文章目录
- 一、修改Chunk数据块大小
-
- [1. 步骤1:连接mongos路由服务](#1. 步骤1:连接mongos路由服务)
- [2. 步骤2:切换至config配置库](#2. 步骤2:切换至config配置库)
- [3. 步骤3:修改chunkSize为64MB](#3. 步骤3:修改chunkSize为64MB)
- [4. 步骤4:查询当前数据块配置](#4. 步骤4:查询当前数据块配置)
- 二、集合分片操作
-
- [1. 预配置Chunk大小为1MB](#1. 预配置Chunk大小为1MB)
- [2. 范围分片](#2. 范围分片)
-
- [2.1 切换数据库](#2.1 切换数据库)
- [2.2 创建集合](#2.2 创建集合)
- [2.3 批量插入数据](#2.3 批量插入数据)
- [2.4 统计文档总数](#2.4 统计文档总数)
- [2.5 创建索引](#2.5 创建索引)
- [2.6 执行分片操作](#2.6 执行分片操作)
- [2.7 查看分片信息](#2.7 查看分片信息)
- [3. 哈希分片](#3. 哈希分片)
-
- [3.1 切换数据库](#3.1 切换数据库)
- [3.2 创建集合](#3.2 创建集合)
- [3.3 批量插入数据](#3.3 批量插入数据)
- [3.4 创建哈希索引](#3.4 创建哈希索引)
- [3.5 执行分片操作](#3.5 执行分片操作)
- [3.6 查看分片信息](#3.6 查看分片信息)
- [4. 删除分片](#4. 删除分片)
-
- [4.1 删除分片](#4.1 删除分片)
- [4.2 迁移数据库主分片](#4.2 迁移数据库主分片)
一、修改Chunk数据块大小
MongoDB 7.0默认Chunk数据块大小为128MB,范围约束:1MB~1024MB;
- 数据增速快:调大chunkSize,减少拆分迁移、提升写入性能
- 分片数据倾斜:调小chunkSize,加快块拆分,便于数据均衡
1. 步骤1:连接mongos路由服务
在任意节点执行客户端连接,路由部署在hadoop2:21020:
shell
mongosh --host hadoop2 --port 27020
2. 步骤2:切换至config配置库
分片全局配置存储在config库,切换数据库:
js
use config
3. 步骤3:修改chunkSize为64MB
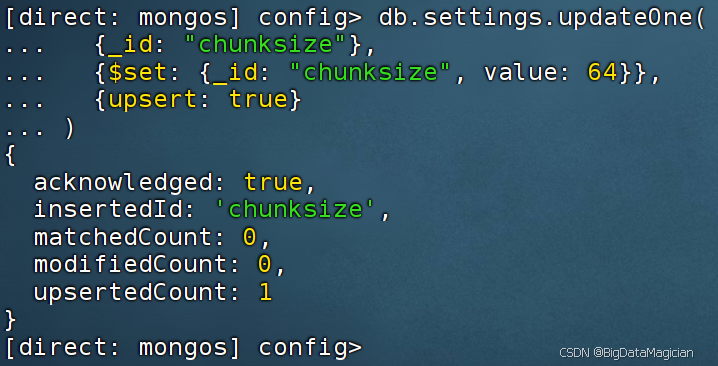
更新settings集合,设置数据块大小:
js
db.settings.updateOne(
{_id: "chunksize"},
{$set: {_id: "chunksize", value: 64}},
{upsert: true}
)
upsert:true:无文档则新增、已有文档则更新。
4. 步骤4:查询当前数据块配置
校验修改结果:
js
db.settings.find({_id: "chunksize"})
二、集合分片操作
默认未分片的集合完整存储在数据库主分片(mongos自动挑选数据量最少分片);MongoDB6.0+首次集合分片时自动开启数据库分片,无需单独对数据库执行分片操作。
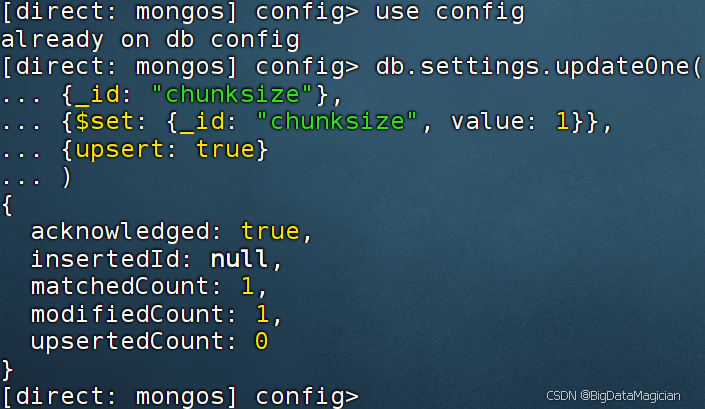
1. 预配置Chunk大小为1MB
调整Chunk大小为1MB,便于自动分片的演示,连接hadoop2:27020的mongos后执行:
js
use config
db.settings.updateOne(
{_id: "chunksize"},
{$set: {_id: "chunksize", value: 1}},
{upsert: true}
)
2. 范围分片
范围分片依据分片键字段数值区间划分 Chunk 数据块,同区间数据落至同一个分片,分片键范围查询可精准路由至单个分片,查询性能优异;本实验选用 age 为分片键,实现按年龄区间拆分数据至 shard1、shard2 两个分片。
2.1 切换数据库
mongosh 环境下切换至目标业务库 mydb,后续所有集合操作均在当前库执行。
js
use mydb
2.2 创建集合
