工程师面对的世界,从来都不是完整的。你测不完所有零件的寿命,跑不完所有批次的强度试验,也等不到每一台设备都故障才去分析原因。你能拿到的,永远只是一把样本------而参数估计,就是用这把样本去猜透整个总体的艺术。
一、先把问题说清楚
统计学里有个基本的世界观:总体(Population)是你真正关心的全集,参数(Parameter)是描述这个全集的某个数字,比如所有同型号轴承的平均寿命 μ,或者某批钢材屈服强度的波动程度 σ2。但你永远看不到总体的全貌,你只有样本 x1,x2,...,xn。
参数估计要回答的,就是这个朴素的问题:手里这把数,能告诉我多少关于那个大世界的事?
它分两条路走:
| 类型 | 输出形式 | 核心问题 | 典型方法 |
|---|---|---|---|
| 点估计(Point Estimation) | 单个数值 θ^ | "参数最可能是多少?" | MLE、矩估计、最小二乘 |
| 区间估计(Interval Estimation) | 区间 θ\^L,θ\^U | "参数以多大概率落在某范围?" | 置信区间、贝叶斯可信区间 |
点估计给你一个答案,区间估计给你一个底气。两者配合,才是完整的推断。
二、点估计:猜,但要猜得有道理
矩估计------最朴素的那种猜法
矩估计的逻辑简单到有点可爱:总体的期望是 μ,那我就用样本均值 xˉ 去代替它;总体的二阶矩是某个表达式,那我就用样本的二阶矩去对应它。列方程,解参数,完事。
以正态分布 N(μ,σ2) 为例,矩估计直接给出:
μ^=xˉ=n1∑i=1nxi
σ^2=n1∑i=1n(xi−xˉ)2
没有高深的数学,胜在直觉清晰、计算省力。工程现场能快速出结果,这一点本身就是价值。
最大似然估计------让数据"开口说话"
MLE 的哲学更有意思一些。它问的是:在所有可能的参数值里,哪一个最能"解释"我观测到的这批数据?
把这个问题数学化,就是构造似然函数:
L(θ)=∏i=1nf(xi;θ)
连乘不好算,取对数变成求和:
ℓ(θ)=lnL(θ)=∑i=1nlnf(xi;θ)
对 θ 求导令其为零,找到让对数似然最大的那个参数值,就是 MLE 估计量 θ^MLE。
对正态分布来说,结果是:
μ^MLE=xˉ,σ^MLE2=n1∑i=1n(xi−xˉ)2
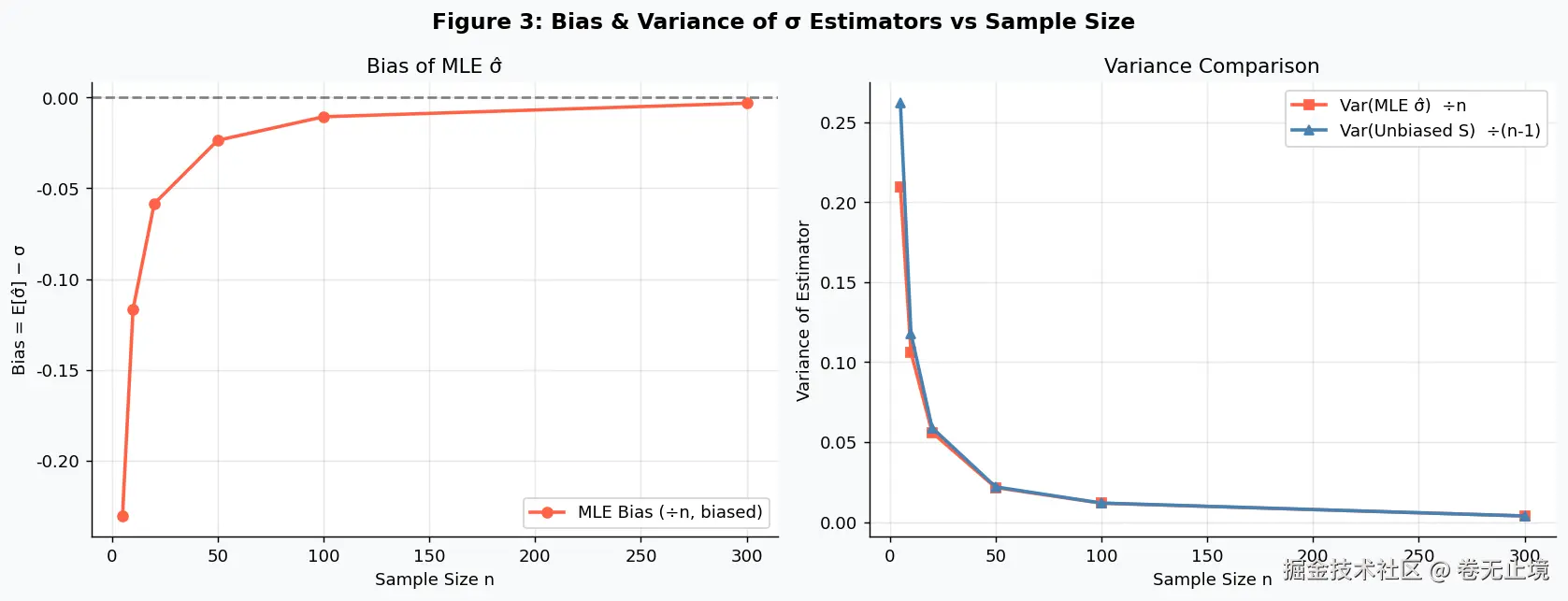
这里有个细节要记住:MLE 给出的 σ^2 分母是 n,是有偏估计 ------它系统性地低估了真实方差。工程计算中,方差的无偏估计要用样本方差 S2,分母换成 n−1。差一个数,在小样本时影响可不小。
估计量的"成绩单"
不是所有估计量都一样好用,评价它们有三把尺子:
- 无偏性 : Eθ\^=θ,估计量的期望等于真值,不系统性地偏高或偏低
- 有效性:在所有无偏估计量里,方差最小------达到 Cramér-Rao 下界
Var(θ^)≥I(θ)1,I(θ)=−E∂θ2∂2lnf(X;θ)
其中 I(θ) 是 Fisher 信息量,衡量数据对参数的"信息含量"。
- 一致性 :样本量 n→∞ 时, θ^P θ,数据越多,估计越准
MLE 的魅力在于,它在大样本下同时满足这三条,还有一个额外的好处------不变性 :若 θ^ 是 θ 的 MLE,那么 g(θ^) 就是 g(θ) 的 MLE。想估计标准差?直接对方差的 MLE 开根号就行,不用重新推导一遍。
三、区间估计:给答案加上"误差棒"
