AI 生成视频的能力在过去一年进步飞快。豆包、即梦、可灵这些工具已经可以让一个不会画画的人生成一段角色动画。
但视频生成只是前半程。后半程的问题是:生成出来的视频,普通人要如何应用?除了短剧和解说漫,它能不能变成游戏引擎能用的精灵图?能不能变成发到社交平台的透明 GIF?能不能做成游戏 MOD?这些是和普通大众日常息息相关的。
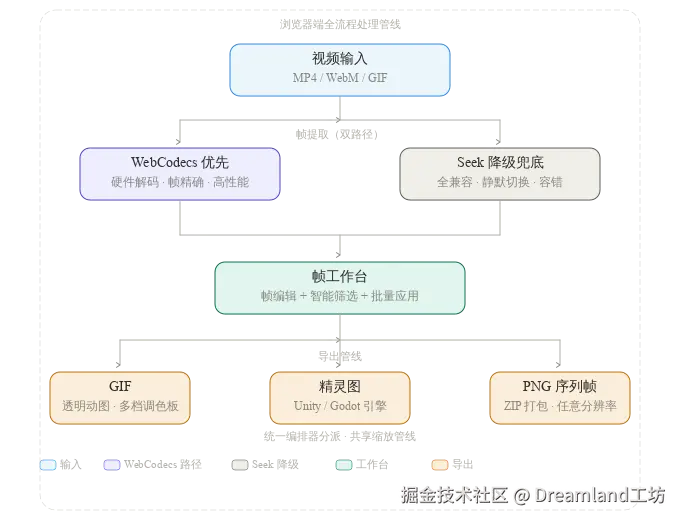
FramePacker 是我们在做的一个浏览器端工具,目标是打通从视频到可用资产的最后一公里。它在一个网页里实现了视频抽帧、抠图、编辑精修、批量改图、智能帧检测和自由分辨率导出。拖入视频、GIF 或者一批图片,在浏览器里完成所有处理,导出为你需要的格式。
本文从工程角度,聚焦这套工具链的管线层:视频帧提取和导出,分享一下我们踩过的坑及最终的方案决策。阅读本文不需要图像处理背景,但需要了解 Canvas API 基础。编辑能力的实现(画笔、橡皮擦、换色工具等)涉及独立的技术主题,后续会单独写文章展开。
 (FramePacker全流程演示)
(FramePacker全流程演示)
 (成品GIF展示)
(成品GIF展示)
核心问题拆解
从视频到序列帧,需要解决三个独立的子问题:
| 子问题 | 难点 | 对应章节 |
|---|---|---|
| 精准抽取目标帧 | 浏览器端没有命令行工具,视频解码 API 兼容性参差 | 视频帧提取 |
| 多种导出格式如何统一 | GIF、精灵图、ZIP 各有完全不同的编码约束 | 导出管线 |
| 浏览器端全流程的架构取舍 | 隐私 vs 性能、预览 vs 应用------这些决策影响整个管线 | 架构权衡 |
视频帧提取:双路径策略
浏览器端抽帧的核心约束是没有命令行工具,只能用 Web API。这里我们设计了一个双路径架构:WebCodecs 优先,video.currentTime seek 降级兜底。
入口设计:为什么需要双路径
WebCodecs 的 VideoDecoder 能实现帧精确解码,走 GPU 硬件管线,性能远超软件方案。但浏览器覆盖率不到 100%。Firefox 和旧版 Safari 不支持,即使在 Chromium 系浏览器中,也并非所有编码格式都能解。
Seek 路径依赖 <video> 元素的 currentTime 跳转 + seeked 事件回调,兼容性极好,几乎覆盖所有现代浏览器。代价是精度受关键帧间隔限制,落点只能到最近的关键帧,抽帧串行且耗时与帧数成正比。
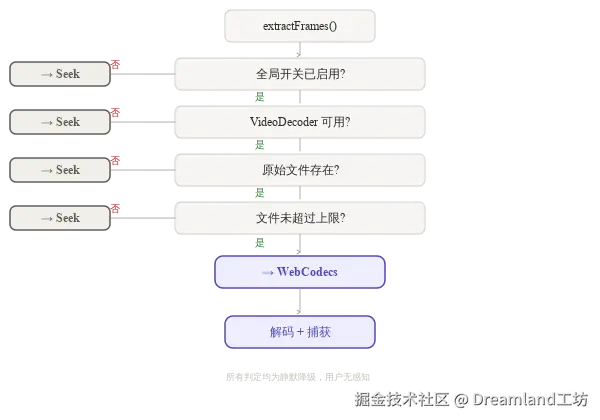
两条路径互补,缺一不可。统一入口 extractFrames() 不向上游暴露内部走的是哪条路径。detectExtractorPath() 做多层降级检测:
javascript
async function detectExtractorPath(source) {
if (!enableWebCodecs) return 'seek' // 全局开关关了
if (typeof VideoDecoder === 'undefined') return 'seek' // 浏览器不支持
if (!source.file) return 'seek' // 没有原始文件
if (source.file.size > MAX_FILE_SIZE) return 'seek' // 文件太大,demux 会 OOM
