目录
1.摘要
针对低空城市交通环境,本文提出一种多无人机协同任务分配与路径规划的分布式决策与自主规划框架,利用演化势博弈对任务与路径建模并证明纳什均衡存在性,设计改进对数线性学习算法(ILLA)确保概率为1地收敛至最优纳什均衡。本文提出基于约束多层双向自适应A-Star算法(CBMBA A-Star)为无人机规划无碰撞最优路径。仿真表明,该方法比基准方法提升了11.67%的任务奖励,缩短了37.41%的执行时间与61.02%的运行时间,验证了其在复杂城市低空交通场景下的高效性。
2.问题表述与系统模型
问题表述
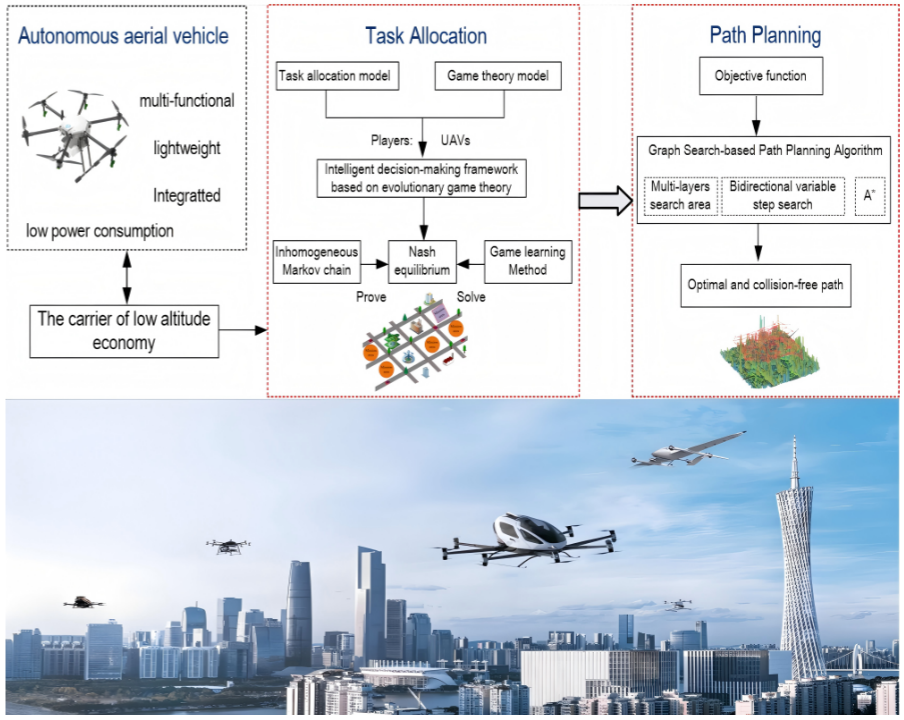
本文研究低空城市交通场景(如应急救援和货物运输)下多无人机协同任务分配与路径规划。由于单机能力有限,系统任务均为多机协同任务(MD任务),每项任务需多台无人机协作,且单机只能执行单项任务。无人机通过通信网络与邻居交互,且仅掌握自身分配的任务与奖励信息。
多无人机协同任务规划模型
无人机在低空城市环境中的三维运动学状态更新方程为
{ x i ( t + 1 ) = x i ( t ) + v i ( t ) Δ t cos ψ i ( t ) sin ϑ i ( t ) y i ( t + 1 ) = y i ( t ) + v i ( t ) Δ t sin ψ i ( t ) sin ϑ i ( t ) z i ( t + 1 ) = z i ( t ) + v i ( t ) Δ t sin ϑ i ( t ) v i ( t + 1 ) = v i ( t ) + u i ( t ) Δ t ψ i ( t + 1 ) = ψ i ( t ) + u ψ i ( t ) Δ t θ i ( t + 1 ) = θ i ( t ) + u θ i ( t ) Δ t ϑ i ( t + 1 ) = ϑ i ( t ) + u ϑ i ( t ) Δ t \begin{cases} x_i(t + 1) = x_i(t) + v_i(t)\Delta t \cos \psi_i(t) \sin \vartheta_i(t) \\ y_i(t + 1) = y_i(t) + v_i(t)\Delta t \sin \psi_i(t) \sin \vartheta_i(t) \\ z_i(t + 1) = z_i(t) + v_i(t)\Delta t \sin \vartheta_i(t) \\ v_i(t + 1) = v_i(t) + u_i(t)\Delta t \\ \psi_i(t + 1) = \psi_i(t) + u_{\psi_i}(t)\Delta t \\ \theta_i(t + 1) = \theta_i(t) + u_{\theta_i}(t)\Delta t \\ \vartheta_i(t + 1) = \vartheta_i(t) + u_{\vartheta_i}(t)\Delta t \end{cases} ⎩ ⎨ ⎧xi(t+1)=xi(t)+vi(t)Δtcosψi(t)sinϑi(t)yi(t+1)=yi(t)+vi(t)Δtsinψi(t)sinϑi(t)zi(t+1)=zi(t)+vi(t)Δtsinϑi(t)vi(t+1)=vi(t)+ui(t)Δtψi(t+1)=ψi(t)+uψi(t)Δtθi(t+1)=θi(t)+uθi(t)Δtϑi(t+1)=ϑi(t)+uϑi(t)Δt
