背景
集合竞价服务在发布后,接口存在超时报错情况,合作方反馈接口异常,影响业务正常运行,在这种情况下,为防止发版对服务的影响,每次发布集合竞价服务都要晚上发版,影响发版效率,且当发版出现问题时往往会处理到很晚,效率较低,开发人员每次都要熬夜,十分难受
排查
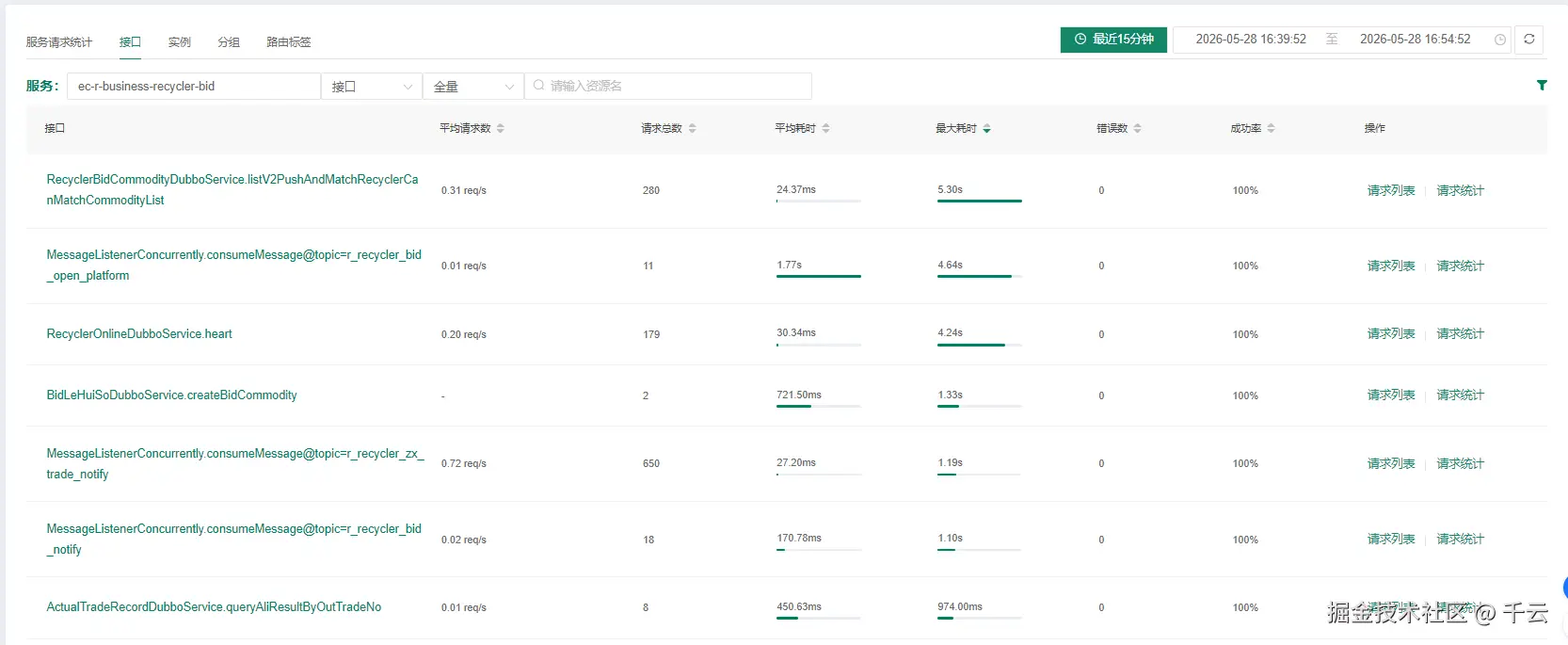
基于云平台监控发现启动的cpu比较高,使用率并不算高大概30%,但是使用量达到300%,所以接口慢初步判定为启动cpu过高
那么是什么导致服务cpu高呢?原始是什么?通过对代码分析,启动过程中会连接mq,而这些mq会占用大量线程,会拉升cpu,这种情况可以让mq分散注册,分散注册会拉长服务启动的时间,而且改造本身也比较大,而且mq的注册本身也是服务启动中的一环,而且未来随着服务功能增多,服务本身是需要更多时间预热的,所以关注的方向应该从减少服务启动性能消耗,转向为给服务启动预热时间,控制服务流量的暴露
怎样去控制服务流量呢?