return 'webcodecs'
}任何一层不通过,静默切换到 seek 路径,用户无感知。
WebCodecs 路径:三个踩坑实录
解复用(Demux)与解码分离
视频文件不能直接丢给 VideoDecoder。MP4、WebM 这些是容器格式,视频里面除了编码数据,还有音频、字幕、元信息等。需要先把容器拆开,取出纯净的编码帧(H.264/H.265 裸数据)和 codec 配置。这一步叫解复用(demux),我们使用 mp4box.js(一个 JS 实现的 MP4 容器解析库)来完成。
第一个坑出现在 onSample 回调里:mp4box 解析完每一帧后,通过这个回调把数据交给我们。mp4box 0.5.x 在回调返回后可能复用底层 ArrayBuffer。如果我们直接把 sample.data 引用存下来、后续异步丢给 VideoDecoder 解码,那么下一个 sample 到来时底层内存已经被覆盖了,decode 出来就是花屏。而且不是每帧都花,取决于异步时序,难复现难排查。
定位过程:先怀疑是 codec 配置不对,换了几个参数都没用。然后怀疑是时间戳映射出问题,打了全量 PTS 日志也没规律。最后逐帧对比 WebCodecs 输出和 seek 路径输出,发现花屏帧的像素值和相邻帧高度相关,这才指向数据竞争。
修复很简单:每个 sample 的 data 做独立拷贝。
javascript
function onSample(sample) {
// mp4box 0.5.x 回调返回后底层 ArrayBuffer 可能被复用,必须拷贝
const dataCopy = new Uint8Array(sample.data).slice()
samples.push({ ...sample, data: dataCopy })
}PTS 时间轴对齐
视频容器的 PTS(Presentation Time Stamp,显示时间戳)时间轴不一定从 0 开始。录屏或剪辑过的视频,首帧时间戳可能是 1024、3000 甚至更大。而用户在 UI 上选择的时间片段是从 0 开始的(「从第 2 秒截到第 4 秒」)。
如果直接把用户选的时间当成 PTS 去匹配解码帧,结果就是用户选了 2 秒到 4 秒的片段,实际拿到的却是 0 秒到 2 秒的帧,因为skip 逻辑把正确帧全跳过了。
对齐算法:先从 mp4box 解析结果中探测容器时间轴的起始偏移,把用户的时间片段统一加上这个偏移再映射到 PTS。mp4box 给的 cts 是 composition timestamp(合成时间戳),单位是容器定义的 timescale(时间刻度,如 90000 表示一秒分成 90000 个单位)。换算到微秒的公式是:cts * 1e6 / timescale。
javascript
// 首帧 PTS 不一定从 0 开始,要先算偏移
const videoStartPTS = Math.round(
samples[0].cts * 1e6 / track.timescale
)
const offset = videoStartPTS || 0
const interval = 1e6 / fps
for (let t = startSec * 1e6, i = 0; t < endSec * 1e6; t += interval, i++) {
targets.push({ time: t + offset, index: i })
