从文本到界面
现在想象一个 LLM 聊天场景。
用户向 LLM 询问"2026 年有哪些值得关注的北欧风室内设计",它开始输出一大段文字:明厅设计采用落地窗搭配浅色木地板,采光充足;厨房以白色橱柜和原木台面为主,强调功能性......用户逐行阅读,在脑海中拼凑画面。
但看一大段文字并脑补,很费力气。同样的内容,也可以这样呈现:
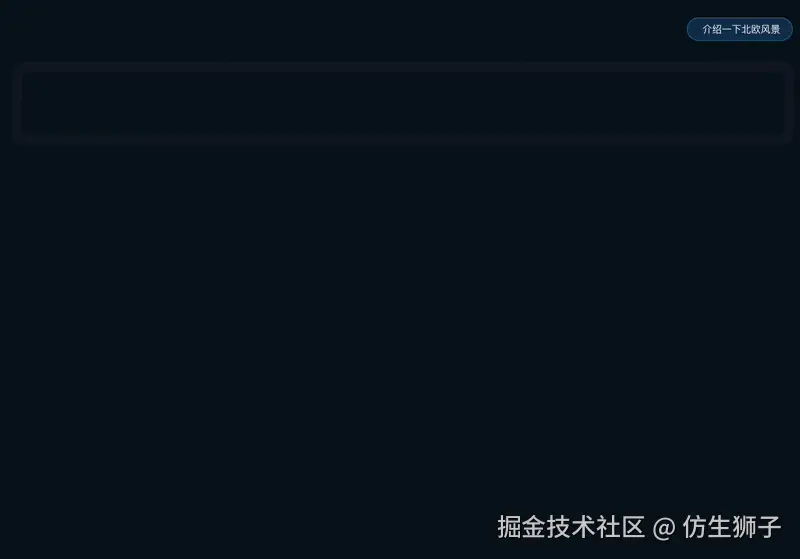
LLM 的纯文本输出的信息密度很高,但需要读者掌握提炼重点的技巧才能流畅阅读。而且存在固有局限,缺乏层次、没有视觉锚点、无法交互。
图中展示了如何在纯文本输出中融入 Generative UI(GenUI)的效果------LLM 的输出不再是一段需要自行消化的文字,而是一个可以直接浏览、点击、交互的界面。人从返回内容中获取信息的效率,存在量级差异。
但纯 HTML 也不行,尽管 LLM 对 HTML 非常精通,但在聊天模式中,工程上难以对产物进行约束。
我认为之后很长一段时间,人机交互形式都不会是 HTML 甚至实时渲染,而是存在于需一种介于两者之间的形式------既保留 Markdown 的简洁和 LLM 的熟悉度,又能承载结构化组件的交互能力。
我猜有人想说 MDX,这的确是一种选型,但在这个场景我们选择了输出和解析都更简单的 Markdown + Spec 模式:用 Markdown 组织文本和推理过程,用代码块承载结构化的组件规格(Specification)。
Spec 比 HTML 语义更单一、结构更扁平,LLM 输出更稳定,前端解析也更简单,作为协议层,恰好处于"足够表达组件语义"和"足够简单可控"之间的中间态。
下面以 vtu-cmpts 的 ImageGallery(画廊)组件为例,按数据流顺序,走完从 LLM 输出到可交互界面的完整旅程。
从流到组件:ImageGallery 的完整旅程
整个数据流分为五层:
arduino
LLM Stream → chunk-processor → Spec 提取 → VtuRenderer → 用户交互 → 新一轮对话组件库架构
结构化的输出需要一套预定义的组件库。组件库用什么框架写并不重要,关键是组件必须是状态驱动的自包含单元------每个组件通过 Props 接收数据,通过事件向外通信,不依赖外部的 context 或状态树。
Headless 模式组件库比较适合这个场景,但因为使用 Vue 技术栈,扫了一圈市面上没有合适的库,所以我只好找到 assistant-ui 抄了一份 vue 组件。
在 Vue 项目中,我们使用经典的桶模式组织组件:
ruby
index.ts // 组件入口,连接组件与工程
index.vue // 组件界面骨架,整合依赖与内部逻辑
meta.jsonc // 组件定义,兼顾人类阅读与机器理解
states/*.ts // 组件状态及状态驱动的方法
config/*.ts // 组件所需的数据或配置桶模式的好处在于结构扁平,LLM 能一步到位理解组件全貌,不需要先读入口文件,再追踪 import 链去翻其他模块。
index.ts 或目录如果有 spec.ts 即组建的 spec 定义。以 ImageGallery 为例,它的 Props 定义如下:
ts
export const ImageGalleryItemSchema = z.object({
id: z.string().min(1),
src: z.url(),
// ...
});
export type ImageGalleryItem = z.infer<typeof ImageGalleryItemSchema>;
/* ... */
export interface ImageGalleryProps {
id: string;
images: ImageGalleryItem[];
onImageClick?: (imageId: string, image: ImageGalleryItem) => void;
// ...
