JVM线程同步机制
-
- [1、Mark Word](#1、Mark Word)
-
- [1.1、Mark Word详解](#1.1、Mark Word详解)
- 1.2、hashCode验证
- 1.3、轻量级锁的状态信息
- 1.4、重量级锁的状态信息
- 2、synchronized设计原理
- 3、synchronized源码分析
- 4、volatile实现原理
- 5、volatile伪共享
- 6、CAS硬件同步原语
-
- 6.1、CAS硬件原语
- [6.2、JVM CAS实现](#6.2、JVM CAS实现)
- 6.3、ABA问题
- 7、Unsafe功能介绍
- 8、Unsafe实现原理
- 9、LockSupport实现原理
Java提供了3种基础的线程同步方式:synchronized、volatile与CAS(Compare And Swap)硬件原语。synchronized是通过内置的对象锁来实现线程间的同步,具备原子性、可见性、有序性。volatile是一种轻量级同步机制,它只保证了可见性与有序性,但无法保证原子性。CAS采用了无锁的原子操作来实现线程同步,避免加锁带来的笨重性。
1、Mark Word
在JVM中,Java对象是用OOP(Ordinary ObjectPointer,普通对象指针)表示的。OOP的数据结构可以分为两部分:一部分是对象的基本信息,另一部分是对象的属性信息。OOP对应的实现类是oopDesc,具体定义 如代码所示。
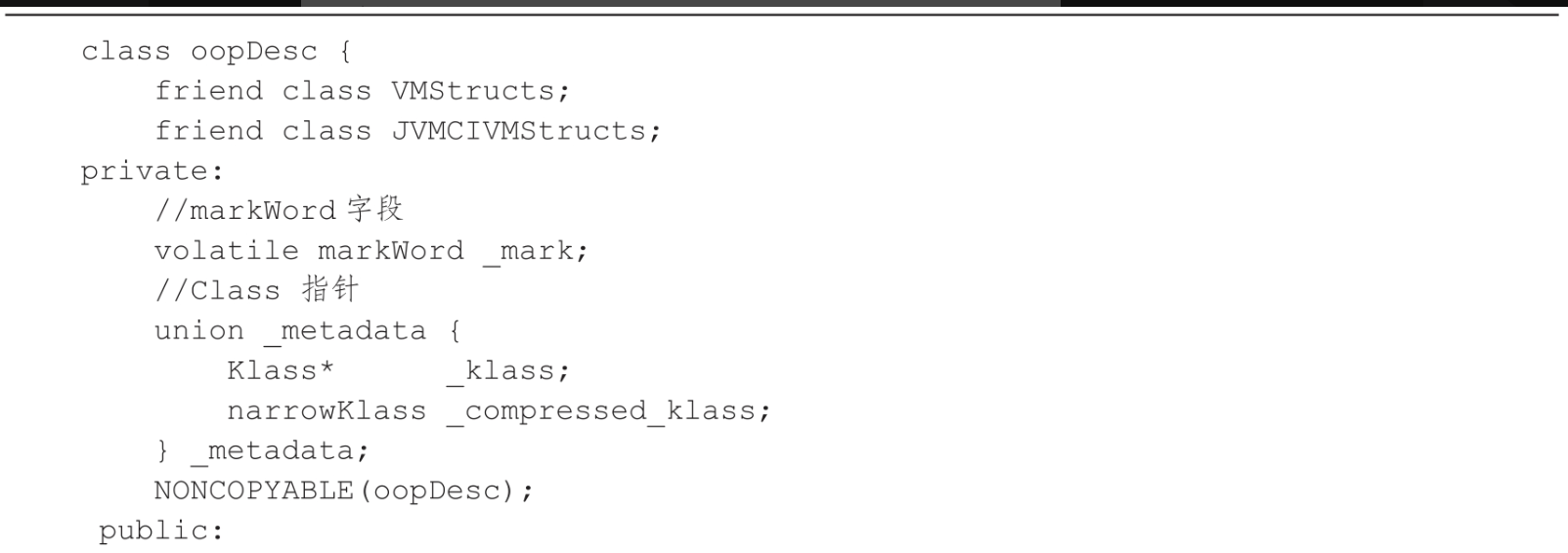

oopDesc内部主要包含markWord、Class指针、对象数据、对齐补充四个部分。markWord是对象的数字化标识,主要是为对象比较、垃圾回收、并发控制的功能服务的。Class指针是指向对象的Class(其对应的元数据对象)内存地址。对象数据包括了对象的所有成员变量,其大小由各个成员变量的大小决定。比如byte和boolean是1字节,short和char是2字节,int和float是4字节,long和double是8字节,reference是4字节。对齐补充确保对象的数据大小能够被8整除,如果不能被8整除,padding则补齐占用空间,使之能被8整除。这样做可以提高内存寻址的效率。
1.1、Mark Word详解
从下面代码中可以看出,Mark Word的值是64位无符号的整型,相当于Java语言的long。那么一个数值怎么表示多个状态呢?其实是把long转换成一个64位的bit数组,然后用每个bit数组中的0、1来表示对应的状态。

Mark Word的头两位用来表示当前对象的状态,两位只能表示4种状态:00、01、10、11。在Mark Word中,用01来表示无锁或者偏向锁的两种状态,00表示轻量级锁,10表示重量级锁,11表示垃圾回收时的引用标志。MarkWord的整个状态表示如图所示。
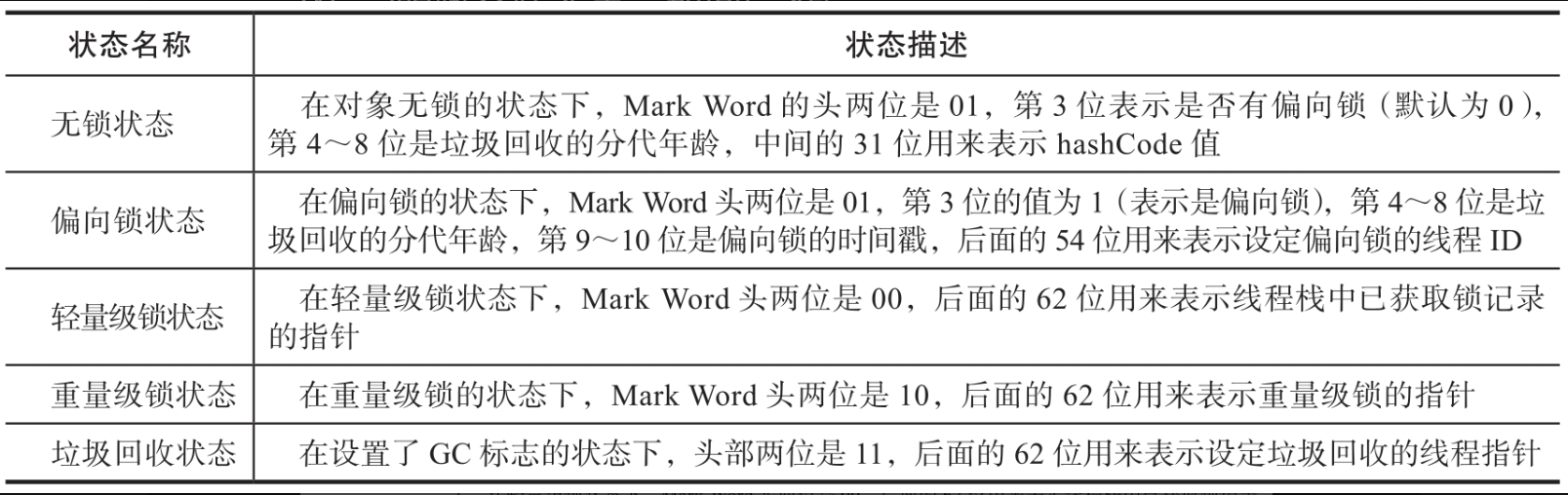
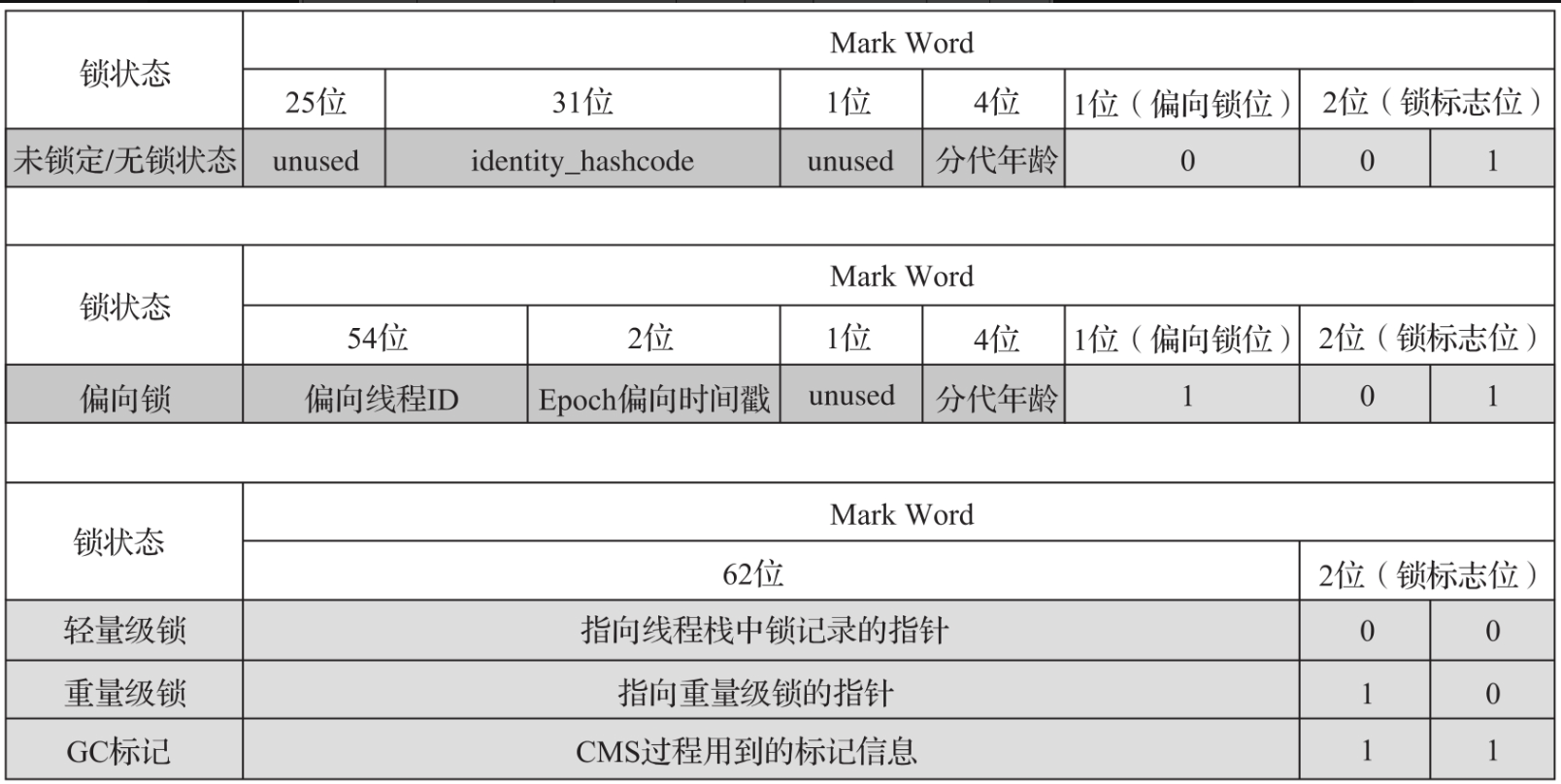
各个锁状态的详细信息如表所示。
1.2、hashCode验证
下面代码是简单的示例,用来验证Mark Word在无锁状态下的hashCode值。在该示例中,首先打印对象的Mark Word值,然后调用hashCode方法来设置Hash值,最后再次打印对象的Mark Word值。

