从本篇起,我们走进 WAM 谱系里另一条主线:级联式 WAM → 潜在表征 → 隐式规划。简单说,就是不再傻乎乎地把整段未来视频一像素一像素地画出来,而是想办法在更高效、更聚焦的层面上做"预测未来"这件事,再从中解码动作。
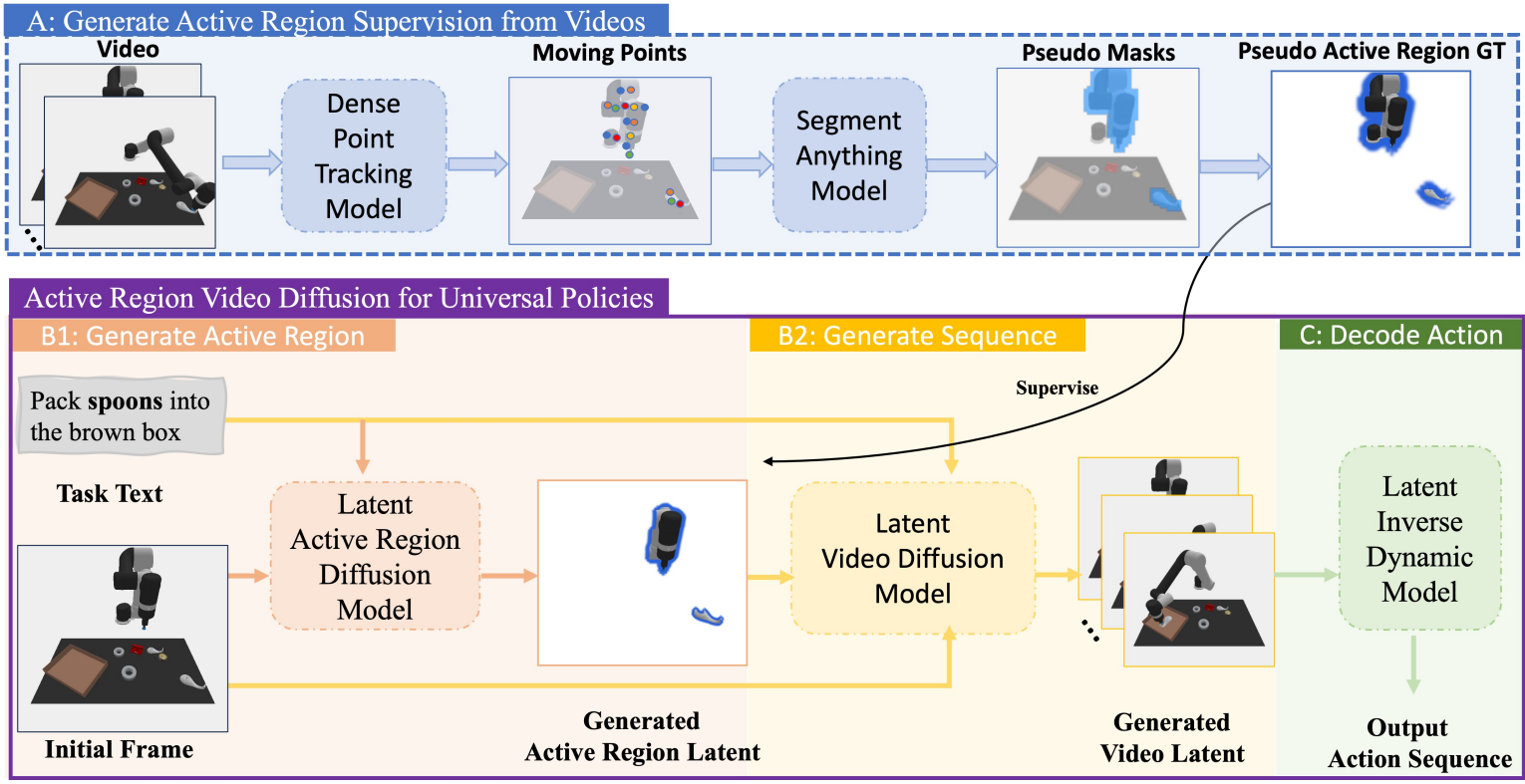
ARDuP(Active Region Video Diffusion for Universal Policies,主动区域视频扩散通用策略) 是这条线上一个很有代表性的早期工作。它抓住了前辈们一个被长期忽视的毛病------视频生成把画面里所有像素一视同仁,结果常常"画对了背景、画错了主角"------并给出一个朴素却有效的修正:先让模型搞清楚"任务到底跟画面里哪块区域有关",再让它带着这份"注意力地图"去生成视频。下面我们慢慢讲。
一、要解决什么问题:视频模型容易"抓错重点"
要理解 ARDuP,得先理解它的"假想敌"------以 UniPi 为代表的视频式通用策略。UniPi 的思路在 WAM 里很经典:给一句指令和一帧初始画面,用一个文生视频的扩散模型生成"接下来该怎么做"的整段视频,再用一个逆动力学模型(IDM,即"看相邻两帧、倒推中间动作"的网络)把视频翻译成机器人动作。
这套思路很优雅,但 ARDuP 的作者点出了一个隐蔽的硬伤:视频扩散模型在训练时,是对画面里每一个像素"平均用力"的。它的目标是让生成的整帧画面尽量逼近真实帧------可问题在于,一帧画面里绝大多数像素其实是无关紧要的背景(桌面、墙壁、不动的杂物),真正决定任务成败的,往往只是那一小块"手和被操作物体"的区域。
这会导致一个很微妙、却很致命的现象。论文举了个生动的例子:假设指令是"拿起白色方块",可桌上还有个紫色方块。模型为了把整帧画面的重建误差压低,完全可以选择去拿那个紫色方块、然后偷偷把它的颜色"改"成白色 ------这样画面看起来和"拿起白色方块"的真值帧很接近,损失降下来了,可任务其实根本做错了。换句话说,"画得像"和"做得对"之间,存在一道鸿沟;而一视同仁的像素级损失,恰恰会纵容模型钻这个空子。
打个生活化的比方:这就像让一个学生临摹一幅画,他为了整体相似度达标,可以把最关键的人物画歪、却在大片天空和草地上精雕细琢------总分看着不低,可画的灵魂全错了。ARDuP 想做的,就是给模型划重点:别在背景上浪费笔墨,给我盯紧"会发生交互的那块区域"。
二、核心思想与直觉:先画"注意力地图",再画视频
ARDuP 的核心 idea 用一句人话概括:
在生成未来视频之前,先生成一张"主动区域(active region)"图------也就是画面里"物体正在被交互的那块关键区域"------然后把这张图当作额外条件喂给视频生成模型,逼它把生成的精力集中到任务相关的地方。
这里的关键概念是"主动区域 "。它指的就是画面里"物体正在被操作、正在发生交互"的区域,集中承载着完成任务所需的关键上下文(被操作物体、末端执行器附近),与那些静止的背景相对。
直觉上,这相当于给视频模型配了一位"导演助理",在开拍前先递上一张分镜重点标注图:"这场戏的核心在桌子左上角那个白方块和夹爪,别的地方随便糊弄。"有了这张图做条件,模型生成时就不容易跑偏去动紫方块了。
