1.页表的本质
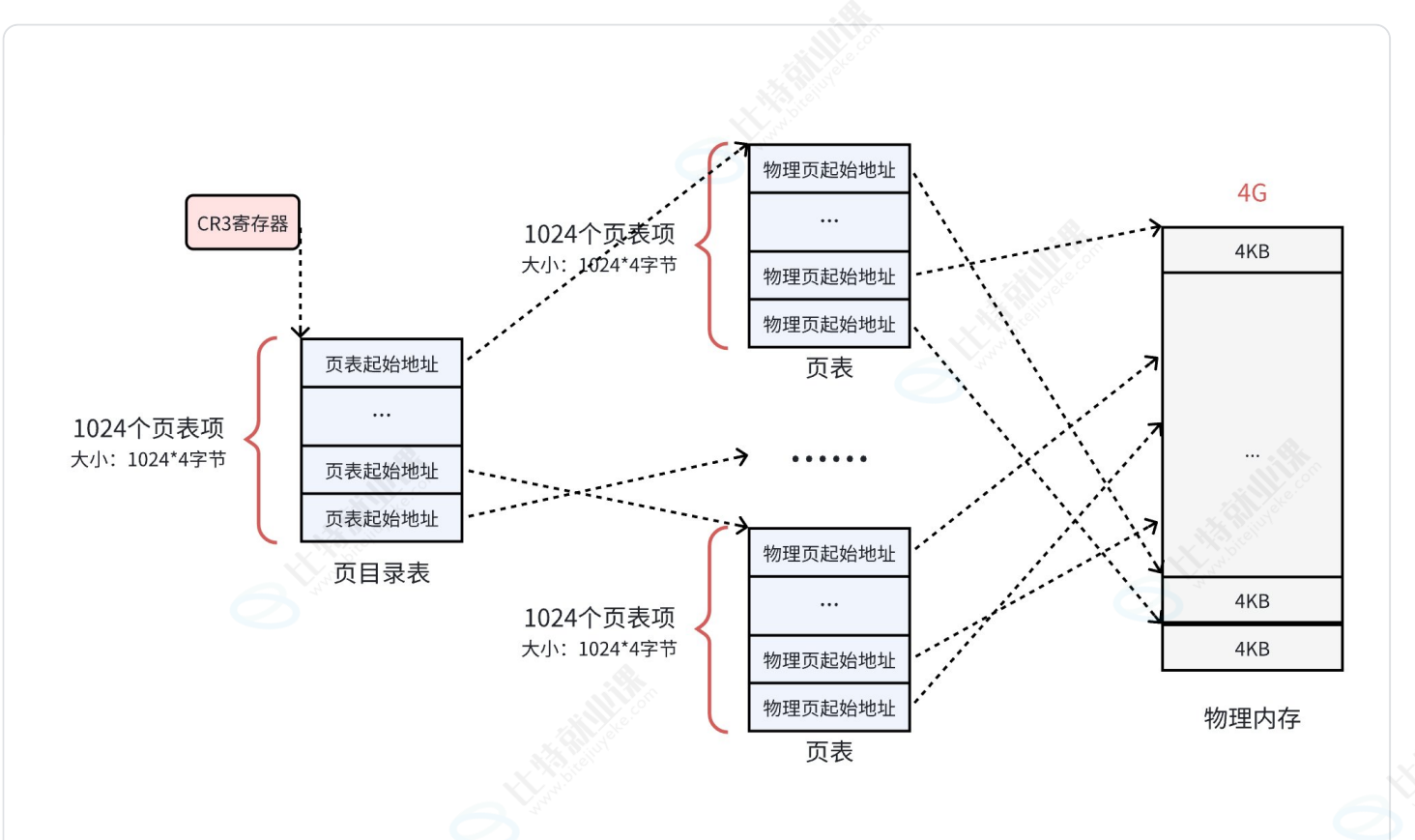
以32位机器为例,此时的虚拟地址大小为32位bit,此时我们把这32位bit分成3个部分,前10位,中间10位,和后12位,取值范围分别是0,1024,0,1024,0,4096。
逻辑运作过程:
CPU首先根据前10bit位的值作为页目录表(这个数组中的元素存的是下级页表的地址)的下标找对应元素从而访问对应的页表(里面存的是一个页框的地址),然后再根据中间10位bit位的值访问这个数组对应下标的元素就可以找得到一个页框的位置了。
后12位bit位的值就是在该页框中的偏移量,此时我们访问物理内存中的一个字节就变成了要访问的起始页框地址+业内偏移量。
CPU的运行过程:
页目录表的起始物理地址被CR3寄存器所指向。
MMU:内存管理单元,是硬件,其拿着虚拟地址和CR3的数据完成查找页框,根据偏移量访问对应具体字节的操作。
因此虚拟地址经过CPU处理后出来的就是物理地址,此时的CPU就可以通过内存总线直接访问物理内存了。
缺页中断的进一步解释:一个合法的虚拟地址在发现没有对应的页目录地址或页框地址,此时就会去申请内存,开辟新的page,并得到page index,翻译成起始物理页框地址后就存入对应页框中即可。
如果是进程的写时拷贝直接修改页框空间中存储的起始页框地址即可。
一个虚拟地址是可以对应多个物理地址的,一个物理地址也是可以对应多个虚拟地址的。
因此页表中并没有存虚拟地址,虚拟地址由虚拟地址地址空间管理,但在页表中的具体体现就是页目录和页表的下标。因此页表的本质是由一张页目录表+多张页表构建的体系映射,其中虚拟地址是索引,起始物理地址是目标,物理地址=虚拟地址(低12位bit组成的偏移量)+页框地址。
EIF的地址说明:
EIF的编址其实是对代码进行有序化(其实就是连续编址),其中每个地址的前20bit的值相同的一定来自于同一个4KB,因此能通过前20bit位的值对不同页框进行划分,也就是一个页框内的不同字节只有后12bit位的值不同。
局部性原理:只有后12bit位不同和连续存址的方式使一个数据的周围很容易出现与它相关联的数据。
页表对虚拟地址的具体划分:
页目录将整个物理地址分成1024大份,页表又将其中的一大份分成1024小份,虚拟地址的后12bit位又将一小份分成4096小小份。
执行流看到的资源本质是在合法的情况下所拥有的虚拟地址数,因为虚拟地址就是资源的代表。
虚拟地址空间(mm_struct和vm_area_struct)本质就是对资源的统计数据。
从线程的角度:
资源划分:本质就是地址空间划分。资源共享:本质就是虚拟地址共享。
线程进行资源划分的本质是地址划分来获取一定范围的合法虚拟地址,在本质就是页表划分。
线程进行资源共享的本质就是的虚拟地址的共享或者页表条目的共享。
2.struct page一些成员的介绍
(1)pages,位图,管理该页框的状态
