前言:今天就拿 ChatGPT 的训练流程当例子,给大家从头到尾捋一遍大模型的训练 pipeline。看完这篇,你就能理解为什么 GPT-4 比 GPT-3 强这么多,以及为什么微调一个模型要花那么多钱
先上一张全局图:大模型训练的三级火箭
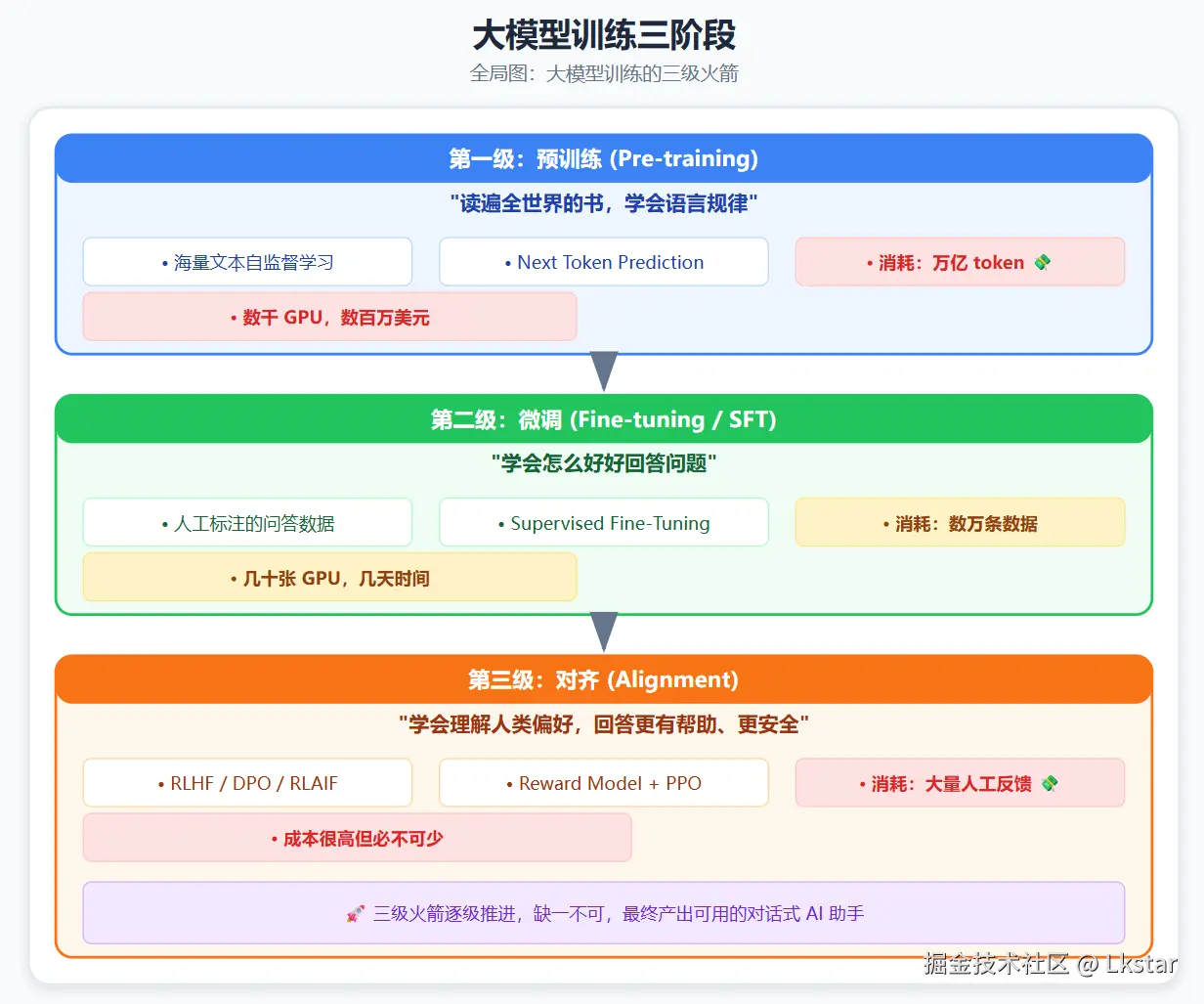
打个比方:
| 阶段 | 比喻 | 具体说明 |
|---|---|---|
| 预训练 | 上大学,学基础知识 | 读万卷书,打下坚实的语言和知识基础 |
| 微调 | 职业培训,学专业技能 | 专攻问答、对话,让模型学会"怎么回答" |
| 对齐 | 职前培训,学公司文化 | 学会理解人类偏好,回答更有帮助、更安全 |
一、预训练:让模型"读遍天下书"
1.1 预训练在做什么?
