
你有没有遇到过这种场景:周围的人都在聊 ChatGPT、大模型、AI,你点了点头,假装听懂了,转身还是一头雾水?
这篇文章不讲论文,不讲公式。我只想用最朴素的语言告诉你,大模型到底是个什么东西,它的本质是什么,为什么它能写代码、能翻译、能聊天,又为什么它有时会一本正经地胡说八道。
一、从一个无聊的游戏说起
小时候玩过一个游戏:我说上半句,你猜下半句。
「床前明月光,疑是___」------几乎所有人都会脱口而出「地上霜」。
为什么?因为你读过这首诗,或者读过足够多带有类似句式的中文文章,大脑里已经形成了一种模式:在这个上下文下,「地上霜」出现的概率远高于「天花板」。
大模型做的事情,本质上和这个游戏完全一样------预测下一个词。
准确来说,是预测「下一个 token」(token 可以理解为词或词的一部分)。给定前面所有的词,模型会输出一个概率分布:下一个词是「的」的概率是 12%,是「了」的概率是 8%,是「地」的概率是 3%......然后从这张概率表里抽取一个词,再把这个词加到输入里,继续预测下下个词。如此反复,直到生成一段完整的文字。
这就是大模型的全部秘密。
二、「大」在哪里?一组让你震惊的数字
既然只是猜词,为什么要叫「大」模型?
大,体现在两个维度。
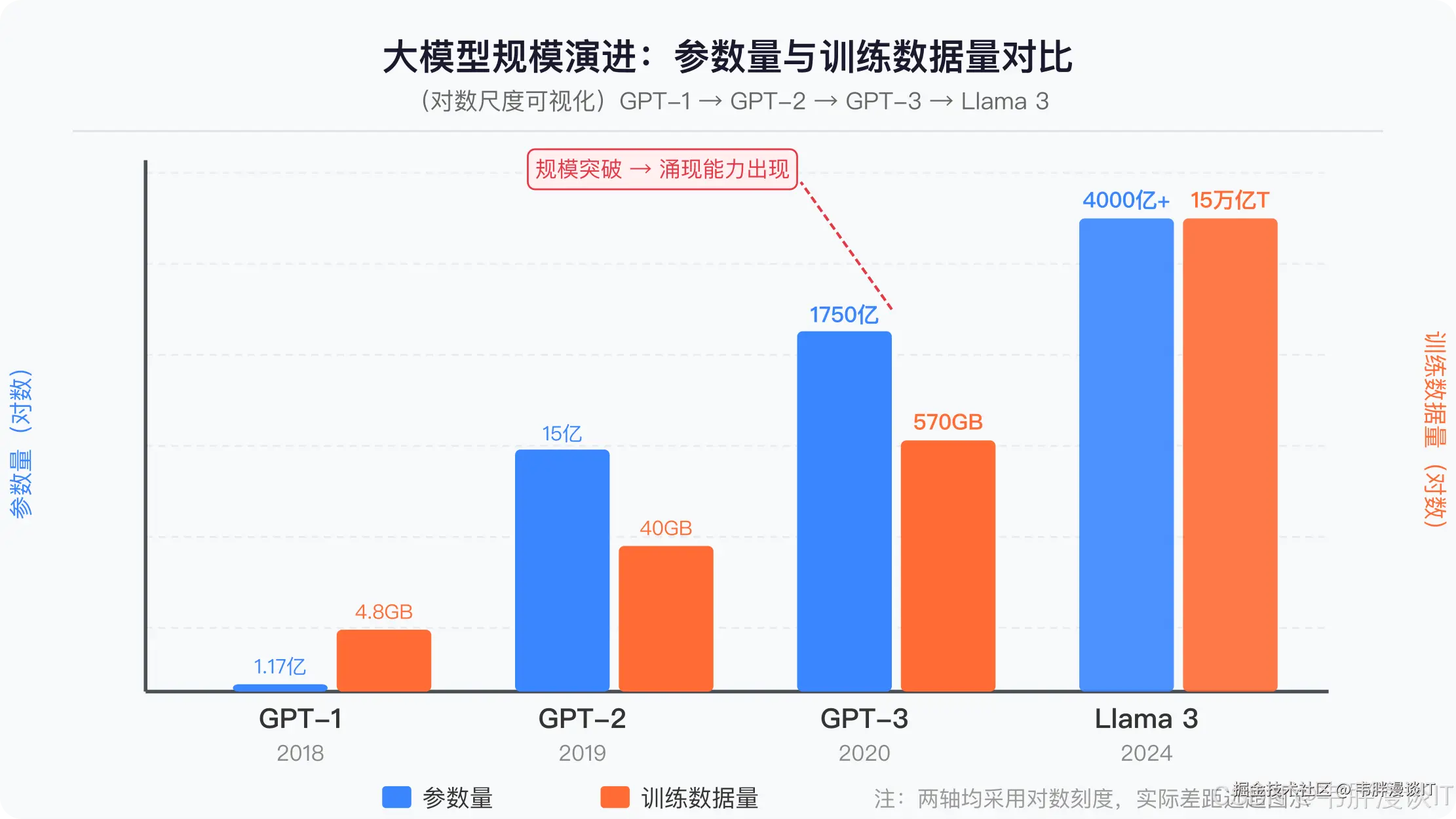
