摘要
很多 RAG 知识库看起来很好用:上传文档、解析文本、切分 chunk、向量化、检索、让大模型回答。只要问题简单,系统通常能给出一段看起来合理的答案。
但在真实业务场景里,问题会很快变复杂。用户不一定只问一个文档里的一个简单事实,他可能会问跨页条大模型"的方案就会暴露问题:答案看起来有道理,但引用对不上;溯源只显示"片段 3"或者"第 5 页",用户无法判断答案到底来自哪里;一个完整条款被切成两个 chunk 后,大模型只能拿到半截上下文,然后开始补全和猜测。
对一个 RAG 知识库来说,无法溯源的回答,本质上就是不可信的回答。
这篇文章记录的是我在项目中对 RAG 检索链路的一次重构:从最开始的 Apache Tika 统一解析、Spring AI 默认切分、直接写入 Milvus,改造成按文档类型差异化解析、父子块切分、混合检索命中子块、父块回查补全上下文、evidence_id 强制引用、引用后处理校验、Ragas 自动评测闭环的一整套可信检索流程。
改造后的效果

背景:RAG 不只是能回答,还要能验证
项目最开始的知识库链路比较直接:
用户上传 PDF、DOCX、Markdown 等文档,系统通过 Apache Tika 读取文本,然后使用 Spring AI 默认切分策略切成 chunk,再生成向量写入 Milvus。查询时,根据用户问题做向量检索,拿到若干 chunk 后拼进 prompt,让大模型生成答案。
这个方案在简单问题上没有太大问题。
比如用户问:
某个标记代表什么含义?
如果对应文本刚好完整落在一个 chunk 里,模型通常能直接回答。
但一旦问题稍微复杂,问题就开始出现:
某个条款的适用条件是什么?
某个规则在不同页面里是怎么描述的?
某个字段在多个文档中是否有冲突?
某个结论能不能回到原文验证?
这时候,系统经常会出现几类问题。
第一,答案看起来合理,但引用对不上。模型可能回答了一段非常流畅的内容,但引用只显示"片段 3"或者"第 5 页",用户点进去后发现原文并不能完全支撑答案。
第二,文档结构丢失。标题、章节、页码、表格、列表、代码块这些结构信息,在解析和切分后变成了普通文本。检索命中的 chunk 只是一段孤立文本,不知道它属于哪个章节,也不知道上下文是什么。
第三,完整语义被切断。固定窗口切分会把一个完整条款、一个表格说明、一个跨页段落切成多个 chunk。检索命中其中一段时,模型拿不到完整语义,只能依靠自身语言能力补齐。
第四,引用粒度不可控。向量检索命中的是 chunk,但用户需要的是可验证的文档位置。只返回 chunk 文本并不能说明这段内容来自哪个文档、哪个章节、哪个页码范围、哪个父块或哪个证据片段。
这些问题最后都会汇聚成一个核心问题:
RAG 系统不是不能回答,而是回答不能被验证。
对于知识库系统,尤其是面向制度、标准、报告、条款类文档的知识库,回答不能验证就意味着不可信。
旧方案的问题
项目早期的链路可以简化成这样:
文档上传
↓
Apache Tika 解析
↓
Spring AI 默认切分
↓
生成 Embedding
↓
写入 Milvus
↓
向量检索 chunk
↓
拼接 chunk 给大模型
↓
生成答案这条链路的优点是简单,开发速度快,适合快速验证知识库问答能否跑通。
但真实使用后,我发现它有几个明显缺陷。
所有文档走同一种解析逻辑
PDF、Word、Markdown、扫描件 PDF,本质上是完全不同的文档形态。
PDF 需要关注页码、版面、跨页内容、表格区域;Word 有 heading 样式、段落层级、表格;Markdown 有标题树、frontmatter、代码块、列表;扫描件 PDF 甚至没有可直接读取的文本,需要 OCR。
如果所有文档都直接交给 Tika 解析,最后得到的往往只是一大段线性文本。这样虽然能被切分和向量化,但文档原有结构已经丢失。
默认 chunk 只解决了"能切",没有解决"怎么切才适合回答"
固定窗口切分或者递归切分可以把长文本切成模型能处理的小块,但它并不理解业务语义。
一个条款可能被切成两段;一个表格说明可能和表格主体分离;一个章节标题可能在上一个 chunk,正文在下一个 chunk;跨页内容可能被硬切。
简单问题不明显,复杂问题就会出错。
检索粒度和回答粒度冲突
向量检索喜欢小 chunk。chunk 越小,语义越集中,召回越精准。
但大模型回答需要完整上下文。chunk 太小,模型拿不到足够背景,很容易基于半截内容生成看似合理但不完整的答案。
这里存在一个天然矛盾:
小 chunk 适合检索,但不适合回答。
大 chunk 适合回答,但不适合精准召回。旧方案没有解决这个矛盾,而是直接把检索到的小 chunk 喂给模型。
溯源只是展示片段,不是真正可验证
旧方案里,溯源信息更像是"检索结果展示",而不是"答案证据约束"。
模型可以引用某个片段,但系统并没有严格校验:
模型声明的引用是否真的存在?
引用内容是否来自候选文档?
这条引用是否能打开到原文位置?
同一个位置的多条引用是否需要合并?
