导读:
本文通过代码示例展示了如何结合阿里云 Elasticsearch(ES)与千问 VL 大模型,以提取图片特征,并利用多模态 Embedding 模型实现高效的多模态搜索,涵盖了以文搜图、以文搜文、以图搜图以及以图搜文等多种检索方式。
背景信息
在多模态搜索场景中,图片和文本的非结构化数据需要被转换为向量表示,然后通过向量检索技术快速找到相似的内容。本实践使用以下工具:
-
ES:高效的向量数据库,用于存储和检索向量。
-
千问VL:提取图片描述和关键词。更多详情请参见图像与视频理解。
-
DashScope Embedding API:将图片和文本转换为向量。更多详情请参见多模态向量。
其功能包括:
-
以文搜图:输入文本查询,搜索最相似的图片。
-
以文搜文:输入文本查询,搜索最相似的图片描述。
-
以图搜图:输入图片查询,搜索最相似的图片。
-
以图搜文:输入图片查询,搜索最相似的图片描述。
系统架构
下图展示了本文中使用的多模态搜索系统的整体架构。 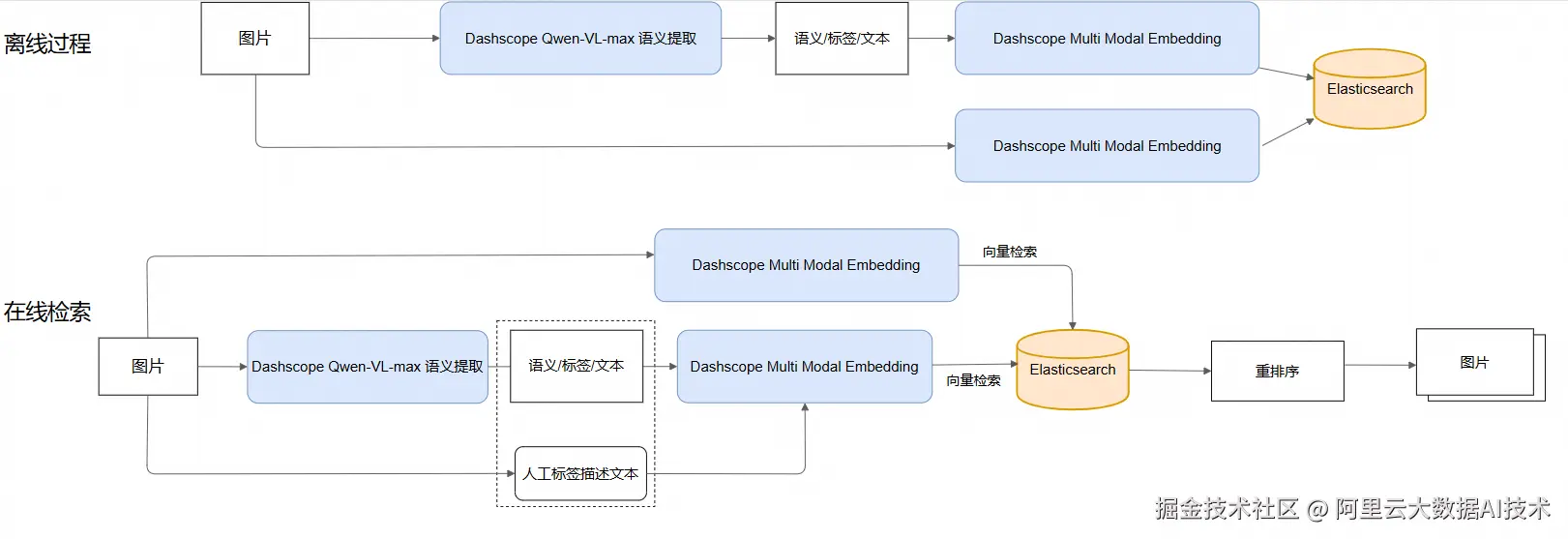
前提条件
-
已创建 8.17及以上版本的 Elasticsearch 实例。具体操作,请参见创建阿里云 Elasticsearch 实例。
-
已开通百炼服务并获得 API-Key。具体操作,请参见获取 API Key。
-
已安装 Python 3.8 及以上版本。
环境准备
安装依赖
plaintext
pip install elasticsearch dashscope requests streamlit下载示例数据集
执行以下命令下载并解压示例数据集:
plaintext
wget https://github.com/milvus-io/pymilvus-assets/releases/download/imagedata/reverse_image_search.zip
unzip -q -o reverse_image_search.zip示例数据集包含一个 CSV 文件 reverse_image_search.csv 和若干图片文件。
目录结构
创建工作目录并按以下结构组织文件:
plaintext
multi_modal_search/
├── reverse_image_search.csv # 数据集CSV文件
├── train/ # 图片目录(解压后生成)
│ └── *.jpg
├── scripts/ # 脚本目录
│ ├── write.py # 数据写入脚本
│ ├── read.py # 查询脚本
│ └── demo.py # 前端演示脚本核心代码介绍
写入流程
在写入流程中,首先利用千问 VL 模型提取图片描述信息,并将其存储在 text_input 字段中。接着,通过多模态 Embedding 模型,将图片及其描述分别转换为对应的向量表示(image_embedding和text_embedding),以便后续进行跨模态检索或分析。
为了简化演示,本示例仅从前200张图片中提取数据并完成上述流程。
详细代码请查看 help.aliyun.com/zh/es/user-...
