现在AI大模型的应用越来越普遍,不过传统大模型还有不少缺点。行业一般靠增加参数来提升模型效果,不仅耗费大量算力,使用成本也比较高,而且参数利用率不高,不利于大模型的推广和落地。针对这些问题,DeepSeek开源了MoE混合专家架构大模型,通过优化架构提升了参数使用效率,有效改善了传统大模型能耗高、效率低的问题。
一、架构革新,重构大模型计算逻辑
1.1 传统稠密模型发展受限
目前市面上多数通用大模型都采用稠密架构,运行模式比较固定,无论面对简单对话还是复杂推理任务,模型全部参数都会参与运算。小规模模型使用这种方式基本没有问题,但随着百亿、千亿级大模型成为行业主流,弊端逐渐凸显。日常简单任务无需全部参数参与运算,大量参数长期闲置,造成算力、内存资源的浪费。这也导致大模型训练和使用成本居高不下,很多中小型开发团队受限于硬件和资金条件,很难落地应用高端大模型技术,制约了行业整体发展。
1.2 MoE稀疏架构实现按需运算
DeepSeek开源的MoE架构,彻底改变了传统模型全量计算的模式,采用稀疏按需调用的运行方式。研发团队将完整的大模型拆分为多个独立的专家子网络,搭配专属门控网络完成任务调度。模型处理不同任务时,门控网络会智能识别任务类型,只调用适配的专家网络参与计算,其余专家处于闲置状态,从根源减少无效运算。这种设计让模型总参数和实际运算参数相互分离,既能凭借海量参数储备保障模型综合能力,又能有效控制算力消耗。同时,模型优化了负载均衡机制,均匀分配各子网络的工作任务,有效提升了整体运行的稳定性。
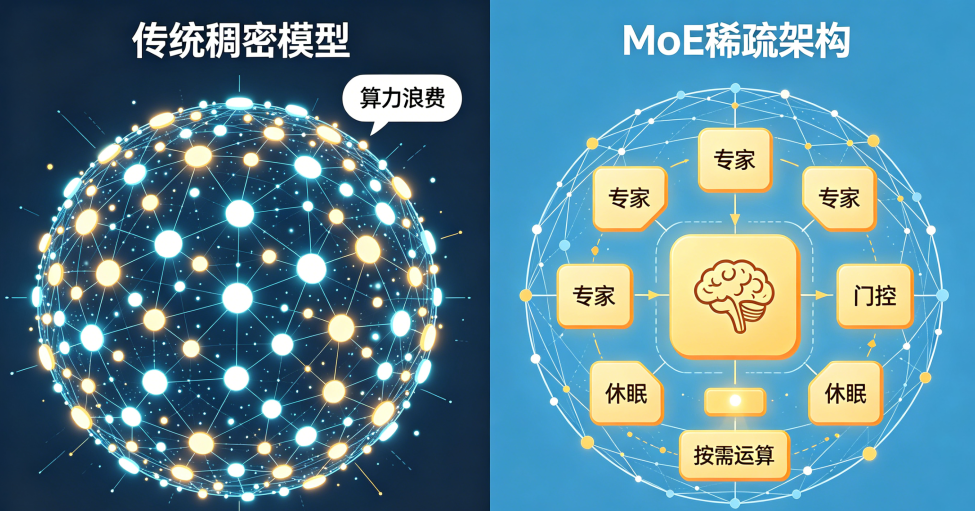
AI传统稠密模型和MoE稀疏架构对比图
二、效率升级,赋能行业普惠发展
2.1 模型使用效率得到明显提升
经过实际测试可以看出,和传统的稠密大模型相比,DeepSeek的MoE架构大模型,整体参数使用效率提升了三倍左右。这次的优化从多个方面都能体现出来。在算力使用上,同样的硬件资源,这款模型能够处理更多的任务,花费的运算时间也更少。在使用成本上,新的计算方式避免了很多不必要的资源浪费,让模型训练和运行的花费有所降低。在内存使用方面,经过简单优化调整,模型的缓存占用变少,能够处理更长的文本内容,适用的使用场景也变得更多。
2.2 模型兼顾了使用效果和实用性
大部分提升大模型运行效率的修改方式,多多少少都会让模型的本身效果变差,很多简化后的模型,在复杂问题解答和文字理解上都会出现问题。但这款MoE模型没有出现这种情况,在常规的模型测试中,它的整体表现和同类型的传统模型差不多,能力上没有明显变差。依靠多个专家网络的配合运行,模型可以应对很多常见场景,不管是解答专业问题、日常聊天还是分析长文本,都能正常输出内容,在实际使用中有着不错的价值。
2.3 开源模式带动行业发展
这次DeepSeek把MoE架构公开出来,打破了高端大模型技术不对外公开的情况,让普通开发者和企业也能轻松使用、修改大模型。很多从业者都可以基于这个现成的模型框架,根据不同的使用场景做出调整,让AI技术可以用到更多行业当中。不同于以往单纯增加模型参数的升级方式,这个架构主要是提高参数的利用率,解决了传统大模型浪费资源、运行低效的问题,为大模型低成本、大范围的普及使用,提供了新的思路,对整个AI行业的发展有一定的帮助。