Shape Key 不是一个简单的"表情参数"。它本质上保存的是同一批顶点在另一种形态下的位置。Blender 官方文档说,Basis 是 rest shape,其他 Key 是变形后的形状;制作 shape key 时不能增删顶点,因为它依赖同一批顶点编号。Blender Documentation 所以它不是自动从 mesh 当前顶点实时推出来的东西,而是每个 key block 里有自己的坐标数据。
这就是为什么会出现你说的"调整的是世界单位,还有一些不听的"。
更准确的分层是这样:
第一层是 Scene Unit 。
它决定 Blender 怎么显示长度,比如 1 个 Blender Unit 被显示成 1 m、1 cm,或者导出时如何写入单位换算信息。它不保证重写每个数据块里的真实坐标。
第二层是 Object Transform 。
比如 Object Scale 是 0.01 或 100。这个是对象外壳的变换矩阵。它会影响视口显示和导出计算,但 mesh data 本身可以仍然保持原始坐标。
第三层是 Mesh vertex data 。
这是网格本体顶点坐标。你脚本里看到的 vertex_size 就是在读这一层。它已经变成了厘米级。
第四层是 Shape Key data / KeyBlock coordinates 。
这是每个 shape key 里另存的一套顶点位置。你的 Basis 和其他 shape key 还在米级。Blender 的 Shape Key 系统把这些当作独立形态数据处理,而不是普通 mesh vertex 的影子副本。
第五层是 Armature / Bone rest pose 。
骨骼也有自己的 rest pose、head、tail、parent、local transform。它也不一定跟 mesh 顶点同一套缩放逻辑走。
第六层是 Animation / Constraint / Driver 。
动画曲线、约束距离、驱动表达式也可能保存了数值。它们更不会因为你改 Scene Unit 就自动全部乘 100。
Blender 的 Unit 设置不是几何数据变换,它主要是"单位解释/显示"和"导入导出换算参数"。
也就是说,把全局 unit 从 1m 改成 1cm,通常不会自动把这些底层数据一起改写:
mesh 顶点坐标
shape key 每个 key block 的坐标
armature edit bone head/tail
pose bone transform
vertex group 权重
动画 keyframe 的 location 数值
constraint target offset
driver 数值
它只是改变"1 个 Blender unit 代表多少现实单位"。
所以:
原来 mesh 高度 = 1.73 Blender units
单位解释 = meters
现实含义 = 1.73m
如果只改成:
单位解释 = centimeters / scale_length=0.01
mesh 坐标仍然 = 1.73 Blender units
那现实含义就变成:
1.73cm
这就是为什么我测试时只改全局 unit 后,UE root scale 变成 1,但角色高度变成 1.73cm。
"全局 unit"不会自动统一所有对象内部数据。要得到正确结果,必须同时满足:
坐标数据本身变成厘米数值: 173
单位解释也变成厘米: scale_length=0.01
对象 scale / FBX root scale 仍然是 1
另外 shape key 是一个单独坑。
Blender 的 shape key 每个 key block 都保存一套顶点坐标。mesh.data.transform(Matrix.Scale(100)) 会影响 mesh 顶点数据,
但在这次实际测试里 shape key 的 Basis 和其他 key block 没有同步变成厘米尺度,所以我又显式遍历了:
for every shape key:
for every point:
point.co *= 100
这就是"全局 unit"不可靠的原因:它不是"把整个 rig 烘焙到新单位"的按钮。真正可靠的是脚本明确处理每类数据。
Animation Blueprint 里的 Skeletal Control 节点。
用于角色 Skeletal Mesh 局部
大面积软布。
希望某些辅助骨骼用物理资产参与模拟的结构。