通过查看云平台功能,我们可以看到,云平台是通过探针的方式来判定服务是否能够对外暴露

这里有两个概念:存活探针与就绪探针,他们的概念分别是
存活探针:存活探针决定何时重启容器(实例)。当程序处在运行期间但由于各种原因导致程序无法正常响应请求的情况、并且需要重启服务才能恢复时,可以通过配置存活探针捕获这类情况。
就绪探针:就绪探针决定何时开始接受流量。 目前通过云平台上持续部署平台部署的应用,在就绪探针校验通过后,会自动上报到注册中心并标记为正常状态,同时会网关也会从注册中心上发现实例,并准备接收流量(需要在接入层上配置注册中心发现方式)
从云平台提供的概念上来看,我们这次主要关注的是就绪探针 ,因为他决定了程序何时向外暴露流量,通过与云平台沟通,针对我们的情况,云平台技术人员推荐的是将首次探测时间属性拉长,这样可以给程序充足的时间进行启动预热
首先,我将测试环境的首次探测时间调整为300s,然后重启服务,发现服务应用在120s便启动完成了,这与配置的服务注册明显不符合
再次询问云平台技术人员,对方答复是集群做了优化,实际集成就绪就会放流量进来,并建议使用http的探测, 实际上http的探测也是平台推荐的探测方式,根据他的建议将tcp探测调整为http探测
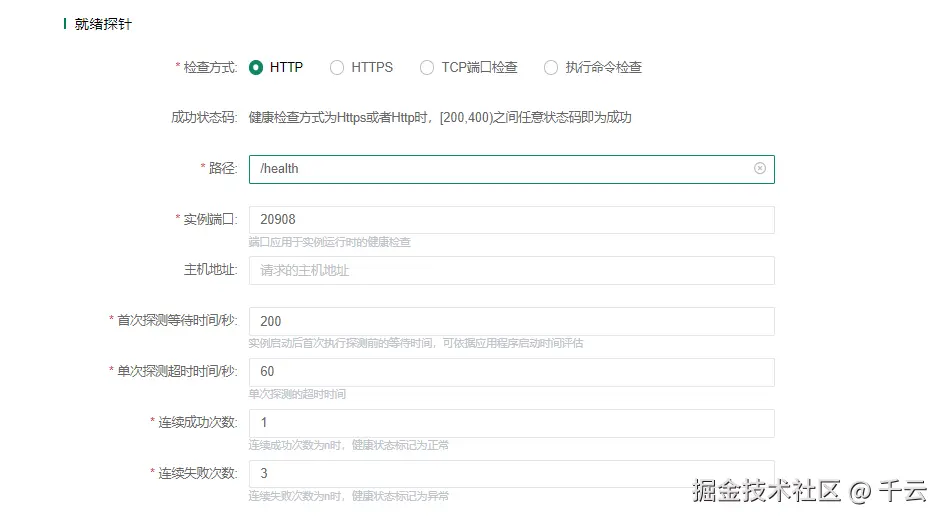
Http的探针方式是通过访问服务暴露的接口,基于接口返回的状态码来判定服务是否已经就绪,规则是如果状态码在【200,400】之间,那么就认为服务准备就绪,可以暴露流量
这种方式需要修改程序代码,在代码中增加探测接口
less
/**
* 健康检查控制器
* 支持延迟暴露,服务启动初期返回503,延迟结束后返回200
*/
@Slf4j
@RestController
public class HealthCheckController {
@GetMapping("/health")
public ResponseEntity<String> health() {
log.info("收到健康检查调用 health check");
return ResponseEntity.ok("ok");
}
}更换为http探针后,情况与tcp访问一样,探针的访问时间仍然未生效、
以上证明云平台的首次探针访问时间配置其实是不生效的
那么怎样让服务暴露的时间延迟呢?