点估计给你一个数,但这个数有多可靠?区间估计回答的正是这个问题。
置信区间怎么构造
对于正态总体,均值 μ 的 100(1−α)% 置信区间有两种形式:
已知总体标准差 σ(用 Z 分位数):
xˉ±zα/2⋅n σ
未知 σ(用 t 分位数,工程中的常态):
xˉ±tα/2,n−1⋅n S
区间宽度正比于 1/n ------这意味着样本量翻 4 倍,精度才提升一倍。这是工程采样设计时必须牢记的代价函数。
置信区间最容易被误解的地方
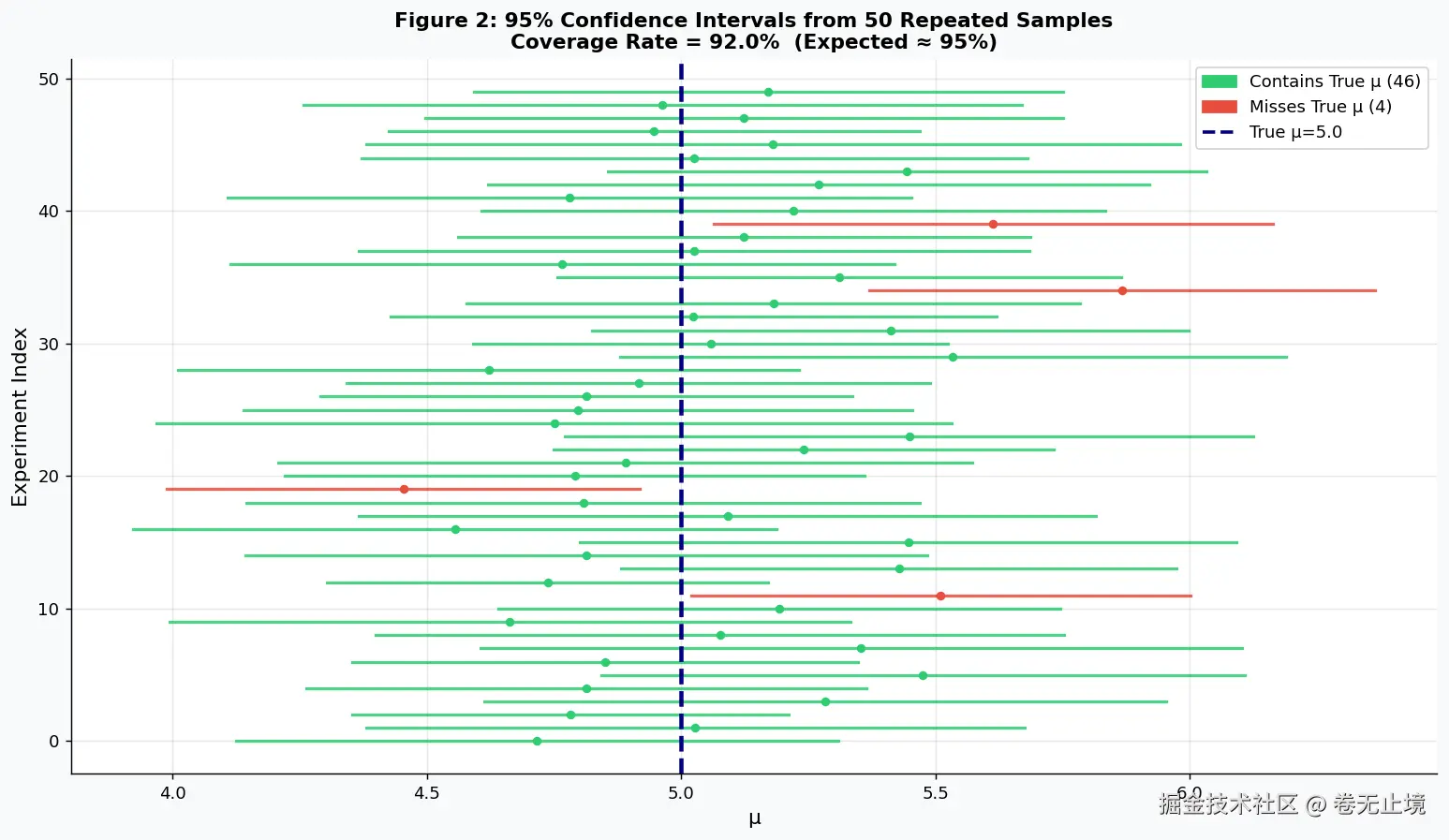
很多人会说:"参数有 95% 的概率落在这个区间里。"------这句话听起来顺耳,但在频率统计的框架下是错的。
正确的理解是:参数是固定的,区间是随机的。如果你重复抽样 100 次,每次都构造一个 95% 置信区间,那么其中大约 95 个区间会包住真实参数,另外 5 个会"射偏"。对于你手头这一个具体区间,它要么包住了参数,要么没有,概率非 0 即 1------只是你不知道是哪种情况。
这个区别不是文字游戏,它关系到你在工程报告里如何表述结论的严谨性。
四、代码实战:把概念画出来
下面三张图,把 MLE、置信区间、偏差-方差权衡这三个核心概念都落到可视化上。
python
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from scipy import stats
plt.rcParams.update({
"font.family": "DejaVu Sans",
"axes.spines.top": False,
"axes.spines.right": False,
"figure.dpi": 130,
})
np.random.seed(42)
# ════════════════════════════════════════════════════════════════════════════
# 图1:MLE 可视化 ------ 对数似然函数等高线 + 拟合效果
# ════════════════════════════════════════════════════════════════════════════
TRUE_MU, TRUE_SIGMA = 5.0, 1.5
n_samples = 30
data = np.random.normal(TRUE_MU, TRUE_SIGMA, n_samples)
mu_range = np.linspace(2, 8, 300)
sigma_range = np.linspace(0.5, 3.5, 300)
MU, SIGMA = np.meshgrid(mu_range, sigma_range)
def log_likelihood_grid(mu, sigma, x):
n = len(x)
return (-n * np.log(sigma)
- n / 2 * np.log(2 * np.pi)
- np.sum((x - mu) ** 2) / (2 * sigma ** 2))
LL = np.array([[log_likelihood_grid(MU[i, j], SIGMA[i, j], data)
for j in range(300)] for i in range(300)])
mle_mu = np.mean(data)
