
仅用低成本双目相机+隐式几何融合,就能让机器人获得媲美3D感知的能力。
------为模仿学习打造更好视觉模块
目录
[01 StereoPolicy核心逻辑:双目特征融合,隐式3D感知](#01 StereoPolicy核心逻辑:双目特征融合,隐式3D感知)
[02 实验验证](#02 实验验证)
[03 价值与局限:落地可行,仍有挑战](#03 价值与局限:落地可行,仍有挑战)
[1. 核心价值:低成本、强泛化、易落地](#1. 核心价值:低成本、强泛化、易落地)
[2. 现存局限:极端场景仍不足](#2. 现存局限:极端场景仍不足)
[04 双目隐式几何,操控新范式](#04 双目隐式几何,操控新范式)
在机器人操控领域,单目视觉长期是主流方案。但单目视觉天生缺失精准深度信息,面对杂乱场景、透明/反光物体(如玻璃杯、金属杯)或精细操作(如插 Toast、挂杯子)时,空间感知模糊,操作成功率大幅下滑。
与此同时,RGB-D、点云等3D方案虽能提供深度,却受传感器噪声、标定复杂、数据稀缺、推理延迟高等问题制约,难以规模化落地。

斯坦福大学李飞飞团队推出的StereoPolicy,提出用同步双目图像直接增强机器人视觉运动策略。
该方法无需复杂相机标定、不用重建深度图或点云,仅通过双目特征融合,就能让机器人获得精准空间感知,在仿真与真实场景中全面超越单目、RGB-D、点云等基线,为机器人3D感知提供了低成本、高适配的新范式。
01 StereoPolicy核心逻辑:双目特征融合,隐式3D感知
StereoPolicy的核心设计思路是:
不用显式重建3D,直接用同步双目图像对,通过预训练2D编码器+立体Transformer,隐式捕捉空间对应与视差线索。
整体框架简洁高效,可无缝适配扩散策略与预训练VLA模型,无需修改骨干网络,兼顾兼容性与扩展性。
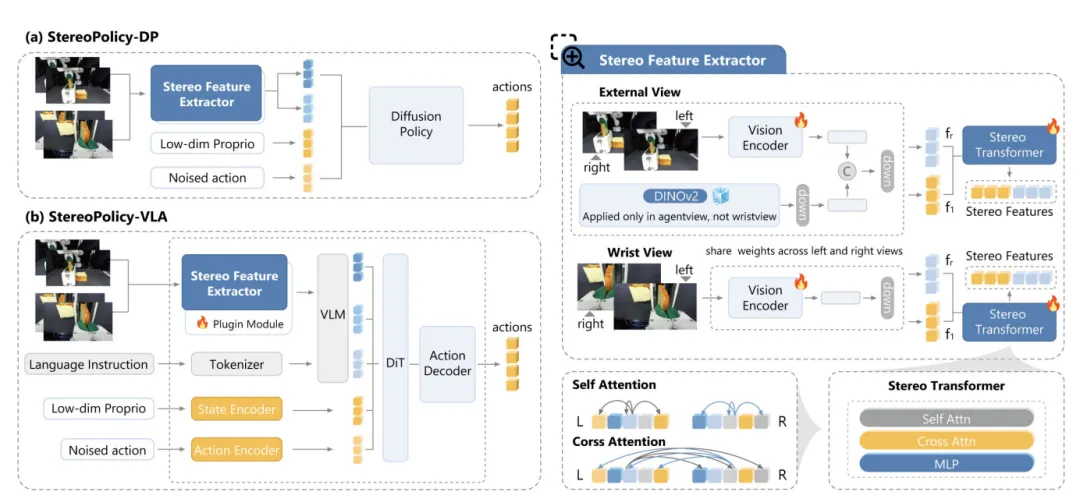
▲StereoPolicy 框架:双目特征提取 + 立体 Transformer 融合
双目特征提取:复用2D预训练优势
StereoPolicy采用"分编后融"策略,先独立处理左右目图像,再融合特征。
具体来说,对同步双目图像(左目 、右目
),分别用共享权重的预训练 2D 视觉编码器(如 ResNet18、DINOv2)提取单目特征图。
共享权重可保证左右目特征空间一致,避免几何错位,同时复用2D预训练模型的强大语义与特征提取能力,弥补3D模型泛化不足的短板。
为增强几何推理,外部视角图像会额外拼接冻结的DINOv2特征(腕部视角因域差异不添加),补充单目先验,提升弱纹理区域的特征可靠性。
