SQL Server学习之旅
基础
使用软件
Microsoft SQL Server Management Studio
创建数据库
方法一:
sql
--创建数据库
create database DBTEST
on --数据文件
(
name ='DBTEST',--逻辑名称
filename ='D:\DATA\DBTEST.mdf',--物理路径和名称
size =5MB,--文件的初始大小
filegrowth =2MB --文件增长方式可以写大小,也可以写百分比
)
log on --日志文件
(
name ='DBTEST_log',--逻辑名称
filename ='D:\DATA\DBTEST_log.ldf',--物理路径和名称
size =5MB,--文件的初始大小
filegrowth =2MB--文件增长方式可以写大小,也可以写百分比
)方法二:
sql
create database DBTEST创建表与表结构
部门表
sql
--判断表是否存在
if exists(select * from sys.objects where name='Department' and type='U')
drop table Department
--建表(部门,职级,员工)
create table Department
(
--部门编号,primary key:主建,identity(1,1):自动增长,初始值1,增长步长1
Departmentld int primary key identity(1.1),
--部门名称
DepartmentName nvarchar(50) not null,
--部门描述
DepartmentRemark text
)说明
char:定长,char(10),无论存储数据是否真的到了10个字节,都要占用10个字节。
--char(10)存储'ab',仍然占用10个字节
varchar:变长,varchar(10),最多占用10个字节。
--varchar(10)存储'ab',占用2个字节
text:长文本
char,varchar,text前面加n:存储unicode字符,对中文友好
--varchar(100):存储100个字母或者50个汉字。
--nvarchar(100):存储100个字母或者100个汉字
员工表
sql
--员工
create table People
(
Peopleld int primary key identity(1,1),--员工编号
Departmentld int references Department(Departmentid) not null,--部门(引用外键)
RankId int references [Rank](RankId) not null,--职级(引用外键)
PeopleName nvarchar(50) not null,--姓名
PeopleSex nvarchar(1) default('男') check(PeopleSex='男' or PeopleSex='女') not null,--性别
PeopleBirth smalldatetime not null,--生日
PeoPleSalary decimal(12,2) check(PeoPleSalary>=1000 and PeoPleSalary<=1000000) not null,--月薪
PeoplePhone varchar(20) unique not null,--电话
PeopleAddress varchar(300),--地址
PeopleAddTime smalldatetime default(getdate()) --添加时间
)说明
primary key:主键
identity(1,1):自动增长,初始值1,增长步长1
references 表名(外键字段):外键
Rank\]:rank是一个表名,但同时也是关键字,所以加\[
not null:非空
default(''):默认
check(字段=' ' or 字段=' ')
smalldatetime:近期的日期,大概在1900年之后
decimal(12,2):共12位数,小数点后两位;如果是货币,使用money更好一些
unique:唯一
getdate():获取当前时间
修改表
添加列
alter table 表名 add 字段名 数据类型
删除列
alter table 表名 drop column 字段名
改变数据类型
alter table 表名 alter column 字段名 数据类型
sql
--员工表添加一列员工邮箱:
alter table People add PeopleMail nvarchar(100)
--删除员工表中的邮箱这一列
alter table People drop column PeopleMail
--需要改变邮箱列的数据类型为varchar(100)
alter table People alter column PeopleMail varchar(100)约束
删除约束
alter table 表名 drop constraint 约束名
直接右键找约束也行
添加check约束
alter table 表名 add constraint 约束名 check(表达式)
添加主键约束
alter table 表名 add constraint 约束名 primary key(字段名)
添加唯一约束
alter table 表名 add constraint 约束名 unique(字段名)
添加默认值约束