式中包含位置 ( x i , y i , z i ) (x_i, y_i, z_i) (xi,yi,zi)、速度 v i v_i vi、偏航角 ψ i \psi_i ψi、横滚角 θ i \theta_i θi、俯仰角 ϑ i \vartheta_i ϑi及对应的线/角加速度。
任务奖励 引入五元组 ( A , T , E , O , C ) (A, T, E, O, C) (A,T,E,O,C)描述系统。无人机 a i a_i ai与任务 T j T_j Tj均有各自的载荷向量 R a i R_{a_i} Rai与 R T j R_{T_j} RTj。协同执行任务 T j T_j Tj的总奖励为
B ( T j ) = ∑ i = 1 ∣ A T j ∣ b i j = ∑ i = 1 ∣ A T j ∣ d i j r T j B(T_j) = \sum_{i=1}^{|A_{T_j}|} b_{ij} = \sum_{i=1}^{|A_{T_j}|} d_{ij}r_{T_j} B(Tj)=i=1∑∣ATj∣bij=i=1∑∣ATj∣dijrTj
其中 d i j d_{ij} dij为成功交付概率, r T j r_{T_j} rTj为任务初始价值。
任务代价由路径代价和载荷代价构成。分配阶段采用欧氏距离估算初始路径代价:
F ( T j ) = ∑ i = 1 ∣ A T j ∣ f i = ∑ i = 1 ∣ A T j ∣ ( x i − x T j ) 2 + ( y i − y T j ) 2 + z i 2 F(T_j)=\sum_{i=1}^{|A_{T_j}|}f_i=\sum_{i=1}^{|A_{T_j}|}\sqrt{(x_i-x_{T_j})^2+(y_i-y_{T_j})^2+z_i^2} F(Tj)=i=1∑∣ATj∣fi=i=1∑∣ATj∣(xi−xTj)2+(yi−yTj)2+zi2
载荷代价与所携带载荷及任务耗时相关
G ( T j ) = α 0 ( 1 − β 0 1 γ 0 ( t j i + t r e s p ) ) ∑ i = 1 ∣ A T j ∣ R T j R a i G(T_j)=\alpha_0\left(1-\beta_0^{\frac1{\gamma_0(t_{ji}+t_{resp})}}\right)\sum_{i=1}^{|A_{T_j}|}\frac{R_{T_j}}{R_{a_i}} G(Tj)=α0(1−β0γ0(tji+tresp)1)i=1∑∣ATj∣RaiRTj
综合奖励与代价 ,最大化全局净收益:
max J ( T j ) = ∑ ∀ T j ∈ T B ( T j ) − F ( T j ) − G ( T j ) = ∑ a i ∈ A ∑ ∀ T j ∈ T U i ( T j , A T j ) x i j \max J(T_j) = \sum_{\forall T_j \in T} B(T_j) - F(T_j) - G(T_j) = \sum_{a_i \in A} \sum_{\forall T_j \in T} U_i(T_j, A_{T_j}) x_{ij} maxJ(Tj)=∀Tj∈T∑B(Tj)−F(Tj)−G(Tj)=ai∈A∑∀Tj∈T∑Ui(Tj,ATj)xij
博弈论模型
博弈论层次化解耦框架将高层任务分配建模为势博弈,底层路径规划则负责落实运动学约束。
针对非齐次马尔可夫链,其单步转移矩阵随时间变化,状态转移概率矩阵为:
H t , k = ∏ i = t t + k − 1 P i H_{t,k} = \prod_{i=t}^{t+k-1} P_i Ht,k=i=t∏t+k−1Pi
当满足 lim k → ∞ ∣ h a , b t , k − h a ′ , b t , k ∣ = 0 \lim_{k \to \infty} |h_{a,b}^{t,k} - h_{a',b}^{t,k}| = 0 limk→∞∣ha,bt,k−ha′,bt,k∣=0 时,该链具备弱遍历性。对于任意两行存在同列元素均大于0攀爬矩阵,其测度定义为:
s p ( P ) = min a , a ′ ∑ b min ( p a b , p a ′ b ) sp(P) = \min_{a,a'} \sum_b \min(p_{ab}, p_{a'b}) sp(P)=a,a′minb∑min(pab,pa′b)
当且仅当 ∑ k = 1 ∞ s p ( H t k , z k ) > ∞ \sum_{k=1}^{\infty}sp(H_{t_k,z_k})>\infty ∑k=1∞sp(Htk,zk)>∞时,马尔可夫链具有弱遍历性。在此基础上,若各时刻 P t P_t Pt 为正
规矩阵,且稳态分布 π t \pi_t πt满足 ∑ t = 0 ∞ ∑ s ∈ S ∣ π s ( t ) − π s ( t − 1 ) ∣ < ∞ \sum_{t=0}^{\infty}\sum_{s\in S}|\pi_s(t)-\pi_s(t-1)|<\infty ∑t=0∞∑s∈S∣πs(t)−πs(t−1)∣<∞,则该链具备强遍历性。在构建的多无人机网络演化势博弈模型 Γ = { A , S , U i } \Gamma=\{A,S,U_i\} Γ={A,S,Ui}中,纳什均衡状态意味着任何单方改变策略均无法提升自身效用:
U i ( s i ∗ , s − i ∗ ) ≥ U i ( s i ′ , s − i ∗ ) Ui(s_i^*,s_{-i}^*)\geq Ui(s_i^{\prime},s_{-i}^*) Ui(si∗,s−i∗)≥Ui(si′,s−i∗)
若存在势函数 ϕ \phi ϕ满足:
U i ( s i , s − i ) − U i ( s i ′ , s − i ) = ϕ ( s i , s − i ) − ϕ ( s i ′ , s − i ) Ui(si,s_{-i})-Ui(s_i^{\prime},s_{-i})=\phi(si,s_{-i})-\phi(s_i^{\prime},s_{-i}) Ui(si,s−i)−Ui(si′,s−i)=ϕ(si,s−i)−ϕ(si′,s−i)
