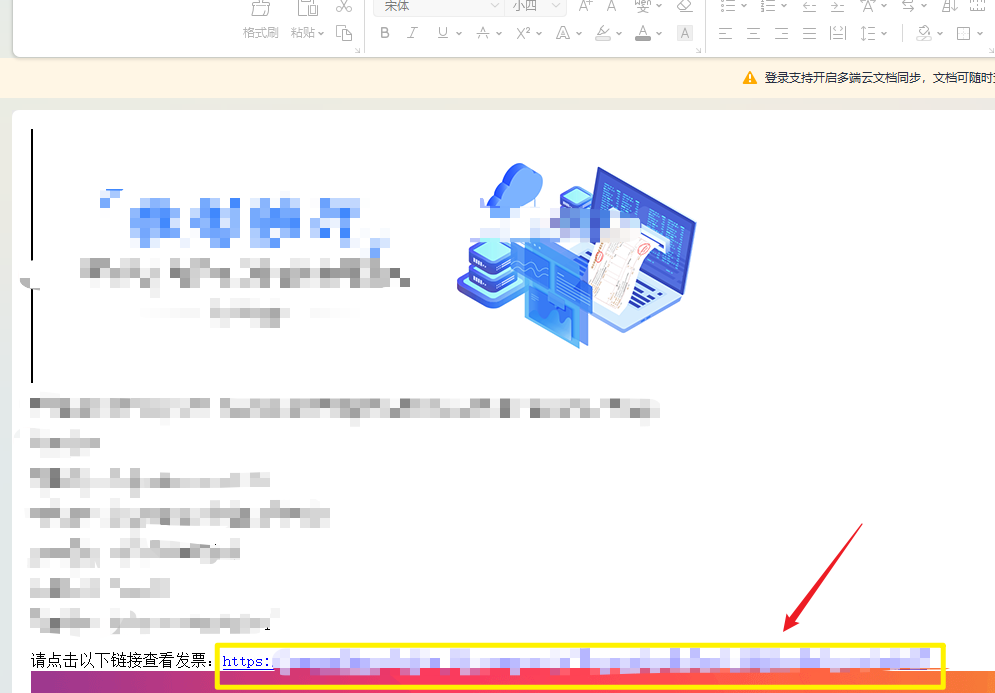
每一个eml文件打开就是这样的,包含一个发票链接:
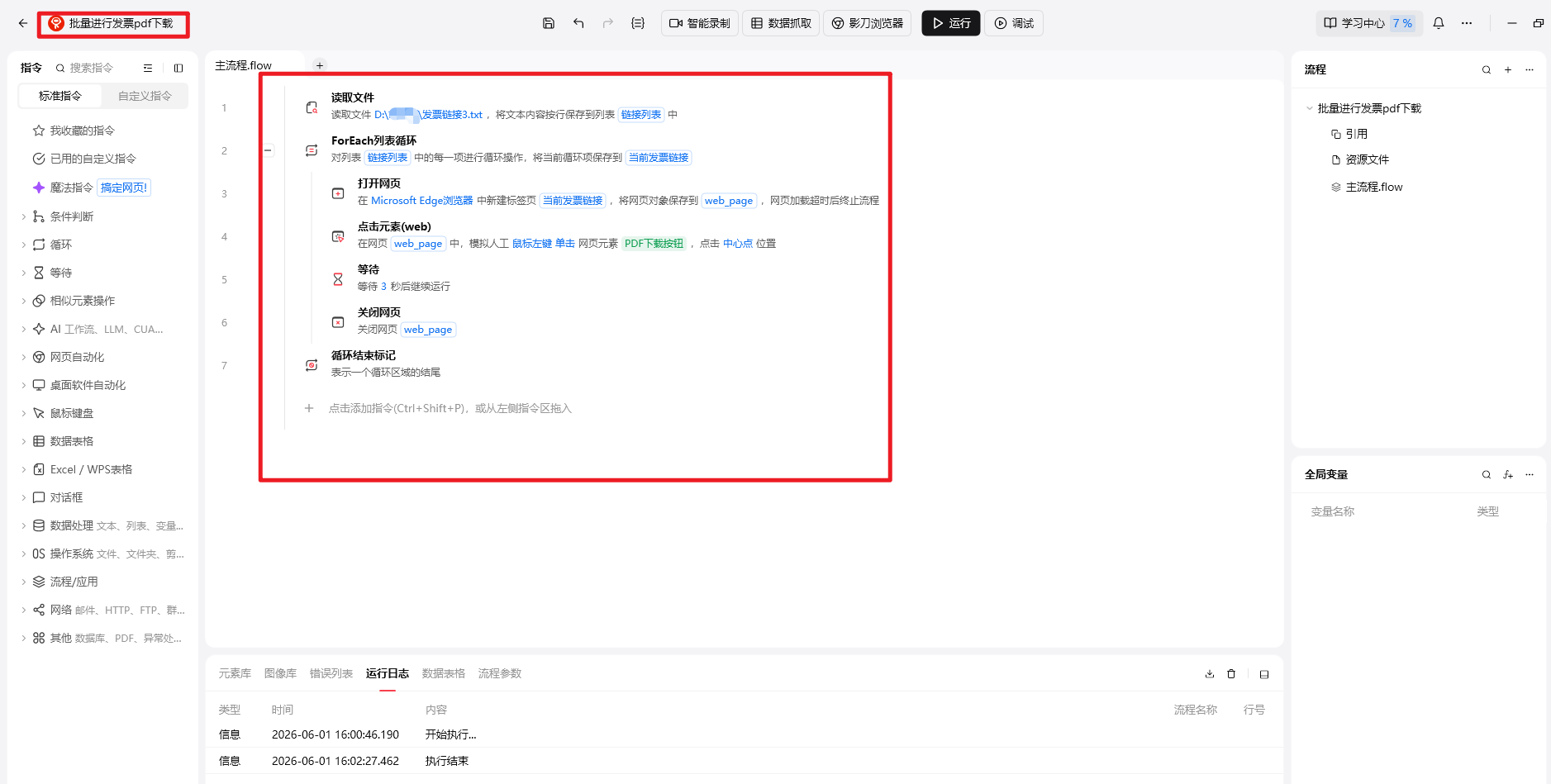
1、提取提取eml文件中的发票链接
# 批量提取200个eml文件的链接地址,保存到发票链接.txt中,
import os
import re
import email
from email.policy import default
# ========== 配置 ==========
# 你的EML文件存放文件夹
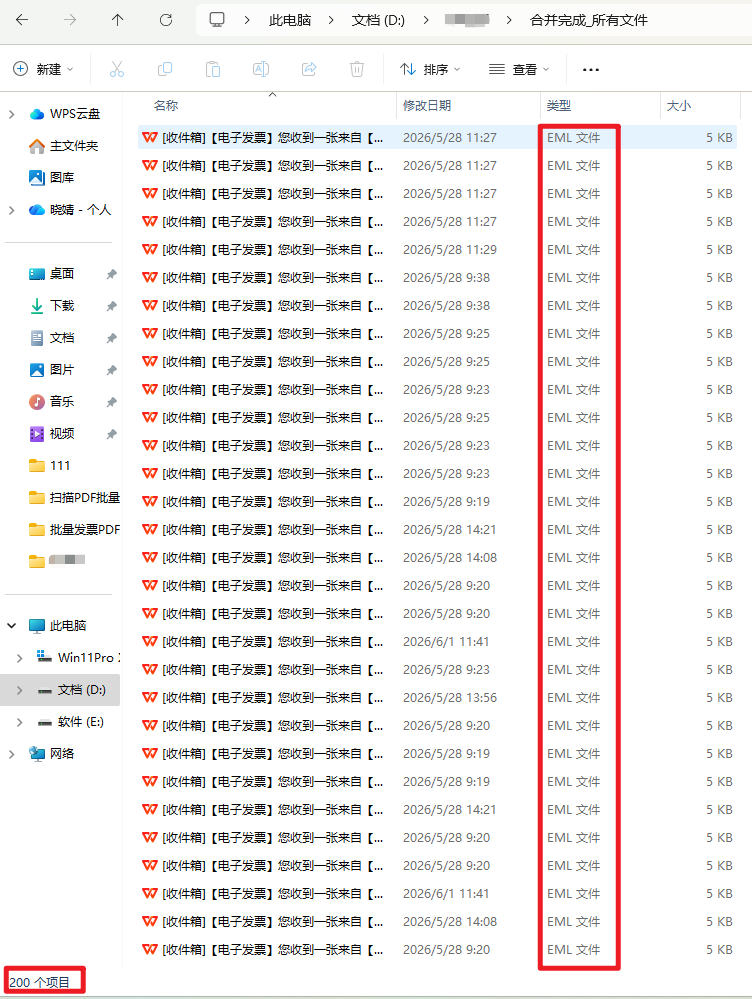
EML_FOLDER = r"D:\XXXXX\合并完成_所有文件"
LINK_OUTPUT = r"D:\XXXXXX\发票链接.txt"
# ==================================================
# 正则匹配发票链接
pattern = re.compile(r"https://dppt\.hebei\.chinatax\.gov\.cn:8443/\S+")
def clean_url(url):
"""清理链接末尾多余符号"""
url = url.split("'")[0]
url = url.split('"')[0]
url = url.split(">")[0]
url = url.split("<")[0]
url = url.strip()
return url
def extract_from_one_eml(path):
"""单个EML提取链接,不去重,返回列表"""
link_list = []
try:
with open(path, "rb") as f:
msg = email.message_from_bytes(f.read(), policy=default)
for part in msg.walk():
if part.get_content_type() in ["text/plain", "text/html"]:
try:
body = part.get_payload(decode=True).decode("utf-8", "ignore")
except:
body = part.get_payload(decode=True).decode("gbk", "ignore")
