k8s容器编排技术实践------K8s对象deployment应用详解![]() https://blog.csdn.net/xiaochenXIHUA/article/details/161427275k8s容器编排技术实践------k8s的介绍及其整体运行架构
https://blog.csdn.net/xiaochenXIHUA/article/details/161427275k8s容器编排技术实践------k8s的介绍及其整体运行架构![]() https://coffeemilk.blog.csdn.net/article/details/161011629
https://coffeemilk.blog.csdn.net/article/details/161011629
一、job简介
容器按照持续运行的时间可分为两类:【服务类容器】和【工作类容器】:
- 【服务类容器】通常持续提供服务,需要一直运行(如:http server,mysql db等)。
- 【工作类容器】则是一次性任务(如批处理程序,完成后容器就退出)。
k8s中的的Deployment、ReplicaSet和DaemonSet都用于管理服务类容器;
对于工作类容器,可以使用Job。
1.1、job是什么
job 是 Kubernetes(k8s) 原生的一类控制器(Controller) ,专门用于管理一次性、短时运行的任务 ,核心目标是保证任务最终成功执行完成。
与 Deployment/StatefulSet 这类常驻服务控制器有本质区别:
- Deployment:期望 Pod 永久运行(业务服务、接口、中间件等),Pod 退出会立刻重建;
- Job:期望 Pod 执行完任务后正常退出,只要任务未完成,就会不断重试,直到任务执行成功。
| 序号 | k8s中job的工作机制 |
|---|---|
| 1 | Job 会根据配置创建一组 Pod,持续监控 Pod 运行状态; |
| 2 | 若 Pod 异常崩溃、节点宕机、任务执行失败,Job 会自动重建 / 重启 Pod 重试任务; |