定义全局效用为 U = ∑ a i ∈ A ∑ ∀ T j ∈ T U i ( T j , A T j ) U = \sum_{a_i\in A} \sum_{\forall T_j \in T} Ui(T_j, A_{T_j}) U=∑ai∈A∑∀Tj∈TUi(Tj,ATj),并证明了当势函数满足 ϕ ( s ) = ∑ a i ∈ A T j U i ( s ) \phi(s) = \sum_{a_i\in A_{T_j}} Ui(s) ϕ(s)=∑ai∈ATjUi(s) 时,该任务分配博弈必为势博弈。将无人机复合状态记为 s i = ( x i , y i , z i , T j ) s_i = (x_i, y_i, z_i, T_j) si=(xi,yi,zi,Tj) 后,利用反证法即可证明协同任务分配与路径规划问题的最优解必然是该有限策略博弈的纯策略纳什均衡。
3.方法
势博弈中的学习算法
在势博弈中,常用对数线性学习算法 (LLA)来实现状态演化。无人机 a i a_i ai 随机选择策略的经典概率公式为
p s i ( t ) = exp { β U i ( s i , s − i ( t − 1 ) ) } ∑ s i ′ ∈ S exp { β U i ( s i ′ , s − i ( t − 1 ) ) } p_{s_i}(t)=\frac{\exp\{\beta U_i(s_i,s_{-i}(t-1))\}}{\sum_{s_i^{\prime}\in S}\exp\{\beta U_i(s_i^{\prime},s_{-i}(t-1))\}} psi(t)=∑si′∈Sexp{βUi(si′,s−i(t−1))}exp{βUi(si,s−i(t−1))}
其中, β \beta β为玻尔兹曼参数。当 β → ∞ \beta\to\infty β→∞时,LLA退化为最佳响应学习算法。在固定 β \beta β下,博弈构成齐次马尔可夫链,其唯一稳态分布 π s ( t ) \pi_s(t) πs(t)代表平衡策略分布而非物理配置。当 β → ∞ \beta\to\infty β→∞时,稳态分布的权重完全集中于使势函数 ϕ ( s ) \phi(s) ϕ(s)最大的最优纳什均衡。
改进对数线性学习算法(ILLA)通过引入时变玻尔兹曼参数和邻居策略探索机制,确保系统以概率1收敛至全局最优纳什均衡。
其策略选择机制为:
s i ( t ) = { random s i ∈ S , with prob. ε random s i ∈ S c , with prob. p s i ( t ) s i ( t − 1 ) , with prob. 1 − ε − p s i ( t ) s_i(t) = \begin{cases} \text{random } s_i \in S, & \text{with prob. } \varepsilon \\ \text{random } s_i \in S_c, & \text{with prob. } p_{s_i}(t) \\ s_i(t-1), & \text{with prob. } 1 - \varepsilon - p_{s_i}(t) \end{cases} si(t)=⎩ ⎨ ⎧random si∈S,random si∈Sc,si(t−1),with prob. εwith prob. psi(t)with prob. 1−ε−psi(t)
