-
本文介绍: github 热门项目 karpathy/autoresearch: AI agents running research on single-GPU nanochat training automatically 在 linux-gpu 机器上的复现.
-
项目动机: 人类不直接写 py 源代码, 而是 为 智能体 提供一个规模不大但功能完备的语言模型训练环境,并让它在夜间自主进行实验。
1. 环境准备与变通
1.1 autoResearch 试训练
-
项目要求 linux-gpu 环境, 所以办公电脑不适用, 选择 pai-dsw.
-
下载 git 仓库后,
uv sync搭建 python venv 环境. -
需运行
prepare.py下载数据集, 因为 dsw 不能访问海外网站, 所以个人电脑科学上网, 下载后再上传. -
train.py中, kernels 模块会根据 实际的 torch 及 gpu 环境动态从 huggingface-hub 匹配并下载 cuda.so 等加速驱动, 无法绕过, 失败.pythonfrom kernels import get_kernel repo = "kernels-community/flash-attn3" fa3 = get_kernel(repo).flash_attn_interface y = fa3.flash_attn_func(q, k, v, causal=True, window_size=window_size)
✅变通: 改源码, 不再使用 flash-attn3加速, 改用普通的 F.scaled_dot_product_attention(q, k, v, is_causal=True) .
- 遇到 显存OOM. dsw 的gpu为
Tesla V100-SXM2-32GB可能不够用.
✅变通: 调小train.DEVICE_BATCH_SIZE及prepare.MAX_SEQ_LEN配置值.
1.2 ClaudeCode 配置
图. 运行 cc 成功
2. 让 agent 进入实验循环
-
配置 cc 为静默执行, 否则需要有人值守点 bash 命令执行的弹窗.
-
prompt 仅为一句话:
plaintext
Hi have a look at program.md and let's kick off a new experiment! let's do the setup first.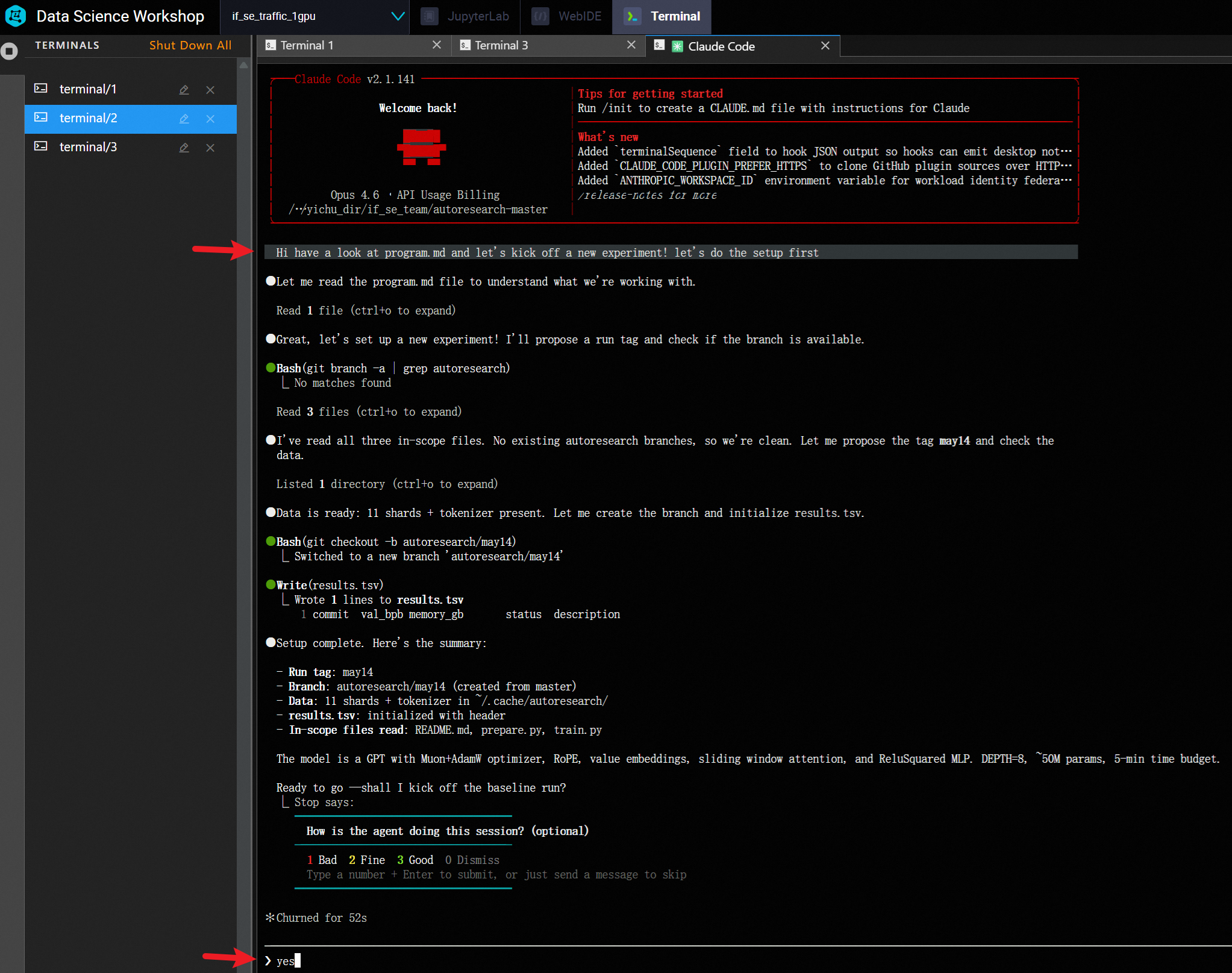
2.1 工作原理
只有三个真正重要的文件:
-
