文章目录
- 自定义词库的背单词助手------设计思路与实现要点
-
- 一、项目愿景
- [二、MVP 数据流](#二、MVP 数据流)
- 三、音频方案
- 四、交互形态
- 五、运行环境与演进愿景
- [六、代码中的三个扩展点(来自 README)](#六、代码中的三个扩展点(来自 README))
- 七、初期问题与解决方案
-
- [问题 1:后台没有词库,用户导入的是英文+中文释义](#问题 1:后台没有词库,用户导入的是英文+中文释义)
- 输入格式设计------让用户怎么写都能解析
- [问题 2:希望支持 .docx 文件](#问题 2:希望支持 .docx 文件)
- [问题 3:点击音频播放键有 2~3 秒延迟](#问题 3:点击音频播放键有 2~3 秒延迟)
- 八、运行与使用
自定义词库的背单词助手------设计思路与实现要点
一、项目愿景
我想做一个小软件或工作流,一句话概括就是 "自定义词库的背单词助手" 。
核心功能:
- 导入自定义词库(先支持 md/txt/xlsx,后续再补充拍照识别等)
- 呈现单词读音(音标 + 音频)
二、MVP 数据流
整体处理流程如下:
导入文件(md/txt/xlsx) → 解析成 [{word, 释义?}]
↓
匹配 ECDICT → 补全音标、词频、词性
↓
前端卡片展示:单词 + IPA + 🔊播放按钮
↓
音频:点击→有道API→缓存到本地→播放三、音频方案
- 最终方向:在线优先,离线降级为本地
- 初期开发:先依托在线拉取
四、交互形态
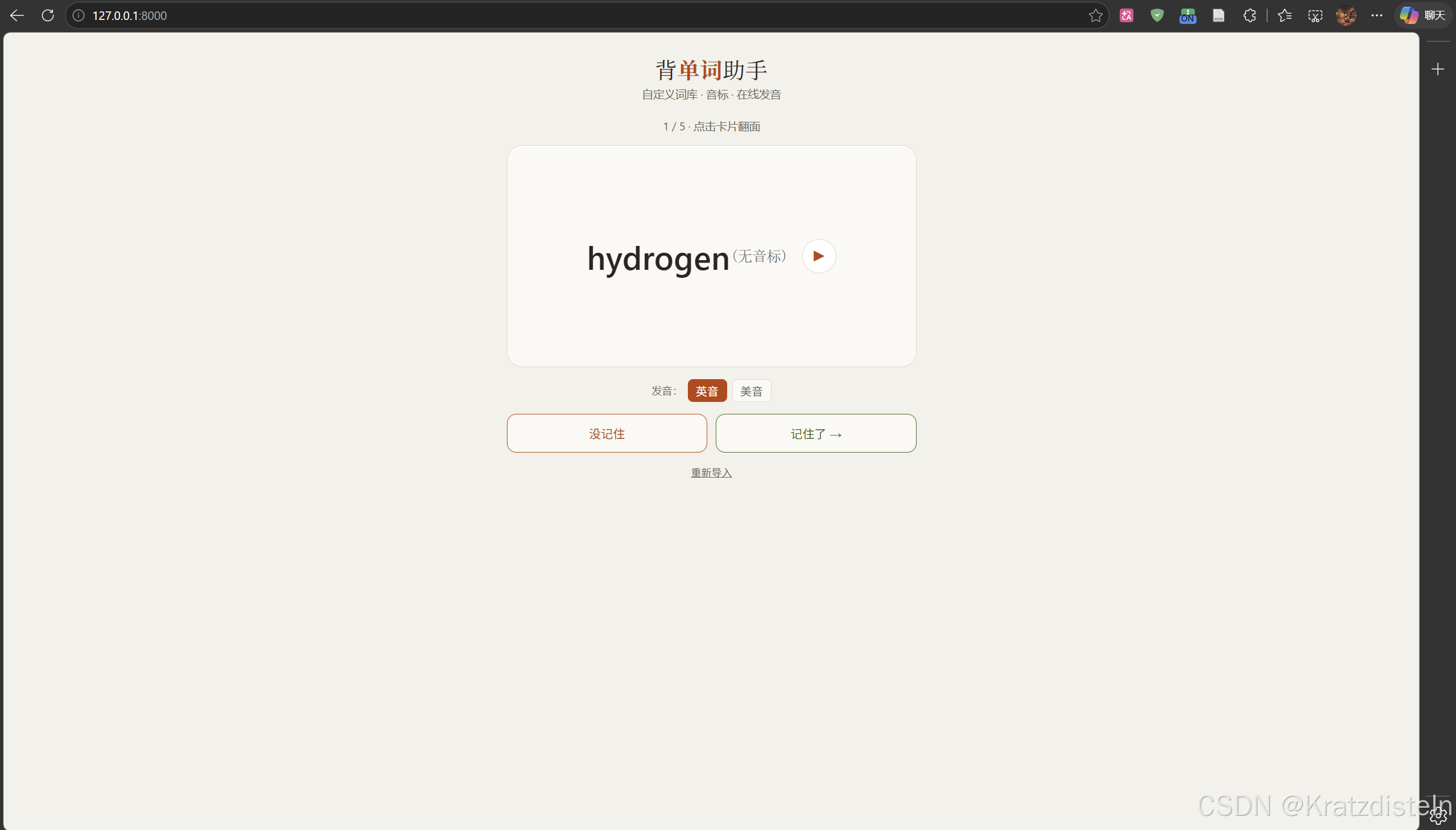