| 3 | 当所有指定任务全部执行成功后,Job 标记为完成状态,不再新建 Pod; |
| 4 | 默认情况下,执行完成 / 失败的 Pod 会保留在集群中,方便查看日志、排查问题。 |
1.2、job有啥用
| job的核心作用 | 说明 |
|---|---|
| 保障一次性任务可靠执行 | 天然内置重试机制,规避节点故障、程序闪退导致的任务中断,保证任务不丢失; |
| 统一调度与资源管控 | 继承 K8s 完整能力(资源配额、节点亲和、污点容忍、网络 / 存储挂载等),和集群业务统一管理; |
| 支持并行批处理 | 通过调整并发数,实现大批量任务并行执行,提升处理效率; |
| 任务状态可追溯 | 完成 / 失败的 Pod 默认保留,日志、运行现场可留存,便于问题排查; |
| 作为定时任务基础 | K8s 的 CronJob(定时任务)底层就是定时创建 Job,是集群标准定时批处理方案。 |
1.3、job的适用与不适用场景
✅Job主打短生命周期、一次性、离线、批处理类任务,在生产中最常用的场景如下表:
| ✅job的典型适用场景 | 说明 |
|---|---|
| 数据批处理 & ETL 离线任务 | 日志清洗、数据同步、数据库全量备份 / 恢复、大数据计算、文件批量转换、报表离线统计等。 > 例:凌晨批量同步业务数据、每日日志归档。 |
| 集群临时运维操作 | 集群初始化、数据库建库 / 初始化脚本、批量修改配置、批量清理临时文件、节点巡检脚本执行等。 > 例:新环境上线前执行一次性初始化脚本。 |
| 短时计算 / 测试任务 | 短时压力测试、离线模型推理、批量校验数据、临时脚本运行等(执行时长从几秒到几小时都可)。 |
| 定时任务(配合 CronJob) | 这是生产高频用法:基于 Cron 表达式定时触发 Job,实现周期性任务。 > 例:每天 0 点数据库备份、每周一生成业务报表、每小时清理垃圾文件。 |
| 批量异步任务 | 拆分大量独立子任务,通过 Job 并行执行,比如批量推送消息、批量处理订单数据等。 |
| ❌job绝对不适用场景 | 说明 |
