我是 Claude Code 铁杆用户!
最近我遇到了个棘手的事情,就是 Opus4.8 上下文管理和压缩出现了问题。
出现了对话卡死无法压缩的情况。
这个事情事关"省钱"和"降智",必须搞搞清楚!

目前已经基本解决了,所以做个笔记,并和大家分享一下!
1、默认 100 万上下文
100 万上下文,现在还是很多公司的卖点,尤其是国产模型都开始慢慢支持 1M 上下文了,都在宣传 100 万上下文有多么厉害。
其实 Claude Code 和 Opus 早就支持了,大概在 3 月份左右,而且是默认就是1M了。
上下文大了确实有好处,能塞很多东西,不用动不动就压缩了。
但是硬币都有两面。
上下文大了降智且烧Tokens,烧Tokens就费钱,降智就费项目。 这是大事情!
我实实在在遇到了这两种情况。
有一次我把上下文干到了 75~80 万左右,然后模型明显降智,出现了弱智行为。有一个简单问题一直搞不好!
另一个情况是,这么大的上下文缓存超时后,一句话把我40%配额全部烧完,还没有任何结果,这种感觉太糟糕了!
2、设置成 200K 上下文
自从这个事情之后,我就一直在控制上下文。几个问题解决了,就重启一个对话。
然后 Opus4.8 更新来了,我发现一个很神奇的事情:Claude 客户端默认把上下文设置成了 200K,用起来超爽,还没满就会自己压缩,根本不用操心任何事情。
但是,一个更新,又变成 1M 上下文了。实在搞不懂,它们的策略是什么!
这么动来动去,就比较难搞了。没办法,看来是要自己修改参数来解决这个问题了!
我早就听说过,是有参数可以控制的!
查了一下可以通过环境变量来控制:
ini
CLAUDE_CODE_DISABLE_1M_CONTEXT=1Windows 平台,为了省事儿,我是手动添加了环境变量:
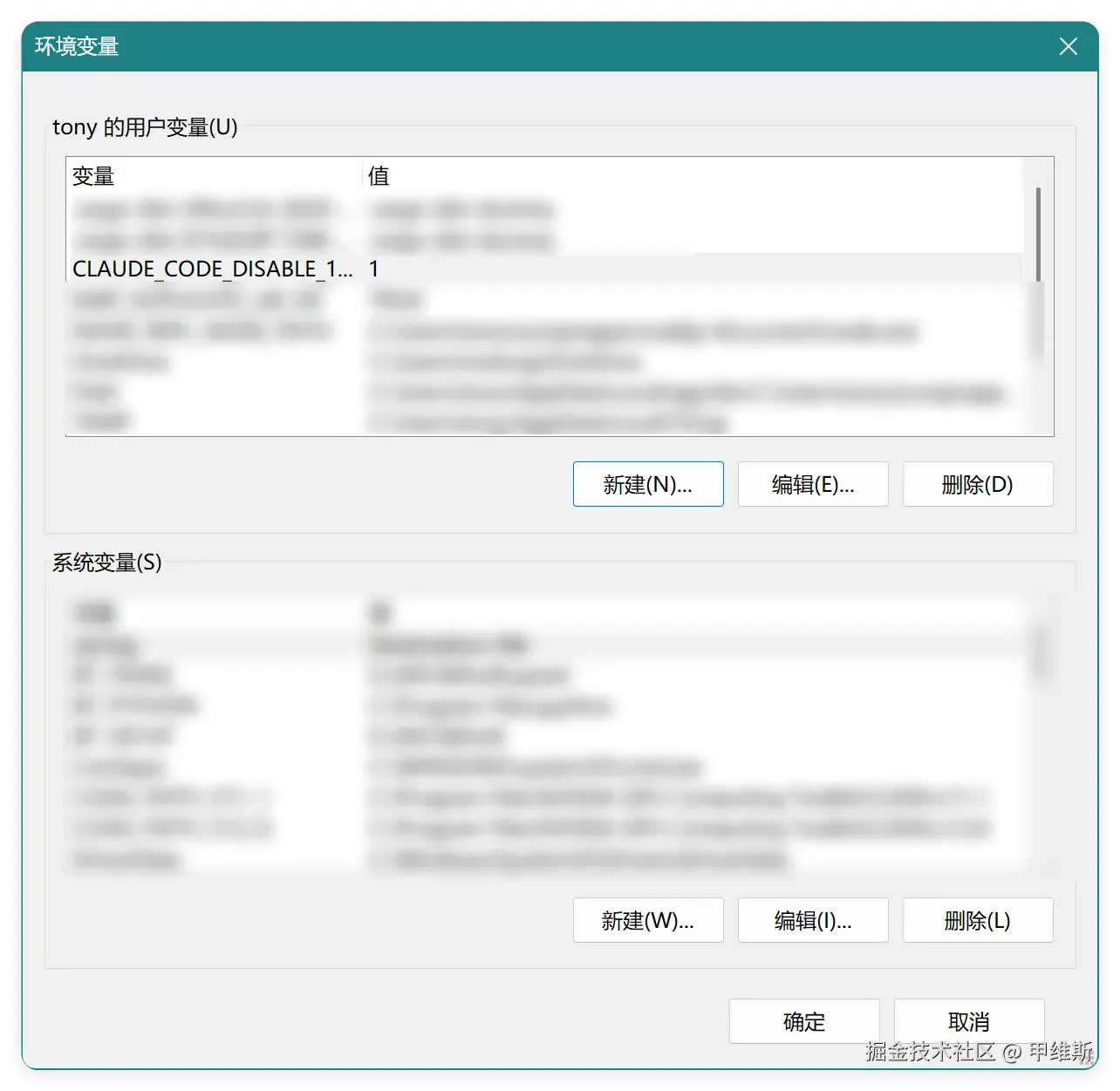
本来以为这样就可以高枕无忧了,但是新的问题来了。
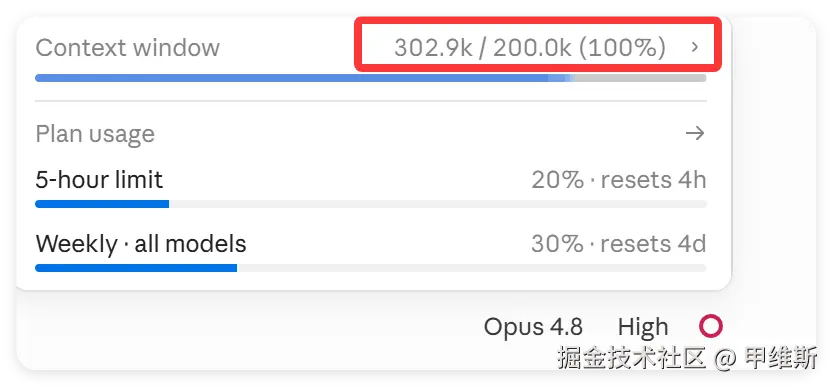
从图中可以看到,上限已经是 200K 了,但是实际上下文已经干到了 302.9K。明显超了,这个逻辑就不对劲啊!
