阅《Claude Code 橙皮书:从入门到精通》有感
前言
这篇博客是对今天所看的橙皮书进行一个梳理,也是对claude code的一个梳理,当然文章的许多内容也都是Claude code帮忙编写的,写该篇文章的目的是为了让我更好的理解它的核心工作流,当然也希望帮助到正在感兴趣点进来的你们。
1. 六种权限模式:一张表看清全局
Claude Code 提供了六种权限模式,本质上是信任梯度的六个档位------从「一步一问」到「完全不管」。先上全景图:
| 模式 | 编辑文件 | Shell 命令 | 网络请求 | 适用场景 |
|---|---|---|---|---|
| default | 需确认 | 需确认 | 需确认 | 陌生项目、敏感代码库 |
| acceptEdits | 自动放行 | 需确认 | 需确认 | 日常开发主力档(推荐) |
| plan | 禁止 | 禁止 | 禁止 | 需求分析、架构规划、接手新项目 |
| auto | 分类器判定 | 分类器判定 | 分类器判定 | 批量重构、长时间自动化任务 |
| dontAsk | 仅白名单放行 | 仅白名单放行 | 仅白名单放行 | CI/CD 流水线、自动化脚本 |
| bypassPermissions | 无限制 | 无限制 | 无限制 | 隔离沙箱、一次性实验环境 |
这张表的理解要点:信任递增,控制递减。
2. 逐模式深度解析
2.1 default 模式:最安全,也最慢
行为:每次文件编辑、每次 Shell 命令执行、每次网络请求都弹确认框。
设计意图:这是 Claude Code 的出厂设置。它假设你对当前环境一无所知,所以凡事都问。
什么时候用:
-
刚 clone 一个陌生仓库,还没读代码
-
操作生产环境配置(数据库 migration、K8s 部署脚本)
-
仓库里有敏感信息(密钥文件、.env、客户数据)
什么时候不用:
-
日常迭代开发------太慢了,确认框会让你想砸键盘
-
你已经信任的项目------此时 acceptEdits 是更好的选择
橙皮书原话:「default 模式就像驾校教练,副驾有刹车------安全,但你不可能一辈子在驾校里开车。」
2.2 acceptEdits 模式:日常开发的最优解
行为:文件编辑自动放行;Shell 命令、网络请求仍需用户确认。
为什么是「最优解」:
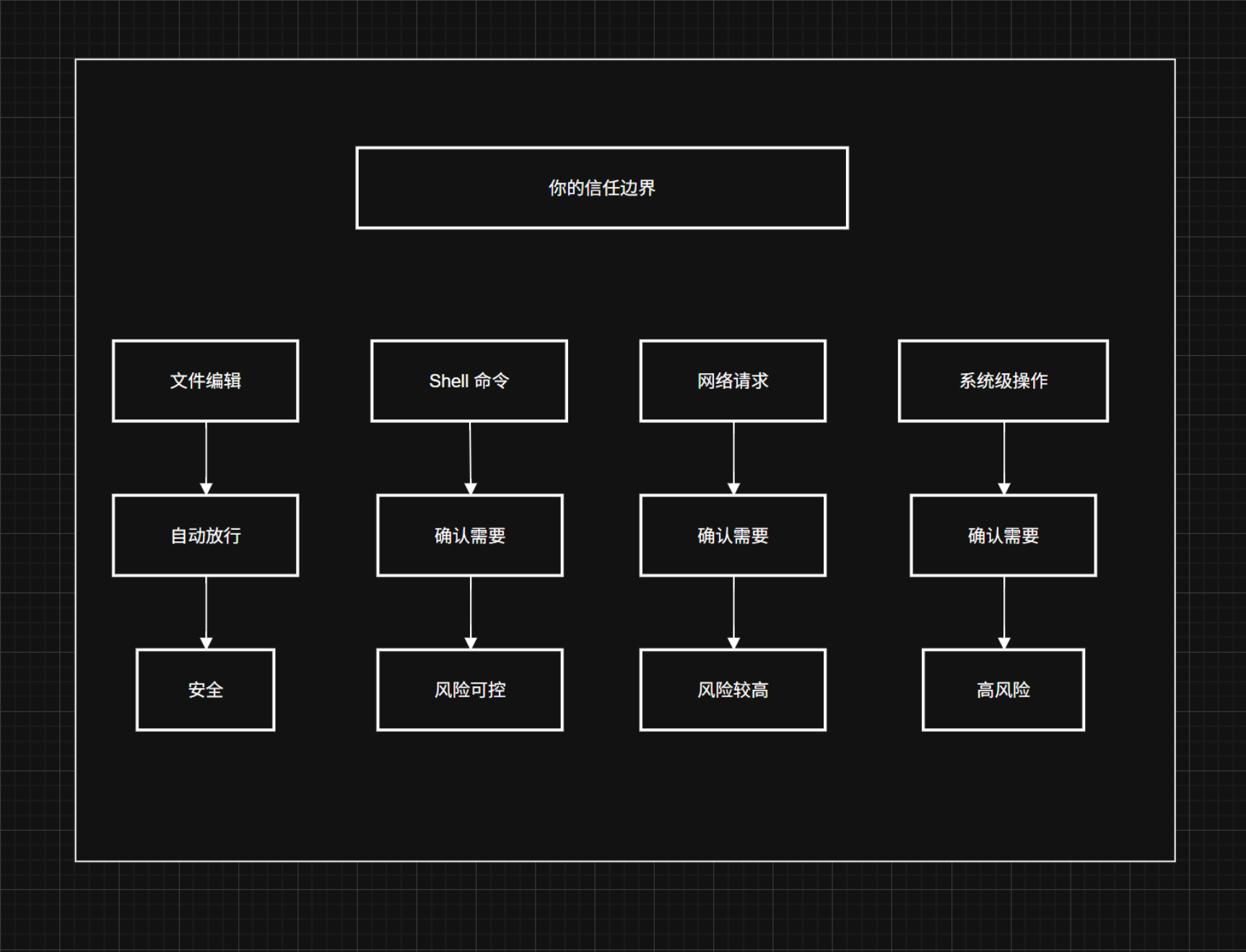
文件编辑的风险可控------有 Git 兜底,错了可以 git diff + git reset 回滚。而 Shell 命令和网络请求有不可逆性:rm -rf、git push --force、调用外部 API 发送数据------这些一旦执行,回滚成本高得多。
日常开发默认开 acceptEdits。 这是效率与安全的最佳平衡点。
2.3 plan 模式:先画地图再上路