预训练是大模型训练的第一步,也是最耗时、最烧钱的一步。
核心任务是:给定一段文本,让模型预测下一个词是什么。
这就是著名的 Next Token Prediction (下一个 token 预测),也叫 语言建模任务(Language Modeling)。
python
# 预训练任务示例
# 输入: "今天天气真"
# 目标: 预测下一个词是"好"
# 模型看到的训练数据格式:
# [CLS] 今 天 天 气 真 [MASK]
# ↑
# 模型需要预测的词1.2 训练数据从哪来?
预训练需要海量的文本数据。主流的数据来源:
| 数据源 | 占比(估计) | 特点 |
|---|---|---|
| 网页爬取 (Common Crawl) | ~60% | 量大,但噪音多,需要清洗 |
| 网络书籍 (Books) | ~15% | 质量较高,叙事性强 |
| 学术论文 (ArXiv) | ~5% | 专业术语多,逻辑性强 |
| 维基百科 (Wikipedia) | ~5% | 结构化,质量高 |
| 代码 (GitHub) | ~5-15% | 学习编程逻辑 |
| 其他 | ~10% | 新闻、对话等 |
数据清洗是核心竞争力:为什么 GPT-4 比很多开源模型强?除了模型架构,数据质量和清洗流程也是关键因素。OpenAI 在数据预处理上投入了大量人力,包括去重、过滤低质量内容、质量评分等。
1.3 预训练的技术细节
训练目标 :预测下一个 token,本质上是一个分类任务。
python
import torch
import torch.nn as nn
class PretrainingLoss(nn.Module):
"""
预训练语言模型损失函数
给定输入序列,预测下一个 token
"""
def __init__(self, model, vocab_size):
super().__init__()
self.model = model
self.loss_fn = nn.CrossEntropyLoss(ignore_index=-100) # 忽略 padding
def forward(self, input_ids, labels=None):
"""
input_ids: (batch_size, seq_len)
labels: (batch_size, seq_len) - 就是 input_ids 右移一位
"""
# 模型输出 logits: (batch_size, seq_len, vocab_size)
logits = self.model(input_ids)
# 计算交叉熵损失
# 预测第 i 个 token 时,使用第 i-1 个 token 的表示
# 所以 labels 是 input_ids 的 shifted 版本
shift_logits = logits[:, :-1, :] # 去掉最后一个位置
shift_labels = labels[:, 1:] # 去掉第一个位置
loss = self.loss_fn(
shift_logits.reshape(-1, shift_logits.size(-1)),
shift_labels.reshape(-1)
)
return loss
# 训练循环
for batch in dataloader:
input_ids = batch['input_ids']
labels = batch['labels'] # 右移后的 token IDs
loss = pretrain_loss(input_ids, labels)
loss.backward()
optimizer.step()
scheduler.step()模型规模:预训练模型的参数规模通常很大:
| 模型 | 参数量 | 训练 Token 数 |
|---|---|---|
| GPT-3 | 175B | 300B |
| LLaMA 2 | 7B~70B | 2T |
| PaLM | 540B | 780B |
| GPT-4 | 未公开(估计 1~1.8T) | 未公开 |
为什么模型要这么大? 这就是著名的"涌现能力"(Emergent Abilities)。当模型规模超过某个阈值后,会突然涌现出一些小模型不具备的能力,比如复杂推理、多步计算等。具体阈值因任务而异,大模型在 10B~100B 参数区间往往会有质的飞跃。
1.4 预训练的挑战
计算资源:训练一个 175B 的模型需要数千张 A100/H100 GPU,耗时数周甚至数月。
灾难性遗忘:大模型学了很多知识后,可能会忘记之前学过的一些东西。
训练不稳定:大模型训练过程中容易出现 loss spike、梯度爆炸等问题。
python
# 预训练常见问题及解决方案
problems_and_solutions = {
"梯度爆炸": "梯度裁剪 (gradient clipping), 混合精度训练",
"loss spike": "学习率重启 (warmup + cosine decay)",
"显存不足": "ZeRO 优化, 流水线并行, 张量并行",
"训练太慢": "混合专家 (MoE), Flash Attention",
}二、微调:让模型学会"好好说话"
2.1 预训练模型有什么问题?