那么随之而来一个现实问题:这张"主动区域图"从哪来? 真实采集的机器人数据里,可没有人手工标注"哪块是主动区域"。ARDuP 的一大巧思,就是在训练时用现成的视觉工具自动"伪造"出这种监督------这正是它和工具集成最精彩的地方,下一节细讲。
在 WAM 分类里,ARDuP 仍属于级联式 (先预测、再解码),且预测发生在潜在空间(视频扩散在 latent 上跑、动作也在 latent 上解码)。它没有 VPP/VILP 那么彻底地追求实时,但"用一个轻量的中间表征(主动区域)去引导、约束未来预测"的思想,是这条隐式规划路线的早期探索。
三、方法详解:分解式视频生成器 + 潜在逆动力学
ARDuP 的整体架构可以拆成三大块:主动区域生成器 、带主动区域条件的视频规划器 、潜在逆动力学模型。再加上一套"自动伪造主动区域监督"的数据流程。我们逐一拆解。
1. 自动伪造主动区域监督:Co-Tracker + SAM 的妙用
在干嘛:训练主动区域生成器需要"标准答案"------每段训练视频里哪块是主动区域。但真实数据没有这种标注,得自己造。
怎么做,分两步:
第一步,用 Co-Tracker 找出"在动的点"。 Co-Tracker 是一个稠密点跟踪模型,能在视频里跟踪大量点各自的运动轨迹。ARDuP 把初始帧切成一个 M×M 的网格,在每个网格点上撒一个跟踪点,让 Co-Tracker 跟踪它们在整段视频里的轨迹。然后看哪些点的平均位移超过了阈值 τ------这些"动起来了"的点,显然就落在交互发生的地方(被操作物体、移动的夹爪)。
第二步,用 SAM 把"动点"扩成完整掩码。 光有一堆离散的"动点"还不够精细,ARDuP 把这些动点作为提示,喂给 SAM(Segment Anything Model,万物分割大模型) ,让它生成一张覆盖交互区域的伪掩码(pseudo mask) 。最后,把初始帧上被这张掩码圈中的区域抠出来、其余部分填成白色背景,就得到一张"主动区域帧"------它就成了训练主动区域生成器的标准答案。
这一步的精妙在于:全程无需任何人工标注,纯靠两个现成的视觉基础模型(一个会跟踪运动、一个会精细分割)自动产出伪监督。这把"哪里是重点"这个本来需要人标的信息,变成了可以批量自动生成的东西。
2. 分解式视频生成器:两阶段扩散
ARDuP 把"生成未来视频"这件事拆成了串联的两阶段(这就是"分解式"的含义):
阶段一:主动区域生成器 ψ。 输入是"初始帧的潜在表征 + 任务文字",用一个条件潜在扩散模型生成一张"主动区域潜在图"------也就是前面那张高亮交互区域的图,在潜在空间里的版本。训练时它的标准答案,正是上一节用 Co-Tracker + SAM 伪造出来的主动区域帧。
阶段二:视频规划器 ϕ。 输入是"初始帧潜在 + 任务文字 + 阶段一生成的主动区域潜在",用扩散生成未来帧的潜在序列。有了主动区域这个额外条件,模型在生成时就能"把力气集中在任务关键区域",从而提升生成序列的相关性与精确度。