|---|---|
| 常驻业务服务 | Web 服务、API 接口、网关、消息队列等需要 7×24 运行的服务(用 Deployment/StatefulSet); |
| 长周期不间断任务 | 持续数天的超长时间任务(节点重启、网络波动会频繁触发重试,易造成重复执行); |
| 复杂多步骤流水线 | 串行 / 分支 / 依赖的多阶段任务(原生 Job 无编排能力,建议用 Argo Workflows、Tekton); |
| 需要断点续跑的任务 | 大文件分片上传、超大计算任务(Job 失败默认从头重试,不支持断点); |
| 需要灰度 / 滚动更新的业务 | Job 是一次性任务,没有版本迭代、灰度发布设计。 |
1.4、job的优缺点
| ✅job的优点 | 说明 |
|---|---|
| 可靠性高,开箱即用重试 | 原生支持失败重试、最大重试次数限制,无需自己开发重试逻辑,解决裸跑 Pod 任务中断丢失的问题。 |
| 轻量简单,学习成本低 | 配置简洁,只聚焦 "任务执行" 本身,没有常驻服务的滚动更新、探针、扩缩容等复杂逻辑。 |
| 灵活支持并行批处理 | 通过 parallelism 和 completions 组合,轻松实现串行、分批并行、全并行三种任务模式,适配不同批量场景。 |
| 集群生态统一 | 完整支持 K8s 资源限制、存储、网络、权限、调度策略,和集群其他组件无缝配合。 |
| 状态可审计、可排查 | 失败 / 完成的 Pod 默认保留,可随时查看容器日志、运行状态,定位任务失败原因。 |
| 定时能力扩展强 | 结合 CronJob 即可实现标准定时任务,是 K8s 官方推荐的定时方案,替代传统 Crontab。 |
| ❌job的缺点 | 说明 |
|---|---|
| Pod 不会自动清理,资源易堆积 | Job 完成后 Pod 默认永久保留,大量历史 Job 会堆积无用 Pod,占用集群 etcd 和节点资源。 > 解决方案:开启 spec.ttlSecondsAfterFinished,任务完成后自动删除 Pod。 |