因为http访问探针是基于接口返回的状态码进行判断的,那么可以通过让接口延迟返回正确的状态码,从而减缓服务的暴露时间
再次尝试,通过配置时间来让接口返回状态码
less
@Slf4j
@RestController
public class HealthCheckController {
@GetMapping("/health")
public ResponseEntity<String> health() {
if (!HealthCheckDelayConfig.isHealthCheckEnabled()) {
log.info("健康检查接口尚未完全启动,返回503状态码");
return ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE)
.body("service starting");
}
log.info("收到健康检查调用 health check");
return ResponseEntity.ok("ok");
}
}
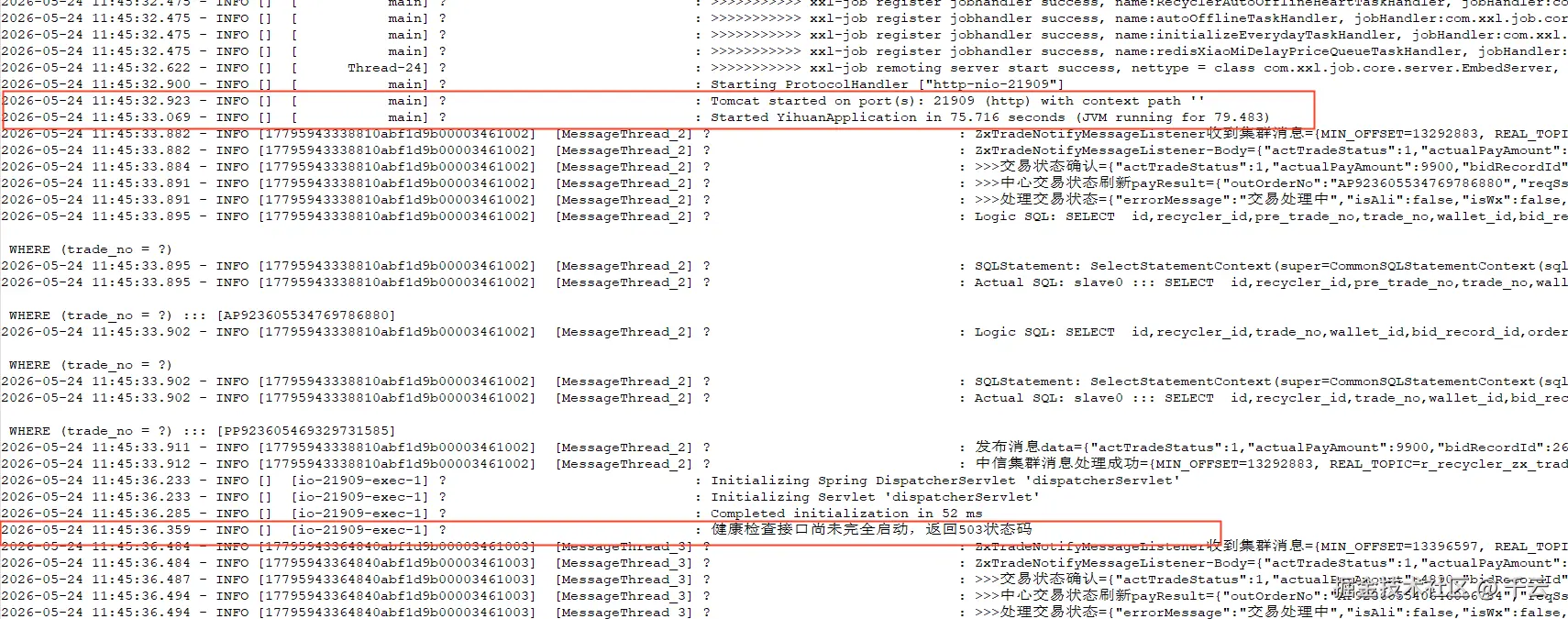
加入这项配置后,设定延迟时间70s,重启服务,发现服务变更为运行中的时间,与配置的时间是对的上的,但是发现服务启动后接口仍然有超时的情况
