小肥柴的Hadoop之旅 快速实验篇(A5)基于 MapReduce 的降水百分位数计算与干旱等级划分
-
- 目录
- 前言
- [0. 背景知识:从绝对阈值到相对阈值](#0. 背景知识:从绝对阈值到相对阈值)
- [1. 任务概述与目标](#1. 任务概述与目标)
- [2. 干旱等级划分标准](#2. 干旱等级划分标准)
- [3. MR 作业设计](#3. MR 作业设计)
-
- [3.1 整体架构](#3.1 整体架构)
- [3.2 Combiner 适用性分析](#3.2 Combiner 适用性分析)
- [3.3 内存估算](#3.3 内存估算)
- [3.4 为何将 A2-2 的结果作为 A5 的输入?](#3.4 为何将 A2-2 的结果作为 A5 的输入?)
- [4. 正确理解 MapReduce 中的 `<K, V, P>` 三元组](#4. 正确理解 MapReduce 中的
<K, V, P>三元组) -
- [4.1 分区编号 P 在数据流中的角色](#4.1 分区编号 P 在数据流中的角色)
- [4.2 默认分区器](#4.2 默认分区器)
- [5. MR程序原理与编码实现](#5. MR程序原理与编码实现)
-
- [5.1 DroughtLevelMapper.java](#5.1 DroughtLevelMapper.java)
- [5.2 DroughtLevelReducer.java](#5.2 DroughtLevelReducer.java)
- [5.3 DroughtLevelDriver.java](#5.3 DroughtLevelDriver.java)
- [6. 编译、打包、提交](#6. 编译、打包、提交)
- [7. 预期输出与验证](#7. 预期输出与验证)
-
- [7.1 控制台输出解读](#7.1 控制台输出解读)
- [7.2 输出数据格式](#7.2 输出数据格式)
- [7.3 Hive 加载验证](#7.3 Hive 加载验证)
- [8. 数据可视化](#8. 数据可视化)
-
- [8.1 结果数据集下载](#8.1 结果数据集下载)
- [8.2 可视化分析](#8.2 可视化分析)
- [9. 踩坑预案](#9. 踩坑预案)
- [10. 拓展:SPI 标准化降水指数------从百分位数到概率论标准化](#10. 拓展:SPI 标准化降水指数——从百分位数到概率论标准化)
-
- [10.1 SPI 是什么?](#10.1 SPI 是什么?)
- [10.2 为什么不能直接算"(值 - 均值)/ 标准差"?](#10.2 为什么不能直接算“(值 - 均值)/ 标准差”?)
- [10.3 Gamma 分布:为什么选它来拟合降水?](#10.3 Gamma 分布:为什么选它来拟合降水?)
- [10.4 完整的 SPI 计算流程](#10.4 完整的 SPI 计算流程)
- [10.5 百分位数方法 vs. 完整 SPI](#10.5 百分位数方法 vs. 完整 SPI)
- [10.6 SPI 的工程应用实例](#10.6 SPI 的工程应用实例)
- [10.7 为什么 A5 没做 SPI,留给 A11?](#10.7 为什么 A5 没做 SPI,留给 A11?)
- [11. 阶段总结](#11. 阶段总结)
目录
前言
本文是"农业气象干旱分析"项目的第五阶段,也是实践周第一个完整的 Java MapReduce 程序(包含 Mapper 和 Reducer)。A4 阶段实际上简化了处理数据的策略,隐藏了两个进阶方案:
- 进阶方案一:"基于降水百分位数的干旱等级划分"
- 进阶方案二:"简易 SPI 标准化降水指数"。
(1)A5 将进阶方案一从 SQL 片段落地为可运行的完整 MR 程序,标志着从 Hive SQL 分析向 Java 编程实现的能力跨越。
(2)而方案二(SPI)因需要拟合 Gamma 分布并做正态标准化,超出了单次 MR 作业的能力边界,本文将在末尾章节对其理论与应用进行详细展开,供大家预习,为后续实验(A11)奠定认知基础。
0. 背景知识:从绝对阈值到相对阈值
- A4 的局限:绝对阈值忽略气候差异
A4 阶段使用 precip < 0.5 mm 作为干旱阈值,结论是 96.25% 的站点无干旱。但这个阈值有一个隐含假设------0.5mm 对所有站点意义相同。
可现实并非如此:年均降水 200mm 的干旱地区,5mm 的日降水已经是"湿润日";而年均降水 2000mm 的湿润地区,5mm 可能仍是"干旱日"。由此可知:干旱是一个相对概念,需要基于各站点自身的气候基线来定义。 那么如何定义干旱才是更加科学合理的呢?
-
进阶方案一:基于降水百分位数的干旱等级划分
对每个站点做如下设定:计算其历史降水分布的百分位数,然后按气象干旱等级标准(GB/T 20481-2017)划分:
(1)特旱(≤10%)
(2)重旱(10%-20%)
(3)中旱(20%-30%)
(4)轻旱(30%-40%)
(5)无旱(>40%)
当下执行的 A5任务,会将这一思路实现为完整的 Java MapReduce 程序。
-
进阶方案二:简易 SPI 标准化降水指数
做如下设定:
(1)按月汇总降水量 → 计算各站点月度均值和标准差 → 将当月降水量减去均值后除以标准差,得到 SPI 近似值。
(2)且SPI 的完整实现需要拟合 Gamma 分布并做正态标准化,其理论与应用将在本文末尾的拓展章节中详细阐述,实现则留给后续实验(A11)。
1. 任务概述与目标
| 项目 | 说明 |
|---|---|
| 定位 | 实践周第一个完整 Java MR 程序(Mapper + Reducer),将 A4 的拓展提示落地为可运行代码 |
| 目标 | 1. 编写 Mapper 解析 CSV,以 station_id 为 Key 输出 2. 编写 Reducer 计算每个站点的降水百分位数阈值 3. 按 GB/T 20481-2017 标准判定每条记录的干旱等级 4. 输出带干旱等级标签的全量记录 5.尝试对输出数据做可视化 |
| 输入 | A2-2 结果,drought_cleaned(9,218,700 行,22 列 CSV) |
| 输出 | station_id \t record_date \t precip \t drought_level,以及对应可视化图 |
| 验证 | 统计各等级记录数占比,与理论预期对比 |
2. 干旱等级划分标准
| 干旱等级 | 降水百分位数范围 | 理论占比 |
|---|---|---|
| 特旱 | ≤ 10%(P10) | 10% |
| 重旱 | 10% ~ 20%(P20) | 10% |
| 中旱 | 20% ~ 30%(P30) | 10% |
| 轻旱 | 30% ~ 40%(P40) | 10% |
| 无旱 | > 40% | 60% |
【须知】:百分位数方法必然将每个站点 10% 的观测日划为"特旱",即使该站点水汽充沛。这与 A4 的绝对阈值(precip < 0.5mm)有本质区别:A4 回答"哪里降水绝对稀少",A5 回答"相对于自身历史,哪些时段降水异常偏少"。
3. MR 作业设计
在基本了解MR架构和运行逻辑的基础上,我们需要细心拆解需求,并精心设计每个环节。
3.1 整体架构
bash
Map 阶段 Shuffle Reduce 阶段
┌─────────────────┐ ┌──────────┐ ┌─────────────────────┐
CSV 行 ─────→ │ 解析 station_id │ ────────→ │ 按站点 │ ──→ │ 1. 收集全部 precip │
│ 输出 <id, 记录> │ │ 分组排序 │ │ 2. 排序, 计算分位数 │
└─────────────────┘ └──────────┘ │ 3. 遍历判定干旱等级 │
│ 4. 输出 <id, 等级> │
└─────────────────────┘判断只需要一个 Job 完成全部逻辑:每个站点仅 90 条记录,Reduce 端一次性收集排序即可,无需拆分为两个 Job。
3.2 Combiner 适用性分析
Combiner操作等同在Map-stage中做的一次小的reduce(规约),主要目的是减少进入shuffle环节的记录数量,以减轻作业压力。但需认识到:Combiner 仅适用于可交换可结合的聚合(COUNT、SUM、MIN、MAX 等),不适用于需要全量排序或全局状态的操作。
回到本任务中,可以判定其不适用 Combiner,分析原因如下:
- Reducer 需要全量排序后计算百分位数,不是可交换可结合的聚合。
- Combiner 在 Map 端预处理后,Reduce 端收到的仍是局部结果,无法正确计算分位数。
- 即使强行使用,不仅逻辑错误,还增加了序列化/反序列化的 I/O 开销。
3.3 内存估算
【注】输入数据集为A2-2 out目录,3.4节做解释。
| 项目 | 计算过程 | 结果 |
|---|---|---|
| 每个站点记录数 | 固定 | 90 条 |
| 每条记录内存 | date(10B) + precip(8B) + Text 对象开销(~40B) | ~60 字节 |
| 每个站点状态大小 | 90 × 60B | ~5.4 KB |
| Reducer 并行处理的站点 | 逐站处理,内存中仅保留当前站点 | 1 个 |
| Reducer 内存占用 | ~5.4 KB,远低于 256 MB 上限 | ✅ |
3.4 为何将 A2-2 的结果作为 A5 的输入?
