本文记录了一次本地知识库工作流实践:通过知识分类、置信度、Skill、工作流和 CLI 工程化,把分散资料沉淀为 AI 可调用、可验证、可持续演进的知识底座。
1. 背景与痛点
1.1 当前的"知识"是什么?
在日常研发中,团队的知识分散在这些地方:
| 载体 | 示例 |
|---|---|
| 飞书文档 | 需求文档、技术方案、会议纪要 |
| 代码仓库 | 业务逻辑、接口实现、配置规则 |
| 聊天记录 | 口头确认的结论、临时讨论的方案 |
| 个人记忆 | 踩坑经验、历史决策的背景 |
| 收藏夹/笔记 | 零散的片段、未整理的素材 |
这些内容都有价值,但没有被统一治理------它们是资料 ,不是知识 资产。
1.2 知识的痛点
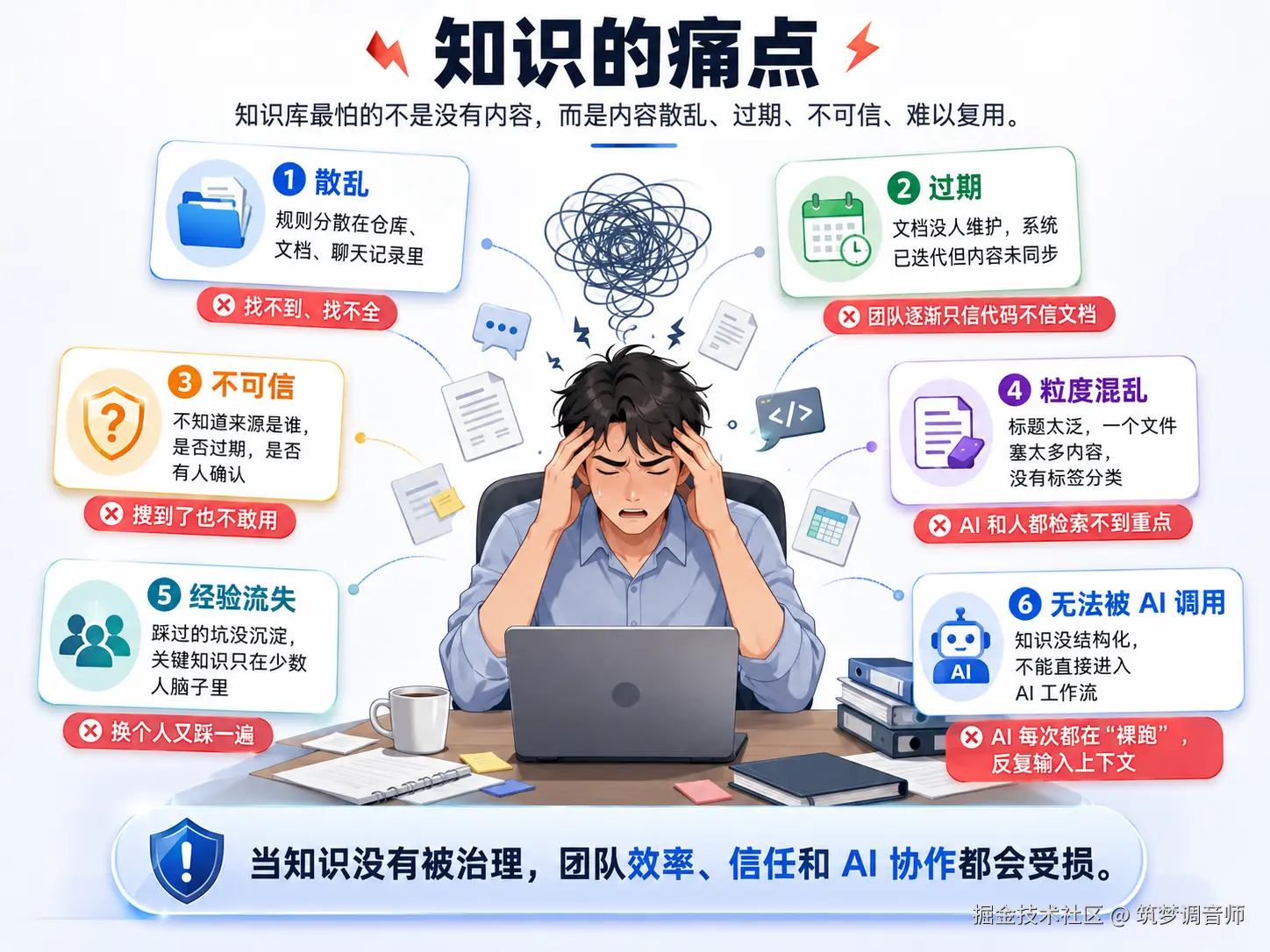
1.3 核心矛盾
团队不缺资料,缺的是一套能把资料转化为知识、把知识转化为 AI 可调用能力的机制。
传统知识库解决的是"存起来"的问题,但真正需要的是:能被找到、能被信任、能被 AI 稳定调用、能持续更新。
2. 我想解决什么问题
简单来说,我不是想做一个"更好看的文档站",而是想解决七件事:统一入口、低摩擦沉淀、代码知识提炼、类型化检索、可信度判断、AI 可调用、工作流闭环。
| 问题 | 传统做法 | 期望做法 |
|---|---|---|
| 知识太分散怎么办? | 同一个业务的知识散落在飞书文档、多个代码仓库、聊天记录、个人笔记里,没有统一入口 | ① 以业务为维度,统一收口到一个 Git 仓库 ② 按业务模块组织目录 ③ 条目关联到具体代码仓库/飞书文档/文件路径 ④ 一个入口查到所有相关知识 |
| 如何持续沉淀? | 写方案文档才算沉淀,成本高(开文档、想标题、选目录),日常结论停留在聊天和记忆里 | ① 对话中"记一下"就能触发 ② AI 自动整理格式、分类、补来源 ③ 摩擦足够低,让沉淀成为日常习惯 |
| 代码中的知识如何提炼? | 业务规则散落在多个仓库多个文件,代码表达的是"实现"而非"意图" | ① 冷启动批量扫描代码+飞书,AI 提炼业务结论 ② 建立代码地图标注跨仓链路 ③ 一次提炼持续复用 |
| 如何分类检索? | 文件夹层级 + 关键词搜索,标题不规范就搜不到 | ① 按知识类型路由检索 ② 问"最多操作几次"查 constraint ③ 问"怎么设计的"查 decision |
| 如何判断可信? | 搜到了不知道谁写的、什么时候写的、是否过期 | ① 每条带来源、置信度、验证时间、确认人 ② 过期自动降级 ③ 置信度不够时自动触发验证 |