代码执行的结果如表所示。

在调用hashCode方法后,Mark Word的值是1945571841,对应的二进制是11100111 1110111 0001001000000001,Mark Word的最后两位是01,表示处于无锁的状态,后面都是hashCode的值。
1.3、轻量级锁的状态信息
下面代码是简单的轻量级锁的示例,用来验证MarkWord在轻量级锁状态下的值。

代码执行的结果如表所示。

在获取轻量级锁之后,Mark Word值是205810064,对应的二进制数是110001000 1000110100110010000, Mark Word的最后两位从最初的01变成了00,后面的数字都是当前线程的指针地址。
1.4、重量级锁的状态信息
如下代码是简单的重量级锁的示例,用来验证MarkWord在重量级锁状态下的值。


代码模拟了多个线程利用synchronized关键字同步加锁的情况。从上述代码中可以看到主线程处于等待状态,详细信息如表所示。

在获取轻量级锁之后,Mark Word的值是71690680,二进制是100010001011110 100110111000,Mark Word的最后两位从最初的01变成了00。在获取重量级锁之后,Mark Word的值是-645868214,二进制是1111111111111111111111111111111111011001100000001101010101001010,Mark Word的最后两位从最初的01变成了10。
2、synchronized设计原理
synchronized关键字是Java的内置同步锁,实现了多线程的同步访问。synchronized可以用在方法或者代码块上。它确保在同一时刻,只有一个线程可以执行被synchronized保护的方法或代码块。synchronized有3个特性:原子性、可见性、有序性。
- 原子性
原子性就是指一个操作或者多个操作,要么全部被执行并且执行过程不会被打断,要么就都不会被执行。被synchronized修饰的方法或者代码块都是原子的,因为在执行操作之前必须先获得类或对象的锁,直到执行完才能释放对象锁。通过锁的机制实现了多线程操作的原子性。 - 可见性
可见性是指当多个线程同时访问一个数据时,其中一个线程对数据的修改对其他线程实时可见。在任何一个时刻,只有一个线程能获得同步的(synchronized)对象锁,而锁的状态对其他任何线程都是实时可见的,并且在释放锁之前会将当前线程对变量的修改同步到主内存中,保证数据修改的多线程可见性。 - 有序性
synchronized具备有序性,Java允许编译器和处理器对指令进行重排,但是指令重排并不会影响单线程的逻辑顺序,它影响的是多线程并发执行的顺序性。synchronized可以确保任意一个时刻只有一个线程可以访问同步代码块,这就确保了代码执行的有序性。
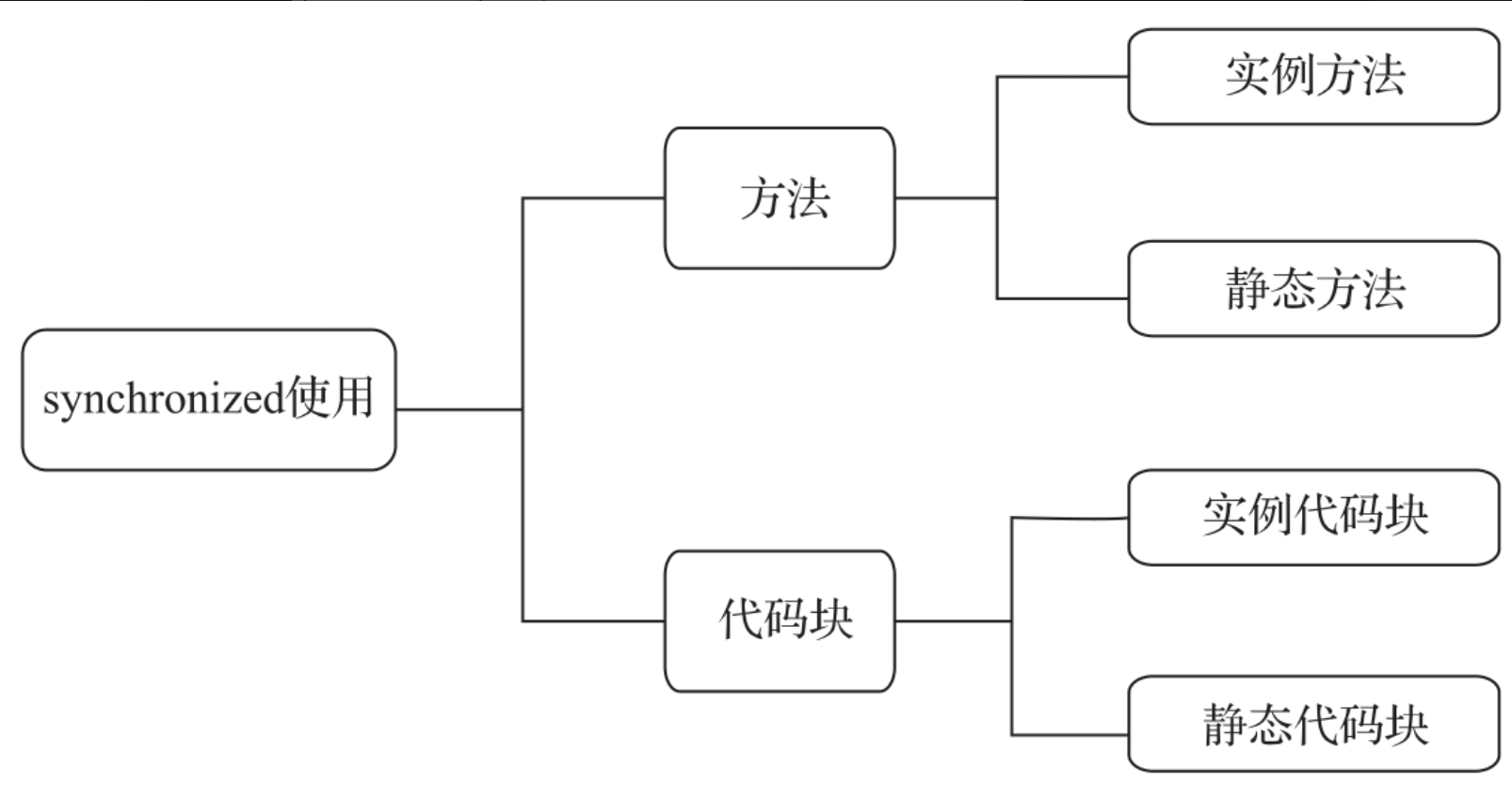
2.1、synchronized的使用
synchronized关键字有两种用法:
- 一种是用于同步方法
- 另一种是用于同步代码块
同步方法又分为两种情况:
- 一种是用synchronized同步普通方法
- 另一种是用synchronized同步静态方法。
同步代码块也分为两种情况:
- 一种是用synchronized修饰的是对象实例的锁
- 另一种是用synchronized修饰的是类对象的锁。
synchronized的具体使用场景如图所示。
1. 同步方法的实现机制
如下代码是一个简单示例,用来演示synchronized在方法上的并发控制,即用synchronized修饰synMethod方法。
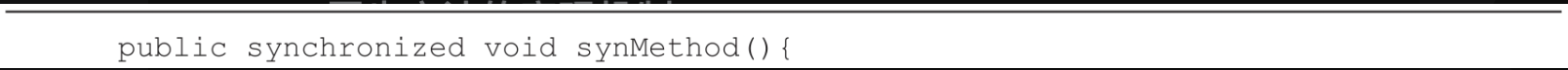

在完成代码编译后,我们可以通过javap- c xxx.class文件来查看Java编译后的字节码文件。synMethod方法的字节码内容如下方代码所示,synMethod方法的flags字段上增加了ACC_SYNCHRONIZED并发控制标志。JVM在执行synMethod方法的时候,首先会判断是否有ACC_SYNCHRONIZED标志,如果有并发控制标志,则JVM会先调用方法获取锁对象。

2. 同步代码块的实现机制
下方代码是一个简单示例,用来演示synchronized在代码块上的使用。

通过javap- c xxx.class文件,我们可以清晰地看到编译后的字节码内容。下方代码是synCode方法的字节码,synchronized的关键字编译成了monitorenter指令和monitorexit的指令。JVM就是通过这两条指令建立一段串行代码的执行区域,在同一时刻,只有一个线程能执行这个区域的代码。


2.2、synchronized的具体设计
为了减少synchronized获得锁和释放锁带来的相关性能消耗,JDK 1.6引入了"偏向锁"和"轻量级锁"的概念。synchronized内置锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几种状态会随着竞争情况逐渐升级,如图所示。

