在 WAM 谱系里,级联式(先预测未来、再解码动作)这一大支下,"如何从预测出的视频里把动作抠出来"是个核心命题。前面我们见过用逆动力学模型(IDM)学习式回归动作的路线,也见过用光流做几何反推的路线。本篇要讲的 RIGVid(Robots Imitating Generated Videos,机器人模仿生成视频),把这条"几何式动作提取"推到了一个相当极端、也相当优雅的地步:它不收集任何真机演示、不做任何机器人专属训练,仅凭一个文生视频大模型"脑补"出的一段操作视频,外加一套纯几何的位姿跟踪与重定向流程,就能让真实机器人完成倒水、揭盖、放铲子、扫垃圾这类带接触、带形变的复杂操作。
更反直觉的是它的一个核心选择:跟踪的不是机器人手或工具,而是"被操作的那个物体"。这一念之差,恰恰是它能绕开传统逆运动学、做到"换个机器人也能用"的关键。下面我们一步步拆开看。
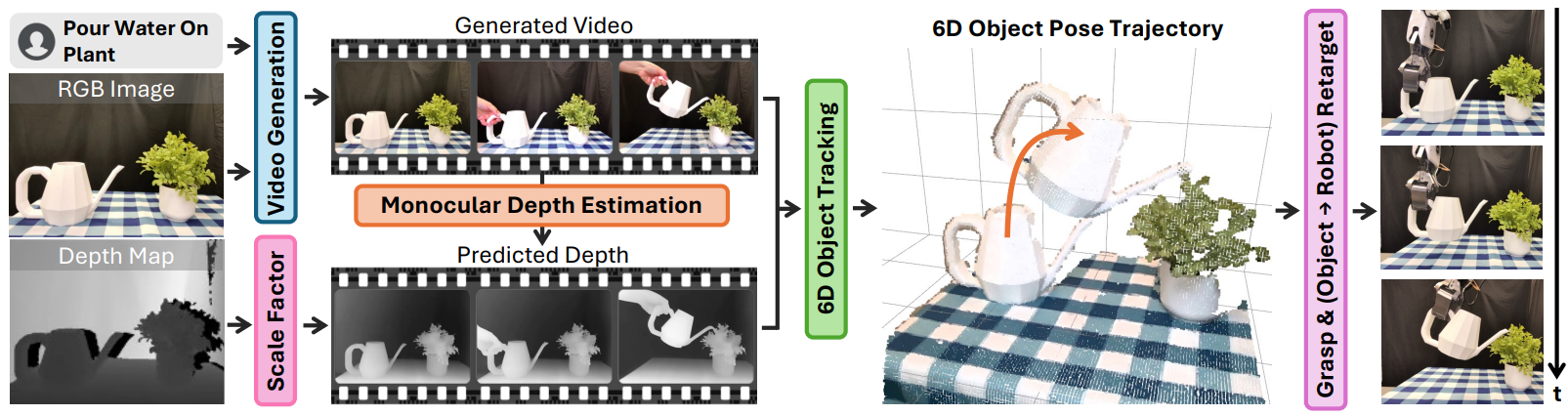
一、要解决什么问题:演示数据太贵,能不能让 AI "脑补"出来?
