JMeter启动模式
JMeter 的 bin 目录下提供了多个启动脚本,它们的功能和适用场景有明显区别,主要可以分为 GUI 模式 、CLI 模式(命令行非 GUI) 、分布式/服务器模式 和 远程控制 四类。
一、GUI 模式相关(编写、调试脚本)
| 脚本 | 关键区别 | 使用场景 |
|---|---|---|
jmeter.bat |
启动 带 Windows 命令行窗口 的 GUI。控制台会同步输出日志,关闭窗口则 GUI 一并退出。 | 在编写、调试测试计划时使用,方便直接看到后台日志和异常信息。 |
jmeterw.cmd |
启动 不带命令行窗口 的 GUI,日志只会写入 jmeter.log,关闭窗口不会因误关控制台而中断 JMeter。 |
当你只想打开 JMeter 界面、不希望被黑色控制台窗口干扰时使用。 |
jmeter-t.cmd |
拖放一个 .jmx 文件到该脚本上,会用 GUI 模式直接打开这个测试计划,免去手动 File → Open。 | 快速加载已有测试脚本进行查看或编辑。 |
二、CLI 模式相关(正式执行压力测试)
| 脚本 | 关键区别 | 使用场景 |
|---|---|---|
jmeter-n.cmd |
非 GUI 命令行模式 ,拖放 .jmx 文件后以 CLI 模式执行,可附加 -l、-e、-o 等参数生成报告。 |
所有正式压测都必须使用此模式,资源消耗低、无界面渲染开销,结果更准确。 |
jmeter-n-r.cmd |
也是 CLI 模式,但会 远程执行(-r 参数),将测试分发到已配置的远程 JMeter 服务器上。 | 需要多台机器产生并发负载的分布式压测场景。需提前在各负载机上启动 jmeter-server。 |
三、分布式 / 服务器组件
| 脚本 | 关键区别 | 使用场景 |
|---|---|---|
jmeter-server.bat |
启动 JMeter 服务器模式,等待控制端(master)发来的测试任务并在本地执行。 | 分布式压测中 所有负载生成机(slave) 上必须运行此脚本,使它们能被主控机调用。 |
mirror-server.cmd |
启动 镜像服务器,它会将收到的 HTTP 请求原样返回。用于验证 JMeter 发出的请求内容是否正确。 | 调试 HTTP 取样器、检查请求头和 body 是否按预期构造,不用于真实压力测试。 |
四、远程控制(停止正在运行的测试)
| 脚本 | 关键区别 | 使用场景 |
|---|---|---|
shutdown.cmd |
向运行中的 CLI 实例发送 优雅停止 信号,会等待当前正在执行的采样器完成后再结束线程。 | 需要让压测"体面"地收尾,收集完进行中的请求数据,不丢失最后的统计。 |
stoptest.cmd |
向运行中的 CLI 实例发送 立即停止 信号,所有线程立刻终止,不等待当前请求完成。 | 测试发现问题需要紧急终止,或不想等待正在执行的慢请求时使用。 |
一句话总结:
- 编辑调试用
jmeter.bat或jmeter-t.cmd; - 正式压测一律用
jmeter-n.cmd(单机)或jmeter-n-r.cmd+jmeter-server.bat(分布式); - 调试 HTTP 请求可用
mirror-server.cmd; - 远程优雅停止用
shutdown.cmd,紧急停止用stoptest.cmd。
JMeter 的测试原理基于多线程并发模拟用户请求,核心工作流程围绕"创建测试计划 → 配置虚拟用户行为 → 执行并发负载 → 收集与呈现结果"展开。
一、测试原理
1. 线程模型:虚拟用户