alter table 表名 add constraint 约束名 default 默认值 for 字段名
添加外键约束
alter table 表名 add constraint 约束名 foreign key(字段名) references 关联表名(字段名(主键))
插入数据
单行插入
sql
insert into Department(DepartmentName,DepartmentRemark) values('市场部','...')一次性插入多行
sql
insert into Department(DepartmentName,DepartmentRemark)
select '总经办','老板、经理、经理助理' union
select '开发部','....' union
select '财务部','财务办公室'查询数据
(1)查询所有行所有列
select * from 表名
(2)指定列查询
select 字段名,字段名,字段名,字段名 from 表名
(3)指定列查询,并自定义中文列名
select 字段名 别名,字段名 别名,字段名 别名 from 表名
(4)查询某列(不需要重复数据)
select distinct(字段名) from 表名
(5)添加列查询
select 字段名表达式 别名 from 表名
sql
--假设工资普调10%,查询原始工资和调整后的工资,显示(姓名,性别,月薪,加薪后的月薪)
SELECT PeopleName 姓名,Peoplesex 性别,Peoplesalary 月薪,Peoplesalary*1.1 加薪后月薪 from
People条件查询
SQL中常用运算符
sql
=:等于,比较是否相等及赋值
!=:比较不等于
>:比较大于
<:比较小于
>=:比较大于等于
<=:比较小于等于
IS NULL:比较为空
IS NOT NULL:比较不为空
in: 比较是否在其中
like:模糊查询
BETWEEN...AND...:比较是否在两者之间
and:逻辑与(两个条件同时成立表达式成立)
or:逻辑或(两个条件有一个成立表达式成立)
not:逻辑非(条件成立,表达式则不成立;条件不成立,表达式则成立)条件查询语句
select * from 表名 where 查询条件
排序
select * from 表名 order by 字段名 asc|desc
asc:升序,默认,可不写
desc:降序
sql
--根据名字长度降序排序
select * from People order by len(PeopleName) desc
--查询工资最高的5个人
select top 5 * from People order by PeopleSalary desc
--查询工资最高的10%的人
select top 10 percent * from People order by PeopleSalary desc空值或非空
select * from 表名 where 字段名 is null or 字段名=''
注意:空值和空字符串是不一样的
更复杂的查询
sql
--查询30-40岁之间,并且工资在10000-15000之间的员工
select * from People where
(year(getdate())-year(PeopleBirth) between 30 and 40)
and
(PeopleSalary between 10000 and 15000)
--查询星座是巨蟹座(6.22-7.22)的信息
select * from People where
(month(PeopleBirth) = 6 and day(PeopleBirth) >= 22)
or
(month(PeopleBirth) = 7 and day(PeopleBirth) <= 22)
--查询比A工资高的人
select * from People where PeopleSalary >
(select PeopleSalary from People where PeopleName='A')
---查询生肖
--鼠、牛、虎、兔、龙、蛇、马、羊、猴、鸡、狗、猪
--4 5 6 7 8 9 10 11 0 1 2 3
select *,
case year(PeopleBirth) % 12
when 4 then '鼠'
when 5 then '牛'
when 6 then '虎'
when 7 then '兔'
when 8 then '龙'
when 9 then '蛇'
when 10 then '马'
when 11 then '羊'
when 0 then '猴'
when 1 then '鸡'
when 2 then '狗'
when 3 then '猪'
else ''
end 生肖
from People模糊查询
模糊查询使用like关键字和通配符结合来实现
常用通配符
sql
%:代表匹配0个字符、1个字符或多个字符
_:代表匹配有且只有1个字符
[]:代表匹配范围内
[^]:代表匹配不在范围内案例解析
sql
--查询姓刘的员工,名字是2个字
--方案一:
select * from People where PeopleName like '刘_'
--方案二:
select * from People where SUBSTRING(PeopleName,1,1) = '刘' and LEN(PeopleName) = 2
--查询出电话号码开头为138的,第四位好像是7或者8,最后一个号码是5
select * from People where PeoplePhone like '138[7,8]%5'