| 如何让 AI 用? | AI 没有业务上下文,每次手动粘贴背景 | ① 结构化存储(YAML frontmatter + 正文) ② Skill 协议按需加载,先索引再条目 ③ AI 从"裸跑"变为"带上下文执行" |
| 如何进入工作流? | 知识库是只读的"展示型"系统,搜到、看完、关掉 | ① 知识库本身是工作流的一部分 ② 查询→发现缺口→沉淀→审查→入库 ③ 闭环演进,知识越用越完善 |
3. 知识库初识
3.1 知识库长什么样
KBFlow 的知识库就是一个普通的 Git 仓库 ------不是网站、不是 wiki、不是数据库。仓库里包含正式区(stable/)、草稿区(inbox/)、全局索引、业务配置,每条知识是一个带 YAML frontmatter 的 markdown 文件。
perl
my-kb/
├── stable/ # 正式区,经人工 review 入库
│ ├── seed/ # 按业务模块分目录
│ │ ├── overview.md
│ │ └── constraints/
│ └── water/
├── inbox/ # 草稿区,AI 自由写入
├── INDEX.md # 全局索引
├── kb.config.yaml # 业务配置选 Git 仓库形态的好处:直接复用版本控制、MR Review、权限管理;本地文件让 AI 工具(Cursor / Claude Code)零延迟读取;通过 kbf link 可以把它 clone 进任意业务仓库当上下文。
3.2 知识库工作流
核心概念速览:
-
init:初始化知识库仓库骨架
-
bootstrap:冷启动,从飞书文档+代码仓库批量提炼第一批知识草稿
-
capture:日常沉淀,随时"记一下"写入草稿区
-
review:对草稿做格式+事实验证
-
promote:审查通过后,将知识从草稿区迁入正式区
-
query:查询业务知识,AI 按置信度决定是否深入验证
-
revise:修正过期或错误的知识
3.3 典型场景:创建知识库
scss
步骤 1:创建仓库
步骤 2:安装 CLI(示例)
npm install -g @kbflow --registry=http://registry.npm.oa.com/
步骤 3:拉取知识库
git clone <url>
步骤 4:初始化知识仓库骨架 (执行命令:kbf init)
步骤 5:打开 AI 工具(Cursor / Claude Code),开始提问.