首选 卡片翻看模式:
- 正面:英文 + 音标 + 点击UI放音频
- 反面:中文释义 + 相关用法
五、运行环境与演进愿景
- 起步 :本地网页(
uvicorn app:app --reload,访问localhost:8000) - 演进路线:本地网页 → 互联网网站 → 桌面独立程序 → 手机应用商城
- 架构硬要求 :前后端彻底分离
- 后端:纯 FastAPI,只吐 JSON 和音频
- 前端:不依赖任何框架的静态页
- 好处:一份核心代码,本地直接跑、部署上线、Tauri 套壳桌面端、Capacitor 打包 App,都无需改动
六、代码中的三个扩展点(来自 README)
dict_lookup()------ 可替换的词典核心。当前内置 8 个 demo 词,替换成 ECDICT 的stardict.csv(77 万词,含 IPA、词频、词性,免费离线)只需改造这一个函数。/audio接口 ------ 已做成"在线优先"代理结构。要加离线降级,只需在拉有道之前先查本地cache/目录,命中即返回。next(known)------ 间隔重复接入点。目前顺序翻页,接上 SM-2 算法即可拥有 Anki 式复习。
七、初期问题与解决方案
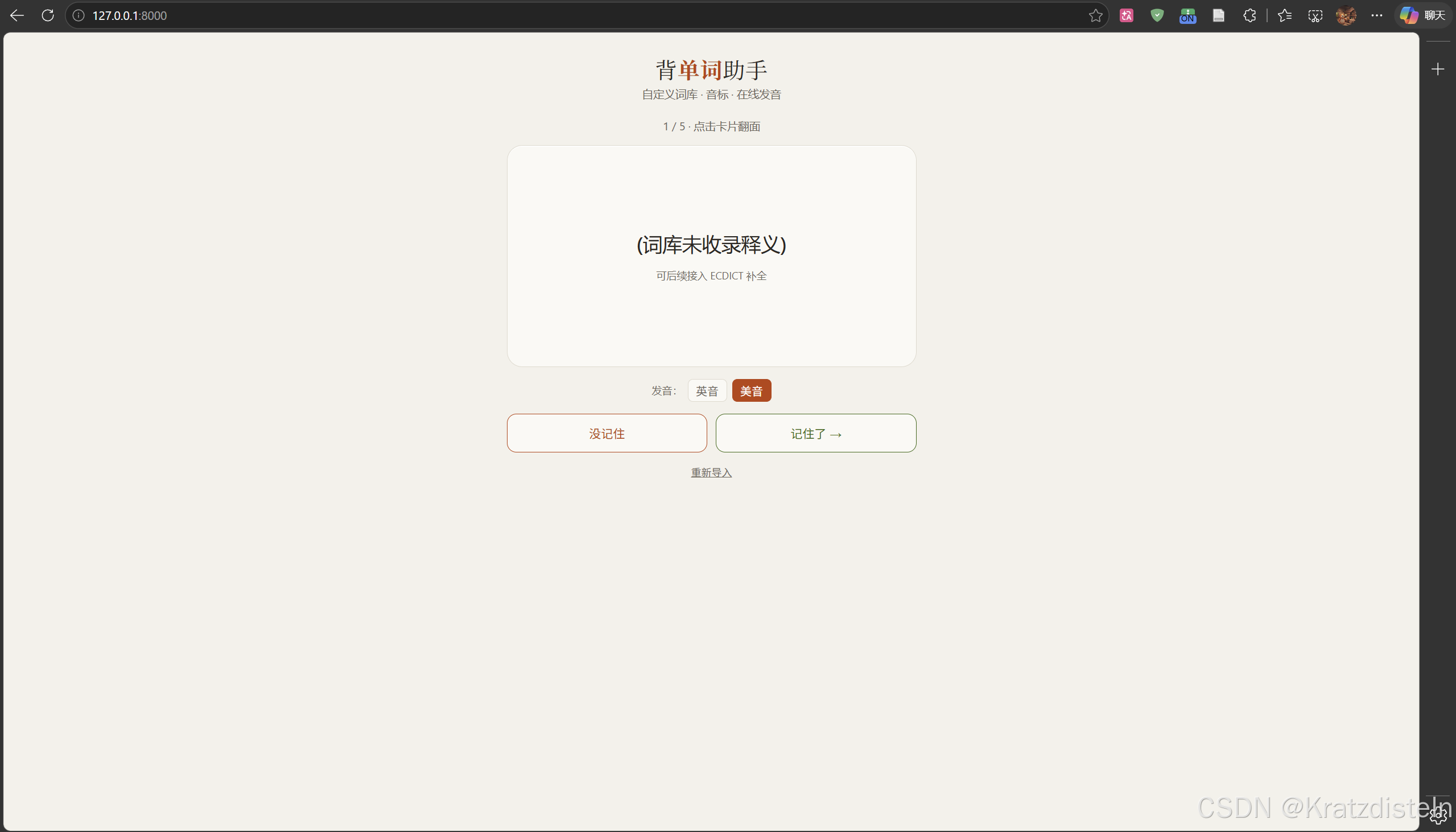
问题 1:后台没有词库,用户导入的是英文+中文释义
解决方案:释义以用户导入的为准,词典只兜底音标。
- 用户导入
hydrogen 氢气,背面就显示"氢气" - 若只写单词没给释义,才去内置词典查;查不到则提示"在词库里给它加上释义即可显示"