--查询出电话号码开头为138的,第四位好像是2-5之间,最后一个号码不是2和3
select * from People where PeoplePhone like'138[2-5]%[^2,3]'SUBSTRING(字符串或字段名,起始位置,取几个字符)
聚合函数
sql
count:求数量
max:求最大值
min:求最小值
sum:求和
avg:求平均值案例
sql
--求数量,最大值,最小值,总和,平均值,在一行显示
select count(*)人数,max(PeopleSalary) 最高工资,min(PeopleSalary) 最低工资,
sum(PeopleSalary)工资总和,round(avg(PeopleSalary),2)平均工资 from People
--求出工资比平均工资高的人员信息
select * from People where PeopleSalary >
(select round(avg(PeopleSalary),2) 平均工资 from People)
--求数量,年龄最大值,年龄最小值,年龄总和,年龄平均值,在一行显示
--方案一:
select COUNT(*)数量
max(year(getdate())-year(PeopleBirth))最高年龄,
min(year(getdate())-year(PeopleBirth))最低年龄,
sum(year(getdate())-year(PeopleBirth))年龄总和,
avg(year(getdate())-year(PeopleBirth)) 平均年龄
from People
--方案二:
select COUNT(*)数量,
max(DATEDIFF(year,PeopleBirth,GETDATE())) 最高年龄,
min(DATEDIFF(year,PeopleBirth,GETDATE()))最低年龄,
sum(DATEDIFF(year,PeopleBirth,GETDATE())) 年龄总和,
avg(DATEDIFF(year,PeopleBirth,GETDATE()) 平均年龄
from Peopledatediff(year|month|day,'时间1','时间2'):时间差
分组查询
select 聚合函数 from 表单 group by 字段名
select 聚合函数 from 表单 where 普通条件 group by 字段名 having 聚合函数条件
多表查询
笛卡尔乘积
select * from 表1,表2
是将两个表所有记录依次排列组合形成新结果,查询结果是两个表数量的乘积
简单的多表查询
select * from 表1,表2 where 表1.字段=表2.字段
内连接
select * from 表1 inner join 表2 on 表1.字段=表2.字段
简单多表查询和内连接共同的特点:不符合主外键关系的数据不会被显示出来
外连接
左外连:以左表表1的主表进行数据显示,主外键关系找不到的数据用null取代
select * from 表1 left join 表2 on 表1.字段=表2.字段
右外连:以右表表2的主表进行数据显示,主外键关系找不到的数据用null取代
select * from 表1 right join 表2 on 表1.字段=表2.字段
A left join B = B right join A
全外连:两张表的数据,无论是否符合关系,都要显示
select * from 表1 full join 表2 on 表1.字段=表2.字段
进阶
T-SQL
信息打印
print '内容'
select '内容'
变量
局部变量
以@开头,先声明,再赋值
声明:declare @变量名 数据类型
赋值:set @变量名='内容' 或 select @变量名='内容'
声明时同时赋值declare @变量名 数据类型 = 内容
set和select进行赋值的时候的区别:
--set:赋值变量指定的值
--select:一般用于表中查询出的数据赋值给变量,如果查询结果有多条,取最后一条赋值
例如:select @变量名 = 字段名 from 表名 是当前表最后一行的字段名赋值给@变量
全局变量
以@@开头,由系统进行定义和维护,全部都是只读的
shell
@@ERROR: 返回执行的上一个语句的错误号
@@IDENTITY:返回最后插入的标识值
@@MAX_CONNECTIONS:返回允许同时进行的最大用户连接数
@@ROWCOUNT:返回受上一语句影响的行数
@@SERVERNAME:返回运行SQL Server的本地服务器的名称
@@SERVICENAME :返回SQL Server正在其下运行的注册表项的名称
@@TRANCOUNT:返回当前连接的活动事务数
@@LOCK_TIMEOUT :返回当前会话的当前锁定超时设置(毫秒)go语句
1、等待go语句之前代码执行完成之后才能执行后面的代码
2、批处理结束的一个标志
运算符
T-SQL中使用的运算符分为7种
sql
算数运算符:加(+)、减(-)、乘(*)、除 (/) 、模(%)
逻辑运算符:AND、OR、LIKE、BETWEEN、IN、EXISTS、NOT、ALL全部、ANY存在
赋值运算符:=
字符串运算符:+
比较运算符:=、>、<、>=、<=、<>
位运算符:|、&、^
复合运算符:+=、-=、/=、%=、*=例1:
sql
--已知长方形的长和宽,求长方形的周长和面积
declare @c int =10
declare @k int = 5