我期望它还没到之前就自己开始压缩了!
但是实际情况不是这样,我也不清楚是什么原因。
我跟 Opus4.8 沟通了一下,它建议我直接修改配置文件:
javascript
~/.claude/settings.json具体的修改内容如下:
json
{
"env": {
"CLAUDE_CODE_DISABLE_1M_CONTEXT": "1"
},
"autoCompactEnabled": true,
"autoCompactWindow": 200000
}
核心:让 auto-compact 按 20 万的窗口算百分比触发,而不是底层 1M。这才真正把压缩阈值摁到 200K。
也就是,单单关闭 1M 上下文还不够,还要设置压缩窗口为 200000!然后确保自动压缩已经启动了,一般是默认启动的。
生效方式:
- 完全重启 Claude(退出进程重开,不是 Ctrl+R/重载界面)。环境变量只对新会话生效。
- 用
/status或状态行确认窗口为 200K。 - 正常聊到接近 20 万时,应在 ~64--75%(约 13--15 万)自动压缩,不再冲过 200K。
3、自动压缩
终于,这回是 Opus4.8 自己读的文档,自己设置的,应该万无一失了。
但是,新的问题又出现了:
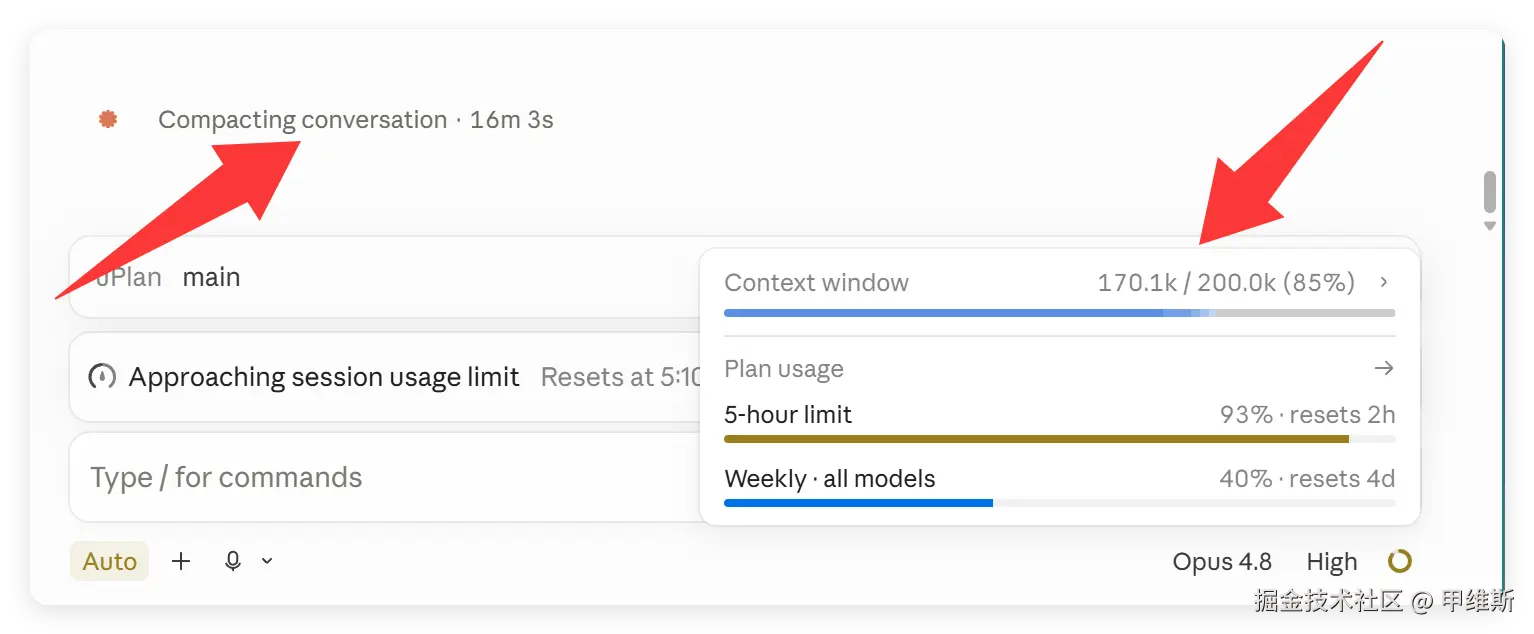
这次确实没有超过 200K,而是在 85% 也就是 170K 的时候触发自动压缩,然后压了 16 分钟还没压完,基本上就是卡死的状态。
另外还出现了这种情况:
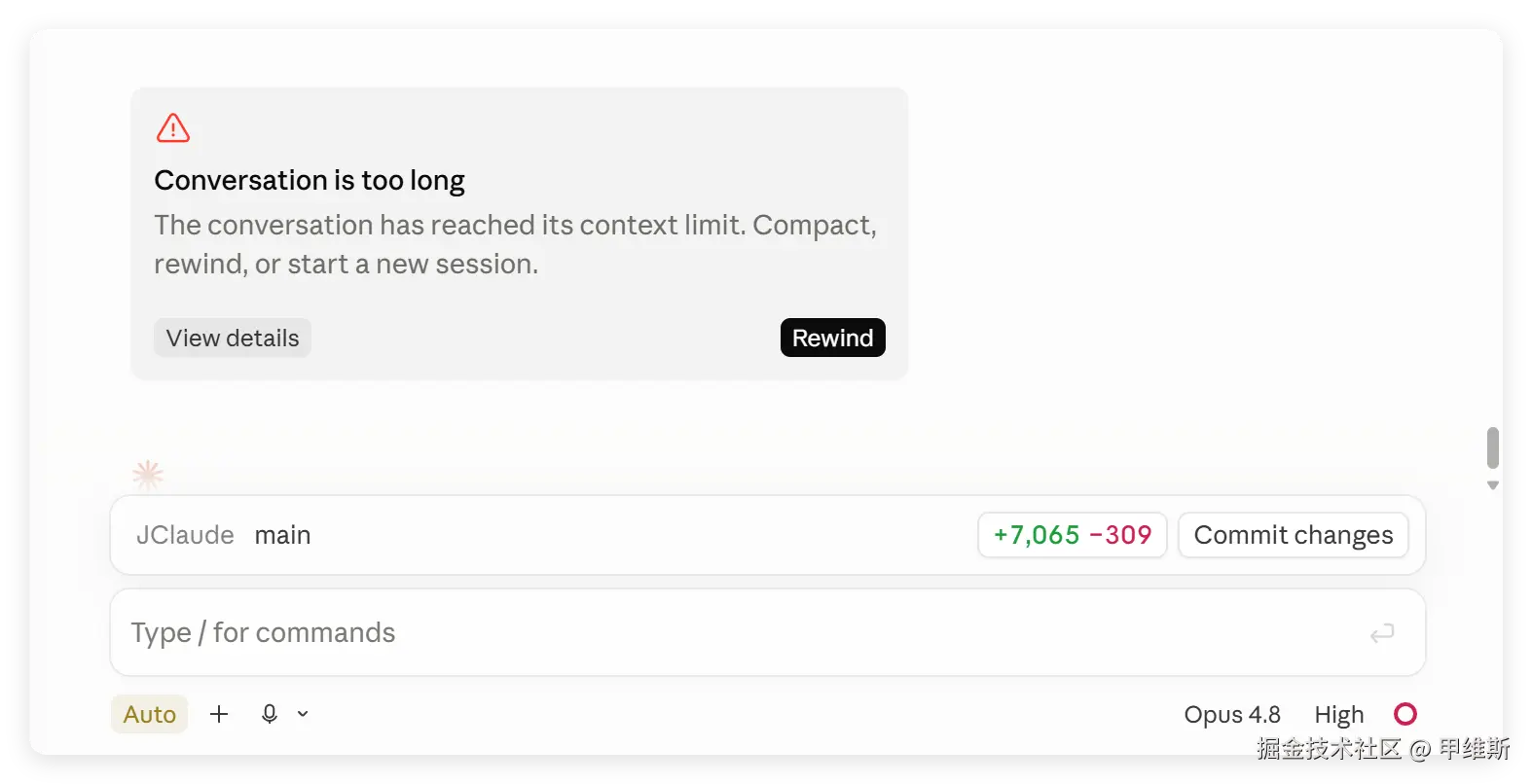
直接停下来什么都不干了,就说上下文太长了。让我压缩或者开启新会话。如果我压缩就直接卡死。
终端也是这样:
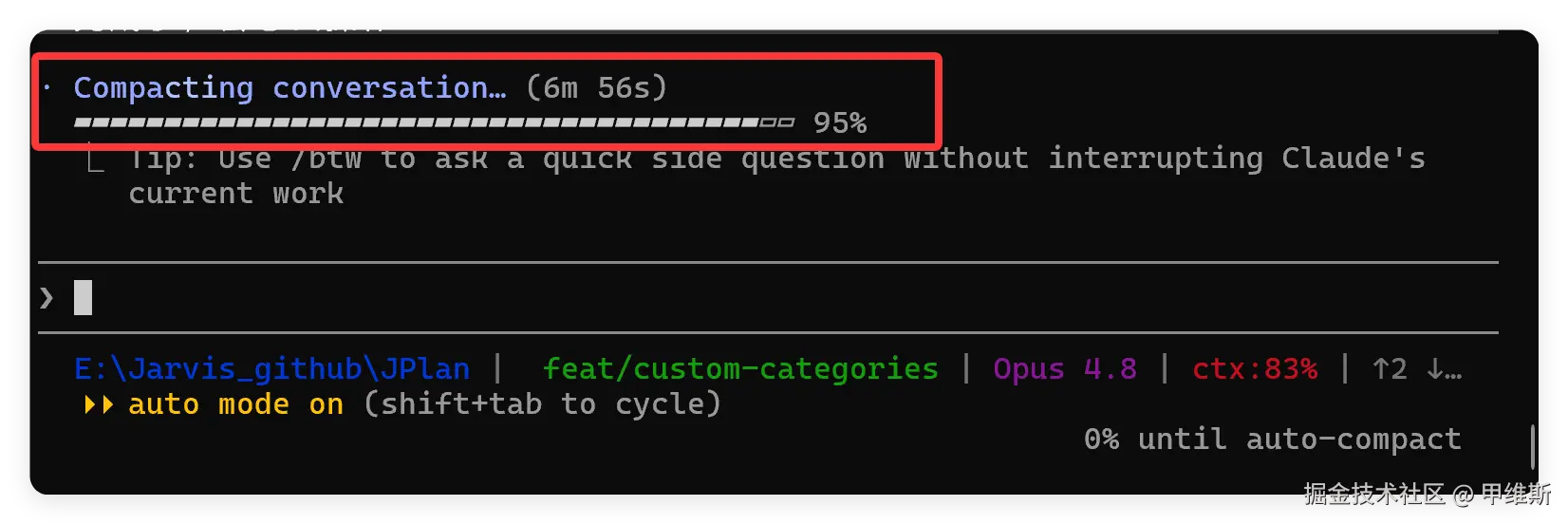
终端好一点,可以看到压缩比例。基本上是上下文用掉 83% 就自动开压缩,然后进度条从 0% 跑到 95% 就不动了。
这又要被搞死了,好多任务开发到一半,就无法继续了,因为上下文达到了上限,又无法压缩。
这个时候要么重新开到 1M 上下文,要么重启会话,我都不甘心啊!
