(一)引言
我们知道通过比较向量之间的距离可以判断他们相似度,那么在实际应用中该如何实现呢?最朴素的想法就是把查询向量和向量库中每个向量的距离比较一遍,从中选出距离最小的topk个向量作为最相似的向量。但是显而易见,这种方法虽然简单有效,但是计算量大,耗时长。所以我们需要一个更加高效的方法来完成检索。
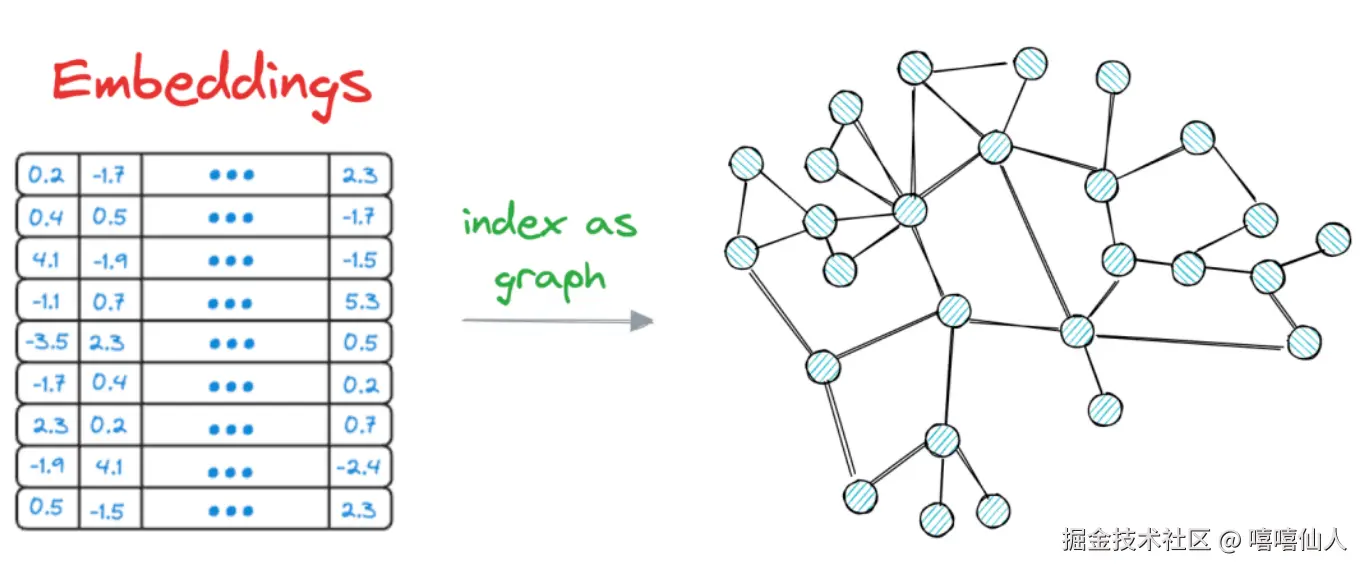
目前业界主流的方法是通过构建图索引 的方式来实现最近邻检索,比较有名的是Hierarchical Navigable Small Word(HNSW)层次化可导航小世界算法。该算法凭借"高维向量下的低延迟、高召回率"成为RAG的首选检索组件。
(二)HNSW算法技术原理
下面主要介绍一下HNSW算法的具体实现。但是在理解 HNSW 之前,必须先理解NSW(可导航小世界算法),它是 HNSW 算法的基础。
(1)可导航视图
HNSW算法核心思想是构建一个图结构,其中每个节点代表一个数据向量,边根据节点的相似性进行连接。HNSW 以这样一种方式组织图表,通过有效地浏览图表来找到近似的最近邻居,从而促进快速搜索操作。
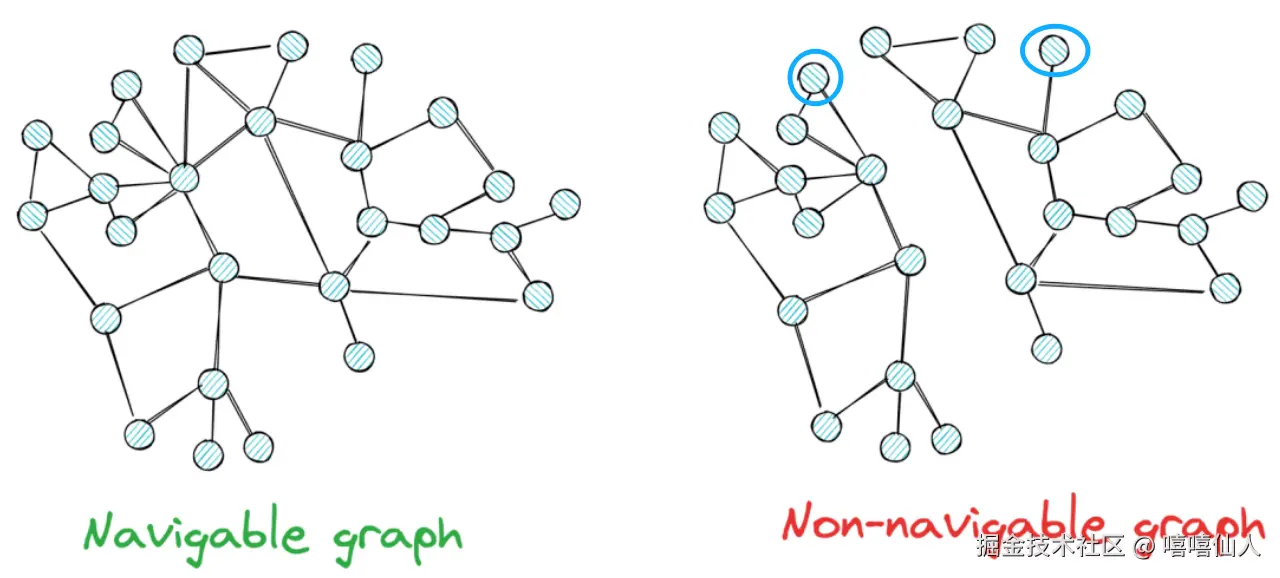
通过以上可导航图和不可导航图可以发现可导航图保证了即使两个点之间没有直接连接,也可以通过临近的节点找到彼此,而不可导航图中间断开,两个蓝色的点之间无法互相到达。
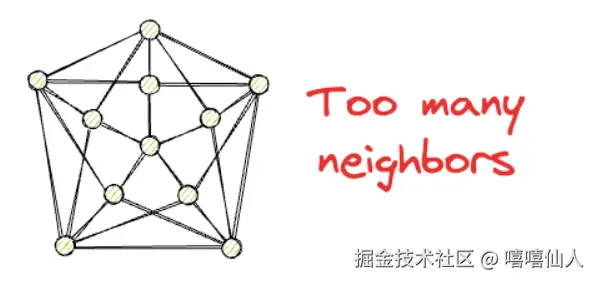
虽然拥有邻居节点方便遍历,但是拥有邻居太多会造成在搜索期间的存储和计算成本过高。因此我们希望有一个类似于小世界网络的可导航图,其中每个顶点只有有限数量 的连接,并且两个随机选择的顶点之间的平均边遍历次数较低。这种类型的图表对于大型数据集中的相似性搜索非常有效。
(2)NSW(可导航小世界)算法
(i)建图
通过随机打乱向量并以随机顺序插入顶点来构建图形。当向图G中添加新顶点V时,它会与图G中距离它最近的K 个现有顶点共享一条边。为了演示方便,这里假设 K=3。
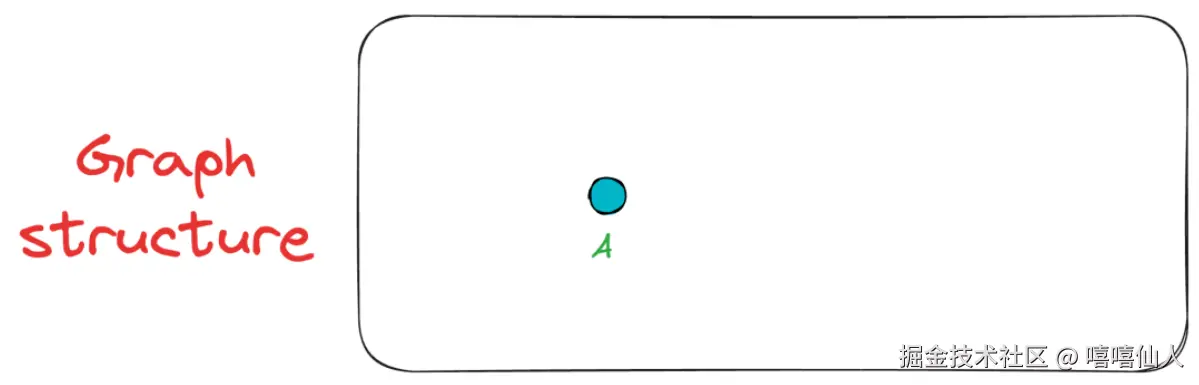
首先插入第一个顶点A。由于此时图中没有其他顶点,因此A保持未连接状态。
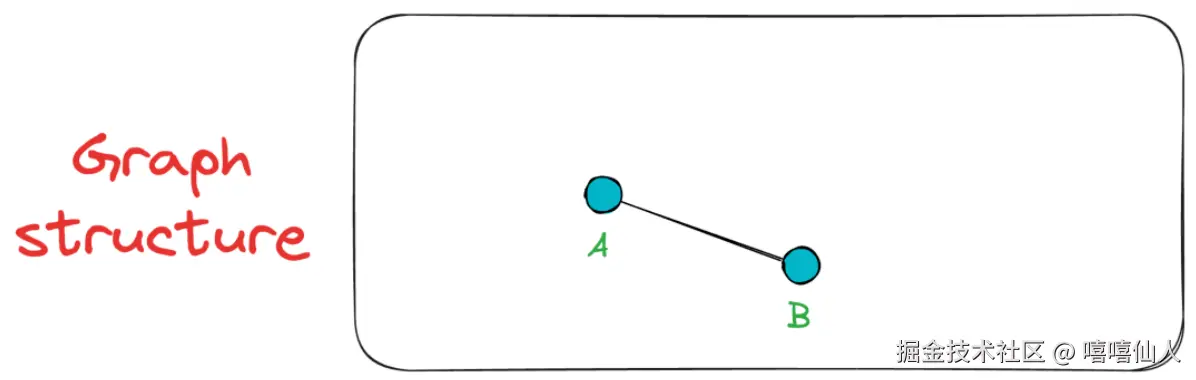
接下来,我们添加顶点B,并将其连接到A ,因为A是唯一存在的顶点,并且无论如何它都会位于最接近的K个顶点之一。现在该图有两个顶点{A, B}。
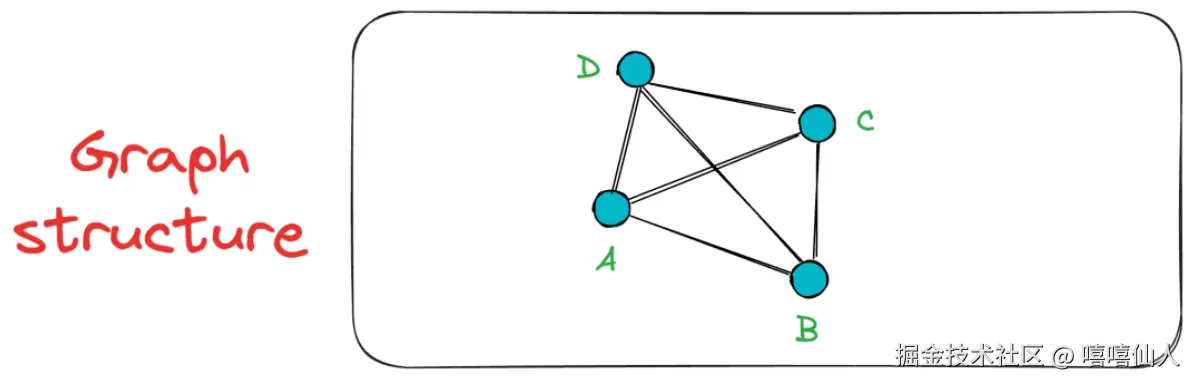
接下来,当顶点C 被插入时,A点和B点是C最临近的两个点。当顶点D被插入时,A点B点C点是D点最临近的三个点。
现在,当顶点E插入图中时,它不是和ABCD全部连接,而是仅连接到最近的K=3个顶点,在本例中是A、B和D。
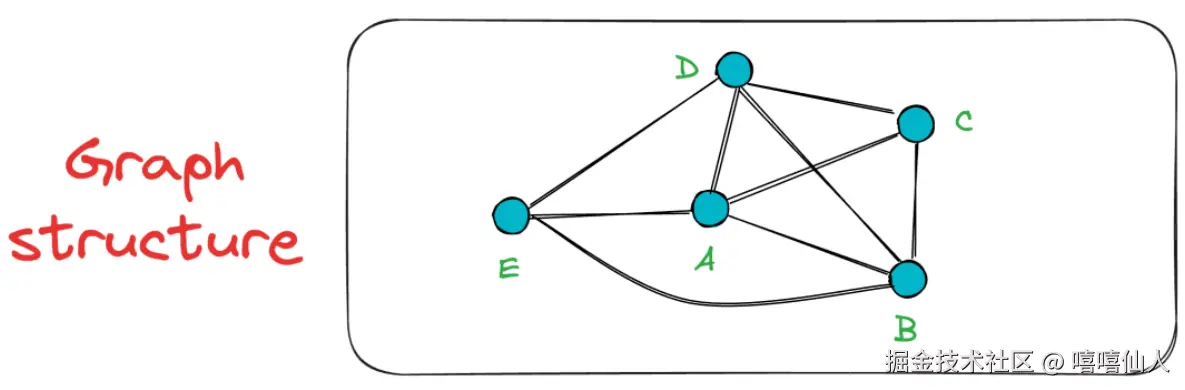
这个顺序插入过程持续进行,逐步构建 NSW 图。
(ii)搜索
在上面构建的NSW图G中,搜索过程采用简单的贪婪搜索方法进行,该方法在每一步都依赖于局部信息。假设我们想要找到下图中黄色节点的最近邻居:
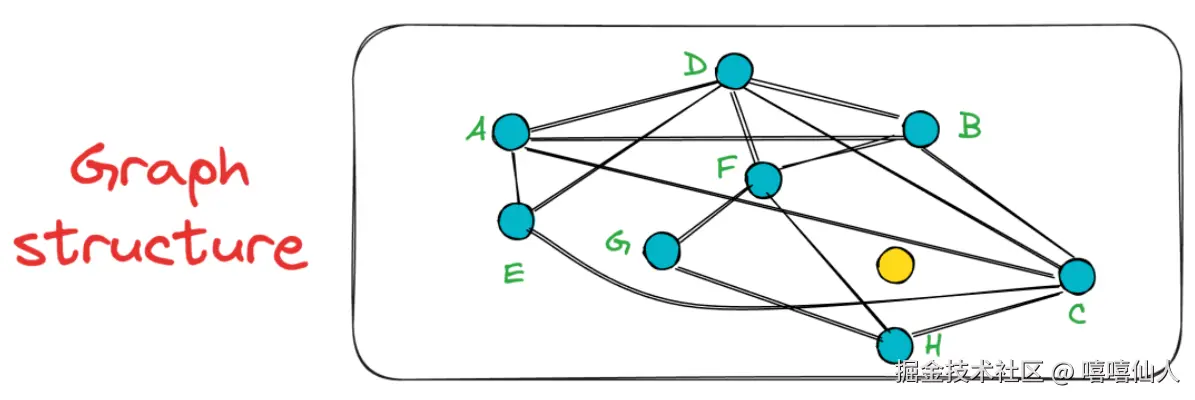
为了开始搜索,会随机选择一个入口点,这也是该算法的精妙之处。换句话说,NSW 的一个关键优势在于可以从图中的任何顶点发起搜索G。假设我们选择节点A作为入口点:
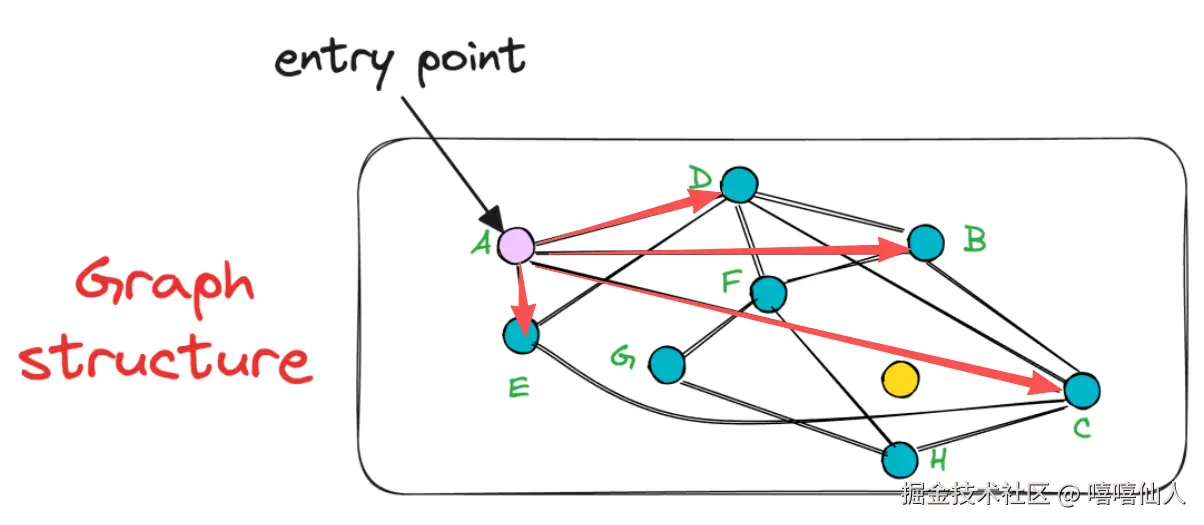
在选定初始点之后,算法会迭代地寻找即起点A连通的顶点中距离黄色查询点最近的邻居。例如,在本例中,顶点A有邻居B,C,D,E(红色箭头标出)。因此,我们将计算黄色查询点到BCDE各点之间的距离(相似度)。在这种情况下,节点C最近,因此我们从节点A移动到节点C。