涉及以下参数,请根据实际情况进行替换

执行 python3 write.py ,可以看到每张图片生成的相应描述,以及相关处理进度

查询流程
在查询流程中,我们定义了四类查询,分别为文搜图,文搜文,图搜图以及图搜文。将输入的文本或者图片调用百炼多模态模型进行 Embedding,将 Embedding 的结果根据查询类型,检索 image_embedding 或 text_embedding 字段,匹配最相关的文本或图片。
详细代码请查看
help.aliyun.com/zh/es/user-...
ES 配置相关参数与写入流程一致。
前端demo
详细代码请查看
help.aliyun.com/zh/es/user-...
操作流程
步骤一:配置参数
在运行脚本之前,需要修改以下配置参数:
打开 write.py 和 read.py 文件,修改以下配置:
plaintext
# ES配置
ES_HOST = "<ES_HOST>" # 替换为您的ES实例地址
ES_PORT = 9200
ES_USER = "<ES_USER>" # 替换为您的ES用户名
ES_PASSWORD = "<ES_PASSWORD>" # 替换为您的ES密码
# 百炼API配置(仅write.py需要)
DASHSCOPE_API_KEY = "<DASHSCOPE_API_KEY>" # 替换为百炼平台中可用的API Key步骤二:加载数据集
进入 scripts 目录,执行数据写入脚本:
plaintext
cd scripts
python3 write.py执行成功后,您将看到类似以下输出:
plaintext
INFO - [1/7] 创建 ES 客户端...
INFO - ES连接状态: xxx
...
INFO - 处理第 1/200 张图片: xxx
INFO - 描述: xxx
...
INFO - 处理完成!成功: 200, 失败: 0步骤三:验证数据写入(可选)
可以运行查询脚本验证数据是否写入成功:
plaintext
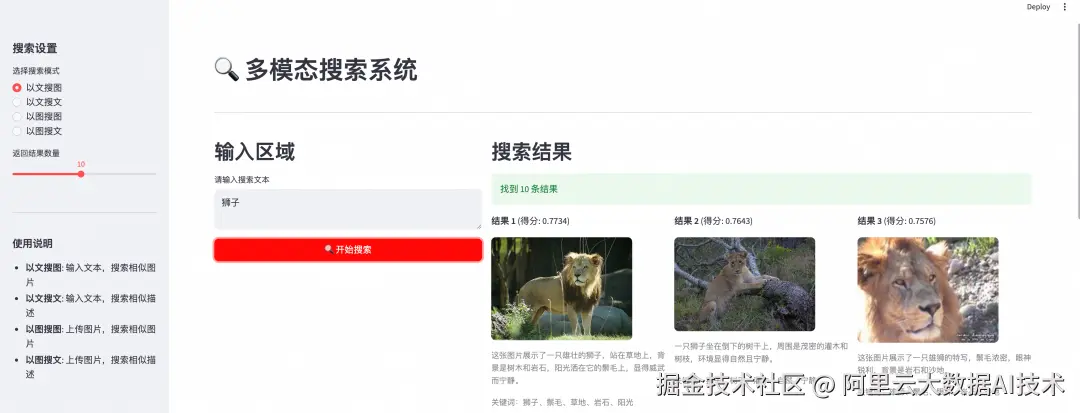
python3 read.py以以文搜图为例,执行成功的返回结果:
plaintext
以文搜图 - 搜索关键词"狮子"
✓ 得分: 0.8077 - 一只狮子坐在倒下的树干上,周围是茂密的灌木和树枝
✓ 得分: 0.7732 - 雄壮的狮子站在草地上,鬃毛在阳光下威武宁静
✓ 得分: 0.7566 - 雄狮特写,鬃毛浓密,眼神锐利步骤四:启动前端演示
plaintext
streamlit run demo.py启动后,浏览器会自动打开 http://localhost:8501。
步骤五:多模态向量检索
在搜索设置中选择搜索类型,在输入区域中输入搜索文本或上传图片,点击开始搜索,检索相关结果。
阿里云 Elasticsearch 正在重新定义企业级 AI 搜索的标准。通过 BBQ 量化、FalconSeek 引擎、Retrievers 框架等企业级创新,我们不仅解决了"搜得准"的问题,更解决了"用得起"和"管得好"的挑战。对于致力于构建下一代智能应用的技术领导者而言,选择阿里云 Elasticsearch,即是选择了效果、成本与安全的最优解。
了解更多:
阿里云 Elasticsearch:www.aliyun.com/product/big...
阿里云 AgenticSearch:help.aliyun.com/zh/open-sea...