核心机制 :plan 模式是一个只读沙箱 。AI 可以读代码、分析架构、搜索文件,但所有写操作、Shell 执行、网络请求全部被系统拦截------不是 AI 自觉不做,而是 Claude Code 的 harness 在工具调用层直接拒绝。
触发方式:
-
命令:
/plan <你的需求> -
快捷键:连按两次
Shift + Tab
四种典型使用场景:
| 场景 | 示例 prompt |
|---|---|
| 接手新项目,快速理解结构 | /plan 帮我理解这个项目的整体架构、核心模块和数据流 |
| 大功能开发,先看整体方案 | /plan 添加用户权限系统,涉及哪些文件?推荐方案是什么? |
| 怀疑 AI 走偏,让它停下来重新审视 | 等一下,先别写。切到 plan 模式重新想想,有没有更优解? |
| 技术选型决策 | /plan 这个项目该用 Tailwind 还是 CSS Modules?结合我们现有的技术栈分析 |
plan 模式输出通常包含:
-
涉及的文件清单及其职责
-
推荐实现方案(含备选方案对比)
-
预估工作量与复杂度
-
潜在风险点和边界情况
「Plan 模式就像买车前让 AI 帮你查参数、看口碑、比价格------但它不能帮你下单。最终决定权在你。」
2.4 auto 模式:分类器驱动的自动驾驶
这是 Claude Code 最具技术含量的模式。
auto 模式背后运行了一个 LLM 安全分类器(safety classifier),对每一次工具调用做出四级安全判定:
【日常开发用 acceptEdits,长时间自动化任务切 auto 模式------比如批量重构、跑全量测试套件、跨几十个文件做统一修改。】
前提条件 :auto 模式要发挥最大价值,需要配合 settings.json 做好信任域配置:
-
企业内网域名 → 可信任的 Shell 操作
-
公司代码仓库 → 可信任的 Git 操作
-
已知安全的 npm 包 → 可信任的安装操作
没有这些配置,auto 模式会频繁触发 soft_deny,最终还是回到你面前要确认------等于白切。
2.5 dontAsk 模式:流水线专用
行为 :只有 settings.json 里显式白名单的工具/命令可用,其他一律拒绝(不是询问,是直接拒绝)。
唯一适用场景:CI/CD 流水线。
dontAsk 与 acceptEdits 的关键区别:acceptEdits 对未知操作是「询问」,dontAsk 对未知操作是「直接拒绝」。后者在无人值守的自动化场景下是安全的唯一选择。
2.6 bypassPermissions 模式:裸奔模式
所有安全检查全部关闭。只用于完全隔离的沙箱环境------比如 Docker 容器、临时虚拟机、一次性实验环境。
慎用
3. 会话管理:对话即资产
如果说六种权限模式控制的是【AI 能做什么】,那会话管理控制的就是【AI 记得什么】以及【你们聊到哪了】。
3.1 会话是什么?