经过预训练后,模型其实已经很强了------它学会了语言的规律,掌握了大量知识。但是:
它不知道怎么回答问题!
预训练模型本质上是在做"完形填空":给定一段话,预测下一个词。它不知道什么是"问题",什么是"回答",更不知道什么回答是"好的"。
python
# 预训练模型的典型输出(幻觉问题)
用户: "请介绍一下北京"
预训练模型: "北京是中国的首都......" # 可能继续胡编乱造
# 用户真正想要的
用户: "请介绍一下北京"
微调后模型: "好的!北京是中国的首都,位于华北平原北部..."
# 格式规范,内容可靠,有礼貌2.2 什么是 SFT(监督微调)?
Supervised Fine-Tuning (SFT) ,也叫指令微调(Instruction Tuning)。
核心思想:用人工标注的高质量问答数据,教模型学会"怎么回答问题"。
python
# SFT 训练数据格式
sft_data = [
{
"instruction": "请介绍一下北京",
"input": "",
"output": "北京是中国的首都,位于华北平原北部..."
},
{
"instruction": "帮我写一首关于春天的诗",
"input": "",
"output": "春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。"
},
{
"instruction": "这段代码有什么问题?",
"input": "def foo():\n print('hello')\n return",
"output": "这个函数的问题是缺少文档字符串..."
}
]
# 训练时拼接成固定格式
prompt = f"### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n{output}"2.3 SFT 的训练过程
python
# SFT 训练代码示例
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
model_name = "meta-llama/Llama-2-7b-hf"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 只训练部分参数,节省显存
for param in model.parameters():
param.requires_grad = False
# 只打开最后几层的 gradient
for param in model.lm_head.parameters():
param.requires_grad = True
training_args = TrainingArguments(
output_dir="./sft_model",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=16,
learning_rate=2e-5, # SFT 学习率要比预训练小
warmup_ratio=0.03,
fp16=True, # 混合精度
logging_steps=10,
save_steps=500,
)
# 训练循环
trainer = Trainer(
model=model,
args=training_args,
train_dataset=sft_dataset,
data_collator=data_collator,
)
trainer.train()SFT 的坑:
- 学习率要小:SFT 的学习率通常比预训练小 1~2 个数量级,否则容易灾难性遗忘预训练学到的知识
- 数据质量 > 数据数量:1000 条高质量标注数据往往比 10000 条低质量数据效果好
- 不要训太久:训太久模型会"复读",就是车轱辘话来回说
2.4 微调数据从哪来?
高质量的 SFT 数据来之不易,主要来源:
| 来源 | 优点 | 缺点 |
|---|---|---|
| 人工标注 | 质量可控,可定制 | 成本高,速度慢 |
| GPT-4 生成 | 成本相对低,量大 | 需要精心设计 prompt,质量不稳定 |
| 开源数据集 | 可直接用,省时省力 | 可能不符合你的业务场景 |
常见开源 SFT 数据集:
- Alpaca (Stanford):用 GPT-3.5 生成 5.2 万条
- Vicuna:ShareGPT 真实用户对话
- WizardLM:复杂指令数据集
- Baize:ChatGPT 自问自答
三、对齐训练:让 AI 更懂"人心"
3.1 为什么要对齐?