步骤 6:初始化知识库配置:填写业务仓库、飞书文档;
步骤 7:冷启动仓库:AI基于知识库配置,从飞书文档+代码仓库批量提炼第一批知识草稿
步骤 8:审查知识库草稿、提交到正式区,并且提交到仓库,由负责人进行review&合并3.4 典型场景:新人快速了解业务
新人接手业务时,不需要逐个翻飞书文档和代码仓库,几步就能开始查询业务知识:
scss
步骤 1:安装 CLI(示例)
npm install -g @kbflow --registry=http://registry.npm.oa.com/
步骤 2:拉取知识库
git clone <url>
步骤 3:打开 AI 工具(Cursor / Claude Code),开始提问.之后直接用自然语言按需查询:
- 问"XX 模块是做什么的" → 查到 overview,了解模块全貌
- 问"这个流程涉及哪些仓库" → 查到 map,定位代码入口
- 问"有什么业务限制" → 查到 constraint,了解规则边界
- 问"上次那个问题怎么解决的" → 查到 debug-log,复用已有经验
从"问人→等回复→再问"变成"直接查→有来源→可验证",新人上手周期缩短,老人也不用反复解释。
4. 方案设计与实现
4.1 整体架构
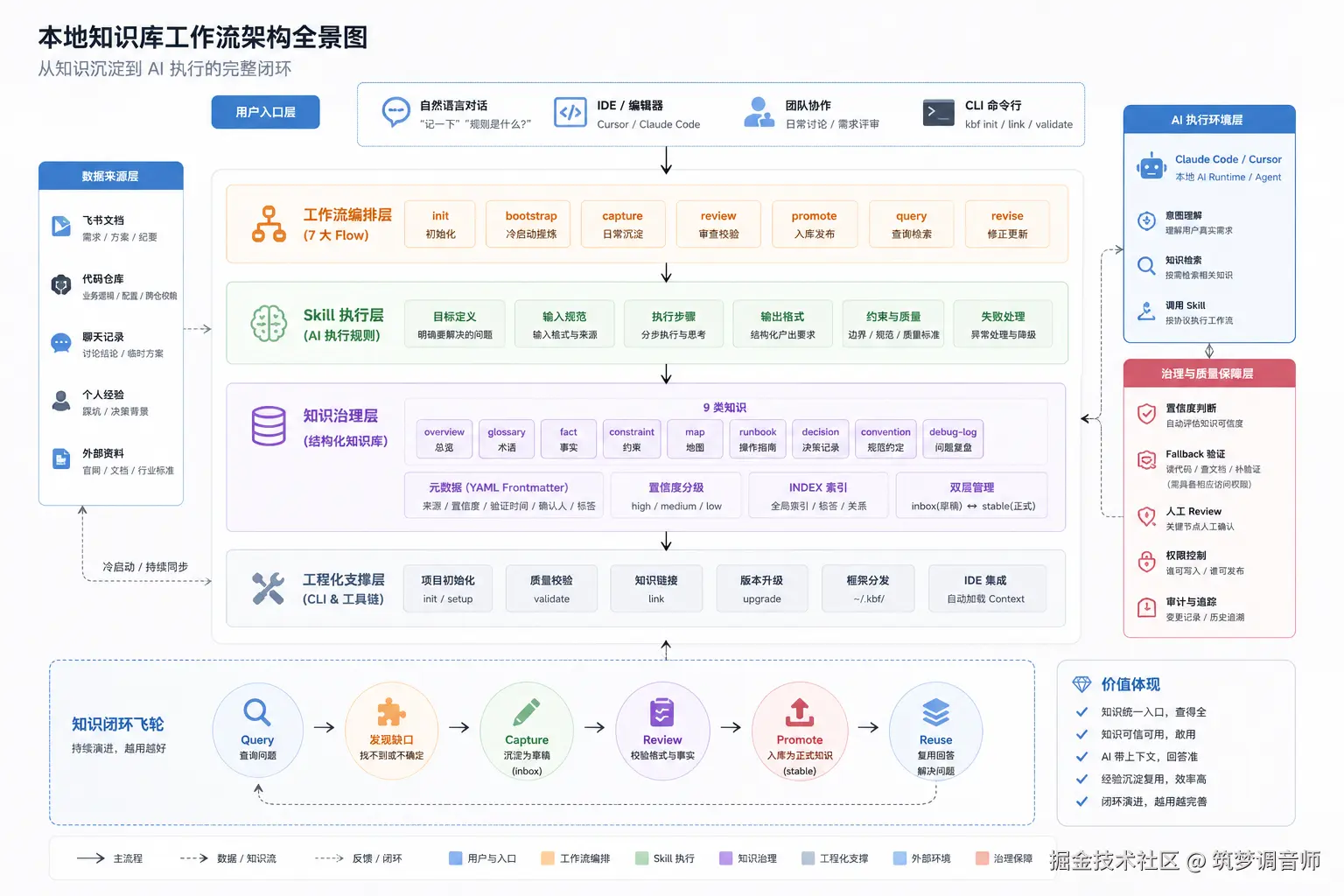
核心理念:AI 负责提议和检索,人类负责事实确认。
AI 的权限止于 inbox/(草稿区),进入 stable/(正式区)必须经人类确认。这保证了知识库不会因为 AI 幻觉而逐渐腐化。
4.2 知识设计
九种知识类型
为什么是 9 类? 基于 MECE 原则(互斥且穷尽),按"这条知识回答什么类型的问题"来划分------描述整体、定义概念、记录现状、约束边界、定位代码、指导操作、记录决策、约定标准、复盘问题。
| 类型 | 回答的问题 | 说明 |
|---|---|---|
| overview | 这块整体是什么? | 模块、业务、系统、领域的总览 |
| glossary | 这个术语是什么意思? | 术语、概念、缩写、定义 |
| fact | 当前真实状态是什么? | 当前配置、接口、表结构、字段定义 |
| constraint | 有什么限制/约束? | 业务规则、系统限制、权限约束、数量限制 |
| map | 去哪里找?结构在哪? | 代码地图、模块入口、调用链路、文档索引 |
| runbook | 遇到某场景怎么操作? | 操作步骤、排查步骤、应急处理流程 |
| decision | 当时为什么这么选? | 背景、方案、取舍、决策理由 |
| convention | 以后应该遵守什么标准? | 规范、约定、质量标准、命名标准 |
| debug-log | 之前发生了什么问题? | 故障、事故、踩坑、复盘、排查记录 |
分类时按决策树判断:
c
你要记录的知识 →
├── 描述"某个东西是什么"?
