新书发行:《编程启蒙:思维与代码》
你好,我是悦创。
我的新书《编程启蒙:思维与代码》已进入发行阶段。本书由北京航空航天大学出版社出版,黄家宝编著,ISBN 为 978-7-5124-4941-1,定价 99.00 元。
这本书的定位不是单纯教语法,而是从"编程思维"切入:上篇先讲解决问题、抽象、算法、AI 与计算机世界的底层思考方式;下篇再进入 Python 基础训练,帮助读者把思维方法落到代码实践里。简单说,它适合想系统理解编程、AI 与代码关系的初学者,也适合家长、老师和自学者作为编程启蒙读物。
购买本书可领取配套福利,具体领取方式和细则以随书说明或客服通知为准。


每次打开一个新的 Claude Code 会话,你面对的都不是"昨天那个已经熟悉项目的同事",而是一个带着强大能力、但上下文从零开始的新执行者。
这就是很多人刚开始用 Claude Code 时最容易遇到的问题:
- 项目用
pnpm,它又写成了npm install。 - 后端用 Fastify,它又生成了 Express 示例。
- 团队要求提交前跑
pnpm lint && pnpm test,它每次都要你提醒。 - 你已经解释过目录结构,换一个会话以后,它又从头猜。
CLAUDE.md 的价值不在于"让 Claude 永远记住一切",而是把那些每次都要重复解释、反复纠正、影响工程决策的共识,提前写成项目说明书。Claude Code 启动时会读取这些记忆文件,把它们放进当前会话上下文里,然后再开始工作。
这篇教程不只讲"文件放在哪里",更重要的是教你判断:什么值得写进 CLAUDE.md,什么应该拆成规则,什么应该交给自动记忆,什么根本不该写进去。
说明:本文以 2026-05-29 的 Claude Code 官方文档为基准。相关功能可能继续变化,团队落地前建议再核对官方文档。
1. 先建立一个正确心智模型
Claude Code 的记忆可以分成两类:
| 类型 | 谁来写 | 主要用途 | 加载特点 |
|---|---|---|---|
CLAUDE.md |
你或团队 | 明确告诉 Claude 应该遵守的指令、规范、工作流 | 每次会话读取 |