锁可以升级但不能降级,目的是提高获得锁和释放锁的效率。
无锁状态表示对象是空闲状态,不存在线程对对象的竞争。
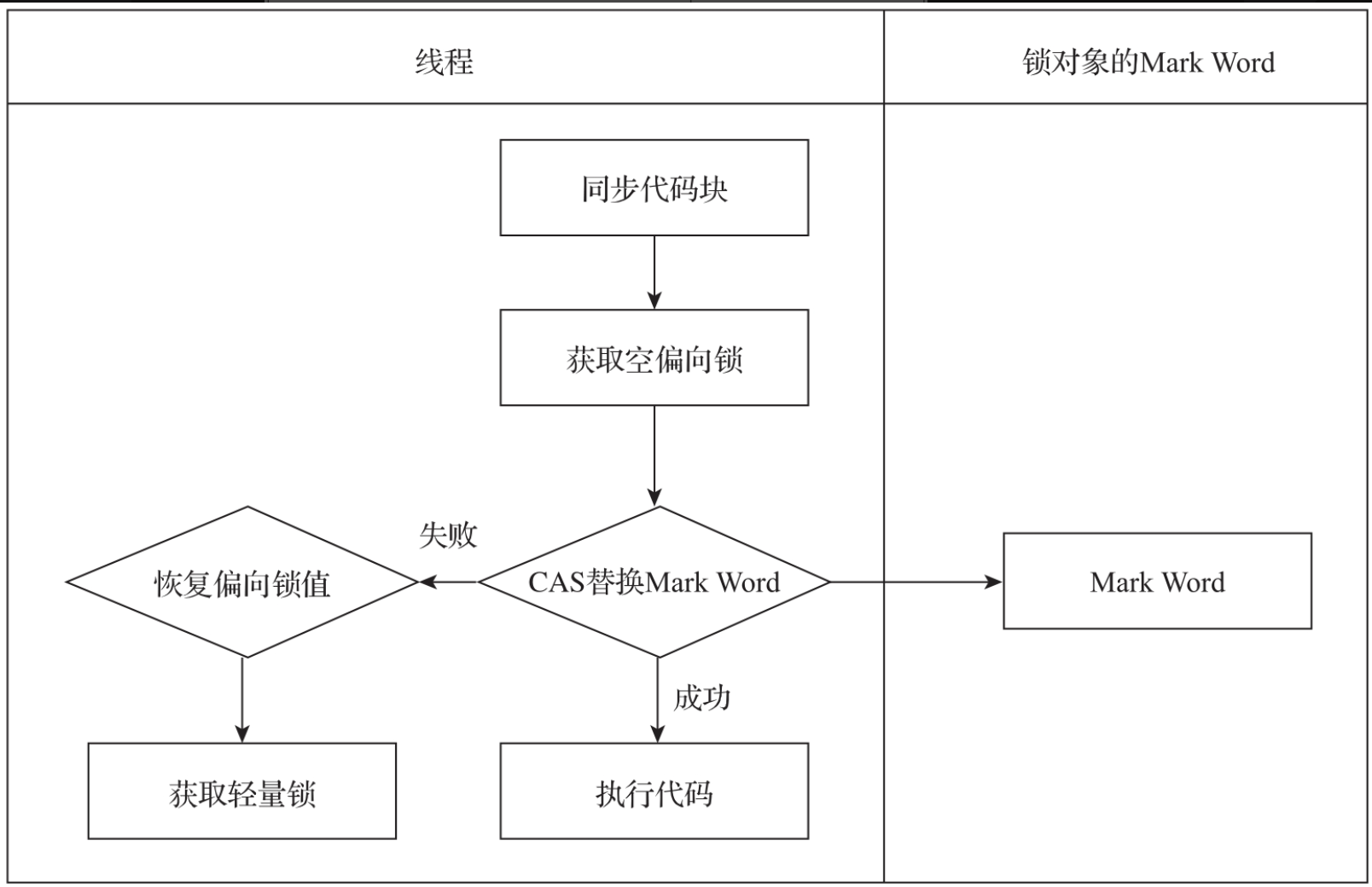
偏向锁主要用来优化同一线程多次申请同一个锁的情况。在很多场景中,大部分时间一个锁都是被一个线程所持有。偏向锁的加锁整个过程只用修改对象的Mark Word值,重点是将偏向锁的标志0改成1,并将当前的线程ID设置到Mark Word中的线程ID字段,原来Mark Word中的年龄等字段保持不变。具体修改过程是,基于已有的Mark Word年龄、偏向锁状态、线程ID等参数构造一个新的Mark Word,然后采用CAS机制整体替换掉老的。偏向锁的获取流程如图所示。
如果JVM没有开启偏向锁或偏向锁获取失败,会直接升级到轻量级锁的获取。轻量级锁的获取流程如图所示,具体处理流程如下。
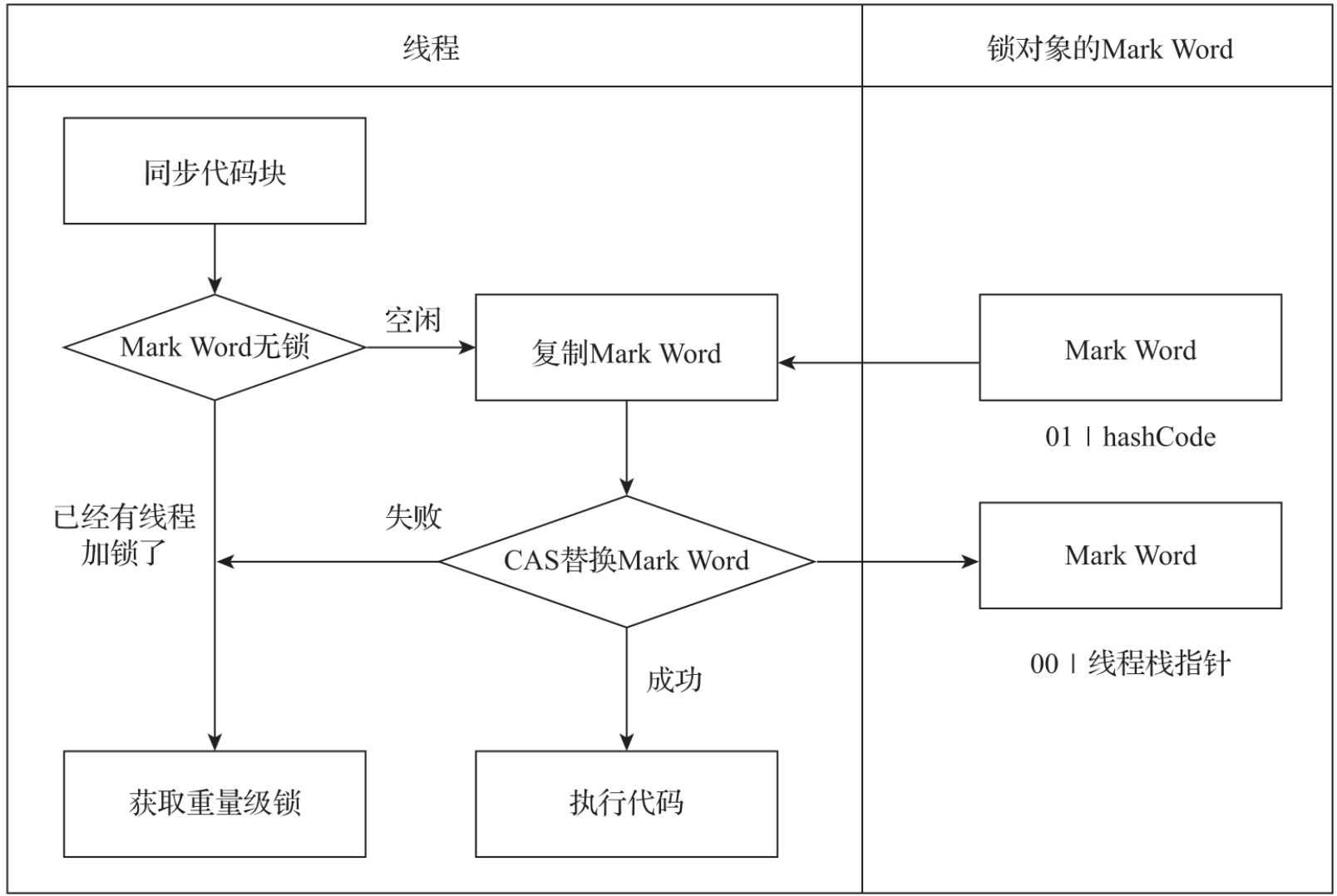
- 首先判断锁对象的Mark Word是否空闲,如果不空闲直接获取重量级锁。
- 如果对象的Mark Word是空闲的,将Mark Word复制备份。
- 将对象的Mark Word的头两位设置成00,并将线程栈中锁记录的指针复制到Mark Word的后62位中。
- 通过CAS的方式更新Mark Word,如果CAS修改失败,线程将会进入重量级锁的竞争。
当在轻量级锁获取失败之后就会升级到重量级锁的竞争。重量级锁整体是通过Object-Monitor来实现的。重量级锁的获取流程如图所示。
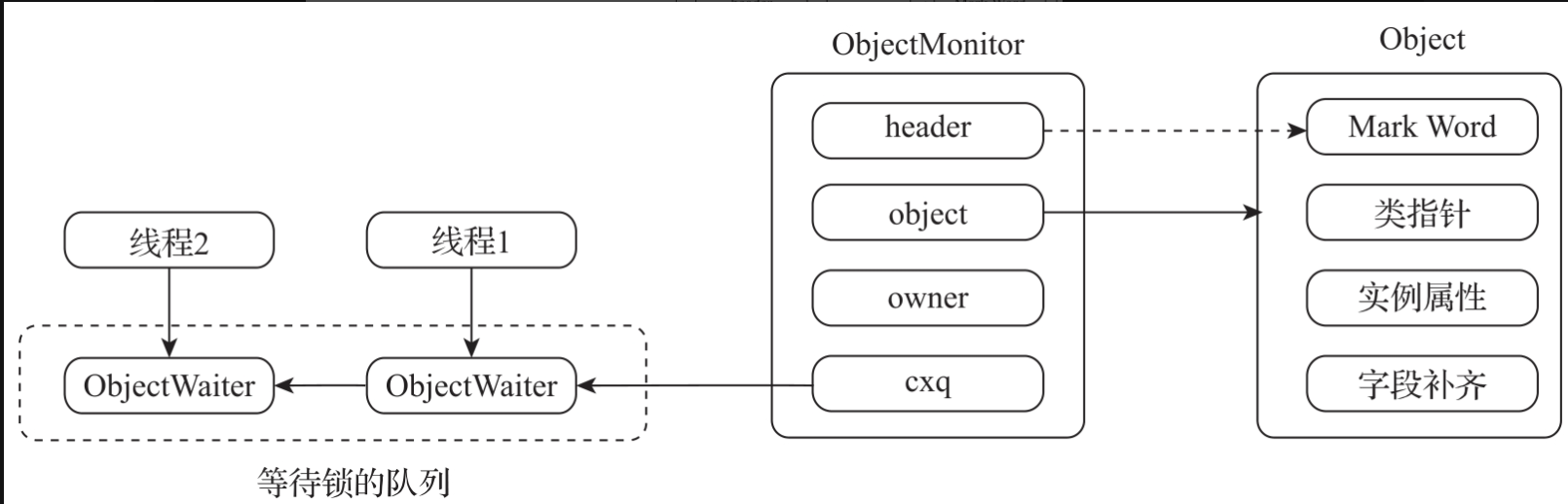
synchronized重量级锁的获取流程如下。
- 尝试快速获取监视器锁,如果成功获取到锁,将ObjectMonitor的owner字段指向当前线程。
- 如果获取监视器锁失败,将当前线程加入cxq队列中进行等待。其他线程释放锁之后,会尝试唤醒当前线程继续来获取锁。
3、synchronized源码分析
在代码编译的时候,方法上的synchronized关键字会被编译成ACC_SYNCHRONIZED标志,代码块上的synchronized关键字会被编译成monitorenter指令和monitorexit指令。
3.1、ACC_SYNCHRONIZED解析过程
bytecodeInterpreter是JVM执行引擎的编译器,主要用于解释并执行字节码。当发现方法上有ACC_SYNCHRONIZED标志,bytecodeInterpreter会获取监视器锁。在获取到监视器锁之后,才会执行方法。ACC_SYNCHRONIZED标志的解析流程如图所示。
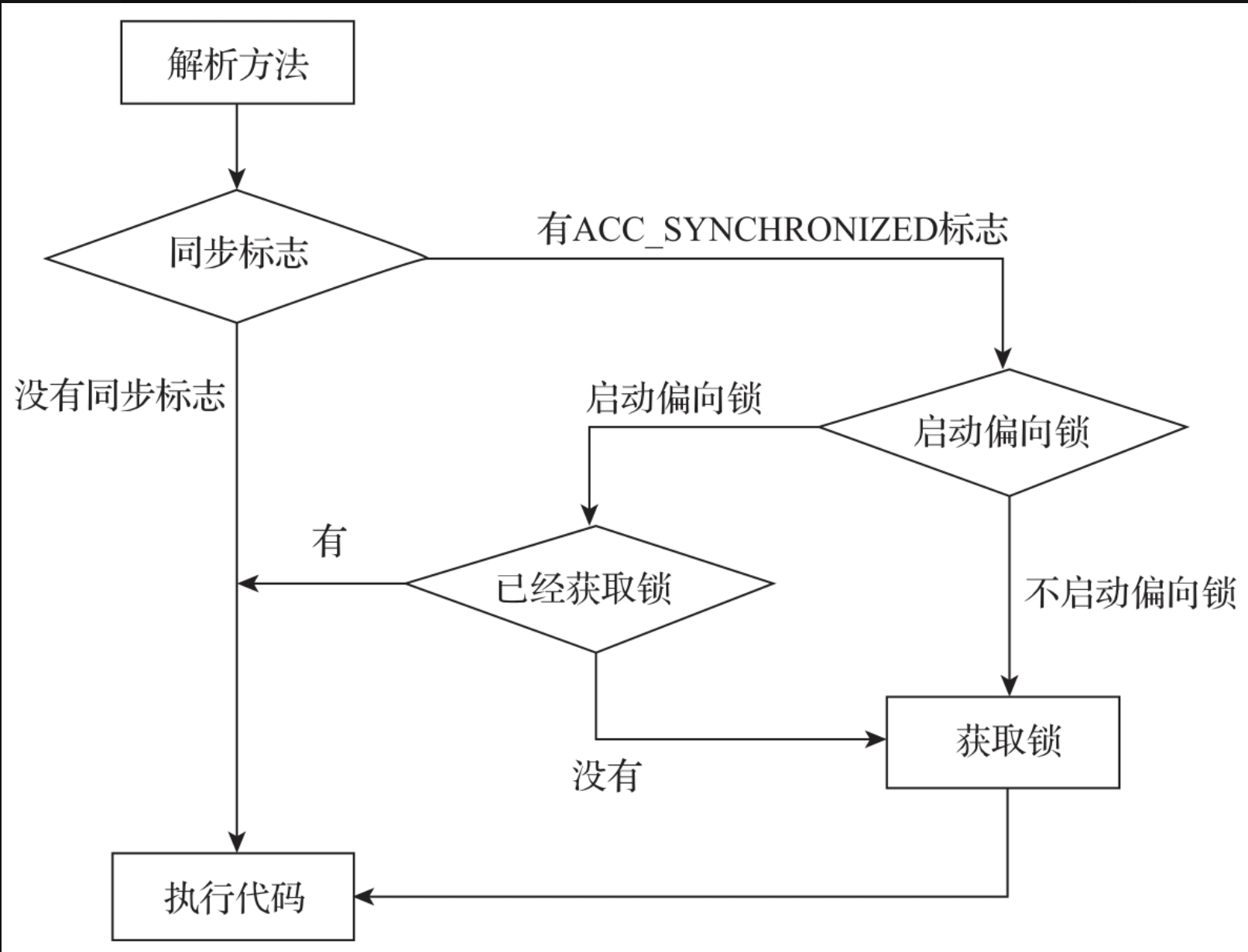
ACC_SYNCHRONIZED标志的具体解析过程如代码所示。