如果没有页码,应该如何降级展示?所以用户看到的引用可能只是"片段 N",而不是可以验证的证据链。
改造目标
这次重构的目标不是简单替换一个切分器,也不是单纯换一个向量库,而是重构整个文档解析、切分、向量化、检索、溯源链路。
核心目标有四个。
第一,文档解析要尽量保留结构。不同格式的文档要走不同解析策略,尽可能保留标题层级、面包屑、页码范围、表格、代码块、列表等信息。
第二,切分策略要同时兼顾检索和回答。不能只为了向量检索切很小,也不能只为了上下文完整切很大,而是要把检索粒度和回答粒度拆开。
第三,检索结果要能回查完整上下文。向量库命中的可以是子块,但最终喂给模型的应该是语义更完整的父块。
第四,引用必须可校验、可定位、可展示。模型不能随便编引用,生成答案时只能引用候选证据中的 evidence_id,后处理阶段还要验证引用是否存在,并把引用映射回文档位置。
最终希望达到的效果是:
从"把碎片化 chunk 扔给 LLM,让它自己猜"
变成
"用子块召回,用父块回答,用 evidence_id 约束引用"整体架构
重构后的链路可以分成四层:
文档解析层
↓
结构化切分层
↓
检索回查层
↓
强制溯源层整体流程如下:
文档上传
↓
文档类型识别
↓
差异化解析策略
↓
生成结构化 ParsedDocument / ParsedSection
↓
构建父块 ParentChunk
↓
父块切分为子块 ChildChunk
↓
子块生成稠密向量和稀疏向量
↓
子块写入 Milvus
↓
父块写入 MySQL
↓
用户提问
↓
Milvus 混合检索命中子块
↓
按 parent_chunk_id 聚合去重
↓
批量回查 MySQL 父块
↓
组装父块上下文和 child 级证据
↓
LLM 基于候选证据回答
↓
校验 evidence_id
↓
渲染可验证引用文档解析层:不同文档不能用同一种解析方式
旧方案里,文档解析基本是统一交给 Tika 处理。Tika 的好处是通用,能快速从多种格式里抽取文本;但它的问题也很明显:通用解析通常不理解业务结构。
对于 RAG 知识库来说,解析层不能只产出一段纯文本,而是应该尽量产出结构化中间结果。
我把文档解析层改造成策略模式,不同类型的文档进入不同解析策略:
markdown
PDF 文档
- 标准 PDF:走文本解析通道
- 扫描件 PDF:走 OCR 解析通道
Word 文档
- 通过 POI 读取 heading 样式
- 按标题层级切分为逻辑 Section
- 构建面包屑导航
- 表格内容转为 Markdown
Markdown 文档
- 通过 CommonMark AST 解析标题树
- 读取 YAML frontmatter 标题
- 按标题层级切分
- 保留代码块、列表、表格格式
兜底策略
- 无法识别结构时使用 Tika + 固定窗口切分这样做的目的不是为了代码设计好看,而是为了让后续 chunk 携带更多可用元数据。
比如一个 chunk 不再只是:
这是某段正文内容。而是可以知道:
bash
它来自哪个文档
属于哪个章节
标题路径是什么
页码范围是什么
是否来自表格
是否来自 OCR
它在父块中的位置
它的证据 id 是什么这些信息后面都会参与检索、上下文组装和溯源展示。
【文档解析策略接口】
arduino
public interface FileParseStrategy {
//策略模式,每种文件格式即为一种策略
ChunkUtils.ParentChildDocuments readAndSplit(String fileType, EtlPipeline.EtlContext ctx);
boolean supports(String fileType);
}【解析策略路由代码】
typescript
public FileParseStrategy getFileParseStrategy(String fileType) {
FileParseStrategy result = getFileParseStrategyOrNull(fileType);
if (result == null) {
throw new IllegalStateException("Unsupported file type: " + fileType);
}
return result;
}
public FileParseStrategy getFileParseStrategyOrNull(String fileType) {
for (FileParseStrategy strategy : strategies) {
if (strategy.supports(fileType)) {
return strategy;
}
}
return null;
}【PDF 标准件和扫描件判断逻辑】
ini
public ScanAnalysis analyze(Path path) throws IOException {
try (PDDocument document = Loader.loadPDF(path.toFile())) {
// 使用 PDFBox 尝试提取内嵌文本层
PDFTextStripper stripper = new PDFTextStripper();
String extractedText = stripper.getText(document);
// 统计有意义的字符数(排除空白和控制字符)
int meaningfulChars = countMeaningfulChars(extractedText);
int pageCount = Math.max(document.getNumberOfPages(), 1);
double averageMeaningfulCharsPerPage = meaningfulChars / (double) pageCount;
// 核心判定:每页平均有意义字符数低于阈值 → 判定为扫描件(图片PDF,无文本层)
boolean scanDetected = averageMeaningfulCharsPerPage < ocrProperties.getPdf().getNativeTextThreshold();
return new ScanAnalysis(scanDetected, meaningfulChars, pageCount, averageMeaningfulCharsPerPage);
}
}【Word heading 解析逻辑】
ini
private List<Section> splitByHeadingStyles(XWPFDocument doc) {
List<IBodyElement> elements = doc.getBodyElements();
List<Section> sections = new ArrayList<>();
// 面包屑栈:记录当前所处的一级标题路径(如 ["第三章 员工纪律"])
List<String> breadcrumb = new ArrayList<>();
SectionBuilder currentSection = null;
// 标记文档是否有任何标题结构,无标题则走固定窗口兜底
boolean hasHeadingStructure = false;
for (IBodyElement element : elements) {
if (element instanceof XWPFParagraph paragraph) {
String styleId = paragraph.getStyleID();
// 根据 Word 样式 ID(如 "Heading1"、"heading 2")识别标题层级
int headingLevel = detectHeadingLevel(styleId);
if (headingLevel == 1) {
// 一级标题:清空面包屑,开始全新的章节上下文
if (currentSection != null && currentSection.hasContent()) {
sections.add(currentSection.build());
}
breadcrumb.clear();
breadcrumb.add(paragraph.getText().trim());
currentSection = null;
hasHeadingStructure = true;
} else if (headingLevel > 1 && headingLevel <= HEADING_LEVEL) {
// 二级标题:作为新 Section 的边界,继承当前一级标题面包屑
hasHeadingStructure = true;
if (currentSection != null && currentSection.hasContent()) {