(2)_mapcount,记录有多少个页表的元素指向该页表
(3)virtual,存该page指向的页框对应的虚拟地址
总结虚拟地址与页表的转换:虚拟地址的三段数据都只代表了数组下标或页框中的偏移量,页目录表和页表中存的元素都是地址。其中并没有说页表中的不同下标要存不同的地址。同时即使存在页表中有多个元素指向同一个起始物理地址最终也能通过偏移量的不同指向不同的数据。
一个物理地址找到其的虚拟地址的方式:一个页框内的数据只有后12bit位不同,因此只要把物理地址的后12bit位清0就能找到其的起始物理地址,将这个数据除以4KB就能找到管理它的page下标,在page数组中找到该page,其内部的virtual成员就能找到它的虚拟地址。
3.线程的优缺点
CPU转换地址的效率其实不高,因此CPU会将第一次出现的映射关系存进TLB表中(这个表是在CPU中的),之后遇到了相同的映射关系就可以直接调用表中的数据以提高效率。
硬缺页中断:要开辟新的物理空间后再构建页表映射关系。
软缺页中断:存在对应物理页但该物理页由其他进程生成(也就是当前进程不知道该物理页的存在),此时直接构建映射关系即可,常见于动态库的页表映射。
new或malloc的底层都是调用的brk系统调用
//在addr(虚拟地址)处开辟空间
int brk(void *addr);判断虚拟地址的合法性就是看该地址是否在mm_struct或vm_area_struct中的已知虚拟地址空间中。
总结:
线程优点:
(1)线程更轻量化,创建代价比进程小
(2)多CPU时使用相同数目的线程能提高效率
(3)线程切换,OS要做的事比进程切换少的多
进程切换:将此时CPU的数据拷贝到当前进程的task_struct中然后CR3指向下一个进程的页目录地址。OS中有一个全局变量struct task_struct*current,存当前进程task_struct的地址(现在这个成员一般存在CPU中),CPU和OS就通过这个变量找进程,同时修改这个地址CPU就能切换到其他进程了。
CPU中有一块空间cache,存储用户特定数据的上下文,是根据局部性原理提高效率的。
//proc/cpuinfo是存CPU信息的,cache size = 36608KB说明了cache真实存在
ubuntu@VM-0-2-ubuntu:~$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 85
model name : Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
stepping : 5
microcode : 0x1
cpu MHz : 2494.140
cache size : 36608 KB(4)进程切换会导致存储历史页表数据的TLB和存上下文的cache失效,也就是进程切换后这两处数据要重新缓存。这里就是进程切换导致效率下降最严重的地方,而线程切换不会出现大量失效,因此效率较高。