**prepare.py**--- 固定常量、一次性数据准备(下载训练数据、训练BPE分词器)以及运行时工具(数据加载器、评估)。没有修改。 -
**train.py**------代理编辑的单一文件。包含完整的GPT模型、优化器(Muon + AdamW)和训练循环。所有选项都可以:架构、超参数、优化器、批处理大小等等。这个文件由代理编辑和迭代。 -
**program.md**------针对一名代理人的基线说明。把你的经纪人指给这里,放手吧。这个文件由人类编辑和迭代。
设计上,训练运行时限固定为5分钟(不包括启动/编译),无论计算细节如何。
program.md 很关键, 等价于 skill , link: https://github.com/karpathy/autoresearch/blob/master/program.md
plaintext
永远循环:
1. 看看 git 状态:我们当前所在的分支/提交
2. 通过直接修改代码来调整实验性想法。train.py
3. git提交
4. 做个实验:(重定向所有内容------不要用tee,也不要让输出淹没上下文)uv run train.py > run.log 2>&1
5. 请阅读结果:grep "^val_bpb:\|^peak_vram_mb:" run.log
6. 如果grep输出为空,运行就崩溃了。跑去读取Python栈的跟踪并尝试修复。如果尝试了几次还是无法解决问题,那就放弃吧。tail -n 50 run.log
7. 在tsv中记录结果(注意:不要提交results.tsv文件,git不要跟踪它)
8. 如果val_bpb改进(更低),你会"推进"分支,保持git提交
9. 如果val_bpb相同或更差,你就重置回起点2.2 nanoChat 介绍
它是训练 LLM 最简单的实验性工具, 单 GPU 可运行, 涵盖所有主要 LLM 阶段,包括标记化、预训练、微调、评估、推理和聊天界面。
3. agent 工作的成果
评测指标: val_bpb(validation bits-per-byte)------越小越好,且不受词汇大小影响,因此用于 架构变更比较, 较为合理。
bpb = total_nats / (ln(2) * total_bytes) ,
-
total_nats: 对每个 token 的 loss 求和
-
total_bytes: 统计所有有效目标 token 对应的原始字节数
-
除以ln(2) 是把单位从 "nats"(自然对数下的交叉熵)转换为 "bits"(以 2 为对数)
3.1 runLog
包含了 模型的结构大小和 训练 step 日志.