3.2、monitorenter指令解析过程
bytecodeInterpreter会将monitorenter指令解析成获取对象锁的执行逻辑,流程如图所示。
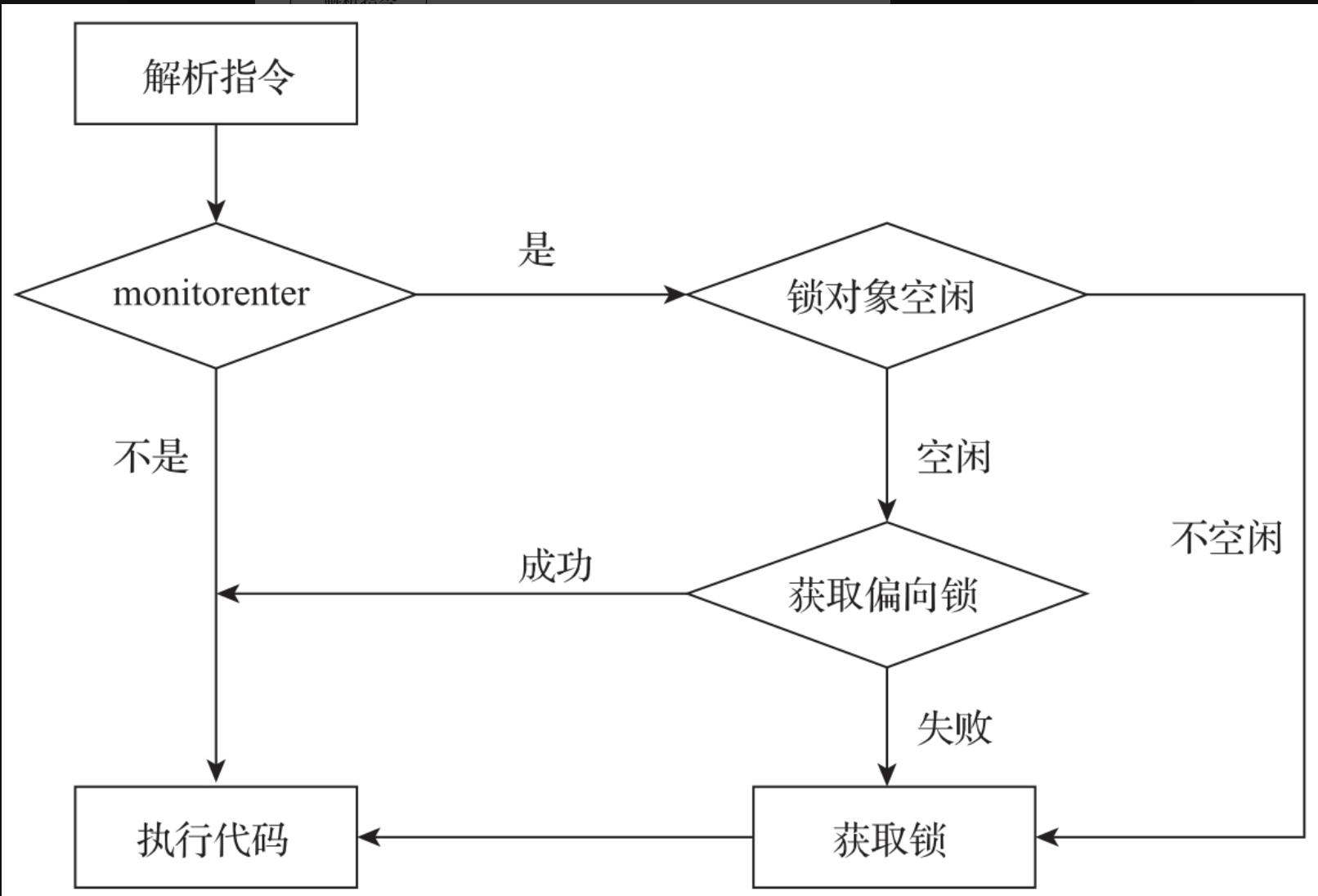
monitorenter指令的执行过程如代码所示。
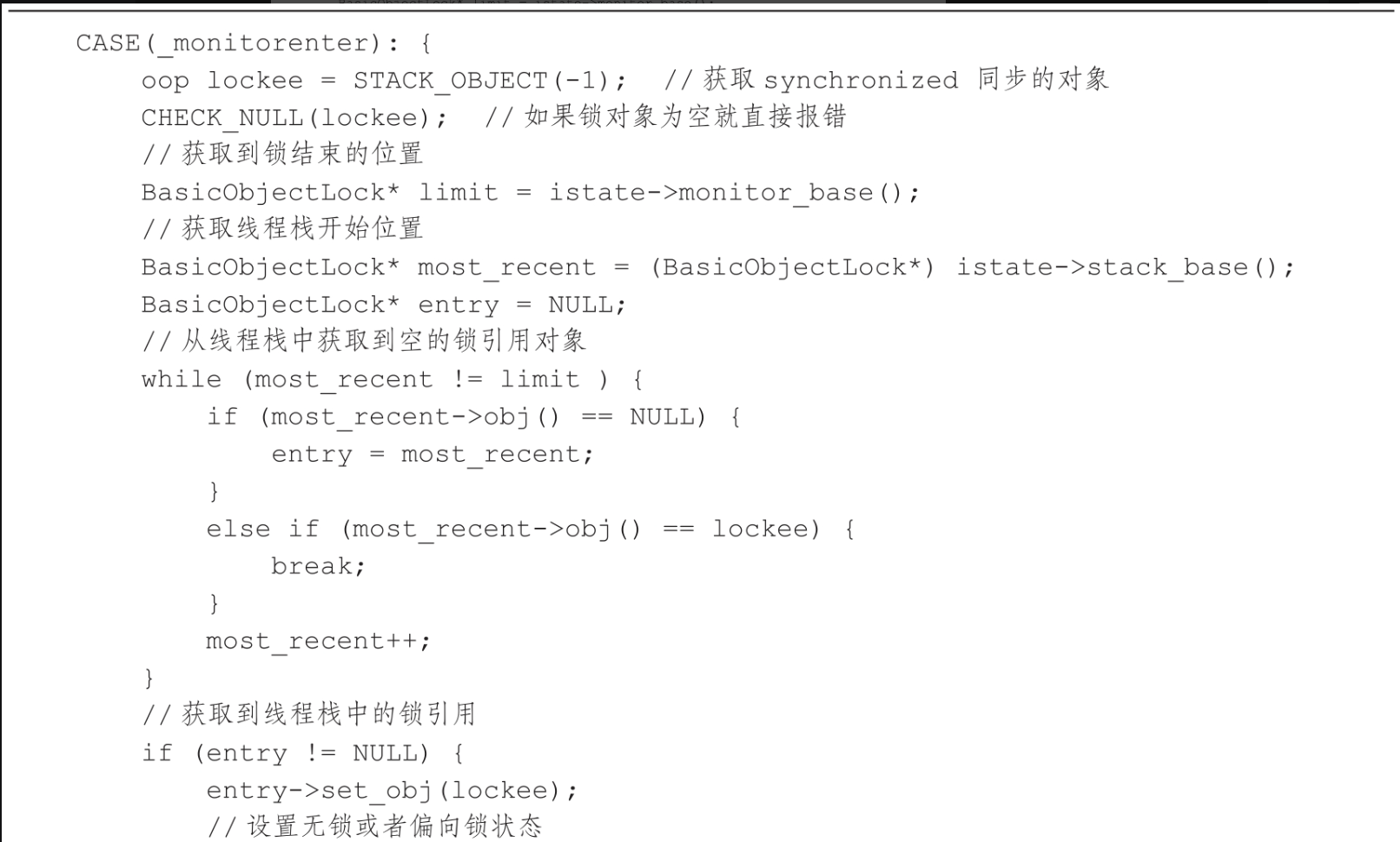

monitorenter指令的执行过程如下。
- 从栈的底部寻找空闲的偏向锁指针,将偏向锁指向锁对象。
- 尝试获取偏向锁,如果获取成功了执行代码。
- 如果偏向锁获取失败了,则调用InterpreterRuntime的monitorenter方法通过排队机制获取对象锁。
3.3、monitorexit指令解析过程
bytecodeInterpreter会将monitorexit指令翻译成锁释放的执行逻辑。monitorexit指令的解释过程如代码所示。


3.4、锁获取实现过程
由前可知,不论是ACC_SYNCHRONIZED方法标志,还是_monitorenter指令最终都是通过InterpreterRuntime类的monitorenter方法来获取锁的。InterpreterRuntime类的monitorenter方法逻辑也非常简单,就是调用ObjectSynchronizer类的enter方法来获取对象锁,具体实现如代码所示。

1. enter方法
enter方法是获取监视器锁的入口方法。enter方法的处理流程如下。
- 判断是否启用了偏向锁:如果启用了偏向锁,则尝试获取偏向锁;如果没有启用偏向锁,则获取轻量级锁。
- 判断对象是否处于无锁状态,如果处于无锁状态,则尝试获取轻量级锁。如果对象已经有锁了,则判断锁是否由当前线程持有,如果是由当前线程持有,则属于锁重入的情况,直接返回。
- 如果无法获取轻量级锁,则调用inflate方法获取ObjectMonitor对象,然后调用ObjectMonitor的enter方法来获取重量级锁。