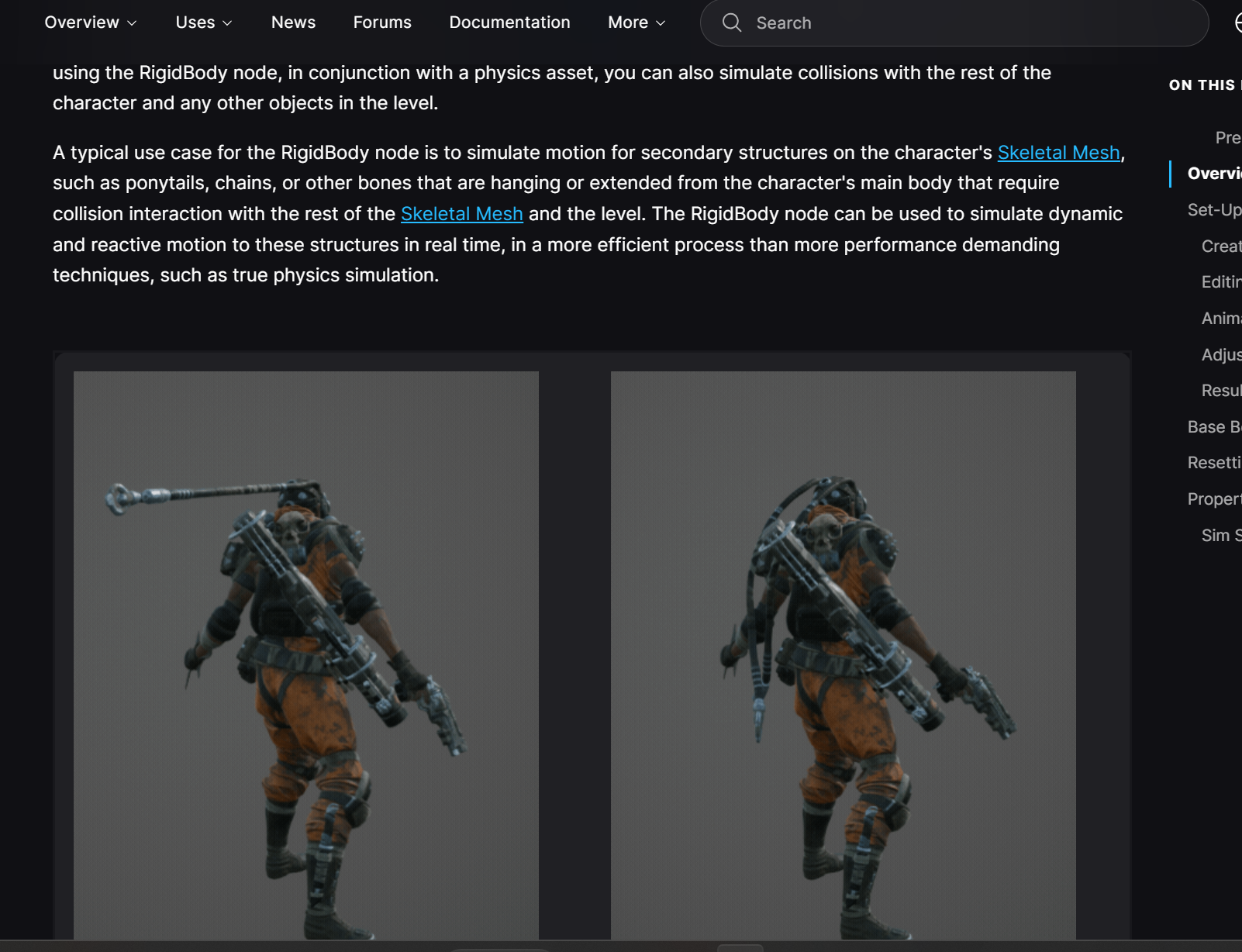
RigidBody 节点不是直接按"网格面片区域"工作,而是按"骨骼 + Physics Asset 里的刚体 Body"工作。
RigidBody 节点主要是从某个骨骼范围开始,让这一批骨骼变成可被物理驱动的次级运动。
在 Physics Asset 里给这些骨骼创建 capsule / sphere / box 之类的刚体 Body,并用 Constraint 连接它们。UE 官方文档也说 Physics Asset 是给 Skeletal Mesh 定义 physics/collision 的资产,里面包含 rigid bodies 和 constraints;RigidBody AnimGraph 节点则会结合 Physics Asset 来模拟 secondary structures,例如马尾、链条、悬挂骨骼等。Epic Games Developers Epic Games Developers
所以你的问题"是不是首先要在某个地方分离要影响哪块区域",准确说不是先分离 mesh,而是先确认:
这块 mesh 有没有独立骨骼链控制。
比如一条头发要动,健康结构应该是:
head
→ hair_root
→ hair_01
→ hair_02
→ hair_03
头发的顶点权重应该主要绑在 hair_01 / hair_02 / hair_03 上。然后你在 Physics Asset 里给 hair_01 / hair_02 / hair_03 加 Body,再在 AnimBP 里用 RigidBody 节点模拟它们。
如果那块 mesh 没有独立骨骼,只是和头、身体、腿共用同一批骨骼,那么 RigidBody 节点没有干净的"作用范围"。它不能凭空知道"只让这片头发 mesh 摆动"。
make a specialized physics asset to isolate the secondary structures you are simulating motion and collision with the RigidBody node.
Using a specialized physics asset with the RigidBody node can be a more optimal method to better control the behaviors of the structures during the simulation.
更像"在当前情况下,我采取这个选择"。
英文用 are choosing,就是把第二种情况写成"当前工作流选择"。
AnimBP 里的连接位置和 Alpha 决定"物理结果和原动画混合多少"。
Mass,质量
位置:打开 Physics Asset,选中某个 Physics Body,在 Details 里找 Mass / Mass in KG。
它决定这节骨骼"重不重"。质量大的 body 更稳、更不容易被甩飞;质量小的 body 更容易摆动。官方示例建议靠近父骨骼的 body 更重,后面的 body 逐级减半,例如第一节 2kg、第二节 1kg,用来减少抖动。Epic Games Developers
对头发、链条、尾巴这类结构,一般规律是:
根部重,尾端轻。
根部稳住,尾端摆动。
Linear Damping / Angular Damping,线性阻尼和角阻尼
位置:Physics Asset,选中 Body,Details 里找 Linear Damping 和 Angular Damping。
这两个是最直接控制"甩动程度"的参数。官方文档说较高的 damping 会减少 motion,用来控制 flailing 和 shaking;示例值是 5.0,但每个实现都要单独微调。Epic Games Developers
Linear Damping 控制位置移动的衰减。
Angular Damping 控制旋转摆动的衰减。
Constraint 限制,决定"能弯到什么程度"
位置:Physics Asset,选中两个 Body 之间的 Constraint。
这组参数比 Mass / Damping 更关键,因为它决定物理链的"关节规则"。也就是说,它不是调"力有多大",而是调"这根骨骼允许怎样相对父骨骼运动"。
目标是"金属链条/挂件",一般是:
质量稍大。
Angular limit 比较明确。
Damping 中等偏高。
不要让它像布条一样软。