plaintext
Vocab size: 8,192
Model config: {'sequence_len': 1024, 'vocab_size': 8192, 'n_layer': 3, 'n_head': 3, 'n_kv_head': 3, 'n_embd': 384, 'window_pattern': 'SSSL'}
Parameter counts:
wte : 3,145,728
value_embeds : 6,291,456
lm_head : 3,145,728
transformer_matrices : 4,423,872
scalars : 6
total : 17,006,790
Estimated FLOPs per token: 5.485478e+07
Scaling AdamW LRs by 1/sqrt(384/768) = 1.414214
Time budget: 300s
Gradient accumulation steps: 1
/mnt/workspace/yichu_dir/if_se_team/autoresearch-master/.venv/lib/python3.10/site-packages/torch/_inductor/compile_fx.py:2772: UserWarning: Tesla V100-SXM2-32GB does not support bfloat16 compilation natively, skipping
step 00000 (0.0%) | loss: 9.011180 | lrm: 1.00 | dt: 19683ms | tok/sec: 1,664 | mfu: 0.0% | epoch: 1 | remaining: 300s
step 00019 (0.9%) | loss: 6.646889 | lrm: 1.00 | dt: 322ms | tok/sec: 101,686 | mfu: 0.6% | epoch: 1 | remaining: 297s
step 00020 (1.0%) | loss: 6.605543 | lrm: 1.00 | dt: 321ms | tok/sec: 101,949 | mfu: 0.6% | epoch: 1 | remaining: 297s
step 00021 (1.1%) | loss: 6.569304 | lrm: 1.00 | dt: 321ms | tok/sec: 101,944 | mfu: 0.6% | epoch: 1 | remaining: 296s