| 自动记忆 | Claude | 从你的更正、项目实践、调试过程里沉淀经验 | 每次会话读取索引,细节按需读取 |
一句话区分:
CLAUDE.md是"你告诉 Claude 的规则"。- 自动记忆是"Claude 在工作中给自己写的笔记"。
但有一个很关键的边界:CLAUDE.md 是上下文指导,不是强制安全策略。如果你必须禁止某个命令、某个工具或某类路径访问,应该使用 settings、permissions、hooks 这类由客户端执行的机制,而不是只在 CLAUDE.md 里写"禁止这样做"。
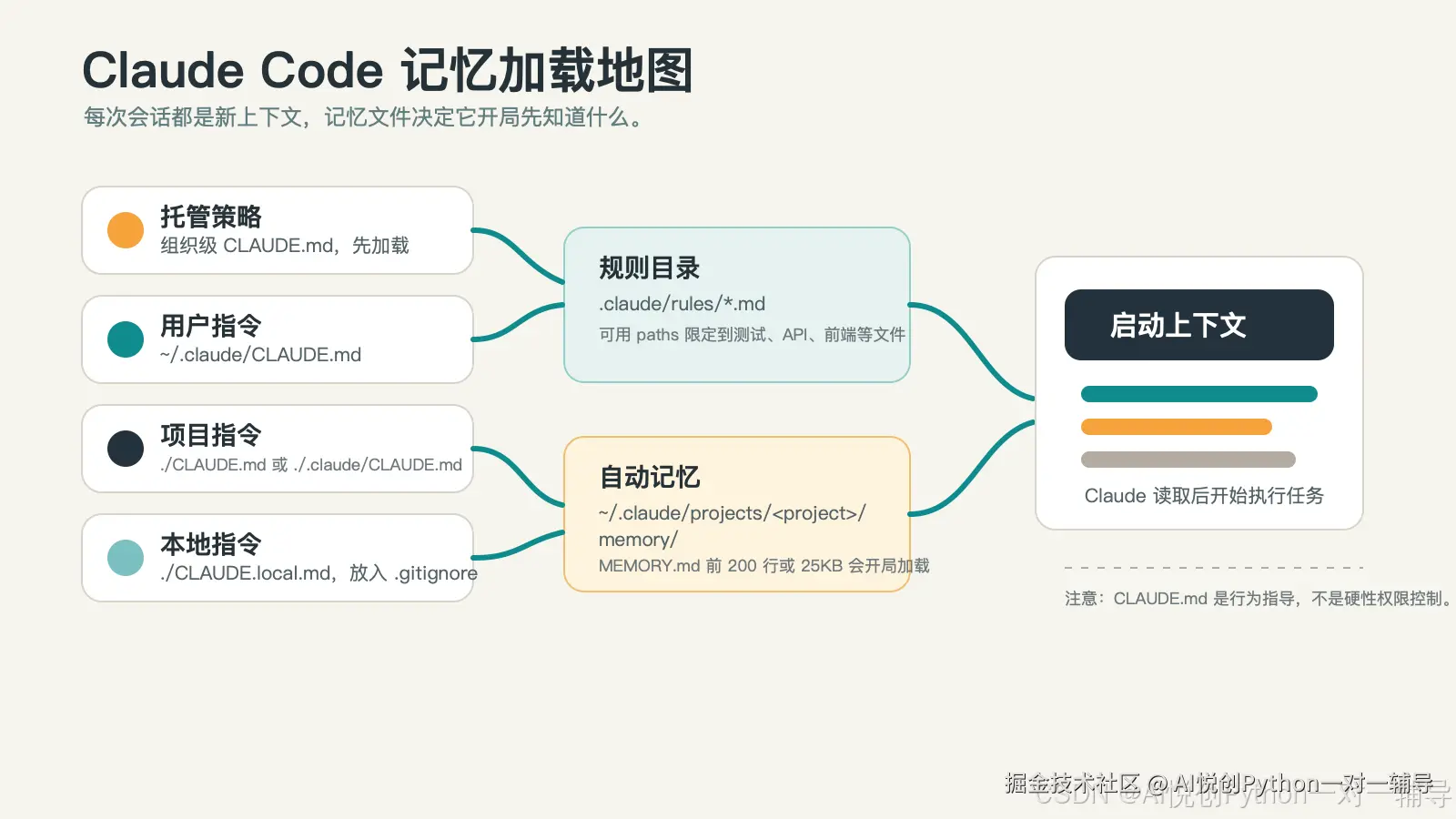
2. 四类 CLAUDE.md:先分清作用范围
Claude Code 支持不同范围的记忆文件。你不需要一上来全都配置,但要知道它们分别解决什么问题。
| 范围 | 位置 | 适合写什么 | 是否共享 |
|---|---|---|---|
| 组织级 | macOS: /Library/Application Support/ClaudeCode/CLAUDE.md;Linux/WSL: /etc/claude-code/CLAUDE.md;Windows: C:\Program Files\ClaudeCode\CLAUDE.md |
公司编码标准、安全合规提醒、组织级开发习惯 | 组织内所有人 |
| 用户级 | ~/.claude/CLAUDE.md |
你跨项目都适用的个人偏好 | 只属于你 |
| 项目级 | ./CLAUDE.md 或 ./.claude/CLAUDE.md |
技术栈、目录结构、测试命令、团队共享规范 | 提交到 Git |
| 本地级 | ./CLAUDE.local.md |
当前机器、当前 worktree 的本地笔记 | 不提交 |
如果你是个人开发者,最常用的是两个文件:
bash
touch CLAUDE.md
touch CLAUDE.local.md
echo "CLAUDE.local.md" >> .gitignoreCLAUDE.md 放团队也应该知道的内容,CLAUDE.local.md 放你自己的工作区信息。例如本地服务地址、临时调试方式、当前任务备注。
