引言
在人工智能飞速发展的今天,大型深度学习模型在各个领域取得了令人瞩目的成就。从 GPT 到 BERT,从 ResNet 到 ViT,模型参数量从百万级飙升到万亿级。然而,当我们试图将这些强大的模型部署到手机、边缘设备或生产环境时,一个严峻的问题摆在面前:模型太大了!
一个典型的 BERT-base 模型有 1.1 亿参数,占用存储空间约 400MB;GPT-3 更是达到了 1750 亿参数。这样的模型不仅需要大量的存储空间,推理速度也慢得让人无法接受。想象一下,如果你的手机 APP 每次调用 AI 都要等待几秒钟,用户体验会有多差?
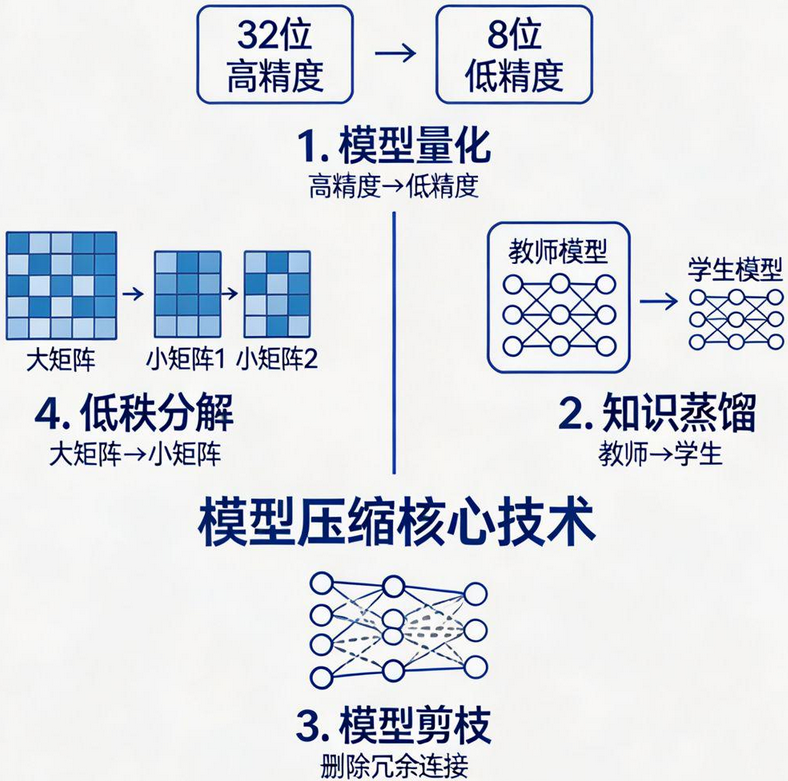
这就是模型压缩技术诞生的背景。今天,我们将系统地讲解模型压缩的四大核心技术:量化、蒸馏、剪枝、低秩分解 ,并深入剖析知识蒸馏中至关重要的KL 散度损失函数。
一、模型压缩概述
1.1 什么是模型压缩?
模型压缩,顾名思义,就是在对模型性能影响不大 的前提下,尽可能减少模型的存储空间、降低参数量、提升推理速度,让模型变得更小、更快。
通俗类比:模型压缩就像是给行李箱打包。原来你带了一大堆东西出门,现在通过巧妙的折叠、整理,用更小的箱子装下几乎所有的必需品,重量轻了,携带方便了,但该有的东西一样不少。
1.2 模型压缩的本质
模型压缩的本质可以概括为两点:
-
模型变小:减少参数量,降低存储空间占用
-
模型变快:提高推理速度,降低计算资源消耗
就像数据压缩有 "压缩比" 一样,模型压缩也有类似的衡量指标。好的压缩技术能在压缩 10 倍甚至 100 倍的情况下,精度损失控制在 1% 以内。
二、模型量化:精度换效率的艺术
2.1 量化的核心思想
模型量化的核心动作:将高精度参数(通常是 32 位浮点数 FP32)转换为低精度参数(通常是 8 位整数 INT8)。
通俗类比:这就像是把一张高清照片(每个像素用 32 位表示)压缩成标清照片(每个像素用 8 位表示),人眼几乎看不出差别,但文件体积缩小了 4 倍!