│ ├── 整体模块/系统 → overview
│ └── 单个术语/概念 → glossary
├── 描述"当前状态/数据是什么"? → fact
├── 描述"有什么限制/不能做什么"? → constraint
├── 描述"代码在哪/怎么串联"? → map
├── 描述"遇到 X 该怎么操作"? → runbook
├── 描述"当时为什么这样选"? → decision
├── 描述"团队应该遵守什么"? → convention
└── 描述"之前出过什么问题"? → debug-log类型不只是标签,而是检索的路由依据。 用户问"每天最多操作几次",AI 优先检索 constraint 类型条目,而不是全文搜索碰运气。
结构化元数据
每条知识都有 YAML frontmatter,记录来源、置信度、验证时间、确认人:
yaml
---
id: BIZ-CST-042
title: 每日购买商品次数上限为 3 次
entry_type: constraint
confidence: high
last_verified: 2025-05-10
confirmed_by: @zhangsan
sources:
- type: gitlab
repo: rewards-service
path: src/rules/water.go:47
- type: feishu
url: https://xxx.feishu.cn/docx/xxx
tags: [seed, water, limit]
---置信度三档
| 级别 | 条件 | AI 查询时行为 |
|---|---|---|
| high | 2+ 来源 + 人工确认 + 未过期 | 直接引用 |
| medium | 单一来源 / 多源未裁定 | 自动 fallback 验证后回答 |
| low | 仅口述 / AI 推测 | 必须 fallback + 标注"仅供参考" |
置信度不是静态的------超过 stale_after_days 未重新验证会自动降级,查询时触发重新验证后可恢复。
4.3 工作流与 Skill 设计:Harness Engineering
设计思想
这套工作流的设计思想来自 Harness Engineering。
什么是 Harness? 不改 AI 本身,而是给 AI 搭建一套外部运行环境------包括知识、规则、流程、模板、约束。Harness一词来自马具------缰绳、马鞍、嚼子------这是一套引导强大但不可预测的动物的完整装备。驾驭工程不是去削弱 AI 的能力,而是为它打造一套黄金缰绳,让它跑得又快又稳。
参考:www.runoob.com/ai-agent/ha...