注意:不要把真实密钥、生产账号、数据库密码写进 CLAUDE.local.md。它虽然不提交,但仍然是明文文件。敏感信息应该放在环境变量、密钥管理器或专门的配置系统里。
3. 用三分钟搭一个可用的项目记忆
你可以在项目根目录运行:
bash
/init/init 会让 Claude Code 分析当前项目,并生成一个起步版 CLAUDE.md。如果你想手写,也可以从下面这个模板开始。
markdown
# 项目:订单管理 API
## 项目事实
- 运行时:Node.js 20
- 语言:TypeScript strict mode
- Web 框架:Fastify
- ORM:Prisma
- 数据库:PostgreSQL
- 包管理器:pnpm
## 常用命令
- 安装依赖:pnpm install
- 启动开发服务:pnpm dev
- 运行测试:pnpm test
- 代码检查:pnpm lint
- 生成 Prisma Client:pnpm prisma generate
## 目录边界
- 路由定义放在 src/routes/
- 请求处理放在 src/controllers/
- 业务逻辑放在 src/services/
- 数据库访问放在 src/repositories/
- 输入输出 schema 放在 src/schemas/
## 必须遵守
- 新增 API 时必须同时添加 Zod schema
- controller 不直接写 SQL
- service 不直接读取 HTTP request
- 提交前运行 pnpm lint && pnpm test
## 参考入口
- API 设计细节见 @docs/api-style.md
- 数据库设计见 @prisma/schema.prisma这个模板的重点不是完整,而是让 Claude 在刚进入项目时知道五件事:
- 项目是什么。
- 用什么技术栈。
- 常用命令是什么。
- 代码应该放在哪里。
- 哪些规则不能靠自由发挥。
4. 判断一条信息应该放在哪里