}
// output 回调里按时间戳匹配
function onOutput(videoFrame) {
const target = targets[currentTargetIdx]
if (videoFrame.timestamp >= target.time) {
captureFrame(videoFrame, target.index)
currentTargetIdx++
}
videoFrame.close()
}首帧附近可能有异常 PTS(如 0 或负值),通过 clamp 到 videoStartPTS 处理。
串行捕获与背压
WebCodecs 帧产出极快(GPU 硬件解码),远远快过 Canvas toBlob 的 PNG 编码速度。不进背压的话,decodeQueueSize 会持续膨胀。因为浏览器是缓存 VideoFrame GPU 纹理引用,不是 JS 内存,decodeQueueSize 大到一定程度直接 OOM。
简单的背压处理:队列长度到阈值就 await 一下。
javascript
const MAX_PENDING = 8
// 简单背压:队列太长就等一下
while (decoder.decodeQueueSize >= MAX_PENDING && !cancelled) {
await new Promise(r => setTimeout(r, 0))
}
decoder.decode(chunk)下游 captureFrame 必须串行,并行 toBlob 的多个 PNG 编码缓冲区会把移动端 GPU 内存打满。这个教训来自 seek 路径的并行尝试(下面讲),WebCodecs 路径一开始就走了串行。
这里可能会有个疑惑,为什么有了背压处理,还要在文件过大的时候降级到seek?因为这两者解决的是不同阶段的问题:背压控制解码→编码流水线的速度差;文件大小限制挡在更上游,即mp4box.js 做 demux 需要把整个文件加载到 JS 堆,大文件在这一步就会 OOM,背压还没机会介入。而Seek 路径的 <video> 元素是内核 streaming 读取,不受此限制。
Seek 降级路径的实战解剖
Seek 路径实现简洁:循环 video.currentTime = t → await seeked → drawImage → toBlob,帧间隔 = 1/FPS。但实际跑起来的耗时结构比表面复杂得多。
单帧操作里,seeked 事件的等待占绝对大头 。浏览器需要从最近关键帧逐帧解码到目标位置,这个延迟在 30ms 到 200ms 之间波动,完全取决于关键帧间隔。相比之下,drawImage 只有几毫秒,toBlob 的 PNG 编码在 40 到 200ms。
这意味着 seek 路径的瓶颈不是像素操作,而是浏览器内核的解码等待,从 JS 侧无法优化这个问题。
我们试过把 seek、drawImage、toBlob 拆成流水线:在一帧等 toBlob 的时候提前 seek 下一帧。用 toBlob 的回调作为流水线的下一级触发器。
javascript
// 这个方案最后没用,但思路记录一下
function pipelinedSeek(frameTimes) {
let idx = 0
video.currentTime = frameTimes[0]
video.addEventListener('seeked', function onSeeked() {
