前几天有个做运营的朋友找我诉苦:
"我们上周开董事会,财务汇报的营收数字,和我们部门报的差了将近200万。两边吵了半天,最后发现是对'成交'的定义不一样------财务算的是到账,我们算的是签合同。但问题是,这两个数字到底是哪张表、经过什么处理算出来的,没人说得清楚。"
这个问题,本质上不是"谁对谁错"的问题,而是数据没有"血缘"------没有人知道这个数字从哪来、经过了什么加工、和其他数据有什么关系。
这就是今天要聊的主题:数据血缘。
从一块牛肉说起
现在买牛肉,讲究的超市都会提供溯源码------扫一下,能知道这块肉来自哪个省、哪个养殖场、哪头牛、几号出栏的。
这套机制存在的原因很简单:如果某批牛肉出了问题,你得能追回去,找到根源,把有问题的批次全部召回,而不是把整个冷柜都清空。
数据血缘,做的是同一件事。
一个数字出现在报表上,它不是凭空冒出来的。它可能来自某个业务系统的原始记录,经过了数据仓库的清洗和加工,再经过BI工具的汇总计算,最终呈现在你眼前。数据血缘,就是把这条"来路"完整记录下来------这个数字从哪张表来,经过了哪些处理步骤,最终流向了哪些报表和应用。
简单说:数据血缘就是数据的"族谱"。
没有血缘,会发生什么?
开头那个故事,是最常见的一种情况------数字打架,查不清来源。但血缘缺失带来的麻烦,远不止这一种。
数据出错了,问题在哪?
报表里有个关键指标突然异常,比昨天少了30%。运营团队开始排查:是采集出了问题?还是加工逻辑有bug?还是源头数据本身就错了?
没有血缘的情况下,这个排查过程要靠人工一张表一张表地往上追,快则几小时,慢则几天。如果这个指标牵涉到多个上游系统,那基本上就是场"数据考古"。
系统要升级,敢动吗?
公司要对某个核心业务系统做升级,需要改动几张关键表的结构。技术团队面临一个两难:这张表被多少下游系统依赖着?改动之后会影响哪些报表、哪些数据流程、哪些业务应用?
没有血缘,这个问题没有人能回答得准。最常见的处理方式是:开会讨论,凭经验估,再多留几个缓冲期观察。整个过程既低效,又充满风险。
监管来审计,怎么举证?
金融、医疗、政府等行业的数据监管越来越严格,监管部门会要求企业说明某份数据报告的来源和处理过程。没有血缘,这类审计需求就只能靠人工整理文档来应对------费时费力,还不一定准确。
这三个场景有个共同的本质:数据在流动,但流动的路径不透明。 血缘要解决的,正是这个透明度问题。
血缘能做到什么程度?
很多人听到"数据血缘",脑海里浮现的是一张线条纵横的流程图,从左到右画出数据从哪来到哪去。这是血缘最基础的形态,但远远不是终点。
真正有用的血缘能力,应该分三个层次来看:
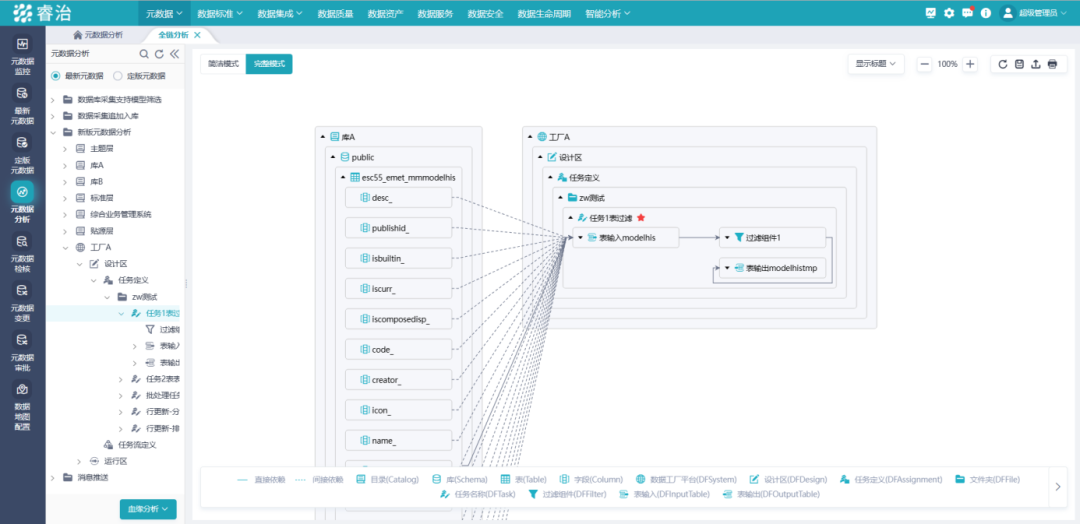
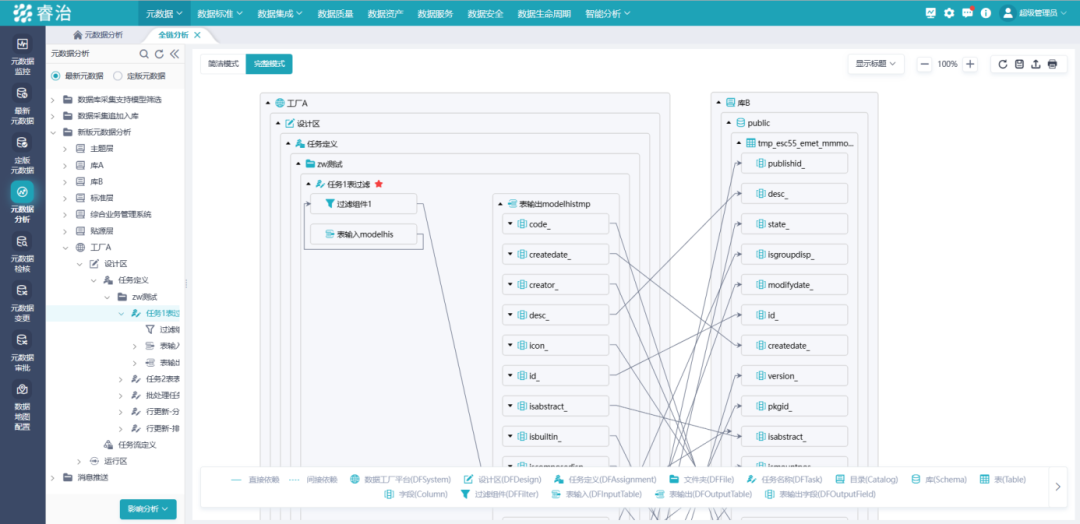
