你必须非常努力,才能看起来毫不费力!
微信搜索公众号 AGIPlayer ,一起From Zero To Hero !
Claude Code 的 Dynamic Workflows 把多 Agent 编排逻辑从 LLM 的上下文窗口移到了 JavaScript 脚本里,单次运行可调度数百个 Subagent,支持暂停恢复、交叉验证、保存复用。这不是又一个 Agent 框架,而是一种让 Agent 系统真正 scale 的工程思路。
最近我在做一个代码库的全局安全审计,大概 200 多个 API 端点,每个都要检查鉴权、参数校验、错误处理。我用 Subagent 并行跑了几个,但很快就撞墙了------每个 Subagent 的结果都回到主对话的上下文窗口里,跑了十几个之后上下文就快满了,后面的 Agent 结果开始被压缩丢失。
然后我试了 Agent Teams,但十几个人协调起来,Lead Agent 的上下文也撑不住。
说实话,那会儿我挺沮丧的。明明模型能力够,Agent 也能干活,就是"协调"这件事本身成了瓶颈。
直到 Claude Code v2.1.154 发布了 Dynamic Workflows,我才意识到问题出在哪:我们一直让 LLM 既干活又管协调,但协调这件事不应该住在上下文窗口里。
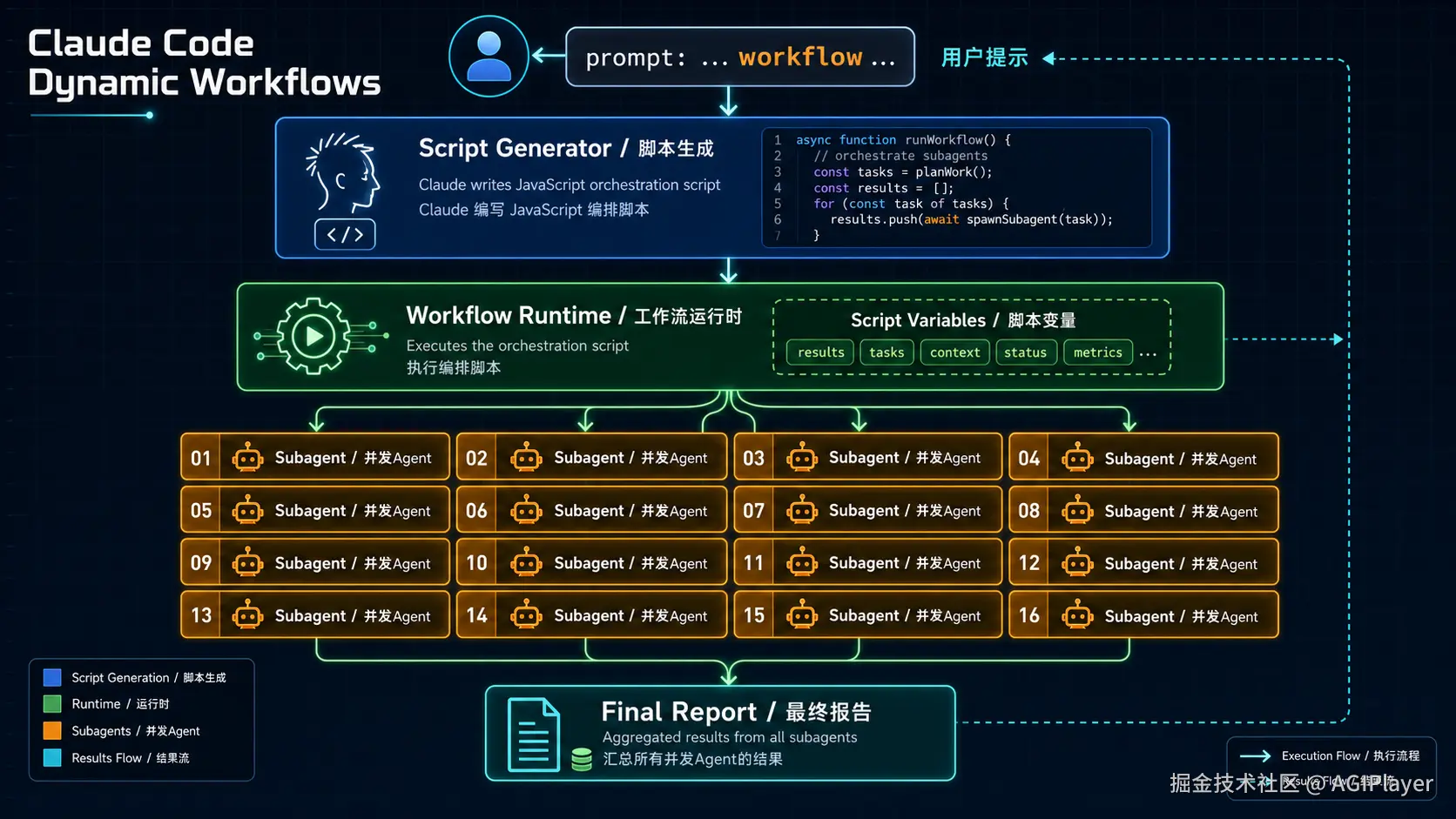 Claude Code Dynamic Workflows 系统架构
Claude Code Dynamic Workflows 系统架构
一. 先搞清楚:Workflow 到底是什么
Dynamic Workflow 就是一段 JavaScript 脚本。你用自然语言描述任务,Claude 帮你写脚本,一个运行时在隔离环境里执行它。脚本本身不直接访问文件系统或 Shell,它通过调度 Subagent 来干活,每个 Subagent 有自己的上下文窗口,结果回到脚本变量里,只有最终报告回到你的对话。
这跟之前的方案有什么本质区别?看这张对比图:
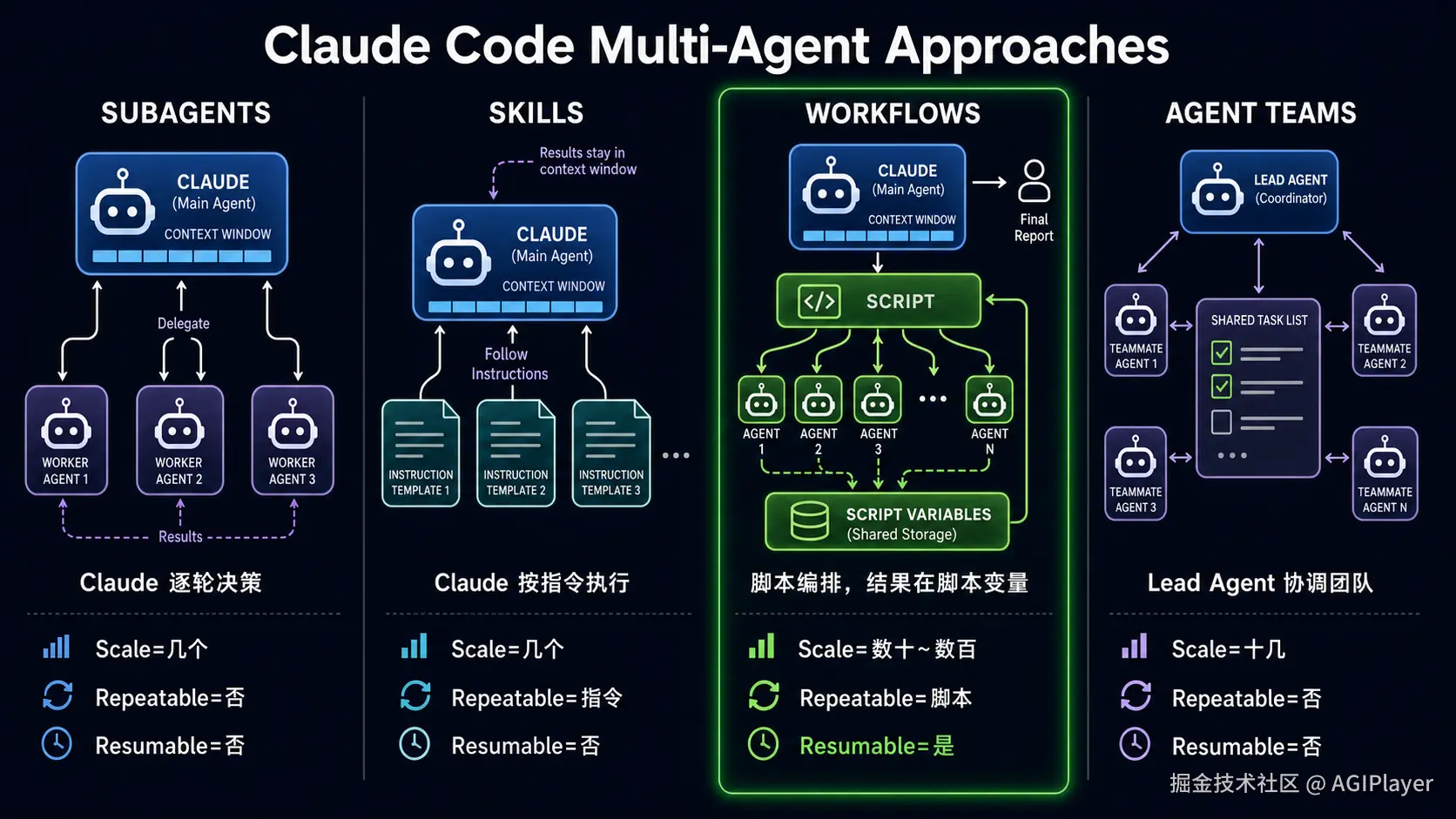 Subagents、Skills、Workflows、Agent Teams 四种方案对比