2.2 量化的效果
-
✅ 模型体积变小:FP32→INT8,体积直接缩小 75%
-
✅ 占用资源更少:内存带宽需求大幅降低
-
✅ 推理速度提升:整数计算比浮点计算快得多
2.3 三种量化方式对比
(1)量化感知训练(QAT, Quantization Aware Training)
-
时机:训练过程中进行
-
特点:量化模拟贯穿前向 / 后向传播,边训练边量化
-
追求目标:极致精度
-
适用设备:高端 GPU/NPU 设备
通俗类比:就像是减肥过程中一边运动一边调整饮食方案,全程监控,确保健康瘦身。
(2)静态量化(PTQ, Post-Training Static Quantization)
-
时机:训练结束后,通过校准步骤执行
-
特点:先用一批校验数据跑一遍,寻找数据分布规律,再进行压缩
-
追求目标:精度与便捷的平衡
-
适用设备:中端设备
通俗类比:这就像是 "量体裁衣"------ 先测量你的身材数据,再根据这些数据为你定制最合适的衣服。
(3)动态量化(DQ, Dynamic Quantization)
-
时机:训练结束后,推理时动态执行
-
特点:保持高精度,只在推理时临时压缩加速
-
追求目标:极致便捷
-
适用设备:边缘设备、CPU 场景
通俗类比:就像是坐飞机时托运行李,平时正常使用,需要托运时才临时打包压缩。
2.4 量化选择策略
-
首选静态量化(PTQ):大多数场景的最佳选择
-
如果精度损失较大:升级到量化感知训练(QAT)提升精度
-
CPU 多的业务场景:特别是 BERT、LSTM 等处理变长文本的 NLP 任务,推荐动态量化(DQ)
三、知识蒸馏:名师出高徒
3.1 蒸馏的核心思想
知识蒸馏的核心:用已经训练好的大模型(教师模型)的输出,去训练一个小模型(学生模型),让小模型 "模仿" 大模型的行为。
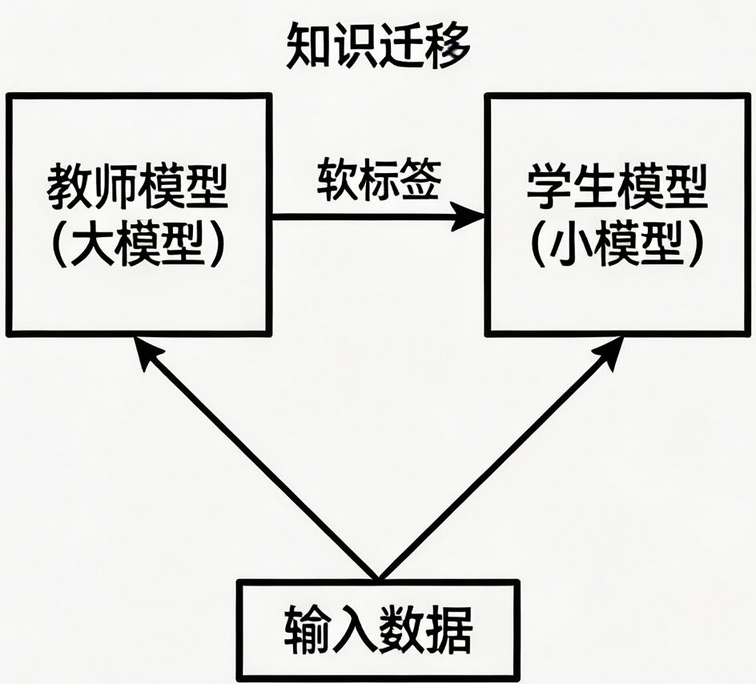
通俗类比:这就像是一位经验丰富的老教授(教师模型)带一个年轻学生(学生模型)。老教授知识渊博但年纪大了行动不便,学生年轻敏捷但经验不足。通过老教授的悉心指导,学生既能保持年轻敏捷的优势,又能学到老教授的智慧。
3.2 教师模型 vs 学生模型
| 维度 | 教师模型 | 学生模型 |
|---|---|---|
| 定义 | 复杂的、高性能的已训练大型深度神经网络 | 简化的、小型的未训练模型 |
| 参数量 | 大(通常是学生的 10-100 倍) | 小 |
| 特点 | 能学习复杂的特征和关系 | 适用于资源受限场景 |
| 推理速度 | 慢 | 快 |
3.3 蒸馏的效果
小模型参数量远小于大模型,但推理速度快,性能可以逼近大模型。这是知识蒸馏最神奇的地方!