在 Claude Code 中,每一次启动(claude 命令)都会创建一个新的会话(Session)。一个会话包含:
理解这个结构是会话管理的第一步:会话不只是聊天记录,它是 AI 对你项目的全部认知的运行时载体。
3.2 会话的生命周期
橙皮书将一次典型的开发会话分为四个阶段:
启动 ──▶ 执行 ──▶ 压缩/整理 ──▶ 归档
│ │ │ │
│ │ │ └─ 关闭会话,关键信息写入 CLAUDE.md 或 Memory
│ │ │
│ │ └─ 上下文过长时 /compact 压缩,保留关键决策
│ │
│ └─ 核心工作阶段:探索→规划→编码→提交 的循环
│
└─ claude 命令启动,自动加载 CLAUDE.md + Memory每个阶段都有对应操作:
| 阶段 | 操作 | 命令/方式 |
|---|---|---|
| 启动 | 新建会话,自动加载项目上下文 | claude 或 claude --resume |
| 执行 | 核心开发循环 | 自然语言交互 + 模式切换 |
| 压缩 | 上下文过长时压缩历史 | /compact |
| 归档 | 将关键发现持久化 | 写入 CLAUDE.md、Memory、或 Git 提交 |
3.3 会话恢复:断点续传的核心能力
这是橙皮书强调的一个关键特性。Claude Code 支持 会话持久化与恢复------你关闭终端、电脑休眠、甚至过了一周,都可以回到上次中断的地方继续工作。
三种恢复方式:
方式一:启动时选择
─────────────────
$ claude
? 检测到 3 个之前的会话,选择要恢复的会话:
[1] 2026-06-01 14:23 --- 「给 ai-news-digest 添加中文摘要功能」
[2] 2026-05-30 09:15 --- 「重构用户模块的数据层」
[3] 新建会话
方式二:命令行指定
─────────────────
$ claude --resume # 恢复最近一次会话
$ claude --resume 2 # 恢复列表中第 2 个会话
方式三:会话内继续
─────────────────
在 Claude Code 运行中,直接说「继续上次的 xxx 任务」,
如果是近期的会话,AI 会从历史中找回上下文。为什么这很重要?传统 AI 编程工具的痛点:ChatGPT 关掉页面就没了;Copilot Chat 每次新对话都是白纸一张。Claude Code 的会话恢复意味着:
-
大型功能可以跨天开发 :今天写到一半下班,明天
claude --resume继续,AI 记得所有上下文。 -
多项目并行不混淆:每个会话绑定到自己的项目目录,不会串上下文。
-
不怕意外中断:断电、崩溃、误关终端------会话自动保存,重启即可恢复。
3.4 上下文窗口管理:/compact 的艺术
这是会话管理中最具实操价值的部分。Claude Code 的上下文窗口有 token 上限(200k)。随着开发推进,对话历史越来越长,终会触达上限。橙皮书详细讲解了应对策略。
问题本质:
Token 使用分布(典型的长会话)
────────────────────────────────────
█████████████████████████████░░░░░░░ 85%
├─ 系统提示词 ─┤├── 对话历史──┤├free┤
↑
剩余空间不够 AI 做复杂推理当上下文即将耗尽时,你有三个选择:
选择一:/compact ------ 压缩历史(首选)
/compact 做的事情:
-
将漫长的对话历史压缩为一份结构化的对话摘要
-
保留所有关键信息:做了什么、改了哪些文件、做了哪些决策、踩了哪些坑
-
丢弃冗长的原始输出、重复内容、已完成的中间步骤
-
释放 60--80% 的 token 空间,让你继续工作
什么时候该 compact:
-
对话历史明显变长,AI 回复开始变慢
-
上下文使用率超过 70%(用
/context查看) -
你需要开启一个全新的、复杂的功能讨论