- JMeter 使用 线程组 来模拟并发用户,每个线程即一个虚拟用户。
- 线程组内可设置:线程数(并发量)、Ramp-Up 时间(启动间隔)、循环次数/持续时间。
- 所有线程彼此独立,按测试计划中的采样器顺序执行请求,完全隔离,不共享状态(除非使用了变量/属性跨线程传递)。
2. 核心组件协作
- 采样器:负责发送具体协议请求(HTTP、JDBC、FTP、JMS 等),记录响应时间、状态、数据大小等。
- 逻辑控制器:控制请求执行顺序(循环、条件、事务等),定义用户行为流。
- 断言:对响应内容做校验(文本、状态码、JSON 路径等),用于功能正确性判定,不影响负载生成。
- 前置/后置处理器:在请求前后做数据处理,如提取变量(正则、JSON 提取器)、生成参数。
- 定时器:模拟真实用户思考时间或固定请求间隔,控制吞吐节奏。
- 配置元件:如 HTTP 请求默认值、CSV 数据源(参数化),供采样器复用。
- 监听器:收集和展示测试数据(聚合报告、图形),可在运行时或结束后分析。
3. 执行引擎
- JMeter 引擎本身不渲染 GUI 响应(如浏览器不会执行 JavaScript),而是 纯协议层负载生成器。
- 它直接构造原始请求并发送,接收响应字节,测量网络往返时间,不解析页面中的静态资源 除非手动添加对应采样器。
- 压力机资源消耗主要来自网络 I/O 和线程调度,因此 CLI 模式(
jmeter-n.cmd)能最大化压测能力。
4. 分布式原理
- 支持 Master-Slave 架构:一台控制机分发测试脚本,多台负载机同时执行。
- Slave 上运行
jmeter-server,接收 Master 发送的测试计划片段,按独立线程组生成负载并回传结果给 Master 汇总。 - 通信通过 RMI(Java 远程方法调用)完成,可突破单机线程数上限。
二、测试流程
一个完整的 JMeter 压测流程分为 7 个关键步骤:
1. 需求分析与场景设计
明确目标:并发数、吞吐量(TPS/QPS)、响应时间要求、测试时长、协议类型。
确定业务场景:哪些接口?比例如何?是否需要参数化、依赖关系处理等。
2. 创建测试计划
打开 JMeter GUI,整个 .jmx 文件就是一个测试计划。
→ 右键测试计划 添加 → Threads (Users) → 线程组。
3. 配置线程组(并发策略)
设置:
- 线程数:模拟的用户数量
- Ramp-Up 期:所有线程的启动耗时(避免瞬间冲击)
- 循环次数 / 持续时间:控制压测时长,推荐使用"调度器------持续时间"
4. 添加配置元件与采样器
- 配置元件:HTTP 请求默认值(协议、服务器 IP、端口),CSV 数据文件(登录多账号)。
- 采样器:HTTP 请求、JDBC 请求等,填写路径、方法、参数、消息体。
- 后置处理器 (关联):提取
token、sessionID供后续请求使用。 - 定时器:如高斯随机定时器,模拟用户阅读/填写等待。
5. 添加断言与监听器(验证与分析)
- 断言:返回码 200、包含特定文字,判断业务是否正确。
- 监听器 :常用 聚合报告 、查看结果树 (调试时)、后端监听器(实时推送到 InfluxDB + Grafana)。
⚠️ 调试阶段可保留监听器,正式压测时务必禁用或移除所有监听器(尤其"查看结果树"),否则极大消耗负载机资源并扭曲结果。
6. 执行测试
- 调试:用少量线程 + 查看结果树,确认请求正确、断言通过。
- 正式压测 :必须使用 CLI 模式执行(
jmeter-n.cmd -t 脚本.jmx -l 结果.jtl -e -o 报告目录)。