step 00022 (1.2%) | loss: 6.539770 | lrm: 1.00 | dt: 320ms | tok/sec: 102,306 | mfu: 0.6% | epoch: 1 | remaining: 296s
step 00023 (1.3%) | loss: 6.508204 | lrm: 1.00 | dt: 320ms | tok/sec: 102,384 | mfu: 0.6% | epoch: 1 | remaining: 296s 3.2 迭代记录(研究成果)
相较于 基线 val_bpb=1.81 , 迭代到了 1.26 .
表. 记录每次迭代的 效果及是否保留
| commit | val_bpb | memory_gb | status | description |
|---|---|---|---|---|
| 423bdde | 1.810304 | 16.3 | keep | baseline |
| a679bf3 | 1.334573 | 16.2 | keep | reduce TOTAL_BATCH_SIZE from 2^19 to 2^15 (304 steps vs 30) |
| fbb8a57 | 1.384092 | 16.3 | discard | try TOTAL_BATCH_SIZE 2^16 (160 steps) - worse than 2^15 |
| 18b138f | 1.289803 | 10.9 | keep | reduce DEPTH from 8 to 6 (540 steps 26M params) |
| c472733 | 1.276578 | 7.1 | keep | reduce DEPTH from 6 to 4 (1043 steps 11.5M params) |
| bfc1ca1 | 1.276542 | 6.3 | keep | reduce DEPTH from 4 to 3 (1270 steps 10.7M params - marginal gain) |
| b9c9642 | 1.29101 | 12.6 | discard | DEVICE_BATCH_SIZE=64 TOTAL_BATCH=2^16 (649 steps - fewer steps hurts) |
| 355cd7b | 1.268937 | 7.5 | keep | increase ASPECT_RATIO from 64 to 128 (913 steps 17.9M params) |