主动区域是怎么"注入"进视频扩散的? ARDuP 用了一种"双重拼接(dual concatenation) "策略:把主动区域的潜在,既和初始帧潜在拼在一起,也在去噪过程中和每一帧正在生成的潜在拼在一起。这样一来,模型对每一帧的去噪,不仅要对齐初始观测,还要对齐主动区域------相当于在每一步生成里都被反复提醒"重点在这儿"。
打个比方:阶段一是导演助理先画好"重点标注图",阶段二则是在拍每一个镜头时,都把这张标注图贴在监视器旁边,时刻提醒摄影师别跑焦。
3. 潜在逆动力学模型:直接在潜在空间里抠动作
在干嘛:视频规划出来了,还得把它翻译成机器人能执行的动作。
怎么做 ,这里 ARDuP 做了个效率上的关键选择------直接在潜在空间里解码动作,不解码回 RGB 像素。传统做法(如 UniPi)是先把生成的视频潜在解码成 RGB 帧,再从 RGB 帧抠动作,这一步解码很费算力。ARDuP 的潜在逆动力学模型则:
- 直接吃两个相邻帧的潜在表征
(x̂ₕ, x̂ₕ₊₁); - 输出一个 7 维的动作向量(适配机械臂操作);
- 它和视频规划器共用同一个编码器,确保两者的潜在嵌入是一致的(在同一个"语言"里对话);
- 可以独立地在较小的数据集上训练。
训练目标方面,主动区域扩散用标准的条件扩散损失(对着伪掩码学)、视频扩散用条件扩散损失(对着帧潜在学)、逆动力学则用动作的 L1 损失(预测动作和真值动作的差)。
把三块串起来,ARDuP 的数据流就是:文字 + 初始帧 → 主动区域潜在 → 带主动区域条件的未来视频潜在 → 相邻潜在帧 → 动作序列。整条链路尽量待在潜在空间,避免了反复解码回像素的开销。
核心公式与逻辑梳理
把 ARDuP 的设计写成公式,能更清楚地看到"主动区域"是怎么从一组稠密跟踪点最终长成一张高亮分镜图、又怎么以"双重拼接"的方式渗透进视频扩散每一步去噪的。
方法逻辑链(五步):
- 撒点跟踪 :在首帧上撒一个 M×MM \times MM×M 网格点,用 Co-Tracker 跟踪它们在整段视频里的轨迹;
- 筛动点 :算每个点逐帧位移的平均量,超过阈值 τ\tauτ 的留下,构成"运动点集";
- 扩成掩码 :把运动点喂给 SAM 当 prompt,得到一张二值掩码 M\mathbf{M}M,并把首帧外的区域漂白,得到主动区域帧 ooo 作为伪真值;
- 两阶段扩散 :先用扩散模型 ψ\psiψ 在潜在空间生成主动区域,再用扩散模型 ϕ\phiϕ 以"初始帧 + 主动区域"为双重条件生成未来视频;
- 潜在 IDM 抠动作 :用一个共用编码器的轻量网络从相邻潜在帧 (x^h,x^h+1)(\hat x_h, \hat x_{h+1})(x^h,x^h+1) 反推动作向量。
核心公式:
(1) Co-Tracker + SAM 伪标签生成
Δph=∥ph−ph−1∥2,Δp‾=1H∑h=1HΔph,Pm={p∈P∣Δp‾>τ} \Delta \mathbf{p}_h = \|\mathbf{p}h - \mathbf{p}{h-1}\|2, \quad \overline{\Delta \mathbf{p}} = \frac{1}{H}\sum{h=1}^{H} \Delta \mathbf{p}_h, \quad \mathcal{P}_m = \{\mathbf{p} \in \mathcal{P} \mid \overline{\Delta \mathbf{p}} > \tau\} Δph=∥ph−ph−1∥2,Δp=H1h=1∑HΔph,Pm={p∈P∣Δp>τ}