CLAUDE.md 最大的问题不是"不够详细",而是很容易被写成项目百科。它不是知识库,而是启动上下文。每多一行都会进入会话上下文,长期消耗 token,也会增加冲突概率。
你可以用下面这张图来做判断。
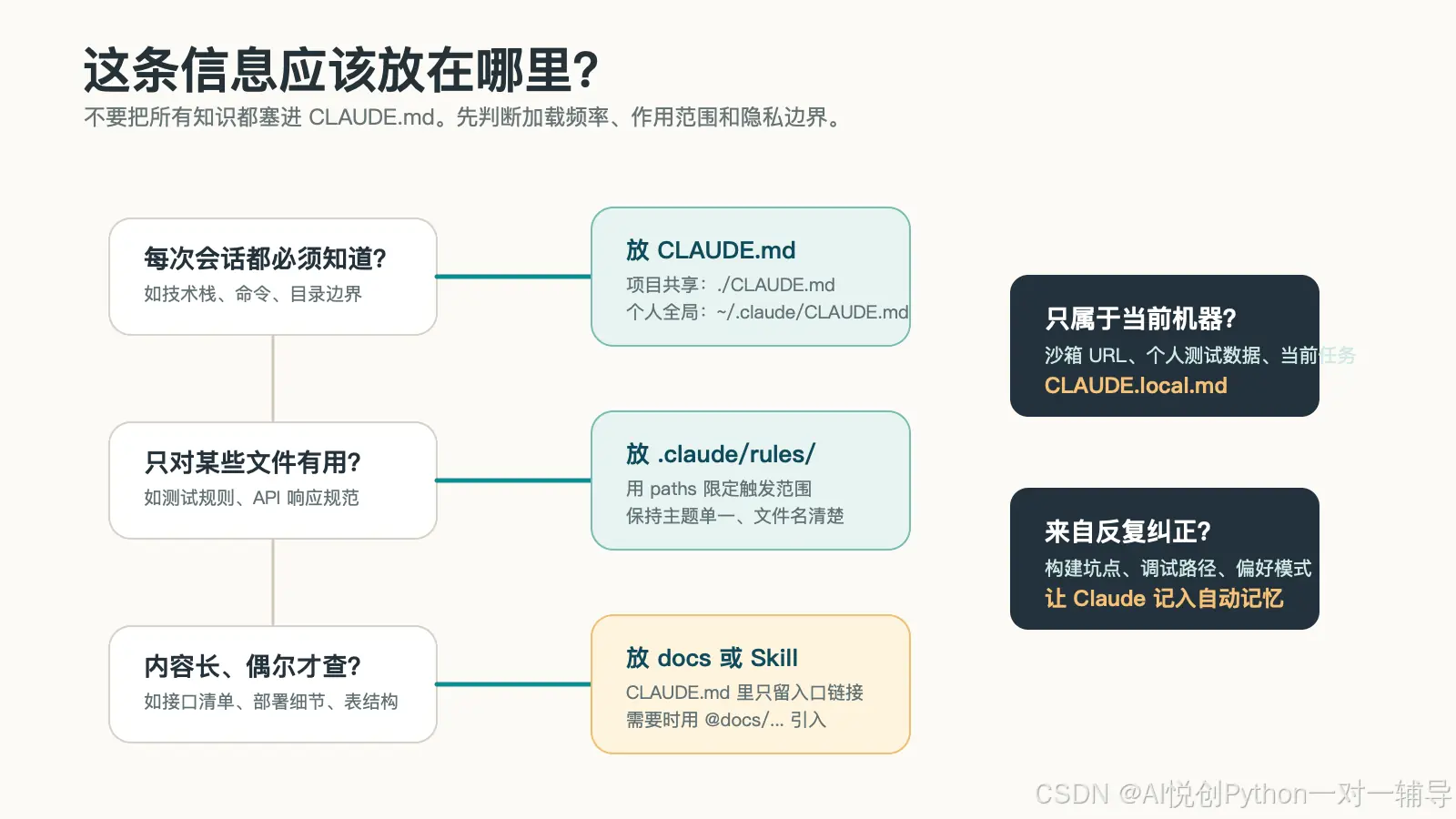
几个常见判断:
| 内容 | 推荐位置 | 原因 |
|---|---|---|
| "本项目使用 pnpm,不使用 npm" | CLAUDE.md |
每次执行命令都可能用到 |
| "我的本地 API 地址是 http://localhost:8080" | CLAUDE.local.md |
只属于当前机器 |
| "所有 React 组件测试使用 Testing Library" | .claude/rules/testing.md |
只在测试相关文件中需要 |
| "完整 API 清单有 200 行" | docs/api.md,在 CLAUDE.md 里引用入口 |
太长,不适合每次加载 |
| "Claude 最近发现某个测试必须先启动 Redis" | 自动记忆或 CLAUDE.local.md |
更像工作经验或本地运行条件 |
一个实用原则:
如果 Claude 不知道这条信息,大概率会在很多任务里做错,那就写进
CLAUDE.md。如果只在少数场景需要,就拆出去。
5. 写好 CLAUDE.md 的关键:具体、可检查、有边界
低质量的 CLAUDE.md 通常长这样:
markdown
请写高质量代码。
保持代码整洁。
遵循最佳实践。
注意安全。这些话看起来正确,但几乎不会改变 Claude 的行为,因为它们没有边界、没有可检查结果,也没有项目特异性。
更好的写法是:
markdown
## API 错误处理
- 业务错误统一抛出 `BusinessError(code, message)`
- controller 中不要写 try-catch
- 错误响应由 `src/plugins/error-handler.ts` 统一处理
- 示例参考:`src/routes/orders.ts`这类规则有效,是因为它回答了三个问题:
- 在什么场景使用?
- 具体要做什么,不要做什么?
- 应该模仿哪个文件,如何检查结果?