- A2-2 做了什么:MapReduce 数据质量筛查与清洗,输出清洗后的 CSV 文件(22 列,无空值、无格式错误)。
- A5 为什么直接用 A2-2 的输出来计算:
(1)数据流的正确起点 :原始数据 /drought/output_a2_2 是整个项目的数据基座。A3 建 Hive 外部表指向它,A4 从 Hive 读它,A5 用 MR 直接读它。如果 A5 去读 A4 的物化表(如 dry_flag),不仅多了一次数据拷贝,而且丢失了列信息(A4 的物化表只保留 station_id、date、precip)。
(2)避免数据拷贝,节省 HDFS 空间 :在 2GB 内存、14GB(现已扩至 28GB)磁盘的受限集群上,每复制一次 1.29 GB 都是奢侈的。直接指向 A2-2 意味着零拷贝------Map 直接从 A2-2 的 HDFS 块读取,不经任何中间表。
(3)证明 A5 的 MR 程序有完整的 CSV 解析能力 :如果 A5 直接读 A4 的 dry_flag(三列,以 \t 分隔),Mapper 只需要简单 split("\t")。但读 A2-2 的原始 CSV(22 列,以 , 分隔),Mapper 必须正确解析列索引(cols0=station_id, cols1=date, cols5=precip)。这证明 A5 的 Mapper 具备处理原始输入格式的能力,而非依赖前序步骤的"预处理"。
(4)保持实验链条的独立性与可复现性:任何一个后续实验(A5-A15)都可以直接从 /drought/output_a2_2 启动,不需要依赖中间物化表的存在。这符合"数据清洗一次,后续多次分析"的数据仓库最佳实践。
4. 正确理解 MapReduce 中的 <K, V, P> 三元组
教材通常说 Map 输出 <K, V>,Reduce 接收 <K, Iterable<V>>。但这个模型无法解释一个关键问题:同一个 K 的多个 Map 输出,如何被路由到正确的 Reducer?
准确的数据模型应该是 <K, V, P> 三元组,其中:
| 元素 | 含义 | 谁决定的? |
|---|---|---|
| K | 键 | Mapper 的 context.write(k, v) |
| V | 值 | Mapper 的 context.write(k, v) |
| P | 分区编号 | Partitioner.getPartition(K, V, numReduceTasks) |
4.1 分区编号 P 在数据流中的角色
bash
Map 端:
context.write(station_id, record)
│
▼
P = Partitioner.getPartition(station_id, record, 3) // 0, 1, 或 2
│
▼
写入环形缓冲区,按 <P, K, V> 排序(先按 P 排,再按 K 排)
│
▼
溢写到磁盘:part-r-00000 ← P=0 的数据
part-r-00001 ← P=1 的数据
part-r-00002 ← P=2 的数据
Shuffle 阶段:
Reducer-0 拉取所有 Map 产生的 P=0 的分区文件
Reducer-1 拉取所有 Map 产生的 P=1 的分区文件
Reducer-2 拉取所有 Map 产生的 P=2 的分区文件4.2 默认分区器
在编写MR程序的Driver时,如果为指定自定义分区器(Partitioner),MR程序会默认使用哈希分区 HashPartitioner:
java
// org.apache.hadoop.mapreduce.lib.partition.HashPartitioner
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}在本次实验中:同一个 station_id 的 Hash 值模 3 后始终得到相同的 P,因此该站点的全部记录必然路由到同一个 Reducer。这就是为什么 Reducer 能拿到某个站点的"所有记录",一切皆不是魔法,是哈希分区保证的;这也是为何在前置课程DSA介绍Hash时,我们会耗费大量时间让大家理解Hash思想,而非单纯的某一种或者某一些实现。
【疑问】你也许会好奇:为什么教学上常被省略?
-
因为默认分区器按
K.hashCode() % N决定 P,P 完全由 K 决定,看起来像是"同一个 K 自动聚到一起"。但当引入自定义分区器 (如按年份分区、按地域分区)时,P 不再由 K 唯一决定,三元组<K, V, P>的独立性就显性化了。 -
【拓展】与后续实验中二次排序的关联。
如果后续实验中 Key 升级为复合键
(station_id, month),且要求按station_id分区、按station_id + month排序,就需要:(1)自定义 Partitioner :只基于
station_id计算 P(忽略 month)(2)自定义 GroupingComparator :只基于
station_id判断是否属于同一组此时
<K, V, P>三元组的 P 和 K 的排序键是不同的维度 :P 只看station_id,而 K 的排序看station_id + month;若仍用二元组思维,这一区别难以解释清楚。
5. MR程序原理与编码实现
【注】依旧是生成完整Maven工程,注意根据实际情况修改两个内容:
(1)编译打包的jar包名称(仅做参考,可自定义):
xml
<artifactId>drought-mr-a5</artifactId>(2)对应的main函数类也需要调整(仅做参考,可自定义,注意包名要以实际工程结构相符):
xml
<manifest>
<mainClass>com.lab.a5.DroughtLevelDriver</mainClass>
</manifest>(3)注意包名!!!
(4)MapReduce 键值对数据转化简图
- Map 端:
bash
[IN] <k1, v1> [OUT] <k2, v2>
↑ ↑
LongWritable, Text Text, Text
│ │
文件偏移量, 一行 CSV station_id, "date\tprecip"
│ │
例: <0, "station_x,2012-04-03,...,3.21,..."> → <station_x, "2012-04-03\t3.21">- Shuffle 阶段(隐式,框架自动完成):
bash
<k2, v2> 三元组 <k2, v2, P=HashPartitioner(k2, 3)>
│
├─→ P=0 的所有 k2/v2 ──→ Reducer-0
├─→ P=1 的所有 k2/v2 ──→ Reducer-1
└─→ P=2 的所有 k2/v2 ──→ Reducer-2- Reduce 端:
bash
[IN] <k3, List<v3>> [OUT] <k4, v4>
↑ ↑
Text, Iterable<Text> Text, Text
│ │
station_id, [全部 date\tprecip] station_id, "date\tprecip\tdrought_level"
│ │
例: <station_x, ["2012-04-03\t3.21", → <station_x, "2012-04-03\t3.21\t轻旱">
"2012-04-04\t8.45", ...]> <station_x, "2012-04-04\t8.45\t无旱">
...k3 = k2(同一个 station_id),由 Shuffle 阶段按 P 分区后聚合
v3 = 该站点全部记录的迭代器(Iterable<Text>),Hadoop 复用同一个 Text 对象以减少 GC
k4 = station_id(Text),与 k3 相同
v4 = "date\tprecip\tdrought_level"(Text),由 Reducer 拼接简图汇总:
bash
Map 输入 (k1,v1) Map 输出 (k2,v2) Reduce 输入 (k3,List<v3>) Reduce 输出 (k4,v4)
┌──────────────┐ ┌──────────────────────┐ ┌──────────────────────┐ ┌──────────────────────────────┐
│<偏移量,CSV行> │ ──→ │ <station_id, │ ──→ │ <station_id, │ ──→ │ <station_id, │
│ │ │ "date\tprecip"> │ │ ["date\tprecip", │ │ "date\tprecip\tdrought_lvl">│
└──────────────┘ └──────────────────────┘ │ "date\tprecip",...] │ └──────────────────────────────┘
└──────────────────────┘
20 个 Map 102,430 个分组 102,430 站 × 90 天
9.2M 行输入 3 个 Reducer 9.2M 行输出- Shuffle 阶段的排序与文件合并机制
MapReduce 的 Shuffle 阶段涉及多次排序和合并,理解这一机制是掌握 MR 性能调优的关键;但毕竟是实验项目,咱们仅做简单的说明;参考下图理解(官方流程解释)。
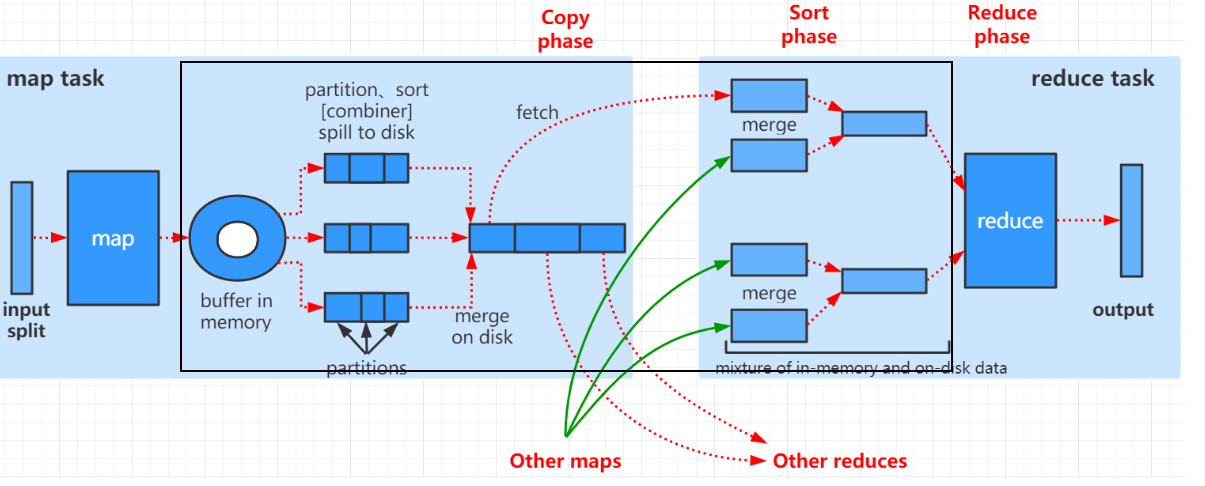
- Map 端
(1)内存缓冲 :Map 输出先写入环形缓冲区(默认 100 MB)
(2) 溢写排序 :缓冲区达到 80% 阈值时,后台线程开始溢写(Spill)到磁盘。溢写前按<P, K>复合键做快速排序 ------先按分区编号排序,再按键排序
(3)多次溢写合并 :Map 完成后,所有溢写文件通过多路归并排序合并为一个大文件,最终输出一个按分区号分割的有序文件 - Reduce 端
(1)Copy 阶段 :从各 Map 节点拉取属于自己的分区数据(由<K, V, P>中的 P 决定)
(2)内存缓冲 + 磁盘溢写 :拉取的数据先放内存,满了溢写到磁盘
(3)多路归并合并 :所有数据拉齐后,将内存和磁盘上的多个文件做多路归并排序 ,合并为一个有序流
(4)送入 Reduce :按 Key 分组,依次调用reduce()函数
5.1 DroughtLevelMapper.java
java
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* Mapper:解析 CSV 行,提取 station_id、record_date、precip。
* Key = station_id,Value = record_date + "\t" + precip
*/
public class DroughtLevelMapper extends Mapper<LongWritable, Text, Text, Text> {
// 对象复用:Mapper 的 map() 每行调用一次,复用 Key/Value 对象避免频繁创建
private final Text outKey = new Text();
private final Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] cols = line.split(",", -1);
// CSV 列索引(与 A3 建表时的字段顺序一致)
String stationId = cols[0]; // station_id
String recordDate = cols[1]; // record_date
String precipStr = cols[5]; // precip (PRECTOT)
// 跳过空值
if (precipStr == null || precipStr.isEmpty()) {
return;
}
outKey.set(stationId);
outValue.set(recordDate + "\t" + precipStr);
context.write(outKey, outValue);
// 注意:context.write() 后,框架立即序列化输出,
// 后续对 outKey/outValue 的覆写不会污染已输出的数据
}
}5.2 DroughtLevelReducer.java
java
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* Reducer:收集每个站点的全部降水记录,排序计算百分位数阈值,
* 然后遍历每条记录判定干旱等级并输出。
*/
public class DroughtLevelReducer extends Reducer<Text, Text, Text, Text> {
// 对象复用:避免在迭代中反复创建对象
private final Text outValue = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
List<Record> records = new ArrayList<>(90); // 预分配合适容量
List<Double> precipList = new ArrayList<>(90); // 仅用于排序计算分位数
// ==================== 第一遍迭代:收集全部记录 ====================
// 【重要】Hadoop 的 Iterable<Text> 迭代器复用同一个 Text 对象
// 每次 next() 返回的是同一个引用,只是内容被新值覆盖。
// 因此必须在循环内做深拷贝(new Text(value.toString()) 再解析),
// 否则 ArrayList 里存的全是同一个对象,最终所有记录的值都一样。
// 这种对象复用是 Hadoop 减少 GC 压力的核心优化------如果框架为每条
// 记录创建新对象,9.2M 行数据将产生巨量临时对象,频繁触发 GC。
for (Text value : values) {
String[] parts = value.toString().split("\t", -1);
if (parts.length < 2) continue;
String date = parts[0];
double precip = Double.parseDouble(parts[1]);
records.add(new Record(date, precip));
precipList.add(precip);
}
int n = precipList.size();
if (n == 0) return;
// ==================== 计算百分位数阈值 ====================
Collections.sort(precipList);
// 线性插值法计算百分位数
// P_k = 排序后第 (n-1)*k 个位置的值
double p10 = percentile(precipList, n, 0.10); // 特旱上限
double p20 = percentile(precipList, n, 0.20); // 重旱上限
double p30 = percentile(precipList, n, 0.30); // 中旱上限
double p40 = percentile(precipList, n, 0.40); // 轻旱上限
// ==================== 第二遍遍历:判定等级并输出 ====================
for (Record r : records) {
String level = classify(r.precip, p10, p20, p30, p40);
outValue.set(r.date + "\t" + r.precip + "\t" + level);
context.write(key, outValue);
}
}
/**
* 线性插值法计算第 k 百分位数
* @param sorted 已排序的数值列表
* @param n 列表大小
* @param k 百分位数(0.0 ~ 1.0)
* @return 第 k 百分位数值
*/
private double percentile(List<Double> sorted, int n, double k) {
double pos = (n - 1) * k;
int lower = (int) Math.floor(pos);
int upper = (int) Math.ceil(pos);
if (lower == upper) {
return sorted.get(lower);
}
double frac = pos - lower;
return sorted.get(lower) * (1 - frac) + sorted.get(upper) * frac;
}
/**
* 根据降水百分位数划分干旱等级
*/
private String classify(double precip, double p10, double p20,