那么存在问题,既然服务已经进行了延迟的暴露,cpu各项参数已经下降了,为什么接口还出现延迟
通过调用链发现了一个现象,就是超时的接口访问被访问的时间是在服务启动过程中,那时健康检查还在执行,服务还没有进入到运行中的状态,也就是说即便服务还没启动完,请求也是可以请求到应用的
通过查看服务启动日志,发现了dubbo的服务暴露日志
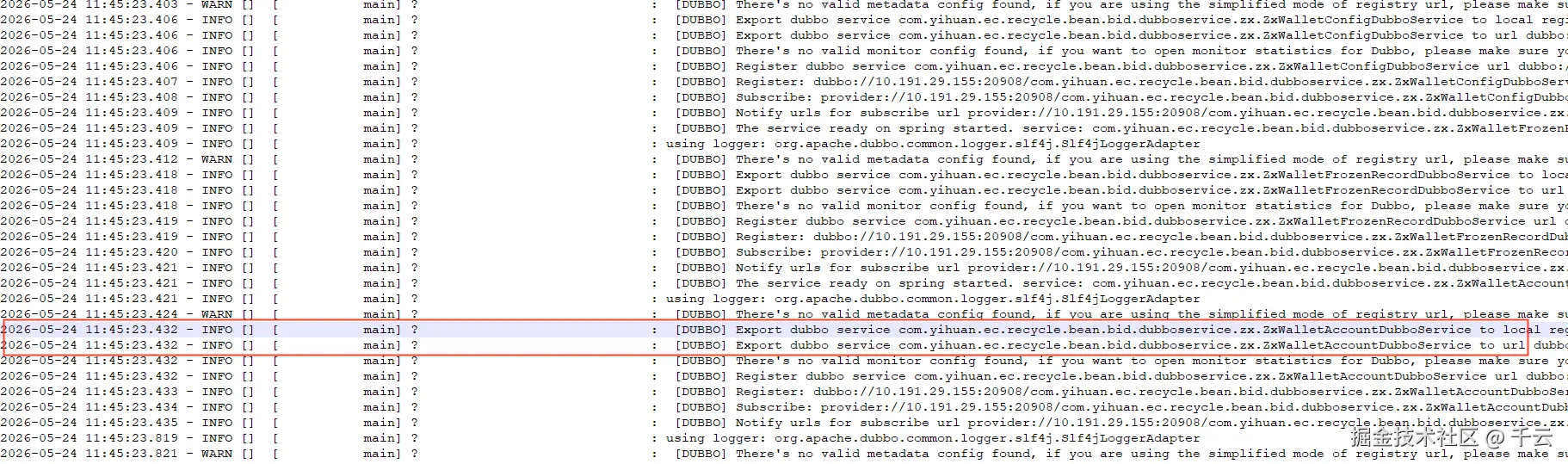
这行日志的意思是,dubbo向其他服务暴露接口,并且打印这行日志时,服务并没有启动完成,也就是说服务是否健康检查成功,和接口的暴露其实是没有关联的,决定接口能不能访问的是,dubbo接口有没有暴露
基于以上可以得出结论,云平台的健康检查和流量控制是存在问题的
当服务运行中也不能代表服务可以访问的情况下,要怎么控制流量呢,也有一种方式,就是通过配置dubbo的暴露时间
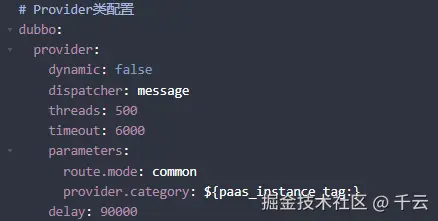
基于服务可能需要启动预热,dubbo在2.7版本提供了延时暴露的能力,可以通过配置delay的属性来设置
delay属性可配置三个参数
arduino
delay:1 不设置延迟(默认)
delay:-1 服务启动后再进行暴露
delay:数值 服务启动后,多少秒后暴露通过设置delay:-1,重启服务,查看dubbo接口的暴露情况
