我为什么开始让 Claude 和 Codex 跨 CLI 协作
最近我做了一件看起来有点绕的事:让 Claude Code 和 Codex 在同一个本地项目里协作。
我最开始只是想验证一件事:既然我平时已经在不同 CLI 里用不同 AI 工具,能不能让它们别各干各的,而是形成一个更稳定的工作流?
实际跑下来,我明显感觉到它不是简单的"多开一个模型"。更像是一个人写,另一个人盯着;一个负责推进,另一个负责挑错;一个更适合长上下文写作和改稿,另一个更适合按文件、命令、权限和验证去卡边界。
我为什么会想尝试跨 CLI 协作
一开始不是为了炫技。
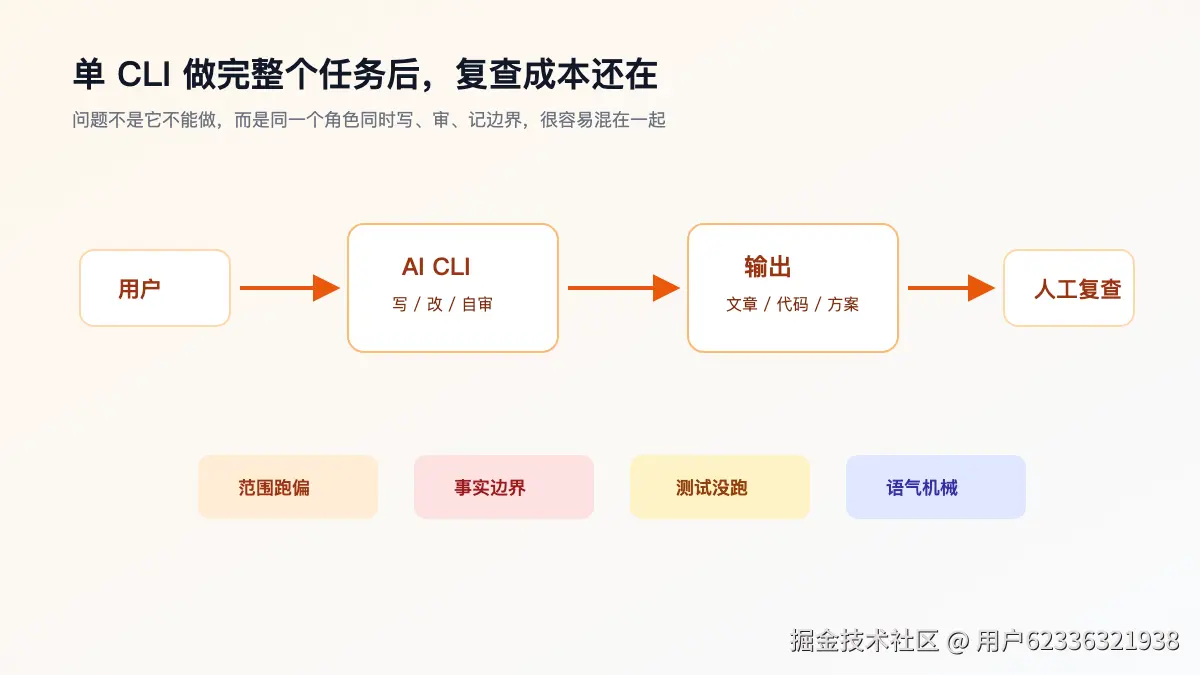
我遇到的问题很具体:一个 CLI 做完整个任务之后,我还是要花不少时间复查。
写文章时,它可能结构已经不错,但语气太像方法论文档;技术判断可能写得太满;涉及产品时可能不小心像广告。写代码时也一样,功能可能能跑,但 diff 里会混入我没要求改的文件,或者测试过了但改动范围已经变宽。
这类问题靠"再提示一次"可以缓解,但不稳定。因为同一个 CLI 在长对话里既要写、又要审、又要记住用户口吻、又要注意技术边界,角色会混在一起。它刚刚还在努力把正文写顺,下一秒又要站出来否定自己,这件事并不总是可靠。
所以我开始想:能不能把角色拆开?