今天的机器人操作学习,主流仍然是"喂演示"。无论是模仿学习还是视觉-语言-动作模型(VLA),背后都要海量的 (观测, 动作) 配对数据------通常靠人遥控真机一条条采集。这套"黄金数据"质量高,但贵得离谱:受限于实验室、绑定特定机器人本体、采一个新任务往往要重新录上百条轨迹。
于是研究者一直在问:互联网上不是有海量视频吗?能不能让机器人直接"看视频学动作"? 这就是"级联式 WAM"里"基于像素空间的显式规划"这一路的初心------先用一个世界模型(这里就是视频生成模型)画出"接下来该发生什么"的一段视频,再从这段视频里反解出机器人该执行的动作。开创性的 UniPi 就是这个思路。
但"从视频里抠动作"这一步,长期是个老大难。打个比方:视频生成模型像一位很会画分镜的导演,能把"往杯子里倒水"画得活灵活现;可机器人要的不是分镜,而是一串精确到毫米和度数的电机指令。怎么把"好看的画面"翻译成"能执行的动作"?过去主要有三条路,各有各的坑:
- 学习式 IDM:训练一个网络看相邻两帧、回归出中间动作。问题是它仍然需要带动作标注的数据来训练,且对没见过的场景泛化差。
- 光流反推(如 AVDC):算出画面里每个像素往哪挪,再优化出轨迹。问题是光流误差会逐帧累积,画面一旦有遮挡、大幅旋转就崩。
- 稀疏点跟踪 / 特征场(如 Track2Act、Gen2Act、4D-DPM):跟踪若干关键点再用 PnP 之类的算法解位姿。问题是物体一旦被大面积遮挡或发生大旋转,点就跟丢了,结果抖得厉害。
RIGVid 的作者把这些痛点看在眼里,给出一个干净利落的判断:与其用稀疏、易碎的对应关系去"凑"轨迹,不如直接做物体级的 6D 位姿跟踪------一次性把被操作物体在三维空间里的"位置 + 朝向"完整地、稳稳地跟出来。
二、核心思想与直觉:跟"被操作的物体",而不是跟"手"
RIGVid 的核心 idea 用一句人话概括就是:
给一句语言指令和一张当前场景照片,让文生视频模型"脑补"出一段完成任务的视频;用一个视觉-语言模型(VLM)当"质检员"把脑补失败的视频筛掉;再用 6D 位姿跟踪器把视频里被操作物体的运动轨迹完整跟出来;最后把这条物体轨迹"平移"到机器人手上去执行。
这里面最值得玩味的,是那个"跟物体、不跟手"的选择。我们换个生活化的类比来体会它的妙处。
设想你要教别人"把铲子放到平底锅上"。一种教法是盯着对方的手 怎么动------可手的姿势千变万化,胖手瘦手、左手右手、机械夹爪和五指灵巧手完全不同,盯着手学,换个人就废了。另一种教法是只盯着铲子 :铲子从这儿挪到那儿、转了多少度、最后稳稳搭在锅沿上。只要铲子走对了这条路,到底是谁、用什么抓着它走的,根本无所谓。
RIGVid 选的就是后者。它的关键洞察是:
- 任务的本质往往由"物体怎么动"定义,而不是由"末端执行器怎么动"定义。倒水成功与否,取决于水壶的倾倒轨迹;揭盖成功与否,取决于盖子的抬升轨迹。
- 一旦机器人抓住了物体 ,物体和夹爪之间就形成了一个固定的相对变换 (刚性连接)。这意味着:只要我知道物体该怎么走,再叠加上"夹爪相对物体偏了多少"这个固定量,就能立刻算出夹爪该怎么走------这是一步纯粹的坐标变换,根本不需要解逆运动学(IK,即"已知手该到哪个位姿、反求各关节角度"的那套求解)里那些与具体机械臂结构强绑定的复杂方程。
于是"换机器人"这件事被极大简化了:换一只机械臂、换一种夹爪,只需要更新"夹爪到物体"这一个偏移量 ,物体轨迹本身一字不改。这就是论文反复强调的"与本体无关(embodiment-agnostic)"。在 WAM 分类里,这正是典型的"几何式动作提取"------把抠动作从一个需要学习、需要标注的机器学习问题,降维成一道解析几何题。
放到 WAM 大图景里,RIGVid 和同属几何式提取的 Dreamitate 是近亲,但它更激进:Dreamitate 仍跟踪工具,RIGVid 直接跟被操作物体,且整条链路零训练、零演示。
三、方法详解:五步流水线
RIGVid 的输入很朴素------一帧 RGBD 观测(彩色图 + 深度图)加一句语言指令。输出则是一条可以直接在真机上执行的末端轨迹。中间走五步,我们逐步拆解,每步先讲"在干嘛",再讲"怎么做"。