}可以看到这个组件使用 Zod 作为唯一的 Spec 来源。type ImageGalleryItem = z.infer<typeof ImageGalleryItemSchema> 从 Zod Schema 派生出 TypeScript 类型------一份定义,同时服务于编译时类型检查和运行时校验,是一个极好的胶水层。
关于这个组件库,它叫vtu-cmpts,有表格、画廊,然后图表等展示类组件,也有表单、审核卡片等交互组件,加起来共计二十余种组件,基本覆盖了我们目前的使用场景。
| 类别 | 组件 |
|---|---|
| 数据展示 | Article、DataTable、Chart、StatsDisplay、WeatherWidget |
| 代码 | CodeBlock、CodeDiff、Terminal |
| 社交/内容 | ContactCard、Citation、XPost |
| 表单/输入 | ApprovalCard、OptionList、ParameterSlider、PreferencesPanel |
| 流程 | QuestionFlow、Plan、ProgressTracker、OrderSummary、GeoMap |
从 React 到 Vue 的迁移过程还是蛮顺利的,如果有人想看看怎么处理代码重构,或者之后有空找机会写篇博客分享一下。
Spec 协议
LLM 不会直接输出组件代码,而是输出一种中间协议------Spec。在我们的实践中,Spec 以 Markdown 代码块的形式嵌入对话:
markdown
2026 年的销售数据和转化率如下:
\`\`\`json
{
"root": "main",
"elements": {
"main": { "type": "Stack", "props": { "direction": "row" }, "children": ["card-1", "card-2"] },
"card-1": { "type": "StatCard", "props": { "title": "总销售额", "value": "120万" } },
"card-2": { "type": "StatCard", "props": { "title": "转化率", "value": "3.2%" } }
}
}
\`\`\`Spec 采用 Vercel json-render 的 Flat Map 协议。组件在 elements 对象中以扁平列表形式输出,而非嵌套结构。扁平 Spec 有两个天然优势:结构简单,不会给 LLM 增加嵌套复杂度;数据易于增量更新,适合做流式渲染。
chunk-processor
数据流从 Markdown 开始处理。在 Markdown 解析器方面选择了开源组件 markstream-vue,因为后者提供了自定义标签与高级组件功能,同时还有高性能的节点缓存,能直接接管由 MD 到混合输出渲染。
chunk-processor 就是 sse streaming 到交给 markstream-vue 中间的数据处理层。把 JSON Spec 提取出来交给渲染引擎,但细的来说:
- 检测------扫描流式文本,找到 ```````json```` spec 代码块
- 提取------用
jsonrepair修复不完整的 JSON(缺少闭合括号、字符串没写完)。 - 验证------检查是否符合 vtu-cmpts Spec,即
{ "root": ..., "elements": ... }结构。 - 转换成文本模板如
<vtu-renderer />,后者通过自定义标签在 markstream-vue 注册。
LLM 吐到一半的内容可能是这样的:
json
{"root":"root","elements":{"root":{"type":"Col括号未闭合,字符串未结束,直接 JSON.parse 会报错。chunk-processor 在流式上下文中持续修复这些碎片,让下游渲染器始终能拿到合法的 JSON。
除了提取以外,chunk-processor 通过中间件的形式提供对 spec 的增强,比如下一小节提到的 spec 流式渲染能力。
流式渲染
如果等 JSON 全部生成完再渲染,用户会面对几秒钟的空白,然后界面突然弹出。流式渲染要解决的是:如何在数据尚未完整时,就给出有意义的界面反馈。
目前一个稳定的方案是在提示词中引导 LLM 按固定顺序生成 Spec 属性,比如先输出 type、id、title 等元信息,再输出数据密集型字段。这样即使 images 数组尚未到达,渲染器已经能画出组件骨架:
json
{
"root": "main",
"elements": {
"main": {
"type": "ImageGallery",
"title": "2026 北欧自然风景精选",