常用命令参数:-n:非 GUI 模式-t:指定测试计划文件-l:记录结果到 JTL 文件-e -o:生成 HTML 报告
7. 结果分析与报告
- 聚合报告中关注:Average(平均响应时间)、Median、90/95/99 百分位、Error%、Throughput。
- HTML 报告会展示图表:响应时间分布、每秒事务数、活跃线程数等。
- 结合服务器资源监控(CPU、内存、IO、网络)定位瓶颈。
流程图简览
需求分析 → 编写脚本(GUI调试) → CLI执行 → 监控与结果收集 → 分析调优
↑ ↓
└──────── 发现问题后重新修改脚本 ←──────┘核心原则 :GUI 仅用于开发调试,所有正式负载测试务必使用 CLI 模式,才能保证压测结果准确、可复现。
实践
一、HTTP 协议层面的最小请求
-
GET 请求
- 请求行:
GET / HTTP/1.1 - 唯一必需的请求头:
Host - 没有请求体。
- 请求行:
-
POST 请求
- 请求行:
POST / HTTP/1.1 - 必需请求头:
HostX-Csrftoken(值=csrf_token)Cookie(含session、csrf_token)
- 特殊的请求头:(部份产品要求)
Referer(且值必须是完整的https://...)User-Agent
- 一般框架自动处理,无需主动添加:
- 如果有请求体,必须加
Content-Length(值为字节数);若无请求体,可带Content-Length: 0。 - 理论上可没有
Content-Type,但服务器通常需要它来解析请求体,所以实际中它也是必需的。
- 如果有请求体,必须加
- 请求行:
二、参数化
1、用户定义变量 + ForEach 控制器
适用场景:数据量较少、逻辑简单、无需外部文件的小规模变量列表遍历,例如固定几个 ID 轮流使用。
配置步骤与关键点:
-
定义变量列表
- 位置 :测试计划 → 添加 → 配置元件 →
用户定义的变量(User Defined Variables)。 - 编辑 :手动添加一系列命名规律、后缀连续的变量,如:
id_1= 1001id_2= 1002id_3= 1003
- 注意 :变量名前缀和后缀数字必须连续,且需额外定义一个变量(如
id_count= 3)记录总个数,供 ForEach 控制器使用。
- 位置 :测试计划 → 添加 → 配置元件 →
-
使用 ForEach 控制器遍历
- 位置 :线程组 → 添加 → 逻辑控制器 →
ForEach 控制器。 - 编辑参数 :
输入变量前缀:填id(与定义时的前缀一致,不含下划线)。开始索引:1(从 id_1 开始)。结束索引:id_count对应变量的值,此处可填变量${id_count}(由用户定义变量中设置)。输出变量名称:currentId,后续请求通过${currentId}引用当前循环到的值。
- 结构:将需要参数化的请求放入 ForEach 控制器内。
- 注意:ForEach 会在一次迭代内顺序走完所有变量,要让它与线程循环配合,可在外层加线程组循环次数,或在 ForEach 内再用循环控制器控制迭代。
- 位置 :线程组 → 添加 → 逻辑控制器 →
2、CSV 数据文件设置(CSV Data Set Config)
适用场景:参数数据量大、需用 Excel/文本文件管理、不同用户使用完全不同数据的并发场景(最常用)。
配置步骤与关键点:
-
准备 CSV 文件
-
文件内容:第一行为变量名可省略(通过配置指定变量名则不读取第一行),每行一条数据,列用分隔符(默认逗号)分开。
-
示例:
users.csvuser1,pass1 user2,pass2 user3,pass3 -
