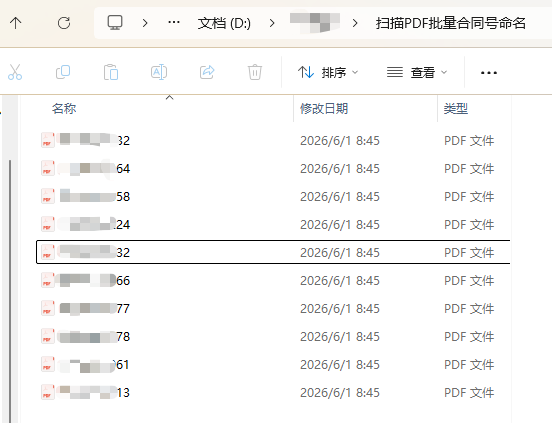
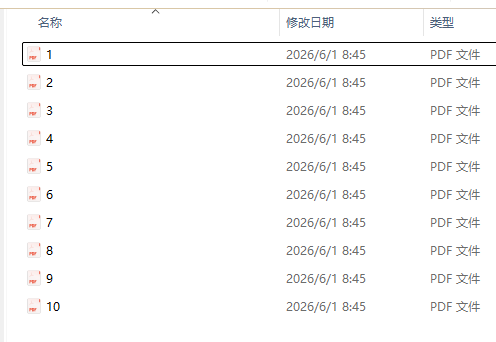
对以下多个pdf合同文件批量识别pdf中的合同号并以合同号命名文件
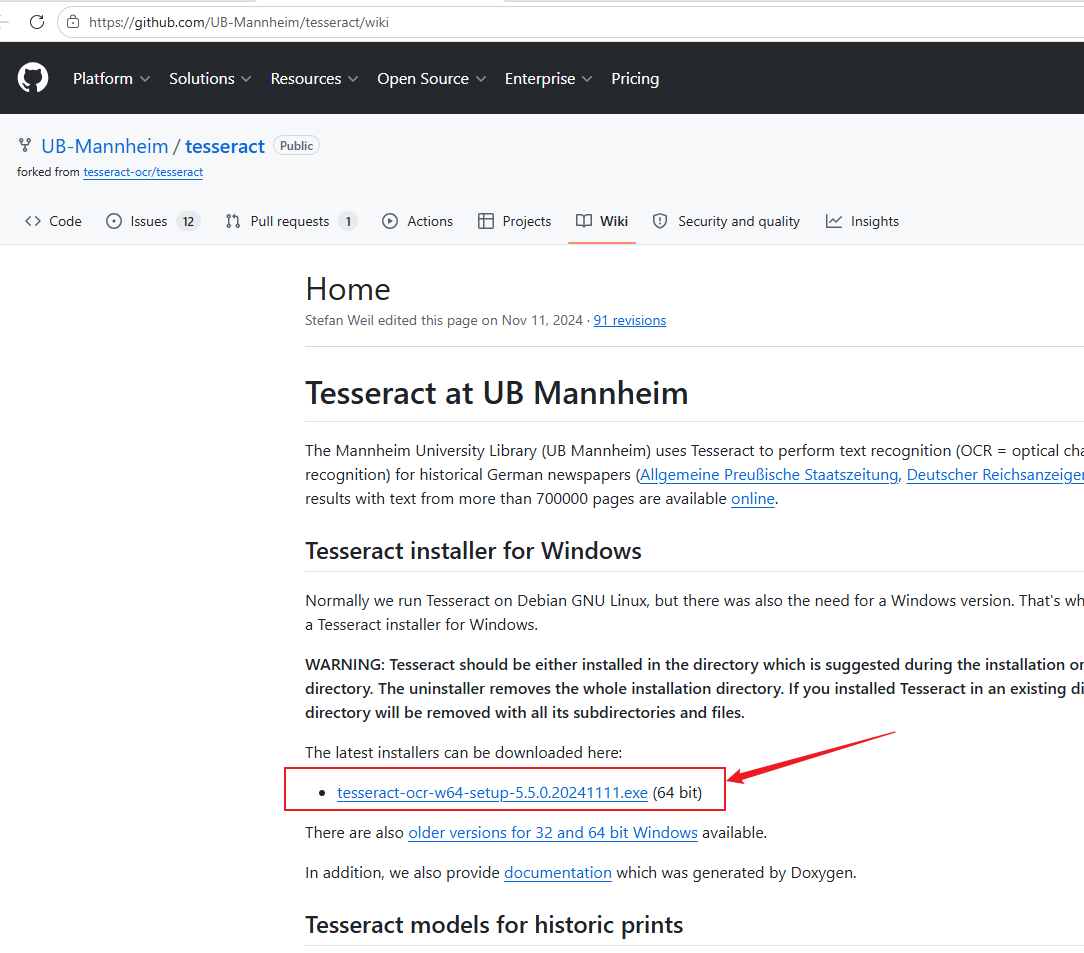
需要先下载安装Tesseract,才能用 OCR 功能,
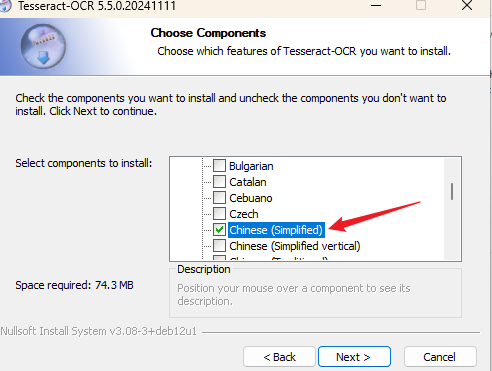
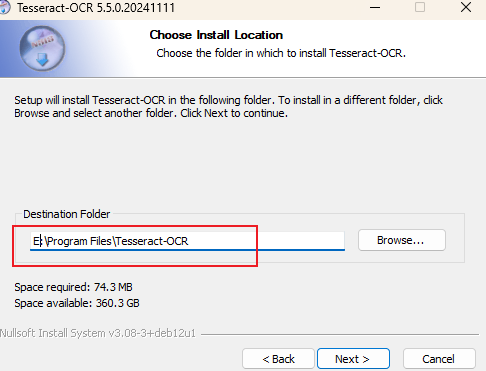
下载后安装时,一定要勾选 中文语言包(chi_sim)
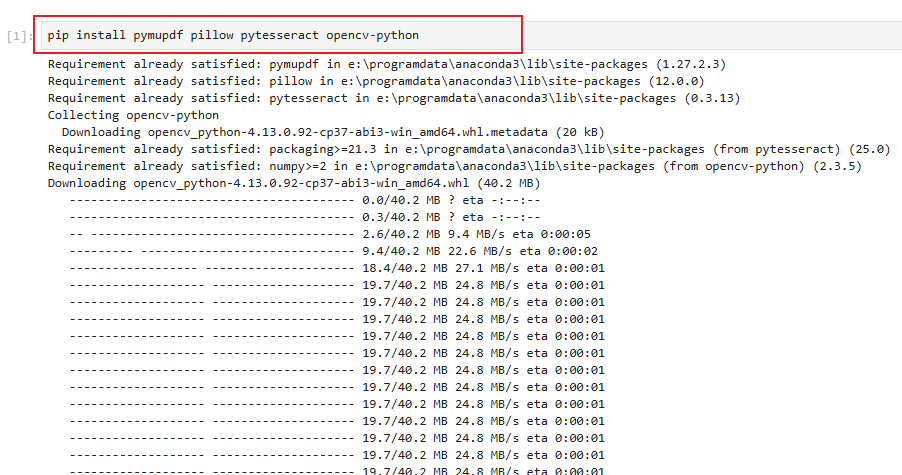
jupyter notebook安装对应软件包:
完整代码如下:
python
pip install pymupdf pillow pytesseract opencv-python
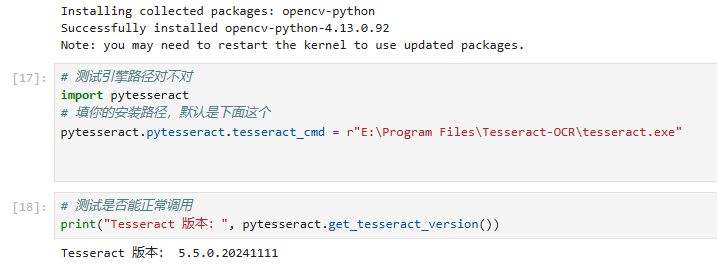
# 测试引擎路径对不对
import pytesseract
# 填你的安装路径,默认是下面这个
pytesseract.pytesseract.tesseract_cmd = r"E:\Program Files\Tesseract-OCR\tesseract.exe"
# 测试是否能正常调用
print("Tesseract 版本:", pytesseract.get_tesseract_version())
python
import os
import re
import fitz
from PIL import Image
import pytesseract
# ===================== 配置项(你只需要改这里) =====================
PDF_FOLDER = r"D:\XXXXX\扫描PDF批量合同号命名"
pytesseract.pytesseract.tesseract_cmd = r"E:\Program Files\Tesseract-OCR\tesseract.exe"
# ==================================================================
def pdf_first_page_ocr(pdf_path):
"""读取PDF第一页,转图片并OCR识别文字"""
doc = fitz.open(pdf_path)
page = doc[0]
mat = fitz.Matrix(2.0, 2.0) # 提高清晰度
pix = page.get_pixmap(matrix=mat)
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