mle_sigma = np.std(data) # MLE(有偏,除以 n)
unbiased_sigma = np.std(data, ddof=1) # 无偏(除以 n-1)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
fig.suptitle("Figure 1: Maximum Likelihood Estimation (Normal Distribution)",
fontsize=14, fontweight="bold", y=1.01)
# 左图:对数似然等高线
ax = axes[0]
cp = ax.contourf(MU, SIGMA, LL, levels=30, cmap="viridis")
fig.colorbar(cp, ax=ax, label="Log-Likelihood ℓ(μ, σ)")
ax.scatter(mle_mu, mle_sigma, color="red", s=120, zorder=5,
label=f"MLE: μ̂={mle_mu:.2f}, σ̂={mle_sigma:.2f}")
ax.axvline(TRUE_MU, color="white", linestyle="--", alpha=0.7, label=f"True μ={TRUE_MU}")
ax.axhline(TRUE_SIGMA, color="cyan", linestyle="--", alpha=0.7, label=f"True σ={TRUE_SIGMA}")
ax.set_xlabel("μ", fontsize=12)
ax.set_ylabel("σ", fontsize=12)
ax.set_title("Log-Likelihood Contour Plot")
ax.legend(fontsize=9)
# 右图:样本直方图 vs MLE 拟合曲线
ax = axes[1]
x_plot = np.linspace(0, 10, 300)
ax.hist(data, bins=10, density=True, alpha=0.5,
color="steelblue", edgecolor="white", label="Sample Histogram")
ax.plot(x_plot, stats.norm.pdf(x_plot, TRUE_MU, TRUE_SIGMA),
"g--", lw=2, label=f"True: N({TRUE_MU}, {TRUE_SIGMA}²)")
ax.plot(x_plot, stats.norm.pdf(x_plot, mle_mu, mle_sigma),
"r-", lw=2.5, label=f"MLE Fit: N({mle_mu:.2f}, {mle_sigma:.2f}²)")
ax.set_xlabel("x", fontsize=12)
ax.set_ylabel("Density", fontsize=12)
ax.set_title("Sample vs MLE Fitted Distribution")
ax.legend(fontsize=9)
plt.tight_layout()
plt.savefig("fig1_mle.png", bbox_inches="tight")