新建空集合 users,提前定义分片承载对象,分片操作依赖已存在的目标集合。
js
db.createCollection('users')
2.3 批量插入数据
使用无序批量写入对象高效批量插入 50000 条测试文档,充足数据量可触发 MongoDB 自动拆分 Chunk,验证分片数据切割效果;age 字段随机 18~77,满足按年龄范围分片的数据条件MongoDB。
js
const bulk = db.users.initializeUnorderedBulkOp();
for (let i = 1; i <= 50000; i++) {
bulk.insert({
username: `user${i}`,
age: Math.floor(Math.random() * 60) + 18,
gender: Math.random() > 0.5 ? 'Male' : 'Female',
height: Math.floor(Math.random() * 60) + 150,
weight: Math.floor(Math.random() * 50) + 50
});
}
bulk.execute();
2.4 统计文档总数
校验批量插入结果,确认 5 万条数据完整入库,保证分片前数据基数达标。
js
db.users.find().count()
2.5 创建索引
非空集合执行分片前,必须提前建立分片键索引,索引字段需与分片键完全一致;创建 age 升序索引并自定义索引名 ageIndex,为后续范围分片提供索引支撑MongoDB。
js
db.users.createIndex({age: 1},{name: 'ageIndex'})
2.6 执行分片操作
sh.shardCollection()为集合分片核心命令,mydb.users为集合全限定名,{age:1}代表以 age 字段做升序范围分片;索引就绪后执行该命令,config 服务生成分片元数据,均衡器自动拆分 Chunk 并分配至各分片。
js