Subagents、Skills、Workflows、Agent Teams 四种方案对比
核心差异在一个维度:谁持有编排计划,中间结果存在哪。
| Subagents | Skills | Workflows | Agent Teams | |
|---|---|---|---|---|
| 谁决定下一步 | Claude 逐轮决策 | Claude 按指令执行 | 脚本 | Lead Agent |
| 中间结果存在哪 | 上下文窗口 | 上下文窗口 | 脚本变量 | 各 Agent 上下文 |
| 规模 | 几个 | 几个 | 数十~数百 | 十几个 |
| 可暂停恢复 | 否 | 否 | 是 | 否 |
| 可复现 | 仅 worker 定义 | 仅指令 | 脚本即编排 | 否 |
用一句话说:Subagents 是委派,Skills 是模板,Agent Teams 是协作,Workflows 是编排代码化。
当编排逻辑变成代码,你就获得了一种之前没有的能力------可复现的质量模式。比如让两组独立的 Agent 互相审查对方的结论,或者从三个角度独立设计方案然后投票选优。这种"交叉验证"在上下文窗口里是做不了的,因为你没法让同一个 Claude 实例同时扮演审计者和被审计者。
二. 什么时候该用 Workflow
不是所有任务都需要 Workflow。说实话,大部分日常编码任务,直接对话就够了。我的判断标准很简单:
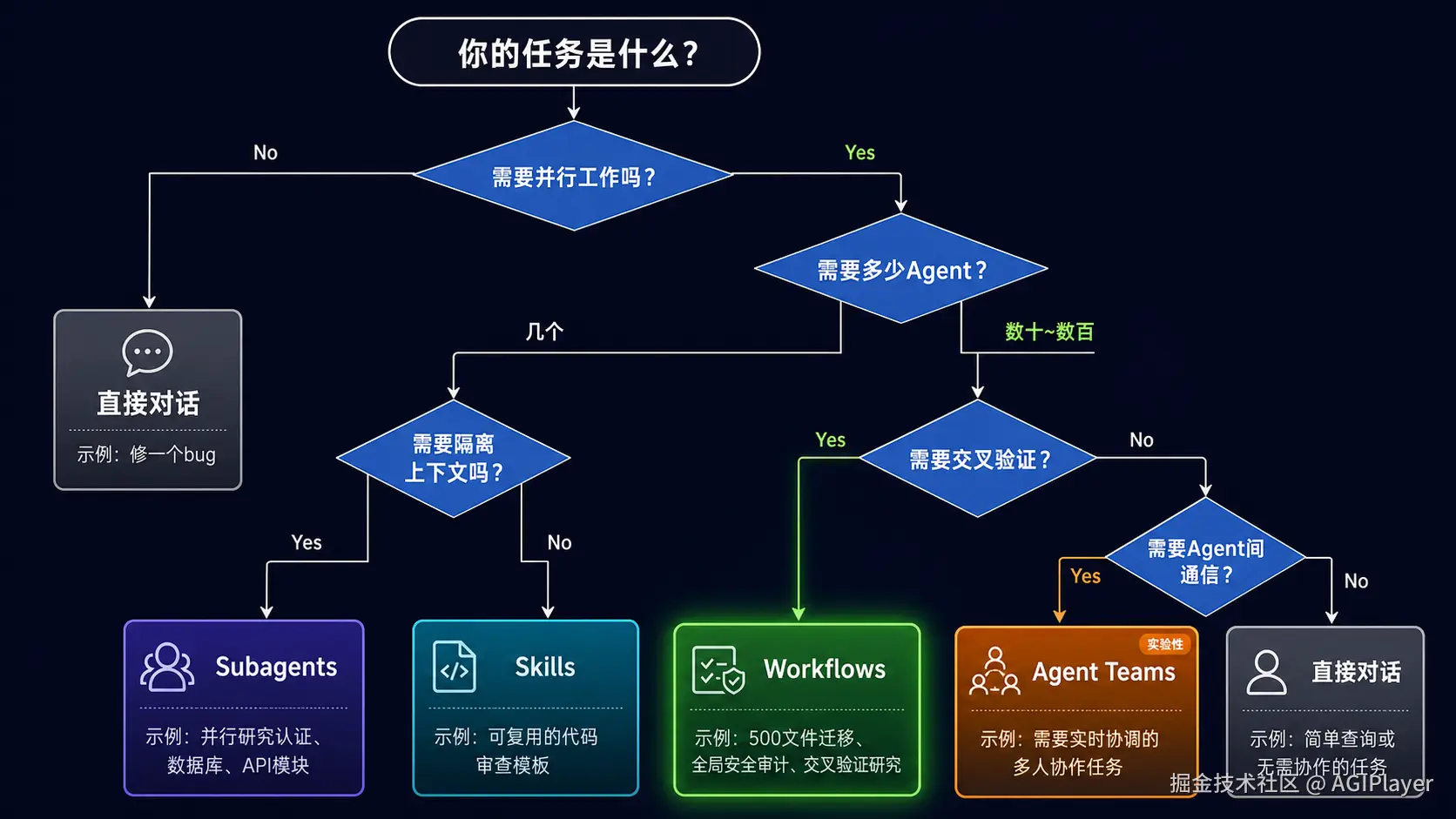 多Agent方案选型决策树
多Agent方案选型决策树
适合用 Workflow 的场景:
代码库全局审计------扫描所有路由的鉴权、所有 API 的错误处理、所有模块的安全漏洞。这种任务的特点是:规模大、模式重复、需要交叉验证。
大规模迁移------500 个文件从 CommonJS 改 ESM、全量 API 版本升级。这种任务的模式是固定的,可以用脚本编码编排逻辑。
交叉验证研究------从多个独立角度调查问题,Agent 之间互审结论。这是 Workflow 独有的优势,其他方案做不了。
多角度方案对比------从性能、安全、可维护性三个角度各自设计方案,然后投票选优。