double p30, double p40) {
if (precip <= p10) return "特旱";
if (precip <= p20) return "重旱";
if (precip <= p30) return "中旱";
if (precip <= p40) return "轻旱";
return "无旱";
}
/**
* 内部类:存储一条观测记录(日期 + 降水量)
*/
private static class Record {
final String date;
final double precip;
Record(String date, double precip) {
this.date = date;
this.precip = precip;
}
}
}5.3 DroughtLevelDriver.java
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* Driver:配置并提交 MapReduce 作业。
* 使用 ToolRunner 处理命令行参数,支持 -D 参数覆盖配置。
*/
public class DroughtLevelDriver extends ToolRunner implements Tool {
private Configuration conf;
@Override
public int run(String[] args) throws Exception {
if (args.length < 2) {
System.err.println("Usage: DroughtLevelDriver <input_path> <output_path>");
System.exit(1);
}
Job job = Job.getInstance(getConf(), "Drought Level Classification");
job.setJarByClass(DroughtLevelDriver.class);
// Mapper / Reducer
job.setMapperClass(DroughtLevelMapper.class);
job.setReducerClass(DroughtLevelReducer.class);
// 输出 Key/Value 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// Map 输出类型(与 Reducer 相同)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// Reducer 数量:3 个(与集群节点数匹配,均衡负载)
job.setNumReduceTasks(3);
// 输入输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean success = job.waitForCompletion(true);
return success ? 0 : 1;
}
@Override
public void setConf(Configuration conf) {
this.conf = conf;
}
@Override
public Configuration getConf() {
return this.conf;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new Configuration(), new DroughtLevelDriver(), args);
System.exit(exitCode);
}
}6. 编译、打包、提交
给出工程结构参考
打包方式参考A2-1操作,之后将目标jar包传送到master节点中,并执行如下命令(仅做参考)提交作业:
bash
hadoop jar drought-mr-a5-1.0.jar /drought/output_a2_2 /drought/output_a57. 预期输出与验证
7.1 控制台输出解读
之前A2-1和A2-2中,虽然我们编写了Map-Only的MR程序,但对控制台输出的理解是不足的,即便在A4中也做了一些分析(且还发现了很多细节,给大家提供了深入学习和研究的切入点),现对A5的MR程序运行过程的控制台输出日志做较为细致的解读,以下是实际输出结果:
bash
hadoop@master:~$ ls
data_org derby.log drought-mr-1.0.jar drought-mr-A21-1.0.jar drought-mr-a5-1.0.jar hadoop-3.3.6.tar.gz hive_metastore metastore_db new_keys.txt old_keys.txt test_set.csv
hadoop@master:~$ hadoop jar drought-mr-a5-1.0.jar /drought/output_a2_2 /drought/output_a5
2026-06-01 22:17:37,069 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at master/192.168.10.101:8032
2026-06-01 22:17:37,928 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1780323203060_0001
2026-06-01 22:17:39,818 INFO input.FileInputFormat: Total input files to process : 20
2026-06-01 22:17:40,472 INFO mapreduce.JobSubmitter: number of splits:20
2026-06-01 22:17:41,030 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1780323203060_0001
2026-06-01 22:17:41,031 INFO mapreduce.JobSubmitter: Executing with tokens: []
2026-06-01 22:17:41,659 INFO conf.Configuration: resource-types.xml not found
2026-06-01 22:17:41,660 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2026-06-01 22:17:42,297 INFO impl.YarnClientImpl: Submitted application application_1780323203060_0001
2026-06-01 22:17:42,365 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1780323203060_0001/
2026-06-01 22:17:42,366 INFO mapreduce.Job: Running job: job_1780323203060_0001
2026-06-01 22:17:55,641 INFO mapreduce.Job: Job job_1780323203060_0001 running in uber mode : false
2026-06-01 22:17:55,644 INFO mapreduce.Job: map 0% reduce 0%
2026-06-01 22:18:06,828 INFO mapreduce.Job: map 5% reduce 0%
2026-06-01 22:18:11,901 INFO mapreduce.Job: map 10% reduce 0%
2026-06-01 22:18:12,916 INFO mapreduce.Job: map 15% reduce 0%
2026-06-01 22:18:13,927 INFO mapreduce.Job: map 25% reduce 0%
2026-06-01 22:18:16,948 INFO mapreduce.Job: map 30% reduce 0%
2026-06-01 22:18:25,049 INFO mapreduce.Job: map 35% reduce 0%
2026-06-01 22:18:26,057 INFO mapreduce.Job: map 50% reduce 0%
2026-06-01 22:18:32,113 INFO mapreduce.Job: map 55% reduce 6%
2026-06-01 22:18:33,119 INFO mapreduce.Job: map 60% reduce 6%
2026-06-01 22:18:34,125 INFO mapreduce.Job: map 65% reduce 6%
2026-06-01 22:18:37,142 INFO mapreduce.Job: map 70% reduce 6%
2026-06-01 22:18:38,148 INFO mapreduce.Job: map 70% reduce 7%
2026-06-01 22:18:39,154 INFO mapreduce.Job: map 75% reduce 7%
2026-06-01 22:18:40,163 INFO mapreduce.Job: map 80% reduce 7%
2026-06-01 22:18:41,171 INFO mapreduce.Job: map 85% reduce 7%
2026-06-01 22:18:44,192 INFO mapreduce.Job: map 85% reduce 19%
2026-06-01 22:18:45,199 INFO mapreduce.Job: map 95% reduce 19%
2026-06-01 22:18:46,210 INFO mapreduce.Job: map 100% reduce 19%
2026-06-01 22:18:50,241 INFO mapreduce.Job: map 100% reduce 52%
2026-06-01 22:18:55,287 INFO mapreduce.Job: map 100% reduce 59%
2026-06-01 22:18:56,294 INFO mapreduce.Job: map 100% reduce 67%
2026-06-01 22:19:02,336 INFO mapreduce.Job: map 100% reduce 100%
2026-06-01 22:19:03,364 INFO mapreduce.Job: Job job_1780323203060_0001 completed successfully
2026-06-01 22:19:03,514 INFO mapreduce.Job: Counters: 55
File System Counters
FILE: Number of bytes read=356182072
FILE: Number of bytes written=718735790
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1291089260
HDFS: Number of bytes written=402275536
HDFS: Number of read operations=75
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=20
Launched reduce tasks=3
Other local map tasks=10
Data-local map tasks=10
Total time spent by all maps in occupied slots (ms)=333508
Total time spent by all reduces in occupied slots (ms)=163008
Total time spent by all map tasks (ms)=166754
Total time spent by all reduce tasks (ms)=81504
Total vcore-milliseconds taken by all map tasks=166754
Total vcore-milliseconds taken by all reduce tasks=81504
Total megabyte-milliseconds taken by all map tasks=85378048
Total megabyte-milliseconds taken by all reduce tasks=41730048
Map-Reduce Framework
Map input records=9218700
Map output records=9218700
Map output bytes=337744636
Map output materialized bytes=356182396
Input split bytes=2350
Combine input records=0
Combine output records=0
Reduce input groups=102430
Reduce shuffle bytes=356182396
Reduce input records=9218700
Reduce output records=9218700
Spilled Records=18437400
Shuffled Maps =60
Failed Shuffles=0
Merged Map outputs=60
GC time elapsed (ms)=5938
CPU time spent (ms)=99010
Physical memory (bytes) snapshot=6226972672
Virtual memory (bytes) snapshot=44322197504
Total committed heap usage (bytes)=4346347520
Peak Map Physical memory (bytes)=269930496
Peak Map Virtual memory (bytes)=1933348864
Peak Reduce Physical memory (bytes)=327933952
Peak Reduce Virtual memory (bytes)=1938952192
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1291086910
File Output Format Counters
Bytes Written=402275536上述log解读如下:
- 前期准备(日志:00:17:37 - 00:17:42)
bash
Connecting to ResourceManager at master/192.168.10.101:8032【解读】:YARN 客户端(你提交命令的这台机器,譬如master)向 YARN 的 ResourceManager(RM,资源管理器)发起连接。这是 MR 作业的"挂号"步骤,而 RM 是整个集群的资源大管家。
bash
Total input files to process : 20
number of splits:20【解读】:HDFS 输入目录下有 20 个文件(A2-2 清洗输出的 part-m-xxxxx),每个文件对应 1 个 Map 任务。因为 FileInputFormat 默认每个文件至少 1 个 Split。这意味着本次作业将启动 20 个 Map 任务来处理全部数据。
bash
Submitted application application_1780323203060_0001
Running job: job_1780323203060_0001【解读】:作业提交成功,获得了 YARN 分配的 Application ID,状态为"运行中"。
bash
Job job_1780323203060_0001 running in uber mode : false【解读】 :
uber mode 是 YARN 的优化:如果作业很小(少量 Map、少量数据),YARN 会让所有任务在同一个容器(Container)内串行执行,避免申请多个容器的开销。这里 false 意味着作业数据量较大(1.29 GB,20 个 Map),YARN 判断不宜使用 uber 模式,转而使用标准的分布式模式,即每个 Map/Reduce 独立申请容器运行。
- Map 阶段(日志:00:18:06 - 00:18:46)
bash
map 5% reduce 0%
map 10% reduce 0%
...