3.4 三种蒸馏方式
(1)硬标签蒸馏
学生模型直接学习教师模型输出的硬标签(one-hot 向量)。
-
损失函数:交叉熵损失
-
硬标签:传统监督学习中使用的确定性分类标签
通俗类比:老师直接告诉你 "这道题选 C",你只记住答案就行。
(2)软标签蒸馏
学生模型同时学习真实标签 和教师模型输出的软标签(概率分布),将两种损失相加来更新参数。
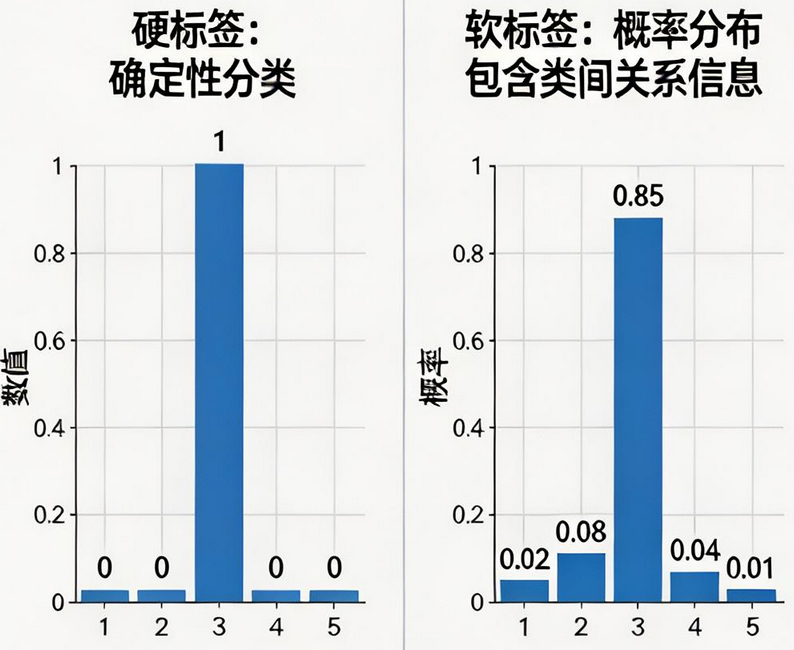
软标签的魔力:它不仅告诉你 "这道题最可能选 C",还告诉你 "选 B 的概率也有 8%,选 D 有 4%"。这些类间关系信息是硬标签完全没有的!
通俗类比:老师不仅告诉你正确答案,还帮你分析每个选项的迷惑性,让你真正理解知识点。
(3)中间层蒸馏
让学生学习教师模型中间层的特征表达方式,具备更相似的 "思考过程"。
- 中间层:神经网络中非最终输出的隐藏层表示(特征图或向量)
通俗类比:老师不仅教你答案,还教你解题思路和思维方法,让你 "知其然更知其所以然"。
四、模型剪枝:砍掉冗余的 "赘肉"
4.1 剪枝的核心思想
模型剪枝:删除模型中对整体识别影响不大的神经元或者连接,直接减少参数量。
通俗类比:这就像是给树木修剪枝叶,剪掉那些不结果实、只消耗养分的枯枝败叶,让树木长得更健康。
4.2 剪枝的效果
-
✅ 直接减少模型参数量
-
✅ 减少模型存储空间
-
✅ 提高推理速度
-
✅ 性能降低通常很小
深度学习模型往往存在大量的参数冗余 ------ 很多权重实际上对最终结果几乎没有贡献。剪枝就是找出这些 "吃白饭" 的参数,果断砍掉!