hysics Mode:Simulated / Kinematic
位置:Physics Asset,选中 Body,Details 里找 Physics Mode。
官方示例里,要被 RigidBody 模拟的结构设为 Simulated ,其余身体碰撞体设为 Kinematic 。也就是说,头发、管子、链条这种要动的 body 是 Simulated;头、背、手臂、武器这种只是作为碰撞对象的 body 是 Kinematic。Epic Games Developers
这是作用范围的核心开关。
Simulated:这部分会被物理计算影响。
Kinematic:这部分跟随动画,只作为碰撞/参考,不被物理甩动。
所以你要做"头发碰到背部",不是把背也设成 Simulated,而是:
头发 body = Simulated。
头、背、肩、身体 body = Kinematic。
碰撞开启。
这样头发会撞身体,身体不会被头发带着乱动。
应该通过 IK Retargeter 导出/复制一份 target Skeleton 版本的 Animation Sequence,或者使用 runtime retargeting。
IK Retargeter 本身更像一个"转换器资产"。它保存的是 source IK Rig、target IK Rig、chain mapping、retarget pose、op stack 等转换规则。它不是普通 Animation Sequence。打开 IK Retargeter 预览 Manny 动作时,你看到的是"把 source 动作临时映射到 target 身上"的结果。要变成你项目里可直接播放、可放进 BlendSpace/AnimBP/State Machine 的 target 动作,通常要 Export Animations 或 Duplicate Anim Assets and Retarget。
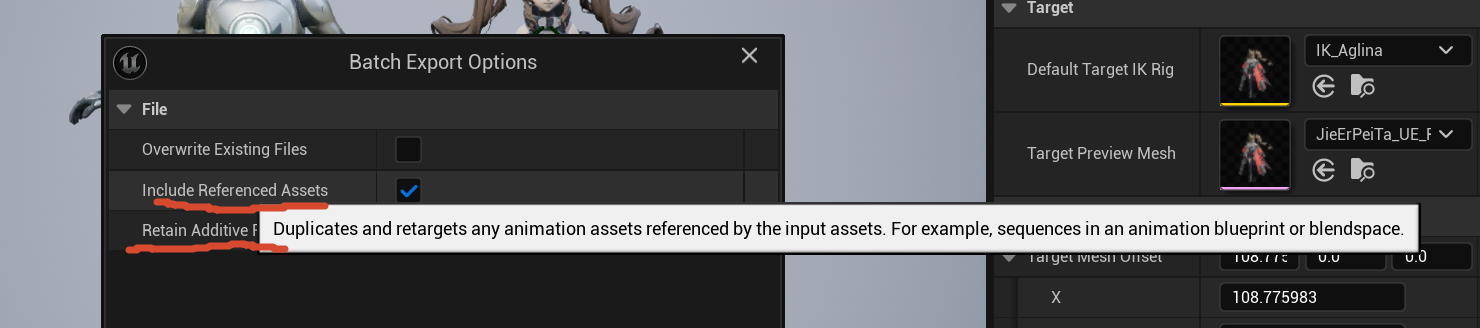
duplicate and retarget input assets 所引用的动画资产,例如 Animation Blueprint 或 BlendSpace 里的 sequences。Epic Games Developers
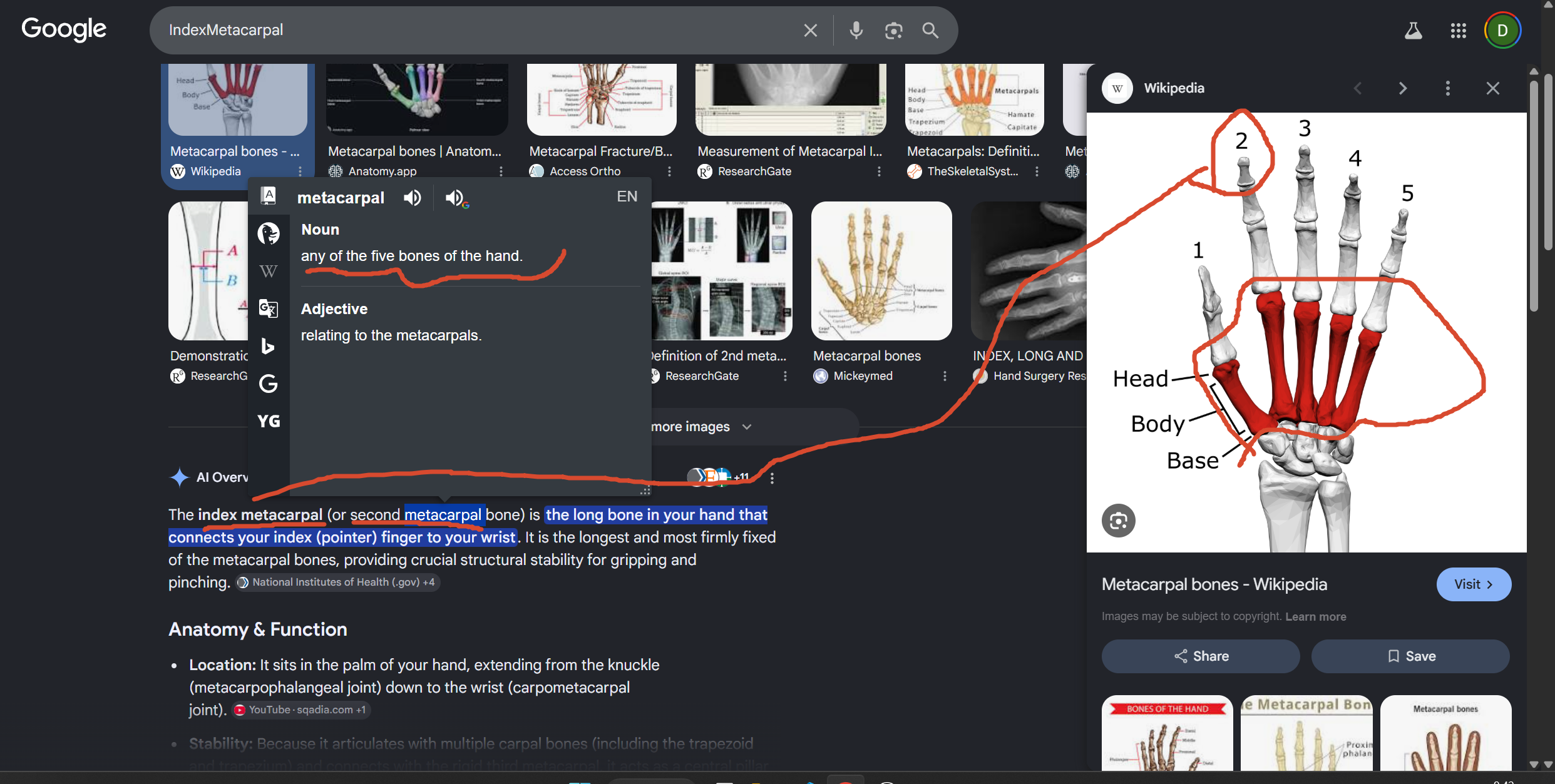
骨骼名稱對應表
| 圖片日文 | 羅馬拼音 | 中文意思 | 3D綁定常見英文 (左手 _L ) |
|---|---|---|---|
| 親指 0_L | Oyayubi | 大拇指 0 | Thumb_01_L / Thumb_Metacarpal_L |
| 人指 1_L | Hitosashiyubi | 食指 1 | Index_01_L / Index_Metacarpal_L |
| 中指 1_L | Nakayubi | 中指 1 | Middle_01_L / Middle_Metacarpal_L |
| 薬指 1_L | Kusariyubi | 無名指 1 | Ring_01_L / Ring_Metacarpal_L |
| 小指 1_L | Koyubi | 小指 1 | Pinky_01_L / Little_01_L |
修了之前卡住的根因:mcp-unreal docs index 锁竞争。现在 wrapper 会给每次启动分配独立 docs index,不再因为旧进程锁住
index.bleve 导致新 Codex 等 115 秒后失败。
今天 NVIDIA 在台北的 GTC Taipei / COMPUTEX keynote,主軸不是單一顯卡,而是把 AI 變成一整套工業基礎設施:AI factory、Vera Rubin、台灣供應鏈、local AI agent、robotics / physical AI。
核心可以這樣看:
第一,黃仁勳把敘事從「賣 GPU」推到「賣 AI factory」。他說現在 AI 已經不是研究玩具,而是「profit generator / GDP generator」;客戶真正想買的不是電腦,而是能把電力、資料、模型轉成 token / intelligence 的 AI factory。NVIDIA 同時推 DSX 這類 AI factory framework,強調在同樣電力預算下塞更多 GPU、降低 token 成本。NVIDIA Blog