found = pattern.findall(body)
for url in found:
clean_url_str = clean_url(url)
if clean_url_str:
link_list.append(clean_url_str)
except Exception as e:
print(f"⚠️ 解析异常:{os.path.basename(path)},错误:{str(e)[:30]}")
return link_list
def batch_extract():
all_links = []
files = [f for f in os.listdir(EML_FOLDER) if f.lower().endswith(".eml")]
total_file = len(files)
print(f"📂 共找到 {total_file} 个eml文件,开始提取...\n")
for idx, fname in enumerate(files, 1):
path = os.path.join(EML_FOLDER, fname)
urls = extract_from_one_eml(path)
# 追加到总列表,不去重
all_links.extend(urls)
print(f"[{idx}/{total_file}] {fname} → 提取 {len(urls)} 条链接")
# 写入文件
with open(LINK_OUTPUT, "w", encoding="utf-8") as f:
for url in all_links:
f.write(url + "\n")
print(f"\n========================================")
print(f"✅ 全部解析完成")
print(f"📄 总文件数:{total_file}")
print(f"🔗 总计提取链接:{len(all_links)} 条(未去重)")
print(f"💾 链接已保存至:{LINK_OUTPUT}")
if __name__ == "__main__":
batch_extract()这样所有的链接都保存到发票链接.txt了,具体大致如下:一行就是一个链接

2、利用影刀软件设置自动化下载流程
我试了试爬虫会有反扒机制,不能批量下载发票pdf,试了试影刀这个软件,就可以下载。