不适合的场景:
简单的几步操作,直接对话或一两个 Subagent 就能搞定。
需要频繁人工介入的阶段间决策------Workflow 运行中不支持用户输入,只能暂停。如果需要每步都确认,不如拆成多个 Workflow 分段跑。
成本敏感的场景------16 个并发 Agent 意味着 16 倍 Token 消耗,后面我会详细聊这个。
三. 怎么用:三种触发方式
最快上手:/deep-research
直接输入:
bash
/deep-research Node.js v20 到 v22 的权限模型有什么变化?这是 Claude Code 内置的 Workflow 命令。它的工作流程很清晰:
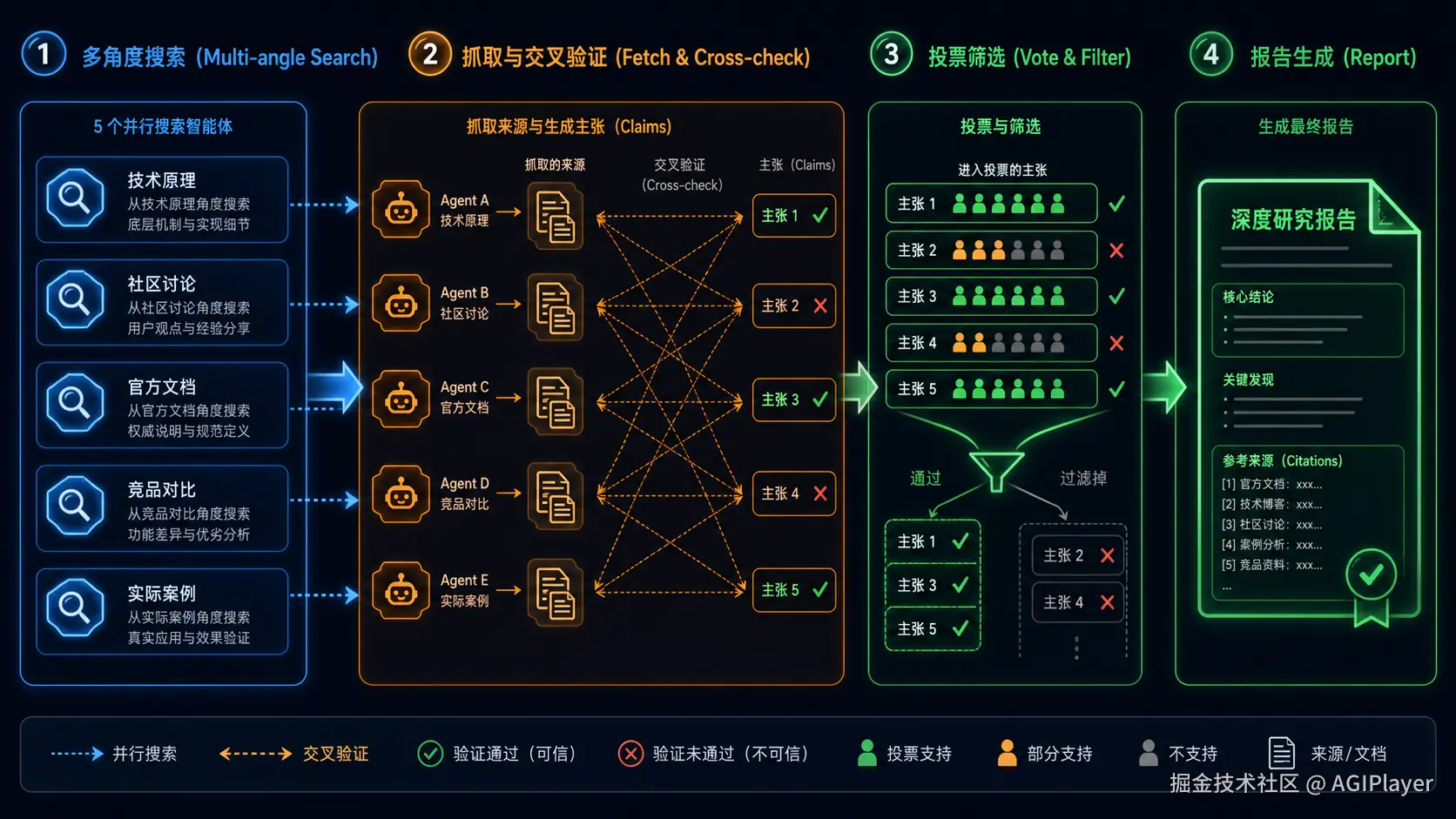 /deep-research 四阶段工作流
/deep-research 四阶段工作流
- 多角度搜索:从技术原理、社区讨论、官方文档、竞品对比、实际案例等角度并行搜索
- 抓取与交叉验证:Agent 们抓取来源,互相验证每个声明
- 投票筛选:未通过交叉验证的声明被过滤掉
- 报告生成:输出带引用的最终报告
运行期间你的对话保持可用,不受阻塞。你可以继续做其他事。
在 prompt 中触发
在任意提示词中包含 workflow 关键字:
css
Run a workflow to audit every API endpoint under src/routes/ for missing auth checksClaude 会高亮 workflow 这个词,然后自动编写 Workflow 脚本。如果误触发,按 alt+w 忽略。
全自动模式:Ultracode
bash
/effort ultracodeUltracode 等于 xhigh 推理强度 + 自动 Workflow 编排。开启后,Claude 对每个实质性任务自动规划 Workflow。一个请求可能触发多个 Workflow 串联:一个理解代码、一个做改动、一个做验证。
但说实话,我不建议日常开着 Ultracode。它的 Token 消耗很猛,适合那种"这个任务我必须一次搞定"的场景。日常编码用 /effort high 就够了,遇到真正的大任务再手动触发 Workflow。