编码建议 UTF-8,文件放于 JMeter 启动目录或测试计划同目录。
-
-
添加 CSV Data Set Config
- 位置 :线程组或具体请求下 → 添加 → 配置元件 →
CSV Data Set Config。 - 关键参数编辑 :
Filename:文件路径(相对路径以 JMeter 启动目录为基准)。File Encoding:UTF-8(避免乱码)。Variable Names:逗号分隔的变量名,如username,password(必须与文件列顺序一致)。忽略首行:如果文件第一行是标题则设为True,否则False。分隔符:默认为逗号,若文件是 Tab 分隔则填入\t。是否允许带引号:数据包含引号时按需设置True。- 并发控制相关 :
线程共享模式:所有线程:所有虚拟用户按文件顺序共同消费数据,每个用户取一条新记录,适合"数据不重复"场景。当前线程组:每个线程组独立读取,组内线程共享。当前线程:每个线程独自从头读取文件,数据可重复。
遇到文件结束符再次循环?(Recycle on EOF):True:读到文件尾后重新从头开始循环读取。False:读到文件尾后停止,此时遇到文件结束符停止线程?(Stop thread on EOF)生效。
遇到文件结束符停止线程?(Stop thread on EOF):True:文件结束且不循环时,停止当前线程。False:文件结束后变量值变为<EOF>或保持最后一行,需注意处理。
- 引用变量 :在请求参数中使用
${username}和${password}即可。
- 位置 :线程组或具体请求下 → 添加 → 配置元件 →
典型并发配置示例:
- 唯一数据、不重复、用完即止 :
共享模式= 所有线程,Recycle= False,Stop thread on EOF= True,数据量 > 并发用户数 × 循环次数。 - 数据可重复、压力持续 :
共享模式= 所有线程,Recycle= True,Stop thread on EOF= False。
总结:
- 少量固定数据、简单循环 → 用户定义变量 + ForEach 控制器。
- 大量、外部管理、真实用户模拟 → CSV Data Set Config。
三、依赖数据提取&使用
添加后置处理器,提取参数 存到变量中:
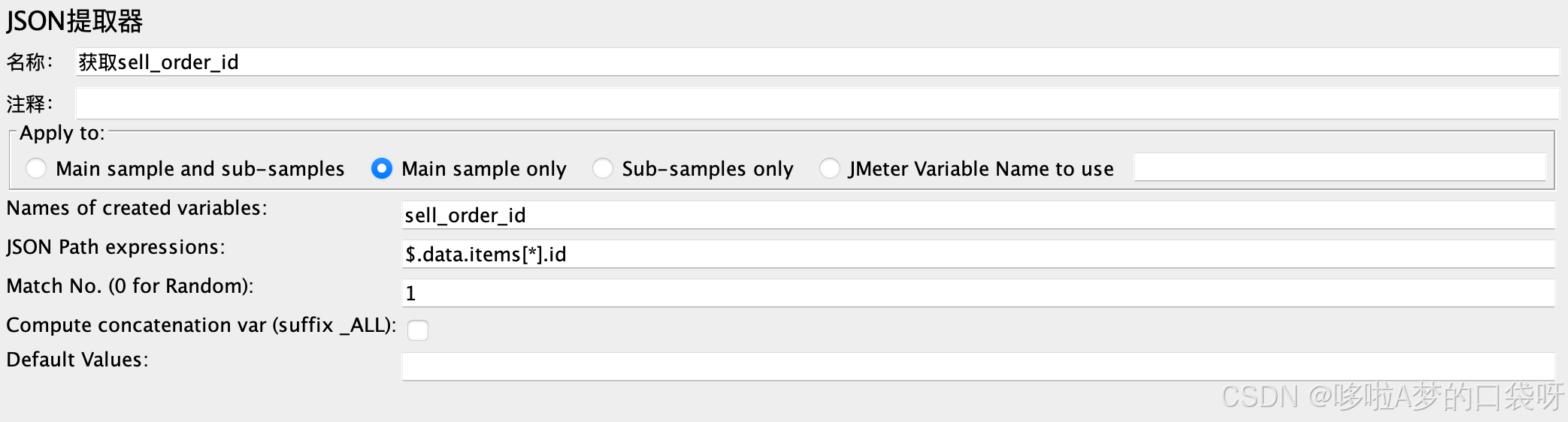
通过变量访问前置响应中的数据:${变量名称}
还可以添加IF控制器,比如:判断市场订单获取成功,才继续购买拉取收银台等后续接口的请求:${__groovy(vars.get("sell_order_id")!=null,)}
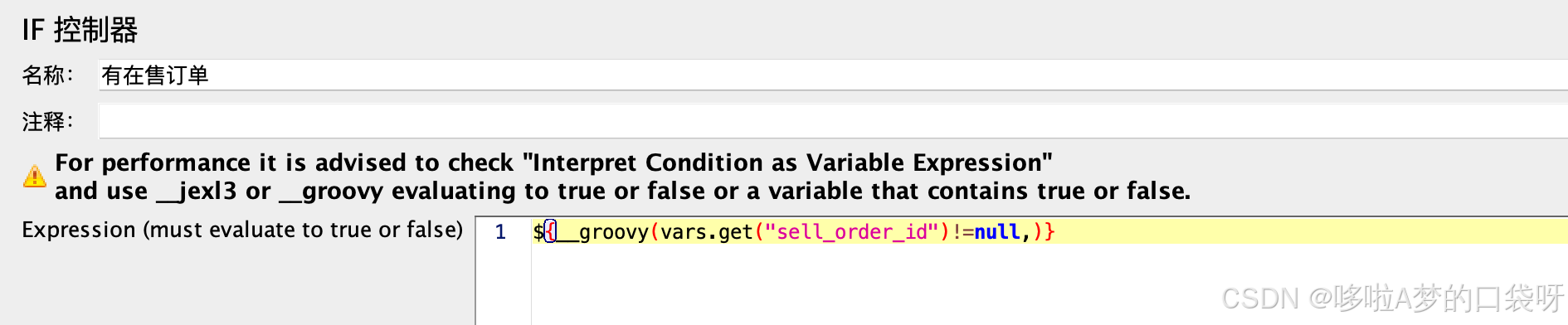
最终的结构如下:

四、修改响应参数
对提取出的值进行计算再使用,最推荐的方式是 JSR223 后置处理器/前置处理器(语言选 Groovy)。
-
在 JSON 提取器同级或之下添加
JSR223 PostProcessor- 右键取样器 → 添加 → 后置处理器 → JSR223 PostProcessor。
-
编辑参数
-
Language :选择
groovy。 -
Parameters:留空或传入需计算的变量名(非必须)。
-
Script :写入计算逻辑,并用
vars.put("新变量名", 计算结果)保存。groovy// 获取原始值 String raw = vars.get("raw_token") // 进行计算(例如 Base64 编码) String encoded = raw.bytes.encodeBase64().toString() // 存入新变量 vars.put("encoded_token", encoded)
