既然你已经对 LLM 是什么,以及它们能做什么、不能做什么,有了扎实的理解,现在是时候看看 LlamaIndex 如何将你的交互式 AI 应用提升到新的层次了。我们将看到,使用 LlamaIndex 实现的 RAG,如何在 LLM 的庞大知识与专有数据之间架起桥梁。
本章将帮助你理解,为什么以及如何使用 LlamaIndex 来增强 LLM 的标准能力。
在本章中,我们将覆盖以下主题:
- 优化语言模型------流行方法概览
- 如何充分利用本书
- 介绍我们的实战项目:Contract Review Expert
- 准备编码环境
- 熟悉 LlamaIndex 代码仓库的结构
技术要求
本章需要以下内容:
- Python 3.11:www.python.org/
我们将使用的编程语言,用来构建、运行和测试所有代码示例。 - Git:git-scm.com/
我们将用它来跟踪、管理和共享代码。 - LlamaIndex:github.com/run-llama/l...
我们的 RAG 框架。 - Ollama:ollama.com/
我们需要它来运行本地 AI 模型。 - Streamlit:github.com/streamlit/s...
我们将用它来构建项目应用的前端。
本书中展示的所有示例代码片段,以及完整的项目代码库,都可以在这个 GitHub 仓库中找到:
优化语言模型------流行方法概览
在上一章中,我们看到,原生 LLM 从一开始就存在一些限制。它们的知识是静态的,并且偶尔会吐出一些毫无意义的内容。我们也学习了 RAG,作为一种潜在技术,可以缓解这些问题。将提示工程技术与 RAG 结合起来,可以优雅地解决 LLM 的许多短板。
但是,RAG 是唯一可能的解决方案吗?当然不是。让我们来探索一些常见的替代方法和互补方法。
LLM 微调
对 LLM 进行微调,指的是在专有数据上对 LLM 进行额外训练,通过强化从专门数据中学习到的新模式或优先级,使其适应特定领域或任务。在微调中,一个已经在通用数据集合上预训练过的模型,会继续在更加专门化的数据集上训练。这个专门化数据集可以针对你感兴趣的某个特定领域、语言或任务集合进行定制。其结果是,模型既能保持广泛的知识基础,又能获得某个特定领域的专业能力。
请看图 2.1,它用图示方式解释了这个过程:
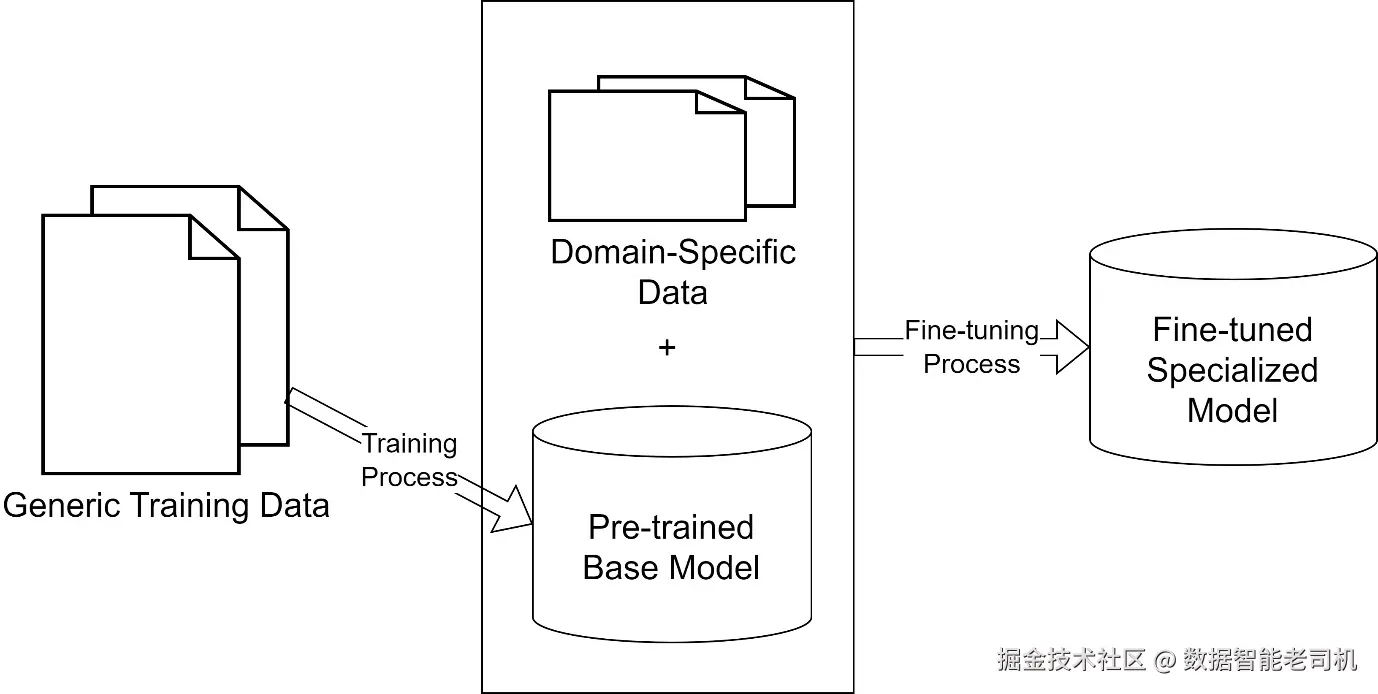
图 2.1 ------ LLM 微调过程示意图
尽管微调可以提升 LLM 的性能,但它也有一些缺点:成本高、需要大型数据集,并且很难用新信息进行更新。它还有一个缺点,就是会永久改变原始 AI 模型。对于可扩展的个性化来说,这种方法不太实用,因为它需要为每一个单独用户执行一次独立的微调过程。你可以把原始 AI 模型想象成一道经典菜肴的传统菜谱。微调这个模型,就类似于修改这份传统菜谱,以适应特定口味或要求。虽然这些改动可能让这道菜更适合某些人,但它们也从根本上改变了原始菜谱。
并不是所有微调方法都会永久改变基础 AI 模型。以低秩适配(Low-Rank Adaptation,LoRA)为例。LoRA 是一种用于 LLM 的微调方法,相比传统的完整微调,它提供了一种更高效的方式。在完整微调中,神经网络的所有层都会被优化;这种方式虽然有效,但资源消耗大,也很耗时。而 LoRA 则避免修改完整模型。它不会重新训练模型全部的内部参数,这些参数可能多达数十亿个,而是引入两个小型的可训练层,让它们学习特定任务的调整,同时保持原始模型冻结不变。这种方式既能保留原始模型,又能让模型适配新任务或获得更好的性能。关于这一方法,你可以在以下研究中找到更多信息:Hu 等人,2021,LoRA: Low-Rank Adaptation of Large Language Models ,doi.org/10.48550/ar...