M=SAM(I0,Pm),o=x0⊙M+xb⊙(1−M) \mathbf{M} = \text{SAM}(I_0, \mathcal{P}_m), \quad o = x_0 \odot \mathbf{M} + x_b \odot (1 - \mathbf{M}) M=SAM(I0,Pm),o=x0⊙M+xb⊙(1−M)
- 符号说明:ph\mathbf{p}_hph 是某个跟踪点在第 hhh 帧的二维像素位置,Δph\Delta \mathbf{p}_hΔph 是它相邻两帧的位移;Δp‾\overline{\Delta \mathbf{p}}Δp 是整条轨迹的平均位移,τ\tauτ 是判断"算不算动起来了"的阈值(论文里 τ=2\tau=2τ=2,网格 M=60M=60M=60);Pm\mathcal{P}_mPm 是被认为"在动"的点集合;M∈{0,1}H0×W0\mathbf{M} \in \{0,1\}^{H_0 \times W_0}M∈{0,1}H0×W0 是 SAM 由这些动点扩出来的二值掩码;x0x_0x0 是首帧、xbx_bxb 是纯白背景帧,⊙\odot⊙ 表示逐像素相乘;ooo 就是"主角抠出来、背景漂白"的主动区域帧。
- 这条式子在做什么:用最朴素的"运动检测"假设------动的就是主角------把整段视频在哪里发生交互这件事自动标注出来。一行 SAM 把稀疏动点扩成完整掩码,伪真值就此造好,全程零人工标注。
(2) 主动区域生成器 ψ\psiψ 的条件扩散损失
Lψ=Eo, ϵ∼N(0,I), k ∥ϵ−ϵψ(ok,k,x0,c)∥22 \mathcal{L}\psi = \mathbb{E}{o, \, \epsilon \sim \mathcal{N}(0,\mathbf{I}), \, k} \Bigl\\, \\bigl\\\| \\epsilon - \\epsilon_\\psi(o_k, k, x_0, c) \\bigr\\\|_2\^2 \\,\\Bigr Lψ=Eo,ϵ∼N(0,I),k ϵ−ϵψ(ok,k,x0,c) 22
- 符号说明:ooo 是上面伪造出的主动区域帧(在潜在空间里它的潜在码我们仍记为 ooo),oko_kok 是给 ooo 加了 kkk 步噪声的潜在;ϵ\epsilonϵ 是加进去的真实噪声;ϵψ\epsilon_\psiϵψ 是要训练的噪声预测网络;x0x_0x0 是首帧潜在(作为视觉条件),ccc 是任务文本的嵌入;E\mathbb{E}E 是对样本、噪声、扩散步数三方面取期望。
- 这条式子在做什么:标准的条件去噪损失------让网络学会,在给定"现在看到什么 + 要做什么"的条件下,从纯噪声里反推出"哪一块是主动区域"。注意这里它学的不是颜色像素,而是"任务相关注意力分布"这件事。
(3) 视频规划器 ϕ\phiϕ 的"双重拼接"条件扩散损失