-
-
在后续请求中引用
${encoded_token}即可。
五、测试活动与测试片段
测试片段
测试片段的关键决策点,在于你是否需要"重复执行同一段复杂逻辑"。
1. 需要多次复用的"原子业务块"
场景 :测试计划中有"领取优惠券 -> 下单 -> 支付"和"领取优惠券 -> 过期退款"两条流程。每个虚拟用户都要用自己的账号领取不同的优惠券。
- 不用片段:你得在两个线程组里,把领取优惠券的整套请求(查询可用券、领取、校验状态)各复制一份。一旦接口变更,你要改两处。
- 用测试片段 :把"领取优惠券"封装成片段,在两个线程组里用模块控制器调用。修改片段即全局生效,代码零重复。setUp 线程组做不到这一点,因为它只执行一次。
2. 需要封装"多步骤、多控制器、多断言"的黑盒组件
场景:一个"安全校验"流程,内部包含 3 个请求,并有多个 If 控制器判断异常,还有响应断言。
- 不用片段:把这一大堆元件到处复制,脚本臃肿难读。
- 用测试片段:这个复杂的逻辑块对外只暴露一个"模块名",调用方不用关心内部细节。setUp 线程组可以执行它,但无法让它在不同的执行分支里被"随地调用"。
3. 需要跨脚本/跨团队复用的独立物理文件
场景 :多个 .jmx 脚本都要用到同一个复杂的加密签名逻辑。
- 不用片段:你只能每次都在新脚本里重建一堆请求和脚本,或者复制粘贴。
- 用测试片段 :把加密逻辑存为
encrypt_fragment.jmx,其他脚本通过 Include 控制器 引用。实现团队级别的模块库。
测试活动
测试活动可以精准控制当前线程的行为,主要有三种用法:
-
暂停 (Pause) :定时器通常作用于一个范围,而测试活动可以像"钉子"一样,在请求A和B之间插入一个一次性的定点等待。比如你在之前的案例里,用于登录后查询前的固定等待。
-
停止线程 (Stop / Stop Now) :这是它更关键的功能。你可以把它放在 If 控制器 里,实现"条件停止"。
- 典型场景就是刚才的案例:当检测到登录失败(token为空),就用"Stop"让这个虚拟用户优雅退出,避免后续请求全报错,污染测试报告。这与通过后置处理器抛错不同,它能直接终止线程的生命周期。
-
继续 (Continue) :它可以放在 ForEach 控制器 或 循环控制器 内部,结合条件判断,用来跳过某次循环 ,就像编程里的
continue语句。
简单总结一下使用时机:
- 何时用暂停 :在请求A和B之间必须有一个固定间隔,且不想影响其他请求时使用。
- 何时用停止 :在遇到无法恢复的错误(如登录失败、用户余额不足等)时,配合 If 控制器来主动终止该线程。
- 何时用继续 :在遍历循环(如 ForEach)中,需要根据条件跳过当前这一项,直接处理下一个时使用。
下面用一个 API 查询场景 串联"测试片段"和"测试活动",让你理解它们的实际用法。
测试目标:查询用户订单列表的接口 /api/orders,该接口必须先登录获取 token 。
要求:
- 登录逻辑(请求 + 提取 token)需要被多个线程组复用。
- 获取 token 后,模拟用户思考 2 秒再查订单。
- 如果登录失败(token 为空),立刻停止当前虚拟用户,避免后续无效请求。
步骤一:用"测试片段"封装可复用的登录模块
1. 创建测试片段
- 右键测试计划 → 添加 → 测试片段 → 测试片段。
- 名称改为
登录模块。
2. 在片段内添加元件
在 登录模块 下添加:
① HTTP 请求(登录接口)