sections.add(currentSection.build());
}
List<String> sectionBreadcrumb = new ArrayList<>(breadcrumb);
sectionBreadcrumb.add(paragraph.getText().trim());
currentSection = new SectionBuilder(sectionBreadcrumb, paragraph.getText().trim());
} else {
// 正文段落:归属于当前 Section
if (currentSection == null) {
currentSection = new SectionBuilder(new ArrayList<>(breadcrumb), null);
}
currentSection.appendParagraph(paragraph);
}
} else if (element instanceof XWPFTable table) {
// 表格:同样归属于当前 Section,转换为 Markdown 表格
if (currentSection == null) {
currentSection = new SectionBuilder(new ArrayList<>(breadcrumb), null);
}
currentSection.appendTable(table);
}
}
// 收尾:提交最后一个 Section
if (currentSection != null && currentSection.hasContent()) {
sections.add(currentSection.build());
}
// 文档中完全没有标题结构 → 返回空列表,调用方走固定窗口兜底
if (!hasHeadingStructure) {
return List.of();
}
return sections;
}【Markdown AST 解析逻辑】
ini
// 基于 CommonMark AST 的标题结构切分:遍历 AST 节点树,以 H1/H2 为 Section 边界
private List<Section> splitByHeadingStructure(String content, String breadcrumbRoot) {
List<Extension> extensions = List.of(YamlFrontMatterExtension.create());
Parser parser = Parser.builder().extensions(extensions).build();
// CommonMark 解析器将 Markdown 文本解析为 AST 节点树
Node document = parser.parse(content);
List<Section> sections = new ArrayList<>();
// 面包屑栈:记录当前所处的标题层级路径(如 ["数据安全", "处罚细则"])
List<String> breadcrumb = new ArrayList<>();
if (breadcrumbRoot != null) {
breadcrumb.add(breadcrumbRoot);
}
SectionBuilder currentSection = null;
// 标记是否至少有一个 H1~H2 标题,没有则走固定窗口兜底
boolean hasH2Plus = false;
for (Node node = document.getFirstChild(); node != null; node = node.getNext()) {
// 跳过 YAML frontmatter 块(已在 extractBreadcrumbRoot 中处理)
if (node instanceof YamlFrontMatterBlock) {
continue;
}
if (node instanceof Heading heading) {
int level = heading.getLevel();
String headingText = textContent(heading);
if (level <= HEADING_LEVEL) {
// H1 或 H2:作为新 Section 边界
hasH2Plus = true;
if (currentSection != null && currentSection.hasContent()) {
sections.add(currentSection.build());
}
// 构建当前 Section 的面包屑路径
List<String> sectionBreadcrumb = new ArrayList<>(breadcrumb);
sectionBreadcrumb.add(headingText);
currentSection = new SectionBuilder(sectionBreadcrumb, heading);
}
// 三级及以上标题也作为内容追加到当前 Section
if (currentSection != null) {
currentSection.appendNode(node);
}
} else {
// 非标题节点(段落、代码块、列表等):归属于当前 Section
if (currentSection == null) {
currentSection = new SectionBuilder(new ArrayList<>(breadcrumb), null);
}
currentSection.appendNode(node);
}
}
// 收尾:提交最后一个 Section
if (currentSection != null && currentSection.hasContent()) {
sections.add(currentSection.build());
}
// 文档中完全没有 H1~H2 标题 → 返回空列表,调用方走固定窗口兜底
if (!hasH2Plus) {
return List.of();
}
return sections;
}结构化中间模型:不要只保存 String
解析层重构后,需要拿到结构化的中间模型。
中间模型大致需要表达这些信息:
css
文档 id
文档名称
文档类型
文件地址
section id
section 标题
section 层级
面包屑路径
页码范围
正文内容
表格内容
代码块内容
额外 metadata切分层:从单层 chunk 改成父子块
旧方案最大的问题之一,是只有一层 chunk。
这一层 chunk 同时承担了两个职责:
用于向量检索
用于大模型回答但这两个目标天然冲突。如果 chunk 很小,检索更精准,但上下文不完整。如果 chunk 很大,上下文更完整,但向量语义会变散,召回效果下降,也更容易把无关内容带进 prompt。
所以我把 chunk 拆成两层,也就是所谓的父子块:
父块 ParentChunk:用于保留完整语义上下文
子块 ChildChunk:用于向量检索召回在我的项目中,父块大小约为 1200 字,200 字重叠,存入 MySQL,携带完整的面包屑和页范围元数据。
子块由父块继续切分生成,大小约为 200 字,80 字重叠,用于生成稠密向量和稀疏向量,并写入 Milvus。每个子块都记录它所属的 parent_chunk_id、document_id、evidence_id、content_hash 和文件位置信息。
父块负责完整语义
父块是回答时真正提供给模型的上下文单位。
一个父块应该尽量包含一个相对完整的语义片段,比如一个小节、一段条款、一个表格及其说明,或者一个连续的页面范围。
【父块表结构】
| 字段 | 含义 | 示例 |
|---|---|---|
| id | MySQL 主键 UUID | a1b2c3d4... |
| parent_block_id | 业务唯一标识 | doc-001:parent:3:d4e5f6 |
| doc_uuid | 所属文档 UUID | doc-001 |
| parent_index | 父块序号(从 1 开始) | 3 |
| content | 父块全文(1200 字) | 完整段落文本 |
| file_name | 源文件名 | 员工手册.pdf |
| page_start | 起始页(PDF 专有) | 15 |
| page_end | 结束页(PDF 专有) | 16 |
| space_code | 知识空间 | public |
| tags | 标签列表(JSON) | "制度", "HR" |
| acl_version | 权限版本号 | 1 |