map 55% reduce 6% ← 慢启动!这不就是A4 实验中详述的慢启动机制(Slow Start)嘛。Map 跑到 55% 时,Reduce 已经有 6% 的进度了。这 6% 不是计算,而是 Reduce 的 Copy 阶段------在从已完成 Map 任务的分区文件中拉取属于自己的 <station_id, record> 数据。Copy 只是网络搬运,不涉及百分位数计算,可以与 Map 完全并行。
Map 端数据流:
bash
Split-0 ──→ Map Task ──→ 输出 <station_id, "date\tprecip">
Split-1 ──→ Map Task ──→ 输出 <station_id, "date\tprecip">
...
Split-19 ─→ Map Task ──→ 输出 <station_id, "date\tprecip">每个 Map 任务的内部流程:
(1)读取 Split 中的每行 CSV。
(2)DroughtLevelMapper.map() 解析出 station_id、record_date、precip。
(3)输出 <Text(station_id), Text("date\tprecip")>。
(4)HashPartitioner 根据 station_id.hashCode() % 3 将输出分区为 3 份(对应 3 个 Reducer)。
(5)Map 端对输出做 <P, K> 排序(先按分区号,再按站点 ID),溢写到磁盘。
(6)所有 Map 完成后,通过多路归并合并为一个大文件。
- Reduce 阶段(日志:00:18:50 - 00:19:02)
bash
map 100% reduce 19%
map 100% reduce 52%
map 100% reduce 59%
map 100% reduce 67%
map 100% reduce 100%Map 100% 后,Reduce 进度从 19% 跳升到 100%,这是典型的 Sort + Reduce 阶段。Copy 拉齐了全部数据后,Reducer 开始做:
(1)多路归并排序:将从 20 个 Map 拉来的 60 个分区文件(20 Map × 3 Reducer),合并为 1 个按 station_id 排序的数据流。
(2)分组:将同一 station_id 的所有记录聚合成 Iterable 。
(3)调用 reduce():依次处理每组(共 102,430 组)
i. 第一遍迭代:将 90 条 precip 值收集到 ArrayList 并排序。
ii. 计算 P10/P20/P30/P40 四个百分位数阈值。
iii. 第二遍遍历:逐条判定干旱等级并输出。
- Counters(计数器)深度解读
bash
Map input records=9218700 ← 总行数(9.2M),与 A3 COUNT(*) 一致
Map output records=9218700 ← Map 无过滤,每行都输出
Reduce input groups=102430 ← 站点总数,与 A4 station_drought_profile 行数一致
Reduce output records=9218700 ← 输出总行数,与输入一致验证通过:输入 9,218,700 行 → 输出 9,218,700 行,没有数据丢失;102,430 个分组,每个站点都被处理。
bash
Reduce shuffle bytes=356182396 ← 约 340 MB
Reduce input records=9218700 ← 9.2M 条,与 Map 输出一致
Spilled Records=18437400 ← 溢写约 18.4M 条(Map + Reduce 端合计)
Shuffled Maps =60 ← 3 Reducer × 20 Map = 60 个分区文件
Merged Map outputs=60 ← 同上,多路归并合并【关键观察】
(1)Map output bytes(约 338 MB)大于 HDFS 最终输出(约 402 MB),这是因为 Map 输出经过压缩和序列化,而最终输出是未压缩的文本。
(2)Spilled Records=18.4M 恰好是 9.2M × 2------Map 端溢写 9.2M + Reduce 端溢写 9.2M,说明数据刚好跨过了内存缓冲阈值,触发了磁盘溢写,但 14 GB 可用空间完全从容应对。
【内存评估】:单 Reducer 峰值物理内存仅 313 MB,低于容器的 384 MB 上限,没有触发任何 OOM 或 Container killed;与我们在 A3 中建立的"384 MB 容器 / 256 MB JVM 堆"内存模型再次得到验证。
7.2 输出数据格式
station_id record_date precip drought_level
-1000799230488340175 2012-04-03 3.21 轻旱
-1000799230488340175 2012-04-04 8.45 无旱
6812413573084174289 2014-03-15 0.12 特旱
...7.3 Hive 加载验证
sql
-- 创建外部表指向 A5 输出
CREATE EXTERNAL TABLE drought_levels_a5 (
station_id STRING,
record_date STRING,
precip DOUBLE,
drought_level STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION '/drought/output_a5';
-- 验证:各等级记录数占比(应与理论值 10%/10%/10%/10%/60% 接近)
SELECT
drought_level,
COUNT(*) AS cnt,
ROUND(COUNT(*) / 9218700.0 * 100, 2) AS pct
FROM drought_levels_a5
GROUP BY drought_level
ORDER BY
CASE drought_level
WHEN '特旱' THEN 1
WHEN '重旱' THEN 2
WHEN '中旱' THEN 3
WHEN '轻旱' THEN 4
WHEN '无旱' THEN 5
END;- 理论预期:
| 干旱等级 | 理论占比 | 实际预期偏差 |
|---|---|---|
| 特旱 | 10.00% | ±0.02% |
| 重旱 | 10.00% | ±0.02% |
| 中旱 | 10.00% | ±0.02% |
| 轻旱 | 10.00% | ±0.02% |
| 无旱 | 60.00% | ±0.02% |
-
偏差来源:每个站点仅 90 条记录,百分位数边界处可能有少量记录因相同降水值分配到同侧,导致微小偏差。这是样本量限制的正常现象,不影响结论的有效性。
-
与 A4 的交叉对比
| 方法 | 阈值逻辑 | 干旱站点/记录占比 |
|---|---|---|
| A4 绝对阈值 | precip < 0.5mm | 3.75% 站点有干旱日 |
| A5 百分位数 | 各站点最低 10% 降水 | ~10% 记录标记为特旱 |
- 两者不矛盾:A4 找"绝对稀少的降水",A5 找"相对于自身气候的异常偏少"。同一站点可能在 A4 中"无干旱"(因为降水绝对值不低),但在 A5 中被标记为"特旱"(因为相对于该站点自身历史,这段时间的降水确实异常偏少)。
8. 数据可视化
8.1 结果数据集下载
VM 可能没有图形界面,直接在里面做可视化比较困难;正确的流程是:HDFS → master 本地 → Windows 主机 → Python 可视化。
- step 1:将 HDFS 输出合并下载到 master 本地。
HDFS 上的 A5 输出是 3 个 part-r-0000x 文件。我们需要把它们合并成一个完整的文本文件,然后拉到本地。
bash
# 在 master 上执行
# 1. 合并三个 Reducer 输出为一个文件
hdfs dfs -getmerge /drought/output_a5/part-r-* /home/hadoop/a5_drought_output.txt
# 2. 查看行数确认完整性(应为 9,218,700)
wc -l /home/hadoop/a5_drought_output.txt
# 3. 查看前几行确认格式
head -5 /home/hadoop/a5_drought_output.txt【解释】:
(1)getmerge 是 HDFS 命令,将目录下所有匹配的文件按顺序拼接为一个本地文件。
(2)输出文件大小约 402 MB(与 Counters 中的 HDFS: Number of bytes written=402275536 一致)。
- step 2:下载A4中的物化结果。
在master上进入hive,执行如下命令:
sql
-- 设置参数(和之前一样)
SET hive.execution.engine=mr;
SET mapreduce.map.memory.mb=384;
SET mapreduce.map.java.opts=-Xmx256m;
SET mapreduce.reduce.memory.mb=384;
SET mapreduce.reduce.java.opts=-Xmx256m;
SET mapreduce.job.reduces=1;
-- 导出 station_drought_profile 表数据到本地
INSERT OVERWRITE LOCAL DIRECTORY '/home/hadoop/a4_export'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
SELECT * FROM station_drought_profile;完事 "quit;" 退出hive。这个命令会把全站点干旱画像表(102,430 行)导出到 /home/hadoop/a4_export/ 目录。因为输出目录只能有一个文件,可能会生成类似 000000_0 这样的文件名。为方便使用,可以将其重命名:
bash
# 查看导出的文件
ls /home/hadoop/a4_export/
# 合并为一个文件并重命名(如果只有一个文件,直接重命名即可)
cat /home/hadoop/a4_export/* > /home/hadoop/a4_drought_profile.txt- step 3:将文件从 master 传输到 Windows 主机,注意事项如下:
(1)从HDFS/Hive上下载文件后,可以使用ls命令查看当前操作的vm目录下是否已经真正完成下载。
(2)在shell软件中尝试下载该文件前,应该刷新页面,否则可能看不到该文件。
【注】上传和下载操作自己看UI页面,A2已经差不多熟悉了。
8.2 可视化分析
输出文件内容(行数)较多,加载过程比较费事,这里我们主要对几个重点指标做可视化,具体说明参考注释,且在可视化过程中,需要根据实际数据显示情况调整展示方案,但我的建议是不要犟,AI十分擅长这些操作。
- 完整程序:使用AI辅助完成,prompt时需要注意解耦、设定进程提示信息,留意公共资源加载过程是否超时等。
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import time
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
matplotlib.rcParams['axes.unicode_minus'] = False
# ====================================================================
# 公共变量区
# ====================================================================
LEVEL_ORDER = ['特旱', '重旱', '中旱', '轻旱', '无旱']
LEVEL_COLORS = ['#8B0000', '#CD5C5C', '#F4A460', '#FFD700', '#90EE90']
# ------ A5 数据加载 ------
print("=" * 60)
print("正在加载 A5 实验数据(约 9.2M 行,预计需要 30-60 秒)...")