| 原生不支持断点续跑 | 任务一旦中断 / 失败,只能整体重新执行,无法从失败位置继续,对超大任务不友好。 |
| 复杂任务编排能力弱 | 无法原生实现「任务 A 执行完再跑任务 B」「分支判断」「循环执行」等流水线逻辑,复杂作业必须依赖第三方工作流组件。 |
| 重试粒度粗 | 仅支持 Pod 级别整体重试,不能针对任务内部局部异常单独重试,小问题也会重跑整个任务。 |
| 运行中无法动态调整并发 | Job 启动后,想修改并行数 parallelism 需要手动编辑 Job 配置,原生不支持运行时动态弹性扩缩。 |
| 长时间任务稳定性差 | 若任务运行时间极长,节点重启、网络抖动都会触发重试,极易导致任务重复执行(比如重复备份、重复写入数据)。 |
| 无自愈之外的高级运维能力 | 没有健康探针、优雅终止、流量管理等常驻服务的能力,不适合对外提供服务。 |
二、job示例解析
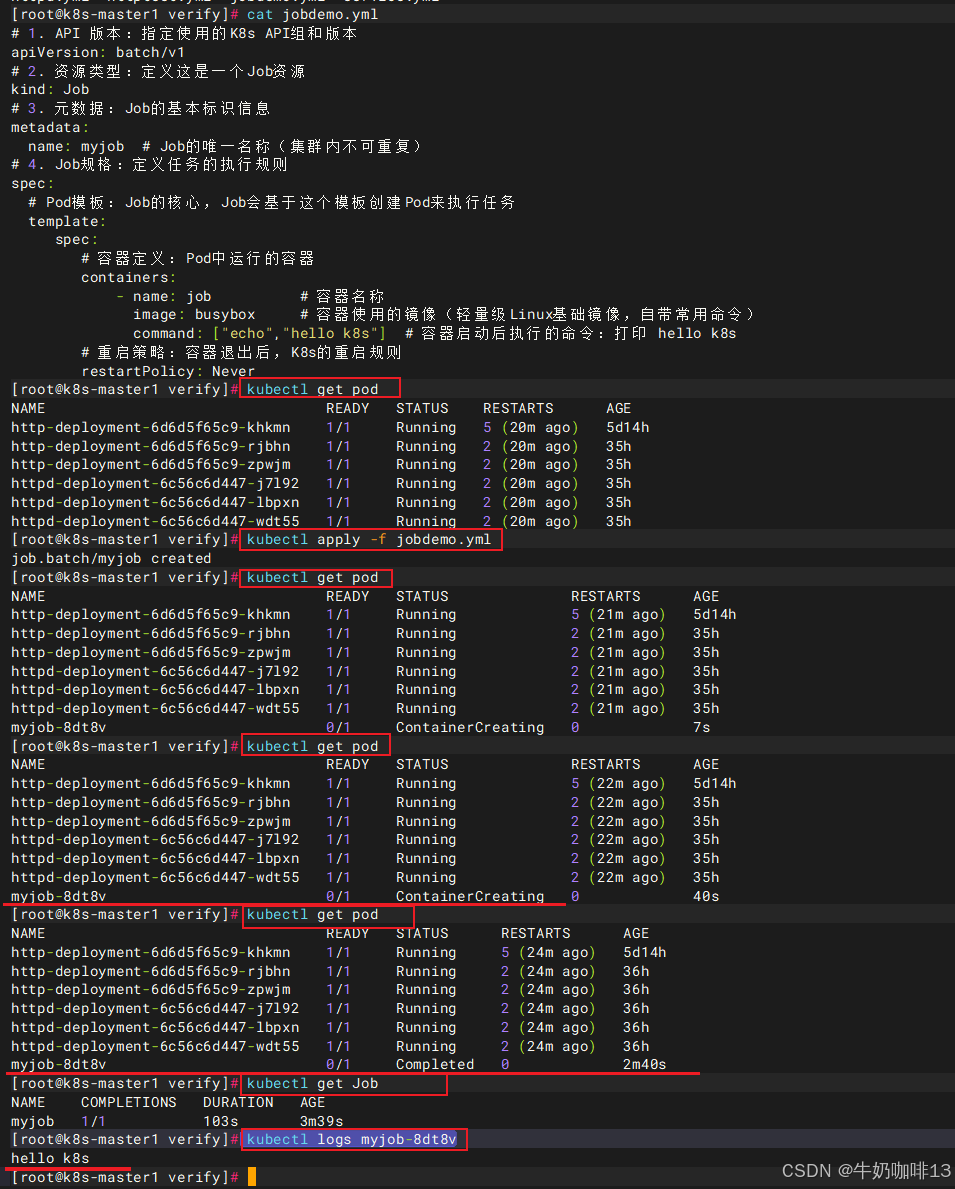
2.1、job示例
bash
#job示例
#1-创建job示例
cat >jobdemo.yml<<EOF
# 1. API 版本:指定使用的K8s API组和版本
apiVersion: batch/v1
# 2. 资源类型:定义这是一个Job资源
kind: Job
# 3. 元数据:Job的基本标识信息
metadata:
name: myjob # Job的唯一名称(集群内不可重复)
# 4. Job规格:定义任务的执行规则
spec:
# Pod模板:Job的核心,Job会基于这个模板创建Pod来执行任务
template:
spec:
# 容器定义:Pod中运行的容器
containers:
- name: job # 容器名称
image: library/busybox # 容器使用的镜像(轻量级Linux基础镜像,自带常用命令)
command: ["echo","hello k8s"] # 容器启动后执行的命令:打印 hello k8s
# 重启策略:容器退出后,K8s的重启规则
restartPolicy: Never
EOF
#2-创建Job资源