declare @zc int
declare @mj int
set @zc = (@c+@k)*2
set @mj = @c*@k
print '圆周长:' + cast(@zc as varchar(10))
print '圆面积:' + Convert(varchar(10),@mj)例2:
sql
create table AccountInfo --账户信息表
(
AccountId int primary key identity(1,1),--账户编号
AccountCode varchar(20) not null,--身份证号码
AccountPhone varchar(20)not null,--电话号码
RealName varchar(20) not null,--真实姓名
OpenTime smalldatetime not null --开户时间
)
create table BankCard --银行卡
(
CardNo varchar(30) primary key,--银行卡卡号
AccountId int not null,--账户编号(与账户信息表形成主外键关系)
CardPwd varchar(30) not null,--银行卡密码
CardMoney money check(money >= 0) not null,--银行卡余额
CardState int not null,--1:正常,2:挂失,3:冻结,4:注销
CardTime smalldatetime default(getdate()) --开卡时间
)
create table CardExchange --交易信息表(存储存钱和取钱的记录)
(
ExchangeId int primary key identity(1,1),--交易自动编号
CardNo varchar(30) not null, --银行卡号(与银行卡表形成主外键关系)
MoneyInBank money not null,--存钱金额
MoneyOutBank money not null,--取钱金额
ExchangeTime smalldatetime not null--交易时间
)
--小A身份证:420107199507104133,到银行来开户,查询身份证在账户表是否存在,
--不存在则进行开户开卡,存在则不开户直接开卡,限制一个人只能开3张卡
declare @AccountId int --账户编号
declare @CardCount int --卡数量
if EXISTS(select * from AccountInfo where AccountCode ='420107199507104133') --存在此人
begin
select @AccountId = (select Accountld from AccountInfo where AccountCode ='420107199507104133') --查出id赋值给AccountId
select @CardCount = (select count(*) from BankCard where AccountId = @AccountId)
if @CardCount <= 2
begin
insert into BankCard(AccountId,CardPwd,CardMoney,CardState) values(@AccountId,'123456'0,1)
end
else
begin
print '每人名下只能拥有3张银行卡,您已到上限,无法再开卡'
end
end
else --不存在此人
begin
insert into AccountInfo(AccountCode,AccountPhone,RealName,OpenTime) values('420107199507104133','电话号码','小A',getdate())
set @AccountId = @@IDENTITY --给AccountId赋值最新插入的数据id
insert into BankCard(AccountId,CardPwd,CardMoney,CardState) values(@Accountld,'123456',0,1)
end
--查询银行卡账户余额,是不是所有的账户余额都超过了3000
if 3000 < All(select CardMoney from BankCard)--有ALL、ANY就不能把数字写在后面
begin
print '所有的银行卡余额都超过了3000'
end
else
begin
print '不是所有的银行卡余额都超过了3000'
end 流程控制
选择分支结构
方案一:if-else
sql
if 条件
begin
--符合条件
end
else
begin
--不符合条件
end方案二:case-end
sql
case
when 条件 then 结果
else 结果
end
sql
--查询银行卡信息,将银行卡状态1,2,3,4分别转换为汉字"正常,挂失,冻结,注销",
--并且根据银行卡余额显示银行卡等级
--30万以下为"普通用户",30万及以上为"VIP用户",
--显示列分别为卡号,身份证,姓名,余额,用户等级,银行卡状态。
select CardNo 卡号,AccountCode 身份证号,RealName 姓名,CardMoney 余额,
case
when CardMoney >= 300000 then 'VIP用户'
else '普通用户'
end 用户等级,
case CardState
when 1 then '正常'