},
}
}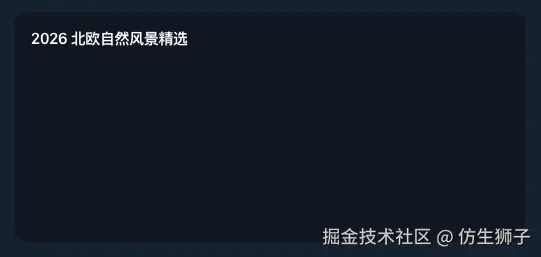
此时 ImageGallery 以空状态或 loading 状态呈现,用户知道内容正在生成。随着流继续,当第一个完整的 ImageItem 到达时,触发节点激活,图片开始逐张渲染:
json
{
"root": "main",
"elements": {
"main": {
"type": "ImageGallery",
"title": "2026 北欧自然风景精选",
"images": [
{
"id": "img-1",
"src": "https://picsum.photos/seed/nordic1/800/600",
"title": "明厅设计",
"caption": "落地窗 + 浅色木地板"
},
]
},
}
}所以第一个要介绍的 chunk-processor 的增强插件就是 data-trigger,他支持给不同组件设置不同的数据触发节点。
举个例子,Chart 允许按 Series 的数据项触发渲染;文档(Markdown inside markdown)允许按行刷新等等。手动实现触发节点可以达到极为精确的控制效果。
当然,回退到简单策略也可行------比如每固定间隔 100ms 对当前 Spec 做一次补全,并触发组件重渲染。
最终,流结束后,ImageGallery 的 images 数组完整,界面从骨架蜕变为可交互的完整画廊。
用户交互
Generative UI 如果只能看不能点,那只是花哨的 Markdown。
传统界面通过事件绑定执行特定函数,但 GenUI 的理想情况是事件不交给 LLM 去配置------LLM 不理解整个交互上下文。我们把交互按复杂度分层:纯文本、可播放媒体、按钮等单点交互、表单等有状态容器、弹窗、长时任务。在展示类场景中,交互复杂度控制在表单及以下层级。
单点交互的处理很直接:给 LLM 提供上下文即可。比如用户点击 ImageGallery 的某张图片,系统捕获到「用户点击了图片:明厅设计」,将其拼接到下一次对话的上下文中,LLM 基于这个信息生成新的回复。
点击 DataTable 表格行的"详情"按钮或 OptionList 的多选一同理,见以下图片:
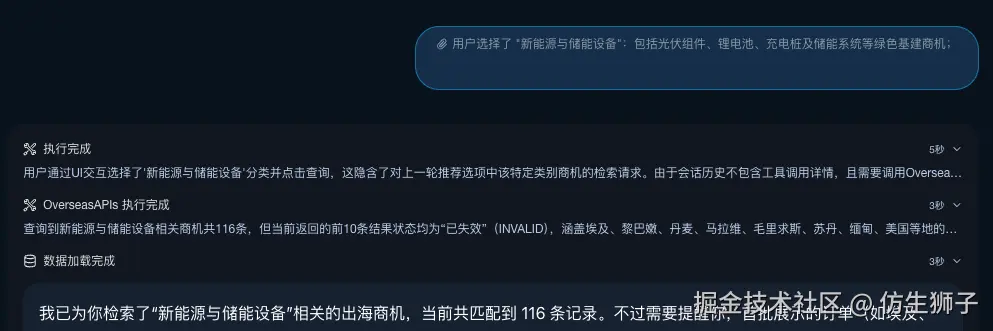
表单类组件带状态,稍微复杂一些,需要渲染器具备注入能力。
注入可以是状态(Vue 的响应式值,可与 localStorage 绑定),也可以是事件。VTU 组件暴露特定事件,所以能注入特定处理函数,也可以通过 DOM 监听统一捕获组件内部的点击、切换等交互。
只要事件能被捕获,操作空间就大了。我们可以决定拼接什么上下文、是否立即发送进入下一轮对话、还是等用户补充更多信息。如果输出包含多个 Spec,多个组件的交互上下文可以同时被收集------比如用户勾选了 DataTable 的几行,再从 OptionList 中选了"查看价格",最终的上下文会携带表格行选择信息和按钮点击信息。
这些被捕获并拼接成带上下文的数据,被添加到下一次用户提问。LLM 根据这个上下文继续生成新的回复,问答场景形成闭环。
容错设计
最后简单提一下容错。LLM 输出不稳定是常态,即使 Prompt 写得再详细,输出也会碰到不合格的状态------缺字段、类型错误、甚至混入自然语言。
组件层、渲染层、交互层都需要相应的容错和恢复机制。组件层通过 Zod Schema 做运行时校验,不合法的 Spec 被拦截在渲染之前。渲染层对不完整的 JSON 做降级或增强溃。交互层则确保事件捕获和上下文拼接的鲁棒性,不会因为某个组件的异常而影响整个对话流程。
未尽之路
这篇文章涵盖了 GenUI 落地的六个核心问题:组件库设计、协议设计、流式碎片提取、中间态渲染、交互回传、异常容错。
每一个环节都还有深入的空间,但将它们串联起来,已经能勾勒出一幅从 LLM 文本流到可交互界面的全景图。
时间成本也是非常低,整个 Demo 从 Agent 到组件库和前端,只花费约 40 人日------放在以前纯手作时代,不敢想象要抄多少代码才能把代码串起来(笑。
不过实践过程中,我也遇到了一些没有解决思路的问题。
一是聊天页的虚拟滚动。每条消息都包含工具调用、思考过程和最终回答等不同聊天块。这些块高度差异极大,精确计算高度比较困难。但开不开虚拟滚动,却会直接影响长对话的性能表现。怎么处理长对话是个问题。
二是自定义组件的可能性。结论可行,但需要一个足够强壮的 Renderer 和规范层。如果做过低码,应该能理解这里的挑战。
如果站在更宏观的视角看,LLM 的输出形态从文本到界面演进是必然进程。当 AI 的回答不再是一段需要自行提炼的文字,而是一个可以直接操作的界面时,人与 AI 的协作模式会发生根本变化。以后有机会会继续分享相关内容。