核心思路:AI 的能力上限取决于你给它的支架质量。
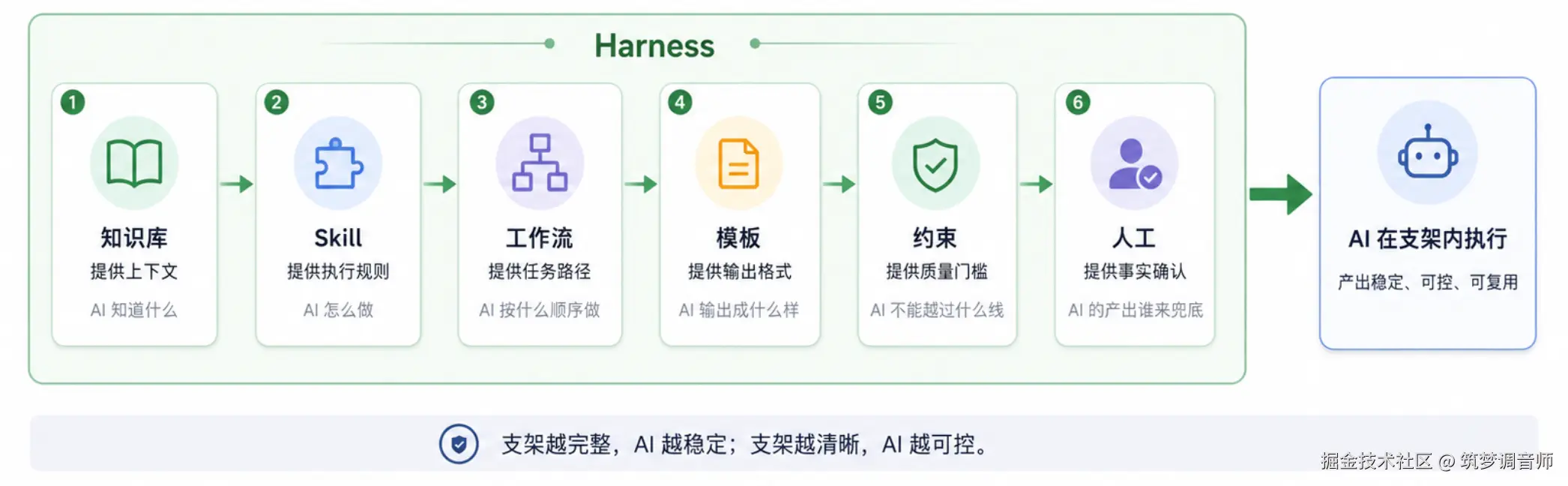
传统做法是写一段 prompt 然后期望 AI 表现好------这相当于"裸跑"。Harness Engineering 的做法是把知识、规则、流程、约束都外化成文件,AI 按协议加载和执行。Prompt 会漂移,但文件协议是稳定的。
具体到 本工作流,Harness 由五层组成:
| 支架层 | 对应文件 | 作用 |
|---|---|---|
| 上下文支架 | stable/ + INDEX.md | AI 知道业务事实 |
| 规则支架 | SKILL.md + conventions.md | AI 知道怎么做、什么能做什么不能做 |
| 流程支架 | skills//SKILL.md | AI 按固定路径完成任务 |
| 格式支架 | templates/ | AI 输出结构一致 |
| 质量支架 | review-flow + validate | 产出有检查机制 |
七大工作流
有了这套支架,七大工作流形成闭环------知识越用越完善:

| 工作流 | 触发方式 | 做什么 |
|---|---|---|
| init | kbf init + /kbf 开始初始化 |
初始化仓库骨架,引导填写业务配置 |
| bootstrap | "开始冷启动" | 从飞书+代码批量生成第一批草稿 |
| capture | "记一下" | 日常沉淀,直接写入 inbox |
| review | "review 一下" | 格式+事实验证,只读不改 |
| promote | "promote 这条" | 经人确认后从 inbox 迁入 stable |
| query | "X 规则是什么?" | 检索+按置信度决定是否深入验证 |
| revise | "这条不对了" | 修正/归档过期知识 |
关键设计 :query 时如果置信度是 medium/low,AI 会自动执行 fallback(读代码、拉飞书文档验证),而不是丢一句"建议你去看一下代码"。这是和传统知识库最大的区别。
Skill:工作流的执行单元
每个工作流通过一个 Skill 文件 (skills/<flow>/SKILL.md)来实现。Skill 是从临时 Prompt 升级而来的稳定执行规则------Prompt 每次写法不同容易漂移,Skill 是固定协议,产出稳定。
每个 Skill 遵循统一模板结构:
css
Purpose - 这个 Skill 做什么
Inputs - 需要什么输入(用户输入 + 配置 + 知识)
Preconditions - 执行前必须满足什么条件