引入时变玻尔兹曼参数为:
β ( t ) = α ln ( t + η ) c \beta(t) = \frac{\alpha \ln(t + \eta)}{c} β(t)=cαln(t+η)
算法诱导非齐次马尔可夫链满足强遍历性,最终实现全局收敛:
lim t → ∞ P r o b . { s ( t ) ∈ { s ∗ | ϕ ( s ∗ ) = max s ∈ S ϕ ( s ) } } = 1 \lim_{t \to \infty} \mathrm{Prob.} \left\{ s(t) \in \left\{ s^* \middle| \phi(s^*) = \max_{s \in S} \phi(s) \right\} \right\} = 1 t→∞limProb.{s(t)∈{s∗ ϕ(s∗)=s∈Smaxϕ(s)}}=1

路径规划算法
约束多层双向自适应A-Star算法(CBMBA A-Star)通过动态微调 h ( k ) h(k) h(k)权重来提高求解精度与路径质量:
f ( k ) = g ( k ) + ( 1 + g ( k ) g ( k ) + h ( k ) ) h ( k ) f(k)=g(k)+\left(1+\frac{g(k)}{g(k)+h(k)}\right)h(k) f(k)=g(k)+(1+g(k)+h(k)g(k))h(k)
在搜索策略上,算法采用双同搜索机制,并以当前节点为中心构建虚拟安全圆。节点坐标更新公式为
{ x k + 1 = x k + L i cos ρ i y k + 1 = y k + L i sin ρ i \begin{cases}x_{k+1}=x_k+L_i\cos\rho_i\\y_{k+1}=y_k+L_i\sin\rho_i&\end{cases} {xk+1=xk+Licosρiyk+1=yk+Lisinρi
搜索步长 λ \lambda λ根据节点到威胁源等效面的距离 r i ( k ) r_i(k) ri(k)以及虚拟圆半径 r r r进行动态自适应调整,从而提升算法的实时防碰撞能力。

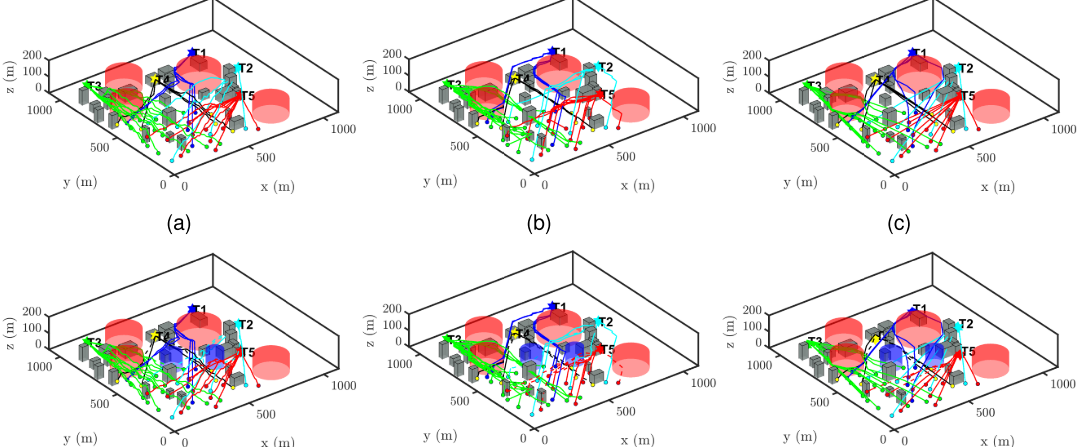
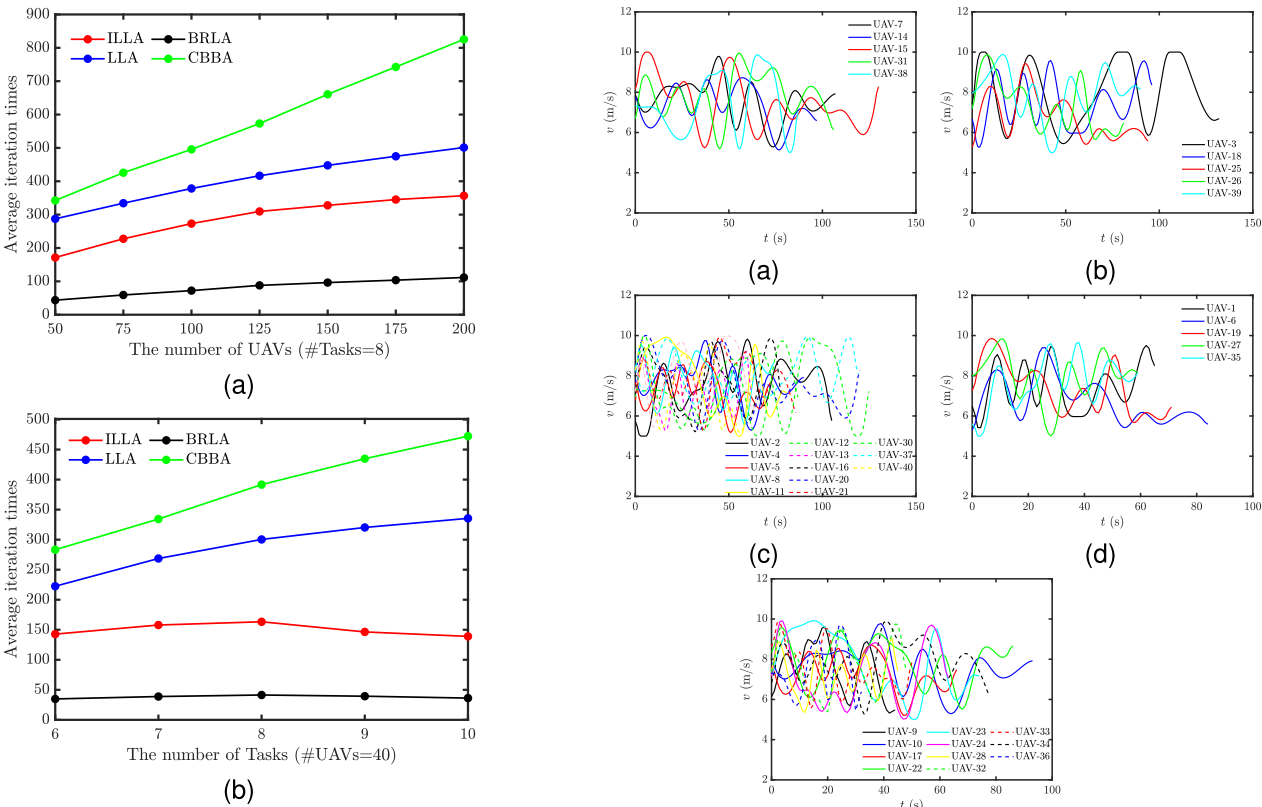
4.论文结果
5.参考文献
Zhang Z, Jiang J, Ling K V, et al. Cooperative Task Allocation and Path Planning for Multi-UAVs in Low-Altitude Urban Intelligent Transportation SystemsJ. IEEE Transactions on Intelligent Transportation Systems, 2026.
6.算法辅导·应用定制·读者交流
xx