kubectl apply -f jobdemo.yml
#3-查看当前所有pod状态
kubectl get pod
#4-查看当前所有的Job状态
kubectl get Job
#5-查看指定Job的日志
kubectl logs myjob-8dt8v
#6-删除指定Job资源
kubectl delete -f jobdemo.yml| deployment资源文件内容 | 说明 |
|---|---|
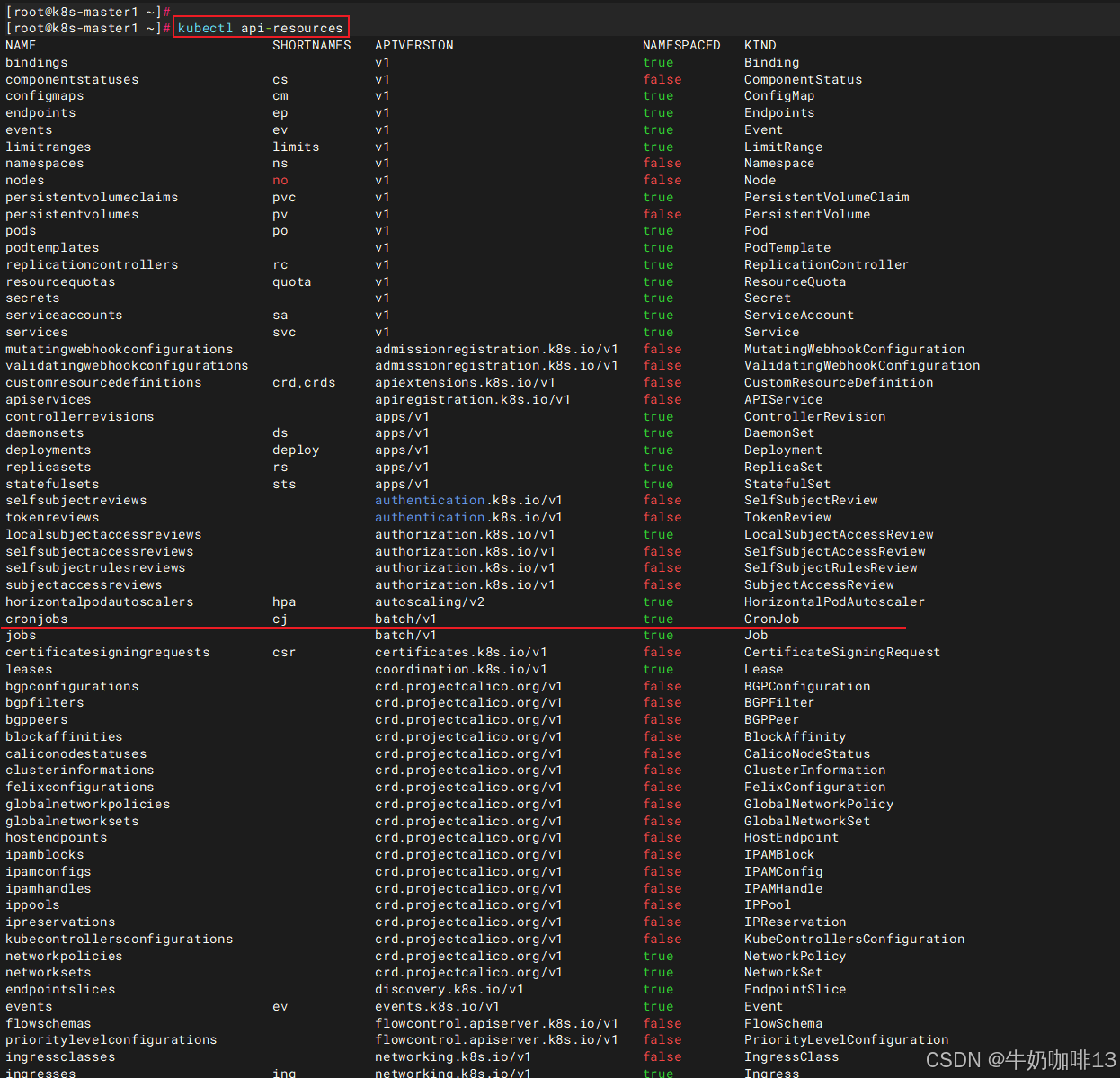
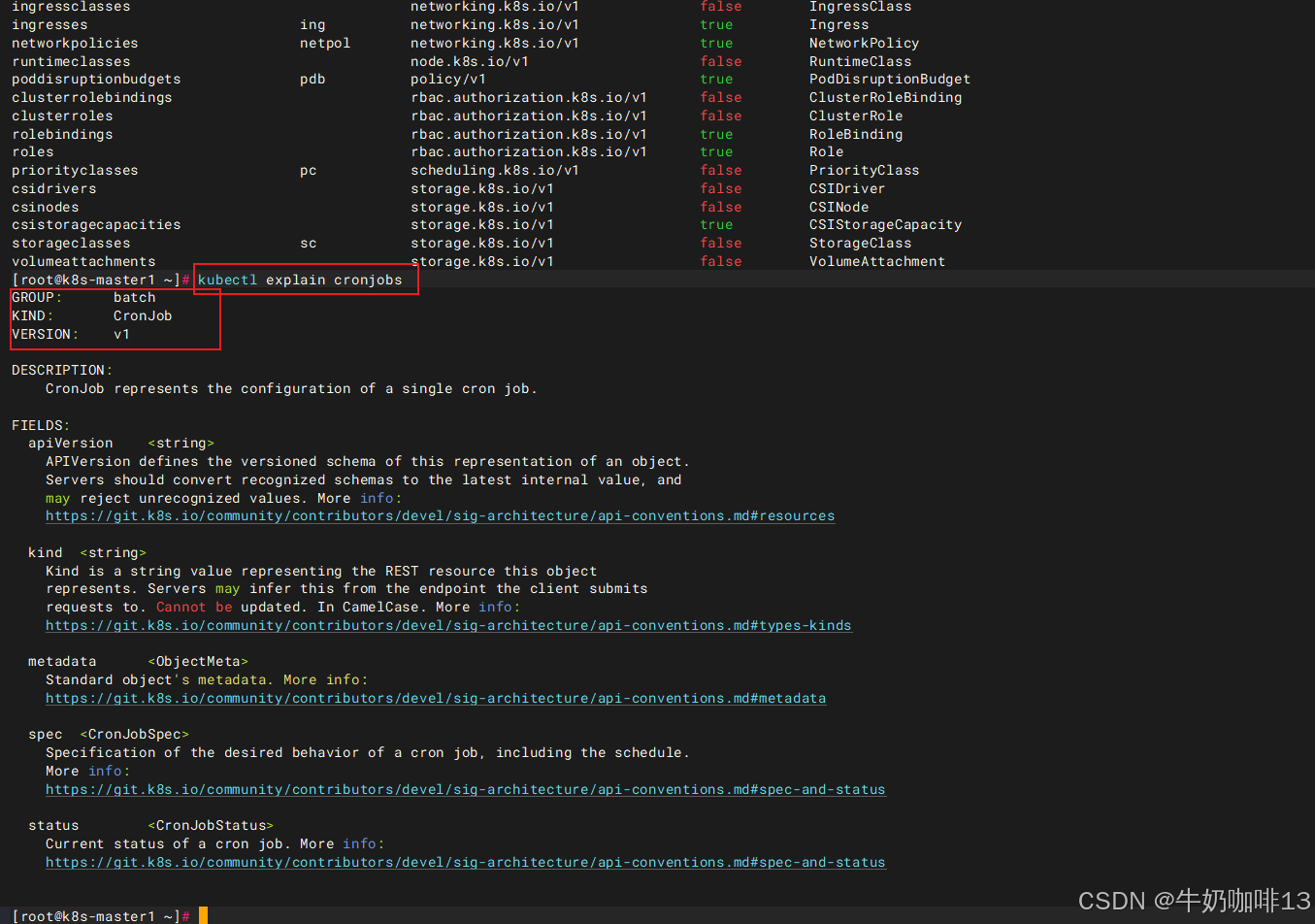
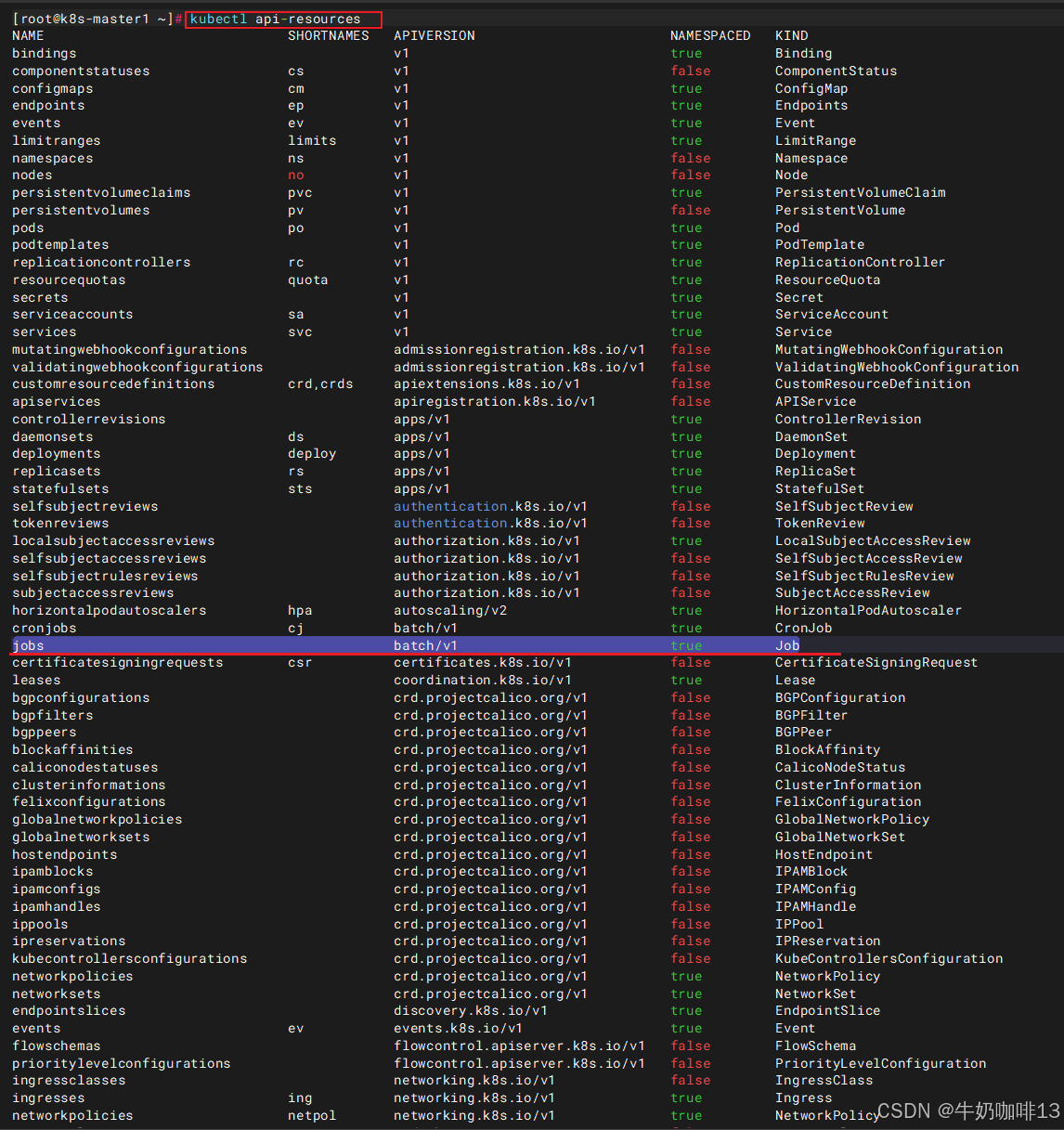
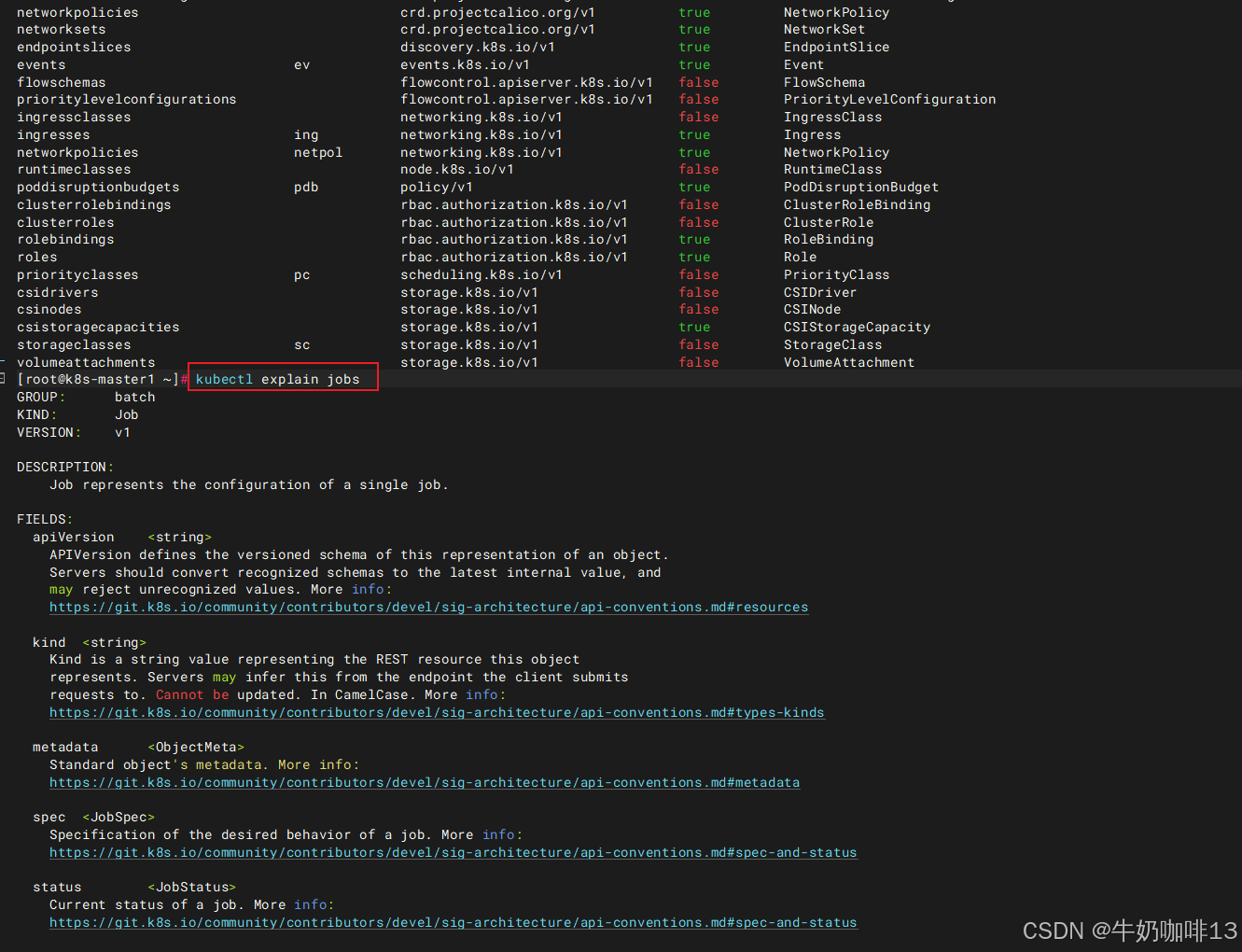
| apiVersion | 当前配置格式的版本(先执行kubectl api-resources找到所有的资源,再执行命令 kubectl explain jobs即可获取到版本和类型信息) |
| kind | 要创建的资源类型,这里是Job。 |
| metadata | 该资源的元数据,name是必需的元数据项,后面名字任意起一个即可。 |
| 第一个spec | 第一个spec部分是该Job的规格说明 |
| template | 定义Pod的模板,这是配置文件的重要部分。 |
| 第二个spec | 第二个spec描述Pod的规格,此部分定义Pod中每一个容器的属性,name和image是必需的。 注意:最后name前面需要加个中杠,是因为container后面是一个列表。 |
| restartPolicy | 用来指定什么情况下需要重启容器。对于Job,只能设置为Never或OnFailure 对于其它的controller(比如 Deployment)可以设置为Always。 1. Never表示不论状态为何, kubelet都不重启该容器; 2. OnFailure表示容器终止运行,且退出码不为0时重启; 3. Always表示容器失效时,kubelet自动重启该容器; |