你可以把每条重要规则写成这个格式:
markdown
## 新增 API 端点
适用场景:新增或修改 HTTP API 时。
规则:
- 在 `src/schemas/` 创建 Zod schema
- 在 `src/routes/` 注册路由
- 在 `src/controllers/` 处理请求和响应
- 在 `src/services/` 写业务逻辑
- 不要在 controller 中直接访问 Prisma
示例:
- 参考 `src/routes/orders.ts`
- 参考 `src/services/order-service.ts`
完成前检查:
- pnpm lint
- pnpm test这比"新增 API 要规范"有效得多。
6. 用 rules 拆分按场景触发的规则
当 CLAUDE.md 开始变长,第一反应不应该是继续补,而应该是拆。
Claude Code 支持 .claude/rules/ 目录,你可以把不同主题的规则拆成独立文件:
text
.claude/
└── rules/
├── api-design.md
├── testing.md
├── frontend.md
└── security.md没有 paths frontmatter 的规则会无条件加载。带 paths 的规则只在 Claude 处理匹配文件时适用。例如:
markdown
---
paths:
- "src/**/*.test.ts"
- "src/**/*.test.tsx"
- "tests/**/*.ts"
---
# 测试规则
- 使用 Arrange-Act-Assert 组织测试
- 优先测试用户可观察行为,不测试内部实现细节
- 新增 service 必须覆盖成功路径和主要失败路径这类规则适合测试、前端、API、安全等"不是每个任务都需要,但一旦触发就很重要"的规范。
7. 用 @ 引用,而不是复制整份文档
CLAUDE.md 支持用 @path 引入其他文件,例如:
markdown
## 参考入口
- 项目说明:@README.md
- API 风格:@docs/api-style.md
- 数据库 schema:@prisma/schema.prisma注意两点:
- 被
@引用的文件会在启动时展开并加载,所以不要滥用。 @适合引用短而关键的入口,不适合把几万字文档全部塞进上下文。
如果只是告诉 Claude "需要时去看这个文件",可以写成普通说明:
markdown
详细部署流程在 `docs/deployment.md`,只有处理部署任务时再读取。这样可以避免每次会话都加载部署细节。
如果仓库里已经有 AGENTS.md,Claude Code 不会直接把它当作自己的记忆文件读取。你可以创建一个 CLAUDE.md 来导入它:
markdown
@AGENTS.md
## Claude Code 补充规则
- 修改 `src/billing/` 前先说明计划。
- 涉及数据库迁移时必须先查看 `prisma/schema.prisma`。8. 本地记忆:记录工作现场,但别提交
CLAUDE.local.md 适合写当前机器相关的信息:
markdown
# 本地工作区
## 服务地址
- API: http://localhost:3000
- Web: http://localhost:5173
- Redis: localhost:6379
## 当前任务
- 正在重构支付回调
- 相关分支:feature/payment-webhook
- 重点关注:幂等处理和失败重试
## 调试命令
- 查看支付日志:LOG_LEVEL=debug pnpm dev
- 跑支付测试:pnpm test payment它不适合写团队规则,因为别人拿不到;也不适合写真实密码,因为它仍然是明文。
你应该确认它已经进入 .gitignore:
bash
rg "CLAUDE.local.md" .gitignore如果没有:
bash
echo "CLAUDE.local.md" >> .gitignore9. 自动记忆:让 Claude 记录经验,但不要完全依赖它
自动记忆会让 Claude 根据工作过程写下未来可能有用的笔记,例如:
- 项目的构建命令。
- 某类测试失败的排查经验。
- 代码库里已经形成的命名习惯。
- 你多次纠正过的偏好。
官方文档说明,自动记忆默认开启,可通过 /memory 或配置项切换。它的项目记忆目录通常位于:
text
~/.claude/projects/<project>/memory/其中 MEMORY.md 是入口索引。每次会话开始时,Claude 会读取 MEMORY.md 的前 200 行或前 25KB,以先到者为准。更细的主题文件会按需读取。
你可以这样使用它:
text
请记住:这个项目运行集成测试前必须先启动本地 Redis。如果你希望这条规则变成团队共享规范,就不要只让自动记忆保存,而要明确说:
text
请把"集成测试前必须启动本地 Redis"加入项目 CLAUDE.md。自动记忆适合沉淀经验,CLAUDE.md 适合声明规则。两者配合使用,而不是互相替代。
10. 用 /memory 做验收
配置完以后,不要凭感觉判断是否生效。直接在 Claude Code 里运行:
text
/memory你应该检查三件事:
- 当前会话加载了哪些
CLAUDE.md、CLAUDE.local.md和 rules 文件。 - 自动记忆是否开启。
- 是否存在你没想到的上级目录记忆或冲突规则。
如果 Claude 不遵守某条规则,可以按这个顺序排查:
- 这条规则真的被加载了吗?