sh.shardCollection("mydb.users", {age: 1})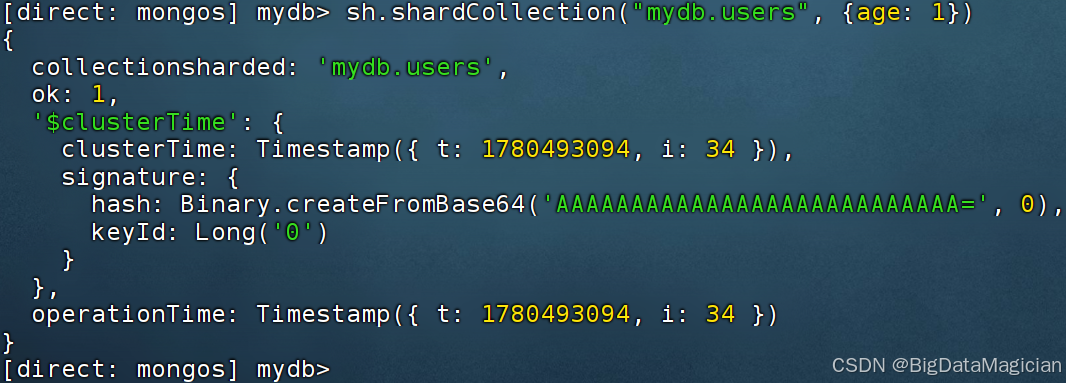
2.7 查看分片信息
sh.status()查看分片集群全局元数据,可查看数据库分片开关、集合分片键、Chunk 区间分布、各分片承载数据块数量,用于校验范围分片是否生效、数据拆分边界是否符合规则。
js
sh.status()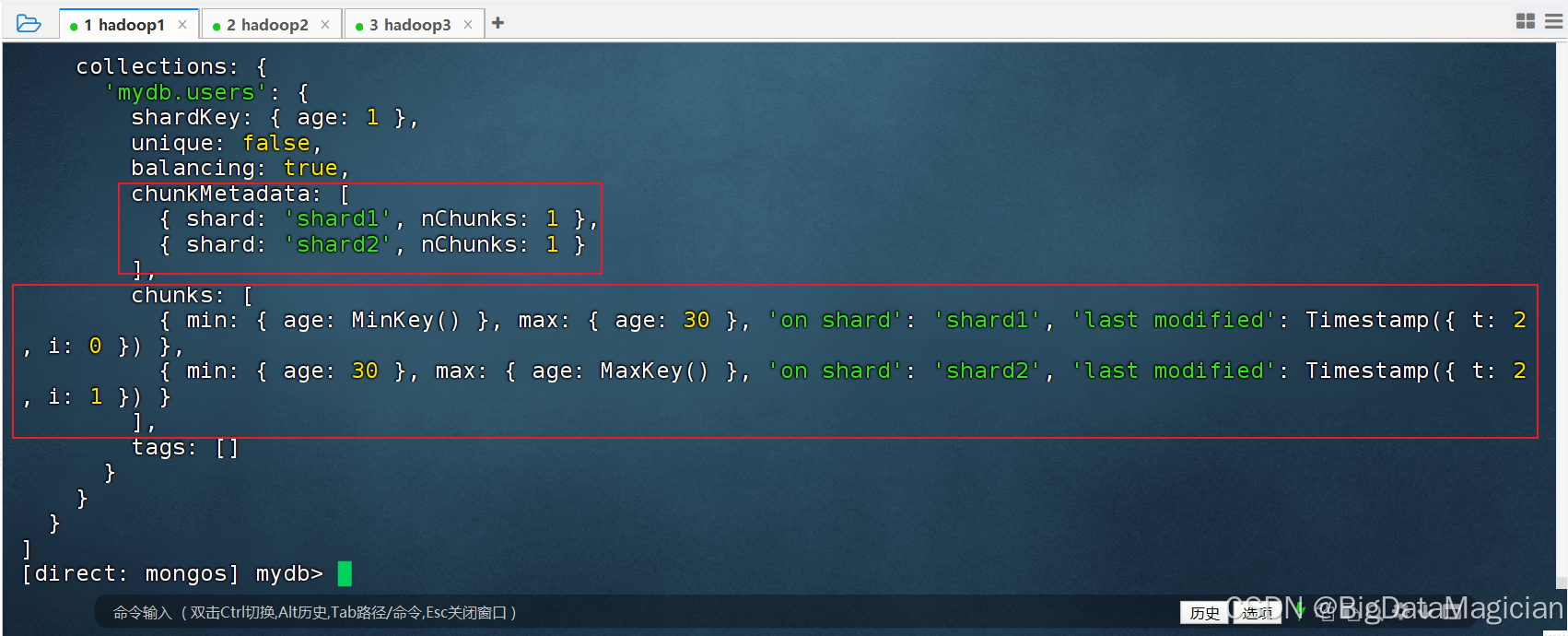
3. 哈希分片
哈希分片对分片键值进行哈希运算后划分 Chunk,数据随机均匀打散至所有分片,有效规避范围分片的数据倾斜、写入热点问题;缺点是分片键范围查询会全分片广播,查询效率偏低MongoDB,本实验基于 age 哈希分片对比范围分片差异。
3.1 切换数据库
复用 mydb 数据库,新建独立集合 users1 用于哈希分片实验,和上方范围分片 users 做对照。
js
use mydb
3.2 创建集合
创建全新集合 users1,隔离实验数据,避免与 users 集合数据互相干扰。
js
db.createCollection('users1')
3.3 批量插入数据
同 users 插入逻辑,批量写入 50000 条异构测试数据,保证数据体量满足 Chunk 自动分裂条件,直观体现哈希分片均匀打散数据的特性。
js
const bulk = db.users1.initializeUnorderedBulkOp();
for (let i = 1; i <= 50000; i++) {
bulk.insert({
username: `user${i}`,
age: Math.floor(Math.random() * 60) + 18,
gender: Math.random() > 0.5 ? 'Male' : 'Female',
height: Math.floor(Math.random() * 60) + 150,
weight: Math.floor(Math.random() * 50) + 50
});
}
bulk.execute();
3.4 创建哈希索引