第一步:生成候选视频------让导演先画几版分镜
在干嘛:把"当前这张照片 + 一句指令"喂给文生视频模型,让它生成若干段"接下来该怎么做"的视频。
怎么做 :RIGVid 实测下来,Kling v1.6 是当前最适合这件事的视频生成模型。作为对比,把同样的任务交给 Sora,几乎全军覆没(论文报告 Sora 在这些任务上的通过率为 0%);Kling v1.5 则时好时坏。这说明一件很现实的事:这套方法的上限,直接被视频生成模型的质量卡着------生成得越像、越符合物理,下游成功率就越高。
值得强调的是,这里生成的视频是针对当前真实场景量身脑补的(用真实照片做首帧),而不是从网上检索一段别人的视频。这保证了画面里的物体、布局和机器人面对的现场是一致的。
第二步:VLM 质检------把"脑补翻车"的视频踢掉
在干嘛:视频生成模型并不总是听话,常常画出"没真的完成任务"的视频(比如手伸过去了却没倒水)。需要一个质检员把这些废片筛掉。
怎么做 :用 GPT-4o(一个视觉-语言模型,能"看图 + 读文字 + 做判断")当质检员。具体做法很简单:从每段视频里等间隔取 4 帧,让 GPT-4o 判断"画面里是否有一只可见的手,确实执行了指令描述的那个动作"。不合格的直接丢弃。
这一步的效果在数据上很明显。各任务的通过率分别约为:倒水 83%、揭盖 66%、放置 55%、清扫 45%。可以看到,越复杂的任务(放置、清扫)翻车率越高,往往要多生成几次才能挑出一段能用的。但只要筛出来的是好视频,下游表现就和真人演示几乎没差别------这正是论文那句"筛选后的生成视频,效果不输真实演示"的底气。
第三步:深度估计------把 2D 画面"撑"回 3D
在干嘛:生成的视频是 2D 的,但要算物体的三维轨迹,得知道每一帧的深度。
怎么做 :对生成视频的每一帧做单目深度预测 (从单张彩色图估计深度)。这里有个经典难题------单目深度天生有"尺度与平移歧义"(estimated depth 只对到相对远近,不知道绝对尺度)。RIGVid 的解法很巧:用首帧来对齐。生成视频的第一帧本质上就是真实场景,因此把首帧预测深度,与开机时拿到的真实深度图(围绕被操作物体那块区域)对齐,解出尺度和平移;这个标定参数再套用到整段视频上。一次对齐,全程受用。
第四步:6D 位姿跟踪------把"被操作物体"的轨迹稳稳跟出来
这是 RIGVid 的技术核心,也是它区别于光流/稀疏点路线的胜负手。它分几个小动作:
- 找出"主角物体":先让 GPT-4o 根据首帧和指令,判断"最可能被操作的是哪个物体"(比如"倒水"里的水壶)。
- 把主角框出来、抠出来 :用 Grounding DINO (一个"文字 → 检测框"的开放词表检测器)把 GPT-4o 说的物体在画面里框出来,再用 SAM-2(Segment Anything 的视频版,能精细分割并跨帧跟踪掩码)把它精细地抠成分割掩码。
- 重建物体网格 :用 BundleSDF 从一小段"把物体在相机前转一圈"的 RGBD 视频里,重建出该物体的三维网格(mesh)。
- 跟踪 6D 位姿 :把网格交给 FoundationPose------一个强大的物体 6D 位姿跟踪器------让它在生成视频的每一帧里,估计该物体的完整 6D 位姿(三维位置 + 三维朝向)。
- 轨迹平滑:对跟出来的位姿序列做均值滤波,尤其把旋转部分抚平,避免抖动。
为什么用 FoundationPose 而不是跟稀疏点? 直觉上,跟一整个物体的"刚体位姿",比跟几十个孤立的点要稳健得多------哪怕物体有一半被遮住、或者转了一个大角度,只要还能看到一部分配合预重建的网格,位姿就能稳稳估出来。而稀疏点一旦被遮就直接跟丢。论文的对比实验(见第四节)会用硬数字证明这一点。
第五步:轨迹重定向 + 闭环跟踪------把物体轨迹"搬"到机器人手上
在干嘛:现在我们有了"被操作物体应该走的 6D 轨迹",要把它变成"机器人末端执行器应该走的轨迹",并稳稳地执行下去。
怎么做,分两个阶段:
(a)抓取与变换合成。 机器人先得抓住物体。用 AnyGrasp(一个抓取检测器)在物体掩码范围内挑出得分最高的抓取位姿,执行抓取。抓住的那一刻,记录下两个变换:① 物体相对夹爪的位姿;② 夹爪到末端执行器的固定偏移。把这两者一组合,就得到了"物体 → 末端执行器"的固定刚性变换。
(b)重定向。 把这个固定变换,套用到整条物体轨迹的每一个点上,物体轨迹立刻就变成了末端执行器轨迹。全程没有解任何逆运动学方程------这就是前面说的"几何式"的精髓。换机器人时,只需重新标定一次这个固定变换即可。
(c)闭环纠偏。 执行不是"算好就一路莽到底"的开环过程。RIGVid 在执行全程用 FoundationPose 实时跟踪真实物体的 6D 位姿 ,与预先算好的目标轨迹逐点比对。一旦发现偏差超过阈值(位置偏离超过 3 厘米,或朝向偏离超过 20 度),机器人就回退到上一个成功的轨迹点重新来过。这套机制让它能扛住执行中的扰动------比如有人故意推一把、或者夹爪打滑------大大提升了鲁棒性。
把这五步连起来看,RIGVid 实际上构成了一条"生成 → 质检 → 撑 3D → 跟物体 → 搬到手上"的零训练流水线。整条链路里没有一个组件是为某台机器人专门训练的,复用的全是现成的通用大模型(Kling、GPT-4o、Grounding DINO、SAM-2、FoundationPose、AnyGrasp)。
核心公式与逻辑梳理
RIGVid 几乎是一篇"纯工程"论文------它的力气主要花在把一串现成的视觉/位姿大模型流水线串起来,关键步骤是几何变换而不是要学习的损失函数。但即便如此,把这条流水线用形式化记号写一遍,能让"为什么换机器人只改一个量"这件事一眼看清。
方法逻辑链(六步):
- 生成与质检 :用 Kling 文生视频模型,以语言指令 ℓ\ellℓ 和首帧 I0I_0I0 为条件,生成候选视频 V∼pKling(⋅∣ℓ,I0)V \sim p_\text{Kling}(\cdot \mid \ell, I_0)V∼pKling(⋅∣ℓ,I0),再用 GPT-4o 给视频打布尔通过/不通过;
- 深度估计 + 首帧对齐 :用单目深度网估 D^t\hat D_tD^t,再用首帧的真实深度 D0realD_0^\text{real}D0real 解一对仿射参数 (s,b)(s, b)(s,b),把整段视频都校到同一尺度;
- 物体定位:GPT-4o 选出被操作物体,Grounding DINO 给框、SAM-2 给跨帧掩码;
- 6D 位姿跟踪 :用 BundleSDF 预重建物体网格 M\mathcal{M}M,再用 FoundationPose 在每帧上算出该物体的位姿 Tobjt∈SE(3)T_\text{obj}^t \in SE(3)Tobjt∈SE(3);
- 抓取并算"物体↔末端"变换 :用 AnyGrasp 抓住物体后,记录下一个固定的刚体变换 TeeobjT_\text{ee}^\text{obj}Teeobj(夹爪末端相对物体);
- 重定向 + 闭环:把物体轨迹乘上这个固定变换,得到末端轨迹并执行;执行过程中持续比对预测轨迹与实测物体位姿,超阈值就回退到上一个安全点。
核心公式:
(1) 首帧深度仿射对齐
(s∗,b∗)=argmins,b ∑p∈Robj(s⋅D^0(p)+b−D0real(p))2,Dt=s∗D^t+b∗ (s^*, b^*) = \arg\min_{s, b} \; \sum_{p \in \mathcal{R}_\text{obj}} \bigl( s \cdot \hat D_0(p) + b - D_0^\text{real}(p) \bigr)^2, \quad D_t = s^* \hat D_t + b^* (s∗,b∗)=args,bminp∈Robj∑(s⋅D^0(p)+b−D0real(p))2,Dt=s∗D^t+b∗
- 符号说明:D^0\hat D_0D^0 是单目深度网在首帧的预测,D0realD_0^\text{real}D0real 是开机时真实 RGBD 相机拿到的深度;Robj\mathcal{R}_\text{obj}Robj 是首帧上被操作物体所在的像素区域;(s,b)(s, b)(s,b) 是仿射的"尺度"和"平移"两个标量;D^t\hat D_tD^t 是后续每帧的预测深度,DtD_tDt 是校正后的深度。