虽然与完整微调相比,LoRA 在内存使用方面更加高效,但它仍然需要计算资源和专业知识,才能被有效实现和优化,这对某些用户来说可能是一个门槛。如果使用微调为大量不同用户创建更个性化的体验,就需要为每个用户重新运行一次调优过程,这显然并不具备成本效益。
我并不是说 RAG 天然优于 LLM 微调。事实上,两者通常是互补的,并且经常会组合使用。不过,在快速集成持续变化的数据以及实现个性化方面,RAG 往往是更实际的选择。
提示工程
提示工程是在 LLM 时代被创造出来的一个新术语,它代表了一种在不修改这些强大系统,也就是 LLM,底层架构的情况下,引导其行为的技术。它也被称为提示设计(prompt design),这种方法涉及编写文本输入,使其能够被生成式 AI 模型有效处理。这些提示词以自然语言编写,描述 AI 需要执行的具体任务。
虽然这并不能完全弥补上一章提到的所有 LLM 固有限制,但根据你的使用场景设计一个好的提示词,会显著增强模型性能,减少幻觉,并提高输出的可靠性。在构建聊天机器人、问答系统或任何其他由 GenAI 驱动的应用时,提示工程通常是最快、最容易上手的方式,用来优化 LLM 的输出,使其满足你的需求。然而,与 RAG、微调以及本章讨论的其他替代方法相比,提示工程更像是一种战术工具,而不是一种全面或系统性的方法。
我们将在第 13 章"提示工程指南与最佳实践"中,对这个主题进行更深入的讨论。
知识蒸馏
另一个值得提及的方法是知识蒸馏。这项技术涉及将知识从一个大型复杂模型,通常被称为教师模型,转移到一个更小、更高效的模型,也就是学生模型。这个过程通常是通过训练学生模型,使其在给定数据集上复现教师模型的输出。这个蒸馏后的模型旨在保留原始模型的大部分准确性和性能,同时在部署时显著更快、更轻量。
你可以把教师模型想象成一位专家教授,把学生模型想象成一位高级学徒。虽然学生可能无法接触教授头脑中所有深层内部运作,但它仍然可以通过仔细观察教授的解题方式,并模仿其行为,学会解决问题。
知识蒸馏在边缘部署、低延迟应用,或计算资源受限的场景中特别有用。不过,需要注意的是,这种方法并不是为了集成新知识或领域专业能力。它关注的是压缩并优化原始模型已经知道的内容。正因为如此,当需要领域特定知识时,它通常会与微调或其他方法结合使用。
知识蒸馏已经成为压缩 LLM 并保留其性能的一种关键方法,例如下面这篇综述所展示的那样:Yang 等人,2024,Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application ,arxiv.org/abs/2407.01...
工具使用与函数调用
工具使用,包括函数调用这类机制,是一种越来越流行的方法,用来在不重新训练 LLM 的情况下扩展其能力。与其试图让模型在孤立状态下变得更聪明,这项技术会让模型能够访问外部工具。这些工具可能包括外部 API、数据库、搜索引擎,甚至系统函数。借助这些工具,模型可以将任务中的某些部分委托给更适合处理它们的系统。
想象一个语言模型就像一位熟练的助手,它知道什么时候该拿起电话,联系某个主题专家。LLM 负责协调流程,理解用户意图,并在必要时将特定请求委托给外部系统。这会创建一个混合系统,将推理和自然语言生成,与访问最新能力或专业能力结合起来。
工具使用是一种高度模块化且灵活的方法,能够支持类似智能体的行为,也就是模型可以决定使用哪些外部系统来完成多步骤任务。它非常适合那些需要实时数据、流程步骤,或模型内部知识库之外动作的使用场景。不过,它确实需要稳健的后端基础设施和谨慎的集成。你需要清楚地定义函数,并确保模型能够优雅地处理失败或意外响应。它并不是 RAG 或微调的独立替代方案;相反,它通过提供实时知识访问来补充 RAG,并通过支持面向行动的工作流来增强微调。在这种工作流中,模型不只是生成回答,而是主动采取步骤来完成任务并产出结果。
这一领域近期的一个进展是模型上下文协议(Model Context Protocol,MCP)。这是一个开放标准,旨在形式化并简化 LLM 与外部工具交互的方式。函数调用允许模型以结构化输出调用特定函数,而 MCP 则增加了一个发现与协调层,使模型能够在运行时查询哪些工具可用,以及如何使用它们。MCP 为智能体软件的商品化和标准化铺平了道路,可以被视为一个框架,它将工具使用从预定义集成提升为一个即插即用能力的生态系统。关于 MCP 的更多信息可以在这里找到:github.com/modelcontex...