| chunk_schema_version | Schema 版本 | 2 |
| create_date / update_date | 时间戳 | --- |
子块负责精准召回
子块是向量库中的检索单位。
子块可以更小,因为它不是最终回答上下文,而是负责帮助系统找到最相关的父块。
【子块 Milvus 向量集合】
arduino
metadata.put("doc_uuid", docUuid);
metadata.put("file_name", fileName);
metadata.put("space_code", ...);
metadata.put("owner_dept_id", ...);
metadata.put("allowed_roles", ...); // ACL 访问控制
metadata.put("allowed_dept_ids", ...); // ACL 访问控制
metadata.put("is_public", ...); // ACL 访问控制
metadata.put("acl_version", ...);
metadata.put("tags", ...);
// 从父块继承的定位信息
metadata.put("page_number", ...); // PDF 页码
metadata.put("page_start", ...); // PDF 起始页
metadata.put("page_end", ...); // PDF 结束页
metadata.put("parent_block_id", ...); // 关联父块
metadata.put("parent_index", ...); // 父块序号
metadata.put("child_index", ...); // 子块在父块内的序号
metadata.put("evidence_id", ...); // 溯源引用 ID
metadata.put("chunk_schema_version", ...);
metadata.put("source_location", ...); // 语义化溯源路径【父块切分为子块的核心代码】
less
@Override
public List<Document> apply(List<Document> documents) {
return documents.stream()
.flatMap(springDoc -> {
// 1. 元数据转换:Spring AI (Map<String, Object>) → LangChain4j (Map<String, String>)
Map<String, String> lcMetadata = new HashMap<>();
if (springDoc.getMetadata() != null) {
springDoc.getMetadata().forEach((k, v) -> lcMetadata.put(k, v != null ? v.toString() : ""));
}
dev.langchain4j.data.document.Document lcDoc = dev.langchain4j.data.document.Document
.from(springDoc.getText(), dev.langchain4j.data.document.Metadata.from(lcMetadata));
// 2. 核心切分:一个 Parent Document → 多个 TextSegment
List<TextSegment> segments = internalSplitter.split(lcDoc);
// 3. 每个 TextSegment 清洗后转为 Spring AI Document,子块继承父块的全部 metadata
return segments.stream()
.map(segment -> TextSanitizer.sanitize(segment.text()))
.filter(result -> !result.isEffectivelyEmpty())
.peek(result -> {
if (result.isLowQualityExtraction()) {
Object pageNumber = springDoc.getMetadata().get("page_number");
log.warn(
"Low-quality chunk after split: page={}, removedRatio={}, " +
"meaningfulCodePoints={}, sanitizedLength={}, preview={}",
pageNumber != null ? pageNumber : "unknown",
result.removedRatioPercent(),
result.meaningfulCodePoints(),
result.text().length(),
TextSanitizer.preview(result.text()));
}
})
.map(result -> {
Map<String, Object> springMetadata = sanitizeMetadata(springDoc.getMetadata());
// 子块继承父块的全部 metadata(parent_block_id、page_start 等)
return new Document(result.text(), springMetadata);
});
})
.collect(Collectors.toList());
}为什么不是直接把父块写入向量库
既然父块更完整,那为什么不直接向量化父块?
我没有这样做,原因是父块作为检索单位会带来两个问题。
第一,父块内容更长,语义更分散。用户问题可能只命中父块中的某一句话,但整个父块向量表达的是一大段混合语义,召回精度会下降。
第二,父块数量虽然更少,但每个父块进入 prompt 的成本更高。如果直接检索父块,很容易把不够精准的大段上下文带进模型,增加噪声。
所以最终采用的是:
子块用于检索
父块用于回答也就是先用小粒度子块找到相关位置,再回查大粒度父块补全上下文。
这个设计解决的是 RAG 中非常典型的粒度冲突问题:
检索需要精准
回答需要完整
溯源需要可定位向量化与入库:子块写 Milvus,父块写 MySQL
在入库阶段,父块和子块分别存储。父块存 MySQL,作为可回查的完整上下文,子块写 Milvus,作为向量检索单位。
子块写入 Milvus 时,不能只写向量和文本,还要写足够的标量字段。否则检索命中后,还要再去数据库查一遍 child 表才能知道它属于哪个父块,会增加一次不必要的数据库访问。
Milvus 检索返回后,可以直接拿到 parent_id、document_id、evidence_id 等信息,用于后续聚合和回查。
如果你的项目里没有 sparse vector,或者稀疏检索不是存 Milvus,而是走其他组件,需要如实改写。
检索层:命中子块,回查父块
查询时,用户问题不会直接检索父块,而是先检索子块。
流程如下:
erlang
用户问题
↓
生成 query embedding / sparse 表示
↓
Milvus 混合检索
↓
返回 child hits
↓
按 parent_id 聚合
↓
计算 parent score
↓
选取 topN parent
↓
批量回查 MySQL 父块
↓
组装上下文不要把 Milvus 返回的所有 child chunk 原样塞进 prompt,要按照 parent_id 聚合。
假设一次检索返回了这些结果:
rust
child_01 -> parent_10
child_02 -> parent_10
child_03 -> parent_11
child_04 -> parent_10
child_05 -> parent_20如果直接把 5 个 child 全部塞给模型,会出现两个问题:
同一个父块下的多个子块重复出现
上下文碎片化例如:
parent_10 命中 3 个子块
parent_11 命中 1 个子块
parent_20 命中 1 个子块然后根据子块得分计算父块候选得分。
父块得分可以简单使用命中子块的最高分,也可以综合考虑命中数量、向量得分、关键词得分、文档权重等因素。
【混合检索参数】
kotlin
// ---------- 配置参数 ----------
@Value("${spring.ai.vectorstore.milvus.collection-name:vector_store}")
private String collectionName; // Milvus 集合名
@Value("${rag.retrieval.dense-vector-field:embedding}")