选择二:新建会话 ------ 彻底重置
当当前会话的话题已经完全偏离、或者你从【开发模式】切换到【代码审查模式】时,开一个新会话更清爽。新会话会重新加载 CLAUDE.md 和 Memory,但不会携带之前的对话历史。
选择三:分层会话策略 ------ 高级玩法
橙皮书作者推荐了一种「一个功能一个会话」的策略:
会话 A:需求分析 + 方案设计(plan 模式为主)
│
│ 输出:方案文档、文件清单、预估工作量
│ 归档:方案写入 CLAUDE.md 或项目 docs/
│
▼
会话 B:编码实现(acceptEdits 模式为主)
│
│ 输入:读取 CLAUDE.md 中的方案
│ 输出:功能代码
│ 归档:Git commit
│
▼
会话 C:代码审查 + 测试(plan 模式为主)
│
│ 输入:git diff
│ 输出:审查意见、测试用例
│ 归档:审查结论写入 PR这样做的优势:
-
每个会话的上下文高度聚焦,token 浪费少
-
出问题时可以精确回到某个阶段重来
-
不同阶段用不同模式,权限边界清晰
3.5 Memory 系统:跨会话的持久记忆
会话会结束,但有些信息需要跨会话持久化 。Claude Code 提供了 Memory 系统来解决这个问题------存储在 ~/.claude/projects/<项目>/memory/ 目录下,每个文件一条事实。
会话 vs Memory 的分工:
| 维度 | 会话 | Memory |
|---|---|---|
| 生命周期 | 一次对话 | 跨会话持久 |
| 存什么 | 对话过程、中间讨论 | 用户偏好、项目约定、重要决策 |
| 类比 | 工作记忆(RAM) | 长期记忆(硬盘) |
| 容量 | 200k tokens | 无硬性上限 |
什么叫「值得写入 Memory」:
不值得写:
"刚才 AI 帮我改了一个 typo" ← 太琐碎
"src/index.ts 第 42 行有个函数" ← 代码本身在 git 里
值得写:
"用户偏好用 Tailwind 而非 CSS Modules" ← 用户偏好
"该项目 API 返回格式多包了一层 wrapper" ← 项目特殊约定
"部署到生产前必须先过 staging 环境验证" ← 流程约束实际工作流中的 Memory 使用:
开发过程中发现 AI 反复犯同一个理解错误
│
▼
「记住:这个项目的 API 认证用的是 JWT + refresh token 双 token 机制,
不是简单的 Bearer token。」
│
▼
Claude Code 自动写入 Memory 文件
│
▼
下次新会话,AI 启动时自动加载这条 Memory,不会再犯同样的理解错误【你不需要在每次新对话里重新教育 AI。教它一次,它记住一辈子。】
3.6 多会话并行:同时推进多个任务
多会话并行的工作方式,这在真实开发中非常常见------你正在做一个功能,突然来了个紧急 bug,或者你想同时推进两个独立的任务。
多会话的工作模型:
终端 A:会话 1 终端 B:会话 2
┌────────────────────┐ ┌────────────────────┐
│ 项目:my-app │ │ 项目:my-app │
│ 任务:新功能开发 │ │ 任务:修复线上 bug │
│ 模式:acceptEdits │ │ 模式:acceptEdits │
│ │ │ │
│ "帮我实现用户权限 │ │ 线上报了个NPE, │
│ 管理的后端接口" │ │ 帮我定位跟修复 │
│ │ │ │
│ 上下文:权限设计 │ │ 上下文:bug 定位 │
│ 方案、数据库 schema │ │ 堆栈、相关代码文件 │
└────────────────────┘ └────────────────────┘
│ │
│ 同一个 git 仓库 │
└───────────────┬───────────────┘
│
注意隔离:
· 不同分支(git checkout -b)