第二,Vera Rubin 是台灣供應鏈的中心。NVIDIA 官方說,台灣有超過 500 個 NVIDIA ecosystem partners,Vera Rubin infrastructure 的超過 100 萬個 MGX rack components 會在台灣、跨 25 個工廠整合;供應鏈包括 TSMC、SPIL、Kinsus、KYEC、UMTC,以及 Foxconn、Pegatron、QCT、Wistron、Inventec 等。這句話的意思是:NVIDIA 的下一代 AI 伺服器不是「美國公司自己做」,而是高度依賴台灣從晶圓、封裝、測試、伺服器組裝到機櫃整合的完整鏈條。NVIDIA Blog
第三,台灣供應鏈不只是代工,還被 NVIDIA 當成「AI 工廠改造範例」。TSMC 用 CUDA-X、AI models、cuLitho、cuEST 做 lithography、process simulation、yield analysis、inspection;Foxconn 用 NVIDIA Factory Operations Blueprint / NemoClaw 做製造管理 agent;QCT 用 Omniverse digital twins 做工廠規劃;Wistron 用 Omniverse DSX Blueprint 模擬 AI server burn-in 環境。這對投資敘事重要,因為 NVIDIA 在講「我不只賣算力給 AI 公司,我也把製造 AI 算力的工廠本身 AI 化」。NVIDIA Blog
第四,發布了 RTX Spark 這個 PC 方向的新東西。官方說 RTX Spark 是一類新的 Windows PC,目標是讓 personal AI agents 在本地跑,規格敘事是最高 1 petaflop AI compute、128GB unified memory、slim Windows laptops / efficient desktops、all-day battery life。這不是普通遊戲筆電敘事,而是 NVIDIA 想把「本地 agent 電腦」做成新的 PC 類別。NVIDIA Blog
第五,NVIDIA 和 Microsoft 的 Windows agent 合作被明確拿出來講。OpenShell runtime 會來到 Windows,基於 Microsoft 新的 agent security primitives,提供 identity、containment、policy、end-to-end security;NVIDIA 這邊負責讓 agent 可以按使用者隱私政策在 local model / cloud model 間路由,甚至把個人資訊做 masking。這其實是在解決一個關鍵問題:如果 AI agent 要真的操作你的電腦和文件,安全邊界必須先被定義。NVIDIA Blog
第六,local AI agent 的軟體生態也被加速。NVIDIA 說 NemoClaw blueprint 會擴展到 GeForce RTX、RTX PRO、RTX、DGX Spark、DGX Station;llama.cpp 和 vLLM 上有 multi-token prediction 等優化,部分 agentic models 推理性能可到 2x;Adobe 的 Photoshop / Premiere 會重構以提升 performance / memory,Blender 也會加入 NVIDIA DLSS 4.5 Ray Reconstruction。NVIDIA Blog
第七,physical AI / robot 方向發布了 Cosmos 3 。Cosmos 3 是新的 open world foundation model,結合 vision reasoning、multimodal generation、action prediction,可以用文字、影片、影像、環境聲音、動作資料生成物理場景資料,幫機器人、自動車、智慧空間系統「先理解世界,再預測下一步,再行動」。它可以生成 robot action data,例如 joint angles、gripper positions、trajectory points,這對機器人訓練很關鍵。NVIDIA Blog