立体Transformer:隐式捕捉空间关联
提取左右目特征后,核心模块立体Transformer通过交替自注意力与交叉注意力,融合双目特征。
自注意力捕捉单目图像内像素级关联,交叉注意力聚焦左右目间空间对应关系,同时引入2D旋转位置编码(2D RoPE),强化跨视角位置推理,让模型隐式学习视差与空间几何,无需显式计算深度。
这一设计的关键价值:避开显式3D重建的计算开销与噪声干扰,同时保留2D预训练特征的泛化能力,让模型既懂语义,又懂空间。
策略适配:无缝对接扩散与VLA模型
StereoPolicy可灵活集成两类主流机器人策略:
- StereoPolicy-DP:面向从 scratch 训练的扩散策略,将融合后的立体特征作为条件输入去噪网络,让动作生成融入隐式空间信息,提升精细操作精度;
- StereoPolicy-VLA:面向预训练视觉-语言-动作(VLA)模型,将单目嵌入替换为立体特征,轻量微调即可适配双目输入,无需重训骨干,高效增强VLA模型空间感知。
02 实验验证
StereoPolicy在RoboMimic、RoboCasa、OmniGibson三大仿真基准,以及桌面单臂、双手机器人真实场景中全面测试,对比RGB、RGB-D、点云、多视角四大基线,结果显示其在成功率、泛化性、鲁棒性上均显著领先。
真实场景:透明/反光物体也能稳操作
真实桌面任务(香蕉抓取、吐司插入、塑料杯/金属杯/玻璃杯悬挂)中,StereoPolicy-DP平均成功率达59%,远超RGB(42%)、RGB-D(41%)、点云(14%)、多视角(44%)基线。
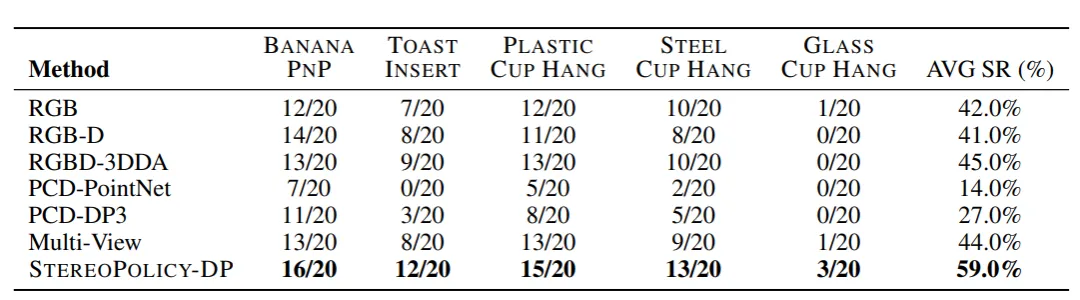
▲真实桌面任务:双目策略全面优于单目、RGB-D、点云基线
双手机器人移动任务(吐司抓取、开收音机)中,StereoPolicy-VLA同样优于单目VLA,能精准完成 gripper 插入、按钮按压等精细动作,而单目VLA常因深度误判失败。

▲真实桌面与双手机器人任务示例
仿真场景:数据效率更高,复杂任务更强
三大仿真基准中,StereoPolicy在低数据(30-100个演示)与高数据(200-300个演示)设置下均最优。

▲仿真任务:双目策略在低 / 高数据下均最优
尤其在遮挡、精细对齐任务(如工具悬挂、倒水)中,优势更明显------例如RoboMimic工具悬挂任务,StereoPolicy成功率达94%,远超RGB(53%)。同时,它比多视角方案更优,验证立体Transformer特征融合的有效性。
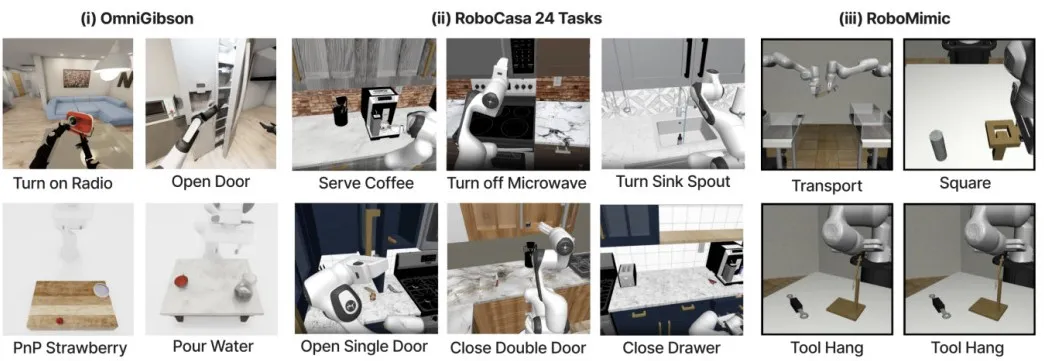