- 规则是否太抽象,例如"保持高质量"?
- 是否有另一条规则与它冲突?
- 这条规则是不是应该放在 paths 规则里,而不是全局加载?
- 你需要的是行为引导,还是硬性权限控制?
11. 给已有 CLAUDE.md 做瘦身
当 CLAUDE.md 长到几百行,常见症状是:
- Claude 启动后要读很久。
- 规则互相打架。
- 一些已经过期的路径还在影响决策。
- 每次都会加载大量当前任务根本用不到的背景材料。
可以按这个流程处理:
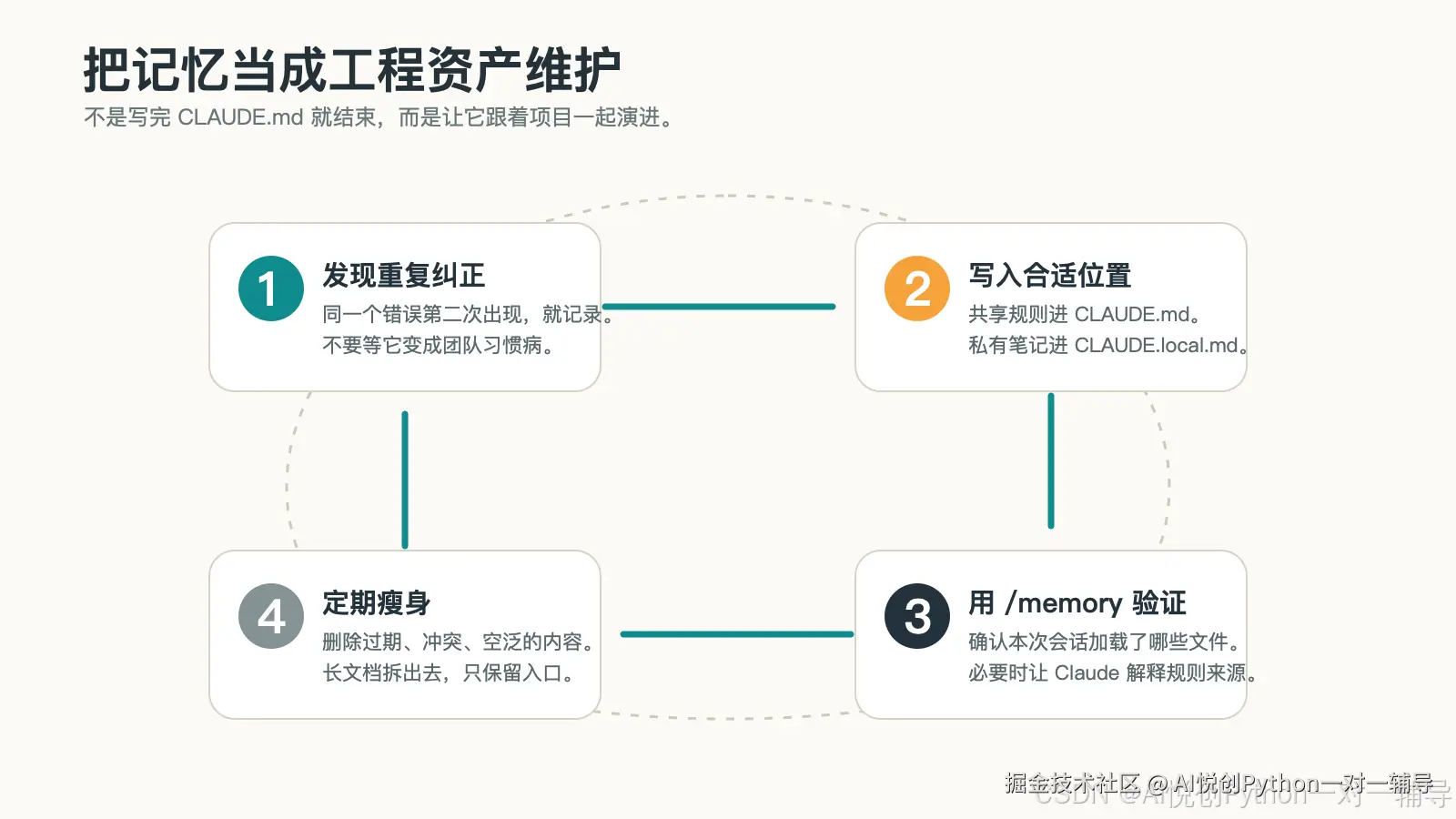
具体做法:
- 标记每一段内容的用途:项目事实、硬性工作流、示例入口、背景资料、临时笔记。
- 删除空泛句子:例如"写优雅代码""遵循最佳实践"。
- 把长内容移到
docs/,只在CLAUDE.md留入口。 - 把测试、前端、API 等场景化规则移到
.claude/rules/。 - 把个人内容移到
CLAUDE.local.md或~/.claude/CLAUDE.md。 - 用
/memory验证加载结果。
目标不是把文件压到最短,而是让每一行都有长期收益。
12. 一份可以直接套用的最终模板
下面是一份更适合真实项目的精简模板。
markdown
# 项目记忆
## 项目事实
- 技术栈:
- 包管理器:
- 主要入口:
- 数据存储:
## 常用命令
- 安装依赖:
- 启动开发:
- 运行测试:
- 构建:
- 代码检查:
## 目录边界
- `src/...`:
- `tests/...`:
- `docs/...`:
## 必须遵守
-
-
-
## 不要这样做
-
-
## 参考入口
- 架构说明:
- API 规范:
- 测试规范:填写时记住三条规则:
- 能被 Claude 自己从代码里稳定发现的,不必重复。
- 只在少数任务里需要的,不放全局。
- 一旦会导致错误实现、错误命令或错误目录,就值得写清楚。