when 2 then '挂失'
when 2 then '冻结'
when 2 then '注销'
else '异常'
end 银行卡状态
from BankCard
inner join AccountInfo on AccountInfo.AccountId = BankCard.AccountId循环结构
使用while,一般是为了读取游标
sql
--循环打印1-10
declare @i int = 1
while @i <= 10
begin
print @i
set @i = @i + 1
end
--打印九九乘法表
declare @i int = 1
while @i <= 9
begin
declare @str varchar(1000)=''
declare @j int = 1
while @j <= @i
begin
set @str = @str + cast(@i as varchar(1)) + '*' + cast(@j as varchar(1))
+ '=' + cast(@i*@j as varchar(2)) + char(9)
set @j= @j + 1
end
set @i = @i + 1
print @str
end特殊字符:
char(9):制表符
char(10):换行
子查询
也就是查询条件是一个需要查询才能得到的数据
sql
--从所有账户信息中查询出余额最高的交易明细(存钱取钱信息)。
--如果有多个人余额一样,并且都是最高,下面查询只能查出一个
select * from CardExchange where CardNo=
(select top 1 CardNo from BankCard order by CardMoney desc)
--如果有多个人余额一样,并且都是最高,需要都查出来
select * from CardExchange where CardNo in
(select CardNo from BankCard where CardMoney =
(select max(CardMoney) from BankCard)分页
使用行号row_number分页
select * from (select ROW_NUMBER() over(order by 主键)RowId,* from 表名)Temp where RowId between (当前页-1)*每页数据量+1 and 当前页*每页数据量
sql
--如果每页5条数据,展示第3分页的内容
declare @PageSize int = 5
declare @PageIndex int = 3
select* from
(select ROW_NUMBER()over(order by Stuld) RowId,* from Student) Temp
where RowId between (@PageIndex-1)*@PageSize+1 and @PageIndex*@PageSize事务
操作捆绑,同时成功或同时失败。
begin transaction:开启事务
commit transaction:提交事务
rollback transaction:回滚
每执行一行,@@ERROR里如果是0就说明执行成功了,通过累计,最后如果依然是0就可以提交事务,如果有执行失败,就会回滚
sql
--模拟取款6000
begin transaction --开始事务
declare @myError int = 0--定义一个累加的标识
update BankCard set CardMoney = CardMoney-6000 where CardNo = '卡号'--取款
set @myError = @myError + @@ERROR--报错累加
insert into CardExchange(CardNo,MoneyInBank,MoneyOutBank,ExchangeTime) values('卡号',0 6000,GETDATE())--添加取款记录
set @myError = @myError + @@ERROR--报错累加
if @myError = 0--全部执行成功
begin
commit transaction--提交事务
print'取款成功'
end
else--有执行失败的部分
begin
rollback transaction--回滚
print'取款失败'
end索引
提高检索查询效率。
SQL SERVER索引类型
1、按存储结构区分:聚集索引(又称聚类索引,簇集索引)、非聚集索引(非聚类索引,非簇集索引),如新华字典。
聚集索引:根据数据行的键值在表或视图中的排序存储这些数据行,每个表只有一个聚集索引 ,比如主键就是表的聚集索引。聚集索引是一种对磁盘上实际数据重新组织以按指定的一列或多列值排序(类似字典中的拼音索引)(物理存储顺序)。
非聚集索引:具有独立于数据行的结构,包含非聚集索引键值,且每个键值项都有指向包含该键值的数据行的指针。(类似字典中的偏旁部首索引)(逻辑存储顺序)。
2、按数据唯一性区分:唯一索引、非唯一索引
3、按键列个数区分:单列索引、多列索引
4、主XML索引、辅助XML索引
5、空间索引
使用索引
通过显式的create index命令
CREATE [UNIQUE][CLUSTERED | NONCLUSTERED] INDEX 索引名 ON 表名(字段名 [ASC | DESC][,...n])
clustered:聚集索引
nonclustered:非聚集索引