我怀疑这个地方是有 BUG 的!
跑去问了一下 Grok,它说其他人也有遇到。
并给了我三种方案:
go
1、立即中断:
按 Esc 两次尝试回退几条消息,再试 `/compact`。
如果卡死,Ctrl + C 中断当前操作,然后尝试手动 /compact。
2、重启会话恢复(最有效 workaround):
完全关闭终端。
重新打开,用 `claude --resume` 选择对应会话。
立即切换模型(输入 `/model` 换成 Sonnet 4.5 或其他),发一条简单消息如 "What happened?"。
成功压缩后,再切回你原来的模型继续。很多用户说这个能强行让压缩通过。
3、预防为主(强烈建议):
提前手动压缩:在上下文到 60-70% 时就主动 `/compact`,别等到 90%+ 自动触发。
用 `CLAUDE.md` 文件固定核心规则和项目信息(压缩时会优先保留)。
定期 `/clear` + 手动总结关键点,或导出历史新建会话。
少让 Claude 输出巨型日志;必要时用工具过滤输出。第一个 Esc,我怕影响代码,没有试过。
后面查了一下,说可以回退消息,但是不回退代码。
我选择了第二种方式。
因为它括号里说了这是最有效的 workaround。翻译一下,最有效的"骚操作"。
骚操作就是好用:
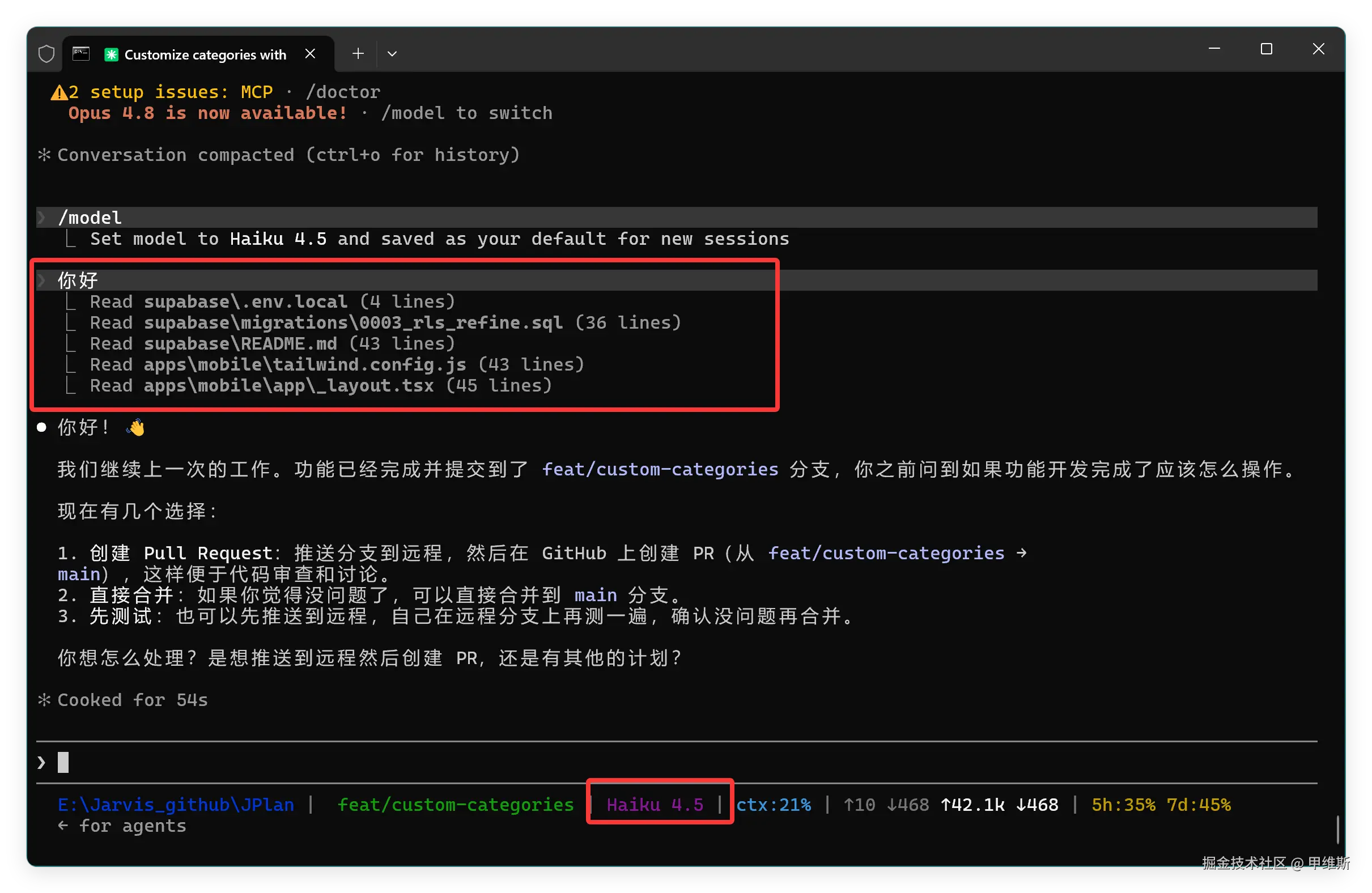
真的成功了!Opus4.8 压了半天压不好,切换到 Haiku4.5 立马搞定!
再切回去,对话就能继续了,好像配额也就少了 2%,这个完全可以接受!
另外 Grok 也说了,可以手动压缩,别等到自动压缩!
问题好像解决,虽然但是......
前几天为什么啥都不用干,就那么丝滑呢,不用自己配置 200K,不用自己压缩,全自动推进,不降智,消耗也很低。
4、补充知识