注意,Ultracode 是 session 级别的,退出或新开会话后重置。仅支持 xhigh effort 的模型(目前是 Opus 4.8 和 Opus 4.7)。
四. 运行管理:审批、监控、暂停恢复
审批机制
第一次运行时,CLI 会展示计划的阶段列表,你可以选择:
- Yes, run it --- 开始运行
- Yes, and don't ask again --- 跳过该 Workflow 的后续审批
- View raw script --- 先看脚本再决定
- No --- 取消
我强烈建议第一次运行时选 View raw script。理解 Claude 编排了什么,比盲目信任重要得多。Ctrl+G 可以在编辑器中查看脚本,Tab 可以在运行前调整 prompt。
不同权限模式下审批行为不一样:
| 权限模式 | 是否弹出审批 |
|---|---|
| Default / Accept Edits | 每次都弹 |
| Auto | 仅首次;Ultracode 下跳过 |
Bypass / -p / Agent SDK |
从不弹出 |
还有一个细节值得注意:Workflow 的 Subagent 固定运行在 acceptEdits 模式,继承你的 tool allowlist,文件编辑自动批准。Shell 命令、Web 请求、不在 allowlist 里的 MCP 工具仍然会中途弹提示。长时间运行前,最好把这些命令提前加到 allowlist 里。
监控运行
bash
/workflows进度视图展示每个阶段的 Agent 数量、Token 消耗和耗时。操作键:
| 键 | 功能 |
|---|---|
↑/↓ |
选择阶段或 Agent |
Enter/→ |
钻入详情 |
p |
暂停/恢复 |
x |
停止单个 Agent 或整个 Workflow |
r |
重启选中的 Agent |
s |
保存脚本为命令 |
暂停与恢复
这是 Workflow 相比其他方案的独特优势。停止后可以恢复------已完成的 Agent 返回缓存结果,剩余的继续运行。但这只在同一 Claude Code 会话内有效,退出后重开会从头跑。