第八,AI Cloud / sovereign AI 也是重點。NVIDIA 說 AI Clouds 會把訓練、fine-tuning、inference、agentic AI、physical AI、sovereign AI 部署帶到更多地區;CoreWeave、Nebius、Nscale、NAVER Cloud、Yotta、Firmus、Indosat、GMI 等都在這個敘事裡。這裡的市場邏輯是:不是每個國家/企業都直接買 GPU 自建,而是透過區域 AI cloud 使用 NVIDIA 全棧。NVIDIA Blog
用交易/投資語言講,今天的 keynote 不是「一個新品發布」,而是三條敘事合流:
NVDA 主線 = AI factory 基建化。
GPU 需求被重新包裝成 token revenue、compute revenue、national infrastructure。
台灣主線 = 全球 AI 基礎設施製造中心。
黃仁勳把台灣從「晶片代工地」提升成「AI factory supply chain hub」。
PC / agent 主線 = NVIDIA 想進入下一代 Windows PC 控制層。
RTX Spark + OpenShell + Windows agent security,是在搶「本地 AI agent 電腦」入口,而不是只賣顯卡。
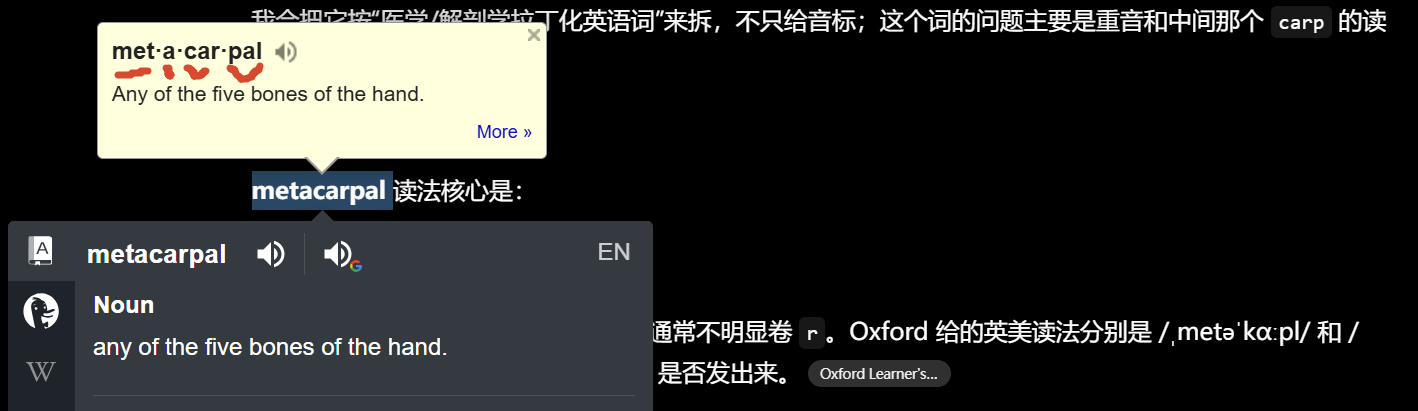
MET-ə-CAR-pəl
这个词听起来专业感来自中间那个 CAR ,不是来自最后的 pal。
waist 读音大概是 /weɪst/ ,像 "waste"。意思是腰、腰围。
wrist 读音是 /rɪst/ ,开头的 w 不发音。意思是手腕。
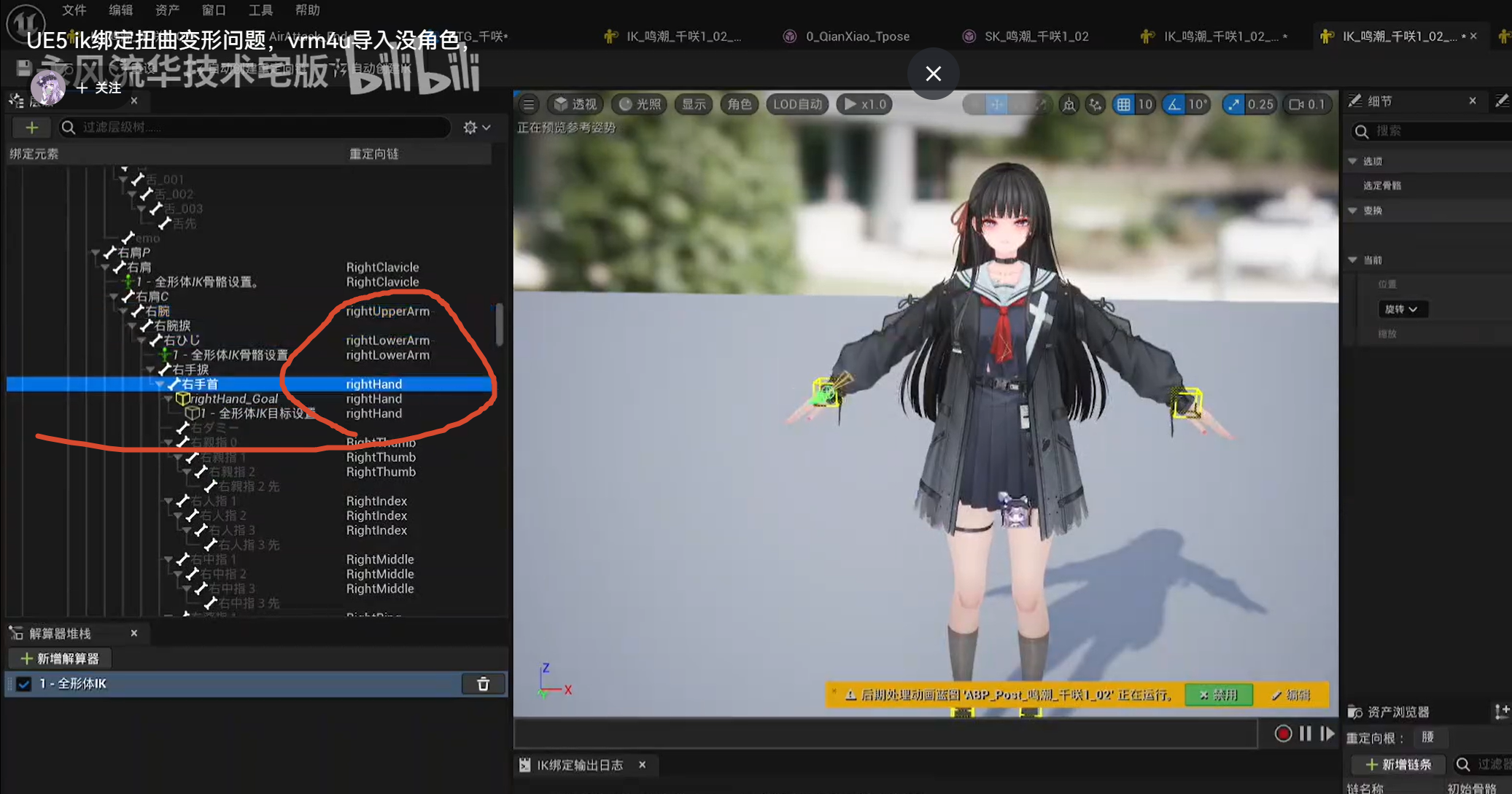
source 的 Arm chain 有 LeftHandIK/RightHandIK goal,但 target 的 Aglina Arm chain 目前没有 IK
goal。这个组合很容易让"手首"成为 FK 末端时在动画帧里跳。


把 腕捩_L/R、手捩_L/R 标成 excluded:UE 有 Exclude Bone,但它主要是"从 IK Solver 求解层级里排除",不是 Retarget Chain 的通用排除开关。
官方 IK Rig Solver 文档里确实有 Excluding Bones :在 IK chain 里的骨骼可以被排除,使它们被所有 Solvers 忽略;操作是选中骨骼,右键,选择 Exclude Selected Bone From Solve 。官方用途是修正坏姿势,或简化复杂链。Epic Games Developers
但关键是:这主要影响 IK Solver 。如果你没有加 Solver,只是用 IK Retargeter 的 FK Chains 做 retarget,那么"Exclude Selected Bone From Solve"不一定会让这些 twist bones 从 FK retarget 插值里消失。它的语义是 exclude from solve ,不是 exclude from retarget chain。
改 LeftArm/RightArm 的 FK Rotation Mode,不用 Interpolated:有,而且很相关。
UE 的 RetargetFKChainSettings 里有 Rotation Mode。官方文档对几种模式的解释是:
Interpolated:source 和 target chain 会按长度归一化,然后 target 每根骨会在 source chain 的相同归一化位置上取旋转,并在相邻 source bones 之间插值。
One to One:target chain 的每根骨按链内顺序,从 source chain 的对应骨复制旋转。
None:target chain 每根骨保持 reference pose 的旋转。Epic Games Developers
这正好解释你说的 twist bone 问题。MMD 里常见 腕捩、手捩 这种扭转辅助骨。它们不是 Manny/Quinn 那种标准手臂主链的一节,而是为了分摊扭转、修皮肤变形用的辅助层。若 LeftArm chain 包含:
上臂 → ひじ → 腕捩 → 手捩 → 手首
并且 FK Rotation Mode 用 Interpolated,UE 会把 source arm chain 的旋转按长度分布到 target chain 上。这样 twist bones 也可能吃到一部分上臂/前臂/手腕旋转,接口就可能变成"旋转被分摊错位",出现手腕折、手掌跳、袖口附近扭曲。