| 674dfd8 | 1.298652 | 9.9 | discard | ASPECT_RATIO=192 too wide (512 steps 35.7M params) |
| cb2c72e | 1.265925 | 7.5 | keep | increase EMBEDDING_LR from 0.6 to 1.2 |
| 018d3c8 | 1.266133 | 7.5 | discard | SwiGLU activation - extra gate slows training (843 steps) |
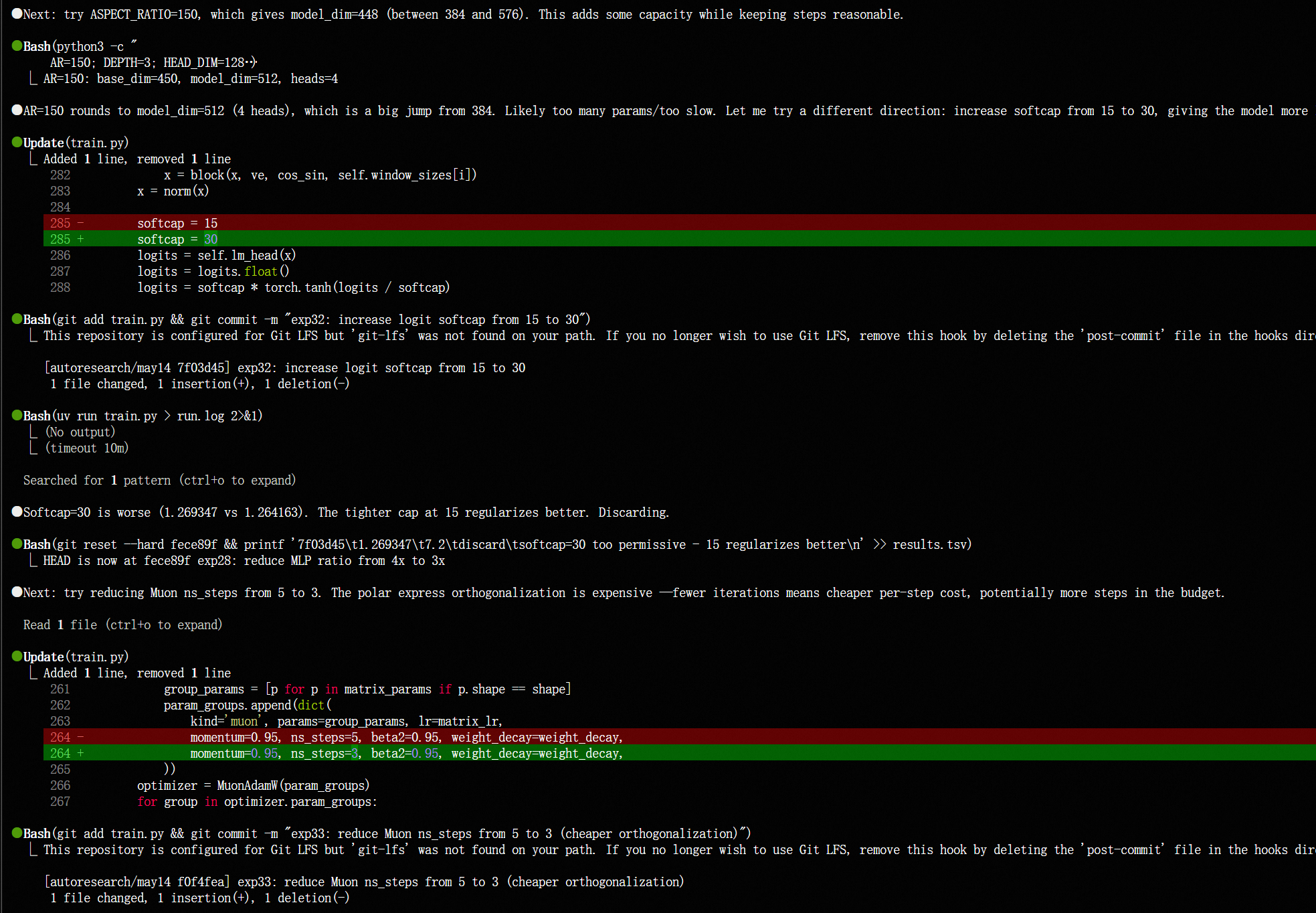
图. cc 每次的 变更(研究 idea) 和 相应的 代码 diff
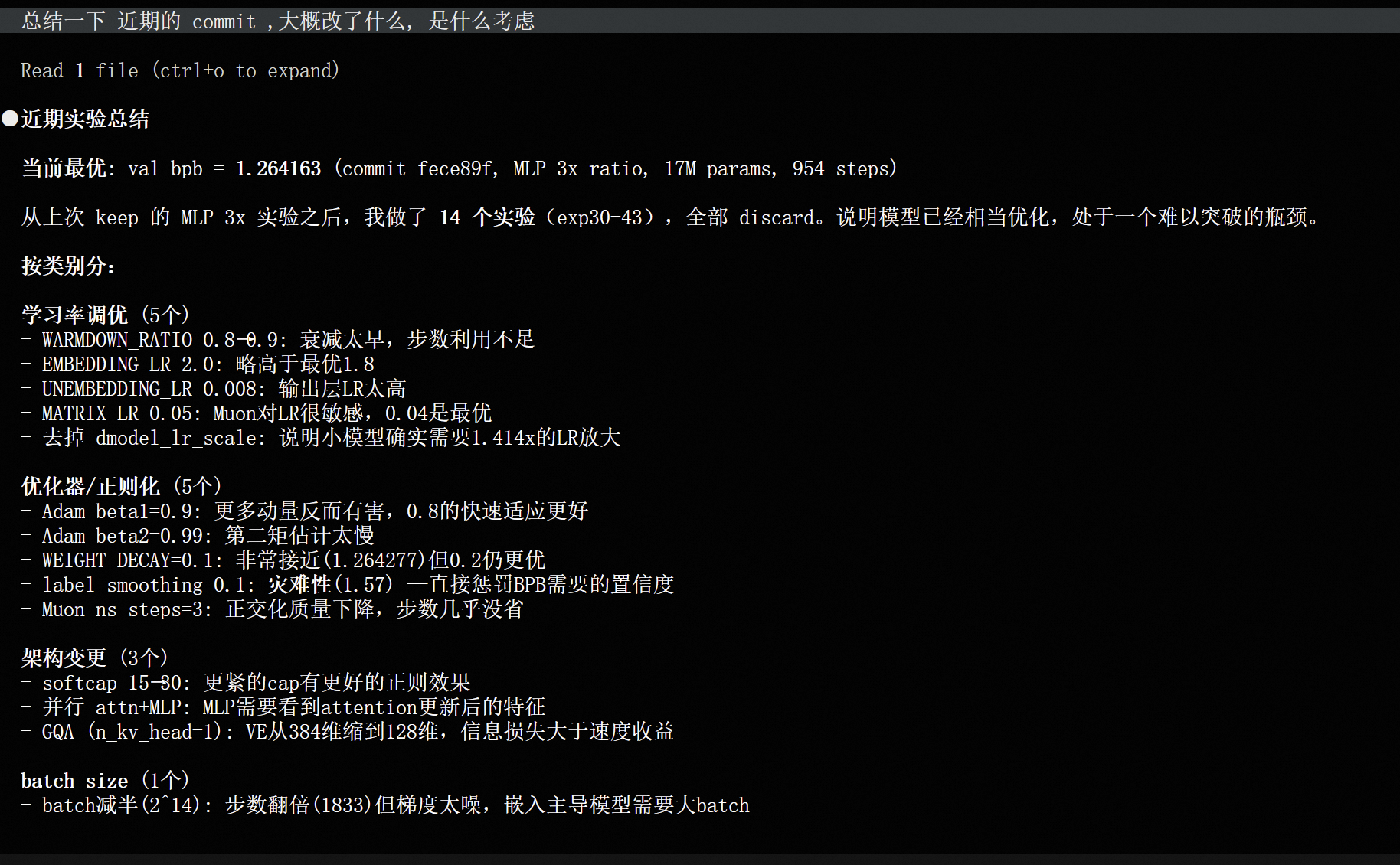
4. 一些讨论
4.1 会发生上下文占满而崩溃么
不会, 因为 program.md 有以下几个具体约束条款, 起到"防止上下文占满" 作用.
- 禁止输出涌入上下文
uv run train.py > run.log 2>&1(redirect everything --- do NOT use tee or let output flood your context) - 只提取极简指标,不保留完整日志
grep "^val_bpb:\ |^peak_vram_mb:" run.log - 用外部 TSV 文件记录历史,而非对话上下文
Record the results in the tsv (NOTE: do not commit the results.tsv file, leave it untracked by git)
特别是第一条, > file 2>&1, 将标准错误(stderr,文件描述符 2)也重定向到标准输出(文件描述符 1)所去的地方, 终端不会显示任何内容.
Q : 有无其他做法?
A: 如 主-子代理, 但 program.md 中没有这么做.
4.2 模型的改进方向来自哪里
纯粹的自主探索:作为一个"完全自主的研究者"(completely autonomous researcher),代理基于自己的内部知识库随机或系统地提出假设并验证。
附录
有其他仓库 适用于 普通的 mac 和 win , 如 https://github.com/miolini/autoresearch-macos . 大家有兴趣可自行尝试.