▲三大仿真基准任务示例
关键参数:双目基线=物体距离10%最优
研究发现,双目性能核心取决于基线-距离比(双目间距/相机到物体距离),最优区间为9%-13%。
如桌面场景(相机距0.6-0.8m),6cm基线效果最佳:基线过小(2cm)视差弱、深度不准;
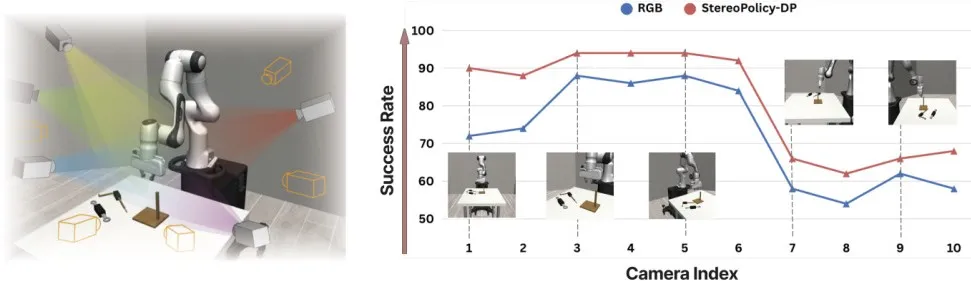
▲双目策略在不同相机角度下更稳健
基线过大(10cm)视角重叠少、几何不一致。此外,正面视角提升最显著(+18%),侧面视角增益较小,为硬件部署提供明确指导。
模型设计:大骨干+立体融合最优
消融实验显示:预训练大骨干(如SIGLIP-SO400M)+立体Transformer性能最优。DINOv2特征仅提升外部视角,腕部视角因域差异无效;
移除立体Transformer,成功率从94%跌至85,直接证明融合模块的核心作用。
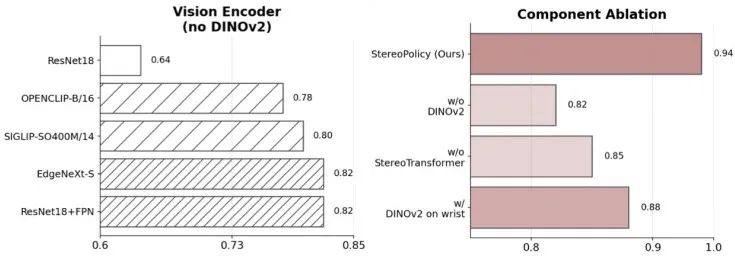
▲骨干选择与双目融合模块的消融结果
03 价值与局限:落地可行,仍有挑战
1. 核心价值:低成本、强泛化、易落地
StereoPolicy的核心突破是重新定义机器人立体感知路径:
不用昂贵3D传感器、不用复杂标定、不用海量3D数据,仅用低成本双目相机+隐式几何融合,就能让机器人获得媲美3D感知的能力。

对行业而言,这意味着机器人操控可摆脱"高精度硬件依赖",快速规模化部署;对科研而言,打通2D预训练模型与3D几何理解的鸿沟,为VLA、世界模型等大模型增强空间感知提供通用方案。
2. 现存局限:极端场景仍不足
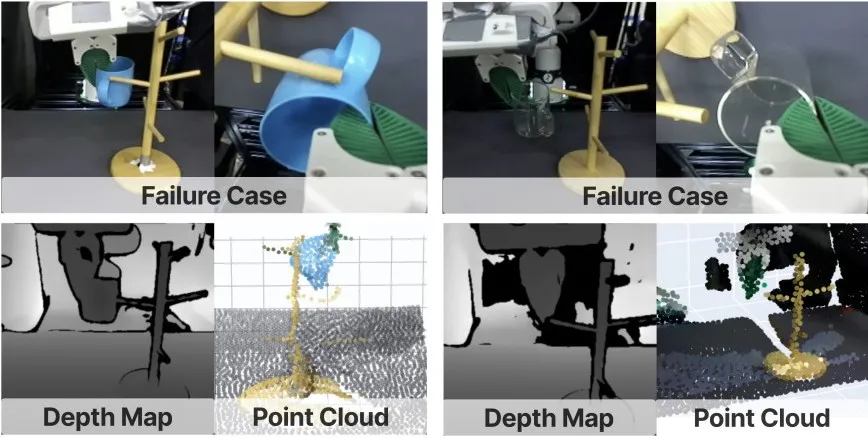
▲真实场景:深度 / 点云对透明物体失效
StereoPolicy仍有短板:
其一,极端光照敏感,强光、弱光下双目匹配易出错;
其二,透明/反光物体仍难,虽优于基线,但绝对成功率仍低;
其三,动态场景适配弱,当前侧重静态环境,动态物体交互需进一步优化;
其四,推理延迟略增,比单目高约12%,但远低于3D重建方案。
04 双目隐式几何,操控新范式
从单目到显式3D,再到StereoPolicy的隐式双目几何,机器人视觉操控正走向"低成本、强泛化、高精度"的平衡态。
StereoPolicy的核心不是否定2D或3D,而是取两者之长:
复用2D预训练的语义与泛化,用双目隐式几何补全空间感知,避开显式3D的痛点。
Ref
论文标题:StereoPolicy: Improving Robotic Manipulation Policies via Stereo Perception