plt.show()
print(f"{'='*50}")
print(f" 样本量 n = {n_samples}")
print(f" MLE 均值估计: μ̂ = {mle_mu:.4f} (真值 {TRUE_MU})")
print(f" MLE 标准差估计: σ̂ = {mle_sigma:.4f} (真值 {TRUE_SIGMA},有偏)")
print(f" 无偏标准差估计: S = {unbiased_sigma:.4f} (除以 n-1)")
print(f"{'='*50}")
# ════════════════════════════════════════════════════════════════════════════
# 图2:置信区间 ------ 重复抽样,看看有多少次"射中"真值
# ════════════════════════════════════════════════════════════════════════════
n_experiments = 50
n_per_exp = 25
alpha = 0.05
t_crit = stats.t.ppf(1 - alpha / 2, df=n_per_exp - 1)
ci_lower, ci_upper, means = [], [], []
for _ in range(n_experiments):
sample = np.random.normal(TRUE_MU, TRUE_SIGMA, n_per_exp)
m = np.mean(sample)
s = np.std(sample, ddof=1)
margin = t_crit * s / np.sqrt(n_per_exp)
means.append(m)
ci_lower.append(m - margin)
ci_upper.append(m + margin)
ci_lower = np.array(ci_lower)
ci_upper = np.array(ci_upper)
covers = (ci_lower <= TRUE_MU) & (ci_upper >= TRUE_MU)
coverage_rate = covers.mean()
fig, ax = plt.subplots(figsize=(12, 7))
for i in range(n_experiments):
color = "#2ecc71" if covers[i] else "#e74c3c"
ax.plot([ci_lower[i], ci_upper[i]], [i, i],
color=color, lw=1.8, alpha=0.85)
ax.scatter(means[i], i, color=color, s=18, zorder=4)
ax.axvline(TRUE_MU, color="navy", lw=2.5, linestyle="--",
label=f"True μ = {TRUE_MU}")
ax.set_xlabel("μ", fontsize=12)
ax.set_ylabel("Experiment Index", fontsize=12)
ax.set_title(
f"Figure 2: 95% Confidence Intervals --- {n_experiments} Repeated Samples\n"