t_load_start = time.time()
a5_cols = ['station_id', 'record_date', 'precip', 'drought_level']
df = pd.read_csv('a5_drought_output.txt', sep='\t', names=a5_cols,
dtype={'station_id': str})
print(f" → A5 原始数据读取完成(耗时 {time.time() - t_load_start:.1f} 秒)")
# 数据预处理
print("正在进行数据预处理(日期解析、衍生列计算)...")
t_prep_start = time.time()
df['record_date'] = pd.to_datetime(df['record_date'])
df['year'] = df['record_date'].dt.year
df['month'] = df['record_date'].dt.month
df['is_severe'] = df['drought_level'].isin(['特旱', '重旱'])
df['year_month'] = df['record_date'].dt.to_period('M')
print(f" → A5 数据预处理完成(耗时 {time.time() - t_prep_start:.1f} 秒)")
print(f" → A5 数据总加载时间:{time.time() - t_load_start:.1f} 秒")
print("=" * 60)
# ------ A4 数据加载 ------
print("=" * 60)
print("正在加载 A4 实验数据(全站点干旱画像表)...")
t_a4_start = time.time()
a4_cols = ['station_id', 'dry_event_count', 'max_dry_days', 'avg_dry_days', 'total_dry_days']
a4_df = pd.read_csv('a4_drought_profile.txt', sep='\t', names=a4_cols)
print(f" → A4 数据加载完成,{len(a4_df)} 行(耗时 {time.time() - t_a4_start:.1f} 秒)")
print("=" * 60)
# ====================================================================
# 图1:干旱等级分布验证 + Top 20 最干旱站点
# ====================================================================
def make_figure_1():
print("开始生成图1:干旱等级分布 + Top 20 最干旱站点...")
t0 = time.time()
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# --- 左侧:干旱等级分布 ---
level_counts = df['drought_level'].value_counts()
level_pct = (level_counts / len(df) * 100).reindex(LEVEL_ORDER)
axes[0].bar(LEVEL_ORDER, level_pct, color=LEVEL_COLORS, edgecolor='black')
axes[0].set_ylabel('占比 (%)')
axes[0].set_title('干旱等级分布(A5)')
for i, v in enumerate(level_pct):
axes[0].text(i, v + 0.3, f'{v:.1f}%', ha='center', fontsize=10, fontweight='bold')
axes[0].axhline(y=10, color='gray', linestyle='--', alpha=0.5, label='理论值 10%')
axes[0].axhline(y=60, color='gray', linestyle='--', alpha=0.5, label='理论值 60%')
axes[0].legend()
# --- 右侧:Top 20 最干旱站点 ---
station_severity = df[df['is_severe']].groupby('station_id').agg(
severe_avg_precip=('precip', 'mean')
).sort_values('severe_avg_precip', ascending=True).head(20)
axes[1].barh(range(20), station_severity['severe_avg_precip'],
color='firebrick', edgecolor='black')
axes[1].set_yticks(range(20))
axes[1].set_yticklabels(station_severity.index.str[:12], fontsize=8)
axes[1].set_xlabel('特旱+重旱期间平均降水量 (mm)')
axes[1].set_title('Top 20 最干旱站点(按严重干旱期平均降水量)')
axes[1].invert_yaxis()
plt.tight_layout()
plt.savefig('a5_drought_distribution.png', dpi=150, bbox_inches='tight')
plt.close()
elapsed = time.time() - t0
print(f" → 图1生成完成,已保存为 a5_drought_distribution.png(耗时 {elapsed:.1f} 秒)")
# ====================================================================
# 图2:年度堆叠柱状图 + 月度干旱强度热力图
# ====================================================================
def make_figure_2():
print("开始生成图2:年度堆叠柱状图 + 月度干旱强度热力图...")
t0 = time.time()
fig, axes = plt.subplots(2, 1, figsize=(14, 8))
# --- 上半:年度堆叠柱状图 ---
yearly_level = df.groupby(['year', 'drought_level']).size().unstack(fill_value=0)
yearly_level = yearly_level[LEVEL_ORDER]
axes[0].bar(yearly_level.index, yearly_level['无旱'], color='#90EE90', label='无旱')
axes[0].bar(yearly_level.index, yearly_level['轻旱'],
bottom=yearly_level['无旱'], color='#FFD700', label='轻旱')
bottom_mid = yearly_level['无旱'] + yearly_level['轻旱']
axes[0].bar(yearly_level.index, yearly_level['中旱'],
bottom=bottom_mid, color='#F4A460', label='中旱')
bottom_severe = bottom_mid + yearly_level['中旱']
axes[0].bar(yearly_level.index, yearly_level['重旱'],
bottom=bottom_severe, color='#CD5C5C', label='重旱')
bottom_extreme = bottom_severe + yearly_level['重旱']
axes[0].bar(yearly_level.index, yearly_level['特旱'],
bottom=bottom_extreme, color='#8B0000', label='特旱')
axes[0].set_ylabel('记录数')
axes[0].set_title('各年度干旱等级分布')
axes[0].legend(loc='upper right', ncol=5)
# --- 下半:月度严重干旱强度热力图 ---
monthly_severe_avg = df[df['is_severe']].groupby('year_month')['precip'].mean()
heat_data = monthly_severe_avg.reset_index()
heat_data.columns = ['year_month', 'severe_avg_precip']
heat_data['year'] = heat_data['year_month'].dt.year
heat_data['month'] = heat_data['year_month'].dt.month
pivot = heat_data.pivot(index='month', columns='year', values='severe_avg_precip')
im = axes[1].imshow(pivot, aspect='auto', cmap='YlOrRd_r',
vmin=0, vmax=pivot.max().max())
axes[1].set_xticks(range(len(pivot.columns)))
axes[1].set_xticklabels(pivot.columns, rotation=45)
axes[1].set_yticks(range(len(pivot.index)))
axes[1].set_yticklabels(pivot.index)
axes[1].set_xlabel('年份')
axes[1].set_ylabel('月份')
axes[1].set_title('月度严重干旱(特旱+重旱)平均降水量 (mm)')
plt.colorbar(im, ax=axes[1], label='平均降水量 (mm)')
plt.tight_layout()
plt.savefig('a5_temporal_drought.png', dpi=150, bbox_inches='tight')
plt.close()
elapsed = time.time() - t0
print(f" → 图2生成完成,已保存为 a5_temporal_drought.png(耗时 {elapsed:.1f} 秒)")
# ====================================================================
# 图3:A4 vs A5 双视角对比
# ====================================================================
def make_figure_3():
print("开始生成图3:A4 vs A5 双视角对比...")
t0 = time.time()
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# ------ A4 视角:对数尺度 ------
a4_dist = a4_df['max_dry_days'].value_counts().sort_index()
axes[0].bar(a4_dist.index[:15], a4_dist.values[:15],
color='steelblue', edgecolor='black')
axes[0].set_xlabel('最长连续干旱天数')
axes[0].set_ylabel('站点数(对数尺度)')
axes[0].set_title('A4:绝对阈值(precip < 0.5mm)')
axes[0].set_yscale('log')
max_val = a4_dist.get(0, 0)
max_pct = max_val / len(a4_df) * 100
axes[0].annotate(f'{max_val} 站点无干旱\n占比 {max_pct:.1f}%',
xy=(0, max_val), xytext=(6, max_val * 0.05),
arrowprops=dict(arrowstyle='->', color='red'),
fontsize=10, color='red')
# ------ A5 视角 ------
df['is_extreme'] = (df['drought_level'] == '特旱').astype(int)
station_extreme_pct = df.groupby('station_id')['is_extreme'].mean() * 100
axes[1].hist(station_extreme_pct, bins=40, color='firebrick',
edgecolor='black', alpha=0.8)
axes[1].axvline(x=10, color='gold', linestyle='--', linewidth=2, label='理论值 10%')
axes[1].set_xlabel('特旱记录占比 (%)')
axes[1].set_ylabel('站点数')
axes[1].set_title('A5:相对阈值(各站点百分位数)')
axes[1].legend()
plt.tight_layout()
plt.savefig('a4_vs_a5_comparison.png', dpi=150, bbox_inches='tight')
plt.close()
elapsed = time.time() - t0
print(f" → 图3生成完成,已保存为 a4_vs_a5_comparison.png(耗时 {elapsed:.1f} 秒)")
# ====================================================================
# 执行入口
# ====================================================================
if __name__ == '__main__':
print("\n" + "★" * 60)
print(" A5 干旱等级划分 - 可视化脚本开始运行")
print("★" * 60 + "\n")
# make_figure_1()
# make_figure_2()
make_figure_3()
print("\n" + "★" * 60)
print(" 全部图表生成完毕!")