2. inflate方法
inflate方法的功能是获取ObjectMonitor对象,其实现细节如代码所示。


多线程同时获取对象监视器ObjectMonitor,可能会遇到如下几种情况。
- 如果其他线程已经获取到ObjectMonitor,则当前线程就直接返回其他线程构造的ObjectMonitor对象。
- 如果其他线程正在获取ObjectMonitor对象的过程中,则当前线程要进行避让,以免发生并发冲突。
- 如果其他线程获取了轻量级锁,则当前线程会构建一个新ObjectMonitor对象,并把ObjectMonitor对象的持有线程设置成其他线程。
- 如果其他线程已经释放了对象锁,那么当前线程构造一个新的ObjectMonitor对象。
3.5、锁释放实现过程
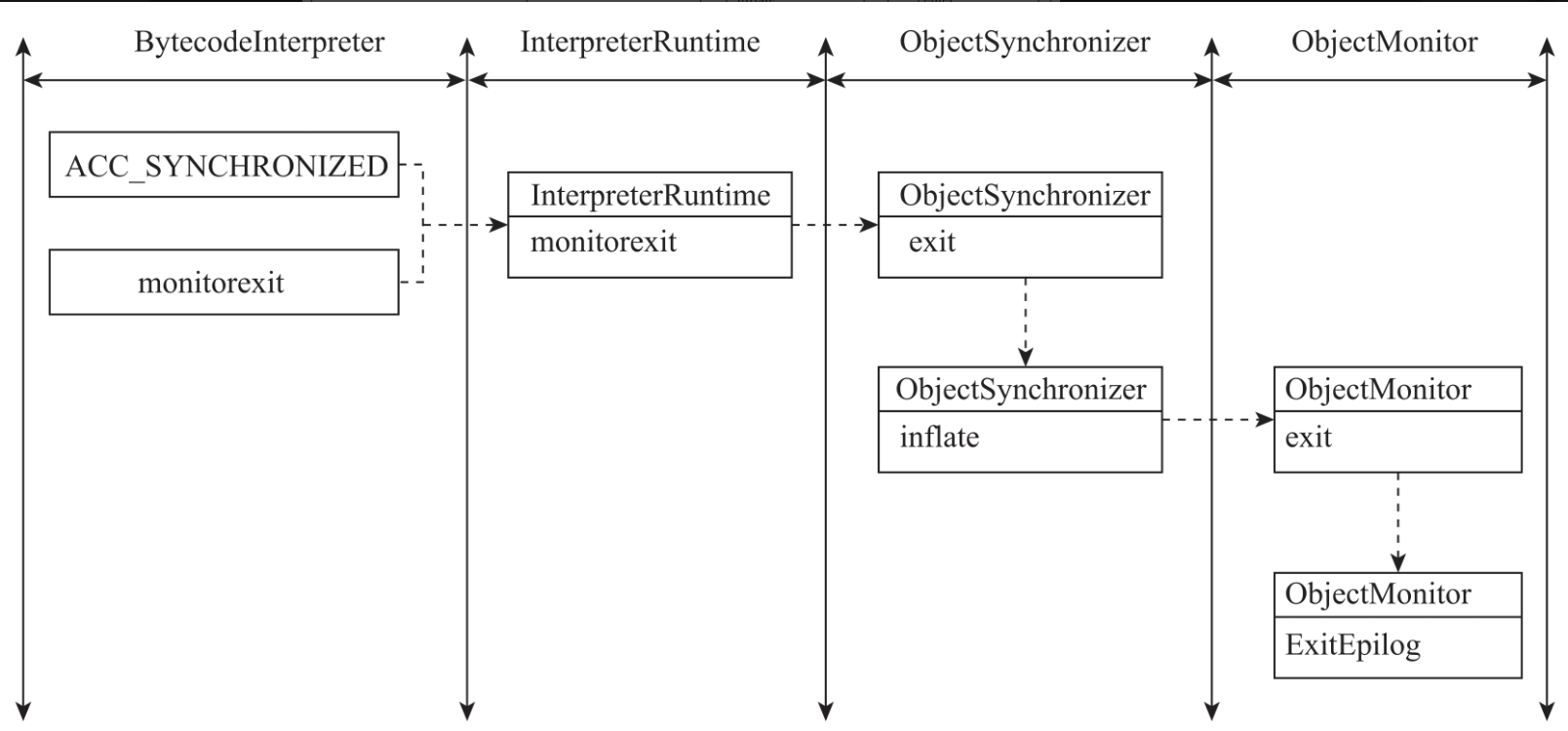
InterpreterRuntime的monitorexit方法的功能是完成锁的释放。从下面代码中可以清晰地看到,monitorexit方法是通过ObjectSynchronizer的exit方法来实现锁释放逻辑的。

ObjectSynchronizer的exit方法首先会判断锁是否已经释放了,如果已经释放了就直接返回。如果锁没有释放,exit方法会调用ObjectMonitor的exit方法来释放监视器锁。exit方法的具体实现如代码所示。

下面进行简单总结。在编译阶段,javac编译器会将synchronized关键字编译为ACC_SYNCHRONIZED标记、monitorenter指令、monitorexit指令。
在代码执行阶段,JVM会把ACC_SYNCHRONIZED标志与monitorenter指令解析成获取对象锁的逻辑,并调用InterpreterRuntime的monitorenter方法来获取对象锁。锁获取的过程如图所示。
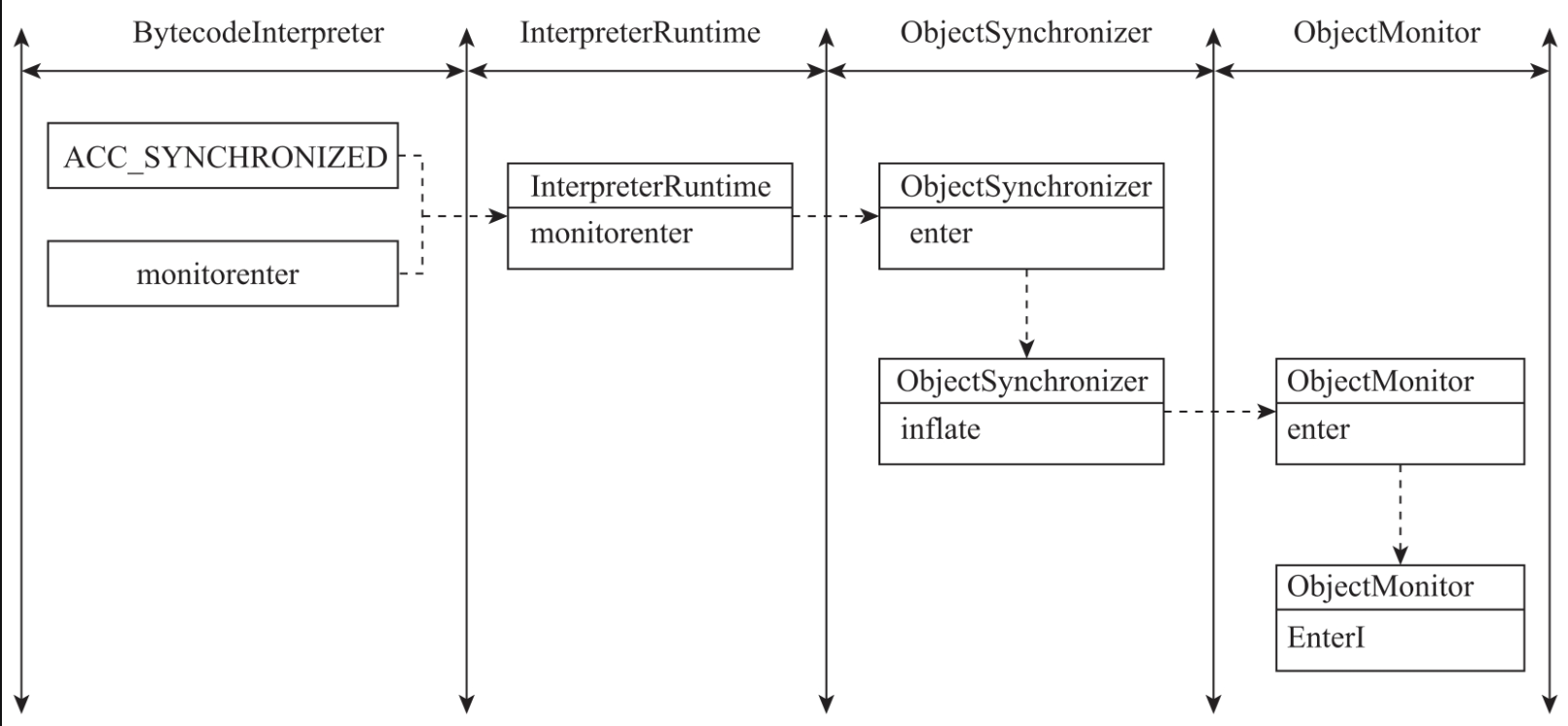
在代码执行结束的时候,JVM会把ACC_SYNCHRONIZED标记与monitorexit指令解析成释放锁的逻辑,并调用InterpreterRuntime的monitorexit方法来释放锁。锁释放的过程如图所示。
4、volatile实现原理
volatile是一种轻量级线程同步机制,它只保证了可见性与有序性,但无法保证原子性。相比synchronized,volatile有一些自身的优势,使用比较简单,并且运行的效率也比synchronized更高。
每个Java线程都拥有一个独立的工作内存,同时有个全局内存(堆内存)来存储数据。当线程需要访问一个变量时,首先将其复制到线程的工作内存中。之后,线程每次对该变量的操作都将是对线程栈中的副本进行操作的。如果变量是被volatile修饰的,每次变量都会直接从内存中读取数据,每次对变量修改都会实时同步到内存中,这样就能确保变量的多线程实时可见。
volatile对任意变量的读写都具备原子性,但对复合操作不具备原子性。所有基础类型与引用类型的赋值都是原子性的,但JVM会将i++这类复合操作解析成多条指令来执行,所以不是原子操作。
4.1、实现原理概述
如下代码是一个简单的例子,用来演示volatile的功能。VolatileTest类里定义了一个volatile的size字段,然后写了一个简单的方法让size进行了加1操作。