如果想更深入探索工具使用和智能体行为,请参阅第 10 章"探索高级智能体使用场景"。
在继续之前,下面是我们讨论过的方法的一个快速对比,帮助你理解每种方法在什么情况下有意义:
| 方法 | 它做什么 | 是否容易更新? | 成本 | 最适合 |
|---|---|---|---|---|
| 微调 | 在专门数据上重新训练模型 | 否,需要重新训练 | 高,计算 + 数据 | 适配特定领域或语气 |
| LoRA | 训练小型适配器层,保持基础模型冻结 | 比完整微调更容易 | 中等 | 在有限硬件上进行轻量级领域适配 |
| 知识蒸馏 | 将大模型压缩成小模型 | 否,需要重新蒸馏 | 中到高 | 以更低延迟和成本部署有能力的模型 |
| 提示工程 | 编写指令来引导模型行为 | 是,只需编辑提示词 | 低 | 快速调整、原型设计、简单任务 |
| 工具 / 函数调用 | 让模型访问外部 API 和系统 | 是,可以添加或替换工具 | 低到中等 | 需要实时数据或外部动作的任务 |
| RAG | 检索相关数据并将其注入提示词 | 是,只需更新数据 | 低 | 将回答锚定在大型或频繁变化的数据集上 |
表 2.1 ------ 常见 LLM 优化方法对比
尽管上述所有技术都提供了增强和定制语言模型行为的方式,但它们都没有真正解决这样一个问题:如何系统性地将 LLM 连接到你自己的数据。提示工程非常适合短指令,但它无法处理成千上万份文档。微调可以把新知识加入模型权重中,但每次数据变化时都更新它,祝你好运。工具可以获取外部信息,但它们并不会给你一条结构化流水线,用于索引、搜索,并在正确时间检索正确片段。这正是 LlamaIndex 这类框架发挥作用的地方。
LlamaIndex 做了什么
借助 LlamaIndex,你可以快速创建智能的、基于 LLM 的应用,并使其适配你的特定使用场景。你不必只依赖 LLM 通用的预训练知识,而是可以通过编程方式注入有针对性的信息,让它们给出准确、相关的回答。它提供了一种简单方式,用来将专有数据集连接到本地或托管的 LLM。
这之所以可行,是因为现代 LLM 有一个关键特性:当信息被直接放入它们的上下文窗口时,它们往往会优先使用这些信息,而不是通用训练知识。这正是 RAG 如此有效的原因。通过检索正确数据,并在查询时将其提供给模型,我们实际上是在用自己的数据锚定模型回答。
LlamaIndex 在你的自定义知识与 LLM 的巨大能力之间架起了一座桥梁。
LlamaIndex 框架由普林斯顿大学毕业生、创业者 Jerry Liu 于 2022 年创建,最初名为 GPT Index,很快就在开发者社区中变得非常流行。LlamaIndex 允许你利用 LLM 的计算能力和语言理解能力,同时将其回答聚焦在特定、可靠的数据上。这种独特组合使企业和个人能够充分发挥 AI 投资的价值,因为他们可以将同一种底层技术用于大量专门化应用。
例如,你可以索引公司的一组文档。然后,当你提出与业务相关的问题时,经过 LlamaIndex 增强的 LLM 会基于真实数据给出回答,而不是随便编出一些模糊答案!
结果就是,你既获得了 LLM 的全部表达能力,又大幅减少了错误或无关信息的数量。LlamaIndex 会引导 LLM 拉取你自己经过策划的来源,而这些来源既可以包含结构化数据,也可以包含非结构化数据。事实上,正如我们将在后续章节看到的那样,这个框架几乎可以从任何可用的数据源摄取数据。很酷,对吧?
如果你还没有想过如何使用这个框架,我来给你一些快速想法。借助 LlamaIndex,你可以做这些事情:
为你的文档集合构建搜索引擎:它最强大的应用之一,是能够索引你的所有文档。这些文档可以是 PDF、Word 文件、Notion 文档、GitHub 仓库或其他格式。一旦完成索引,你就可以查询 LLM 来搜索特定信息,让它成为一个专门针对你自己资源定制的强大搜索引擎。
创建拥有定制知识的公司聊天机器人:如果你的业务有特定术语、政策或专业知识,你可以让 LLM 理解这些细微差别。然后,这个聊天机器人就可以处理一系列查询,从基础客户服务问题,到通常需要人类专业能力才能处理的更专门化交互。
生成大型报告或论文的摘要:如果你的组织需要处理冗长文档或报告,LlamaIndex 可以用于将它们的内容提供给 LLM。然后,你可以要求 LLM 生成简洁摘要,抓住最重要的要点。
为复杂工作流开发智能助手:通过引导 LLM 理解你组织中特有的多步骤任务或流程细节,你可以把它转变成一个智能助手型数据智能体,提供有价值的洞察和指导。
而这些只是冰山一角。
图 2.2 展示了实现 LlamaIndex 这类智能 RAG 策略,如何抵消一部分与针对特定领域微调模型相关的成本。本质上,每当你的专有知识发生变化时,你并不需要重新微调模型。
图 2.2 ------ 通过 RAG 更新数据(左)比通过微调重新训练模型(右)便宜且快速得多
在我们深入 LlamaIndex 框架的应用和使用场景之前,先花一点时间理解本书是如何组织的,以及每一部分如何建立在前一部分之上。
如何充分利用本书
LlamaIndex 框架旨在同时提供高级、开箱即用的函数,以及可用于深度定制的低层组件。这种双层方法,让初学者和有经验的开发者都能以最少的工作量实现自己的想法,同时充分利用框架的灵活性和能力。本书也秉承同样思路:先从可快速实现的高级概念开始,然后再进入框架中可用的更高级定制技术。
也就是说,在开始编码之前,我们需要先考虑一些事情。
LlamaIndex 的许多功能,无论是元数据提取、索引、检索,还是响应合成,都是基于 LLM 或嵌入模型的。随着你阅读本书并开始尝试其中提供的示例,有一点非常重要,需要牢记:虽然 LlamaIndex 框架默认配置为使用 OpenAI 的模型,但本书采用了不同的方法。
为了让学习体验完全免费且完全私密,除非另有说明,本书中的所有示例都被配置为通过 Ollama 使用本地托管模型:ollama.com/。这包括用于响应生成的语言模型,也包括用于文档索引和检索的嵌入模型。我们将在第 11 章"定制和部署我们的 LlamaIndex 项目"中进一步讨论 Ollama。
本书选择以下模型来运行代码示例:
- LLM:gemma3:4b,huggingface.co/google/gemm...
