随着多模态大模型技术落地加速,OCR 已从传统字符识别,进化为文档智能理解核心模块。
结合最新 OmniDocBench 权威评测与技术架构、落地实践,目前国内 OCR 领域已形成稳定的第一梯队,多款轻量化模型凭借高精度、低算力消耗,成为行业主流选型。
从评测数据来看,头部模型综合表现十分亮眼:智谱 GLM-OCR 识别准确率 94.60%,位列榜首;百度 PaddleOCR-VL-1.5 以 94.50% 紧随其后;小红书 FireRed-OCR、深度求索 DeepSeek-OCR-2 分别达到 92.94%、91.09%。不同于以往重型模型设计,这几款产品均采用轻量化架构,彻底摆脱 "大参数 = 高性能" 的固有思维。
其中 GLM-OCR 与 PaddleOCR-VL-1.5 参数量仅 0.9B,DeepSeek-OCR-2 激活参数低至 0.57B。轻量化设计大幅降低部署门槛,无论是云端服务、边缘设备、移动端集成,还是企业私有化部署,都能在普通算力环境下实现高效推理,兼顾性能与落地成本,也是技术团队选型时的重要加分项。
四款标杆模型技术路线各有侧重,针对不同技术难点与业务场景做了定向优化。 智谱 GLM-OCR 基于 GLM-V 多模态底座,搭载自研 CogVIT 视觉编码器,结合端到端强化学习训练,对手写字体、印章、多语种混排、复杂版式文档鲁棒性极强,多用于政务、金融等对识别精度要求极高的 To B 场景。
百度 PaddleOCR-VL-1.5 主打通用场景适配,创新异形框定位算法,突破传统矩形检测局限,可精准捕捉弯曲、倾斜文本,同时原生支持表格、公式解析与阅读顺序还原,开发接入简单,是办公类系统、教育类工具的常用方案。
FireRed-OCR 聚焦内容结构化难题,通过多阶段训练抑制结构幻觉,优化 Markdown 标准化输出,适配图文排版、内容聚合类业务,能有效减少后续格式二次开发工作量。
DeepSeek-OCR-2 采用视觉因果流架构搭配 MoE 稀疏激活解码器,模拟人类阅读逻辑处理图文内容,推理延迟低、吞吐能力强,更适合实时扫描、批量票据识别等对响应速度敏感的业务。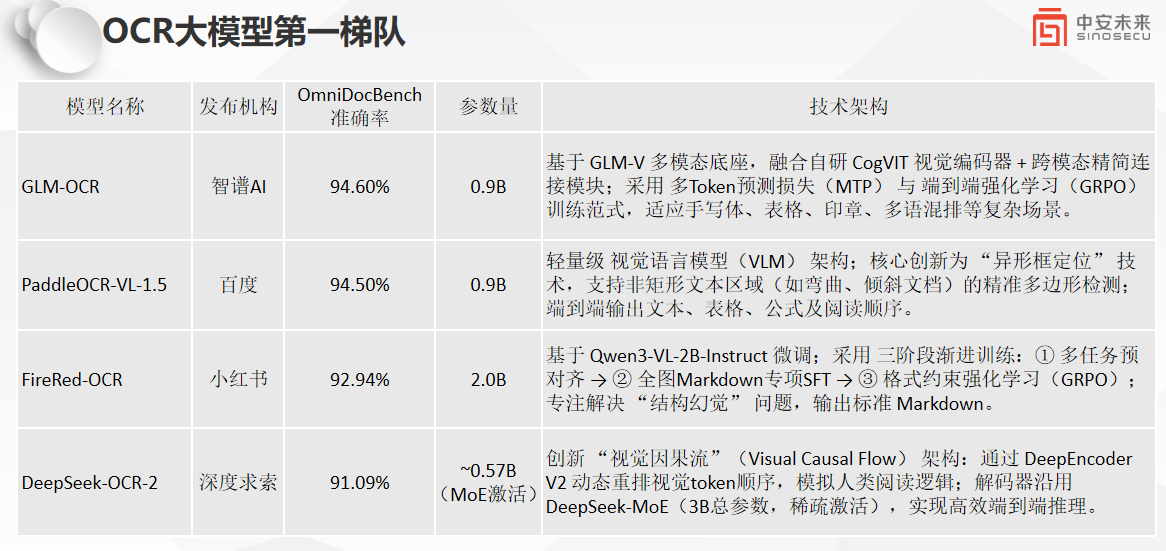
现阶段行业最大的技术变革,是 OCR 完成了从感知识别 到认知理解的升级。传统方案仅能完成图文转写,而大模型驱动的 OCR 可解析文档层级、逻辑结构,直接输出结构化数据,极大简化后端数据处理流程。同时主流模型均开放多端适配能力,兼容主流开发框架,便于开发者快速集成至自有项目。
放眼整个技术赛道,国产 OCR 大模型已在算法精度、工程化能力、场景落地层面实现全面突破。对于开发者与企业技术团队而言,多样化的技术路线也提供了更丰富的选型空间,可根据精度、速度、部署环境、业务场景按需选择。
未来,随着多模态技术持续迭代,OCR 还会向更强语义理解、更低功耗、更强跨场景泛化能力方向演进,持续成为数字化系统中不可或缺的基础技术组件。