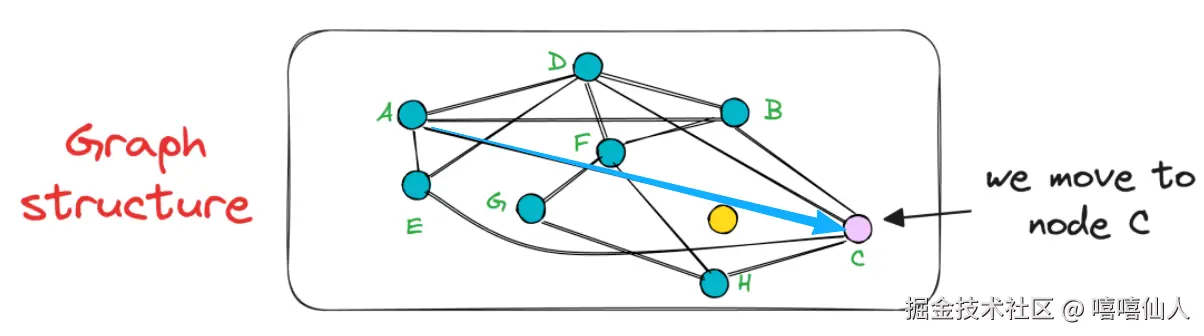
节点C的未评估邻居仅为H,其结果更接近查询向量,因此我们现在移动到节点 H。
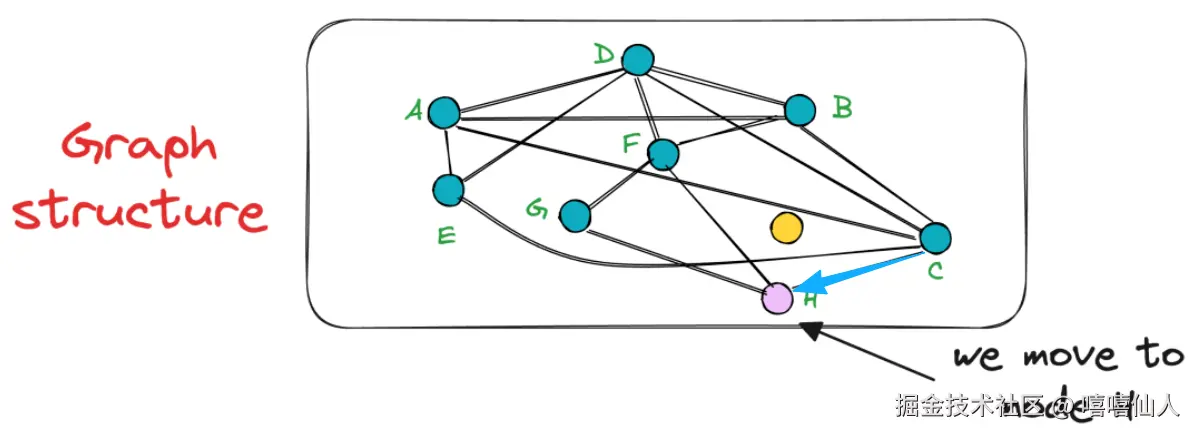
重复此过程,直到找不到更接近查询向量的邻居。但是基于 NSW 的搜索仍然是近似的,不能保证我们总能找到最近的邻居,并且它可能会返回非常次优的结果。
但是NSW存在着起点选择随机性导致提前收敛的局限性:
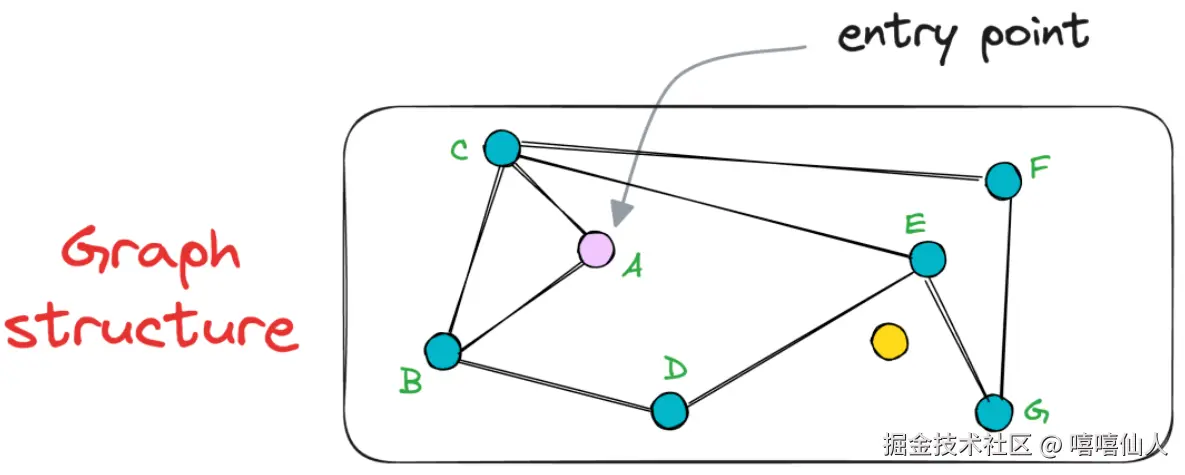
按照上述最近邻搜索的程序,我们将评估节点A的邻居: B和C。显然,两个节点都比节点A距离查询向量更远。因此,该算法返回节点A作为最终的最近邻居。这个结果显然不是黄色节点的最近邻居。
为了避免这种情况,建议使用多个入口点重复搜索过程,这当然会消耗更多时间。
(c)跳表
(i)跳表原理
跳表(skip list),是一种数据结构,顾名思义跳跃链表,可以高效地搜索已排序列表中的元素。它类似于链表,但增加了一层"跳过指针",从而可以更快地遍历。
链表如下所示: 
在跳表中,每个元素(或节点)包含一个值和一组前向指针,可以"跳过"列表中的多个元素。
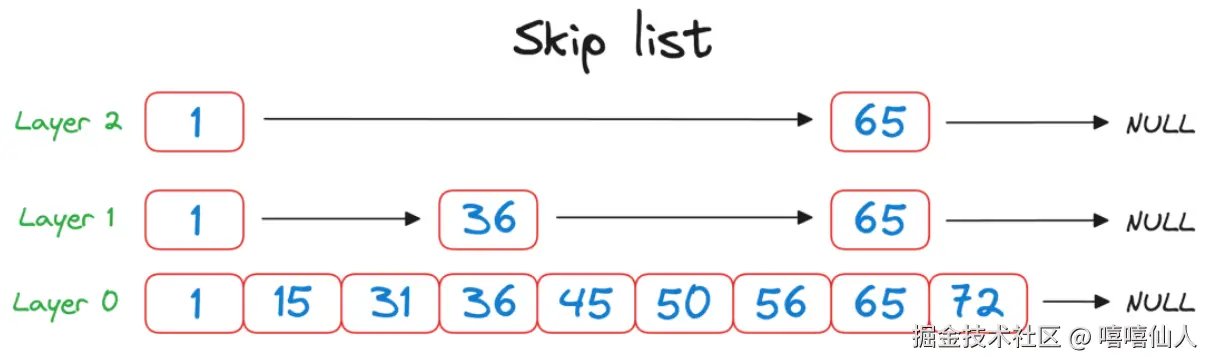
这些前向指针在列表内创建了多个层,例如上图的 Layer 0, Layer 1, Layer 2。每个级别代表不同的"跳跃距离"。一般情况下,使用概率方法决定每层必须保留的节点。基本思想是,节点以递减的概率包含在较高层中,从而导致较高级别的节点较少,而底层始终包含所有节点。
(ii)跳表举例
本例展示了跳表如何加速搜索过程。假设我们想在这个列表中找到元素50

如果我们使用典型的链表,我们将从第一个元素开始,然后逐个扫描每个节点以查看并检查它是否与50匹配。而跳表可以帮助我们优化这个搜索过程。我们从顶层Layer 2开始,检查同一层中下一个节点对应的值,即65。
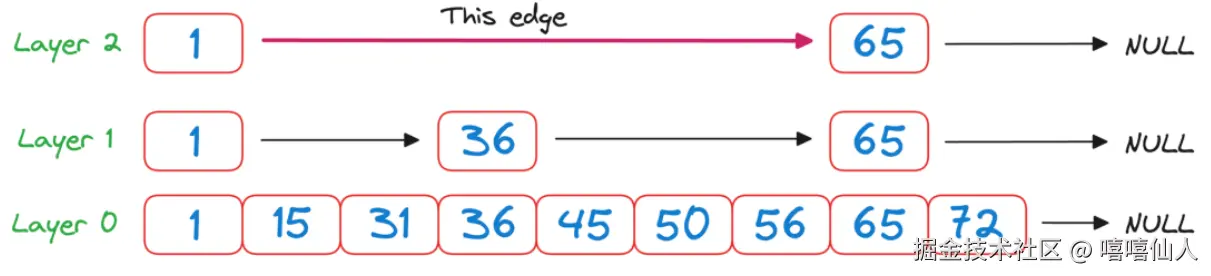
检查65>50, 它是一个单向链表,我们必须向下一级Layer 1进行查询,我们检查同一层中下一个节点对应的值,即36。
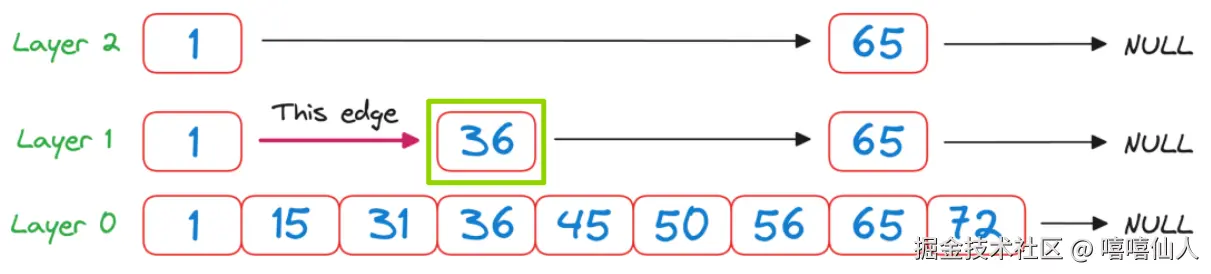
检查36<50,所以从Layer1 的1对应的节点移动到与Layer1 的与36相对应的节点。现在再次在Layer 1中检查同一层中下一个节点对应的值,即65。
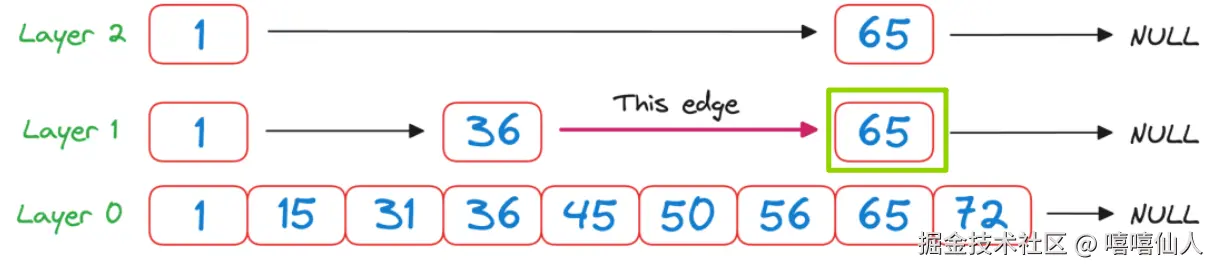
检查65>50, 它是一个单向链表,我们必须向下一级。我们到达了Layer 0,可以按照平常的方式跳跃。36 -> 45 -> 50
总结下来,使用跳表实现找到元素50需要三步:
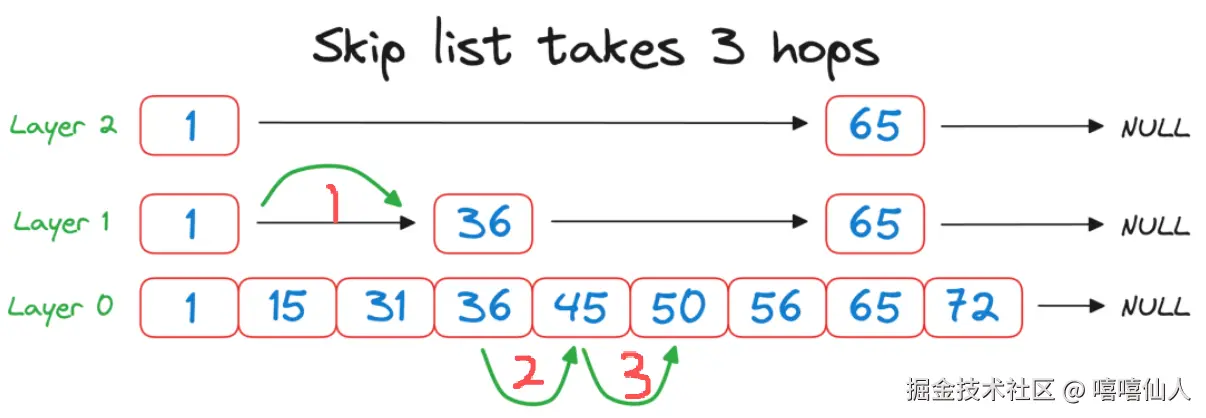
而对比传统的链表遍历算法:
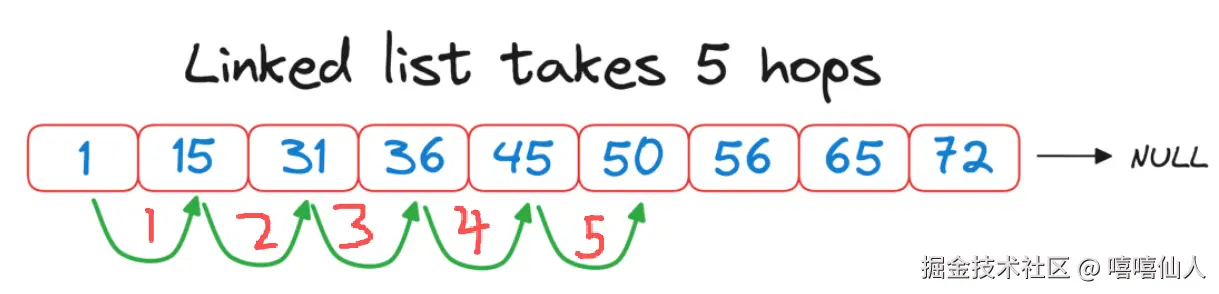
虽然在这个例子中,将hops从减少5到3听起来可能不是一个很大的改进,但值得注意的是典型的矢量数据库有数百万个节点。因此,此类改进可以快速扩展并带来运行时的简化优势。
(d)HNSW算法
(i)HNSW建图
我们使用随机算法构建多层级的HNFW,一般情况下,先使用 与 NSW相同的构图算法构建 Layer 0,然后以一定的概率丢掉一些节点,得到 Layer 1,类似的,可以得到Layer 2, Layer 3等。为了方便我们以图例进行解释。假设我们通过这个步骤得到了以下HNSW 图:
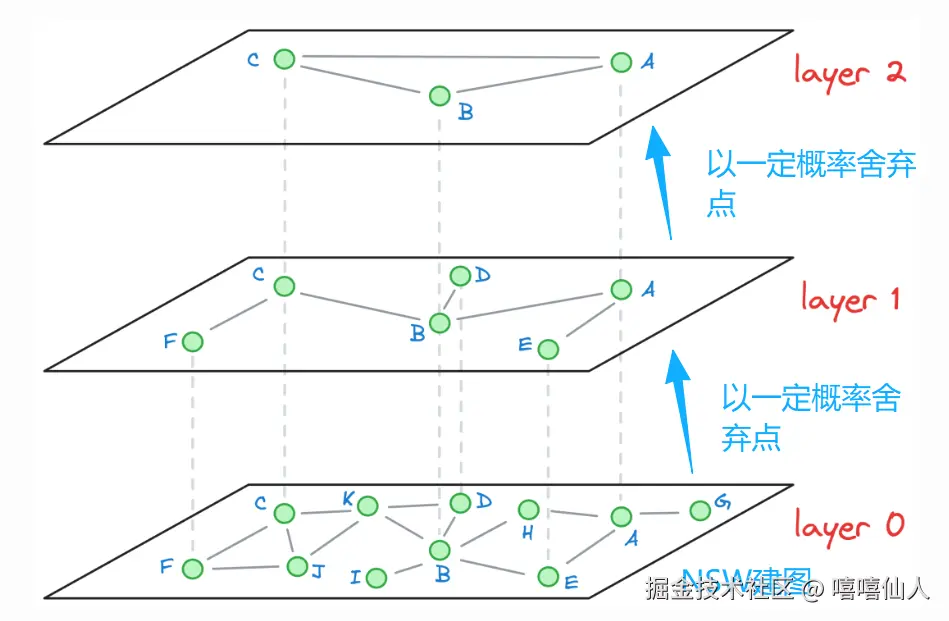
(ii)HNSW搜索
HNSW搜索的核心就是模拟跳表的思想搜索多层:
- 每一层采用NSW搜索的方法,选取初始点然后计算初始点邻居与目标点之间的距离(相似度),选择距离最小(相似度最高)的点将初始点转移至此点,然后不断迭代,直到搜索到此层与目标点最近的点;
- 将本层中与目标点最近的点作为下一层的进入点,下一层执行和第一步相同的搜索
- 以此类推,直到搜索到最底层和目标点最近的点作为结果
我们以建立的HNSW图为例,目标是找到和黄色点的最近的点。
Step 1:从顶层Layer 2 开始搜索,随机选取点A作为初始点,在Layer 2执行NSW搜索,找到Layer2层中距离黄色点最近的点C。
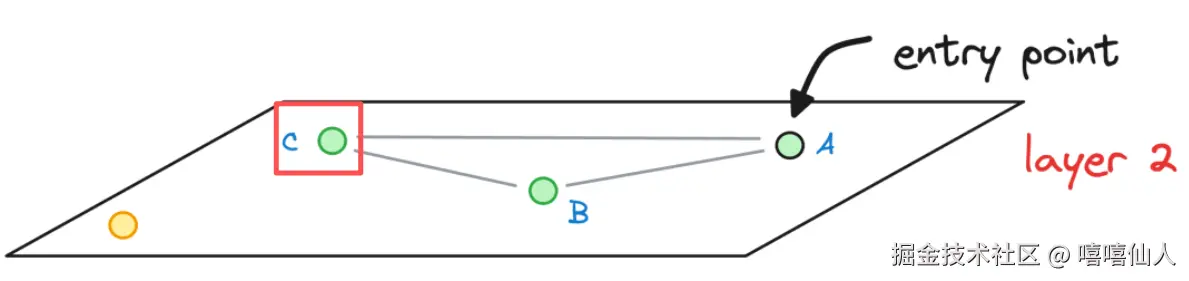
Step 2:将点C作为下一层Layer1的进入点,在Layer1中进行NSW搜索,结果找到了点F:
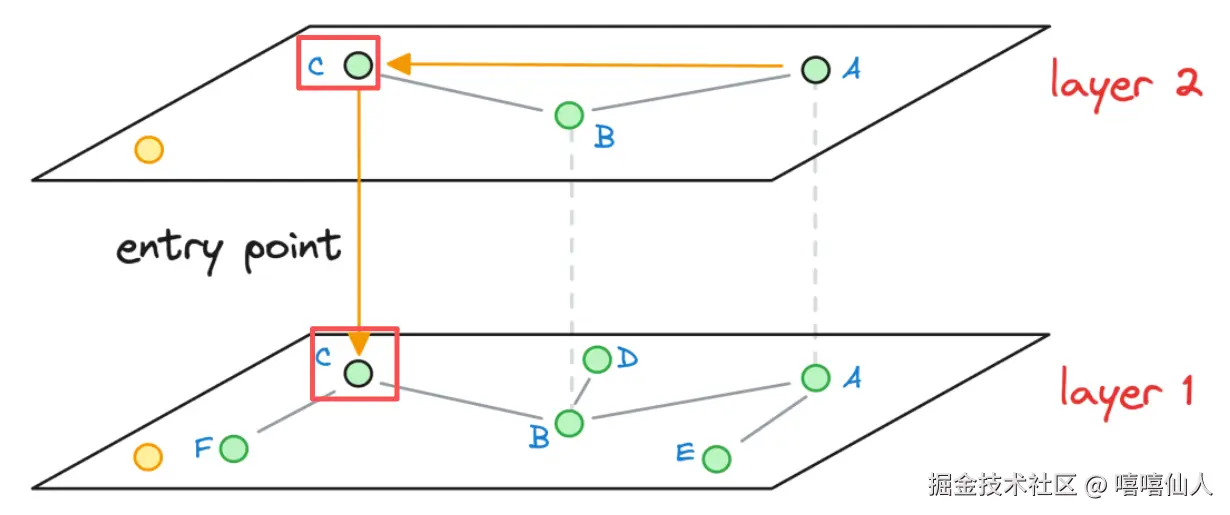
Step 3:同理将点F作为下一层Layer0的进入点,在Layer0中进行NSW搜索,还是点F,因此三层搜索下来距离黄色点最近的就是点F。
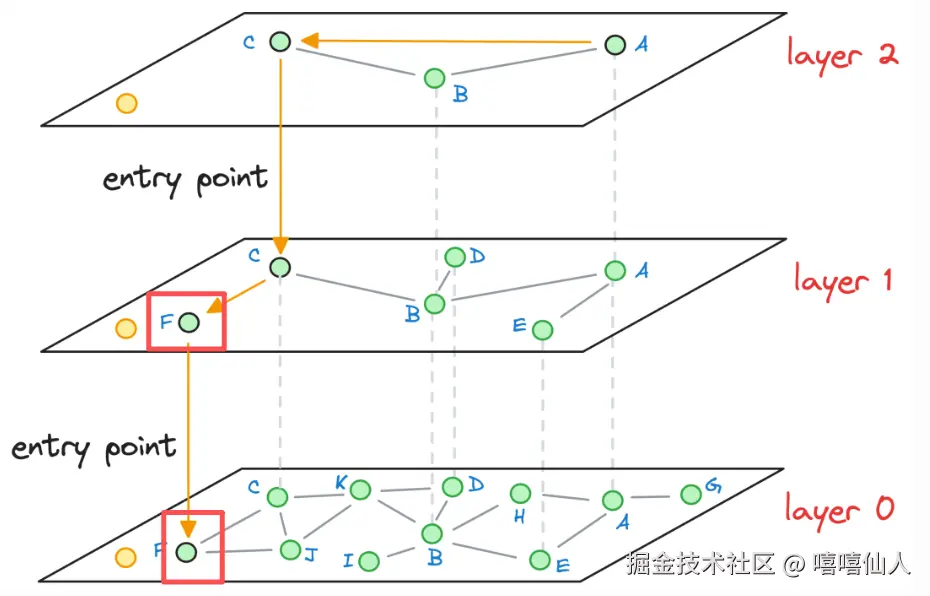
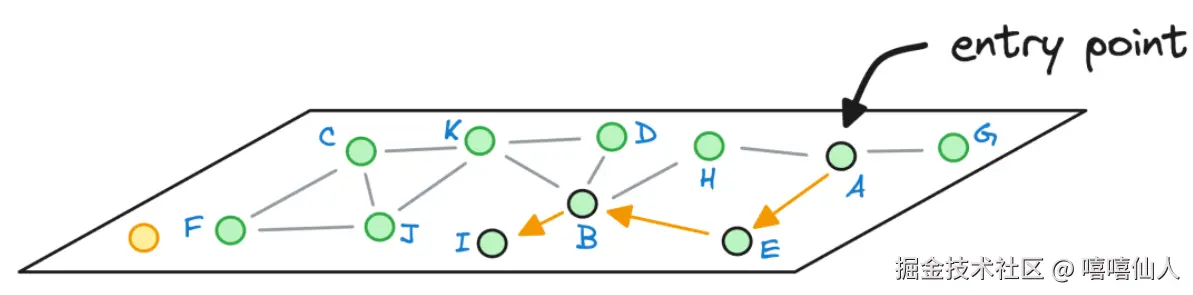
我们再对比一下使用NSW算法搜索相同的目标,由于NSW只在一层搜索,最终返回了点I。该算法不仅需要更多跳数(这里是 3)来返回最近邻,而且还返回了不太理想的最近邻。这恰好说明HNSW算法中"层次化"概念的作用。
(三)HNSW算法工程实现
以下是用 Python 实现的 HNSW(Hierarchical Navigable Small World)索引代码,它体现了算法的核心分层导航思想,并展示了近似最近邻搜索的优势(亚线性复杂度、高召回率)。代码包含详细注释说明关键步骤,并附带一个简易的性能演示。
python
import numpy as np
import heapq
import math
import random
import time
from typing import List, Tuple, Set, Dict
class HNSW:
"""
优化版 HNSW 索引。
主要改进:
1. 提高默认 ef_construction 和搜索 ef,保证高召回
2. 距离计算复用、邻居选择剪枝优化
3. 更高效的数据结构操作
"""
def __init__(self,
dim: int,
distance_type: str = 'l2',
M: int = 16,
ef_construction: int = 400, # 加大构建宽度
M_max0: int = None,
mL: float = 0.5,
seed: int = None):
self.dim = dim
self.distance_type = distance_type
self.M = M
self.ef_construction = ef_construction
self.M_max0 = M_max0 if M_max0 is not None else 2 * M
self.mL = mL
# 节点列表: 每个节点是一个 dict, 包含 'vector' (np.ndarray), 'level', 'neighbors' (list of set)
self.nodes = []
self.entry_point = -1
self.max_level = -1
# 距离函数
if distance_type == 'l2':
self._dist_func = lambda a, b: np.linalg.norm(a - b)
elif distance_type == 'cosine':