Invariants - 执行过程中不能违反的约束
Flow - 具体步骤(核心)
Outputs - 产出什么、写到哪里
Failure Modes - 遇到异常怎么处理
Completion - 怎么判断做完了同时有一个总入口 Skill (SKILL.md)负责统一调度:接收用户意图 → 路由到对应工作流 Skill → 约束全局行为(权限边界、反幻觉、来源要求)。
4.4 工程化处理
通过 CLI 工具 kbf 实现框架的分发和维护。
安装:
ini
# 全局安装(推荐)(示例)
npm install -g @kbflow --registry=http://registry.npm.oa.com/
# 或通过 npx 直接使用(无需安装)
npx --registry=http://registry.npm.oa.com/ @kbflow init命令列表:
bash
kbf init # 在 git 仓库初始化 KB 结构
kbf setup # 全局安装框架到 ~/.kbf/,含 IDE 适配器
kbf link <url> # 在业务仓库引入知识库(clone 到 .knowledge/)
kbf validate # 检查 KB 健康状态
kbf upgrade # 一键升级到最新版kbf link 跨仓共享 :在业务代码仓库执行 kbf link <kb-repo-url>,将团队知识库 clone 到 .knowledge/ 目录。写代码时可以直接询问业务规则,AI 会优先结合 .knowledge/ 中的知识库上下文进行回答。多个业务仓库可 link 同一个 KB,知识统一管理。
CLI 与 AI 的职责边界:
| 工作 | CLI(确定性) | AI(需要判断) |
|---|---|---|
| 创建目录骨架 | ✅ | ❌ |
| 生成配置模板 | ✅ | ❌ |
| 引导填写业务内容 | ❌ | ✅ |
| 知识沉淀与检索 | ❌ | ✅ |
| 格式校验 | ✅ | ❌ |
设计理由:机器做确定性工作,AI 做需要判断的工作。两者通过文件协议(kb.config.yaml、SKILL.md、conventions.md)对接。
5. 关键设计亮点
5.1 从 Prompt 到 Harness:把 AI 能力工程化
与其花精力调 prompt 期望 AI 表现好,不如把精力放在搭建 AI 运行的外部环境。
| 问题 | 裸跑 Prompt | Harness 方式 |
|---|---|---|
| AI 不了解业务 | 每次手动粘贴背景 | 知识库自动提供上下文 |
| AI 输出不稳定 | 每次在 prompt 里写格式要求 | 模板文件固定输出结构 |