print("★" * 60)- 最终效果(仅供参考)
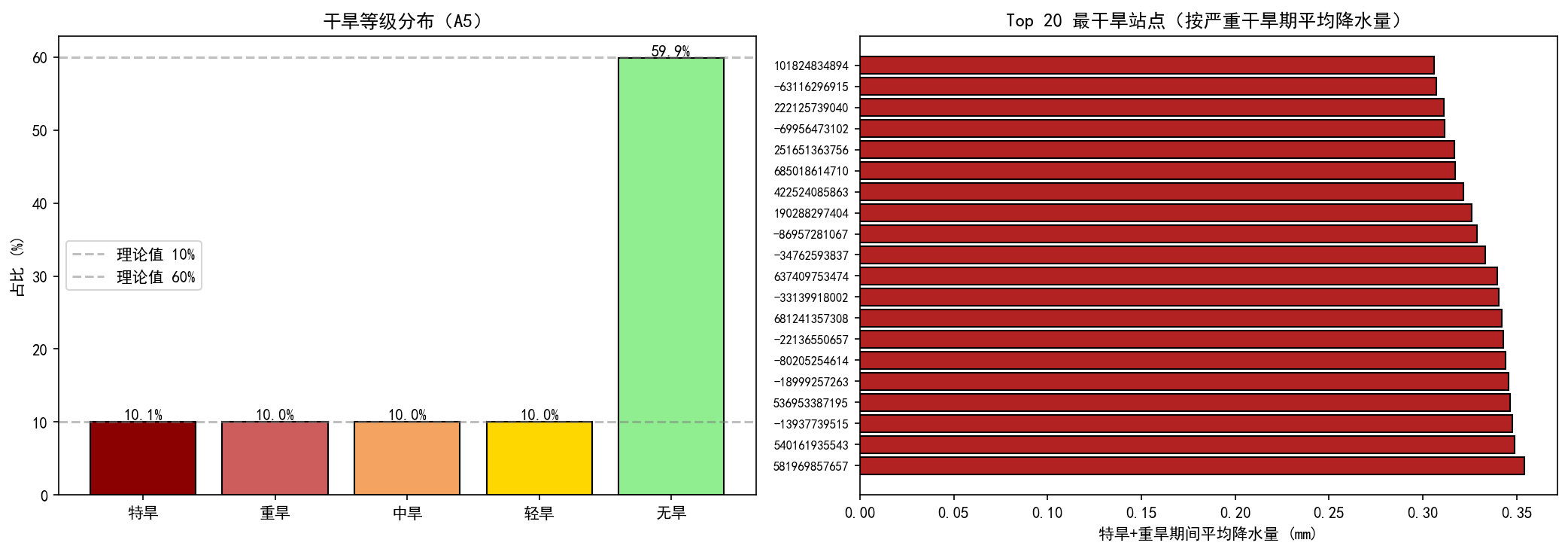
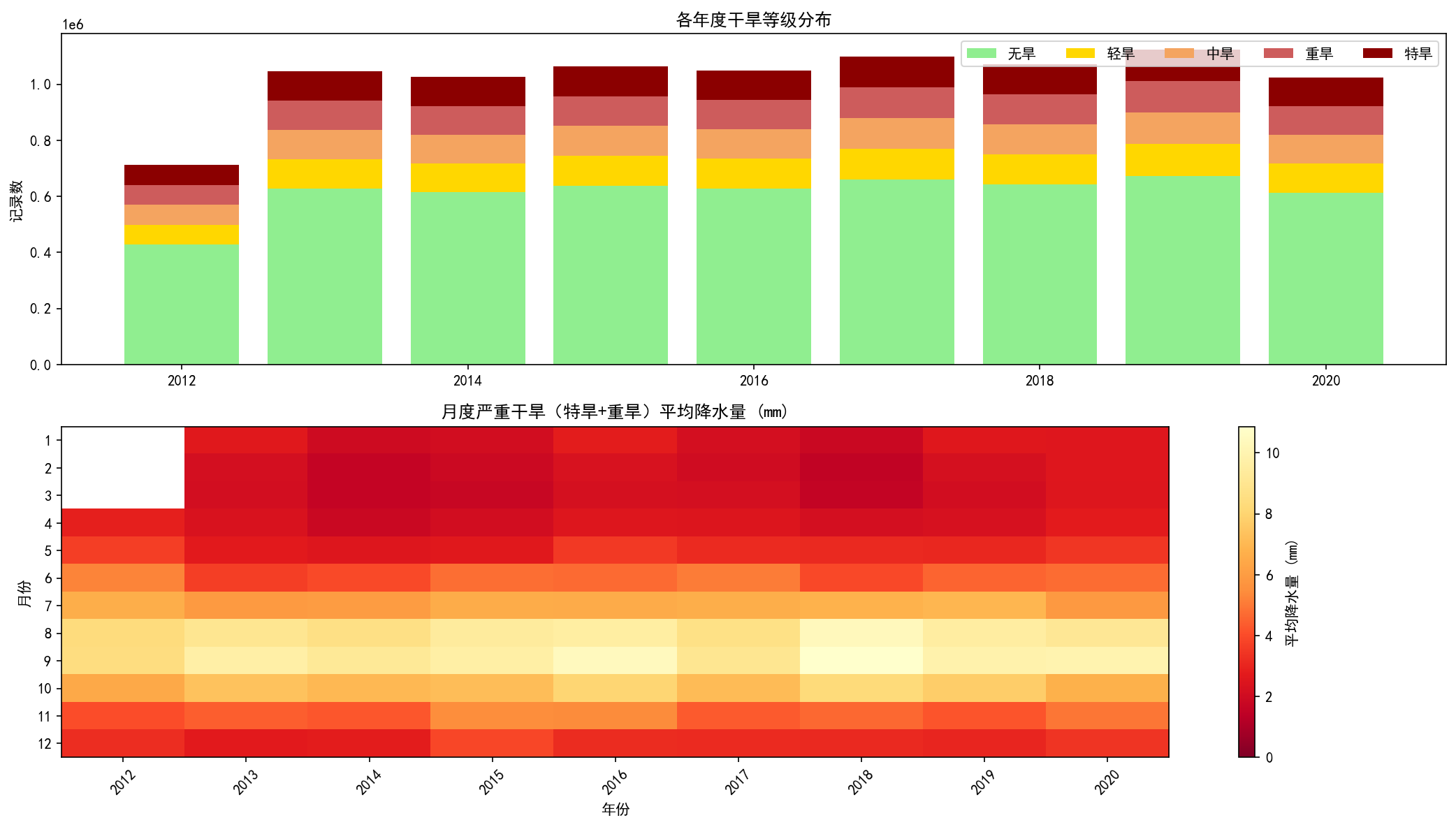
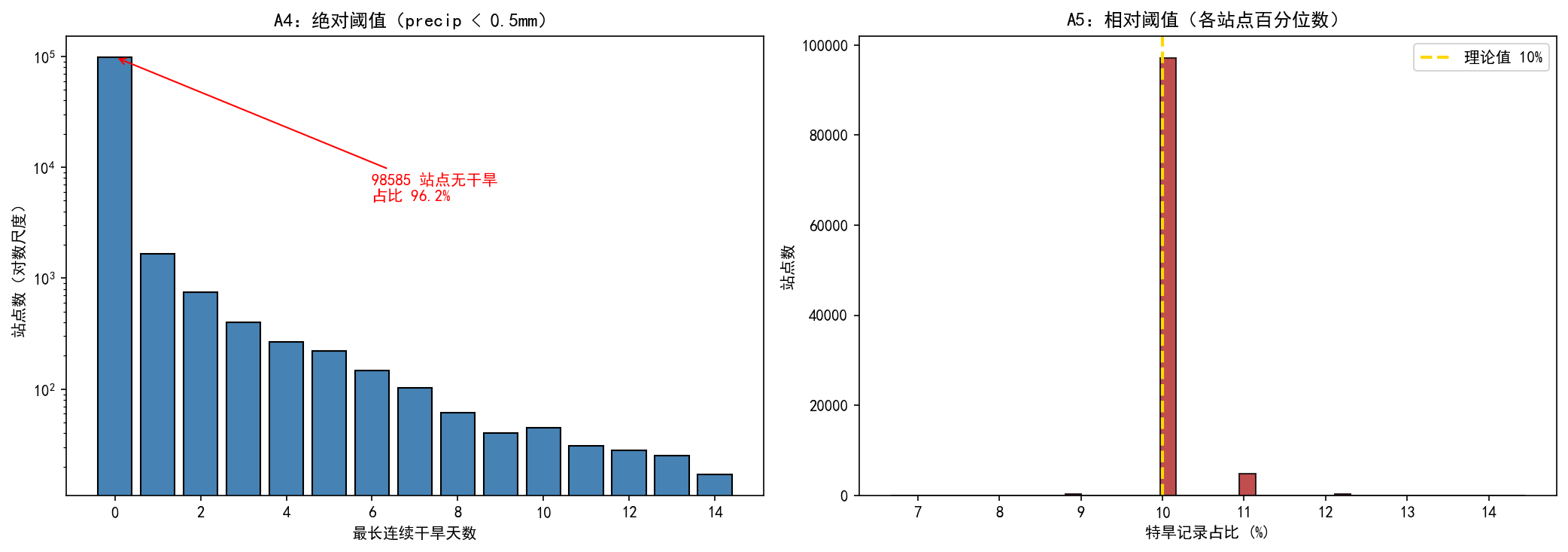
【追问】上述可视化图表表达的信息细节,你能正确解读吗?譬如:为何第三章图的左边要用对数轴?