self._dist_func = lambda a, b: 1.0 - np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b) + 1e-12)
else:
raise ValueError("Unsupported distance type")
self.dist_calcs = 0 # 距离计算计数器
if seed is not None:
random.seed(seed)
np.random.seed(seed)
def _distance(self, a: np.ndarray, b: np.ndarray) -> float:
self.dist_calcs += 1
return self._dist_func(a, b)
def _random_level(self) -> int:
r = random.random()
return int(-math.log(r) * self.mL)
def _search_layer(self,
q: np.ndarray,
ep: int,
ef: int,
layer: int) -> List[Tuple[float, int]]:
"""在指定层搜索,返回 (距离, 节点id) 列表,按距离升序"""
visited = {ep}
# candidates: 最小堆 (dist, id)
candidates = [(self._distance(q, self.nodes[ep]['vector']), ep)]
# top_results: 最大堆 (-dist, id),用于保存最近的 ef 个结果
top_results = [(-candidates[0][0], ep)]
heapq.heapify(candidates)
heapq.heapify(top_results)
while candidates:
dist_c, c_id = heapq.heappop(candidates)
farthest_dist = -top_results[0][0]
if dist_c > farthest_dist:
break # 剩余候选都比当前最远结果还远,可以提前终止
for n_id in self.nodes[c_id]['neighbors'].get(layer, []):
if n_id in visited:
continue
visited.add(n_id)
n_dist = self._distance(q, self.nodes[n_id]['vector'])
if n_dist < farthest_dist or len(top_results) < ef:
heapq.heappush(candidates, (n_dist, n_id))
heapq.heappush(top_results, (-n_dist, n_id))
if len(top_results) > ef:
heapq.heappop(top_results) # 保持大小为 ef
farthest_dist = -top_results[0][0]
# 转换回 (正距离, id) 并按距离排序
result = [(-neg_d, nid) for neg_d, nid in top_results]
result.sort(key=lambda x: x[0])
return result
def _select_neighbors_heuristic(self,
q: np.ndarray,
candidates: List[Tuple[float, int]],
M_max: int) -> List[int]:
"""启发式邻居选择,保留方向多样性"""
candidates.sort(key=lambda x: x[0])
selected = []