这个设计很务实。想象一下,你跑了一个 200 个 Agent 的审计任务,跑到第 150 个发现需要调整------如果是 Subagent 你得全部重来,Workflow 只需要恢复然后从 151 继续。
五. 保存与复用:从一次性到可重复
当一次 Workflow 运行产出了你满意的结果,在 /workflows 里选中它按 s 即可保存。保存位置有两个:
- 项目级
.claude/workflows/--- 随仓库共享给团队 - 用户级
~/.claude/workflows/--- 仅自己可见,所有项目可用
保存后,该 Workflow 变成 /<name> 命令,出现在 / 自动补全中。同名时项目级优先。
这个功能特别适合这些场景:
每个分支都要跑的代码审查流程------保存成 /security-audit,以后一个命令搞定。
定期执行的迁移检查------保存成 /migration-check,不用每次重新描述任务。
团队共享的标准化流程------提交到 .claude/workflows/,clone 仓库就能用。
六. 运行时约束与设计哲学
Workflow 运行时有几个硬约束,理解它们很重要:
| 约束 | 原因 |
|---|---|
| 不允许运行中用户输入 | 只有权限提示可以暂停 |
| 脚本无直接文件系统/Shell 访问 | Agent 负责读写,脚本只负责协调 |
| 最多 16 个并发 Agent | 限制本地资源 |
| 单次运行最多 1000 个 Agent | 防止失控循环 |
这些约束体现了一个设计哲学:脚本是编排者,不是执行者。 它只决定"谁做什么、谁先谁后、结果怎么交叉验证",具体的读写和计算全部交给 Agent。
不允许运行中用户输入这个约束,看起来是个限制,但其实是正确的工程取舍。如果你需要阶段间审批,就把大任务拆成多个 Workflow,每个阶段跑一个。这比让一个 Workflow 等待用户输入要清晰得多------每个 Workflow 的输入输出是确定的,更容易调试和复现。
七. 成本:必须认真对待
Workflow 会大量调度 Agent,Token 消耗远超逐步处理同一任务。
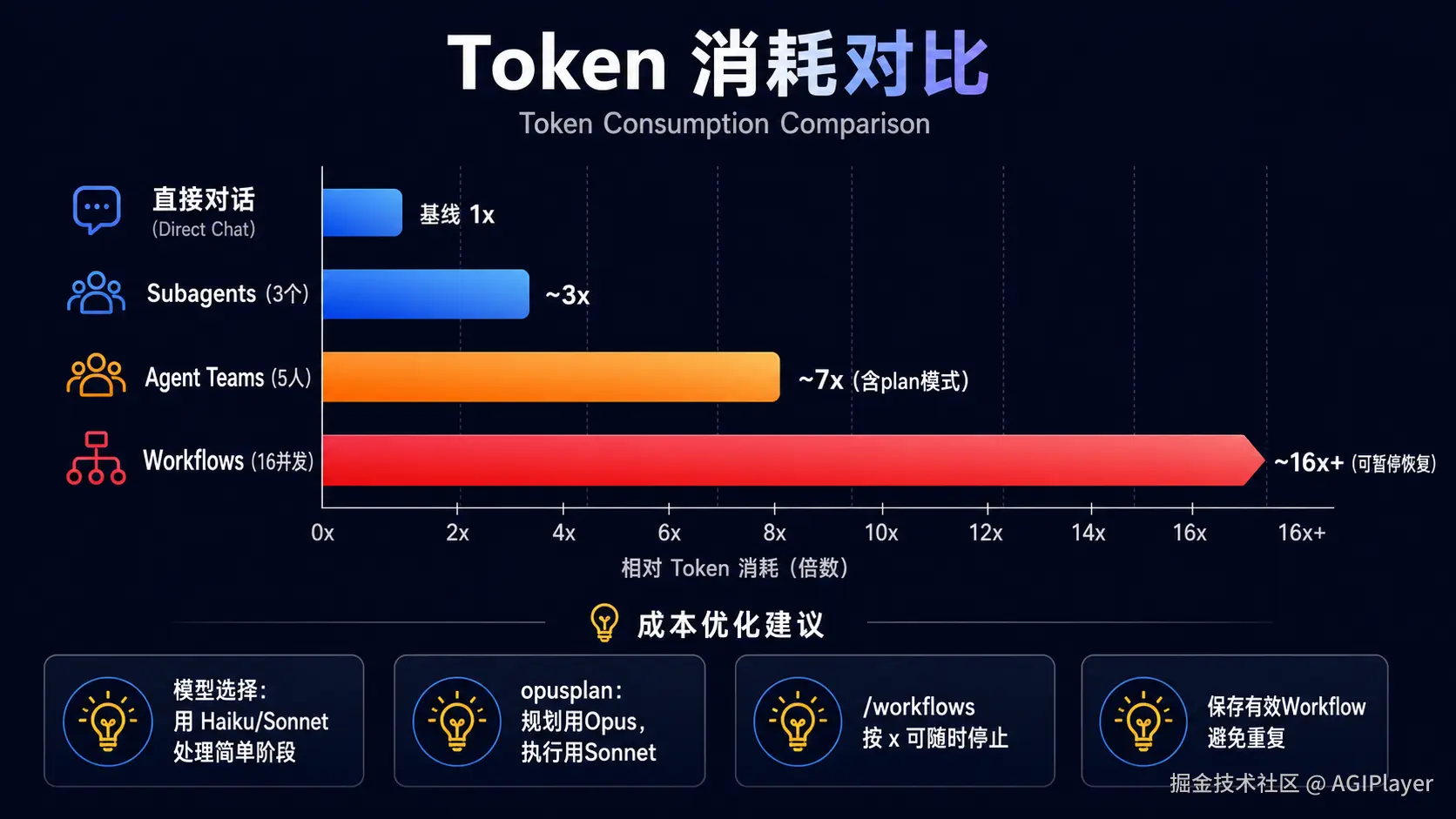 不同方案的 Token 消耗对比