第一,训练数据大得离谱。
GPT-3 的训练数据来自约 45TB 的原始互联网文本,最终过滤后用了 570GB、约 4900 亿个 token。这是什么概念?如果你每天读 10 小时书,每本书 200 页,读完这些内容需要大约 450 万年。
GPT-4 的传言参数规模在 1.8 万亿左右,训练数据规模比 GPT-3 还要大一个数量级。Meta 的 Llama 3 直接将训练数据扩展到超过 15 万亿个 token。
换句话说,大模型是把人类几十年在互联网上积累的文字------论文、新闻、小说、代码、论坛帖子、维基百科------全部「读」了一遍,再「读」了一遍,再「读」了一遍......
第二,参数大得离谱。
参数是模型里面的「旋钮」。训练过程,就是在用海量数据反复调整这些旋钮,直到模型能把「下一个词」猜得尽量准。
GPT-3 有 1750 亿个参数。GPT-4 据传有 1.8 万亿个参数,分布在 8 个专家子模型里。相比之下,人脑大约有 860 亿个神经元------大模型的参数量已经和人脑神经元数量处于同一量级,甚至远超它。
当然,参数和神经元是两个不同的概念,这个类比只是帮你建立一个直觉:这玩意儿确实很大。
三、它到底「学」到了什么?
这里有个反直觉的地方让很多人困惑:一个只会「猜下一个词」的系统,怎么会写代码、解数学题、做翻译?