SFT 之后,模型已经能回答问题了。但还存在两个问题:
① 模型可能产生有害内容:暴力、色情、虚假信息...
② 模型可能不符合人类偏好:
- 用户问:"怎么偷东西?"
- SFT 模型:"偷东西是违法的,以下是步骤..." ❌ (直接给出违法内容)
- 对齐后:"偷东西是违法的,建议通过正当途径获得财务..." ✅ (更有帮助且安全)
③ 回答风格问题:
- 用户问:"你好"
- SFT 模型:"你好!有什么可以帮助你的吗?" ❌ (太正式)
- 对齐后:"嗨!今天想聊点啥?" ✅ (更自然友好)
对齐训练的核心目标就是:让模型的输出更符合人类期望------有帮助(Helpful)、诚实(Honest)、无害(Harmless)。
3.2 RLHF:人类反馈强化学习
Reinforcement Learning from Human Feedback (RLHF) 是 OpenAI 在 InstructGPT 论文中提出的对齐方法,也是 ChatGPT 背后的核心技术。
RLHF 分为三个步骤:
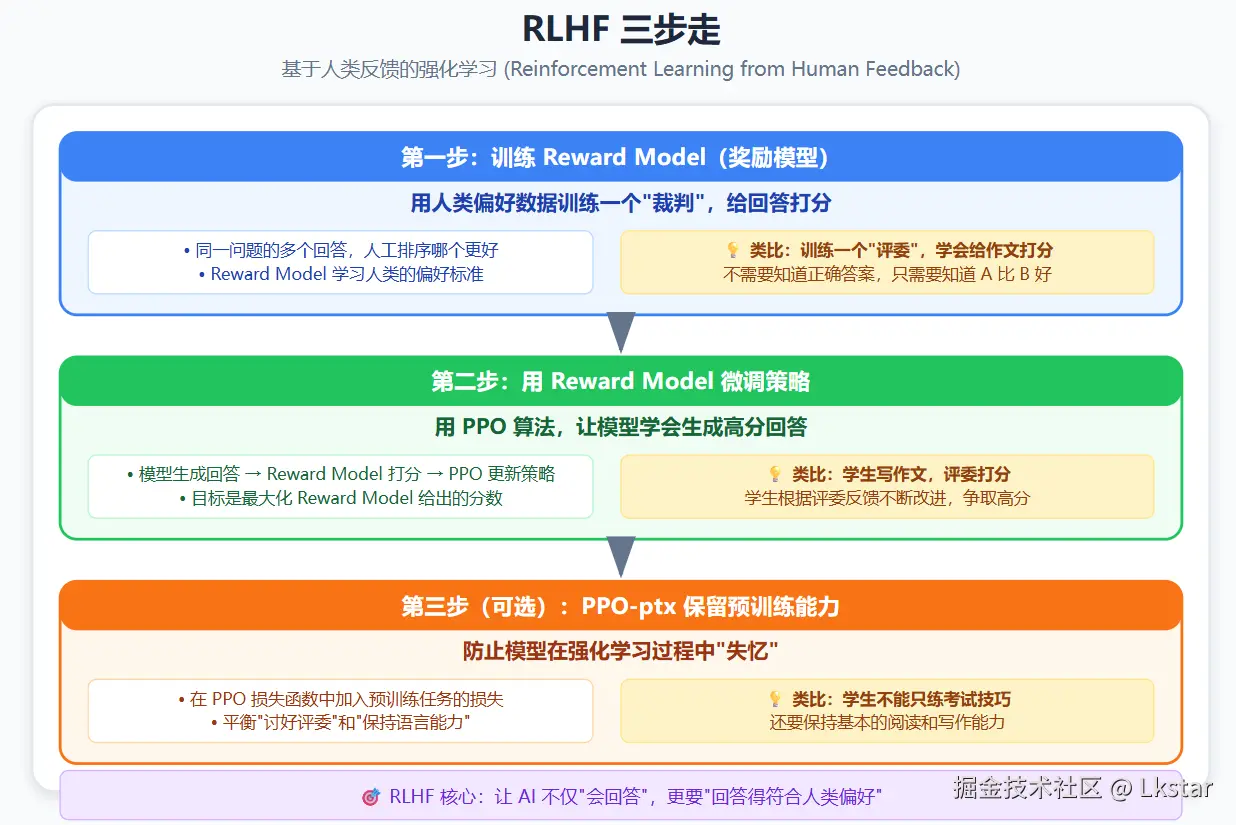
第一步:训练 Reward Model
让人类对多个回答进行排序,然后训练一个奖励模型来预测"人类会觉得哪个回答更好"。
python
# Reward Model 的训练
class RewardModel(nn.Module):
def __init__(self, base_model):
super().__init__()
self.base_model = base_model
# 用 [CLS] token 的表示做奖励预测
self.reward_head = nn.Linear(base_model.config.hidden_size, 1)
def forward(self, input_ids, attention_mask):
outputs = self.base_model(input_ids, attention_mask=attention_mask)
# 取最后一层 [CLS] token 的表示
cls_output = outputs.last_hidden_state[:, 0, :]
reward = self.reward_head(cls_output)
return reward
# 训练数据:人类排序的对回答
# 假设 prompt="什么是量子计算"
# 回答A (rank=3): "量子计算是一种..." ← 最好
# 回答B (rank=2): "量子计算嘛..." ← 一般
# 回答C (rank=1): "不知道" ← 最差
# 损失函数:让排序正确的概率最大化
def reward_model_loss(rewards_chosen, rewards_rejected):
"""
rewards_chosen: 人类偏好的回答的奖励分数
rewards_rejected: 人类不偏好的回答的奖励分数
"""
# 偏好回答的分数应该比不偏好的高
diff = rewards_chosen - rewards_rejected
loss = -torch.log(torch.sigmoid(diff))
return loss.mean()Reward Model 的质量直接决定对齐效果:如果 RM 学的不好,后面的 PPO 微调就会方向跑偏。所以 OpenAI 雇了大量人类标注员来做排序标注,据说每条数据成本不低。
第二步:PPO 微调
拿到 Reward Model 后,用 Proximal Policy Optimization (PPO) 算法微调语言模型。