· 或不同 worktree
· 避免两个会话同时改同一个文件多会话并行三原则:
-
一个会话只做一件事:不要在一个会话里同时聊三个功能------AI 会混淆,你也会。
-
用 Git 分支做物理隔离:两个会话如果涉及文件修改,至少要在不同分支上工作,否则互相覆盖。
-
用 Memory 做信息桥接:会话 A 发现的通用约定,写入 Memory;会话 B 启动时自动继承。
3.7 会话管理的常见坑
坑 1:一个会话扛到底
症状:从项目初始化到上线部署,全程一个会话不换。对话历史 500+ 条,AI 回复越来越慢,上下文过载导致 AI 混淆早期决策。
正确做法:按功能/阶段拆分会话,会话间通过 CLAUDE.md、Memory、Git commit message 传递关键信息。
坑 2:不写 Memory,每次重新教育 AI
症状:每次新会话都跟 AI 说一遍「我们这个项目 API 返回格式不是标准 RESTful」------浪费 token,也浪费生命。
正确做法:AI 一旦犯了理解错误,纠正之后立刻让它写入 Memory。一次纠正,终身受益。
坑 3:/compact 恐惧症
症状:怕 compact 丢失重要信息,死撑着不压缩,直到上下文爆满报错。
正确做法:compact 不是删除------是压缩。关键决策、已修改的文件、当前任务状态都会被保留在摘要中。用完 70% 上下文就应该考虑 compact。
坑 4:忘记恢复会话,重复劳动
症状 :昨天写了一半的功能,今天直接 claude 开了个新会话,AI 一问三不知,你又从头描述一遍需求。
正确做法 :进项目目录直接 claude --resume,恢复上次的会话继续干。养成肌肉记忆。
4. 核心工作流循环:四步法
Claude Code工作流抽象为一个迭代循环:
4.1 循环的力度:大功能 vs 小改动
| 任务规模 | 循环方式 | 模式选择 |
|---|---|---|
| 大功能(跨 5+ 文件,新增模块) | 完整的四步循环,每一步都认真走 | 探索(plan) → 规划(plan) → 编码(acceptEdits) → 提交 |
| 中等改动(改 2--5 个文件) | 压缩循环,探索+规划合并 | 规划(plan) → 编码(acceptEdits) → 提交 |
| 小修小补(单文件、改一行) | 直接编码 | 编码(acceptEdits) → 提交 |
4.2 循环中的回头箭
一个容易被忽视的点:循环不是单向的。 Plan 出来的方案在执行中暴露问题,你要有勇气回到 Plan 阶段重新设计。
你在 acceptEdits 下写新功能,写到一半突然觉得 AI 的方案可能有问题。不要硬着头皮让它继续写。立刻切到 plan 模式:「等一下,你先别写了,重新想想是不是有更优解。」AI 重新分析,给修正方案,审完再切回 acceptEdits。
这种随时叫停、调整方向、重新出发的能力,在传统编程中需要重构、回滚、重写的成本,在 Claude Code 中变成了两次快捷键切换。
5. 模式切换的实战决策树
开始一个任务
│
├─ 这是我熟悉的项目吗?
│ │
│ ├─ 是 ──▶ 改动影响范围大吗?(3+ 文件 / 新模块)
│ │ │
│ │ ├─ 是 ──▶ 切 plan 模式,先看方案
│ │ │ │
│ │ │ ├─ 方案 OK ──▶ 切 acceptEdits,执行
│ │ │ │
│ │ │ └─ 方案有问题 ──▶ 继续在 plan 下讨论
│ │ │
│ │ └─ 否(小改动)──▶ 直接用 acceptEdits
│ │
│ └─ 否 ──▶ 用 default 或 plan 模式先探索项目
│ │
│ └─ 熟悉之后再切入 acceptEdits
│
├─ 这是一个长时间自动化任务吗?(批量重构 / 跑全量测试)
│ │
│ ├─ 是 ──▶ 切 auto 模式,前提是 settings.json 信任域已配好
│ │
│ └─ 否 ──▶ 回到上面的判断
│
└─ 这是 CI/CD 流水线吗?