Lϕ=Ex1:H, ϵ, k ∥ϵ−ϵϕ(\[x1:H,k ∥ o; x0 ∥ o; c)∥22 ] \mathcal{L}\phi = \mathbb{E}{x_{1:H}, \, \epsilon, \, k} \Bigl\\, \\bigl\\\| \\epsilon - \\epsilon_\\phi\\bigl(\[x_{1:H, k} \\;\\Vert\\; o; \, x_0 \\;\\Vert\\; o; \, c \bigr) \bigr\|_2^2 \,\Bigr] Lϕ=Ex1:H,ϵ,k ϵ−ϵϕ(\[x1:H,k∥o;x0∥o;c) 22]
- 符号说明:x1:Hx_{1:H}x1:H 是未来 HHH 帧的潜在序列(标准答案),x1:H,kx_{1:H, k}x1:H,k 是它加噪 kkk 步后的版本;ooo 是上一阶段生成的主动区域潜在;∥\Vert∥ 表示沿通道维拼接;中括号里第一项是"每一帧正在去噪的潜在和主动区域拼起来",第二项是"初始帧潜在和主动区域拼起来"------这就是"双重拼接(dual concatenation) ";ccc 仍是文本条件。
- 这条式子在做什么:让视频扩散模型在去噪每一帧时,两处都看得到主动区域------一处是稳定的视觉锚(首帧条件),一处是动态的去噪输入(当前帧)。相当于在每一步生成里都把"重点标注图"贴在监视器上反复提醒,让模型把笔墨集中在交互区域、别再跑去画错主角。
(4) 潜在逆动力学的 L1 动作损失
LIDM=E(xh,xh+1,ah) ∥fIDM(xh,xh+1)−ah∥1 \mathcal{L}\text{IDM} = \mathbb{E}{(x_h, x_{h+1}, a_h)} \Bigl\\, \\bigl\\\| f_\\text{IDM}(x_h, x_{h+1}) - a_h \\bigr\\\|_1 \\,\\Bigr LIDM=E(xh,xh+1,ah) fIDM(xh,xh+1)−ah 1
- 符号说明:xh,xh+1x_h, x_{h+1}xh,xh+1 是相邻两帧的潜在表征 (与视频规划器共用同一个编码器,所以两者"说同一种语言");aha_hah 是真值动作(一个 7 维向量);fIDMf_\text{IDM}fIDM 是要学的潜在逆动力学网络;∥⋅∥1\|\cdot\|_1∥⋅∥1 是逐元素绝对值之和。
- 这条式子在做什么:跳过"解码回 RGB 再抠动作"那一步贵开销,直接在潜在空间里把两帧的差异翻译成动作。L1 比 L2 对离群更鲁棒,适合机器人动作这种偶尔会有大跳变的输出。
四式拼起来,ARDuP 的训练流程就清楚了:先在数据上跑一遍 Co-Tracker + SAM 自动造好 ooo,再用 Lψ\mathcal{L}\psiLψ 学"该往哪儿看",再用 Lϕ\mathcal{L}\phiLϕ 学"在这个重点下未来会怎样",最后用 LIDM\mathcal{L}_\text{IDM}LIDM 学"两帧之间该怎么动"------每一环都为下一环留出一个干净的接口。
四、实验怎么做·结果说明了什么
ARDuP 在一个仿真环境和一个真实数据集上做了验证。