不同方案的 Token 消耗对比
举个直观的例子:一个 16 并发的 Workflow,每个 Agent 平均消耗 50K Token,一轮就是 800K Token。如果跑 5 轮,就是 4M Token。这个消耗在 Opus 4.8 上是相当可观的。
我的成本控制策略:
模型分级:对只读扫描类阶段用 Haiku 或 Sonnet,只在需要深度推理的阶段用 Opus。在描述任务时可以指定,比如"对简单阶段用 Haiku"。
opusplan 的妙用:规划阶段用 Opus 深度推理,执行阶段自动切到 Sonnet。这是性价比最高的模式。
随时可停 :/workflows 中按 x 停止,已完成的工作不丢失。
不要 Ultracode 日常用:Ultracode 对每个任务都自动规划 Workflow,Token 消耗会爆炸。只在"这个任务我必须一次搞定"的时候开。
运行前检查 /model:如果你日常会用更便宜的模型,大运行前确认当前模型。
还有一个容易被忽略的点:所有 Workflow Agent 默认使用你的会话模型。如果你当前是 Opus 4.8,16 个并发 Agent 都用 Opus 4.8,成本会非常惊人。大任务前切到 Sonnet,或者让 Claude 在脚本里对不需要深度推理的阶段指定更小的模型。
八. 与竞品的本质差异
这不是 Claude Code 第一次做多 Agent。Cursor 有 Agent 模式,Codex CLI 支持并行任务,Amp 也在做类似的事。但 Workflow 的思路跟它们有一个根本区别。
Cursor 和 Codex 的多 Agent 本质上是"并行执行"------同时跑多个任务,各自独立完成。这解决的是速度问题。
Workflow 解决的是另一个问题:编排的可复现性和质量保证。
当你把编排逻辑编码为脚本,你获得的不只是"更快",还有:
可审查:脚本可以在运行前检查,你可以看到每个阶段做什么、Agent 之间怎么交互。
可复现:同样的脚本,同样的输入,产出同样的编排逻辑。不是每次都依赖 LLM 的"灵光一现"。
可交叉验证:让两组独立 Agent 互审结论,这种质量模式可以编码到脚本里,而不是靠提示词祈祷。