哈希分片要求分片键字段建立hashed类型专用索引,区别于范围分片普通升序索引;非空集合必须预先创建哈希索引,才可执行分片命令。
js
db.users1.createIndex({age: "hashed"})
3.5 执行分片操作
{age:"hashed"}标识采用哈希分片策略,MongoDB 内部自动计算 age 字段哈希值、分配 Chunk 至各分片,无需人工划定数值区间。
js
sh.shardCollection("mydb.users1", {age: "hashed"})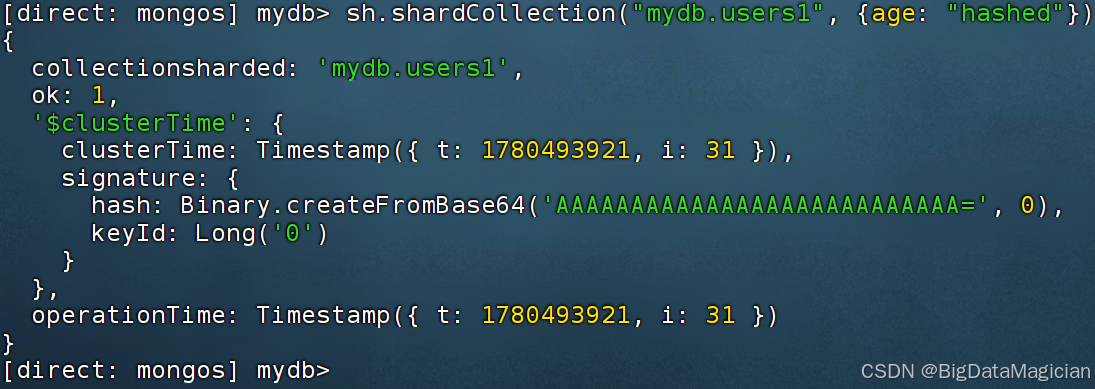
3.6 查看分片信息
查看哈希分片 users1 的分片元数据;通过 sh.status 查看哈希分片的 Chunk 分布,对比 users 范围分片的数据分布规律差异。
js
sh.status()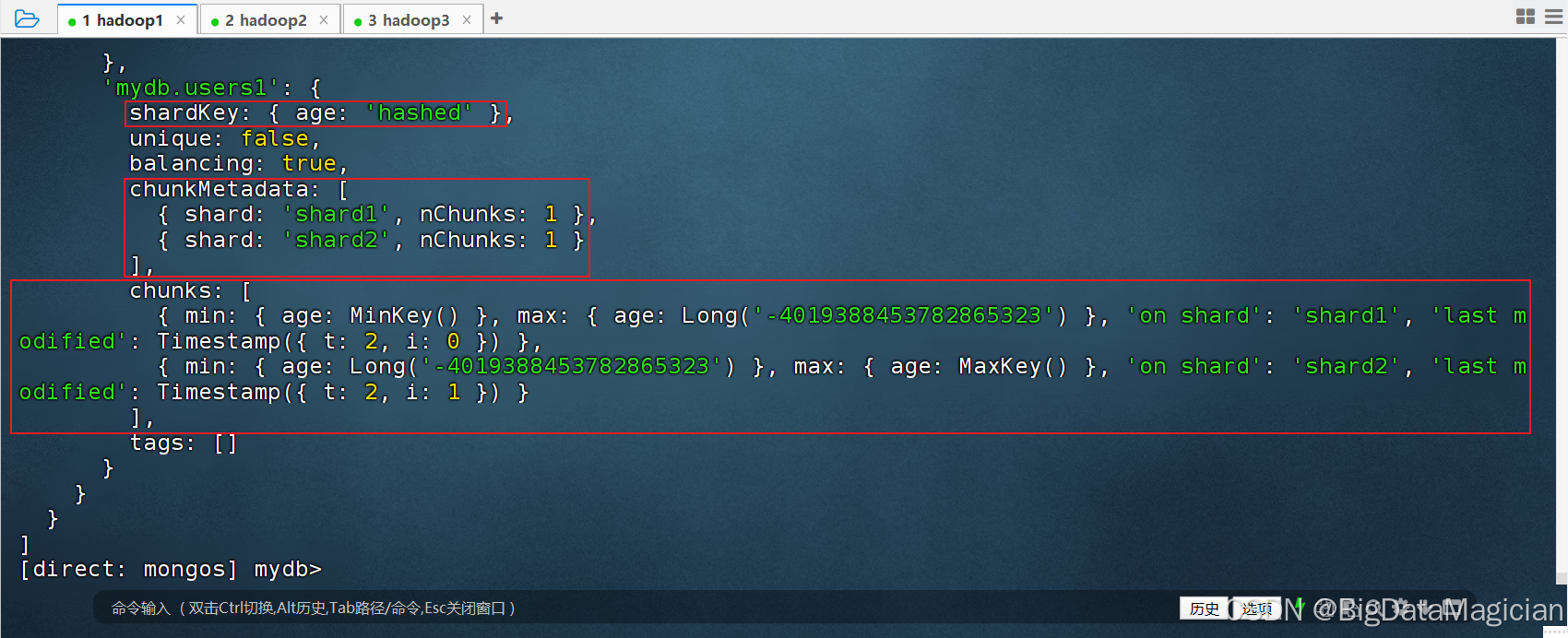
4. 删除分片
删除分片是集群缩容操作,removeShard为异步指令,均衡器后台自动迁移分片内所有 Chunk 至其余分片;若待删分片是某数据库主分片(Primary Shard),需先行迁移主分片再执行删除,否则命令报错无法执行MongoDB。
4.1 删除分片
removeShard:"shard"中 shard 替换为实际分片副本集名称;命令提交后后台自动数据搬迁,重复执行该命令查看搬迁进度,直至状态为 completed 才算分片移除成功。
js
db.adminCommand({removeShard: "shard"})4.2 迁移数据库主分片
每个数据库默认绑定一个主分片,主分片存储库内所有未分片集合;待删分片绑定主分片时,通过movePrimary变更库的主分片指向,仅修改 config 元数据、不迁移存量数据;database 替换库名、to 填写目标可用分片名称,主分片迁移完成后才可正常删除分片。
js
db.adminCommand({movePrimary: "database", to: "shard"})