- 这条式子在做什么:单目深度只能猜出"相对远近",不知道一米到底有多长。所以用真机相机给的物体那一块绝对深度当"尺子",一次性把尺度和零点拧对------之后整段生成视频里所有点的深度就都校到了真实坐标系下。一次标定、全程受用。
(2) 6D 物体位姿轨迹
Tobjt=Rttt0⊤1∈SE(3),t=0,1,...,H−1 T_\text{obj}^t = \begin{bmatrix} R_t & \mathbf{t}_t \\ \mathbf{0}^\top & 1 \end{bmatrix} \in SE(3), \qquad t = 0, 1, \dots, H-1 Tobjt=Rt0⊤tt1∈SE(3),t=0,1,...,H−1
- 符号说明:Rt∈SO(3)R_t \in SO(3)Rt∈SO(3) 是物体在第 ttt 帧的三维朝向(旋转矩阵),tt∈R3\mathbf{t}t \in \mathbb{R}^3tt∈R3 是物体的三维位置;SE(3)SE(3)SE(3) 就是"刚体位姿"这一类齐次变换的总称;HHH 是视频帧数。FoundationPose 给的就是逐帧的这个 TobjtT\text{obj}^tTobjt。
- 这条式子在做什么:把"物体在三维里怎么摆"打包成一个 4×44\times 44×4 矩阵。比起跟踪几十个稀疏点再凑位姿,整体刚体跟踪只要 mesh 的一部分还能看见就能稳定输出------这就是为什么 RIGVid 在大遮挡、大旋转下依旧稳。
(3) 物体轨迹 → 末端轨迹的重定向
Teet=Tobjt⋅Teeobj,其中 Teeobj 在抓取瞬间一次性测得,全程不变 T_\text{ee}^t = T_\text{obj}^t \cdot T_\text{ee}^\text{obj}, \quad \text{其中 } T_\text{ee}^\text{obj} \text{ 在抓取瞬间一次性测得,全程不变} Teet=Tobjt⋅Teeobj,其中 Teeobj 在抓取瞬间一次性测得,全程不变
- 符号说明:Teet∈SE(3)T_\text{ee}^t \in SE(3)Teet∈SE(3) 是机器人末端执行器在第 ttt 帧应该到达的位姿;TeeobjT_\text{ee}^\text{obj}Teeobj 是"末端相对物体"的固定刚体变换(包括"夹爪相对物体"和"末端相对夹爪"两部分组合)。
- 这条式子在做什么:这是 RIGVid 的"灵魂"------抓住物体那一刻起,末端和物体就被焊死成一个整体,于是只要物体该走的轨迹有了,末端的轨迹就是它乘上一个固定的偏移量。没有逆运动学、没有学习、没有动作标注 ,纯一道矩阵乘法。换机器人只需在新机上重测一次 TeeobjT_\text{ee}^\text{obj}Teeobj,物体轨迹本身一字不改------这就是"本体无关"在数学上的极简写法。
(4) 闭环偏差判据
trigger_backtrack(t) ⟺ ∥tobjt−tobjt,real∥2>3 cm 或 ∠ (Robjt,Robjt,real)>20∘ \text{trigger\backtrack}(t) \iff \bigl\| \mathbf{t}\text{obj}^t - \mathbf{t}\text{obj}^{t,\text{real}} \bigr\|2 > 3\,\text{cm} \;\;\text{或}\;\; \angle\!\bigl(R\text{obj}^t, R\text{obj}^{t,\text{real}}\bigr) > 20^\circ trigger_backtrack(t)⟺ tobjt−tobjt,real 2>3cm或∠(Robjt,Robjt,real)>20∘
- 符号说明:左侧是"应到位姿",右侧带 real\text{real}real 上标的是 FoundationPose 在真机上实时测出的"实际位姿";∥⋅∥2\|\cdot\|_2∥⋅∥2 是欧氏距离,∠(⋅,⋅)\angle(\cdot, \cdot)∠(⋅,⋅) 是两个旋转矩阵之间的角度(可由 arccos((tr(R1⊤R2)−1)/2)\arccos((\text{tr}(R_1^\top R_2)-1)/2)arccos((tr(R1⊤R2)−1)/2) 算)。