【进阶可视化建议】当前的可视化效果不是很高级,可以尝试依靠AI完成下列表中的改进内容,这些图表可在 A6-A15 的各阶段中根据分析目标选用。
| 图表类型 | 适用场景 | Python 库 |
|---|---|---|
| Choropleth 地图 | 站点空间分布 + 干旱等级(若有经纬度) | geopandas + matplotlib |
| Ridgeline 山脊图 | 多个站点的降水分布曲线叠加 | seaborn / joypy |
| 动态时间序列 | SPI 随时间的演变(A11 后可用) | plotly / bokeh |
| 热力日历图 | 一整年逐日干旱等级矩阵 | calmap |
| 弦图 | 干旱等级转移概率(马尔可夫链) | holoviews |
9. 踩坑预案
| 序号 | 潜在问题 | 原因分析 | 预案 |
|---|---|---|---|
| 1 | ArrayList 里所有记录的 precip 值都一样 |
Hadoop 迭代器对象复用,没有在循环内做深拷贝 | records.add(new Record(date, precip)) 已做深拷贝;建议加一条验证日志,打印首个和最后一个记录的 precip 值,确认不同 |
| 2 | Reducer OOM | 某站点数据异常多(应 90 天,实际可能有几千行) | 虽然 A3 确认每个站点 90 行,但首次运行时加 records.size() 日志输出,超过 200 行就打印警告 |
| 3 | 输出文件数与 Reducer 数不一致 | 某些 Reducer 处理站点数过少 | 102,430 站点 / 3 Reducer ≈ 34,143 站点/Reducer,均匀分布,无倾斜风险 |
| 4 | 百分位数计算边界错误 | 整数索引取整导致阈值偏差 | 使用线性插值法 percentile(),避免整数索引取整误差 |
| 5 | ToolRunner vs implements Tool 写法错误 |
Hadoop 3.x 中 ToolRunner.run() 需要 Configuration 和 Tool 实例 |
Driver 中 implements Tool 并实现 setConf/getConf,main 中用 ToolRunner.run(new Configuration(), new DroughtLevelDriver(), args) |
| 6 | 编译时找不到 Hadoop 类 | CLASSPATH 未正确设置 | export HADOOP_CLASSPATH=$(hadoop classpath) 后再编译 |
| 7 | 输出目录已存在 | MR 作业不允许覆盖已有目录 | 提交前 hdfs dfs -rm -r /drought/output_a5 |
| 8 | Shuffle 阶段磁盘 I/O 高 | Reducer 需从多个 Map 拉取数据并归并排序 | 本次仅 1.29 GB 输入 + 14 GB 可用空间,完全安全。但可在教学中解释溢写文件的合并过程 |
| 9 | 迭代器对象复用导致数据错误 | 学生直接在 ArrayList.add(value) 而忘记 new Text(value.toString()) |
代码中已通过 value.toString().split() 做深拷贝,并在注释中解释原因 |
10. 拓展:SPI 标准化降水指数------从百分位数到概率论标准化
【注】这部分内容的解读,要求具备一定的统计学理论基础知识,或者已经学完/具备"数据挖掘"基本技能。
作为干旱分析领域最重要的标准化指标,SPI 的理论基础和应用价值值得深入阐述。此处将系统介绍 SPI 的原理、数学基础、工程应用,以及与 A5 百分位数方法的关系,为后续实验(A11 专项 SPI 实现)奠定认知基础。
10.1 SPI 是什么?
SPI(Standardized Precipitation Index,标准化降水指数)是世界气象组织推荐的气象干旱监测核心指标。其本质是:
将某时段(如 1 个月、3 个月、6 个月)的累积降水量,转换成一个标准正态分布的 Z 值,使得不同地点、不同时间尺度的干旱程度可以统一比较。
SPI 值是一个 Z-score,即标准正态分布下的偏离程度:
| SPI 值 | 含义 | 发生概率 |
|---|---|---|
| 0 | 降水等于历史中位数 | 50% |
| -1.0 | 偏少 1 个标准差 | ~16% |
| -1.5 | 中度干旱阈值 | ~7% |
| -2.0 | 偏少 2 个标准差,严重干旱 | ~2.3% |
| +1.0 | 偏多 1 个标准差 | ~16% |
对应的干旱等级(中国国标 GB/T 20481-2017):
| SPI 范围 | 干旱等级 |
|---|---|
| -0.5 < SPI | 无旱 |
| -1.0 < SPI ≤ -0.5 | 轻旱 |
| -1.5 < SPI ≤ -1.0 | 中旱 |
| -2.0 < SPI ≤ -1.5 | 重旱 |
| SPI ≤ -2.0 | 特旱 |
10.2 为什么不能直接算"(值 - 均值)/ 标准差"?
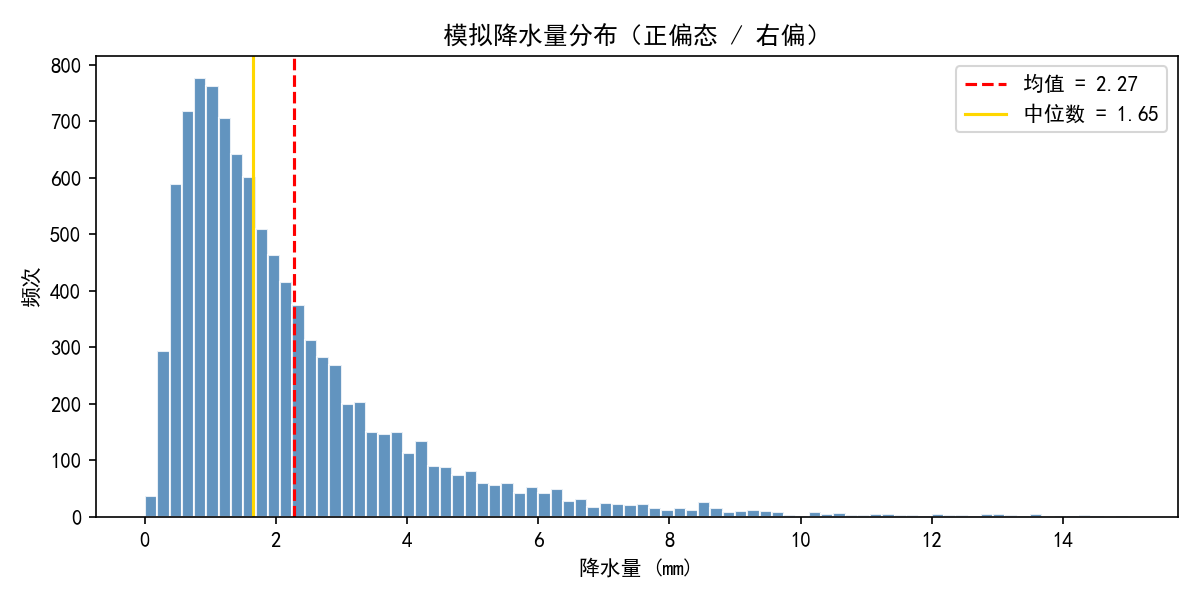
因为降水量不服从正态分布。
正态分布是对称的钟形曲线。但降水量分布是这样的,wiki链接 若不可用参考下图:
降水量的特点:
- 非负:不能小于 0
- 右偏:大量日子降水少(0-5mm),少数暴雨日降水极大(50mm+)
- 方差随均值变化:降水多的站点/月份,波动也大
直接算 (X - μ) / σ 的前提是 X 近似正态分布。降水量不满足这个前提,强行标准化会扭曲干旱评估------极端偏少的信号被压制,极端偏多的信号被放大。
