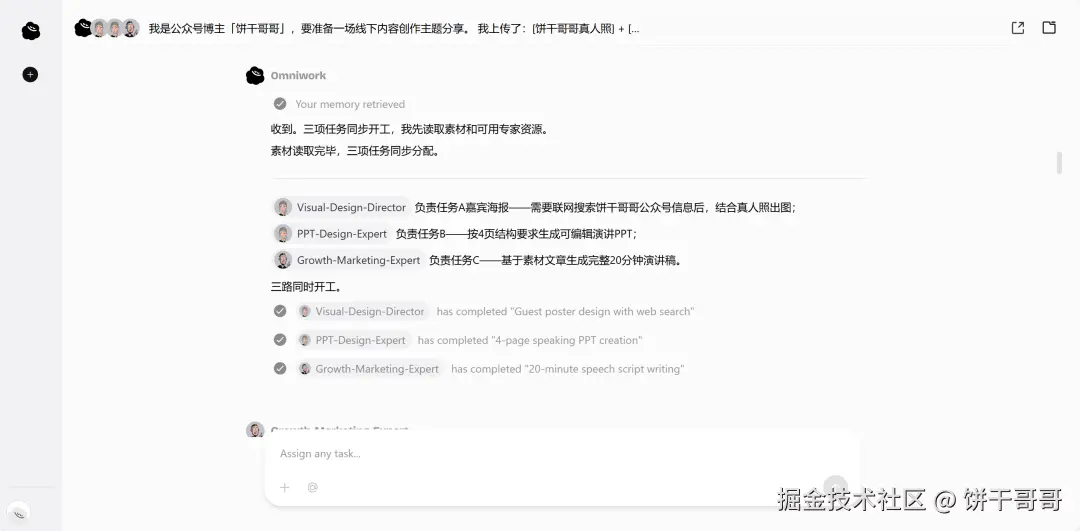
Case3 准备线下分享会,10分钟直出海报、PPT、演讲稿
前两个 Case 都是跨境电商的活。但作为一名博主,还有一件事让我苦恼:准备线下会的物料、文稿。
通常这件事要做三样东西:嘉宾海报、演讲 PPT、演讲稿。三件事加起来自己做怎么也要一两天、找个外包也要一两百。
而这次我只提供了两样东西:一张真人照,加一篇之前写好的素材文章。主脑派了三个 Expert 各自接活,三路同时开工。
Visual-Design-Director 接了海报:我让它联网搜索「饼干哥哥」的相关信息,提取真实的成绩和定位数据,再结合真人照生成嘉宾介绍海报。它搜出来的不是通用介绍,是真实数据,直接写进海报文案。

卧槽没想到 AI 还认识我了。。
PPT-Design-Expert 接了 PPT:基于素材文章,生成演讲 PPT,风格是科技感排版,层次感清晰,线下投屏直接用。


Growth-Marketing-Expert 接了演讲稿:基于同一篇文章,生成完整20分钟演讲稿,约3000字,口语化,按 PPT 分节标注。
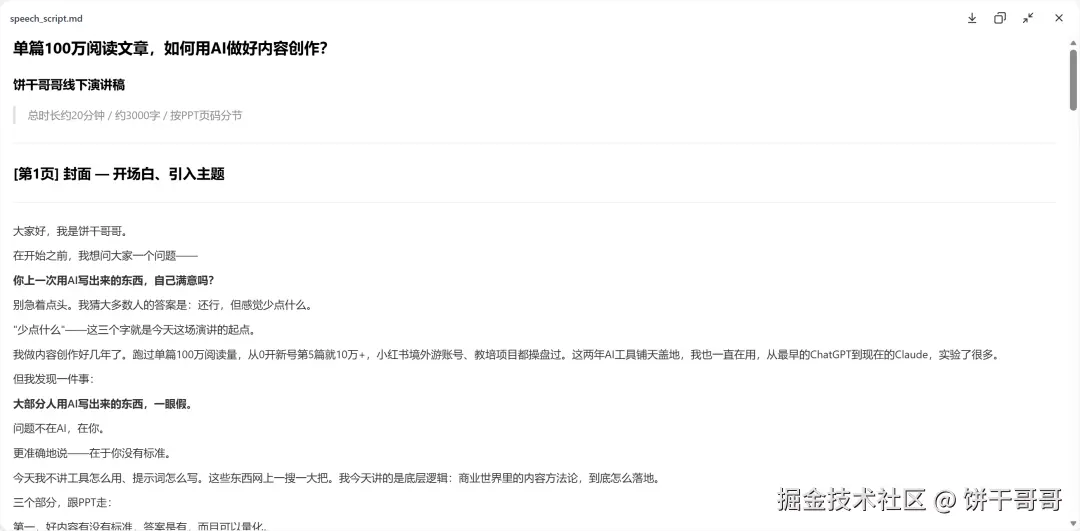
三个 Expert,三件完全不同的事------视觉设计、PPT 制作、内容写作,并行跑完。前后不到10分钟。
这就是「全干」的意思。不是什么都能聊,是什么都能交付出来。
03 多Agent任务跑烂,其实是差在执行层
多 Agent 被需要,原因只有一个:执行。并行跑、持续跑、分工跑,一个上下文窗口装不下的任务量,拆开给多个 Agent 各执行一块;不是为了让 AI「想得更聪明」,深度推理这件事,单 Agent 反而更稳。
但执行层,是绝大多数产品真正烂掉的地方。
症状你一定见过。Expert 说自己会抓数据,但实际上是套了一层「我是爬虫专家」的 prompt------数据哪来的?网络拦截那一关就已经死掉了,只能靠编;Skill 生成了一堆 md 和 py 文件,下次调用能不能成功全靠运气;一个复杂任务下来 Token 爆炸,基本消耗在你重复跟主脑强调需求和 Agent 间对话上,真正干活的寥寥无几。
能演示,跑不稳。这是大多数多 Agent 产品的真实状态。
而 OmniWork 做对的地方,是它从一开始就没有搞错多 Agent 的目的。
- 一是效率,可以并行的任务真正并行跑,时间压缩;
- 二是完成度,超出单个上下文窗口的复杂长任务,拆开各跑一块,才有机会真正做完;
- 三是专业度,每个 Expert 只专注一件事,上下文干净、注意力集中,这件事本身做出来的质量就更高。
执行层,就是围绕这三点建起来的。
你做判断,OmniWork来执行
很多人搭多Agent,架构图画得很好看,但执行层三件事一件都没做干净:工具是假的(prompt包装)、过程看不见(黑盒吐结果)、跑一次就断(没有持续运行)。
OmniWork在这三个Case里,每一件都做到了:
- 真工具调用(抓真实数据、写真实文件、生成可运行代码)
- 过程可见(任务清单实时更新,每一步都清晰)
- 持续运行(Autowork定时触发,退出来还在跑)
它就像一个你在知乎上遇到的全能型大神------你问编程,它写代码;你问运营,它出方案;你问设计,它给插画;你问音乐,它作曲。而且不只会回答,还会把成品交到你手上。
一个人 + OmniWork = 一个「全干」内容团队。你负责判断和方向,执行层全部交出去。这不是未来,这是现在就能体验的事。