Java文件在编译之后会生成字节码文件,可以通过javap来查看字节码文件,并通过javap-v-p VolatileTest.class命令解析出字节码文件的内容,详细信息如代码所示。
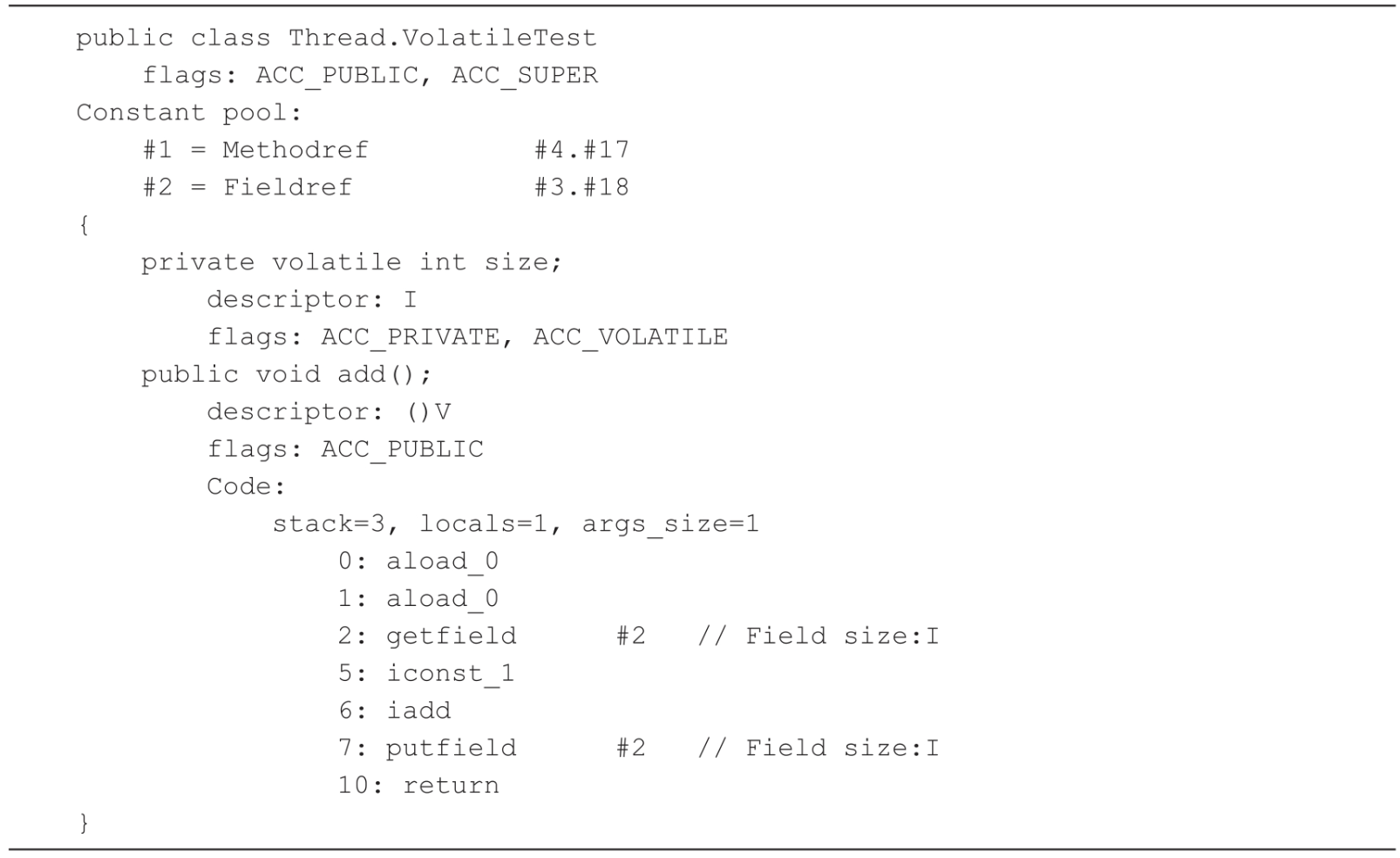
字节码内容包含常量池、字段定义、方法定义、方法内容等信息。size字段有ACC_PRIVATE、ACC_VOLATILE访问标志。ACC_PRIVATE表示这个字段是私有的,ACC_VOLATILE表示这个字段是由volatile关键字修饰的。数据的读取是通过getfield命令来实现的,数据的赋值是通过putfield命令来实现的。
4.2、getfield指令实现过程
在执行getfield指令读取变量时,JVM会先判断变量是否有ACC_VOLATILE标志。如果有ACC_VOLATILE标志,则JVM会强制使CPU本地缓存失效,从内存中直接读取数据。如果变量没有ACC_VOLATILE标志,则JVM会从CPU本地缓存中读取数据。getfield指令解析过程如代码所示。

以int类型的变量为例,如果变量有ACC_VOLATILE标志,JVM会调用int_field_acquire方法来读取数据,如果变量没有ACC_VOLATILE标志,JVM会调用int_field方法来获取数据。
int_field_acquire方法会调用Atomic类的load_acquire方法来读取数据。load_acquire方法会调用OrderAccess的acquire方法来使CPU的本地缓存失效。load_acquire方法的实现如代码所示。

OrderAccess的acquire方法会根据不同CPU型号来发送不同的指令信息。下方代码是x86处理内存屏障的实现。

compiler_barrier函数是直接面向CPU硬件编程的,是采用内嵌汇编命令来实现的。asm指令表示当前代码是汇编代码。volatile指令用来禁止编译器对代码进行优化。memory指令用来让CPU本地缓存失效。
4.3、putfield指令实现过程
在执行putfield指令修改变量时,JVM会先判断变量是否有ACC_VOLATILE标志。如果变量有ACC_VOLATILE标志,在修改完数据后,JVM会调用OrderAccess的storeload方法来刷新CPU缓存,将CPU缓存中的数据同步到主内存中。如果变量没有ACC_VOLATILE标志,JVM会直接将数据写入CPU缓存。putfield指令的解析过程如代码所示。

以int类型的变量为例,如果变量有ACC_VOLATILE标志,JVM会调用release_int_field_put方法来写入数据。release_int_field_put方法最终是调用Atomic类的release_store方法来实现数据写入。在写入数据之前,release_store方法会调用OrderAccess的release方法使CPU本地缓存失效,然后写入数据。volatile数据写入的具体实现如代码所示。

OrderAccess的release方法在不同CPU有不同的实现的方式。release方法和acquire方法实现逻辑相同,都是调用了compiler_barrier来实现内存屏障,使当前CPU本地缓存失效。而storeload则是先对内存地址加锁,再加上内存屏障,来实现内存同步。
5、volatile伪共享
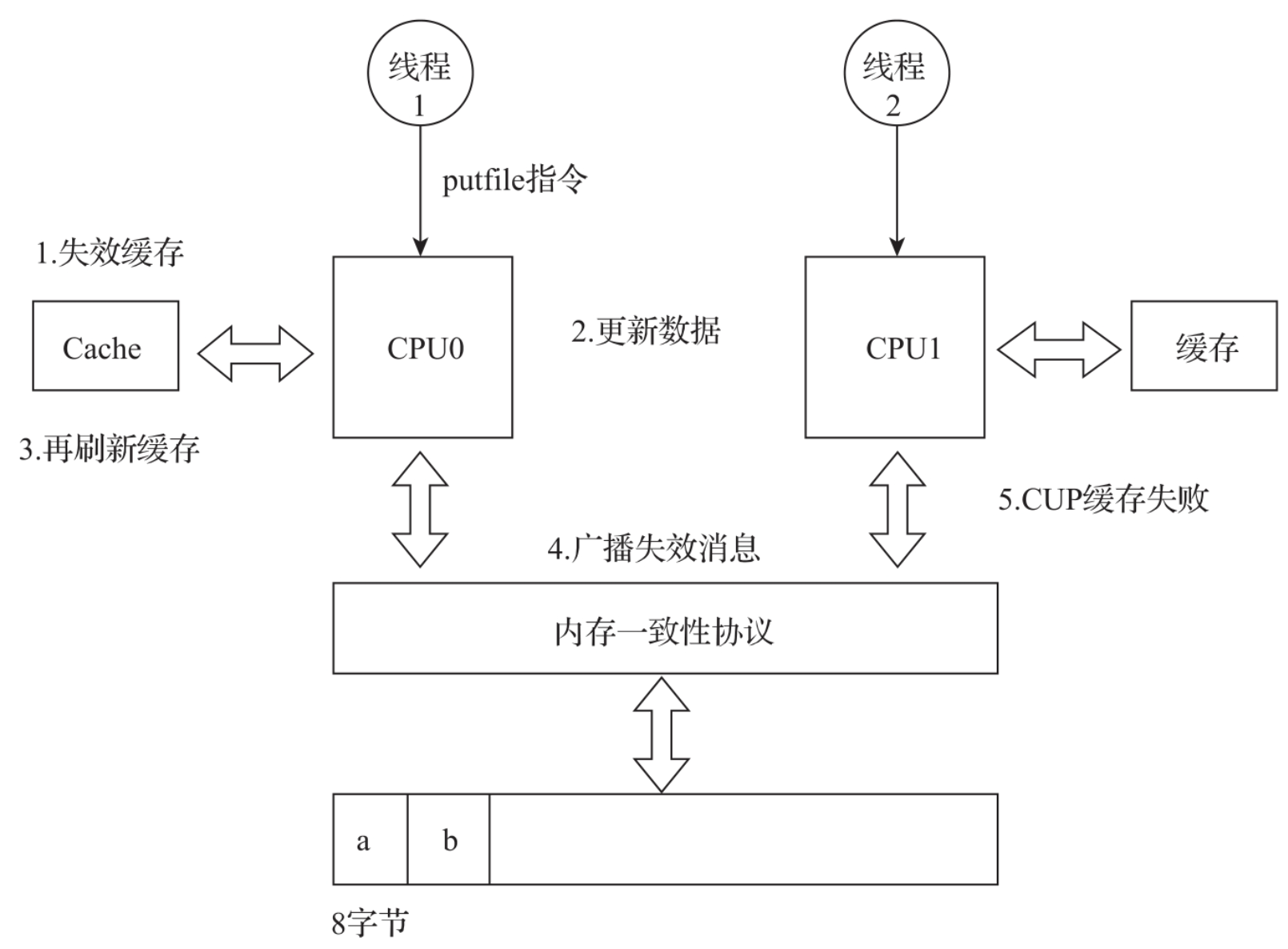
volatile关键字是通过CPU缓存与内存数据的实时同步来实现多线程的可见性的。每次内存与CPU缓存之间的数据同步是以缓存行(Cache Line)为单位的。
缓存行是CPU的最小缓存单位,大小为64字节,逻辑结构如图所示。CPU每次从内存往CPU缓存读取数据,或者从CPU缓存向内存同步数据,都是以一个缓存行作为单位的。这样做是为了提升CPU缓存与内存之间的数据交换效率。

缓存行虽然提高了数据传输效率,但也带来了新的问题。变量a与变量b在同一个缓存行中。CPU0上的线程用到了变量a,CPU1的线程用到了变量b。变量a是用volatile修饰的,那每次线程对变量a的修改都会让CPU0的缓存行失效,并将消息广播到CPU1。CPU1收到缓存广播失效了以后,就会为CPU缓存中的b打上失效标记。当线程2需要读取b的时候会直接从缓存中读取数据。如果同一个缓存中存储了多个变量,并且变量都是用volatile修饰的,多个线程同时对缓存行中的多个变量进行修改,就会产生大量的CPU缓存数据失效的消息,这将极大地降低CPU的运行效率。缓存行失效的示意图如图所示。
那如何解决这个问题呢?可以在volatile修饰的字段后面填充无效的数据,使得无效数据刚好填满一个缓存行,也就是我们常说的volatile伪共享。在JDK8以前,只能通过手动方式填充无效字段。代码清单5-25是一个简单的计数器,用来演示如何手动填充数据。计数器Counter内部定义了一个long型的字段count。因为Java里面long只占用8个字节,而要确保long型字段能够在一个缓存行里面,则需要填充56个字节的无效数据,所以代码里定义了7个无效的long型字段,即p1~p7。

在JDK8以后,Java提供了@sun.misc.Contended注解来实现自动填充,但同时需要设置JVM的启动参数-XX:-RestrictContended。可以把上面的例子进行简单改造,在count字段上加上Contended注解即可,改造后的代码如代码所示。

那手动填充字段和Contended注解有什么差别呢?手动填充需要在编码时计算出要填充多少个数据字段,而如果采用自动填充方式,开发人员则不用关心此类问题。
6、CAS硬件同步原语
6.1、CAS硬件原语
CAS是解决多线程并行情况下使用锁造成性能损耗的一种机制,采用这种无锁的原子操作可以实现线程安全,避免加锁带来的笨重性。CAS操作包含3个操作参数:内存位置(V)、预期原值(A)、新值(B)。伪代码如下所示,如果内存位置的值与预期原值相等,那么CPU自动将该位置值更新为新值。如果内存位置的值与预期原值不相等,则处理器不进行任何操作。CAS操作是通过CPU指令来完成的,它需要硬件的支持。

6.2、JVM CAS实现
在JDK1.5以后,Java就提供了CAS机制来实现线程安全的控制。具体来说,sun. misc.Unsafe类里的compareAndSwapInt和compareAndSwapLong方法提供了CAS的功能,JVM里面的Atomic类的cmpxchg方法实现了CAS功能。Atomic是个抽象类,不同的操作系统与处理器上有具体的实现,如下代码是Linux系统x86处理器上的具体实现。