| AI 容易幻觉 | 靠 prompt 说"不要编" | 自检清单 + 来源强制要求 |
| AI 流程不可控 | 一段 prompt 塞所有逻辑 | 每个工作流独立 Skill,步骤明确 |
| AI 质量无保障 | 全靠人肉 review | validate 自动校验 + review-flow 核查 |
关键洞察:Prompt 会漂移,文件协议是稳定的。 规则外化成文件后,AI 每次加载同一套协议,产出一致性大幅提升。这就是 Harness Engineering 的核心------不是让 AI 更聪明,而是让 AI 跑在更好的轨道上。
5.2 从全文搜索到渐进式加载:降低上下文噪音
传统做法是把整个文档丢给 AI;KBFlow 的做法是按需逐层深入,像漏斗一样过滤:
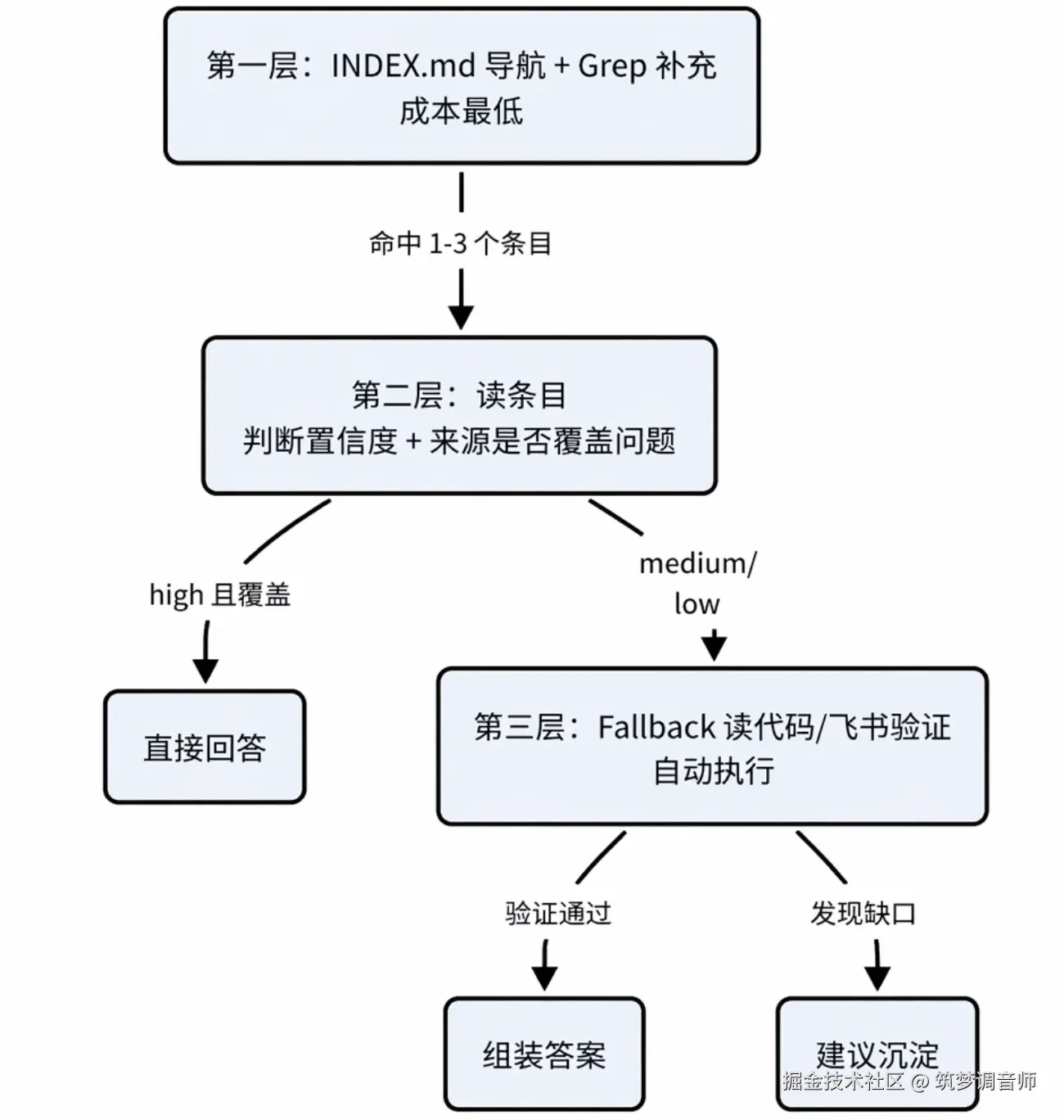
好处:节省 token、按需验证、发现缺口时自动建议沉淀。不是一次性灌全量,而是逐层确认够用了就停。
5.3 从静态文档到置信度机制:让知识可被信任
传统文档没有"保质期"概念;KBFlow 给每条知识加上证据状态,并且让它动态流转:

核心区别:medium/low 时 AI 自动执行验证,而不是推给用户。 不确定时自动深入验证,这是"执行型知识库"和"展示型知识库"的根本分界线。
5.4 从 AI 生成到人类确认:避免知识库被幻觉污染
AI 可以高效产出,但不能无限制地写入正式知识。KBFlow 设计了四道质量关卡:
| 关卡 | 机制 | 做什么 |
|---|---|---|
| 1 | 格式校验 kbf validate |
自动检查 frontmatter、sources、id 唯一性、正文结构 |
| 2 | 事实验证 review-flow | 对比代码和飞书,确认内容一致性,评估置信度 |
| 3 | 入库操作 promote-flow | 分配正式 ID,从 inbox 迁移到 stable,更新 INDEX |
| 4 | 人工 Review MR 审批 | 团队成员基于 review 报告判断,通过后才能合并 |
同时 AI 在回答业务问题前必须过自检清单:信息是从 KB 读到的还是编的?代码是真的读了还是只给了路径?来源填全了吗?过期了吗?没找到来源就说"KB 暂无确认条目",不编。
5.5 从一次性沉淀到闭环演进:让知识越用越完善
知识库最怕"写完就死了"。KBFlow 的七大工作流形成飞轮------每次使用都可能让知识库变得更好:
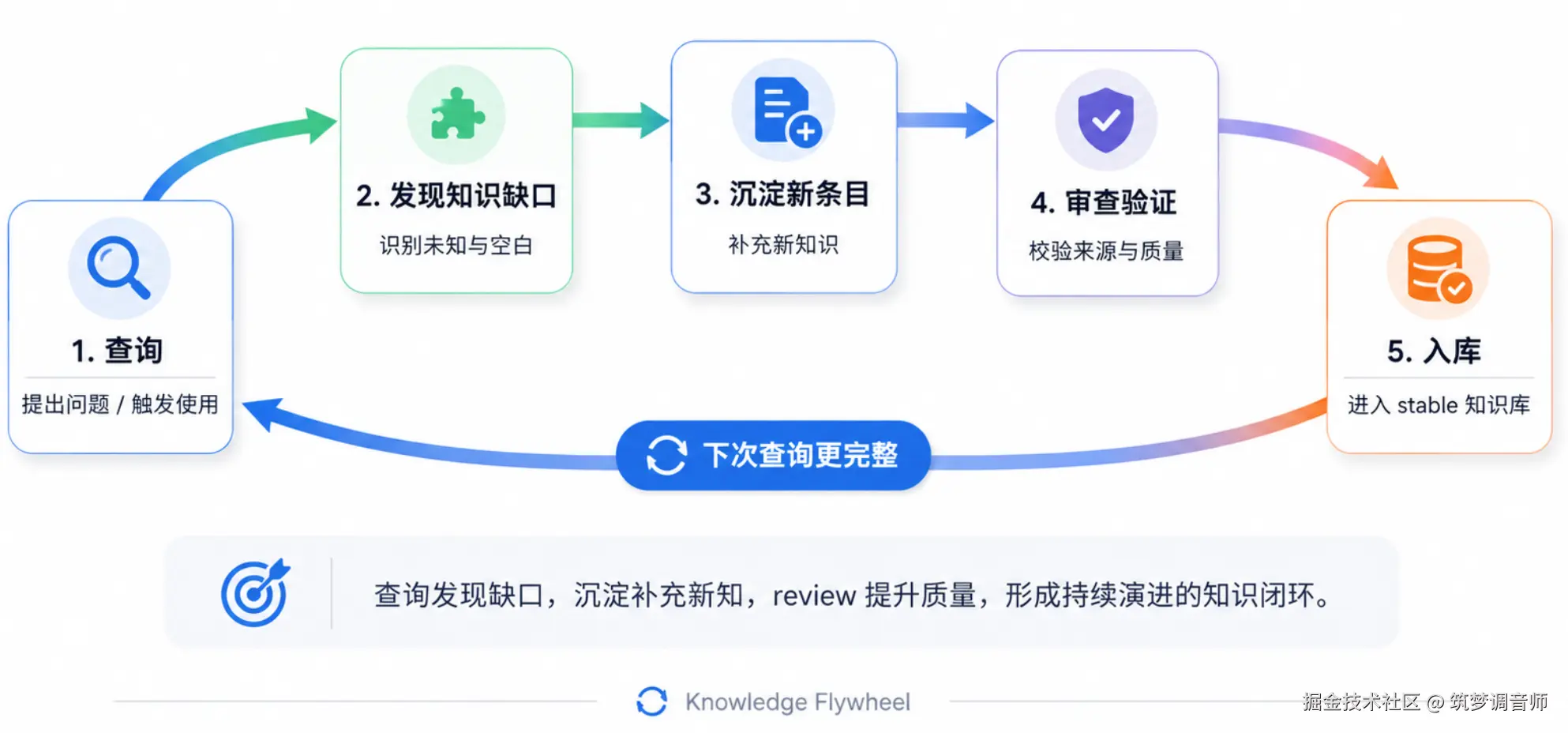
6. 搭建过程
这套系统不是先画完架构图再实现,而是从一个最小可验证能力开始:先让 AI 能稳定沉淀一条知识,再逐步扩展到查询、审查、入库和工程化分发。