private String denseVectorField; // Dense 向量字段名
@Value("${rag.retrieval.sparse-vector-field:sparse_vector}")
private String sparseVectorField; // Sparse 向量字段名
@Value("${rag.retrieval.dense-topk:50}")
private int topK; // 两路子查询各自取 50 条
@Value("${rag.retrieval.rrf-k:60}")
private int rrfK; // RRF 融合系数 k=60【子块回查父块聚合去重代码】
scss
// 子块回查父块:将检索命中的子块按 parent_block_id 去重聚合,批量查询 MySQL 获取完整父块上下文
private Mono<List<ParentContextBlock>> expandParentContexts(List<Document> childCandidates) {
if (childCandidates == null || childCandidates.isEmpty()) {
return Mono.just(List.of());
}
// 按 parent_block_id 去重聚合,同时收集每个父块下所有命中子块的 evidence_id
Map<String, ParentAccumulator> byParentId = new LinkedHashMap<>();
int rank = 0;
for (Document child : childCandidates) {
rank++;
Map<String, Object> metadata = child.getMetadata();
String parentBlockId = stringValue(metadata.get("parent_block_id"));
String evidenceId = evidenceId(child);
if (!StringUtils.hasText(parentBlockId) || !StringUtils.hasText(evidenceId)) {
return Mono.error(new ParentContextMissingException("知识库索引数据不一致,请重建该文档索引后重试。"));
}
int currentRank = rank;
// 首次遇到该 parent_block_id → 创建累加器,记录最佳排名
// 重复遇到 → 仅追加 evidence_id(同一父块下的不同子块均被命中)
ParentAccumulator accumulator = byParentId.computeIfAbsent(parentBlockId,
ignored -> new ParentAccumulator(parentBlockId, stringValue(metadata.get("doc_uuid")), currentRank));
accumulator.evidenceIds().add(evidenceId);
}
// 批量查询 MySQL,一次取出所有去重后的父块
List<String> parentBlockIds = new ArrayList<>(byParentId.keySet());
return parentBlockService.findByParentBlockIds(parentBlockIds)
.map(parentBlocks -> toParentContextBlocks(byParentId, parentBlocks));
}
// 将 MySQL 查询结果与累加器合并,校验 schema 版本和 docUuid 一致性
private List<ParentContextBlock> toParentContextBlocks(Map<String, ParentAccumulator> accumulators,
Map<String, KnowledgeParentBlock> parentBlocks) {
List<ParentContextBlock> contexts = new ArrayList<>();
for (ParentAccumulator accumulator : accumulators.values()) {
KnowledgeParentBlock parentBlock = parentBlocks.get(accumulator.parentBlockId());
// 校验:父块必须存在、schema 版本匹配、docUuid 一致(防止跨文档误关联)
if (parentBlock == null
|| parentBlock.getChunkSchemaVersion() == null
|| parentBlock.getChunkSchemaVersion() != KnowledgeParentBlockService.CHUNK_SCHEMA_VERSION
|| !Objects.equals(parentBlock.getDocUuid(), accumulator.docUuid())) {
throw new ParentContextMissingException("知识库索引数据不一致,请重建该文档索引后重试。");
}
contexts.add(new ParentContextBlock(
parentBlock.getParentBlockId(),
parentBlock.getDocUuid(),
parentBlock.getFileName(),
parentBlock.getContent(), // 1200 字完整段落,发给 LLM 推理
parentBlock.getParentIndex(),
parentBlock.getPageStart(),
parentBlock.getPageEnd(),
List.copyOf(accumulator.evidenceIds()), // 该父块下所有被命中的子块 evidence_id,供 LLM 引用
accumulator.bestRank())); // 该父块下最佳排名的子块排名,用于最终排序
}
return contexts;
}
private record ParentAccumulator(
String parentBlockId,
String docUuid,
int bestRank, // 该父块下最早被命中的子块排名(数字越小越靠前)
List<String> evidenceIds // 该父块下所有被命中子块的 evidence_id 集合
) {
private ParentAccumulator(String parentBlockId, String docUuid, int bestRank) {
this(parentBlockId, docUuid, bestRank, new ArrayList<>());
}
}Prompt 构造:给模型完整上下文,也给它证据边界
父块回查后,系统会构造 prompt 上下文。
这里有一个关键点:给模型的不是一堆无序 chunk,而是带结构的候选证据。
每个父块应该包含:
文档名称
章节路径
页码范围
父块内容
命中的 child evidence_id
child 命中文本模型在回答时,只能引用候选证据中出现过的 evidence_id。
这样做的目的是给模型一个明确边界:
你可以基于这些上下文回答
你只能引用这些 evidence_id
如果证据不足,需要说明无法确定
不能编造不存在的引用【Prompt 证据上下文构造代码】
scss
// 将父块上下文列表格式化为 LLM Prompt 中的结构化证据块
// 每个父块包含:来源文件+位置、parent_block_id、可引用的 evidence_id 列表、完整段落内容
public String formatParentContexts(List<ParentContextBlock> parentContexts) {
StringBuilder contextBuilder = new StringBuilder();
for (int i = 0; i < parentContexts.size(); i++) {
ParentContextBlock block = parentContexts.get(i);
String structuredEntry = String.format(
"""
【上下文块 %d】
来源: %s
parent_block_id: %s
可引用 evidence_id:
%s