可暂停恢复:大任务跑到一半发现需要调整,不需要从头来过。
这些能力是"编排代码化"带来的,不是"多 Agent 并行"带来的。并行只是手段,代码化编排才是核心。
九. 实战建议
如果你准备开始用 Workflow,我的建议是这样的:
先用 /deep-research 感受。 最零成本的理解方式。问它一个你真正关心的问题,观察 Agent 怎么分阶段工作、怎么交叉验证。这个过程比看任何文档都直观。
从具体任务入手。 别上来就 Ultracode。先用 workflow 关键字触发单次任务,比如"workflow audit all API endpoints for auth checks"。确认效果后再考虑保存复用。
第一次运行时选 View raw script。 理解 Claude 编排了什么,这比盲目信任更安全。脚本就是普通 JavaScript,你完全能看懂。
保存有效的 Workflow。 一旦某次运行产出了你满意的结果,立刻按 s 保存。下次不用重新描述任务,一个命令搞定。
大任务前清理上下文。 /clear 开新会话再跑大 Workflow,减少无关 Token 消耗。主对话的上下文窗口应该留给最终报告,不是留给之前的闲聊。
合理选择模型。 对只读扫描类阶段指定 Haiku/Sonnet,只在需要深度推理的阶段用 Opus。这是成本控制最直接的手段。
注意权限配置。 长时间运行的 Workflow 如果中途弹出 Shell 权限提示而你不在旁边,会卡住。提前把需要的命令加到 allowlist 里。
十. 局限性与期待
坦率地说,Workflow 目前还有几个明显的局限。
Research Preview 状态。 行为可能变化,API 不稳定,不建议在生产环境强依赖。
同会话内才能恢复。 暂停后可以恢复,但只限同一 Claude Code 会话。退出后重开会从头跑。如果能在跨会话间恢复,对长时间运行的任务会友好得多。
不支持运行中交互。 如果你需要在阶段之间做审批决策,只能拆成多个 Workflow。这在某些场景下不够灵活。
脚本对用户不可编辑(目前)。 Claude 写完脚本你就只能看,不能直接改。如果你想调整编排逻辑,只能通过修改 prompt 重新生成。