查看索引:select * from sys.indexes where name='索引名' with (参数设置)
删除索引:drop index 索引名 on 表名
sql
--给身份证字段添加索引
create unique nonclustered index index_code on AccountInfo(AccountCode)
--查看索引
select * from sys.indexes where name='index_code'
--删除一个索引
drop index index_code on AccountInfo
--使用索引查询
select * from AccountInfo with(index = index_code)
where AccountCode = '420107199507104133'表中的数据存储
数据页
8KB(8192字节,减去96字节的头)大小的数据
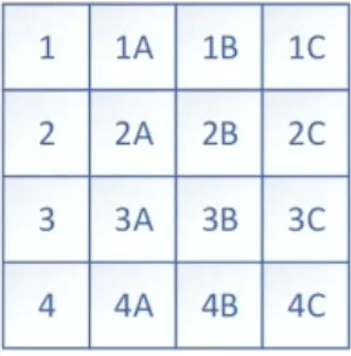
每个数据页是会记录自己的上一页和下一页
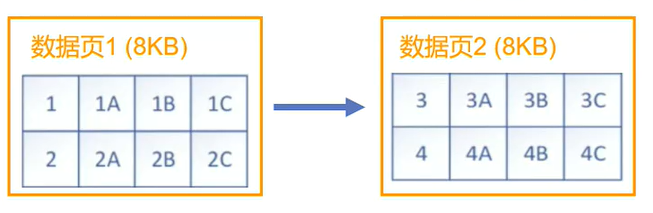
如果在某数据页加数据,会这样加
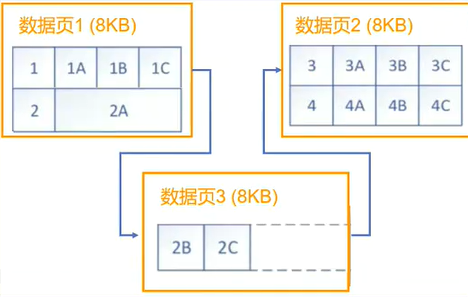
LOB类型
LOB(large object)是一种用于存储大对象的数据类型,每个LOB
可以有2GB。LOB列可以跨多页,并且页不一定是连续的。
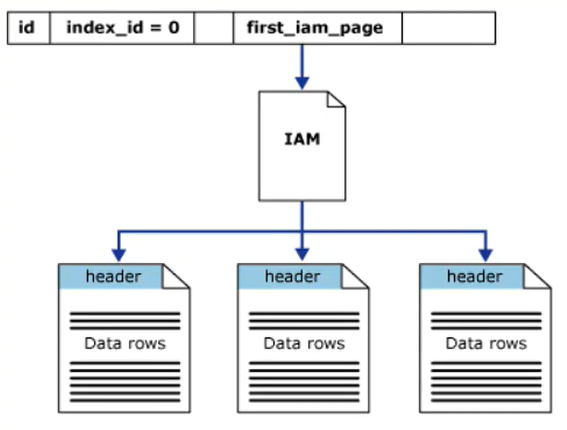
堆结构
堆是一个没有聚集索引的表。表中的数据不按任何字段排序。
用"索引分配映射(IAM)"页将堆的页面联系在一起。也就是IAM知道数据在哪
视图
创建视图:
sql
create view View_名称
as
语句
go删除视图:drop view View_名称
未来直接使用视图:select * from View_名称
视图的功能主要是做数据的展示,但是数据的维护修改,最好还是在实体表中去修改
游标
游标:定位到结果集中某一行。
游标分类
(1)静态游标(Static):在操作游标的时候,数据发生变化,游标中数据不变
(2)动态游标(Dynamic):在操作游标的时候,数据发生变化,游标中数据改变,默认值。
(3)键集驱动游标(KeySet):在操作游标的时候,被标识的列发生改变,游标中数据改变,其他列不改变。
使用游标
1、创建指向单列的游标
declare 游标名 cursor scroll for select 游标移动的列名 from 放置游标的表
scroll:滚动游标,没有scroll游标是只进的,有了就可以上下移动
2、创建指向多列的游标
declare 游标名 cursor scroll for select 列名1,列名2,列名3... from 表名
3、打开游标
open 游标名
4、关闭游标,可以再次打开
close 游标名
5、删除游标,只能再次创建
deallocate 游标名
6、提取某行数据
提取第一行:fetch first from 游标名
提取最后一行:fetch last from 游标名
提取第N行:fetch absolute N from 游标名
提取当前行下面的第N行:fetch relative N from 游标名
提取下一行:fetch next from 游标名
提取上一行:fetch prior from 游标名
7、遍历游标
sql
declare @acc varchar(20)--创建一个变量存数据
fetch absolute 1 from 游标名 into @acc --提取第一行并赋值给acc
while @@fetch_status = 0 --判断是否提取成功
begin
print '提取成功:'+@acc
fetch next from 游标 into @acc --游标下移并存入acc
end备注:
(1)全局变量@@fetch_status:0提取成功,-1失败,-2不存在
(2)如果是游标指向多列,需要定义多个变量,然后 into 多个变量
8、通过游标修改和删除
update 表名 set 列名=值 where current of 游标名
delete from 表名 where current of 游标名
函数
触发器
某一事件发生,自动发生后续事件
触发器分类
1、Instead of 触发器:在执行操作之前被执行
2、After 触发器:在执行操作之后被执行
触发器使用
1、创建触发器
create triggrt 触发器名称 on 表 触发器类型 操作 as sql语句 go
触发器类型:instead of | after
操作:insert | update | detele
sql
--(1)假设有部门表和员工表,在添加员工的时候,该员工的部门编号如果在部门表中找不到,则自动添加部门信息,部门名称为"新部门"
create trigger tri_InsertPeople on People after insert
as
--触发器有一个特殊的表,添加的时候会自动生成一个inserted临时表把查询语句放在里面
if not exists(select * from Department where DepartmentId = (select DepartmentId from inserted))
begin
insert into Department(DepartmentId,DepartmentName)
values((select DepartmentId from inserted),'新部门')
end
go