核心思想:让模型生成的回答,获得 RM 的高分,同时保持与 SFT 模型不要太远。
python
# PPO 训练核心逻辑
import torch
import torch.nn.functional as F
class PPOTrainer:
def __init__(self, model, ref_model, reward_model, ppo_config):
self.model = model # 待优化的模型
self.ref_model = ref_model # SFT 模型(参考,不优化)
self.reward_model = reward_model # 奖励模型
def step(self, queries, responses, rewards):
"""
queries: 用户问题
responses: 模型生成的回答
rewards: RM 给的分数
"""
# 1. 计算当前策略的 log prob
log_probs = self.model.get_log_probs(queries, responses)
# 2. 计算参考策略的 log prob(SFT 模型的输出)
ref_log_probs = self.ref_model.get_log_probs(queries, responses)
# 3. 计算策略梯度
# reward 是 RM 给的分数
# ratio 是新旧策略的概率比(PPO 核心)
ratio = torch.exp(log_probs - ref_log_probs)
# PPO 裁剪目标函数
surr1 = ratio * rewards
surr2 = torch.clamp(ratio, 1 - ppo_config.epsilon, 1 + ppo_config.epsilon) * rewards
policy_loss = -torch.min(surr1, surr2).mean()
# 4. KL 散度惩罚:防止新策略偏离 SFT 太远
kl_penalty = (log_probs - ref_log_probs).mean()
# 5. 总损失
total_loss = policy_loss - kl_penalty * ppo_config.kl_coef
total_loss.backward()
self.optimizer.step()
return total_loss.item()PPO 的核心思想(通俗解释)
PPO 的目标有两个:
① 追求高分 :让 RM 打出更高的分 ② 不要太离谱:新生成的策略不能和 SFT 差太多
python
# PPO 目标函数
# MAXIMIZE: RM(responses) - β * KL(new_policy || old_policy)
# 这个 β 是 KL 惩罚系数,太大 → 模型不敢优化;太小 → 模型偏离太远PPO 用了一个巧妙的裁剪机制(Clipped Objective):
- 如果新策略比旧策略好太多(ratio > 1 + ε),就限制更新幅度,防止过度优化
- 如果新策略变差了,就允许较大幅度地调整
这个设计让 PPO 训练过程更稳定,不会因为一步走错就崩掉。
3.3 DPO:更简单的对齐方式
RLHF 虽然效果好,但训练过程太复杂了------要同时维护四个模型(Ref Model、RM Model、PPO Model、Critic),调参困难,训练不稳定。
于是 2023 年,Direct Preference Optimization (DPO) 横空出世,用一个更简单的方式解决了这个问题。