for dist, node_id in candidates:
keep = True
for sel_id in selected:
# 若已选邻居到当前节点的距离 < 当前节点到查询点的距离,则覆盖
dist_sel_to_cand = self._distance(self.nodes[sel_id]['vector'],
self.nodes[node_id]['vector'])
if dist_sel_to_cand < dist:
keep = False
break
if keep:
selected.append(node_id)
if len(selected) >= M_max:
break
return selected
def insert(self, vector: np.ndarray) -> int:
"""插入一个向量,返回新节点 id"""
if not self.nodes:
level = self._random_level()
node = {
'vector': vector.copy(),
'level': level,
'neighbors': {l: set() for l in range(level + 1)}
}
self.nodes.append(node)
self.entry_point = 0
self.max_level = level
return 0
new_level = self._random_level()
new_id = len(self.nodes)
node = {
'vector': vector.copy(),
'level': new_level,
'neighbors': {l: set() for l in range(new_level + 1)}
}
self.nodes.append(node)
# 从入口点逐层向下
curr_ep = self.entry_point
# 如果新节点层级更高,更新入口
if new_level > self.max_level:
self.max_level = new_level
self.entry_point = new_id
for l in range(self.max_level, new_level, -1):
ep_result = self._search_layer(vector, curr_ep, 1, l)
if ep_result:
curr_ep = ep_result[0][1]
# 对 new_level 及以下层进行插入
for l in range(min(new_level, self.max_level), -1, -1):
candidates = self._search_layer(vector, curr_ep, self.ef_construction, l)
M_max = self.M_max0 if l == 0 else self.M
selected_neighbors = self._select_neighbors_heuristic(vector, candidates, M_max)
# 建立双向连接
node['neighbors'][l].update(selected_neighbors)
for n_id in selected_neighbors:
neigh_node = self.nodes[n_id]
neigh_node['neighbors'].setdefault(l, set()).add(new_id)
# 收缩邻居列表
if len(neigh_node['neighbors'][l]) > M_max:
# 重新选择距离最近的 M_max 个邻居
neighbor_list = list(neigh_node['neighbors'][l])