if (idx >= frameTimes.length) return
drawImage(ctx, video)
canvas.toBlob(blob => {
frames[idx] = blob
idx++
if (idx < frameTimes.length) {
video.currentTime = frameTimes[idx] // toBlob 完成后再 seek
}
})
})
}结果:桌面端提升不到 1%。瓶颈始终在 seeked 等待上,toBlob 的并行窗口完全被淹没。移动端更惨:3 个并发的 toBlob PNG 编码缓冲区同时占用 GPU 内存,跑 20 帧直接 OOM 崩溃。DevTools Memory 面板显示 GPU 内存用量呈阶梯上涨,每步恰好对应一个新 toBlob 启动。
这个方案最终全面回退。结论:seek 路径的并行化在天花板(seeked 延迟)和地板(GPU 内存)两个方向都被夹死了。要突破,必须跳过 seek 等待本身,也就是走 WebCodecs 路径。
为什么没选 ffmpeg.wasm
ffmpeg.wasm 是浏览器端视频解码的常被提及方案。评估后没选,核心原因不在性能,在架构层面。
硬件 vs 软件解码的结构性差距。 WebCodecs 走 GPU 硬件解码管线:macOS 走 VideoToolbox,Windows 走 DXVA,Android 走 MediaCodec。解码产物 VideoFrame 是 GPU 纹理引用,直接供给 Canvas,中间零拷贝。ffmpeg.wasm 走 WASM CPU 软件解码,每帧需要 WASM → JS → ImageData → Canvas 三次跨边界拷贝,这是结构性的差距,不是优化能补的。
包体积。 WebCodecs 零字节,浏览器内置。ffmpeg.wasm 核心 WASM 二进制文件超过 60MB(@ffmpeg/core@0.12.6 解包约 64.5MB)。每次启动需要从 CDN 拉取或从 CacheStorage 恢复,对用户体验是实打实的负担。
更关键的理由:WebCodecs 与 seek 降级共享基础设施。 无论选 WebCodecs 还是 ffmpeg.wasm 做主力路径,seek 降级都必须保留,因为它是兼容性兜底。如果选 WebCodecs,两条路径天然共享同一套 <video> 元素、Canvas 上下文、缩略图生成和帧缓存管理。选 ffmpeg.wasm 等于从零搭建另一套:Worker 线程协调、SharedArrayBuffer 跨域头配置、WASM 内存生命周期,每条都是独立工程线,和 seek 降级路径零复用。
决策矩阵:
| 维度 | WebCodecs | seek 降级 | ffmpeg.wasm |
|---|---|---|---|
| 帧精确 | ✅ 逐帧精准 | ❌ 关键帧粒度 | ✅ |
| 解码速度 | GPU 硬件管线 | 内核解码等待 | WASM CPU 软件解码 |
| 包体积 | 0 | 0 | 60MB+ |
| 兼容性 | Chromium 系为主 | 近乎全平台 | 需 SharedArrayBuffer |
| 工程复杂度 | 与 seek 共享基础设施 | 低 | 独立 Worker/WASM 环境 |
| 与降级路径集成 | ✅ 天然共享 | --- | ❌ 零复用 |