2.2、job失败分析
上面展示了job执行成功的情况,若执行失败会怎样呢?(模拟错误:修改 jobdemo.yml,故意引入一个错误【即将 command: "echo","hello k8s"修改为:command: "echocoffeemilk","hello k8s"):
bash
#手动模拟一个故障job
#1-修改 jobdemo.yml,故意引入一个错误【即将 command: ["echo","hello k8s"]修改为:command: ["echocoffeemilk","hello k8s"]
#2-创建job资源
kubectl apply -f jobdemo.yml
#3-查看当前所有Pod状态
kubectl get pod
#4-查看指定pod的详细信息(可通过该命令了解到具体的执行流程内容与报错信息)
kubectl describe pod myjob-ckn4d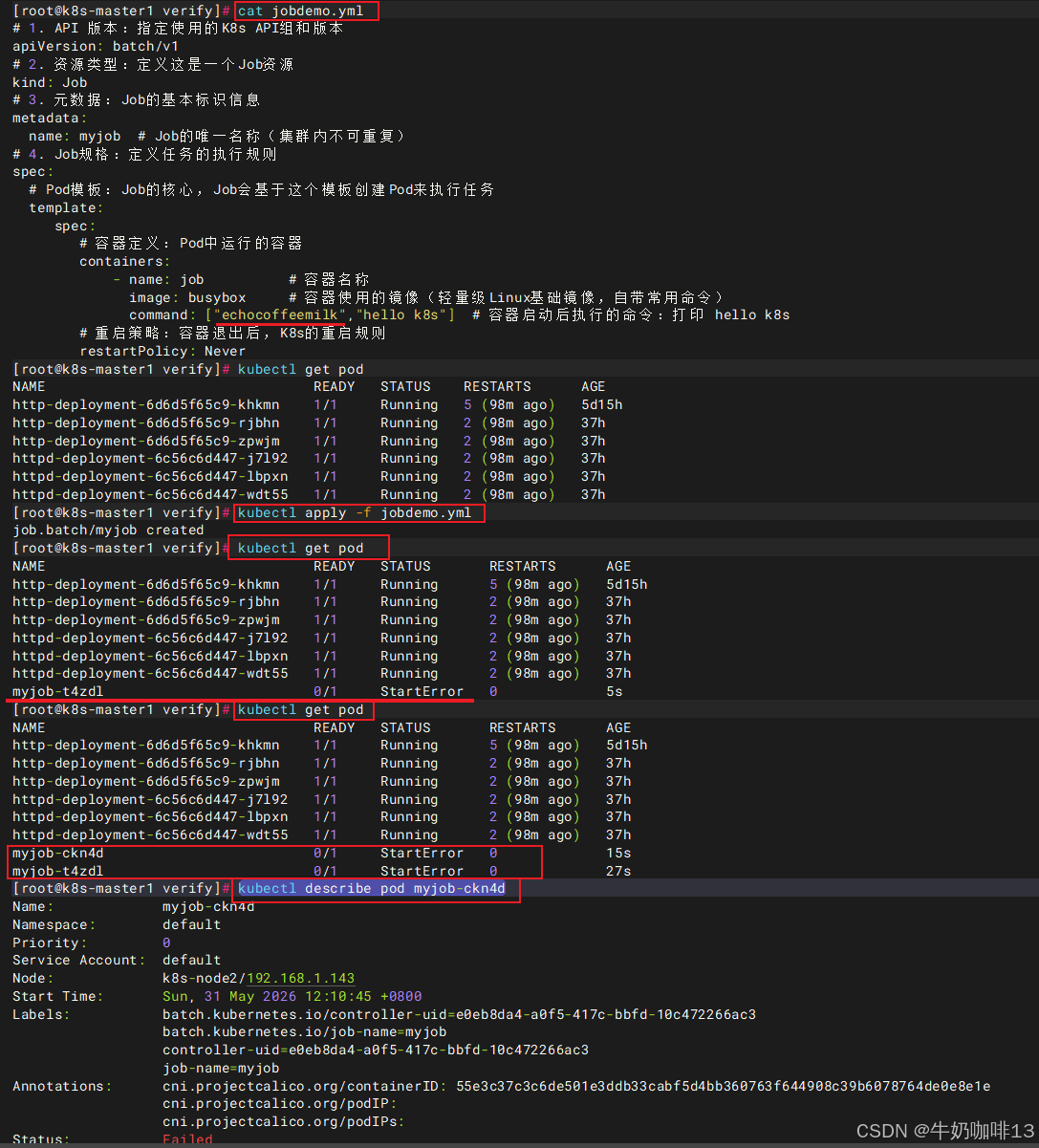
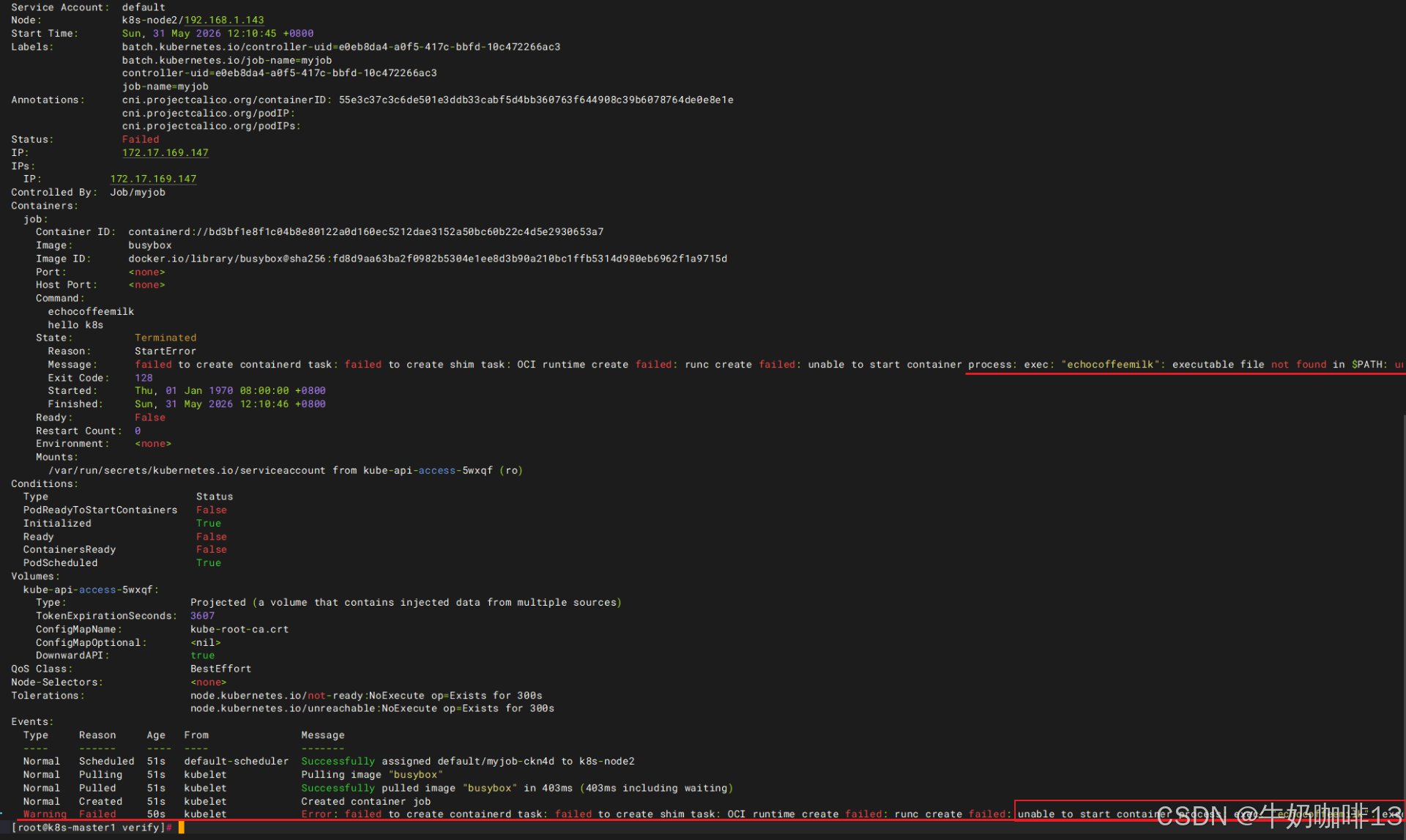
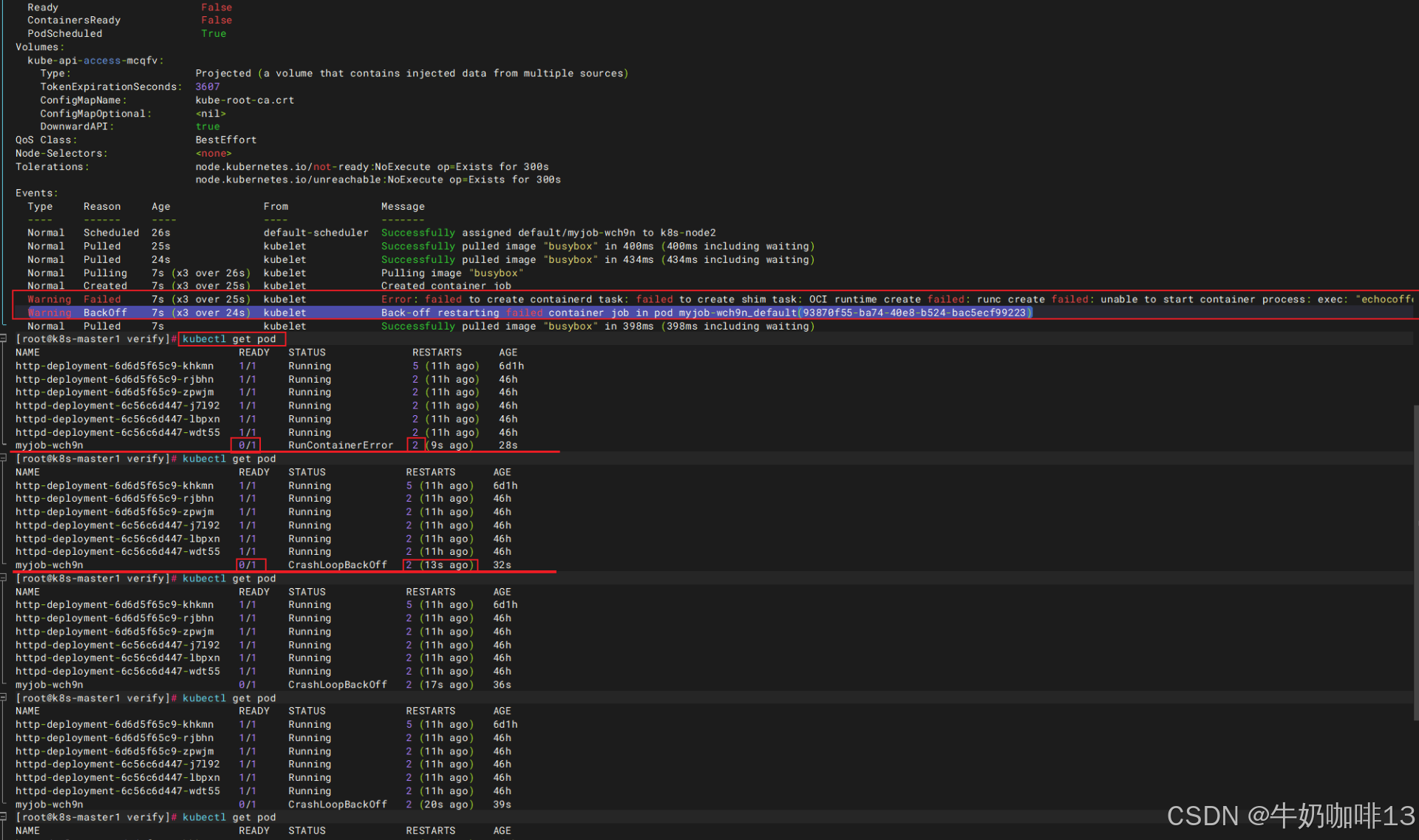
通过如上截图可以了解到是由于echocoffeemilk命令不存在,导致的报错。
为什么kubectl get pod会看到这么多个失败的 Pod?如下图所示:
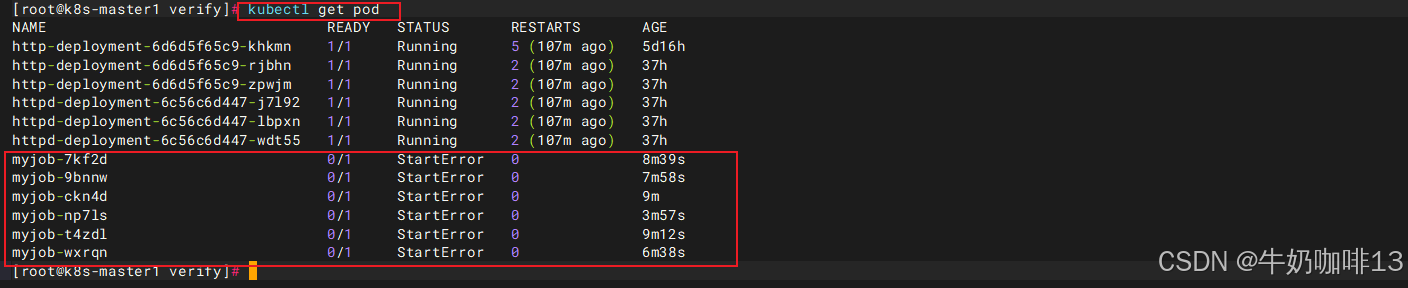
| kubectl get pod会看到这么多个失败的 Pod看到很多原因解析 | 说明 |
|---|---|
restartPolicy: Never 的作用(控制单个 Pod 内部是否重启容器) |
这个策略只作用于单个 Pod: 当 Pod 内的容器启动失败 / 异常退出时,kubelet 不会在当前这个 Pod 里重启容器 ,直接把整个 Pod 标记为「失败 Pod」,所以截图里所有 myjob Pod 的RESTARTS列都是 0。 |