五、低秩分解:化整为零的智慧
5.1 低秩分解的核心思想
低秩分解:将一个大的权重矩阵,通过数学上的低秩分解,用两个或多个小矩阵来表示。
通俗类比:这就像是把一个大箱子拆成几个小箱子,总体积不变甚至更小,但搬运起来方便多了。
举个简单的数学例子:
-
原来:一个 1024×1024 的矩阵,参数量 = 1,048,576
-
分解后:1024×64 + 64×1024,参数量 = 131,072
-
压缩比:8 倍!
5.2 低秩分解的效果
-
✅ 大幅减少模型参数量
-
✅ 显著提高推理速度
-
✅ 特别适用于全连接层和卷积层
六、KL 散度损失详解:知识蒸馏的灵魂
在知识蒸馏中,KL 散度是最核心的损失函数。没有 KL 散度,软标签蒸馏就无从谈起。让我们深入理解这个神奇的数学工具。
6.1 KL 散度的数学定义
KL 散度(Kullback-Leibler Divergence),又称相对熵,用于衡量两个概率分布之间的差异程度。
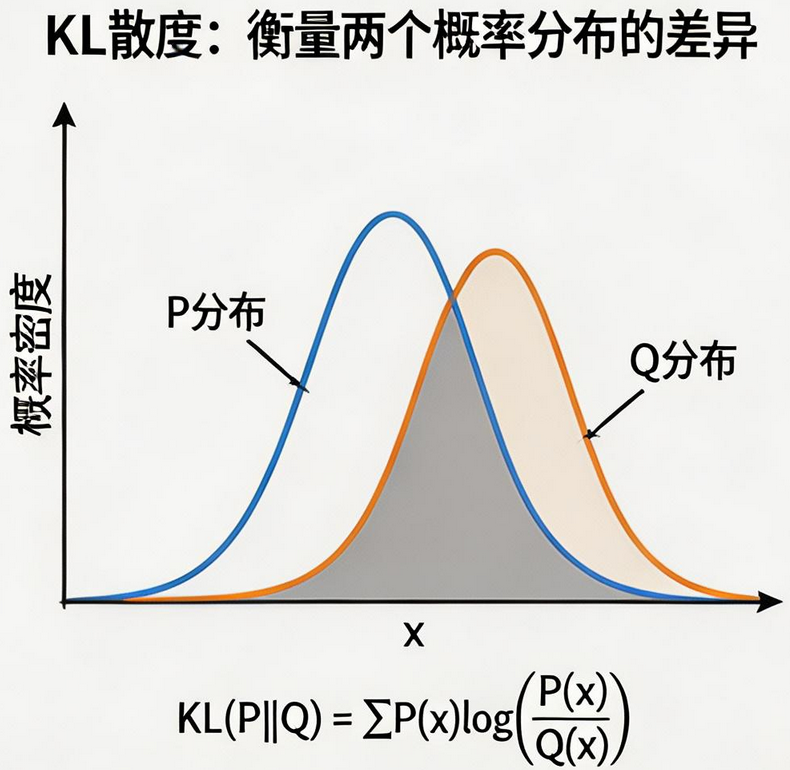
对于离散概率分布 P 和 Q,KL 散度定义为:
D K L ( P ∣ ∣ Q ) = ∑ x P ( x ) log ( P ( x ) Q ( x ) ) D_{KL}(P||Q) = \sum_{x} P(x) \log\left(\frac{P(x)}{Q(x)}\right) DKL(P∣∣Q)=∑xP(x)log(Q(x)P(x))
对于连续概率分布:
D K L ( P ∣ ∣ Q ) = ∫ − ∞ ∞ p ( x ) log ( p ( x ) q ( x ) ) d x D_{KL}(P||Q) = \int_{-\infty}^{\infty} p(x) \log\left(\frac{p(x)}{q(x)}\right) dx DKL(P∣∣Q)=∫−∞∞p(x)log(q(x)p(x))dx
其中:
-
P 是真实分布(教师模型的输出)
-
Q 是近似分布(学生模型的输出)
6.2 KL 散度在知识蒸馏中的作用
在软标签蒸馏中,我们的目标是:让学生模型的输出概率分布 Q,尽可能接近教师模型的输出概率分布 P。
KL 散度在这里扮演了三个关键角色:
-
衡量分布差异:量化学生和教师输出的 "差距"
-
提供梯度信号:指导学生模型参数更新的方向
-
保留类间信息:捕捉软标签中蕴含的丰富知识
6.3 为什么用 KL 散度,而不是其他损失函数?