CLIPort 仿真:对未见任务有明显增益
设置 :在 CLIPort 模拟器上,用 11 个任务的约 11 万条演示训练,再在 3 个没见过的任务上测试泛化。
结果(相对 UniPi 基线的成功率提升):
| 任务 | ARDuP | UniPi | 提升 |
|---|---|---|---|
| Place Bowl(放碗) | 86.7% | 65.4% | +21.3% |
| Pack Object(装单物体) | 69.0% | 51.8% | +17.2% |
| Pack Pair(装成对物体) | 46.6% | 30.9% | +15.7% |
提升幅度都在 15 个百分点以上,相当可观。论文也展示了定性对比:带主动区域条件生成的视频,在关注物体周围的视觉质量明显更高,不再像 UniPi 那样容易在关键物体上糊掉或画错。
BridgeData v2 真实数据:杂乱场景里选对物体
设置 :在 BridgeData v2 真实机器人数据集上,用 60,096 条真机轨迹,95% 训练、5% 评测。
结果 :定性上,ARDuP 能在杂乱、拥挤的真实环境里稳定地选对物体、放到正确位置;而 UniPi 在这种场景里"经常选错物体、放错位置"------正好印证了开头那个"抓错重点"的痛点,以及主动区域条件的纠偏作用。
消融实验:主动区域质量越高,任务表现越好
这是 ARDuP 最能说明问题的一组实验。它系统地改变"主动区域"的质量,看任务表现怎么变:
| 主动区域来源 | 任务表现增益 |
|---|---|
| 不用主动区域 | 基线 |
| 训练时用无监督伪主动区域(Co-Tracker+SAM 自动产出) | +1.3% ~ +8.6% |
| 训练时用真值主动区域 | +9.9% ~ +13.7% |
| 推理时也用真值主动区域 | +16.6% ~ +24.8% |
这条递增的链条说明:任务表现随主动区域的质量单调上升。哪怕只是用自动伪造的(不那么完美的)主动区域,就已经能带来正向收益;如果能拿到更准的主动区域,收益还会进一步放大。这等于从正反两面证明了"给视频模型划重点"这个核心思想是真有用的。
论文还引入了一个量化"生成质量"的指标------"任务损失(task loss)",即把生成视频解码出的动作与真值动作之间的 L1 误差。结果显示,带主动区域条件的模型任务损失明显更低,从动作层面验证了"主动区域让生成更贴合预期动作"。这一点其实和综述里反复强调的"视觉合理 ≠ 可执行"遥相呼应------ARDuP 用任务损失这个代理指标,部分地把"生成质量"和"动作可用性"挂上了钩。
五、亮点与为什么重要
ARDuP 的贡献可以拎成三条:
- 诊断出"像素一视同仁"的病根。 它清晰地指出,视频式通用策略容易"画对背景、画错主角",并把这种"视觉损失低、任务却失败"的现象摆到台面上。这个洞察本身就很有价值。
- 提出"主动区域"这个轻量而聚焦的中间条件。 用一张"任务相关区域图"去引导视频生成,让模型把算力和注意力花在刀刃上------这是一种简单、可解释、即插即用的归纳偏置。