- 这条式子在做什么:每一步都检查"现在物体在不在该在的位置和朝向上"。一旦差得超过 3 厘米或者 20 度,就退回到上一个被验证为成功的轨迹点重来。这把开环的"算好就一路莽"变成了闭环的"边做边纠",扛得住执行中的打滑、推扰等扰动。
四条公式拼起来,RIGVid 的全部"动作生成"逻辑------撑 3D、跟物体、变末端、纠偏差------就完整呈现出来了。它的妙处恰在于:核心算法没有一处"需要训练",全是几何与查询。
四、实验怎么做·结果说明了什么
在四个真实任务上"以假乱真"
RIGVid 在四个真机操作任务上评测:倒水、揭盖、放铲子到平底锅、扫垃圾。这组任务覆盖了几类不同的挑战------较大的深度变化、又薄又会被部分遮挡的物体(如锅盖、铲子)、以及多样的几何形状与动作类型。
最核心的一组对照是"用筛选后的 Kling v1.6 生成视频 vs 用真实演示视频",结果几乎完全持平:
| 任务 | RIGVid(生成视频) | 真实演示 |
|---|---|---|
| 倒水 | 100% | 100% |
| 揭盖 | 80% | 80% |
| 放铲子 | 90% | 90% |
| 扫垃圾 | 70% | 70% |
| 平均 | 85% | 85% |
这张表是全文最有冲击力的结论:精心筛选过的"AI 脑补视频",在下游任务成功率上和真人演示打成平手。换句话说,至少在这几类任务上,昂贵的真机演示数据,可以被"视频生成 + VLM 筛选"这套零成本组合替代。
跟其他"抠动作"路线比,6D 位姿大幅领先
RIGVid 还把"从视频抠轨迹"这一步换成各路前作来做对照(视频生成这步保持一致),结果差距巨大:
| 方法 | 倒水 | 揭盖 | 放铲子 | 扫垃圾 | 平均 |
|---|---|---|---|---|---|
| RIGVid(6D 位姿) | 100% | 80% | 90% | 70% | 85.0% |
| Gen2Act(稀疏点 + PnP) | 100% | 70% | 60% | 50% | 67.5% |
| 4D-DPM(特征场) | 50% | 30% | 30% | 20% | 35.0% |
| AVDC(光流) | 60% | 40% | 20% | 10% | 32.5% |
| Track2Act(2D 点轨迹) | 20% | 10% | 0% | 0% | 7.5% |
解读一下这些数字背后的故事:
- Track2Act(学习式 2D 点轨迹预测 + PnP 抬升)几乎全线崩盘,对新场景泛化极差。
- AVDC(光流 + 优化重建轨迹)受累于光流误差逐帧累积。
- 4D-DPM(3D 高斯场 + 特征跟踪)跟踪不稳、轨迹抖动剧烈。
- Gen2Act(从生成视频抠稀疏点 + PnP)是这批里最强的对手,但物体一旦大面积被遮、或大幅旋转就会失手。
- RIGVid 的物体级 6D 跟踪,在深度变化大、有遮挡的场景里稳定性碾压上述所有稀疏/光流方法。
跟"VLM 直接出关键点"比,视频监督更富信息
另一组对照是和 ReKep (一种让 VLM 直接预测关键点约束的方法)比:RIGVid 85% vs ReKep 50%。这说明一整段视频所携带的信息量,远比一组压缩过的关键点丰富------视频把"过程"完整地呈现了出来,而关键点只是几个稀疏锚点。
泛化性与消融
- 换本体也能用 :把整套流程迁移到 ALOHA(一种双臂机器人)上,倒水任务依旧拿到 80% 成功率;并能扩展到双臂任务以及擦拭、搅拌、熨烫、拔插头等更多操作。这印证了"换机器人只需重标一个变换"的本体无关性。
- 生成质量决定一切 :未筛选的 Sora(0% 成功)→ 未筛选的 Kling v1.5(时好时坏)→ 筛选后的 Kling v1.6(80--100%),清晰地呈现出"视频生成质量 ↔ 任务成功率"的强正相关。这也反过来说明 VLM 质检这一步不是可有可无的装饰,而是把"能用的视频"从"翻车视频"里捞出来的关键阀门。