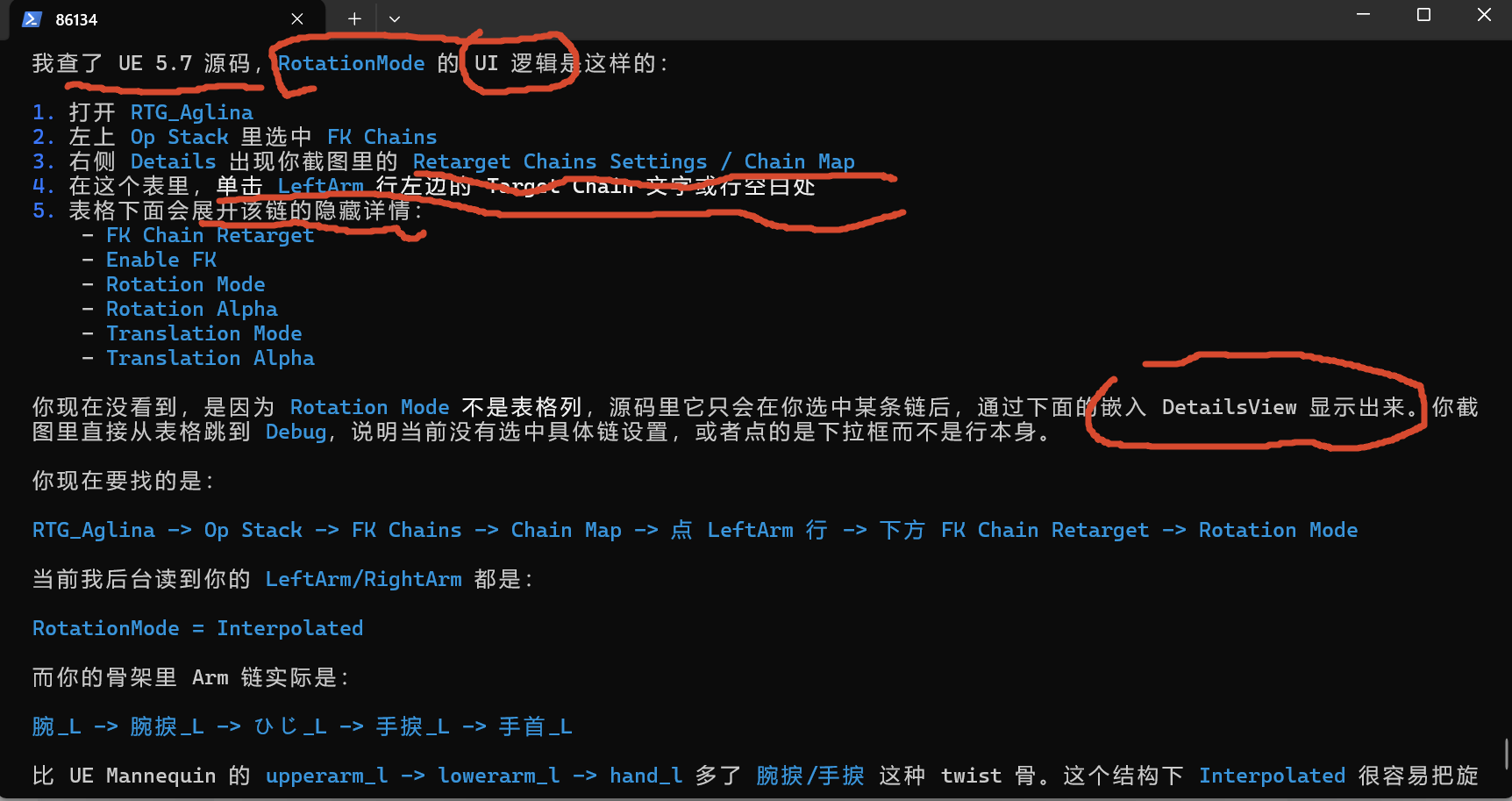
One to One Reversed 的意思是:
UE 不从链的根部开始配对,而是从链的末端开始配对。
你现在的 source 大概是:
upperarm_l → lowerarm_l → hand_l
target 是:
腕_L → 腕捩_L → ひじ_L → 手捩_L → 手首_L
如果用 One to One,它从根部开始对:
upperarm_l → 腕_L
lowerarm_l → 腕捩_L
hand_l → ひじ_L
后面的 手捩_L / 手首_L 没有 source 对应,就可能保持 reference pose,或者效果很怪。
如果用 One to One Reversed,它从末端开始对:
hand_l → 手首_L
lowerarm_l → 手捩_L
upperarm_l → ひじ_L
前面的 腕_L / 腕捩_L 没有 source 对应。
所以它不是"减少 twist 骨数量"。它只是改变 source chain 和 target chain 的配对方向 。官方文档也这样说:One to One 是按 chain 顺序从 root 开始复制 source bone rotation;One to One Reversed 是同样的一对一方式,但从 chain tip 开始。Epic Games Developers
也就是说,一只野外刷出来的龙,系统会把它的等级点随机分配到 Health、Stamina、Weight、Damage 等属性里。Wild Dino 页面里的数值 决定这些"野生点"每一点值多少钱。Beacon 对 ARK 的配置解释也是这个逻辑:Wild Per-Level 用于野生生物按野生等级获得并随机分配的属性点;Tamed Per-Level 则用于驯服后玩家手动加点。usebeacon.app
所以从配置结构看:
overflow-visible!
Wild Dino
= PerLevelStatsMultiplier_DinoWild[x]
= 野外生成时,每个野生属性点的倍率而:
overflow-visible!
Tamed Dino
= PerLevelStatsMultiplier_DinoTamed[x]
= 驯服后升级时,每个手动加点的倍率Nitrado 的 ASA 配置说明也把它们分成 PerLevelStatsMultiplier_DinoTamed[0] 和 PerLevelStatsMultiplier_DinoWild[0] 两套代码,说明底层确实是两个不同配置组,不是同一个东西。
Stats Per Level
意思是:驯服后,你给龙手动升级时,每点属性增加多少。
对应配置大概是:
overflow-visible!
PerLevelStatsMultiplier_DinoTamed[属性ID]这就是你理解的"升级"。比如你想让已驯服的龙每升一次 Weight 加更多负重,就改这一列的 Weight。
Add Per Level
意思是:驯服完成时,系统给这只龙的"驯服奖励等级 / bonus levels"带来的属性加成倍率。
对应配置大概是:
overflow-visible!
PerLevelStatsMultiplier_DinoTamed_Add[属性ID]这不是你手动升级。举例:野生 150 级龙,完美驯服后可能变成 224 级左右,中间多出来的那些驯服奖励等级会被分配成属性点。Add Per Level 影响的就是这类驯服后额外等级/额外点数的属性收益。社区解释里也通常把它理解为 taming level bonuses,也就是驯服奖励等级带来的属性。Steam Community
Stat Affinity
意思是:驯服有效性 / taming effectiveness 对某些属性的额外亲和加成倍率。
对应配置大概是:
overflow-visible!
PerLevelStatsMultiplier_DinoTamed_Affinity[属性ID]这个更不是手动升级,也不是野生等级。它主要处理"驯服质量"对属性的额外修正。尤其是 Health 和 Damage 这类属性,ARK 会给驯服生物做额外平衡,所以你看到默认值不是 1,而是比如 Health 0.44、Damage 0.44,这是正常的。
所以三列的真正逻辑是:
overflow-visible!