我在压缩的过程中就产生一个疑问:压缩到底是发生在本地,然后传到服务端,还是服务端完成,传给本地?
另外的疑问是压缩过程中要不要联网,压缩一次要消耗多少 Tokens。
我查询的结果是,压缩需要联网:
Claude Code 的上下文压缩(
/compact或自动 compaction)是 server-side 操作,由 Anthropic 的 API 完成。Claude 会把当前对话历史发送到服务器,让模型生成一个总结(summary),然后把旧历史替换成这个总结。如果你处于离线状态(无网络),压缩无法进行,会报错或卡住。
关于 Tokens 消耗的情况如下:
一次 compaction 的额外消耗 :通常在 几千到几万 Tokens(input + output)。
- 典型例子:输入 ~150k--180k tokens 的历史 → 输出一个 3k--5k tokens 的总结。
- 这部分会单独计费/计入你的使用量。
压缩后,后续对话的输入 Tokens 会大幅减少,所以长期来看是节省的。
但单次压缩本身是比较贵的,尤其是频繁压缩时。
精打细算过日子太难了,不压不行,压不好也费钱!1M 太贵,200K 老是压缩也不便宜。
这个问题就和 1 小时缓存和 5 分钟缓存一样,每种方法都有各自的消耗点。
5 分钟缓存 + 1M 上下文,控制不好节奏,分分钟消耗完配额!
我感觉设置一个定时任务,每四分钟打一次招呼,这样最省。
当然设置成 200K 之后,心理负担轻很多,即便过期了,重新载入的数据也比较小!
按这种方式使用了一阵子。
Opus4.8 配 High,现在还是很经用的,我上午改了一堆功能,只用了 50%!
大概有十几轮对话了吧,Claude Code 不会是用了什么黑科技,或者默默增加了配额吧!以前,有时候两三轮对话,就没有配额了!
当然也有可能是我上下文和缓存管理优秀,节奏把握的比较好,用的全是缓存!