13. 小练习:把一句抱怨变成一条有效记忆
假设你经常对 Claude 说:
text
不要再用 npm 了,我们项目用 pnpm。不要只在聊天里纠正。把它变成项目记忆:
markdown
## 包管理
- 本项目只使用 pnpm。
- 不要生成 npm、npx、yarn 命令。
- 安装依赖使用 `pnpm add <pkg>`。
- 执行脚本使用 `pnpm <script>`。再假设你经常说:
text
别把业务逻辑写到 controller 里。把它改成:
markdown
## 分层边界
- controller 只负责解析请求、调用 service、返回响应。
- 业务判断放在 `src/services/`。
- 数据访问放在 `src/repositories/`。
- 新增复杂逻辑时,优先参考 `src/services/order-service.ts`。这就是 CLAUDE.md 的本质:把反复发生的纠正,升级为稳定的工程规则。
14. 最后总结
Claude Code 记忆系统不是为了让 AI 记住所有细节,而是为了减少重复沟通,让协作从"每次重新培训"变成"带着项目手册上岗"。
实际使用时,按下面的优先级思考:
- 团队共享、每次都重要:写进
CLAUDE.md。 - 个人偏好、跨项目有效:写进
~/.claude/CLAUDE.md。 - 当前机器、当前任务:写进
CLAUDE.local.md。 - 文件类型相关:写进
.claude/rules/并用paths限定。 - 长文档、背景资料:放进
docs/,只保留入口。 - 工作中学到的经验:让自动记忆保存,但关键团队规则仍要显式写进项目文件。
真正好用的记忆文件不一定长,但一定具体。它应该像项目里的测试一样,持续维护、定期删除过期内容,并且能在关键时刻约束错误方向。
当你下次又想说"这个我不是说过了吗",那很可能就是一条应该进入记忆系统的规则。