f"Coverage Rate = {coverage_rate*100:.1f}% (Expected ≈ 95%)",
fontsize=12, fontweight="bold"
)
green_patch = mpatches.Patch(color="#2ecc71", label=f"Contains True μ ({covers.sum()})")
red_patch = mpatches.Patch(color="#e74c3c", label=f"Misses True μ ({(~covers).sum()})")
ax.legend(handles=[green_patch, red_patch,
plt.Line2D([0], [0], color="navy", lw=2, linestyle="--",
label=f"True μ = {TRUE_MU}")],
fontsize=10)
plt.tight_layout()
plt.savefig("fig2_ci.png", bbox_inches="tight")
plt.show()
# ════════════════════════════════════════════════════════════════════════════
# 图3:样本量对估计精度的影响 ------ 偏差与方差随 n 的变化
# ════════════════════════════════════════════════════════════════════════════
sample_sizes = [5, 10, 20, 50, 100, 300]
n_sim = 2000
mle_biases, mle_vars, unbiased_vars = [], [], []
for n in sample_sizes:
mle_sigmas, unb_sigmas = [], []
for _ in range(n_sim):
s = np.random.normal(TRUE_MU, TRUE_SIGMA, n)
mle_sigmas.append(np.std(s, ddof=0))
unb_sigmas.append(np.std(s, ddof=1))
mle_biases.append(np.mean(mle_sigmas) - TRUE_SIGMA)
mle_vars.append(np.var(mle_sigmas))
unbiased_vars.append(np.var(unb_sigmas))
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
fig.suptitle("Figure 3: Bias & Variance of σ Estimators vs Sample Size",
fontsize=13, fontweight="bold")
axes[0].plot(sample_sizes, mle_biases, "o-", color="tomato", lw=2,
label="MLE Bias (÷n, biased)")
axes[0].axhline(0, color="gray", linestyle="--")
axes[0].set_xlabel("Sample Size n")