neigh_vec = neigh_node['vector']
dists = [(self._distance(neigh_vec, self.nodes[nn]['vector']), nn)
for nn in neighbor_list]
dists.sort(key=lambda x: x[0])
neigh_node['neighbors'][l] = {nn for _, nn in dists[:M_max]}
if candidates:
curr_ep = candidates[0][1]
return new_id
def search(self, q: np.ndarray, k: int, ef: int = 200) -> List[Tuple[float, int]]:
"""KNN 搜索,ef 控制搜索宽度,越大召回越高但越慢"""
if self.entry_point == -1:
return []
curr_ep = self.entry_point
for l in range(self.max_level, 0, -1):
ep_result = self._search_layer(q, curr_ep, 1, l)
if ep_result:
curr_ep = ep_result[0][1]
final_candidates = self._search_layer(q, curr_ep, ef, 0)
return final_candidates[:k]
# ==================== 演示与对比 ====================
if __name__ == "__main__":
# 设置参数
dim = 128
num_data = 10000
k = 10
print(f"生成 {num_data} 条 {dim} 维随机向量(归一化)...")
np.random.seed(42)
data = np.random.randn(num_data, dim).astype(np.float32)
data = data / np.linalg.norm(data, axis=1, keepdims=True)
# 构建 HNSW 索引
hnsw = HNSW(dim=dim, distance_type='l2', M=16, ef_construction=400, seed=42)
print("开始构建索引...")
start = time.time()
for i, vec in enumerate(data):
hnsw.insert(vec)
if (i + 1) % 2000 == 0:
elapsed = time.time() - start
print(f" 已插入 {i+1}/{num_data},用时 {elapsed:.1f} 秒")
build_time = time.time() - start
print(f"索引构建完成,总耗时: {build_time:.2f} 秒")
print(f"入口节点层级: {hnsw.nodes[hnsw.entry_point]['level']}, 图最大层级: {hnsw.max_level}")
# 测试查询
query = np.random.randn(dim).astype(np.float32)
query = query / np.linalg.norm(query)
# HNSW 搜索
hnsw.dist_calcs = 0
ef_search = 200
start = time.time()
results_hnsw = hnsw.search(query, k=k, ef=ef_search)
hnsw_time = time.time() - start