- 用 Co-Tracker + SAM 自动伪造监督,零人工标注。 把"哪里是重点"这种本需人标的信息,变成可批量自动产出的伪监督,工程上非常务实。
对后续工作的意义在于:它示范了**"在视频世界模型里引入任务相关的注意力/区域先验"**这一思路的可行性。当大家都在卷"把整段视频生成得多逼真"时,ARDuP 提醒我们------对机器人而言,生成得"对"(任务相关区域准)比生成得"全"(整帧都逼真)更重要。这与 WAM 综述里"显式像素预测是否真的必要、好处是否主要来自训练辅助梯度"的反思,是同一个方向上的早期回声。
六、局限与未解
作者也指出了几处待改进:
- 强依赖 Co-Tracker 的跟踪质量。 在长程任务或复杂背景下,稠密点跟踪可能不准,伪主动区域的质量随之下降,进而拖累整体表现。
- 伪监督本身有噪声。 自动产出的主动区域不可能完美,消融也显示真值主动区域能带来更大增益------这意味着当前的伪监督还有不小的提升空间。
针对这些,作者提出的改进方向包括:用更强的稠密点跟踪模型、引入带噪标签学习技术、以及用视觉-语言模型做"文字引导的分割"(先让 VLM 锁定目标物体、再用 SAM 分割),以获得更干净的主动区域。这些被列为未来工作,当前版本尚未实现。
七、在 WAM 谱系中的位置
把 ARDuP 放回 WAM 的分类树:它属于级联式 WAM (生成未来在前、解码动作在后),预测发生在潜在空间而非纯像素回放------逆动力学直接吃潜在帧、不解码回 RGB,已经体现出"隐式/潜在规划"的取向。
- 承上 :它是对 UniPi 的直接改进------同样是"文生视频 + IDM"的级联范式,但针对 UniPi"像素一视同仁、易抓错重点"的毛病,加上了主动区域这层任务先验。
- 同类对照:和同走"潜在隐式规划"的后辈(本系列接下来要讲的 VPP、VILP)相比,ARDuP 的潜在化更多是为了"聚焦任务区域 + 省去 RGB 解码",还没像 VPP 那样把"逼近实时控制"当作头号目标、也没像 VILP 那样主打"多视角同步 + 极致推理速度"。可以说它是这条隐式规划路线上承前启后的一环:在像素式 UniPi 与高效潜在式 VPP/VILP 之间,先用"主动区域 + 潜在逆动力学"探了探路。
- 方法论上的呼应:ARDuP"给世界模型注入任务相关注意力"的思想,和综述里 MWM"用语义掩码替代 RGB 预测以抗视觉扰动"在精神上相通------都是在追问"未来预测里,到底哪些信息对动作才真正重要"。
八、参考
- 论文标题:ARDuP: Active Region Video Diffusion for Universal Policies
- 出处:IROS 2024(IEEE/RSJ International Conference on Intelligent Robots and Systems);arXiv:2406.13301
- arXiv:https://arxiv.org/abs/2406.13301
- 相关数据集:CLIPort(仿真)、BridgeData v2(真实机器人)
注:本文为基于该论文公开信息的学习性解读,方法与数据集名称均保留英文原名以便检索;具体数字以原论文为准。