结论:不是 ffmpeg.wasm 不好。是在这个场景下,WebCodecs 作为主力路径、seek 做降级兜底,两条路径共享一套基础设施,比引入另一套独立工程线简洁得多。
导出管线:帧序列的三种归宿
导出是用户看到的最终结果。视频抽帧之后,帧序列需要变成透明 GIF、拼成精灵图、或打包为 PNG 序列帧。
GIF 的核心约束
GIF 格式有几个硬约束:最多 256 色、不支持半透明通道:每像素只能是全透明或全不透明。从 RGBA 帧到 GIF,必须解决色彩量化和透明通道处理两个问题。
我们使用 gifenc 作为 GIF 编码器。它内置 LZW 压缩和 quantize 色彩量化,是一个高效的纯 JS GIF encoder,但透明通道处理和调色板策略需要自己在上层实现。
处理流水线按四阶段推进:
准备阶段。 先统一所有帧尺寸,逐帧 drawImage → getImageData 拿到像素数据(此时不做二值化)。然后做整序列软边检测:扫描 alpha 通道中 (0, 255) 之间的半透明像素。判断标准是「是否存在这种边缘」,不是「有多少像素」。一旦在任意一帧中发现 ≥16 个半透明像素,即判定整序列有软边,扫描提前终止。
软边判定是粘滞的:一经验定,整批帧统一走抖动二值化。因为 GIF 的视觉效果是帧序列连续播放------如果第 3 帧用硬切(边缘锯齿)、第 7 帧用抖动(边缘平滑),播放时边缘会出现明显的闪烁跳变。粘滞策略保证整批 GIF 的透明边缘视觉一致。
二值化根据判定结果走两条路径:硬边用直接阈值切割(alpha ≥ threshold → 255,否则 → 0)。软边走蓝噪声有序抖动,用像素密度模拟半透明渐变。
为什么是蓝噪声而不是更常见的 Bayer 矩阵?Bayer 的固定周期模式在低分辨率下会产生肉眼可见的十字网格纹理。蓝噪声把能量分散到高频区域,没有这种问题。64×64 的矩阵用 Ulichney void-and-cluster 算法预生成,在图像上以 64 像素周期平铺。
软边缘检测的核心逻辑:只需扫描 alpha 通道,发现足够证据即提前终止:
javascript
function detectSoftAlphaBatch(imageDataList) {
for (const imageData of imageDataList) {
if (!imageData) continue
const data = imageData.data
let softCount = 0
for (let i = 3; i < data.length; i += 4) {
if (data[i] > 0 && data[i] < 255) {
softCount++
if (softCount >= 16) return true
}
}
}
return false
}判定为软边后,走蓝噪声抖动二值化,三个分支覆盖所有 alpha 区间:
javascript
function ditherBinarizeAlpha(imageData, threshold) {
for (每个像素 x, y) {
alpha = imageData.data[(y * width + x) * 4 + 3]
if (alpha >= 255) {
finalAlpha = 255 // 完全不透明
} else if (alpha < threshold) {
finalAlpha = 0 // 低于阈值,直接透明