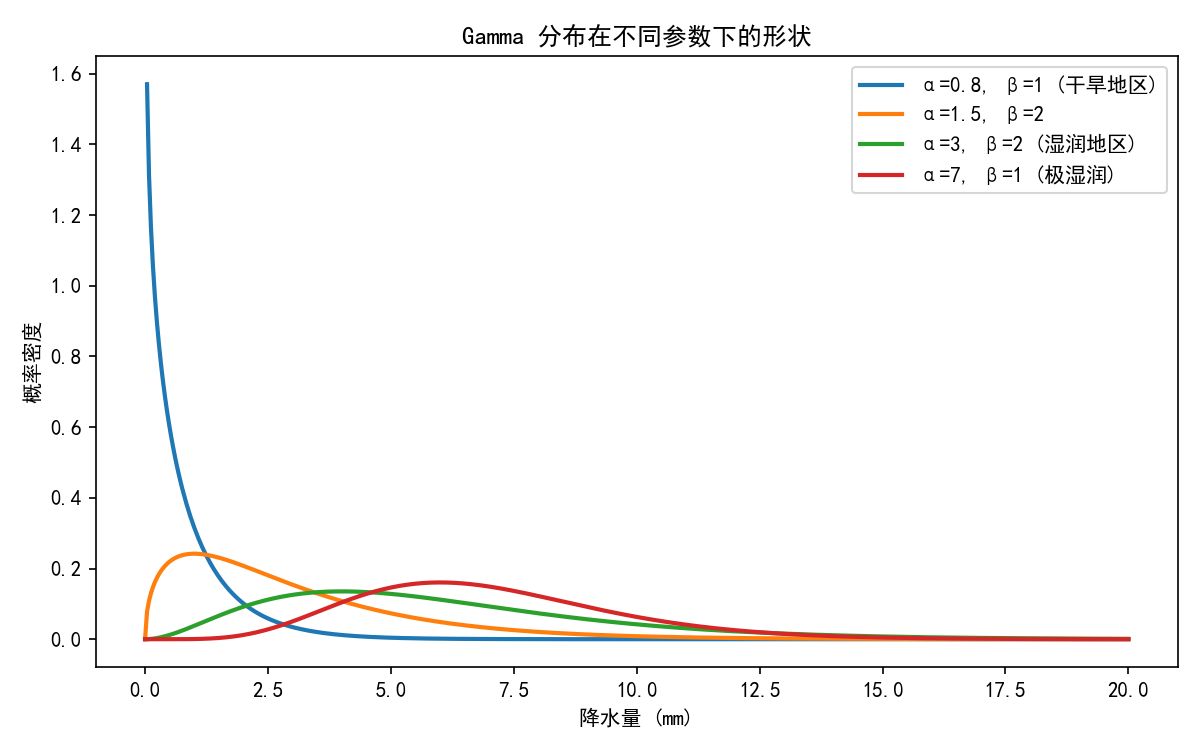
10.3 Gamma 分布:为什么选它来拟合降水?
Gamma 分布是一个定义在正实数域上、可以灵活调节形状的连续概率分布。它由两个参数控制:
| 参数 | 符号 | 含义 |
|---|---|---|
| 形状参数 | α(alpha) | 控制分布的形状------是单调递减(α<1)、指数形(α=1)、还是钟形(α>1) |
| 尺度参数 | β(beta) | 控制分布的"伸展"程度------β 越大,分布越宽 |
Gamma 分布的形状极其灵活,wiki链接 若不可用参考下图:
正是这种灵活性,使得 Gamma 分布能够很好地拟合各种形状的降水分布------从极为干旱的地区(α 很小,大部分日子无雨)到湿润地区(α 较大,分布接近钟形)。它是经过 30+ 年全球气象数据验证的标准选择(McKee et al., 1993)。
10.4 完整的 SPI 计算流程
SPI 的计算分为三步,每一步都有其数学和物理意义:
原始降水量序列(如历年 7 月降水:15, 22, 8, 31, 18, ...)
│
▼
[1] 拟合 Gamma 分布
- 用最大似然法从数据中估计 α 和 β
- 得到该站点/月份的降水概率分布模型
│
▼
[2] 计算累积概率
- 对于今年 7 月降水 = 8mm
- 计算在拟合的 Gamma 分布中,降水 ≤ 8mm 的概率
- 例如:CDF(8) = 0.07 → 7% 的年份降水 ≤ 8mm
│
▼
[3] 正态标准化(等概率变换)
- 在标准正态分布中,找到累积概率 = 0.07 对应的 Z 值
- Z = Φ^(-1)(0.07) ≈ -1.48
- 这个 Z 值就是 SPI
│
▼
SPI = -1.48 → 中旱第一步(拟合 Gamma 分布)的意义:降水数据本身不服从正态分布,我们需要一个能够描述降水真实分布的数学模型,Gamma 分布就是为这个目的服务的。
第二步(计算累积概率)的意义:把今年的降水量代入拟合好的 Gamma 分布,得到"降水不超过这个值的概率"。这个概率是一个统一的度量------不管原始数据是什么分布,概率永远在 0, 1 之间。
第三步(正态标准化)的意义:有了概率,就可以映射到标准正态分布上。标准正态分布有一个性质:给定概率,可以唯一对应一个 Z 值。这个 Z 值就是 SPI。因为标准正态分布的均值为 0、标准差为 1,所以 SPI = -1.48 的含义是"该值偏离均值 1.48 个标准差"。这一步将千差万别的降水分布统一映射到了一个公共的"干旱语言"上。
10.5 百分位数方法 vs. 完整 SPI
A5 的百分位数方法可以看作 SPI 的一阶近似,两者的对比如下:
| 维度 | A5 百分位数方法 | 完整 SPI |
|---|---|---|
| 数据建模 | 离散排序,取分位点 | 连续 Gamma 分布拟合 |
| 标准化 | 站点内部比较,不跨站点标准化 | 正态标准化,全局可比 |
| 极端值敏感度 | 低(离散排序丢失尾部信息) | 高(连续分布精确描述尾部) |
| 计算复杂度 | O(n log n) 排序 | 最大似然估计 + 数值积分 |
| 适用场景 | 教学演示、快速筛查 | 业务监测、保险精算、跨国比较 |
SPI 的第三步------正态标准化------是其方法论的核心。它使得一个干旱地区站点(年降水 50mm)和一个湿润地区站点(年降水 3000mm)在 SPI = -2.0 时,都可以被解读为"仅 2.3% 概率发生的极端干旱"。
10.6 SPI 的工程应用实例
-
美国干旱监测系统(U.S. Drought Monitor):USDM 每周发布的全美干旱地图,融合了多种时间尺度的 SPI(1/3/6/12/24 个月)。USDM 的地图被美国农业部用于决定灾害援助资金的发放------某县若被标记为"D2(严重干旱)"连续 8 周,该县农户即自动获得联邦农作物保险的低息贷款资格。SPI 在这里从统计指标变成了真金白银的决策依据。
-
FAO 全球粮食安全预警系统(GIEWS):联合国粮农组织定期计算全球农业区的 SPI(主要用 3 个月和 6 个月尺度)。3 个月 SPI 对土壤湿度敏感------反映作物根系层的水分状况;6 个月 SPI 对径流和水库蓄水敏感------反映灌溉水源的丰枯。2015-2016 年厄尔尼诺事件期间,GIEWS 通过 SPI 在埃塞俄比亚、索马里等国提前 3 个月发现了严重干旱信号,协调了早期粮食援助。
-
中国气象局干旱监测业务:国家气候中心每日接收全国 2400+ 个国家级气象站的实时降水数据,滚动计算各站不同时间尺度的 SPI,生成全国干旱分布图。2010 年西南大旱、2014 年华北夏旱期间,SPI 监测产品在旱情初现时就捕捉到了 -2.0 以下的极端信号。
-
南非开普敦"零日"干旱:2015-2018 年,开普敦遭遇有记录以来最严重干旱,24 个月 SPI 在 2017 年初已跌至 -2.5 以下(概率约 0.6%,相当于 160 年一遇)。事后分析表明,若当时使用了 SPI 长期监测,可以提前 1-2 年启动节水措施。此事件后,南非水利部将 SPI 纳入了国家干旱监测框架。
-
世界银行天气指数保险:在肯尼亚、埃塞俄比亚等国试点的指数保险产品中,3 个月 SPI 是触发赔付的核心指标。合同约定:若作物生长季的 SPI 低于 -1.5,所有投保农户自动获得赔付,无需现场查勘。SPI 的数学定义消除了理赔争议,且数据来源公开透明,解决了发展中国家农业保险"理赔难、成本高"的痛点。
10.7 为什么 A5 没做 SPI,留给 A11?
完整的 SPI 需要在 Reduce 端对每个站点/月份组合:
- 用最大似然法估计 Gamma 分布的 α 和 β 参数:这是一个迭代优化过程,涉及对数 Gamma 函数的求导。
- 计算累积概率:需要数值积分或查不完全 Gamma 函数表。
- 做正态分位数变换:需要逆正态累积分布函数。
这些数学运算在 Java 中可以实现(使用 Apache Commons Math 等库),但:
- 代码复杂度极高:需要引入第三方数学库并打包到 jar 中。
- 计算量大:每个站点都要做迭代拟合,102,430 个站点 × 多次迭代 = 不可忽视的开销。
- 教学节奏考虑:A5 的核心任务是"第一个完整 MR 程序",应聚焦于 MR 编程模型本身。
因此 A5 采用百分位数方法作为教学级的实现,完整的 SPI 留给 A11。相信大家那时候已熟悉 MR 编程范式,可以集中精力解决"如何在 MR 中实现 Gamma 拟合和正态标准化"这一高阶工程问题。
11. 阶段总结
-
从 SQL 到 Java 的能力跨越:A5 是实践周第一个完整的 MapReduce 程序(A2-1 只有 Map 无 Reduce),学生首次亲手实现 Mapper → Partitioner → Shuffle → Reducer 全流程。代码从 Hive SQL 的"描述式分析"转变为 Java MR 的"过程式实现",对分布式计算的理解进入了更深的层次。
-
干旱定义的深化:从 A4 的绝对阈值(precip < 0.5mm)进阶到 A5 的相对阈值(各站点降水百分位数),揭示了干旱是一个相对概念。百分位数方法确保每个站点 10% 的观测日被标为特旱,与 A4 的"96% 站点无干旱"形成互补视角。
-
<K, V, P>三元组认知:修正了教材中常见的"键值对"简化表述,明确了分区编号 P 在 Map 端排序、Shuffle 路由中的核心作用,为后续自定义分区器和二次排序打下理论基础。 -
对象复用与内存优化 :通过代码注释和讲解,说明了 Hadoop 迭代器对象复用的原理和必要性------减少 GC 压力,提升吞吐。同时强调了深拷贝的重要性------不复制的后果是
ArrayList里全是同一个对象的最后一条值。 -
Combiner 适用性判断:明确了 Combiner 仅适用于可交换可结合的聚合操作,不适合需要全量排序的场景。这一判断能力是 MR 性能优化的基本功。
-
Shuffle 机制全景:从 Map 端环形缓冲区 → 溢写排序 → 多路归并,到 Reduce 端 Copy → 溢写 → 归并 → 分组,完整覆盖了 Shuffle 阶段的数据流动路径,为性能调优提供了理论支撑。
-
SPI 理论铺垫:深入介绍了 SPI 的原理、Gamma 分布的数学基础、正态标准化的必要性,以及全球经典工程实例。百分位数方法是 SPI 的一阶近似,完整 SPI 的实现(Gamma 拟合 + 正态标准化)留待 A11 攻关。这种"先建立理论认知,再动手实现"的节奏,符合从入门到进阶的学习规律。
下一步:A6 可在本阶段输出的干旱等级标签基础上,进行干旱等级的时间序列分析、站点空间分布统计,或实现 SPI 的简易版本(Map 端按月汇总 + Reduce 端计算均值/标准差/标准化)。磁盘和内存瓶颈已在 A4 中根治,后续 MR 作业可放心使用标准资源配置。