核心方法论:先跑通一个点,再连成一条线。

具体过程:
- 先搭建单个 Skill:从 capture-flow 开始,定义"沉淀一条知识"的完整规则
- 用 Skill 产出内容:真的去沉淀几条业务知识,看 AI 输出是否符合预期
- 通过真实结果验证:如果 AI 写出的条目缺来源、格式不对、幻觉严重,就修改 Skill 规则
- 稳定后迁移到工作流:capture 稳定后,再搭 query、review、promote,逐步串联
- 最后 CLI 工程化:当工作流验证通过,才做 npm 包、分发、IDE 适配器
关键心得:不要一开始设计全套系统。 先解决一个具体问题("怎么让 AI 帮我记一条知识"),验证有效后再扩展。
7. 总结与展望
7.1 价值
搭建这套知识工作流后带来的核心收益:
| 维度 | 价值 |
|---|---|
| 降低重复沟通成本 | 部分高频问题可以优先通过知识库获得答案,减少反复问人的成本;新人理解模块更快,老人不用反复解释 |
| 提升 AI 输出质量 | 知识库是 AI 工作流的上下文底座,AI 在需求理解、方案设计、代码生成等场景中,可以获得更稳定的上下文支撑 |
| 降低人员流动风险 | 把个人经验转成组织资产,关键知识不再只在某些人脑子里 |
| 提高决策质量 | decision 类型记录历史决策------当时为什么这么选、牺牲了什么,未来做类似决策不需要从零开始 |
| 提升协作效率 | convention、runbook、debug-log 让团队形成统一标准,从"靠个人经验做事"升级为"靠系统机制做事" |
7.2 总结
知识库不是终点,能被 AI 稳定调用和执行,才是知识真正进入工作流的开始。
AI 工作流的稳定性,不只取决于模型本身,更取决于外部上下文、执行规则、质量门槛和反馈机制。知识库真正有价值的地方,不是把内容存起来,而是让它成为 AI 每次执行时可依赖的底座。
一套好的知识工作流做到的事情是:让下次遇到同样问题的人,能因此节省 30 分钟。
附录
参考文章
| 资料 | 链接 |
|---|---|
| Harness Engineering 概念 | www.runoob.com/ai-agent/ha... |
| 知识基座:让"AI 越用越懂业务"的团队经验实践【天猫 AI Coding 实践系列】 | www.bestblogs.dev/en/article/... |
| Harness 不是目的,知识才是护城河 ------ 一个 AI 工程交付团队的知识沉淀实践 | www.bestblogs.dev/en/article/... |
| LLM Wiki | gist.github.com/karpathy/44... |