| Job 控制器的重试逻辑(控制新建 Pod) | Job 控制器的目标:生成 spec.completions(默认值 = 1)个正常执行完成的 Pod 才算任务结束。 * 当前所有新建的 Pod 全部启动失败(StartError),成功完成的 Pod 数量 = 0,没达到目标值 1; * 只要成功 Pod 数量不足,Job 控制器就会不断创建全新的 Pod 重新尝试; * Job 默认配置 backoffLimit: 6:最多重试创建 6 个失败 Pod,到达上限后 Job 停止新建 Pod。 截图里正好 6 个myjob-xxx失败 Pod,就是触发了默认 6 次重试上限。 为了终止这个行为,只能删除此job。 |
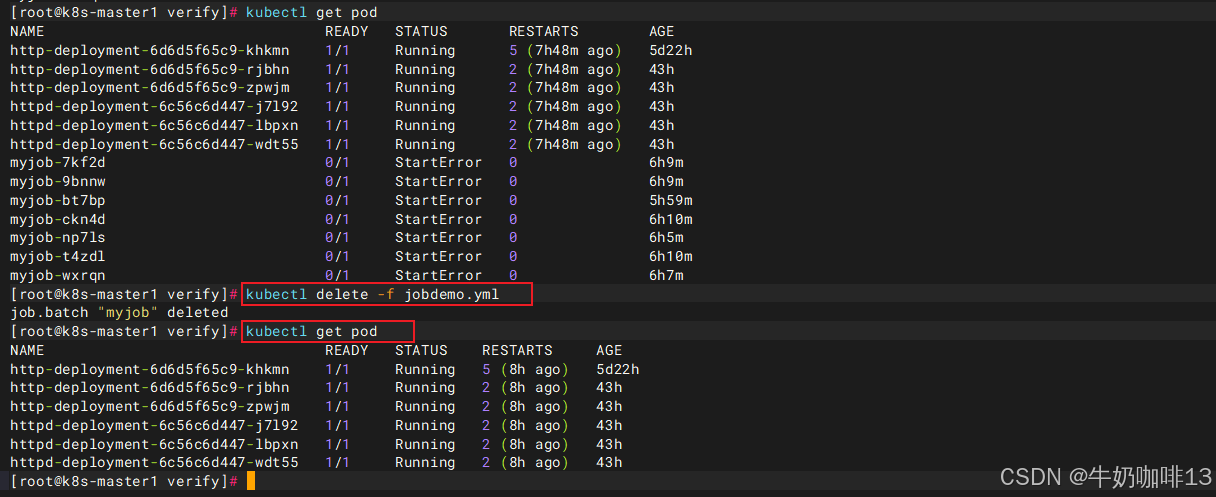
bash
#优化 Job 配置(避免大量失败 Pod)
cat > jobdemo.yml <<EOF
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
backoffLimit: 2 # 最多只重试2次,只会产生3个Pod(初始1+重试2)
template:
spec:
containers:
- name: job
image: busybox
command: ["echocoffeemilk","hello k8s"]
restartPolicy: Never
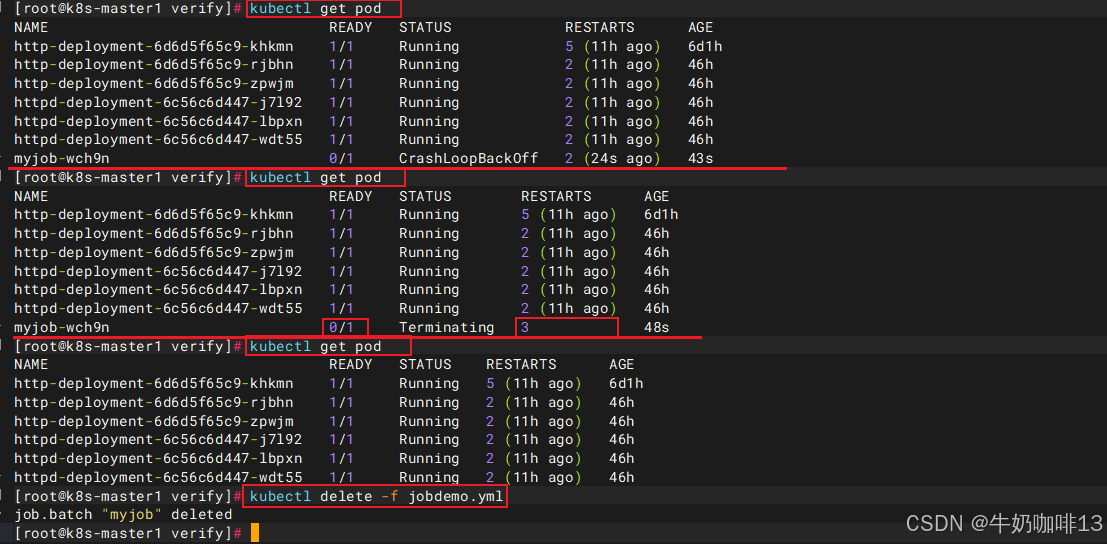
EOF如果将restartPolicy 设置为OnFailure会怎么样(根据OnFailure的含义,当pod失败后,会进行重启,因此,可以看到pod只有一个,但是pod的RESTARTS会不断增加,这说明了容器失败后会自动重启)。
bash
#将restartPolicy 设置为OnFailure
cat >jobdemo.yml <<EOF
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
backoffLimit: 3 # 最多3次失败重试(默认6)