内容: %s
------------------------
""",
i + 1,
sourceLabel(block), // 如 "员工手册.pdf · 第3-4页" 或 "保密协议.docx · 违约责任 > 赔偿标准"
block.parentBlockId(), // 父块唯一标识,LLM 不需要用,调试/追踪用
formatEvidenceIds(block.evidenceIds()), // 该父块下被命中的子块 evidence_id 清单,LLM 引用时用
block.content()); // 父块 1200 字完整段落,LLM 推理的核心依据
// 超长保护:上下文总长度超过 maxContextChars(40000) 时截断,避免撑爆 token 窗口
if (contextBuilder.length() + structuredEntry.length() > maxContextChars) {
log.warn("Parent context limit reached, dropping remaining parent blocks from rank {}", i);
break;
}
contextBuilder.append(structuredEntry);
}
return contextBuilder.toString();
}【系统提示词】
python
static String buildSourcedAnswerPrompt() {
return """
你是一个专业的"校园智能知识库问答助手"。你必须基于【知识库上下文】回答。
必须遵守:
1. 只能使用【知识库上下文】中的事实,不得编造或外推。
2. 如果知识库证据不足,answerType 输出 refusal,answer 简洁说明无法可靠回答,usedSources 输出 []。
3. 如果输出事实性回答,answerType 输出 factual,usedSources 至少包含一个来源。
4. 每个事实段落或列表项末尾必须带引用,格式为《文件名》第 X 页;没有页码时用《文件名》片段 N。
5. 每个事实段落或列表项最多展示 2 个引用。
6. usedSources 必须是字符串数组;每个字符串都必须来自上下文"可引用 evidence_id",不能创造新的 evidenceId。
7. 你必须且只能输出合法 JSON 对象,不要输出 Markdown 代码块或额外文字。
8. JSON 字段固定为 answer、answerType、usedSources。
9. answer 必填且不能为空;answerType 只能是 factual 或 refusal。
10. usedSources 只输出字符串数组,例如 ["docUuid:child:1:hash"];不要输出对象数组,不要输出 docUuid、fileName、pageNumber、fileType,也不要输出 parent_block_id。
11. 输出必须是单个 JSON object;第一个字符是英文左花括号,最后一个字符是英文右花括号。
12. factual 时 answerType=factual,answer 中必须包含段落引用,usedSources 必须列出实际采用的 evidenceId。
13. refusal 时 answerType=refusal,answer 说明当前知识库没有足够信息,usedSources 必须是空数组。
14. 不要输出内部思考、解释、代码块或 JSON 之外的任何文字。
================ 知识库上下文 ================
{context}
============================================
""";
}强制溯源:不能让模型自己编引用
仅靠 prompt 约束是不够的。
因为模型仍然可能输出不存在的 evidence_id,或者把某个证据 id 用在不相关的句子上。
所以生成答案后,还需要做后处理校验。
校验逻辑至少包括:
提取答案中的所有 evidence_id
检查每个 evidence_id 是否存在于候选证据列表
不存在则判定为非法引用
非法引用触发重试、删除、降级或报错这一步非常重要。
因为如果系统允许模型引用不存在的证据,那么溯源只是形式上存在,实际上仍然不可信。
【答案引用解析代码】
scss
// 验证 LLM 回答中的引用:确保每个 usedSources 中的 evidence_id 都在候选文档中存在
// 验证失败 → 抛异常,回答被拒绝,返回"无法可靠生成带溯源的答案"
public List<UsedSource> validate(SourcedAnswerResult result, List<Document> candidates) {
// 1. 回答必须有内容
if (result == null || !StringUtils.hasText(result.answer())) {
throw validationFailure(REASON_ANSWER_MISSING, null, candidates);
}
// 2. answerType 只能是 factual 或 refusal
boolean refusal = "refusal".equalsIgnoreCase(result.answerType());
boolean factual = "factual".equalsIgnoreCase(result.answerType());
if (!refusal && !factual) {
throw validationFailure(REASON_INVALID_ANSWER_TYPE, result, candidates);
}
List<String> requestedSources = result.usedSources() == null ? List.of() : result.usedSources();
// 3. refusal 不要求引用,直接通过
if (refusal) {
return List.of();
}
// 4. factual 必须有至少一个引用
if (requestedSources.isEmpty()) {
throw validationFailure(REASON_USED_SOURCES_EMPTY, result, candidates);
}
// 5. 将候选文档按 evidence_id 建索引,O(1) 查找
Map<String, Document> candidatesByEvidenceId = new LinkedHashMap<>();
for (Document candidate : candidates == null ? List.<Document>of() : candidates) {
String evidenceId = evidenceId(candidate);
if (StringUtils.hasText(evidenceId)) {
candidatesByEvidenceId.put(evidenceId, candidate);
}
}
// 6. 逐个验证 LLM 声明的 evidence_id 是否在候选集合中
List<UsedSource> validated = new ArrayList<>();
for (String requestedEvidenceId : requestedSources) {
// evidence_id 不能为空
if (!StringUtils.hasText(requestedEvidenceId)) {
throw validationFailure(REASON_EVIDENCE_ID_MISSING, result, candidates);
}
// evidence_id 必须在候选文档中存在(杜绝 LLM 幻觉引用)
Document candidate = candidatesByEvidenceId.get(requestedEvidenceId.trim());
if (candidate == null) {
throw validationFailure(REASON_EVIDENCE_ID_NOT_IN_CANDIDATES, result, candidates);
}
validated.add(fromDocument(candidate));
}
// 7. 同文档同位置的引用去重合并展示
return collapseDisplayedSources(validated);
}引用展示:从 evidence_id 映射回用户能看懂的位置
校验 evidence_id 存在,只是第一步。
用户真正关心的是:
这个引用来自哪个文档?
哪个章节?
第几页?