Token 消耗不低。 16 并发 Opus 的成本不是开玩笑的。希望未来能支持在脚本层面更细粒度地控制每个阶段的模型选择。
但话说回来,这些局限都不影响 Workflow 的核心价值------把编排逻辑从 LLM 的上下文窗口搬到代码里。这个方向是对的。
当系统复杂度上升,协调成本会指数级增长。这不是靠更强的模型能解决的,因为问题不在模型能力,而在架构。Workflow 做的事,本质上就是把"谁来做什么、谁先谁后、结果怎么验证"这件事从 LLM 的黑箱推理变成可审查的代码逻辑。
这让我想起分布式系统里的一个经典教训:协调逻辑应该是显式的,不是隐式的。 你不会把服务编排逻辑藏在某个微服务的大脑里,你会用 Kubernetes manifest 或者 DAG 配置来声明。Workflow 对 Agent 编排做的,是同样的事。
回到开头那个问题------为什么我的 Agent 总是协调不好?
现在看来,问题不在 Agent 能力不够,而在我们一直让 LLM 同时干两件事:执行任务和协调任务。当任务规模超过一定阈值,这两件事就开始互相干扰。
Workflow 的答案是:执行交给 Agent,协调交给代码。
如果你也在做多 Agent 系统,我觉得这个思路值得认真想想。至少对我而言,那 200 个 API 端点的安全审计,从"跑了十几个就上下文爆炸"变成了一次 Workflow 搞定,结果还比之前更可靠------因为两组 Agent 交叉验证了每个发现。
有时候解决复杂问题的方法不是更复杂的推理,而是更简单的架构。
参考资料
- Claude Code 官方文档 - Dynamic Workflows
- Claude Code 官方文档 - Run Agents in Parallel
- Claude Code 官方文档 - Create Custom Subagents
- Claude Code 官方文档 - Model Configuration
- Claude Code 官方文档 - Manage Costs
- Claude Code Changelog - v2.1.154
话题标签:#ClaudeCode #Agent #Workflow #AI工程 #多Agent编排