答案是:语言本身就蕴含了知识和推理结构。
想一想,当你在数学题里写「因为 A,所以 B」,你其实是在用语言编码推理关系。当你在代码里写注释「这个函数用于排序」,你是在用语言描述程序逻辑。当你在维基百科上写「法国的首都是巴黎」,你是在用语言存储事实。
一个被迫要「精准猜词」的系统,为了完成这个任务,必须内化所有这些关系。它要知道「法国的首都是___」后面大概率跟着「巴黎」;它要知道「def quicksort(arr):」后面应该跟着怎样的代码逻辑;它要知道「if a > b: return a else:」后面最合理的补全是什么。
这种「内化」,在参数达到足够规模之后,会突然冒出一种叫「涌现能力」(Emergent Ability)的现象------模型开始展示出它从未被明确训练过的能力,比如类比推理、多步数学、甚至某种程度的常识判断。就像水加热到 100 度会突然沸腾,量变引发质变。
四、Transformer:让「猜词」变得极其精准的架构
当然,光有数据和参数还不够。支撑大模型运转的核心架构叫 Transformer,它在 2017 年由谷歌提出,用一篇名为《Attention is All You Need》的论文改变了整个 AI 领域。
Transformer 的核心机制是注意力机制(Attention)。
用一个比喻来理解:你在读「小明把苹果放在桌子上,他很喜欢___」这句话时,你的大脑会自动判断「他」指的是「小明」,而不是「苹果」或「桌子」。你在处理「喜欢」这个词时,会重点「关注」前面的「小明」和「苹果」,而不是每个词一视同仁。
注意力机制就是让模型学会这种「有选择地关注」。在预测每个词时,模型会动态计算当前词和上文所有词之间的相关性权重,然后加权整合信息,再做预测。
这比之前的循环神经网络(RNN)强在哪里?RNN 是一个词一个词地处理,距离远的词容易被「遗忘」;而 Transformer 一次性处理整个上下文,任意两个词之间的关系都能被直接建模,无论它们相隔多远。
正是这个架构,让大模型得以真正利用起海量训练数据里的长程依赖关系。
五、那它为什么会「胡说八道」?
了解了大模型的本质,它的局限性就变得一目了然。
大模型只是一个「超级精准的概率猜词机」。它输出的每个词,都是基于概率的最优猜测。它并不「知道」自己在说什么,也没有一个内部的事实核查模块。
2023 年,美国一位律师在法庭文件中引用了 ChatGPT 给出的案例引用,结果那些案例根本不存在------是模型以极高的流畅度「编造」出来的。这种现象被称为「幻觉」(Hallucination)。
原因很简单:如果训练数据里,「某某案件」后面紧跟着「原告胜诉」这样的语句模式,模型就会生成它,哪怕那个案件根本不存在。它猜的是「最可能出现的下一个词」,而不是「最符合事实的下一个词」------除非做了额外的事实对齐训练(RLHF 等技术),但即便如此,幻觉也无法完全消除。
这不是 bug,这是大模型工作原理的必然结果。
六、「大」不等于「慢」------技术落地的真正挑战
你可能会想:这么大的模型,运行起来得多慢、多贵?
这恰恰是技术落地最核心的挑战。
2024 年,DeepSeek-R1 以远低于同量级 GPT 系列的训练成本(据报道约 600 万美元)横空出世,引发了整个行业对「效率优先」路线的重新审视。同年,多家机构开始大量研究「模型蒸馏」和「量化压缩」技术------把数千亿参数的大模型「压缩」成几十亿参数的小模型,在手机或边缘设备上跑,同时保留 80% 以上的能力。
苹果在 2024 年发布的 Apple Intelligence 系统,核心就是一个运行在本地的约 30 亿参数的小模型,处理日常任务,复杂任务才上云端大模型。这是「大模型落地」的一个缩影:不是把最大的模型直接塞给用户,而是找到规模与效率的平衡点。
「下一个词预测」的本质没有变。变的是,工程师们想尽办法,让这台超大规模的概率机器跑得更快、更便宜、更准确,从实验室走进每一个真实的使用场景。
结语:理解本质,才能用好工具
大模型,本质上是一台用 570GB 乃至更大量级的人类文字喂养出来的、拥有数千亿个参数的「超级猜词机」。
它之所以「聪明」,是因为语言本身就是人类知识和推理的载体------猜词猜到极致,就等于理解了语言背后的世界模型。
它之所以会出错,是因为它的目标函数从来不是「说真话」,而是「说出最合理的下一个词」。
当你下次打开 ChatGPT、Kimi 或者任何一个大模型产品,输入一段提示词,背后发生的事情,就是这台庞大的概率机器,在用数千亿个参数的合力,为你猜出下一个词,再下一个词,再下一个词......
而如何让这台机器猜出真正有价值的「下一个词」,才是技术落地的真正战场。