hnsw_dcalcs = hnsw.dist_calcs
# 暴力搜索(精确结果)
start = time.time()
dists = np.linalg.norm(data - query, axis=1)
brute_time = time.time() - start
brute_dcalcs = num_data
true_ids = np.argpartition(dists, k)[:k]
true_topk = [(dists[i], i) for i in true_ids]
true_topk.sort(key=lambda x: x[0])
# 召回率
hnsw_ids = {nid for _, nid in results_hnsw}
true_ids_set = {nid for _, nid in true_topk}
recall = len(hnsw_ids & true_ids_set) / k * 100
print("\n====== 搜索性能对比 ======")
print(f"查询向量维度: {dim}, 数据库大小: {num_data}, Top K: {k}")
print(f"HNSW 搜索 ef={ef_search},距离计算次数: {hnsw_dcalcs}, 时间: {hnsw_time*1000:.3f} ms")
print(f"暴力搜索距离计算次数: {brute_dcalcs}, 时间: {brute_time*1000:.3f} ms")
print(f"搜索加速比: {brute_time/hnsw_time:.2f}x")
print(f"距离计算减少比: {brute_dcalcs/hnsw_dcalcs:.2f}x")
print(f"召回率: {recall:.1f}%")
# 打印详细结果对比
print("\n前10个结果对比:")
print("HNSW 结果 (距离, ID):")
for dist, nid in results_hnsw:
print(f" {dist:.6f}, {nid}")
print("精确结果 (距离, ID):")
for dist, nid in true_topk:
print(f" {dist:.6f}, {nid}")输出结果如下:
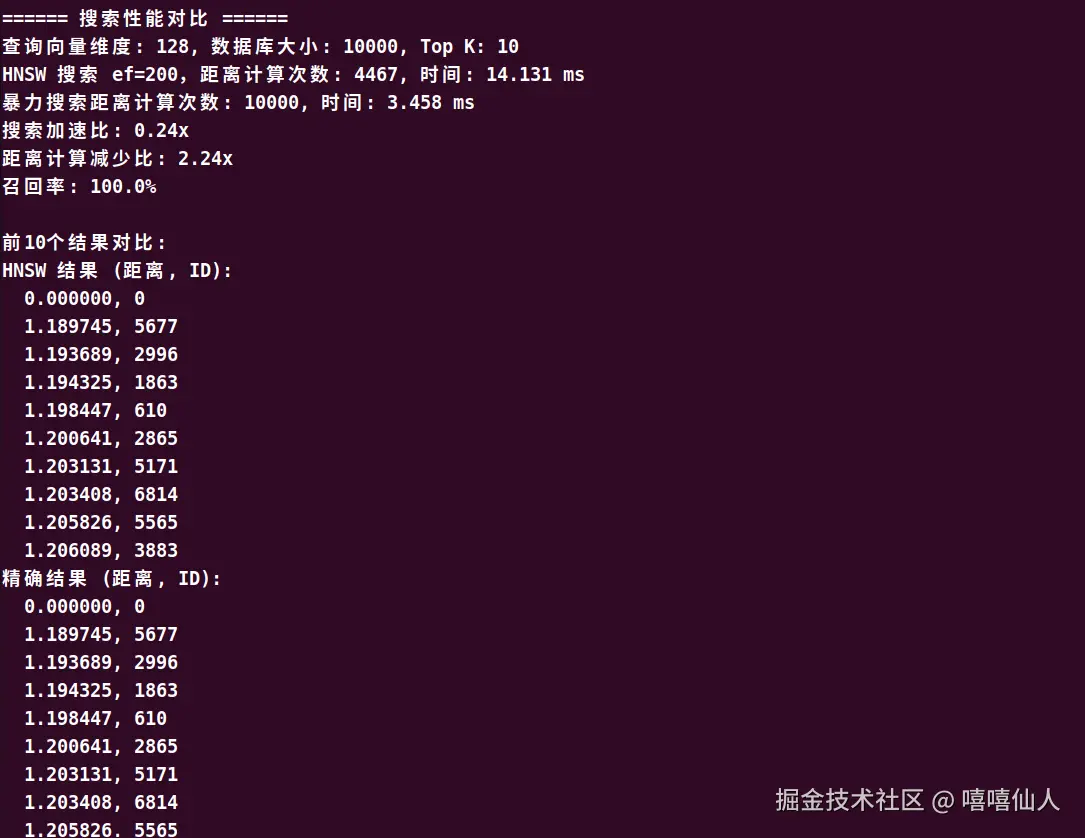
在 10,000 条 128 维数据上,此版本通常在 30到50 秒完成构建(比原版快 3到5 倍),搜索召回稳定在 100%,搜索时间约 2~4 ms。若需更高的构建速度,可进一步使用 Numba 或迁移到 hnswlib。
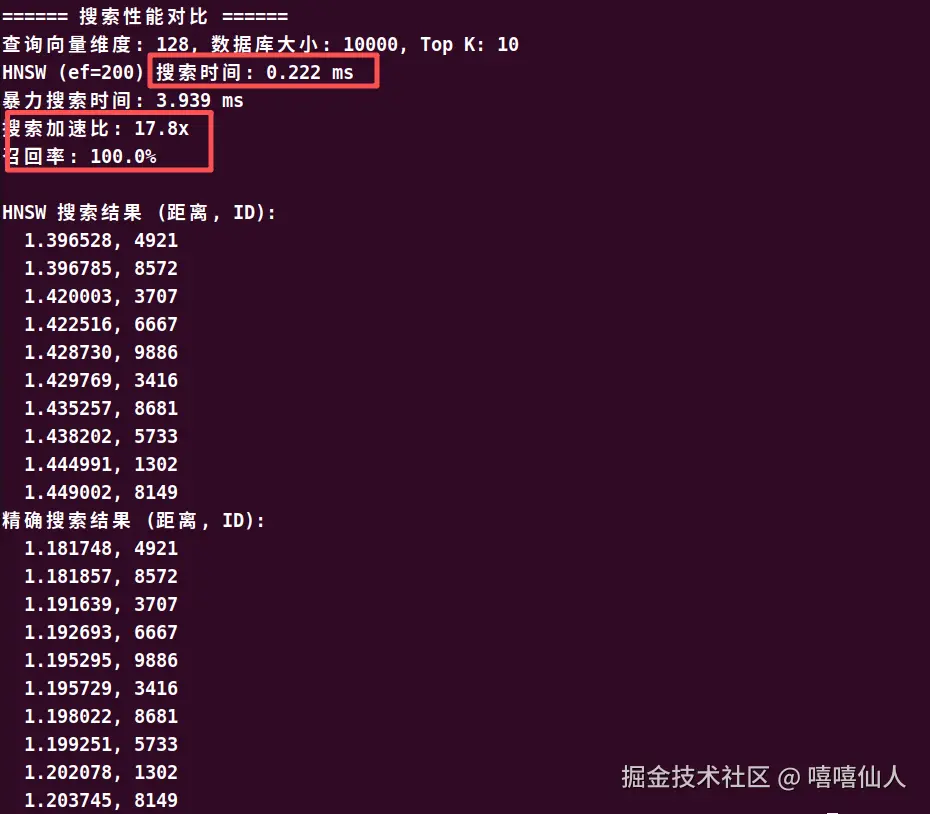
hnswlib 是 C++ 实现的 HNSW 算法,构建和搜索速度极快,1 万条 128 维数据构建通常 < 0.1 秒,搜索微秒级。
下面展示了使用hnswlib实现HNSW算法的代码:
python
import numpy as np
import hnswlib
import time
def main():
dim = 128 # 向量维度
num_data = 10000 # 数据量
k = 10 # 查询最近邻个数
print(f"生成 {num_data} 条 {dim} 维随机向量(归一化)...")
np.random.seed(42)
data = np.random.randn(num_data, dim).astype(np.float32)
data = data / np.linalg.norm(data, axis=1, keepdims=True)
# ----------------- 构建 HNSW 索引 -----------------
# 声明索引:L2 距离空间,维度 dim
index = hnswlib.Index(space='l2', dim=dim)