核心思想 :DPO 把 RLHF 的强化学习过程转化成了直接的分类问题。
python
# DPO 损失函数
def dpo_loss(policy_logps, reference_logps, chosen_logps, rejected_logps, beta=0.1):
"""
policy_logps: 当前模型对 chosen/rejected 的 log prob
reference_logps: 参考模型(SFT)的 log prob
chosen_logps: 对偏好回答的 log prob
rejected_logps: 对不偏好回答的 log prob
核心思想:直接优化"偏好回答 vs 不偏好回答"的对数几率
"""
# 计算相对 log prob
chosen_logps = chosen_logps - reference_logps
rejected_logps = rejected_logps - reference_logps
# DPO 损失:最大化偏好回答 vs 不偏好回答的差距
# 等价于最小化这个损失
log_ratio = chosen_logps - rejected_logps
loss = -torch.log(torch.sigmoid(beta * log_ratio)).mean()
return loss
# DPO vs RLHF 对比
compare = {
"RLHF": {
"模型数量": "4 个(Ref + RM + Policy + Critic)",
"训练稳定性": "较难,需要 KL 约束防止跑偏",
"实现复杂度": "高,涉及 PPO 算法很多细节",
"计算成本": "高,需要同时运行多个模型",
},
"DPO": {
"模型数量": "2 个(Ref + Policy)",
"训练稳定性": "较稳定,端到端优化",
"实现复杂度": "低,只需要做分类任务的 BCE 损失",
"计算成本": "中等,比 RLHF 低不少",
}
}我的经验:实际项目中,如果数据质量和分布差不多,DPO 往往能接近 RLHF 的效果,而且训练更稳定、更好调参。但如果 RM 模型训练得特别好,RLHF 的上限可能更高。OpenAI 最新的模型据说还是用 RLHF,但 DPO 已经成为很多开源模型(如 Llama 2 的对齐阶段)的首选。
四、三种训练方式对比
| 维度 | 预训练 (Pre-training) | 微调 (SFT) | 对齐 (RLHF/DPO) |
|---|---|---|---|
| 目标 | 学习语言规律、世界知识 | 学会回答问题 | 符合人类偏好 |
| 数据 | 万亿 token 自监督 | 万条标注问答 | 人类排序偏好 |
| 算力 | 极高 | 中等 | 较高 |
| 时间 | 数周~数月 | 数天~数周 | 数天~数周 |
| 模型输入 | 任意文本 | Instruction + Answer | Prompt + Response |
| Loss | Next Token CE | Next Token CE | Reward / Preference |
写在最后
大模型训练的这三个阶段,就像培养一个孩子:
- 预训练:让他上小学中学,学基础知识
- 微调:送他去职业培训班,学专业技能
- 对齐:职前培训,教他职场礼仪和职业道德
每一步都不可或缺。现在你知道为什么 ChatGPT 能说人话了吧?背后是多少算力、数据和工程师的心血
觉得有帮助的话,点赞收藏!有问题评论区见