│
├─ 是 ──▶ dontAsk,配置好白名单
│
└─ 否 ──▶ 回到上面的判断6. Permissions 白名单:渐进式驯养
橙皮书在这一章还讨论了 permissions 配置的实操理念。核心观点就一个:
不要一上来就搞完美配置。
作者的建议是渐进式收敛:
第一周:用 acceptEdits,每遇到一个需要确认的命令,
如果你觉得"这个操作以后都不用问我",
就加到 settings.json 的白名单里。
第二周:白名单已经覆盖了 90% 的日常操作,
确认框变得很少,体验丝般顺滑。
第三周:白名单基本稳定,你几乎感知不到权限确认的存在。这种做法的好处:
-
不需要预判:你不用在第一天就去猜"哪些命令我未来会频繁用到"
-
低风险:每个加入白名单的命令都是经过你实际检验的
-
自然收敛:用得越久,白名单越贴合你的实际工作流
作者把这种渐进式驯养形容为:「跟养猫似的------开始它啥都不懂,每个操作都来蹭你;你慢慢教它,后来它就懂你的节奏了,安静高效地自己干活。」
7. 常见反模式与纠正
橙皮书第四章穿插了几条「别这样用」的提醒,我整理如下:
反模式 1:永远只用 default 模式
症状:所有操作都弹确认框,点确认点到麻木,最后是「无脑点确认」------安全形同虚设。
纠正:信任的项目切 acceptEdits,让确认框回归它的本意------只有真正需要你关注的操作才弹出来。
反模式 2:一上来就开 auto 模式写新功能
症状:AI 改了一大堆文件,你中途没有介入,最后发现方向跑偏了。
纠正 :新功能先 plan,定了方案再切 acceptEdits 或 auto。auto 模式适合你已经知道要做什么、只是量大重复 的场景(比如「把项目里所有 var 改成 const」)。
反模式 3:plan 模式审完方案,不切模式就让 AI 动手
症状:在 plan 模式下说「OK 开始写吧」,AI 不动------然后你觉得 AI 不行。
纠正:plan 模式在工具调用层拦截了所有写操作。审完方案后,必须手动切到 acceptEdits(或 auto),AI 才能动手。这不是 AI 的问题,是你忘了从「地图室」走到「工地」。
反模式 4:白名单一上来就写满
症状 :第一天就把 npm *、git *、rm * 全加到白名单。
纠正:你给了 AI 一个「随意删库跑路」的权限集。渐进式配置,一步一步来。
反模式 5:一个会话死扛到底
症状:从项目初始化到上线,全程不换会话。上下文臃肿,AI 回复越来越慢,早期关键决策被淹没在历史中。
纠正:大功能拆分会话,关键信息写入 Memory 或 CLAUDE.md。一个会话聚焦一件事,上下文清爽,AI 表现更好。
8. 核心 Takeaways
如果整篇文章只能记住几句话,那么浓缩精华是:
-
默认用 acceptEdits ------ 编辑自动、命令确认,效率与安全的黄金平衡点。
-
大改动先 plan ------ 让 AI 先画地图,你确认方向,再切模式让它跑。
-
白名单渐进式养 ------ 别一上来就搞完美配置,边用边加,一周后自然收敛。
-
会话是资产,主动管理 ------ 用
--resume断点续传,用/compact瘦身,用 Memory 做跨会话持久化。 -
一个会话一件事 ------ 多任务并行用多会话 + Git 分支隔离,别让 AI 在同一个会话里同时处理三个需求。
记住这五条,再加上肌肉记忆 Shift + Tab 在模式间横跳,以及每次结束时问自己一句「刚才有什么值得写进 Memory 的?」,你的 Claude Code 使用效率会有质的飞跃。