- CPU将exchange_value加载到rax寄存器中,rax寄存器用来存储最终返回结果的值。
- CPU将compare_value的值存入eax寄存器。
- dest表示数据对象的当前值,该值可存入任意的通用寄存器。
- 比较eax寄存器的值compare_value和dest寄存器的值是否相等。如果相等则把exchange_value的值写入dest寄存器,完成新值的设置。如果不相等,则把dest寄存器中的值写入eax寄存器。
- 返回eax寄存器中的exchange_value值。如果exchange_value等于compare_value,表示这次修改失败了。如果exchange_value等于要修改的值,表示修改成功了。
6.3、ABA问题
但是CAS会有一个ABA的问题,如图所示。变量A在内存中最初的值为10,有3个线程都需要对变量A进行操作。最初线程1读取了变量A的值,在线程1读取后,线程2把A的值改成20,然后线程3又把变量A的值改成10。
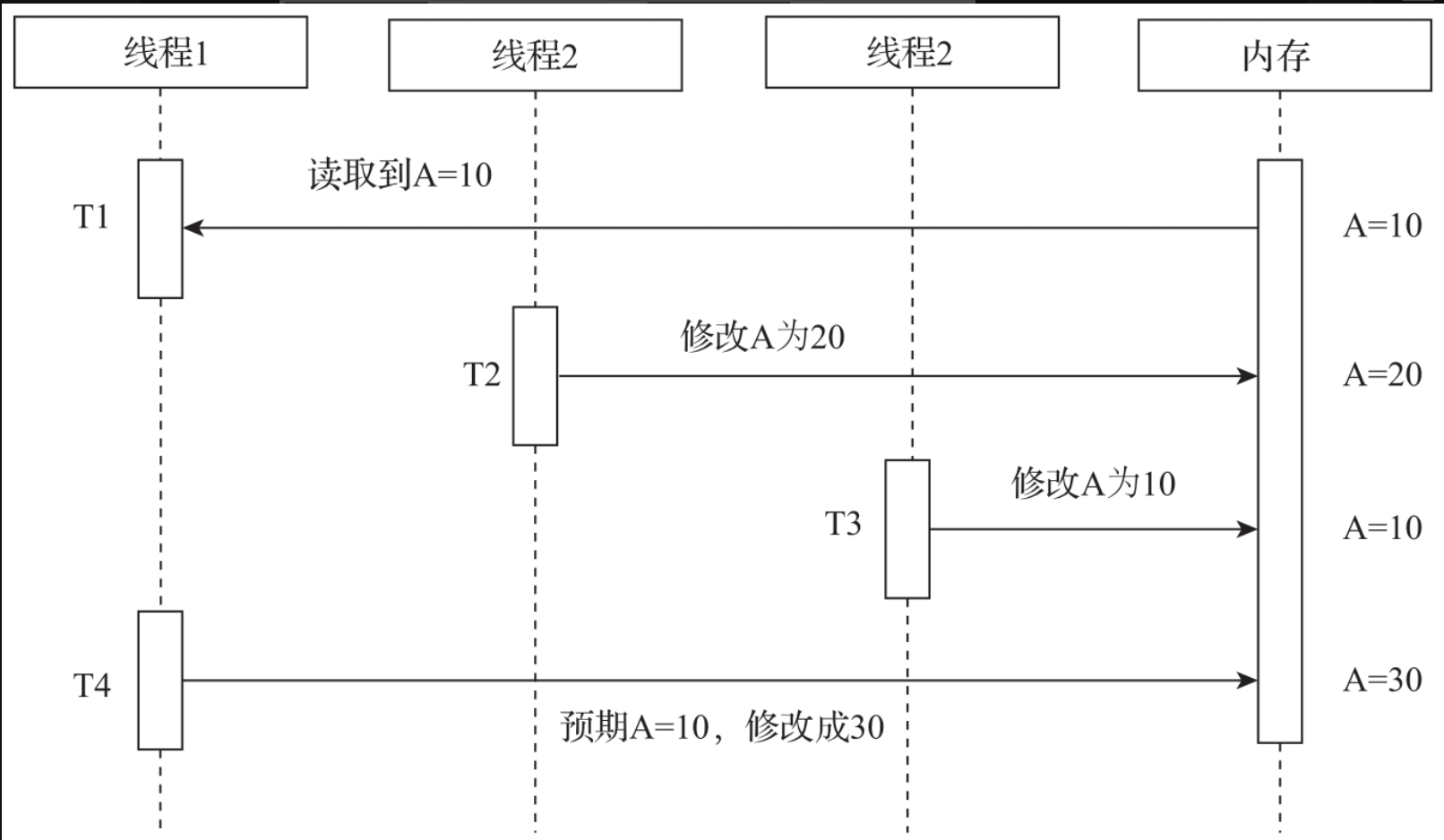
最后线程1采用CAS的方式想把A改成30,这时由于A的预期值为10,A的当前值也是10,此时线程1就会错误地把A改成30。原来CAS的预期是从T1时刻读取数据,到T4时刻去修改数据。这中间A是没有变化的,但实际情况是A经历了10→20→10的变化。这里就对CAS的使用提出了一个要求,要求在一定的时间周期内,数据的变化是不可逆的,是单向线性变化的,我们需要规避ABA这种可逆性的改变。
CAS的核心思想是把变量的当前值和预期值进行比较,如果当前值等于预期值就会把变量设置成一个新的值。如果当前值不等于预期值,说明变量已经发生了变化,就不进行修改。在使用CAS进行数据修改的时候,一定要考虑ABA问题,要确保在一定周期内数据的变化是不可逆的。
7、Unsafe功能介绍
Unsafe类在sun.misc包路径下,是由sun公司实现的扩展工具类,主要提供一些直接面向JVM内部操作的功能。由于Unsafe可直接操作JVM,因此操作不当会导致程序的整体性崩溃。Unsafe的含义是提醒大家要注意使用时的安全,确保不会导致程序崩溃。Unsafe提供的功能如图所示。
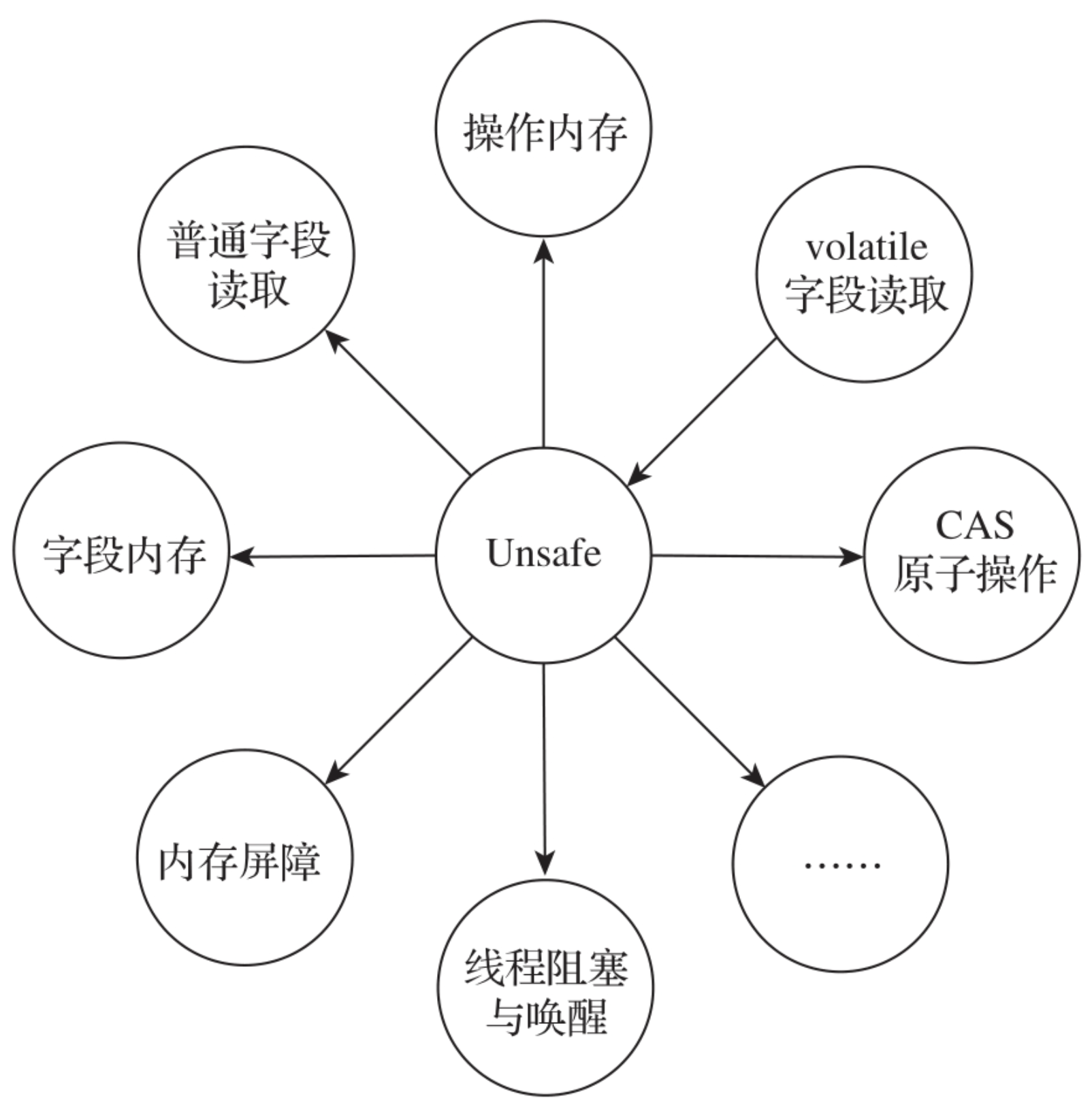
7.1、操作内存
Unsafe提供了直接操作JVM内存的能力,主要包含内存的分配、复制、释放、给定地址值操作等方法,如代码所示。

其中,allocateMemory方法的功能是申请堆外内存,通过allocateMemory方法申请的内存需要手动释放,垃圾收集器不会进行垃圾回收。DirectByteBuffer就是通过这个方法来申请本地内存的。
reallocateMemory方法的功能是对已经申请的内存进行缩容与扩容。freeMemory方法是用来释放前面申请的内存。setMemory方法用于设置内存空间的值,例如DirectByteBuffer在申请完内存空间后会调用setMemory来设置默认值。
7.2、获取字段内存偏移量
Unsafe提供了获取JVM对象字段内存位置的能力,主要包含获取普通字段、static字段、数组等的内存偏移量,如代码所示。


Java对象在JVM中对象是用OOP表示的,OOP包含Mark Word、Class指针、属性信息等内容。objectFieldOffset方法就是用来获取具体属性的偏移量。通过对象的首地址加上偏移量,JVM就能准确地获取到内存的绝对地址。JVM就可以通过绝对地址去进行赋值。通过上面这种方式赋值,减少了中间换算的过程,极大提升了访问效率。
7.3、普通字段的读取与赋值
Unsafe提供了直接读写JVM对象属性的能力,包含对常见的8种基础数据类型的读取与赋值的能力,方法描述如代码所示。

7.4、volatile字段的读取与赋值
Unsafe提供了volatile字段的读取与赋值能力,包含对常见的8种基础数据类型的读取与赋值,方法描述如代码所示。


7.5、CAS操作能力
Unsafe提供了对int、long、对象引用三种数据类型的CAS操作能力,如代码所示。

ConcurrentHashMap、AtomicBoolean、AtomicInteger、AbstractQueuedLongSynchronizer等类都使用了compareAndSwapInt方法来实现对应的业务逻辑。AtomicLong、AtomicLo-ngArray等类都使用compareAndSwapLong来实现业务功能。AtomicReference、Atomic-MarkableReference等类都使用compareAndSwapObject来实现安全修改对象的属性引用。
7.6、线程阻塞与唤醒
Unsafe提供了线程的阻塞与唤醒能力,如代码所示。