**第一层:表级血缘。**知道A表的数据来自B表和C表,B表又来自D系统的原始日志。这是入门级,能回答"大概从哪来",但粒度太粗,出了问题还是定位不到具体原因。
**第二层:字段级血缘。**报表里"华东区客户复购率"这个字段,是由哪张表的哪个字段,经过什么计算逻辑得出来的。字段级血缘才是真正能用于排查问题的粒度------不是"这张表有问题",而是"这个字段的计算逻辑在这一步引入了错误"。就像你能查到一块牛肉来自哪头牛,而不只是来自哪个省------粒度粗的血缘,出了问题还是找不到根。
**第三层:跨系统全链追踪。**从最上游的业务系统原始记录,一路追到最下游的报表展示,中间经过的每一个数据库、每一个ETL加工步骤、每一个数仓层级,都在血缘链路上有完整记录。企业的数据系统越复杂,这个能力就越关键。但跨系统追踪有个前提:平台能接入的数据源种类要足够广,Oracle、MySQL、Hive、各类ETL工具、报表系统------接不到的地方,血缘链路就会断。像睿治数据治理平台这类软件,支持近60种数据源的元数据采集,覆盖数据库、ETL工具、报表工具等各类系统,血缘链路才能真正从源头连到终端,不断链。
**影响分析:血缘的另一面。**血缘不只是往上追,还要能往下评估。当你要改动一张表的结构,系统应该能告诉你:这次改动会波及哪些下游任务、哪些报表、哪些业务指标。往上溯源、往下评估,两个方向合在一起,才构成完整的血缘管理。
为什么说它是数据治理的核心?
数据治理包含很多方面------数据标准、数据质量、元数据管理、数据安全......血缘为什么能被称为"核心"?
答案在于:血缘是把所有这些能力串联起来的那条线。
数据质量出了问题,要靠血缘来溯源;数据标准发生变更,要靠血缘来评估影响范围;元数据采集进来,血缘决定了这些元数据之间的关联关系是否完整。
没有血缘,其他治理能力就像一个个孤立的工具------各自能发现问题,但发现了之后不知道怎么处理,处理完了也不知道有没有漏掉什么。
有了血缘,数据治理才从"分散的工具集合"变成了一个真正有联动能力的体系。
打个不那么严谨但很直观的比方:数据标准是规则,数据质量是体检,血缘是整套血管图谱。 规则再完善、体检再频繁,如果不知道血液怎么流、流到哪,出了问题还是找不到病灶。
这不只是理论上的说法。某金融机构在引入亿信华辰睿治数据治理平台、建立完整血缘体系后,数据质量问题的发现时效从原来的"以周计"直接降到了"分钟级"------根本原因就在于,血缘把各个治理模块真正连通了,问题一旦触发,溯源路径是现成的,不再需要人工一层一层往上找。
写在最后
数据血缘,听起来是个技术概念,但它解决的是一个所有和数据打交道的人都会遇到的问题:当一个数字出现在你面前,你敢相信它吗?你知道它从哪里来吗?当这个答案是"不确定"的时候,所有基于这个数字的判断,都站在沙地上。数据血缘要做的,就是把沙地变成实地。