一个轻量但有能力的模型,适用于大多数查询任务。 - 嵌入模型:nomic-embed-text,huggingface.co/nomic-ai/no...
它为语义搜索提供高质量嵌入。
通过 Ollama 在本地运行这些模型,你可以避免与云端托管 API 相关的成本、速率限制和隐私影响。这种设置非常适合实验、测试,甚至适合简单应用的原型开发。我有意让示例保持简单,使用小型样例数据集,以尽量降低计算需求,并使所需系统配置保持最低。配置过程很直接,并会通过一个共享代码模块自动应用到所有示例中。你将在本章的"设置 Ollama"部分找到关于如何安装和运行 Ollama 的详细说明。
重要免责声明
本书中提供的所有示例,都是使用这些特定模型编写并测试的。当在其他替代设置上运行时,一些示例可能表现不佳,甚至完全无法工作,这是可以预期的。
另一个需要考虑的关键方面是,虽然本地 LLM 提供了独立性和完全控制权,但它们可能无法匹配 OpenAI、Google、Anthropic 或 Mistral 等公司提供的大型云端托管模型在原始能力或理解广度上的水平。尽管这些最先进模型极其强大且用途广泛,但它们会产生成本,也可能带来隐私风险。如果你选择改用它们,也可以通过调整 LlamaIndex Settings 很容易地做到。这将在第 11 章"定制和部署我们的 LlamaIndex 项目"中介绍。
如果你决定在项目或实验中使用云端托管 LLM,我强烈建议你密切关注 API 使用量,并考虑隐私问题,尤其是在你计划使用自己的数据运行代码示例时。这些潜在问题将在第 4 章"将数据摄取到我们的 RAG 工作流中"和第 5 章"使用 LlamaIndex 进行索引"中进一步讨论。
记住这些之后,让我们快速浏览一下我们的实战项目,然后开始为有趣的部分做准备:写代码。
介绍我们的实战项目:Contract Review Expert
没有什么比边做边学更有效。
所以,我为我们准备了一个实用且有影响力的案例研究,用来探索 LlamaIndex 的实际应用!
让我介绍我们的主项目:Contract Review Expert。想象一下,有一个注入了 AI 能力的应用,它可以审查合同,并将合同与你的内部政策文档进行对比------智能、快速,并且提供详细的、带引用的反馈。这正是我们将一起构建的东西。
用户首先会上传一份想要审查的合同,以及一个或多个代表内部指南、监管标准或最佳实践的政策文档。
然后,应用会执行两个主要任务:
- 对合同进行通用风险分析,以显示潜在有问题的条款或危险信号
- 进行合规性审查,将合同与上传的政策文档进行评估,以发现不一致或违规之处
它真正强大的地方在于,所有发现都可以追踪。系统会引用合同或政策文档中的确切段落,以证明其结论。除此之外,用户还可以访问一个聊天机器人界面,并提出如下问题:
- 这份合同中的终止条件是什么?
- 这是否符合我们的数据保留政策?
- 哪些条款在 GDPR 下可能存在问题?
聊天机器人会从合同和政策材料中提取答案,保持完整上下文,并在回答时引用相关段落。
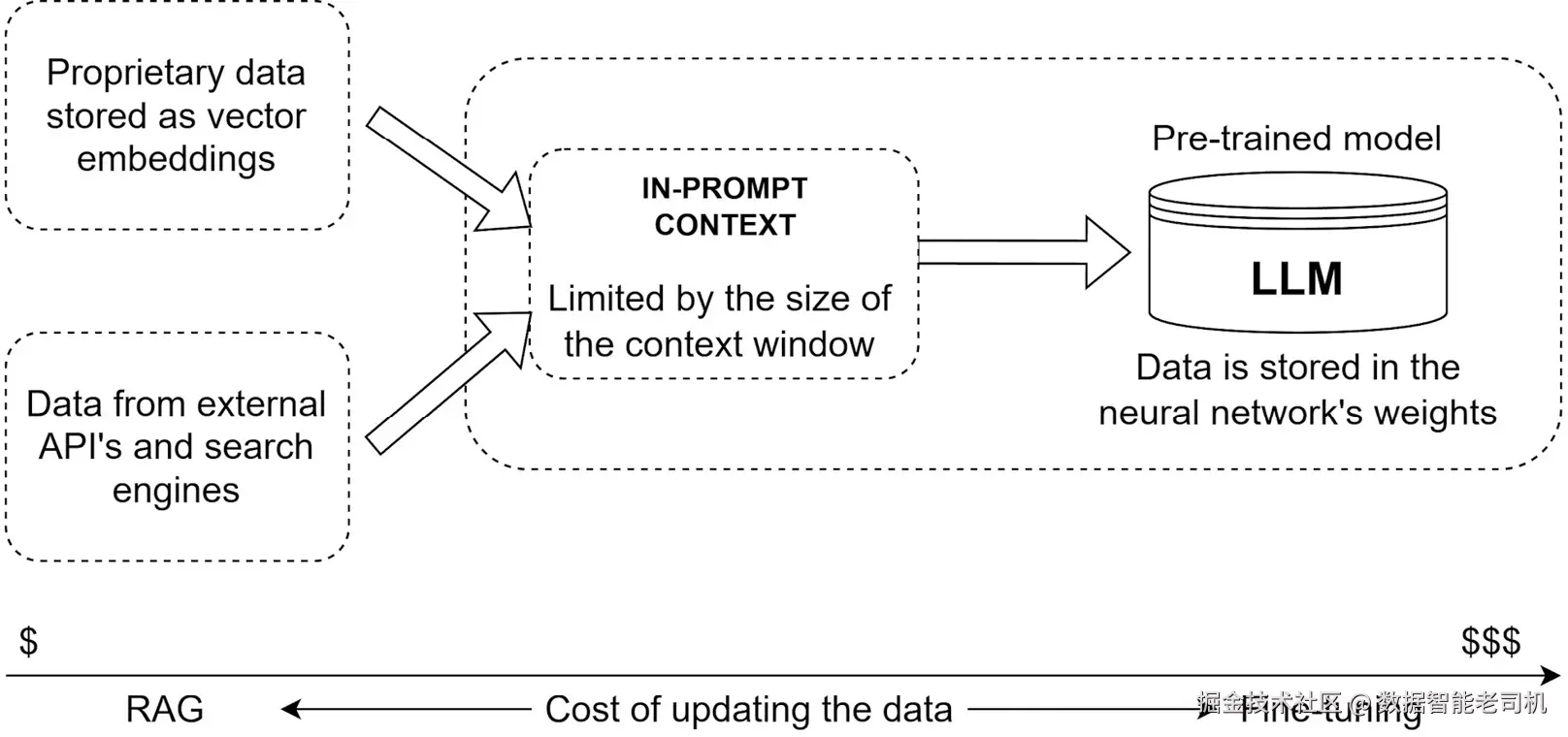
图 2.3 ------ Contract Review Expert 工作流概览
这是一个实用的真实世界项目,旨在帮助你以有意义的方式应用我们即将学习的一切。正如你可以想象的那样,我们的应用需要在几个方面足够智能:
- 它必须能够摄取和索引多份包含复杂法律或政策语言的文档
- 它必须执行检索增强分析,以在文档之间找到并关联相关段落
- 它必须支持与用户进行流畅且具备上下文意识的对话