--创建好后再insert时,如果符合条件会自动生效
--(2)触发器实现,删除一个部门的时候将部门下所有员工全部删除。
create trigger tri_DeleteDept on Department after delete
as
--删除时,会自动生成一个deleted临时表放置将要删除的数据
delete from People where DepartmentId =(select DepartmentId from deleted)
go
--(3)创建一个触发器,删除一个部门的时候判断该部门下是否有员工,有则不删除,没有则删除。
drop trigger tri_DeleteDept
create trigger tri_DeleteDept on Department instead of delete
as
if not exists(select * from People where DepartmentId =(select Departmentld from deleted))
delete from Department where Departmentld =(select DepartmentId from deleted)
go
--测试触发器
delete from Department where Departmentld ='001'
--(4)修改一个部门编号之后,将该部门下所有员工的部门编号同步进行修改
create trigger tri UpdateDept on Department after update
as
--修改数据实际是先删除再在原位置上添加,所以被修改的旧数据存在于deleted表中,修改的新数据存在于inserted表中
update People set DepartmentId=(select DepartmentId from inserted)
where DepartmentId=(select DepartmentId from deleted)
go
--测试
update Department set DepartmentId = '005' where DepartmentId = '001'2、删除触发器
drop trigger 触发器名
3、注意事项
在项目里尽量慎用触发器,因为多个触发器容易导致一直触发
存储过程
存储过程(Procedure)是SQL语句和流程控制语句的预编译集合。
存储过程与函数的区别:函数会嵌入到语句中调用,存储过程是被封装好的语句直接被外部的程序去调用
1、创建无需参数的存储过程
create proc 存储过程名称 as SQL语句 go
2、使用存储过程
exec 存储过程名称
3、删除
drop proc 存储过程名称
4、有输入输出参数的存储过程
sql
--有输入参数,没有输出参数,但是有返回值的存储过程(返回值必须整数)。
--模拟银行卡取钱操作,传入银行卡号,取钱金额,实现取钱操作,
--取钱成功,返回1,取钱失败返回-1
create proc proc_Quqian
@CardNo varchar(30),
@money money
as
update BankCard set CardMoney= CardMoney - @money
where CardNo = @CardNo
if @@ERROR <> 0 --不等于0
return -1
insert into CardExchange(CardNo,MoneyInBank,MoneyOutBank,ExchangeTime)
values(@CardNo,0,@money,getdate())
return 1
go
declare @returnValue int
exec @returnValue = proc_Quqian '63215400639007',1000
--有输入参数,有输出参数的存储过程
--查询出某时间段的银行存取款信息以及存款总金额,取款总金额,
--传入开始时间,结束时间,显示存取款交易信息的同时,返回存款总金额,取款总金额。
deate proc proc selectExChange
@start varchar(20),--开始时间
@end varchar(20),--结束时间
@sumIn money output,--存款总金额,output输出参数
@sumOut money output --取款总金额,输出参数
as
select @sumIn =(select sum(MoneyInBank) from CardExchange
where ExchangeTime between @start +'00:00:00' and @end +'23:59:59')
select @sumOut = (select sum(MoneyOutBank) from CardExchange
where ExchangeTime between @start +'00:00:00' and @end +' 23:59:59')
select *from CardExchange
where ExchangeTime between @start +'00:00:00' and @end +'23:59:59'
go
declare @sumIn money
declare @sumOut money
exec proc_selectExChange '2020-1-1','2020-12-11',@sumIn output,@sumOut output
select @sumIn
select @sumOut