这是一个非常好的问题。让我们对比一下:
(1)为什么不用 MSE(均方误差)?
MSE 衡量的是数值差异: M S E = 1 n ∑ ( p i − q i ) 2 MSE = \frac{1}{n}\sum (p_i - q_i)^2 MSE=n1∑(pi−qi)2
问题:MSE 对概率分布不友好。概率分布的核心是 "相对关系",而不是 "绝对数值"。
举例:P=0.1, 0.8, 0.1,Q1=0.2, 0.7, 0.1,Q2=0.1, 0.7, 0.2
-
MSE 认为 Q1 和 Q2 差不多
-
但 KL 散度能识别出 Q2 改变了类别相对关系,差异更大
(2)为什么不用交叉熵?
交叉熵: H ( P , Q ) = − ∑ P ( x ) log Q ( x ) H(P,Q) = -\sum P(x)\log Q(x) H(P,Q)=−∑P(x)logQ(x)
问题:交叉熵 = KL 散度 + P 的熵。当 P 固定时(教师模型固定),H (P) 是常数,此时最小化交叉熵等价于最小化 KL 散度。
但 KL 散度的优势:它有明确的 "信息损失" 物理意义 ------ 用 Q 来近似 P 时,平均每个样本损失多少比特的信息。
(3)KL 散度的独特优势
-
信息论意义明确:直接衡量信息损失量
-
非对称性 : D K L ( P ∣ ∣ Q ) ≠ D K L ( Q ∣ ∣ P ) D_{KL}(P||Q) \neq D_{KL}(Q||P) DKL(P∣∣Q)=DKL(Q∣∣P)------ 这正是我们需要的!我们要让学生模仿老师,而不是反过来
-
非负性:KL 散度≥0,当且仅当 P=Q 时取 0
-
对概率分布友好:天然适合处理 softmax 输出
6.4 通俗语言解释 KL 散度
生活化类比 1:天气预报
假设真实天气概率分布 P 是:晴天 0.8, 阴天 0.15, 下雨 0.05
天气预报 Q1 说:晴天 0.7, 阴天 0.2, 下雨 0.1
天气预报 Q2 说:晴天 0.5, 阴天 0.3, 下雨 0.2
KL 散度就是衡量:如果我相信了天气预报,会比知道真相 "多惊讶" 多少次?
显然 Q2 让你更惊讶(KL 散度更大),因为它和真实情况差太远了。
生活化类比 2:翻译质量
P 是原文的意思,Q 是翻译后的意思。
KL 散度衡量的是:翻译稿和原文相比,丢失了多少信息,扭曲了多少原意?
七、总结:模型压缩技术选型指南
7.1 四大技术对比
| 技术 | 核心思想 | 压缩比 | 精度损失 | 实现难度 |
|---|---|---|---|---|
| 模型量化 | 高精度→低精度 | 4× | 小 | 低 |
| 知识蒸馏 | 大模型教小模型 | 10-100× | 极小 | 中 |
| 模型剪枝 | 删除冗余连接 | 5-10× | 小 | 中 |
| 低秩分解 | 大矩阵拆小矩阵 | 4-8× | 小 | 中 |
7.2 实战建议
-
入门首选:先尝试静态量化(PTQ),成本最低,见效最快
-
精度优先:量化 + 蒸馏组合使用,效果 1+1>2
-
极致压缩:量化 + 蒸馏 + 剪枝三管齐下,挑战极限压缩比
-
NLP 场景:优先考虑动态量化 + 知识蒸馏
模型压缩不是单一技术的单打独斗,而是多种技术的组合拳。在实际工程中,往往是多种技术配合使用,才能在精度和速度之间找到最佳平衡点。
希望这篇文章能帮助你理解模型压缩的核心技术。记住:小模型也能有大智慧,关键在于用对方法!
参考资料:
-
Hinton et al. "Distilling the Knowledge in a Neural Network", 2015
-
Jacob et al. "Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference", 2018
-
Han et al. "Learning Both Weights and Connections for Efficient Neural Networks", 2015