} else {
// 中间区间做蓝噪声抖动
normalizedAlpha = (alpha - threshold + 1) / (255 - threshold + 1)
// 64x64 蓝噪声矩阵,周期平铺
T = BLUE_NOISE_64[((y & 63) << 6) | (x & 63)] / 255
finalAlpha = normalizedAlpha > T ? 255 : 0
}
imageData.data[...] = finalAlpha
if (finalAlpha === 0) transparentMask[pixelIndex] = 1
}
return { needsTransparency, transparentMask }
}归一化公式里的 +1 保证 alpha === threshold 时概率 > 0 变为不透明,与硬边分支的「等于阈值保留」方向一致。
降噪阶段(可选)。 帧间存在随机噪点时,可插入时域降噪:比较相邻帧像素差异,过滤孤立噪点。与调色板策略完全正交,所有档位都可使用。
分析阶段。 调用调色板提供器构建色彩映射表。三档策略:
javascript
// 调色板策略,不同档位实现这个接口
class PaletteProvider {
async prepare(frames) // 构建调色板
getPaletteForFrame(idx) // 取指定帧的调色板
isSegmented?() // 是否分段(可选)
dispose() // 释放资源
} (GIF导出)
(GIF导出)
- 默认档(逐帧独立)。每帧单独做色彩量化,256 色自给自足。相邻帧的同色区域可能被映射到调色板的不同索引,产生轻微的画面抖动。适合帧间色彩变化大的素材。
- 稳定档(全局共享)。从所有帧联合采样后一次性量化,全程使用同一张 256 色调色板。彻底消除邻帧同色跳索引的抖动。默认推荐。
- 多场景档(分段共享) 。先做直方图场景检测,自动切割为多个色彩段,每段独立构建调色板。适合有明显场景切换的长动画。单场景视频自动退化为稳定档,此时
isSegmented()探测由编码层用可选链检查,退化为 GCT 时零额外开销。
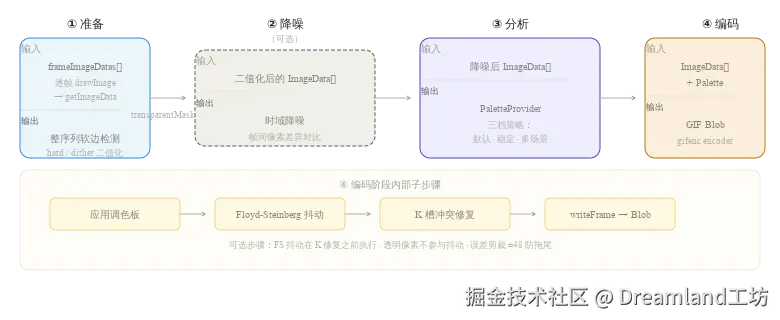
编码阶段。 逐帧:应用调色板 → 可选 Floyd-Steinberg 误差扩散抖动 → 确定透明索引 → 透明索引冲突修复 → 写入 GIF。
这里解释下「透明索引冲突」。GIF 的透明机制是在调色板 256 个颜色槽中指定一个索引作为透明色,这个槽位记作 K。问题来了:选哪个索引当 K?最优策略是选不透明像素使用频率最低的颜色,最小化被「误伤」的像素数。但即便如此,仍然存在冲突。某些不透明像素的最佳匹配色恰好就是 K,如果直接写 K 进去,这些像素会被解码器当成透明的,出现透明噪点。
修复方式:单轮扫描。透明像素直接写 K;冲突的不透明像素重定向到次近色 (排除 K 后距离最近的颜色)。帧内用 Map 缓存已计算的次近色,因为冲突像素的 RGB 分布通常极窄,缓存命中率 >90%。修复后保证一条不变量:encodedIndex 中 K 出现的位置,等价于像素是透明的。
不止 GIF:精灵图与 PNG 序列帧
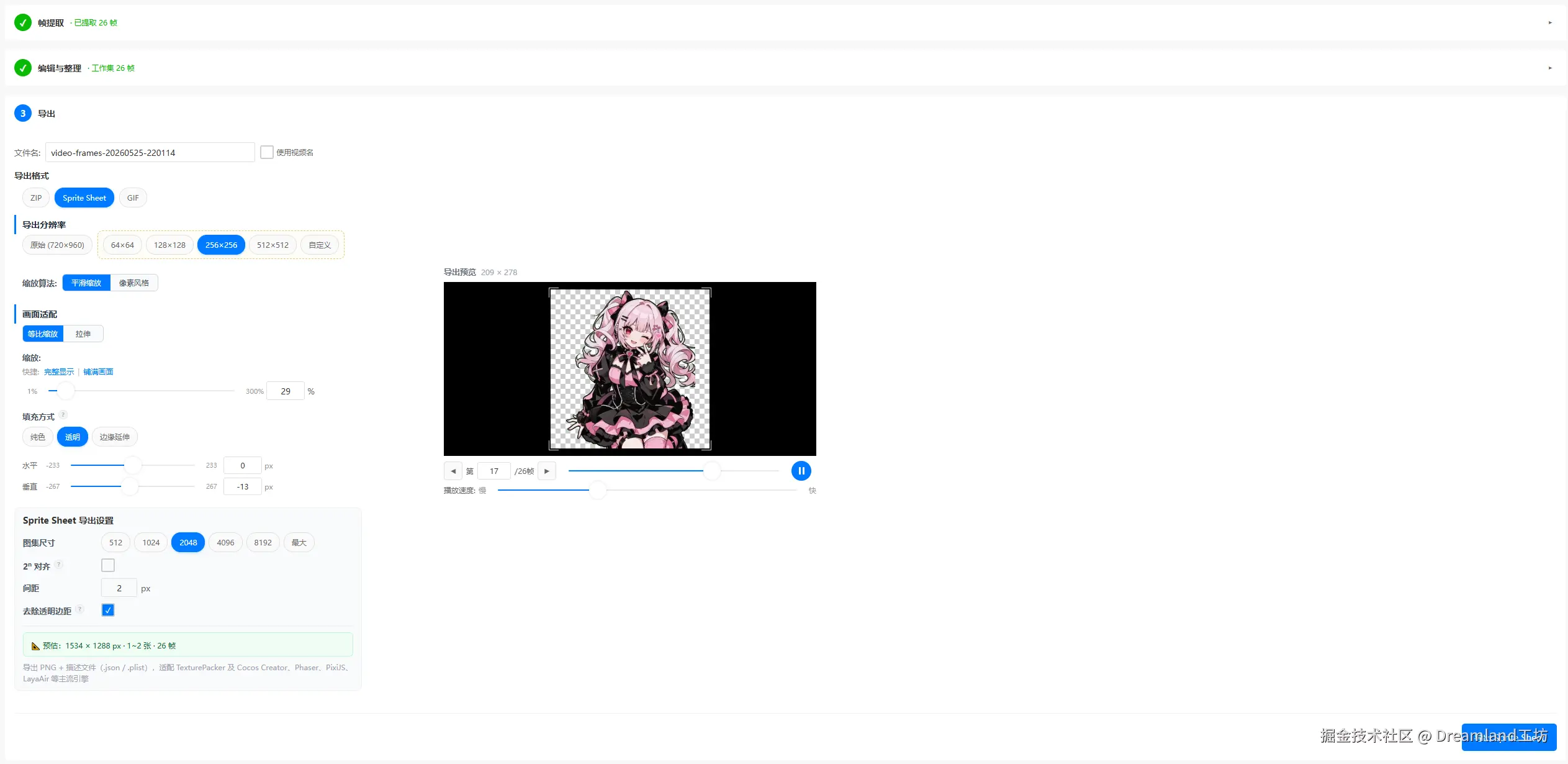
还支持两个导出格式:
精灵图。 所有帧拼合为一张大图 PNG,附带描述文件(TexturePacker JSON + Cocos2d-x plist),可直接拖入 Unity、Godot 等引擎。
 (精灵图导出)
(精灵图导出)
这里有一个容易被忽略的问题:浏览器 Canvas 有最大尺寸限制。不同浏览器和设备差异很大:桌面 Chrome 通常支持 16384×16384,但 Safari 和移动端可能只有 4096 或 8192。不能写死一个值。
我们的做法是在运行时主动探测 :创建候选尺寸的测试 Canvas,从大到小向下尝试(16384 → 8192 → 4096),填充品红色后 getImageData 读回两个对角像素。读回值和写入值不一致,说明该尺寸下 Canvas 实际不可用。探测结果缓存为模块级变量,全局复用。
拿到浏览器上限后,布局算法做线性重排 :按帧索引顺序逐页填满。列数默认 ceil(sqrt(帧数)),用户可手动指定。每个满页尺寸 ≤ 浏览器上限;最后一页自动收缩行列数,不浪费空白。所有帧统一 padding 后对齐到网格,帧尺寸不一致时以最大帧为 cell 尺寸。
我们没有选择把帧摊成大网格再切块的方案。这种方案会产生极度不均衡的边角页,比如最后一页只装两三帧,大片空白。线性重排的每页帧数均匀,最后一页最多差一个满页的量。
 (精灵图成品示例)
(精灵图成品示例)
PNG 序列帧。 ZIP 打包所有帧为独立 PNG 文件,支持自定义分辨率缩放:像素算法(最近邻)保持像素风格的锐利,平滑算法(双线性)适合非像素风素材。
三种格式共享缩放管线:自定义宽高、缩放偏移调节、适配模式。导出层统一编排器分派,格式切换对上游透明。
架构取舍
浏览器端 vs 服务端
| 维度 | 浏览器端 | 服务端 |
|---|---|---|
| 用户隐私 | 视频不离开设备 | 需上传 |
| 处理速度 | 受设备性能限制 | 可用高性能服务器 |
| 部署成本 | 零服务端算力 | 需要 GPU 服务器 |
| 复杂算法 | 受浏览器性能限制 | 无限制 |
核心权衡:视频不离开设备比处理快几秒重要得多。用户处理的是创作素材------一个未公开的角色、一套正在迭代的动画,隐私必须被保护。以及现实因素:浏览器端处理意味着服务端算力成本大幅降低,这让工具在运营策略上可以宽松很多,而且不需要限制用量。
已知限制
这套方案有几个硬边界。
浏览器端单线程,大尺寸多帧数素材的耗时随帧数线性增长。WebCodecs 的 GPU 解码只解决抽帧,后续的色彩量化、抖动、GIF 编码全在 CPU 上。V8 堆内存是另一个天花板:实测 1080p 视频 482 帧 GIF 导出在降噪阶段 OOM,和设备 GPU 显存多少无关。Safari 的 Canvas 最大尺寸、移动端 GPU 内存、各平台的 codec 支持矩阵差异也大,运行时探测是唯一可靠方案。 另外浏览器端在性能和工具链丰富度上都不如原生应用,这也是客观事实。纯粹 Web 路线,有些代价是必须付的。这一点就要看技术和产品层面的取舍了。
收尾
本文聚焦了 FramePacker 的抽帧和导出的管线选型:WebCodecs 优先 + seek 降级双路径、gifenc 上的四阶段 GIF 流水线、三档调色板策略、ffmpeg.wasm 的架构级弃用,以及精灵图布局和 Canvas 运行时探测的工程细节。编辑管线(画笔、橡皮擦、换色工具、批量改图)涉及命令模式和撤销/重做栈,后续单独展开。对完整工具感兴趣的同学,可以在专栏简介中看到链接。