输入格式设计------让用户怎么写都能解析
要求正则足够"灵活",自动识别分隔符。支持的写法:
hydrogen 氢气
hydrogen = 氢气
hydrogen: 氢气
hydrogen | 氢气
hydrogen,氢气
hydrogen, 氢气
hydrogen 氢气 (Tab 分隔,xlsx 双列同理)
hydrogen氢气 (中英文连写)
carbon dioxide 二氧化碳 (带空格的词组)解析规则:第一段连续英文是单词,遇到第一个分隔符或第一个中文字符时,后面全算释义。这样用户几乎不用记格式。
问题 2:希望支持 .docx 文件
解决方案 :直接加解析分支,用 python-docx 读取段落文本和表格。
问题 3:点击音频播放键有 2~3 秒延迟
原因 :每次点击才去远端拉取音频,存在网络往返耗时。
解决办法(两层叠加):
- 前端预取:渲染当前卡片时,在后台提前请求下一张卡片的音频
- 后端加本地缓存 :
/audio接口先把有道返回的 mp3 存入cache/目录,第二次听同一个词直接返回本地文件,秒开
这样,第一次听某个词仍需在线等待,但后续全程无延迟。同时,cache/ 目录里的 mp3 断网也能播放,实现了"在线优先、离线降级"的第一步。
八、运行与使用
安装依赖后启动即可:
bash
pip install -r requirements.txt
uvicorn app:app --reload浏览器打开 localhost:8000,把单词文件拖进去就行。
依赖说明:相比最初版本,增加了
python-docx用于解析 Word 文档。