Stats Per Level = 驯服后手动升级加点
Add Per Level = 驯服完成时,奖励等级带来的属性
Stat Affinity = 驯服有效性带来的额外属性修正

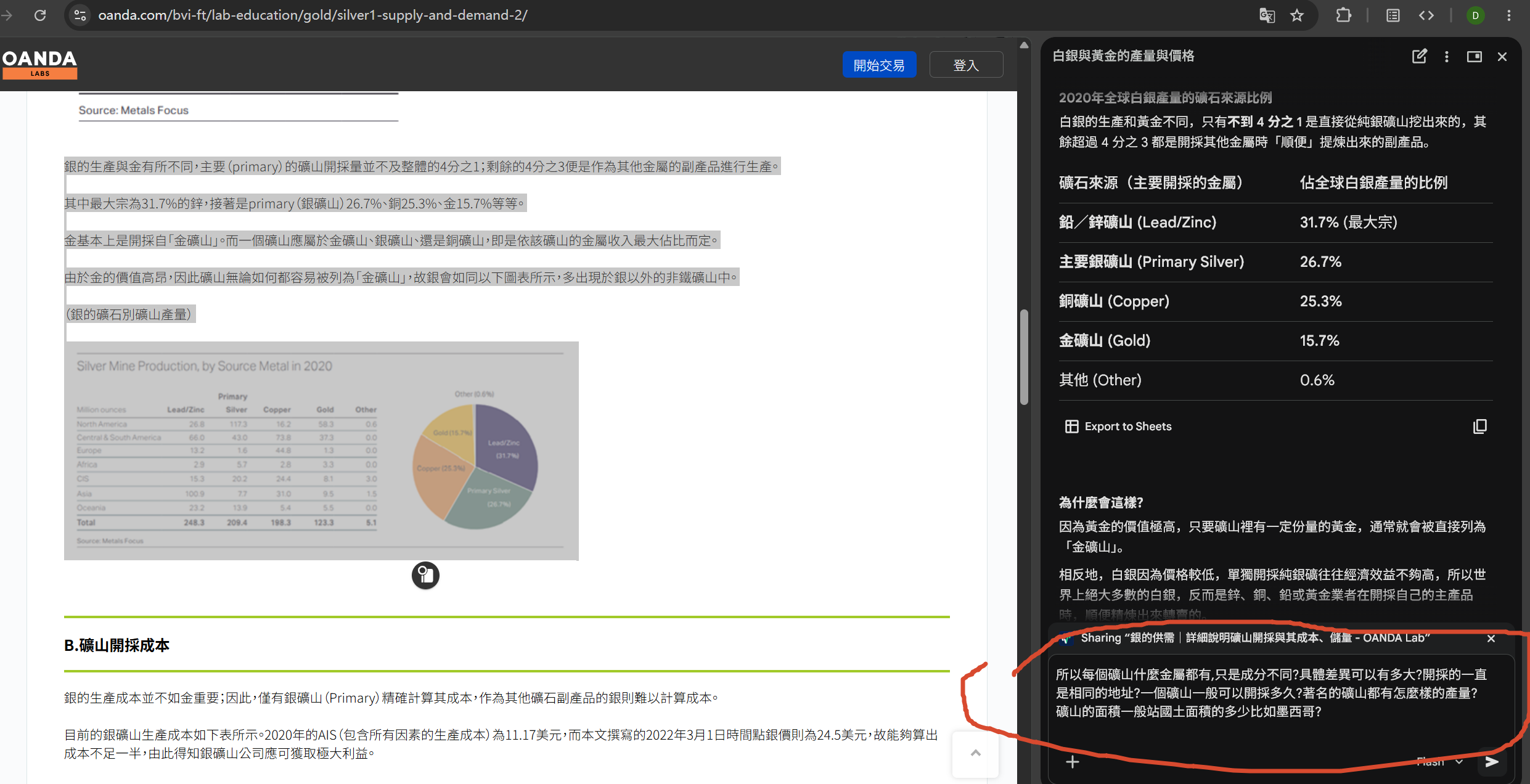
銀的開採 約有四分之三來自於銅、鉛、鋅等非鐵金屬礦的提煉副產品,其餘四分之一才是專門的銀礦山開採 。全球主要銀礦生產國包含墨西哥、秘魯、中國與澳洲。隨著科技發展,現今開採多依賴大型重型機械、爆破技術與先進的化學提煉(如氰化法)來提取。
銀約有26,000噸是透過礦山開採,比金的4,000噸多了約莫6.5倍。
但是,銀價在目前2022年2月來到80分之1的程度,故以稀有價值來看,銀可說是比金廉價許多。
銀的主要產地為墨西哥、秘魯等中南美以及中國,其中以墨西哥為最大宗,2020年產出5541噸;接著是秘魯的3411噸、中國的3377噸。此三個國家正好佔據了全球礦山產量的一半。
日本為銀的進口國,主要由墨西哥、秘魯、韓國以及澳洲進口。論及日本國內的銀供給者,大多是由貿易公司進口自銀的生產國(塊狀進口)、以及日本礦山精練公司從進口的銅礦石、鋅礦石中,生產該品牌特有的銀作為副產品,並被稱為「國內礦業公司」。
銀的生產與金有所不同,主要(primary)的礦山開採量並不及整體的4分之1;剩餘的4分之3便是作為其他金屬的副產品進行生產。
The United States Geological Survey, founded as the Geological Survey, is an agency of the United States Department of the Interior whose work spans the disciplines of biology, geography, geology, and hydrology. The agency was founded on March 3, 1879, to study the landscape of the United States, its natural resources, and the natural hazards that threaten it. The agency also makes maps of planets and moons, based on data from U.S. space probes. The sole scientific agency of the U.S. Department of the Interior, USGS is a fact-finding research organization with no regulatory responsibility.
USGS 2025 估計全球銀礦產量約 25,000 噸,全球銀儲量約 640,000 噸。直接相除是 640,000 / 25,000 ≈ 25.6 年。
銀礦石品位下降時,要磨更多岩石、耗更多水電、處理更多尾礦,成本上升。不是沒有銀,而是每多拿一噸銀,需要付出更多能源、資本、污染處理和時間。
2024 年全球銀消費約 37,000 噸,並且消費超過供應,是銀價上漲原因之一。Silver Institute 也預測 2025 年市場連續第五年赤字,總供應約 10.5 億盎司,礦山產量約 8.44 億盎司,回收超過 2 億盎司,但仍有約 1.49 億盎司缺口。
每個礦山都有一個主礦化系統,這個系統會偏向某幾種元素組合。比如鉛鋅銀型、銅鉬銀型、金銀型、銅金型、鎳銅鈷型、鐵礦型、鋰鹽湖型。它不是元素週期表全部都有,只是比例不同。
以銀為例,USGS 2025 明確說,銀主要作為鉛鋅礦、銅礦、金礦的副產品產出;雖然有一些「primary silver mine」,但含銀的多金屬礦床占美國與全球銀資源三分之二以上。這就是為什麼銀價上漲,不一定能立刻讓銀產量暴增,因為很多銀藏在別人的生產線裡。U.S. Geological Survey
一個礦山如果收入 60% 來自銀,就會被市場叫銀礦;如果銀只貢獻 5% 或 10% 收入,即使每年產很多銀,也可能被叫銅礦、金礦或鉛鋅礦。
礦床 deposit:地下真正有礦化的地質體。
礦山 mine:圍繞這個礦床建立的開採工程。
露天坑 open pit 或井下巷道 underground workings:實際挖礦的位置。
礦區/礦權 concession:法律允許公司勘探、開採的一片土地。
所以「地址」可以相同,但採場會變。露天礦會沿著 pit shell 一層層下挖、擴坑、換礦段;地下礦會沿著礦脈、礦體走向開新水平、新巷道、新採場。公司報告裡常說的 mine sequencing,就是「今年挖哪一段,明年挖哪一段」。Newmont 對 Peñasquito 的說法就是,它是墨西哥一座生產金、銀、鉛、鋅的露天多金屬礦,產量會隨不同 pit、不同礦段的開採順序變化。Q4 Communications
「一個礦山一般可以開採多久?」
差異很大。小型礦可能幾年到十幾年;大型世界級礦山可以二三十年、五十年,甚至更久。不是因為一開始就知道能挖一百年,而是因為邊挖邊勘探、邊把資源升級成儲量。
Newmont Corporation - About Us - About Mining - Mining at Newmont - Lifecycle of a Mine