axes[0].set_ylabel("Bias = E[σ̂] − σ")
axes[0].set_title("Bias of MLE σ̂")
axes[0].legend()
axes[1].plot(sample_sizes, mle_vars, "s-", color="tomato", lw=2,
label="Var(MLE σ̂) ÷n")
axes[1].plot(sample_sizes, unbiased_vars, "^-", color="steelblue", lw=2,
label="Var(Unbiased S) ÷(n-1)")
axes[1].set_xlabel("Sample Size n")
axes[1].set_ylabel("Variance of Estimator")
axes[1].set_title("Variance Comparison")
axes[1].legend()
plt.tight_layout()
plt.savefig("fig3_bias_var.png", bbox_inches="tight")
plt.show()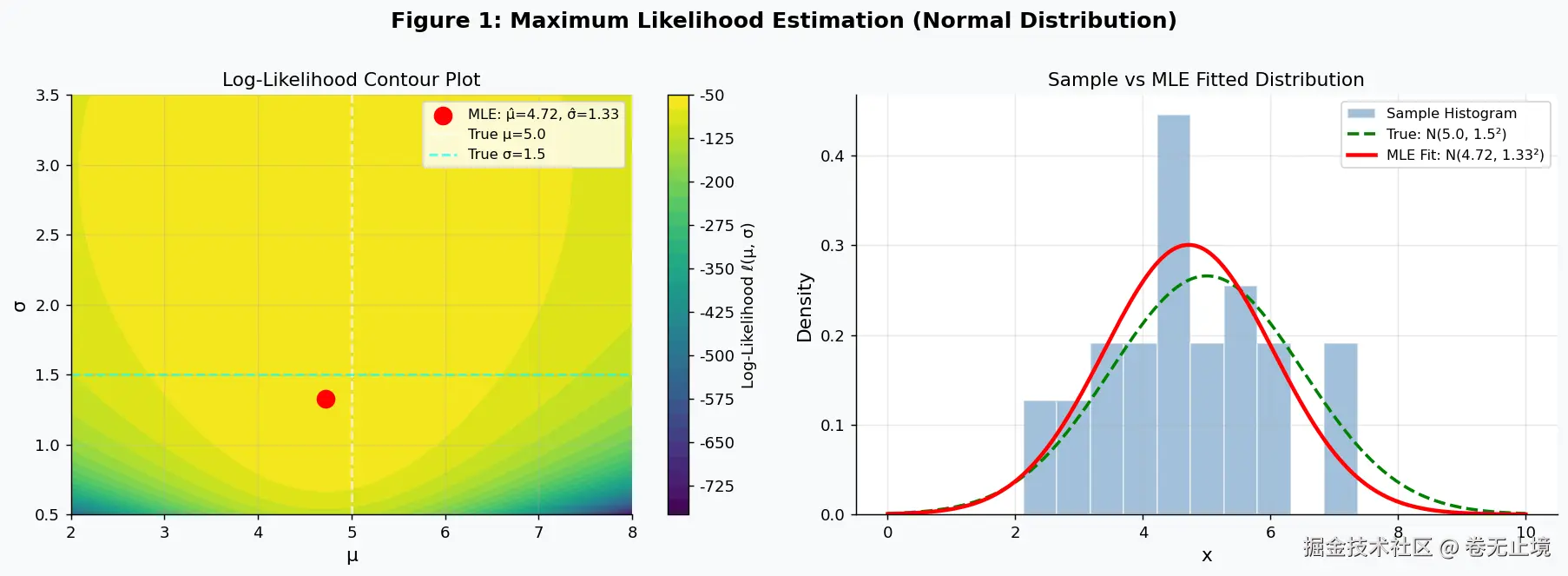
ini
==================================================
样本量 n = 30
MLE 均值估计: μ̂ = 4.7178 (真值 5.0)
MLE 标准差估计: σ̂ = 1.3273 (真值 1.5,有偏)
无偏标准差估计: S = 1.3500 (除以 n-1)
==================================================
五、工程里真正用得上的地方
参数估计不是课本上的习题,它贴着工程实践的皮肤生长。
| 应用场景 | 待估参数 | 常用方法 | 工程意义 |
|---|---|---|---|
| 产品寿命分析 | 威布尔分布 β,η | MLE | 预测故障率、制定维护计划 |
| 质量控制(SPC) | 过程均值 μ、标准差 σ | 矩估计 + 控制图 | 判断过程是否受控 |
| 材料强度测试 | 正态分布 μ,σ2 | t 区间估计 | 确定安全系数 |
| 传感器校准 | 系统误差 δ、随机误差 σ | 最小二乘 + MLE | 提高测量精度 |
| 可靠性工程 | 失效率 λ(指数分布) | MLE + 置信区间 | 计算 MTBF |
每一行背后都是真实的工程决策:这批零件能不能出厂?这台设备还能撑多久?这条生产线的波动是偶然还是系统性的?参数估计给不了你确定性的答案,但它能告诉你,你的判断建立在多扎实的数据基础上。
六、几个值得反复咀嚼的结论
读到这里,有三个点可以带走:
MLE 的 σ^2 是有偏的。 除以 n 而非 n−1,在小样本时会系统性地低估真实方差。工程计算里,方差估计请用样本方差 S2。
置信区间的精度代价是 n 。 区间宽度正比于 1/n ,样本量翻 4 倍,精度才提升一倍。这是采样成本的硬约束,没有捷径。
MLE 的不变性是个实用礼物。 想估计标准差?对方差的 MLE 直接开根号,结果就是标准差的 MLE,不需要重新推导。这个性质在复合参数估计里省了大量功夫。
归根结底,参数估计做的事情,和工程师每天做的事情本质上是一样的:在信息不完整的条件下,做出尽可能合理的判断,并清楚地知道这个判断的边界在哪里。