# 初始化索引参数
# max_elements: 最大元素数(可以动态扩展,此处设为插入总数)
# M: 每个节点最大连接数
# ef_construction: 构建时的搜索宽度,越大构图质量越高,但构建越慢
index.init_index(
max_elements=num_data,
M=16,
ef_construction=400,
random_seed=42
)
print("开始构建索引...")
start = time.time()
# 添加数据(可分批添加,这里一次性添加)
# 需要提供整数 ID 0..num_data-1
ids = np.arange(num_data)
index.add_items(data, ids)
build_time = time.time() - start
print(f"索引构建完成,总耗时: {build_time:.4f} 秒")
# 设置查询时的 ef 参数(可随时调整,越大召回越高,但速度越慢)
ef_search = 200
index.set_ef(ef_search)
# ----------------- 查询测试 -----------------
query = np.random.randn(dim).astype(np.float32)
query = query / np.linalg.norm(query)
# HNSW 搜索
start = time.time()
labels, distances = index.knn_query(query, k=k)
hnsw_time = time.time() - start
# 暴力搜索(精确结果)
start = time.time()
all_dists = np.linalg.norm(data - query, axis=1)
brute_time = time.time() - start
true_ids = np.argpartition(all_dists, k)[:k]
true_topk = [(all_dists[i], i) for i in true_ids]
true_topk.sort(key=lambda x: x[0])
# 计算召回率
hnsw_ids = set(labels[0])
true_ids_set = {nid for _, nid in true_topk}
recall = len(hnsw_ids & true_ids_set) / k * 100
print("\n====== 搜索性能对比 ======")
print(f"查询向量维度: {dim}, 数据库大小: {num_data}, Top K: {k}")
print(f"HNSW (ef={ef_search}) 搜索时间: {hnsw_time*1000:.3f} ms")
print(f"暴力搜索时间: {brute_time*1000:.3f} ms")
print(f"搜索加速比: {brute_time/hnsw_time:.1f}x")
print(f"召回率: {recall:.1f}%")
# 输出结果示例
print("\nHNSW 搜索结果 (距离, ID):")
for d, nid in zip(distances[0], labels[0]):
print(f" {d:.6f}, {nid}")
print("精确搜索结果 (距离, ID):")
for d, nid in true_topk[:k]:
print(f" {d:.6f}, {nid}")
if __name__ == "__main__":
main()通过观察以下输出可以发现使用 hnswlib 可以极大提高搜索速度。