第一種是建材級資源:砂石、石灰石、大理石、黏土、蛇紋石、白雲石這類。這些跟房屋、道路、水泥、骨材有關。台灣本地確實有一些,尤其東部有石灰石、大理石,河川也曾提供砂石來源。這類資源可以補一部分本地建設需求,但受環保、地形、保育、水土保持、居民反對限制,不是想挖多少就挖多少。
第二種是能源資源:煤、石油、天然氣。這一類台灣基本不夠。經濟部能源署 2024 年資料顯示,台灣總能源供給中,進口能源占 95.8%,自產能源只占 4.2%;進口能源裡,原油及石油產品、煤、液化天然氣是主體。這表示台灣不是「礦山小但努力挖就能自給」,而是整個能源底座高度依賴外部供應。Moeaea

「磨得開」的能力:破碎、磨礦、能耗控制。這裡的物理限制很硬,因為很多金屬不是以純金屬顆粒存在,而是鎖在礦物晶粒裡。你必須把岩石打碎到足夠細,讓有價礦物和脈石分離,這叫 liberation,解離。問題是磨得越細,耗電越高,泥化越嚴重,分選越難。所以進步的指標不是單純磨得更細,而是「在更低能耗下達到足夠解離」。
熱力學與能量。要把金屬從氧化物、硫化物、矽酸鹽、碳酸鹽裡拉出來,必須付出能量或化學試劑。越穩定的化合物越難還原。鋁為什麼不是古代金屬,就是因為鋁氧化物非常穩定,必須靠電解鋁工業;鐵、銅、鉛、銀、金則更早被人類處理,因為它們的化學與冶煉門檻不同。
礦石品位依賴什麼?先依賴地質成因。熱液礦床、斑岩銅礦、矽卡岩、火山塊狀硫化物、沉積型鉛鋅礦、偉晶岩鋰礦、鹽湖鋰礦、砂礦,每一類形成時的溫度、壓力、流體、圍岩、構造通道不同,所以元素富集方式不同。這是第一層。
第二層依賴礦體內部位置。同一礦山也不是均勻的。上部氧化帶、下部硫化帶、富礦脈、貧礦段、斷層破碎帶、邊界低品位帶,都會差很多。礦山每年產量波動,很多時候不是設備變差,而是今年剛好挖到低品位礦段。
礦石 → 破碎 → 磨礦 → 解離 → 分選/浸出 → 精礦/溶液 → 冶煉/電解 → 金屬。

鐵產量最高,主要不是因為「最好分離」,而是因為「地殼含量高 + 鐵礦床規模巨大 + 鋼鐵需求極大 + 冶煉體系成熟」。磁性分離只是其中一部分,尤其對磁鐵礦有效,不是所有鐵礦都靠磁性。
鐵是產量最高的金屬,直接原因是人類需要大量鋼。USGS 說,幾乎所有鐵礦石都用於煉鋼;鐵礦在約 50 個國家開採,澳洲、巴西在出口中占主導地位。這背後不是珠寶級、小體積高價邏輯,而是建築、橋梁、汽車、船舶、機械、管線、軍工、基礎設施都吃鋼。USGS
鐵「容易成為大宗金屬」,主要靠幾個條件疊加。
第一,鐵在地殼中很常見。它不像金、銀、鉑、鈷、鋰那樣需要在很稀薄的背景中找局部富集。地質上能形成非常大的鐵礦床,比如條帶狀鐵建造 BIF、赤鐵礦礦床、磁鐵礦礦床。礦體可以大到適合露天大規模開採。
第二,鐵礦品位可以很高。鐵礦常見品位是幾十個百分點,比如 55% Fe、62% Fe、65% Fe 這種商品指標。相比之下,銅礦 0.5%--1% Cu 已經可以是大礦,金礦常常是 g/t 級別。這代表一噸鐵礦裡有幾百公斤鐵,而一噸金礦可能只有幾克金。處理成本完全不是一個級別。
第三,鐵的冶煉路線非常成熟。主路線是高爐---轉爐:鐵礦石被還原成生鐵,再煉成鋼。還原劑主要是焦炭/煤,也有直接還原鐵 DRI + 電爐路線。這不是「物理分離」就得到鐵,而是化學還原:把鐵氧化物裡的氧拿走。
第四,鐵礦選礦確實可以利用磁性,但只對部分礦物特別有效。磁鐵礦 magnetite,Fe₃O₄,有強磁性,可以磁選;赤鐵礦 hematite,Fe₂O₃,磁性弱,通常更多靠破碎、篩分、重選、浮選、焙燒磁化等方法;褐鐵礦、菱鐵礦更麻煩。所以「鐵產量最高 = 因為磁性最好分離」這句太窄。
所以銅的邏輯是:不是每噸石頭很富,而是礦體大到可以用露天礦、大型卡車、破碎磨礦、浮選、冶煉,把 0.3%--1% 這種低濃度物質變成可賺錢的工業金屬。有研究總結,斑岩銅礦通常是低品位礦,約 0.2%--1% Cu,但貢獻了全球很大一部分銅供應。ScienceDirect
「缺」要拆成三層。
第一,地殼不缺。銅不是金銀鉑那種極低豐度金屬。它之所以能成為大宗金屬,就是因為自然界確實能形成大型銅礦床。
銅導電性好、延展性好、耐腐蝕,很多地方可以省用量,但不能完全替代。USGS 2025 估計 2024 年全球銅礦產量約 2,300 萬噸,全球銅儲量約 10 億噸;這不是馬上挖完,但新增礦山速度、精礦供應、冶煉產能、環評與政治風險會讓市場緊。U.S. Geological Survey
第一個原因:Slate row 是虛擬化的 UI item,不一定等於完整選擇狀態。
STreeView / SListView 常見做法是只生成當前可見的 row。滾動區外的 item 可能根本沒有對應的 Slate widget。你能掃到的只是"目前畫面上生成出來的 row"。如果 selection 在滾動區外、或 tree 有多選、或 UI 剛刷新,Slate 掃描可能漏掉。
Details Panel 只渲染當前展開、當前可見、當前 selection 對應的屬性。被折疊的、滾動區外的、因 edit condition 隱藏的、或由 custom details customization 動態生成的項目,不一定出現在當前 Slate tree。
圖中的 HOOD 代表的是美國知名線上金融服務公司 羅賓漢(Robinhood Markets, Inc.) ,其在美股的股票交易代碼即為 HOOD 。