能不能打开原文?所以引用展示需要做一次渲染。
我采用了多级 fallback 策略:
优先展示精确位置
其次展示页范围
再次展示父块序号
最后回退到片段编号这样可以避免因为某些格式没有页码,就完全无法展示引用。
比如:
PDF:可以展示第 10-11 页
Word:可以展示章节路径 + 父块序号
Markdown:可以展示标题路径 + 片段编号
兜底文本:可以展示片段 N同时,同一文档同一位置的多条引用需要合并,避免用户看到一堆重复来源。
【引用位置 fallback 渲染代码】
dart
// 解析溯源展示位置:四级 fallback 链
// ① 显式 source_location(DOCX/MD 面包屑,如"学生纪律 > 开除程序")
// ② page_start/page_end(PDF 页码范围,如"3-4"或"5")
// ③ parent_index → "片段N"(无标题结构的非 PDF 文档)
// ④ page_number / page(最老数据的兜底兼容)
private Object sourceLocation(Map<String, Object> metadata) {
// ① 优先:语义化溯源路径(DOCX/MD 策略写入的面包屑)
Object sourceLocation = metadata.get("source_location");
if (sourceLocation != null && StringUtils.hasText(sourceLocation.toString())) {
return sourceLocation.toString().trim();
}
// ② 次选:PDF 页码范围
Object pageStart = metadata.get("page_start");
Object pageEnd = metadata.get("page_end");
if (pageStart != null && pageEnd != null) {
String start = pageStart.toString();
String end = pageEnd.toString();
// 单页 → 直接返回页码,跨页 → 返回"起始-结束"范围
return start.equals(end) ? pageStart : start + "-" + end;
}
// ③ 再次:通用 parent_index → "片段N"
Object parentIndex = metadata.get("parent_index");
if (parentIndex != null) {
return "片段" + parentIndex;
}
// ④ 兜底:旧版元数据的 page_number / page
return metadata.getOrDefault("page_number", metadata.get("page"));
}【同源引用去重合并代码】
typescript
// 同文档同位置的多个 evidence_id 只保留第一条(去重合并展示,避免溯源列表冗余)
private List<UsedSource> collapseDisplayedSources(List<UsedSource> sources) {
Map<String, UsedSource> unique = new LinkedHashMap<>();
for (UsedSource source : sources) {
if (source == null || !StringUtils.hasText(source.docUuid())) {
continue;
}
String key = source.docUuid() + "|" + (source.pageNumber() == null ? "" : source.pageNumber());
unique.putIfAbsent(key, source);
}
return List.copyOf(unique.values());
}【打开原文位置的实现方式】
typescript
// 格式化溯源引用标签:PDF 显示"文件名 · 第N页",DOCX/MD 显示"文件名 · 面包屑路径"
const formatSourceReference = (source: any) => {
const docUuid = source.doc_uuid || source.docUuid;
const title = docUuid ? (source.file_name || source.fileName || source.source || t("chat.document")) : t("chat.unknownSource");
const page = source.page_number || source.pageNumber;
if (page) {
if (isSegmentLocation(page)) {
return t("chat.sourceReferenceWithSegment", { title, segment: String(page) });
}
return t("chat.sourceReferenceWithPage", { title, page: formatPageValue(page) });
}
return t("chat.sourceReferenceWithoutPage", { title });
};
// 点击溯源标签时打开原文预览:PDF 定位到对应页面,非 PDF 直接打开文件
const openSource = async (source: SourceMeta) => {
const docUuid = source.doc_uuid || source.docUuid;
if (!docUuid) return;
try {
const page = source.page_number ?? source.pageNumber;
// 片段标签无法定位到具体页面,不带 page hash
await openDocPreview(String(docUuid), isSegmentLocation(page) ? undefined : page);
} catch (e) {
console.error(e);
ElMessage.error(t("chat.previewFailed"));
}
};一个完整查询请求的链路
重构后,一个查询请求的执行过程大致如下:
erlang
用户输入问题
↓
系统生成检索 query
↓
Milvus 混合检索命中 child chunk
↓
返回 child_id、parent_id、document_id、evidence_id、score、page_range 等字段
↓
按 parent_id 聚合 child hits
↓
计算 parent candidate score
↓
选择 topN parent
↓
批量回查 MySQL parent chunk
↓
可选:预加载相邻 parent chunk
↓
根据 token 预算筛选上下文
↓
构造带 evidence_id 的 prompt
↓
LLM 生成结构化答案
↓
解析答案中的 citations
↓
校验 citation evidence_id 是否存在
↓
渲染引用位置
↓
返回答案和可验证溯源【RAG 查询主流程编排伪代码】
ini
用户输入 query
│
├─ 1. 确定检索范围
│ searchScope = { spaces: ["hr","public"], tags: ["制度"] }
│ currentUserContext = { role, deptId }
│
├─ 2. 混合检索(HybridSearchService)
│ denseVec, sparseMap = TEI.embed(query) // 同时产出 Dense+Sparse
│ filterExpr = "chunk_schema_version==2 // 过滤旧数据
│ AND (is_public OR ACL...) // 访问控制
│ AND space_code IN (...) // 空间过滤
│ AND JSON_CONTAINS(tags, ...)" // 标签过滤
│
│ subQueryDense = ANNS(embedding, denseVec, topK=50, expr=filterExpr)
│ subQuerySparse = ANNS(sparse_vector, sparseMap, topK=50, expr=filterExpr)
│ childCandidates = Milvus.hybridSearch([subQueryDense, subQuerySparse],
│ ranker=RRF(k=60), topK=20)
│ │ ↑ 融合两路排名
│ │
│ ├─ 3. 重排(RerankService)
│ │ reranked = TEI.rerank(query, childCandidates, topK=8)
│ │
│ └─ 4. 父块扩展(expandParentContexts)
│ byParentId = groupBy(reranked, key=parent_block_id) // 按父块去重
│ parentBlocks = MySQL.batchGet(byParentId.keys) // 批量回查
│ 校验 schema_version == 2 && docUuid 一致
│ 输出: [{ content:"1200字段落", evidenceIds:["ev1","ev2"], ... }]
│
├─ 5. 构造 LLM Prompt
│ context = ContextFormatter.format(parentBlocks)
│ // → "【上下文块 1】来源: xxx · 第3页\n可引用 evidence_id:\n- ev1\n内容: ..."