text = pytesseract.image_to_string(img, lang='chi_sim+eng')
doc.close()
return text
def get_contract_number(text):
"""从识别文本中提取合同编号(8-15位数字)"""
# 优先匹配:合同编号 + 数字
pattern = r"合同编号.*?(\d{8,15})"
match = re.search(pattern, text, re.DOTALL)
if match:
return match.group(1)
# 兜底匹配:连续8-15位长数字
numbers = re.findall(r"\d{8,15}", text)
if numbers:
return numbers[0]
return None
# ===================== 批量处理主逻辑 =====================
if __name__ == "__main__":
print("===== 扫描PDF合同号批量重命名工具 =====")
print(f"目标文件夹:{PDF_FOLDER}\n")
for filename in os.listdir(PDF_FOLDER):
# 只处理PDF文件
if not filename.lower().endswith(".pdf"):
continue
old_path = os.path.join(PDF_FOLDER, filename)
print(f"正在处理:{filename}")
try:
# OCR识别
text = pdf_first_page_ocr(old_path)
contract_num = get_contract_number(text)
if not contract_num:
print(" → 未识别到合同编号,跳过\n")
continue
# 生成新文件名
new_name = f"{contract_num}.pdf"
new_path = os.path.join(PDF_FOLDER, new_name)
# 重名自动加后缀(不覆盖)
count = 1
while os.path.exists(new_path):
new_name = f"{contract_num}_{count}.pdf"
new_path = os.path.join(PDF_FOLDER, new_name)
count += 1
# 执行重命名
os.rename(old_path, new_path)
print(f" → 重命名成功:{os.path.basename(new_path)}\n")
except Exception as e:
print(f" → 处理失败:{str(e)}\n")运行结果如下