五、亮点与为什么重要
把 RIGVid 的贡献拎成几条:
- 零演示、零训练,却能比肩真人演示。 它用现成的视频生成模型 + VLM 筛选,绕开了机器人操作学习里最贵的一环------真机演示采集。这对"如何低成本扩展到新任务"是一个很有说服力的答案。
- "跟物体、不跟手" + 轨迹重定向,把动作提取从学习问题降为几何问题。 不需要逆运动学、不需要动作标注,换机器人只改一个固定变换。这是它本体无关、即插即用的根基。
- 物体级 6D 位姿跟踪,实证胜过光流/稀疏点/特征场。 在有遮挡、大旋转、深度变化的真实场景里,刚体位姿跟踪的稳健性是稀疏对应关系比不了的。
- 闭环纠偏带来鲁棒性。 实时跟踪 + 偏差回退,让它能扛住执行中的人为扰动和打滑。
对后续工作的意义在于:它提供了一个强有力的证据------在级联式 WAM 里,"显式像素预测 + 几何式动作提取"这条路,配上够好的视频生成模型和够稳的位姿跟踪器,是真的能跑通到真机的,而且成本极低。这为"用视频大模型当机器人世界模型"这一大方向打了一针强心剂。
六、局限与未解
作者也坦诚了几处短板:
- 深度估计是头号失败源。 即便视频生成得很好,单目深度的固有误差仍会影响位姿跟踪的精度,是当前最主要的翻车原因。
- 依赖预重建的物体网格。 FoundationPose 需要事先有物体的三维网格(靠 BundleSDF 重建)。论文也试了免网格的替代方案,但目前还达不到实时部署的要求。
- 复杂任务的视频生成成功率仍偏低。 像放置、清扫这类任务,生成通过率只有 45%--55%,往往要反复生成多次才能挑出一段能用的,整体算力开销因此偏高------这比直接用 VLM 出关键点的方法要贵不少。
这些局限大体可归结为对"现成大模型质量"的依赖:视频生成更准、单目深度更稳、位姿跟踪更省,RIGVid 就能水涨船高。
七、在 WAM 谱系中的位置
把 RIGVid 放回 WAM 的分类树:它属于级联式 WAM 下"基于像素空间的显式规划 ",并且走的是其中的"几何式动作提取"分支------即不用学习式 IDM 回归动作,而是用几何手段(这里是物体 6D 位姿跟踪 + 刚体变换重定向)解析地反推动作。
- 承上:它和 UniPi 一脉相承(都先用视频生成模型画出未来再抠动作),但 UniPi 用学习式 IDM、需要训练;RIGVid 把抠动作彻底几何化、做到零训练。
- 同类对照:与同走几何路线的 Dreamitate(跟踪工具)相比,RIGVid 跟踪被操作物体、更彻底地实现本体无关;与 AVDC(光流)、Im2Flow2Act/3DFlowAction(光流)、Track2Act/Gen2Act(点轨迹)相比,它用物体级 6D 位姿换来了在遮挡和大旋转下的稳健性。
- 启下:它和"基于潜在表征的隐式规划"(如本系列后面要讲的 VPP、VILP)形成鲜明对照------后者嫌像素级合成太慢,干脆跳过解码回像素、在潜在空间里规划;而 RIGVid 反其道而行,坚持在像素空间显式预测,再用几何手段把"慢"换成"准且通用"。两条路线各擅胜场,正是 WAM 领域"架构耦合之争"在动作提取这一层的生动缩影。
八、参考
- 论文标题:Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations(RIGVid)
- 作者:Shivansh Patel, Shraddhaa Mohan, Hanlin Mai, Unnat Jain, Svetlana Lazebnik, Yunzhu Li(UIUC / UC Irvine / Columbia 等)
- 会议/年份:arXiv 2025(arXiv:2507.00990);ICLR 2026(亦曾于 CVPR 2025 FMEA Workshop 口头报告)
- arXiv:https://arxiv.org/abs/2507.00990
- 项目主页:https://rigvid-robot.github.io/
注:本文为基于该论文公开信息的学习性解读,方法名称与数据集均保留英文原名以便检索;具体数字以原论文为准。