LlamaIndex 将通过处理文档摄取、索引和检索,帮助我们构建基础。你将学习如何构建、定制和查询文档索引,从而创建一个模拟专家法律审查,并支持人工合同分析的系统。图 2.4 展示了项目实际 UI 的预览:
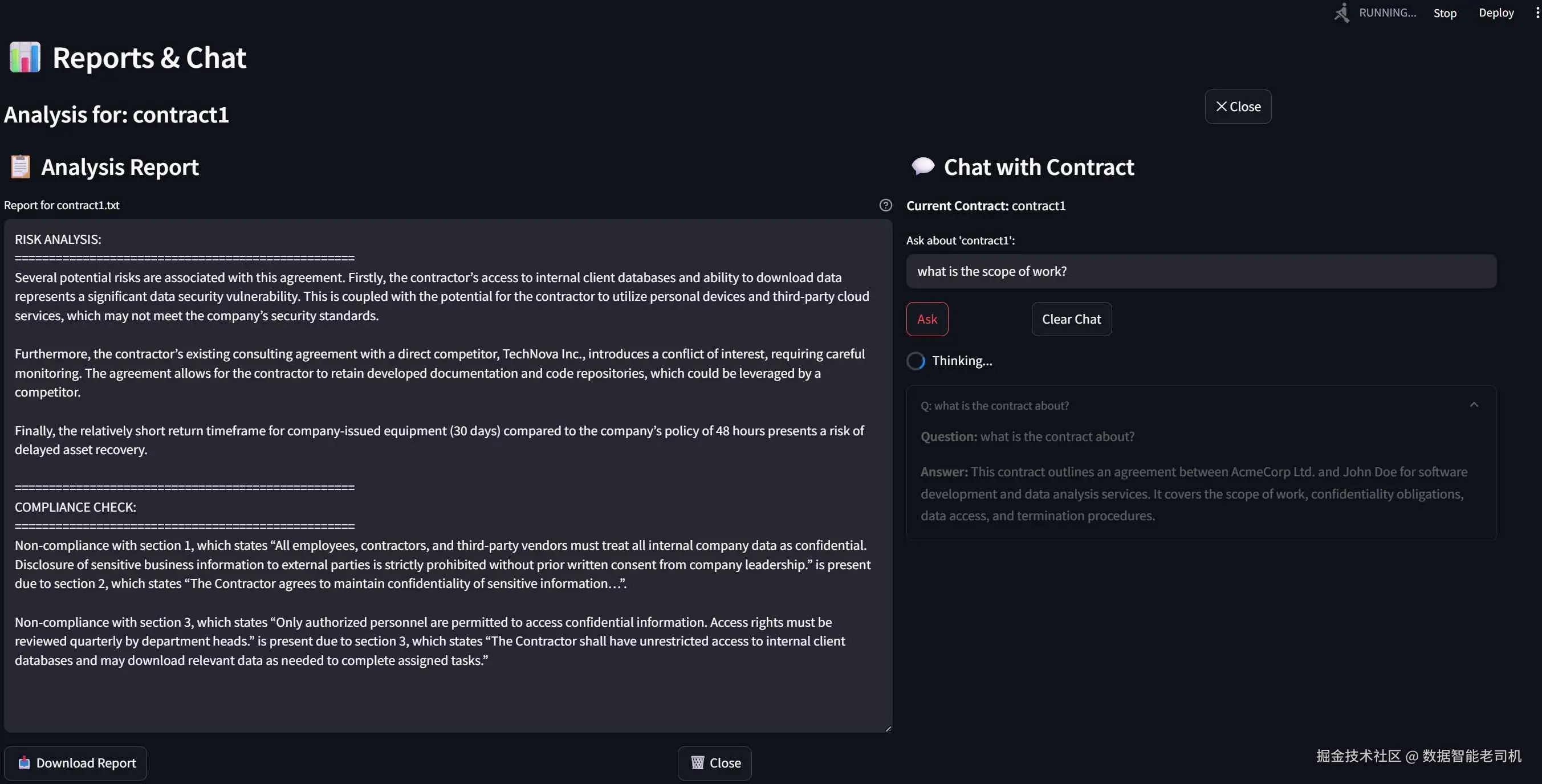
图 2.4 ------ 这是本书结束时我们将构建出的内容
作为一个亲眼见过合同分析多么繁琐且高风险的人,我非常兴奋能展示 GenAI 和 LlamaIndex 这类工具,如何让更多人获得这种专业能力。话虽如此,鉴于合同解释涉及法律和伦理影响,对于这种敏感使用场景,强烈建议采用人在回路中的方式。这个应用被设计为一种辅助工具,而不是专业法律审查的替代品。任何输出都应被视为建议性内容,并在真实场景中依赖之前,由合格人员进行验证。
接下来,让我们开始设置必要组件。
准备编码环境
在我们开启 LlamaIndex 编码之旅之前,正确设置开发环境非常重要。这个设置是第一步,可以确保我们能够顺利运行我为你准备的示例和练习。
为了保持简单,并确保所有示例的一致性,我设计的示例代码会在本地 Python 环境中运行。我知道你们很多人都喜欢使用 Google Colab 和 Jupyter Notebooks 这类基于 Web 的编码环境来做项目,所以如果这些示例不能直接迁移到这些平台,或者不能在其中运行,还请理解。我的目标是让设置尽量直接,让我们能够专注于学习体验,而不必担心兼容性问题。感谢理解,祝编码愉快!
让我们快速把电脑设置好,准备进行一些很酷的 LlamaIndex 编码。
安装 Python
你需要一个 Python 3.8.1+ 环境。如果可以,我推荐 Python 3.11。在本书第二版写作时,对 Python 3.12 以及更新版本的支持目前仍然有限,并且可能在安装或运行时导致兼容性问题。
如果你没有 Python,请从 www.python.org 安装。如果你已经有较旧版本,可以升级,或者并行安装一个更新版本的 Python。
对于编码环境,我个人偏好 NotePad++:notepad-plus-plus.org/。它不完全是一个 IDE,但速度非常快。不过,你也可以使用 Microsoft 的 VSCode:code.visualstudio.com/,PyCharm:ht...,或者任何你喜欢的工具。
安装 Git
在继续之前,安装 Git 很重要。Git 是一个版本控制系统,可以让你管理代码变更,并与他人协作。它对于克隆代码仓库也非常重要,例如本书将使用的那个仓库。
前往 Git 官方网站:git-scm.com/book/en/v2/...,下载适合你操作系统的安装程序。按照安装步骤操作,很快就可以让 Git 正常运行。
本书中展示的所有示例代码片段,以及完整项目代码库,都可以在这个 GitHub 仓库中找到:
因此,如果你想将项目文件下载到本地,在完成 Git 安装之后,可以按照以下步骤操作:
导航到目标目录 :打开一个新的命令提示符或终端窗口。使用 cd 命令导航到你想存放项目的目录。下面是一个示例:
bash
cd path/to/your/directory克隆仓库:运行以下命令克隆 GitHub 仓库:
bash
git clone https://github.com/AG-ITAcademy/Building-Data-Driven-Applications-with-LlamaIndex-2nd-Edition这会将项目的一份副本下载到你的本地机器。
进入项目目录:进入新创建的项目文件夹:
bash
cd Building-Data-Driven-Applications-with-LlamaIndex-2nd-Edition随着项目推进,你有两个选择:
- 自己编写代码,并将其与仓库中的代码进行对比
- 直接探索仓库中的代码文件,以更好地理解代码结构
如果你正确完成了前面的所有步骤,列出当前文件夹内容时,应该会看到几个名为 chX 的子文件夹,其中 X 是章节编号,以及一个单独名为 Project 的子文件夹。章节文件夹中包含与每章对应的所有示例源文件。Project 文件夹中包含我们主项目的源代码。
安装 LlamaIndex
接下来,让我们安装 LlamaIndex 库。在命令提示符中运行以下命令:
perl
pip install llama-index这会安装一个 LlamaIndex 包,其中包含核心 LlamaIndex 组件,以及一组有用的集成。为了实现尽可能高效的部署,也可以选择只安装最小核心组件和必要集成,但对于本书目的来说,上面展示的安装方式已经完全够用。
如果你已经在运行低于 v0.10 的 LlamaIndex 版本,建议你在虚拟环境中进行一次全新安装,以避免与旧版本发生冲突。
因为我们将使用本地托管的 LLM 和嵌入模型,所以还需要安装所需的 Ollama 集成:
perl
pip install llama-index-llms-ollama
pip install llama-index-embeddings-ollama现在,我们已经准备好导入并开始使用 LlamaIndex 框架了。
设置 Ollama
由于本书中的所有示例都将在本地运行,不依赖云 API,也不会产生使用成本,你需要安装 Ollama。Ollama 是一个工具,可以让你在自己的机器上运行 LLM 和嵌入模型。要安装 Ollama,只需访问 Ollama 官方网站:ollama.com/,并按照你的操作系统,也就是 Windows、macOS 或 Linux,对应的安装说明进行操作。他们网站上的设置流程很直接,文档也很完善。
拉取所需模型
安装好 Ollama 后,你需要下载本书示例所使用的特定模型:
arduino
ollama pull gemma3:4b
ollama pull nomic-embed-text这些命令会下载模型,并使它们可以在本地使用。它们大约会占用 3.5 GB 磁盘空间,所以请确保你有足够空间。
这是两种不同类型的模型:gemma3:4b 是一个小型但有能力的 LLM,拥有 40 亿参数,将负责文本生成;而 nomic-embed-text 是一个嵌入模型,拥有 1.37 亿参数,用于将文本转换为可用于搜索和检索的数值表示。在接下来的章节中,你会看到它们如何协同工作。
你可能会想,为什么我选择这些特定模型。对于 LLM,我选择 gemma3:4b,是因为它在能力和硬件需求之间取得了不错的平衡。它有 40 亿参数,足够聪明,可以处理合同分析这类任务,同时又足够小,可以在大多数消费级机器上舒适运行,而不需要高端 GPU。对于嵌入模型,我选择 nomic-embed-text,因为它是一个可靠且成熟的选项,在各种检索任务中表现稳定。
也就是说,LlamaIndex 是模型无关的,所以你可以根据自己的硬件或使用场景,自由替换为更合适的替代模型,因为你将在本书中学习到的技术,不管你使用哪种模型,都同样适用。
启动 Ollama
要开始使用 Ollama,请运行以下命令启动服务:
ollama serve这个命令会初始化 Ollama 服务器,让你的应用可以与模型交互。
请确保在你处理本书示例时,ollama serve 一直在后台运行。
好了,后端已经全部设置完毕。接下来我们来谈谈技术栈的其余部分。
发现 Streamlit------快速构建和部署的完美工具!