7.7、内存屏障
Unsafe提供了3种内存屏障的能力。loadFence(读屏障)的功能是让CPU本地缓存失效。storeFence(写屏障)的功能是将CPU本地缓存中修改的数据及时同步到主存中。fullFence屏障的作用相当于storeFence加loadFence,执行过程是先触发CPU本地缓存进行数据同步,再使CPU本地缓存中的数据失效。Unsafe方法的内存屏障功能如下所示。

StampedLock就是通过调用loadFence来实现实时读取内存中的数据的。MethodHandle就是通过调用fullFence来实现Lambda表达式的更新与优化的。
8、Unsafe实现原理
8.1、volatile字段读取
在JVM里,volatile字段的读取功能是通过Unsafe_Get函数实现的,JNI描述如下所示。

Unsafe_Get函数实际是调用MemoryAccess的get_volatile函数来进行数据读取的。如下代码是get_volatile函数的具体实现。

RawAccessBarrier是RawAccess的实现类,它通过load_internal函数完成数据读取。load_internal是通过调用Atomic类的load_acquire函数来完成数据读取,具体实现可参考如下代码。load_acquire功能就是在读取数据前加入内存屏障让CPU的缓存失效,然后从主内存读取数据。
 !!(https://i-blog.csdnimg.cn/direct/876af8ec2ec74324b17bbf9b1234e871.png)
!!(https://i-blog.csdnimg.cn/direct/876af8ec2ec74324b17bbf9b1234e871.png)
8.2、volatile字段写入
volatile字段的赋值能力主要是通过Unsafe_Put函数实现的。Unsafe_Put函数的描述如代码所示。

Unsafe_Put函数是通过MemoryAccess类的put_volatile函数来实现的。put_volatile函数具体实现如代码所示。

put_volatile函数会调用RawAccess的store函数来完成写入。store函数对应的具体实现是store_internal函数。如下代码是store_internal函数的具体代码实现:先将数据写入CPU缓存中,然后通过写屏障将CPU本地的缓存数据同步到主内存中,最后调用内存读屏障来使CPU的本地缓存失效。

8.3、CAS操作能力
compareAndSwapInt方法对应的JNI是Unsafe_CompareAndSetInt函数,compareAnd-SwapLong方法对应的JNI是Unsafe_CompareAndSetLong函数,compareAndSwapObject方法对应的JNI是Unsafe_CompareAndSetReference函数,CAS JNI函数如代码所示。


如下代码是Unsafe_CompareAndSetInt函数的代码,核心逻辑是先获取到obj的内存地址,接着根据对象的内存地址加上内存偏移量(offset)来获取字段的内存地址。然后调用Atomic类的cmpxchg方法来实现数据的赋值,cmpxchg方法先会比较addr内存中的值有没有改变,没有改变就赋予新的值。

如下代码是Unsafe_CompareAndSetReference函数的代码,核心逻辑也是获取到对象的内存地址,然后调用HeapAccess的oop_atomic_cmpxchg_at方法来实现数据的比较与交换。

8.4、线程阻塞与唤醒
Unsafe分别通过park和unpark方法提供了线程的阻塞与唤醒能力,二者在JVM里对应处理的函数是Unsafe_Park与Unsafe_Unpark函数,如代码所示。
Unsafe_Park函数会先获取当前线程的Parker对象,然后调用Parker对象的park方法来阻塞线程。Unsafe_Unpark函数会先获取当前线程的Parker对象,然后调用Parker的unpark方法来唤醒线程。
9、LockSupport实现原理
LockSupport方法是通过sun.misc.Unsafe来实现线程阻塞与唤醒的。
LockSupport方法提供了一组线程阻塞与唤醒的方法,详细方法如表所示。
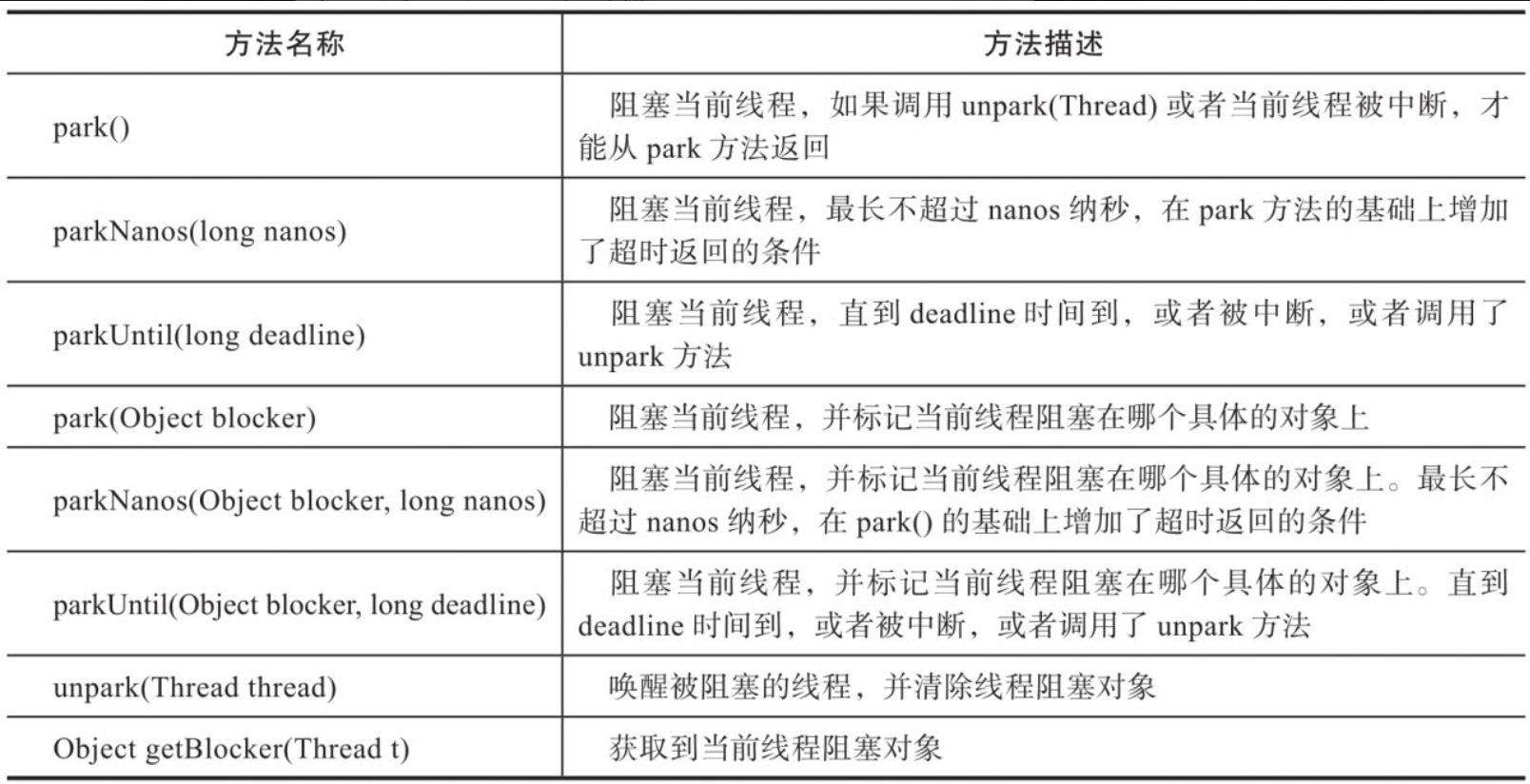
LockSupport提供了2种线程阻塞的方式:一种是不带阻塞对象的方法,另一种是带阻塞对象的方法。阻塞对象可以表示线程阻塞的原因,JVM会把阻塞对象设置到线程的parkBlocker字段中,这样我们就可以通过诊断工具查看线程阻塞的原因。
9.1、Unsafe初始化
在使用Unsafe之前,需要先实例化Unsafe。如代码所示,LockSupport定义了UNSAFE静态全局变量。

9.2、无阻塞对象方法
LockSupport提供了3个无阻塞对象的线程阻塞方法,如代码所示。

这3个方法最终都是调用Unsafe的park方法来实现线程阻塞的。
9.3、有阻塞对象方法
LockSupport提供了3种有阻塞对象的线程阻塞方法。这3个方法的处理流程基本都是一样的,首先调用setBlocker方法设置阻塞对象,然后调用Unsafe的park方法来阻塞当前线程,线程醒来后会再次调用setBlocker方法清除绑定对象,如代码所示。

在上述代码中,setBlocker方法通过调用Unsafe的putObject方法将阻塞对象设置到当前线程的parkBlocker字段中。
如下代码展示了有阻塞对象与无阻塞对象之间的差别。LockSupportTest有2个方法:park方法与parkObject方法。

调用park方法来实现线程阻塞时,可通过Arthas的thread命令来查看线程的信息,线程阻塞结果如图所示。

从上图中可以清晰地看到,当前线程被sun.misc.Unsafe.park方法阻塞了,线程处于WAITING状态,但不知道线程是因为什么而阻塞的。
调用parkObject方法来实现线程阻塞时,可通过Arthas的thread命令来查看线程的信息,线程对象阻塞结果如图所示。
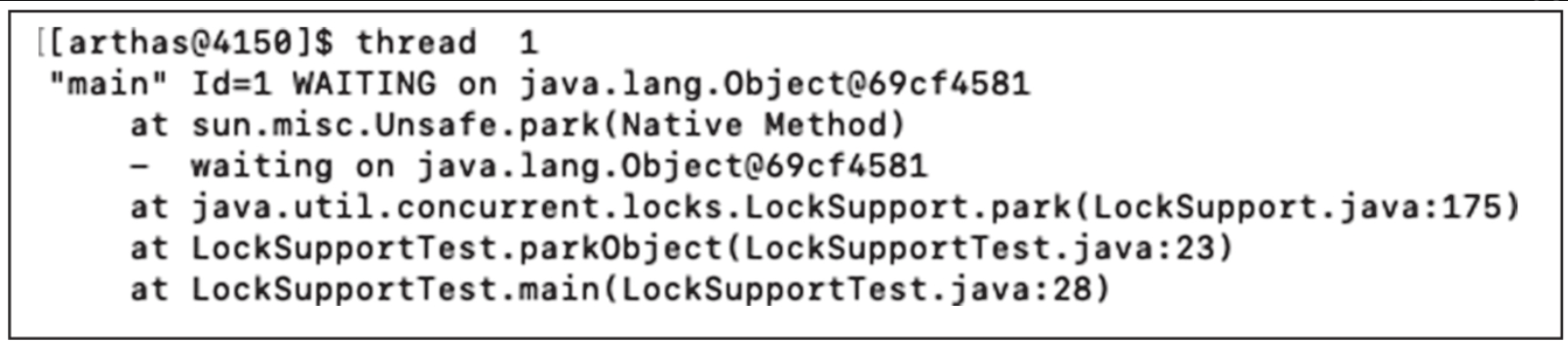
从上图中可以清晰地看到,线程被sun.misc.Unsafe.park方法阻塞了,并阻塞在java.lang.Object对象上,这样就能清晰地知道线程是因为什么而阻塞了。
9.4、线程唤醒
Unsafe的unpark方法用来唤醒线程,下面代码是unpark方法的具体实现。