接口的访问仍然存在超时的情况,通过查看日志,发现dubbo接口的暴露还是在启动之前,通过分析,发现我们的dubbo版本虽然是2.7.2符合版本条件,但是springboot-started的版本过低,影响了dubbo的暴露,调整delay配置为70s
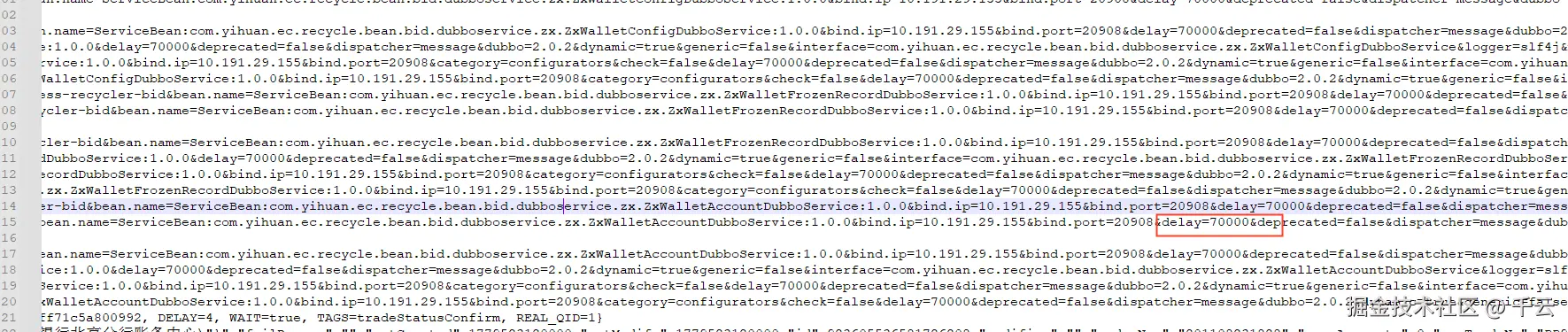
日志上是生效的,验证延迟暴露的时间是否为70s
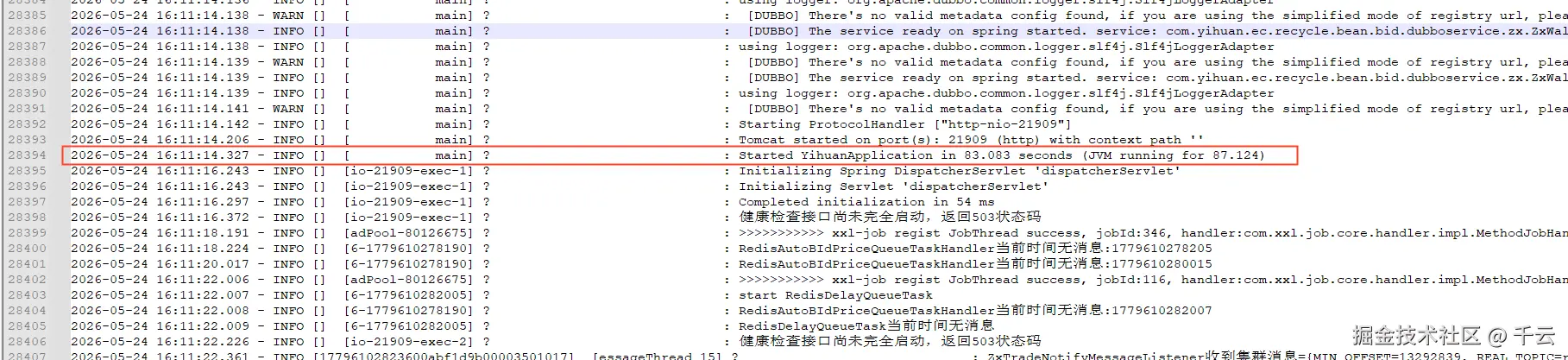
从日志上行可看到,实际的延迟时间为57s,并非70s,说明延迟本身是生效的,但是延迟的时间由于框架问题并没有按照70s时间延迟
在测试环境重启服务后查看接口的调用情况,发现dubbo接口的调用未出现超时的情况,接口延迟暴露是成功的
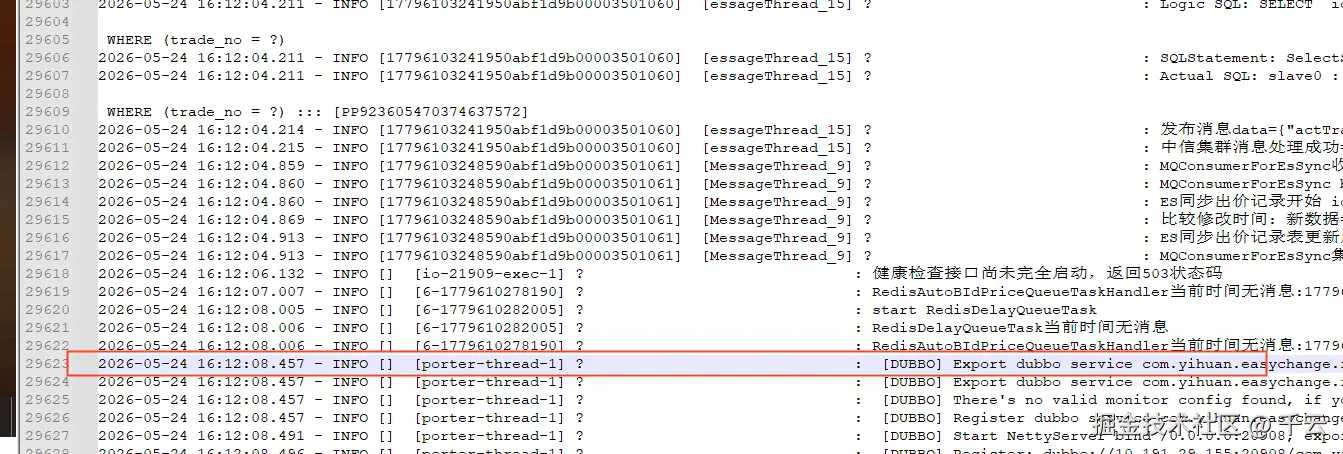
设定生产的delay:90 查看是否可以解决启动后接口超时问题
重启后,查看接口调用,接口响应时间正常,启动后接口访问超时问题得到解决,白天发布不影响相关业务
总结
虽然,dubbo的延迟暴露能够解决接口访问超时,但是服务中还存在MQ的访问,也会受到影响,本质上应该由云平台进行流量的管理,现在接入的云平台流量暴露的能力其实是无效的,后续需要优化才能完成流量控制