线程缺点:
一个线程出问题可能导致整个进程的所有线程出问题,因此线程之间缺少保护。
4.线程的私有和共享内容
私有部分:
(1)线程有自己的上下文数据,可以被独立调度
(2)有自己独立栈结构和自己的生命周期
共享部分:
文件描述符表,信号的处理方式,当前的工作目录,id。
5.线程控制
int pthread_create(pthread_t * thread,const pthread_attr_t *attr,void*(start_routine)(void*),void*arg);不是系统调用,是第三方库中的一个文件。
thread是未来线程的id,attr是线程的属性,arg是strat_routine的参数。生成的新线程会直接去调用strat_routine函数,而主进程继续往下运行。
cpp
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <pthread.h>
void *rout(void *arg)
{
int i;
while(true)
{
printf("I'am thread 1\n");
sleep(1);
}
}
int main()
{
pthread_t tid;
int ret;
if ( (ret=pthread_create(&tid, NULL, rout, NULL)) != 0 )
{
fprintf(stderr, "pthread_create : %s\n", strerror(ret));
exit(EXIT_FAILURE);
}
int i;
while(1)
{
printf("I'am main thread\n");
sleep(1);
}
return 0;
}可以说rout就是新线程独有的一段虚拟地址,main剩下的代码就是主线程独有的虚拟地址,从而实现不同线程有独立的代码与数据。
由于是第三方库,因此链接时要用 -l pthread,连接第三方库。
cpp
//可视化所有的线程
ps -aL
ubuntu@VM-0-2-ubuntu:~$ ps -aL
PID LWP TTY TIME CMD
351851 351851 pts/0 00:00:00 test
351851 351852 pts/0 00:00:00 test
351890 351890 pts/1 00:00:00 ps可以发现PID相同的为同一个进程。LWP就是轻量级进程的缩写,不同线程的LWP值不同,task_struct中有一个成员pid_t lwp就是用于记录该线程的lwp,只是主线程的lwp与pid的值相同。
linux中其实只有轻量级进程,因此CPU调度时看的是lwp。
时间片的调度问题:
一个进程中所有线程的时间片是平分的,如一个进程的时间片为10ms,其有5个线程,那么每个线程的时间片为2ms。