- 协议、服务器、端口、方法(POST)、路径填
/api/login。 - Body Data 填写
{"username":"test","password":"123456"}(后续可参数化)。
② JSON 提取器
- 变量名:
token。 - JSON Path:
$.data.access_token。 - Match No.:
1。 - 默认值:
NOT_FOUND。
这个片段现在就是一个独立的、可被调用的模块,但它本身不会执行。
步骤二:主测试计划引用片段,并用"测试活动"控制流程
1. 添加线程组
- 线程数:
1(便于观察,实测可加大)。 - Ramp-Up:
1。 - 循环次数:
1。
2. 引用登录片段
- 右键线程组 → 添加 → 逻辑控制器 → 模块控制器。
- 在模块控制器中,
Module to Run选择刚创建的登录模块。
此时,模块控制器执行时会运行片段内的所有元件,即发送登录请求并提取 token。
3. 根据 token 结果决定是否停止线程
我们希望:如果 token 为 NOT_FOUND(登录失败),则停止该线程,不再执行后续查询。
- 右键线程组 → 添加 → 逻辑控制器 → 如果(If)控制器。
- 条件:
"${token}" == "NOT_FOUND"(勾选"Interpret Condition as Variable Expression?")。 - 在 If 控制器下添加 取样器 → 测试活动 ,配置:
- 目标 :
当前线程(只停当前用户)。 - 动作 :
停止(优雅停止,完成本次迭代后不再继续)。 - 持续时间留空。
- 目标 :
这样,当 token 提取失败时,测试活动会让当前线程停止,后续的查询请求就不会执行了。
4. 模拟思考时间后再查询
如果 token 正常(即 If 条件不成立),我们希望延迟 2 秒再发查询请求(模拟用户浏览)。
- 右键线程组 → 添加 → 取样器 → 测试活动(另一个)。
- 配置:
- 目标 :
当前线程。 - 动作 :
暂停。 - 持续时间 :
2000(毫秒)。
- 目标 :
- 将这个测试活动直接放在查询请求的前面(不用 If 包裹)。
5. 添加查询请求
- 右键线程组 → 添加 → 取样器 → HTTP 请求。
- 路径:
/api/orders。 - 在 HTTP 头管理器中添加
Authorization: Bearer ${token}。
整个结构如下:
线程组
├── 模块控制器(→ 登录模块)
├── If 控制器(token == "NOT_FOUND")
│ └── 测试活动(停止)
├── 测试活动(暂停 2000ms)
└── HTTP 请求(/api/orders)执行效果:
- 测试片段:登录请求和 token 提取被复用,当有多个线程组都要登录时,只需再添加模块控制器引用即可,不用复制粘贴。
- 测试活动(停止):当 token 未提取成功时,优雅终止当前线程,避免后续请求因缺少 token 而大量报错,保持测试结果干净。
- 测试活动(暂停):在查询前定点插入 2 秒等待,模拟真实用户操作间隔,而且不依赖于定时器(定时器会影响作用域内所有请求,而测试活动只在这里停一次)。
六:总结
JMeter 的核心角色是"负载生成器"和"客户端性能数据采集器",它能告诉你的是:
- 并发压力下,从用户端看,响应有多快、成功与否、吞吐量有多大。
- 但它无法直接告诉你"为什么慢",因为服务器内部的线程、CPU、内存、锁、SQL 执行计划等信息,JMeter 是完全看不到的。
因此,JMeter 的定位就是:
发现问题 + 量化现象,而不是根因定位。