在我们能够构建合同审查系统这类很酷的应用之前,需要有一个地方来......嗯,构建并运行它们!这就是 Streamlit 发挥作用的地方。Streamlit 是一个很棒的开源 Python 库,可以非常轻松地创建和部署 Web 应用与仪表板。
只需要几行 Python 代码,你就可以构建完整的 Web 界面,并立即看到结果。最棒的是,Streamlit 应用几乎可以部署到任何地方:本地服务器、Docker 容器,或者 Heroku、AWS、Microsoft Azure 这类云平台。
我喜欢 Streamlit,因为它让我可以专注于用 LlamaIndex 应用构建真正有用的功能,而不是纠结复杂的 Web 开发。对于 AI 实验来说,它非常完美!
我们将主要使用它来为合同审查项目创建 UI,并用它在本地运行和测试我们的应用。不过,在第 11 章"定制和部署我们的 LlamaIndex 项目"中,我们也会了解如何使用 Streamlit Share,或者任何你喜欢的其他托管服务,轻松部署应用。
Streamlit 拥有大量很酷的能力,例如数据框、图表和小部件,但现在不必担心要全部学会。随着我们逐步构建功能,我会解释相关部分,这样你可以在过程中逐渐掌握 Streamlit 技能。
要安装 Streamlit 库,请运行以下命令:
pip install streamlit很好!现在我们已经有了平台,也就是 LlamaIndex;前端层,也就是 Streamlit;以及目标,也就是合同审查应用。让我们回顾一下到目前为止安装的所有内容:
- Python 3.11+
- Git
- LlamaIndex 包
- Streamlit,用于应用前端
- Ollama,用于运行本地 LLM 和嵌入模型
最后检查一次
为了验证所有内容是否正确安装,请打开一个新的命令提示符或终端窗口,并运行以下命令:
sql
python --version
git --version
pip show llama-index
pip show streamlit
ollama --version检查你的环境是否准备就绪的一个简单方式,是尝试进入本地 Git 文件夹中的 ch2 子文件夹,并运行名为 sample1.py 的文件:
python sample1.py如果所有内容都正确安装,你应该会得到 ch2/files 子文件夹中两个示例文档的漂亮摘要:
第一份文档详细介绍了古罗马的历史,强调了它作为庞大帝国中心的重要性。它描述了这个帝国在建筑、工程和军事征服方面的成就,以及它对现代社会的持久影响。
第二份文档关注狗作为深受喜爱的伴侣动物。它讨论了犬种的多样性,以及狗对人类生活的积极影响,强调了它们的忠诚、保护天性,以及它们给主人带来的快乐。
如果缺少任何内容,请返回并重新执行必要步骤,然后再继续。相信我,这会让你在后续少经历很多痛苦和挫败。
我们现在已经准备好开始摄取数据、使用 LlamaIndex 构建索引,并构建我们的合同审查应用了!我不知道你是不是这样,但我已经像进了糖果店的小孩一样,迫不及待想开始实验了。
在第 3 章"开启你的 LlamaIndex 之旅"中,我们将亲手编写第一个 LlamaIndex 程序。真正有趣的部分就从这里开始!我会一路用简单的话解释每个概念和每一行代码。很快,你就会像 LlamaIndex 专家一样实现基础功能!一旦掌握这些基础,我们就可以开始扩展应用能力。
不过首先,让我们先弄清楚这个框架 GitHub 仓库的整体代码结构。
熟悉 LlamaIndex 代码仓库的结构
因为你可能会花很多时间浏览 LlamaIndex 框架的官方代码仓库,所以对它的总体结构有一个整体印象会很有帮助。你随时可以在这里查看该仓库:
从 0.10 版本开始,代码已经被彻底重组为更加模块化的结构。这个新结构的目的,是通过避免加载不必要的依赖来提高效率,同时改善可读性和开发者整体使用体验。
图 2.5 描述了代码结构中的主要组件:
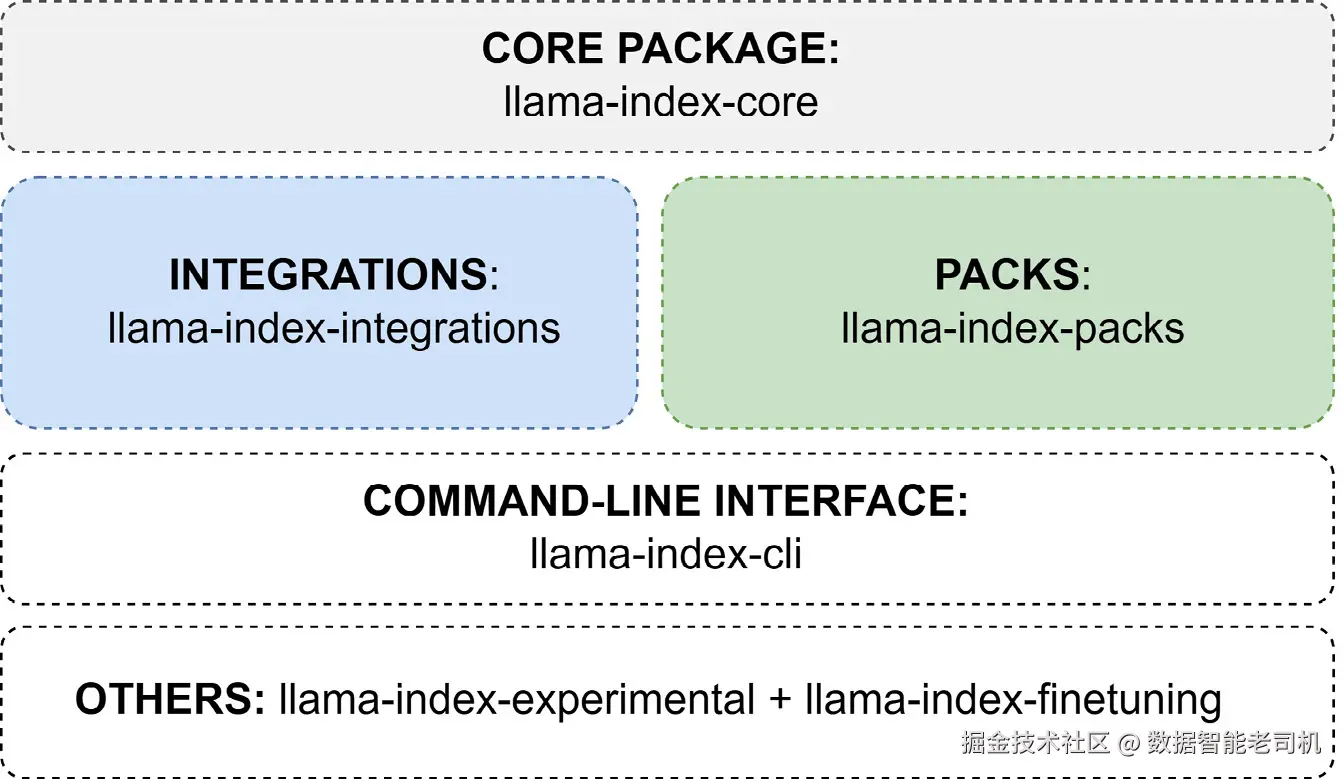
图 2.5 ------ LlamaIndex GitHub 仓库代码结构
llama-index-core 文件夹是 LlamaIndex 的基础包,使开发者能够安装核心框架,然后从 300 多个集成包和不同的 Llama packs 中选择性添加内容,以便为特定应用需求定制功能。
LlamaIndex 的 llama-index-integrations 文件夹由各种附加包组成,用来扩展核心框架的功能。这些包允许开发者使用特定元素来定制自己的构建,例如自定义 LLM、数据加载器、嵌入模型和向量存储提供商,从而最大程度适配应用需求。我们将在本书后面介绍其中一些集成,从第 4 章"将数据摄取到我们的 RAG 工作流中"开始。
llama-index-packs 文件夹包含 50 多个 Llama packs。这些包由 LlamaIndex 开发者社区开发并持续改进,作为现成模板,帮助用户快速启动自己的应用。
llama-index-cli 文件夹由 LlamaIndex 命令行界面使用,我们也将在第 11 章"定制和部署我们的 LlamaIndex 项目"中简要介绍。
最后一个部分,在图 2.5 中称为 OTHERS,由两个文件夹组成,目前包含微调抽象和一些实验性功能,本书不会覆盖这些内容。
llama-index-integrations 和 llama-index-packs 中的子文件夹代表单独的包。文件夹名称与包名称对应。例如,llama-index-integrations/llms/llama-index-llms-mistralai 文件夹对应的是 llama-index-llms-mistralai PyPI 包。
按照这个例子,在你像下面这样在代码中导入并使用 mistralai 包之前:
javascript
from llama_index.llms.mistralai import MistralAI你必须先运行下面的命令安装对应的 PyPI 包:
pip install llama-index.llms.mistralai不用太担心本书示例中会缺少任何必要包,因为你会在每一章开头的"技术要求"部分看到它们被清楚地列出来。
总结
在本章中,我们介绍了 LlamaIndex,这是一个用于将 LLM 连接到外部数据集的框架。我们了解到,LlamaIndex 如何让 LLM 将真实世界知识纳入其回答中。本章说明了 RAG 和微调并不是互斥的,而是在生产系统中经常互补使用;同时也讨论了 LlamaIndex 相比微调的优势,例如更容易更新和个性化,并探索了 LoRA 和知识蒸馏等替代方法。我们强调了 LlamaIndex 的双层设计:它既提供用于快速开发的开箱即用函数,也提供适合高级使用场景的可定制组件。我们还简要介绍了 LlamaIndex 生态系统的模块化结构,这种结构使针对特定使用场景定制和优化解决方案变得很容易。
最后,我们介绍了我们的实战项目:Contract Review Expert,一个简单但非常有用的合同审查应用。最后几节介绍了如何设置所需工具,例如 Python、Git、Streamlit 和 Ollama,并验证我们的环境已经准备好,可以构建 LlamaIndex 应用。现在,我们已经准备好继续旅程,并进一步从技术层面理解 LlamaIndex 框架的内部工作机制。下一章见!