│ systemPrompt = buildSourcedAnswerPrompt()
│ // → "必须输出 JSON: {answer, answerType, usedSources}"
│ // → "usedSources 必须来自上下文中的 evidence_id,不得编造"
│
├─ 6. LLM 推理(structured output)
│ llmResponse = LLM.chat(systemPrompt + context + userQuery)
│ // → { answer: "...", answerType: "factual", usedSources: ["ev1","ev3"] }
│
└─ 7. 溯源验证(UsedSourceValidator)
candidates = Map<evidence_id, Document> // 候选文档按 evidence_id 建索引
for each usedSource in llmResponse.usedSources:
if usedSource ∉ candidates → 拒绝,返回"无法可靠生成带溯源的答案"
sources = candidates[usedSource].sourceLocation // "员工手册.pdf · 第3页"
去重合并 → 返回 [{ evidenceId, fileName, pageNumber }]评测:使用Ragas评测
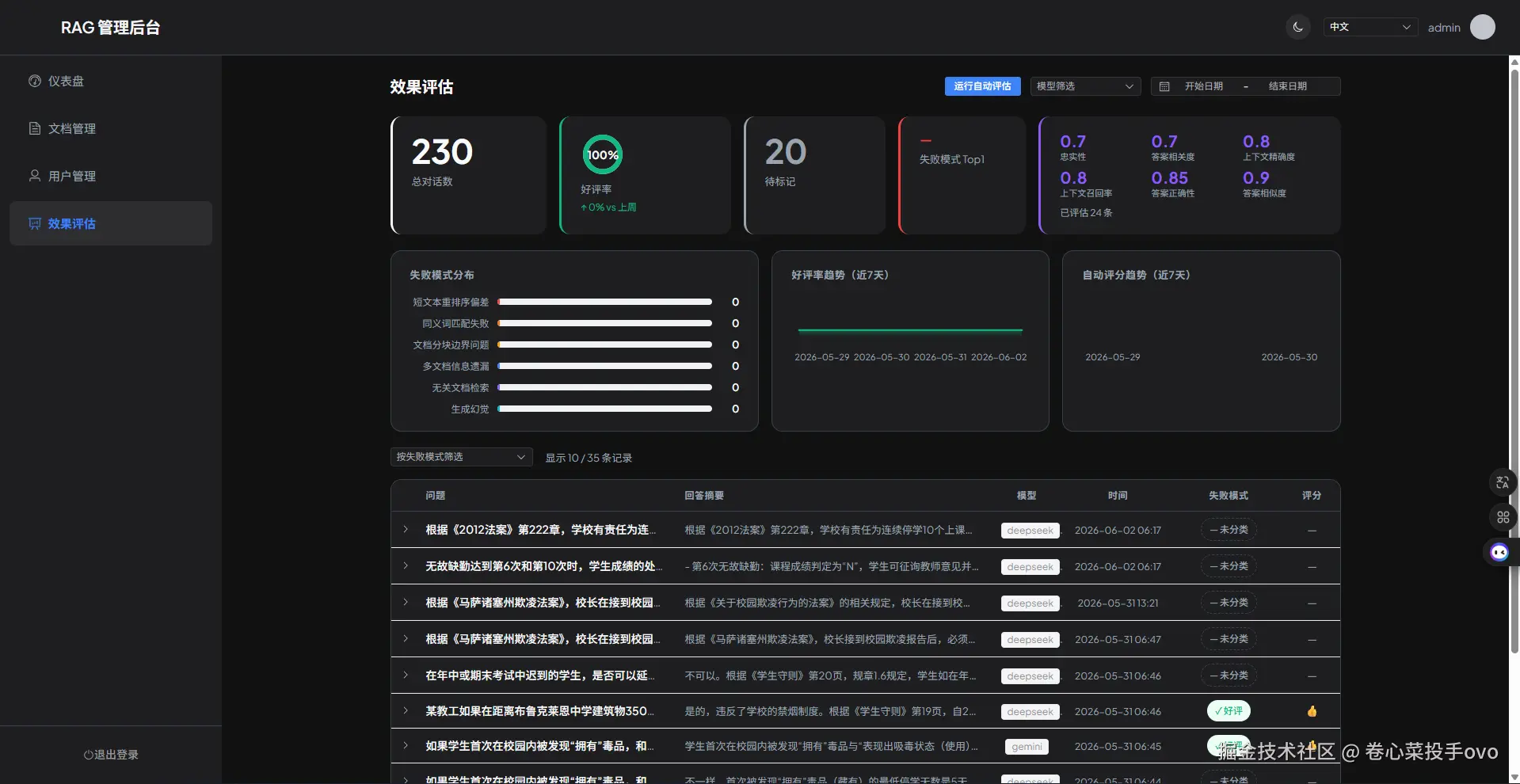
基于我自建的 Ragas 自动评测体系,在跨文档条款级问题场景下,回答准确率从约 70% 提升到了约 85%。
同时,在评测集范围内,系统生成的引用都能映射到候选证据记录,并能打开到对应文档位置,大语言模型主动写出的引用可定位率达到 99%。
最后
RAG 知识库的核心不是"能不能回答",而是"回答是否可信"。
一个看起来流畅的答案,如果无法回到原文验证,在知识库系统里就是不可靠的。
旧方案的问题在于,它把文档拆成碎片,然后把碎片交给大模型,让模型自己补全上下文、自己组织答案、甚至自己生成引用。
最终,系统从"给 LLM 扔碎片信息让它自己猜",变成了"给 LLM 完整条款上下文,并强制它对每个引用负责"。
如果你对我的项目感兴趣,可以到我的github上下载
参考资料
Spring AI ETL Pipeline 官方文档
Milvus 官方文档:Vector Search、Metadata Filtering、Multi-Vector Hybrid Search
Ragas 官方文档:RAG Evaluation Metrics
Apache Tika 官方文档
Apache POI 官方文档
CommonMark Java 相关文档
项目源码与内部评测记录