template:
spec:
containers:
- name: job
image: busybox
command: ["echocoffeemilk","hello k8s"] #(模拟失败)
restartPolicy: OnFailure # 关键修改
EOF
#创建资源
kubectl apply -f jobdemo.yml
#查看所有资源的状态
kubectl get pod
#最后一定要删除资源
kubectl delete -f jobdemo.yml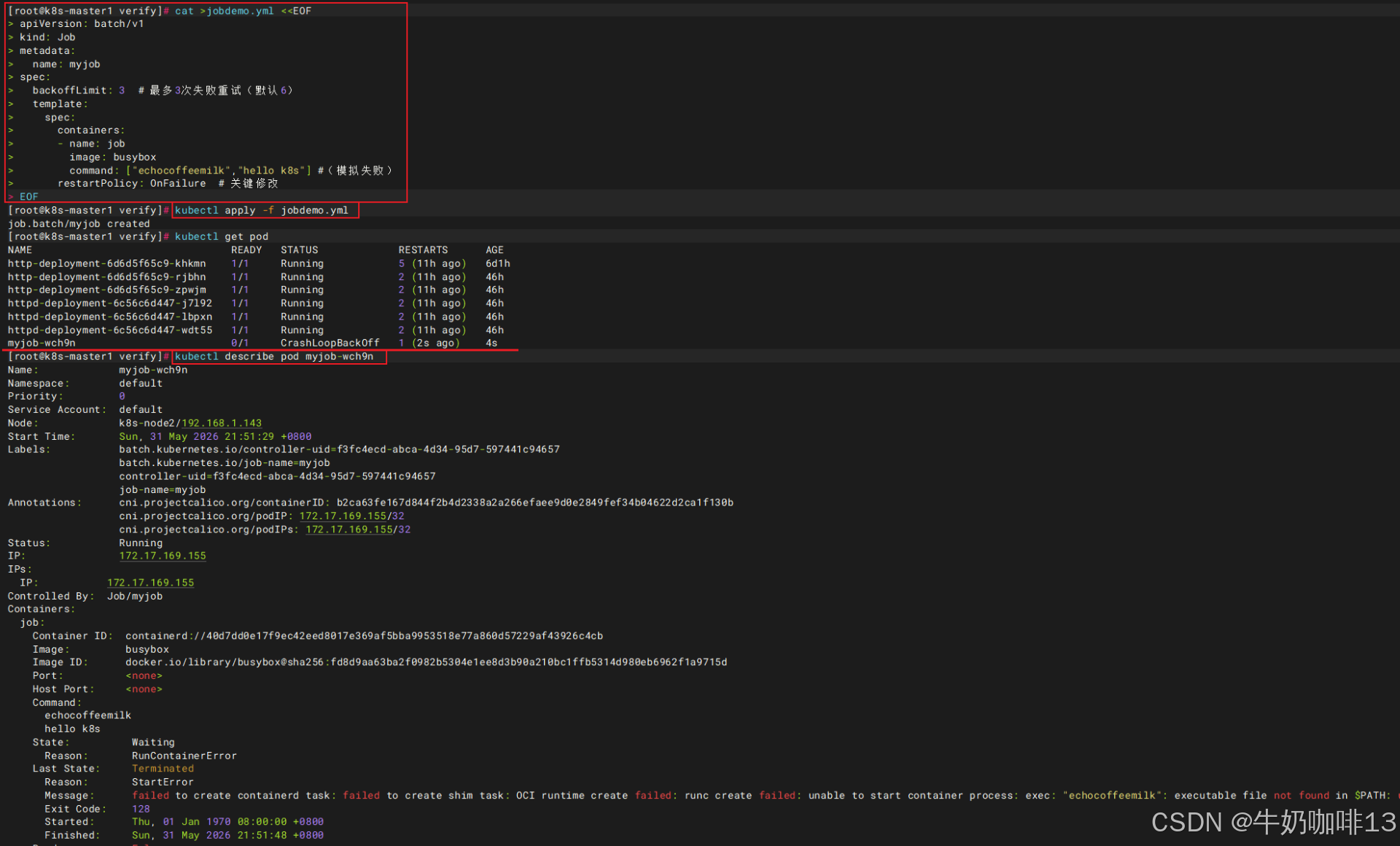
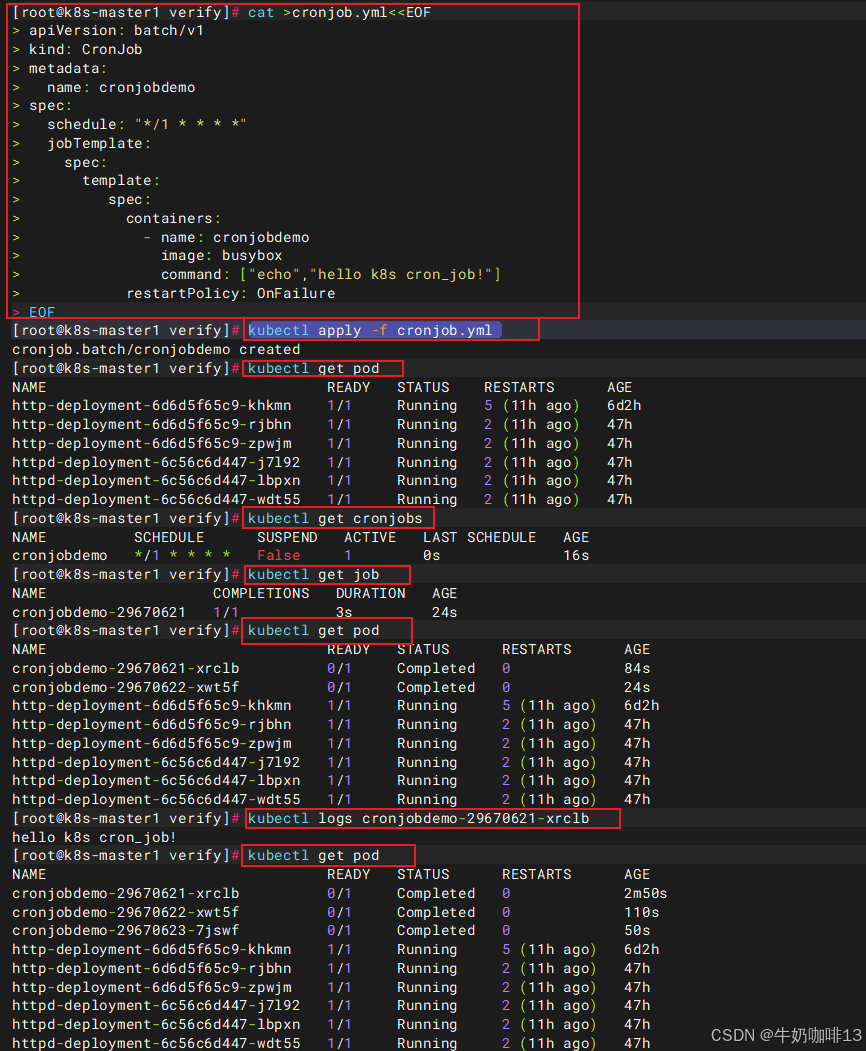
2.3、定时执行job
Linux中有crontab程序定时执行任务,k8s的CronJob也提供了类似的功能,可以定时执行Job。
bash
#定时执行job示例
cat >cronjob.yml<<EOF
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjobdemo
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: cronjobdemo
image: busybox
command: ["echo","hello k8s cron_job!"]
restartPolicy: OnFailure
EOF
#创建资源
kubectl apply -f cronjob.yml
#查看所有cronjobs配置内容
kubectl get cronjobs
#查看所有真正执行定时任务的状态
kubectl get job
#查看所有pod状态
kubectl get pod
#查看指定的pod定时任务日志
kubectl logs cronjobdemo-29670621-xrclb
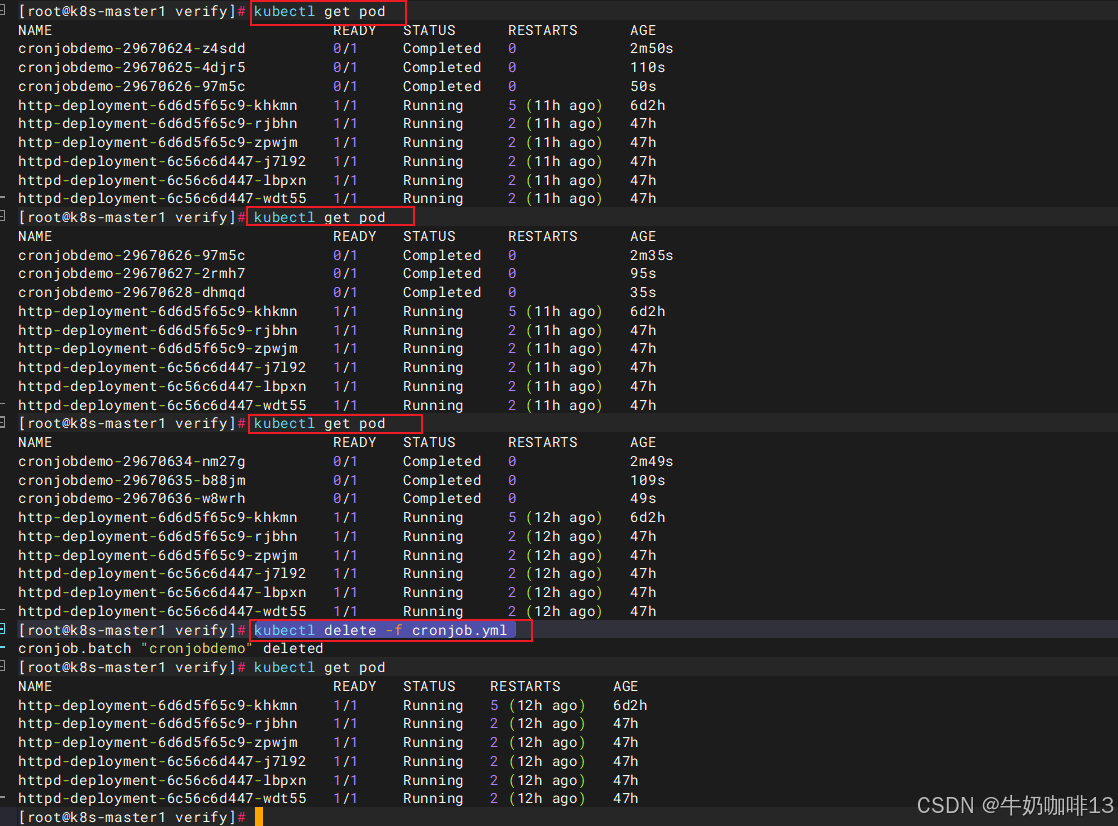
#删除指定资源
kubectl delete -f cronjob.yml