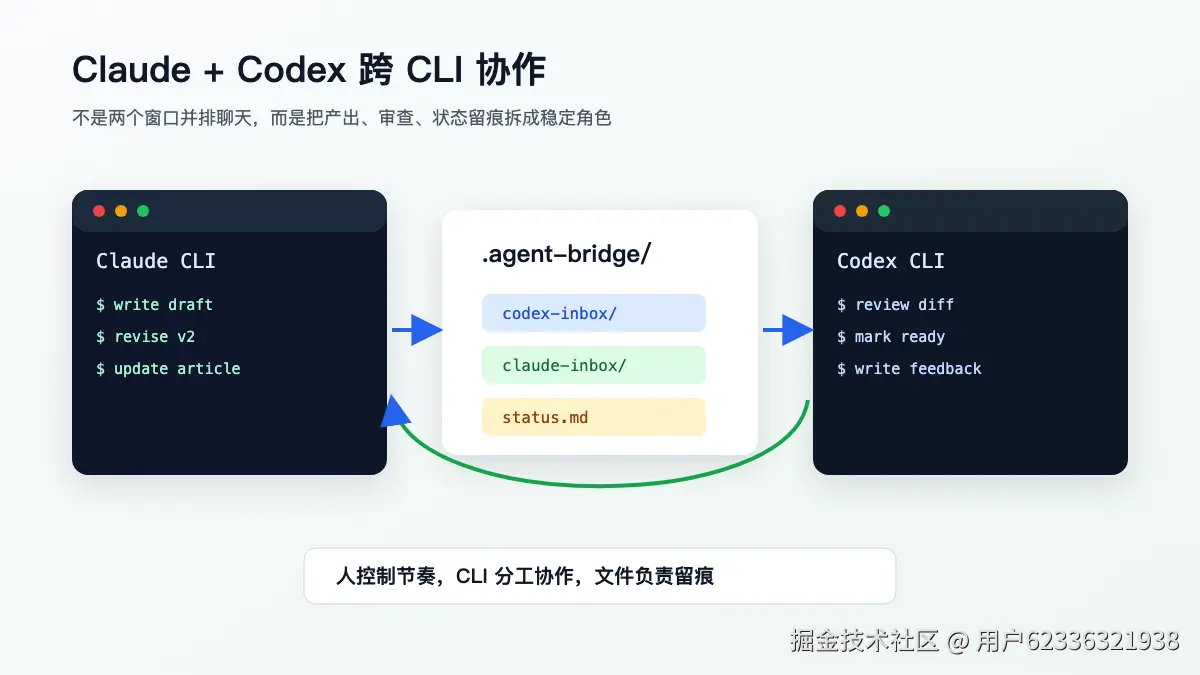
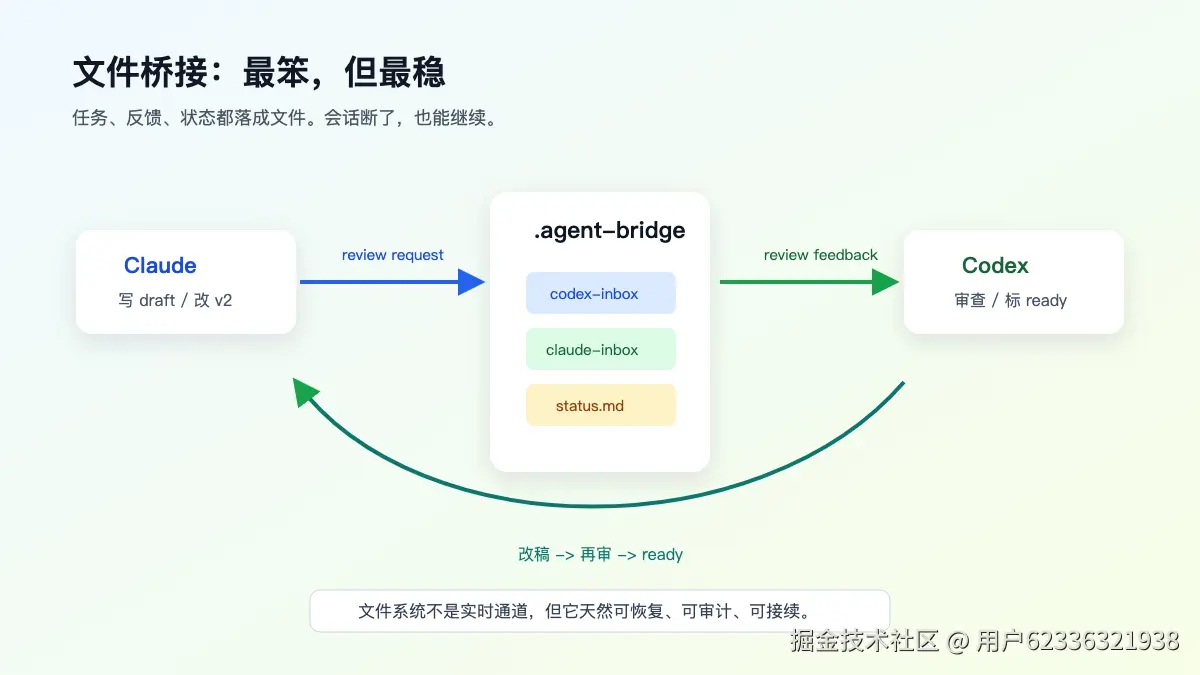
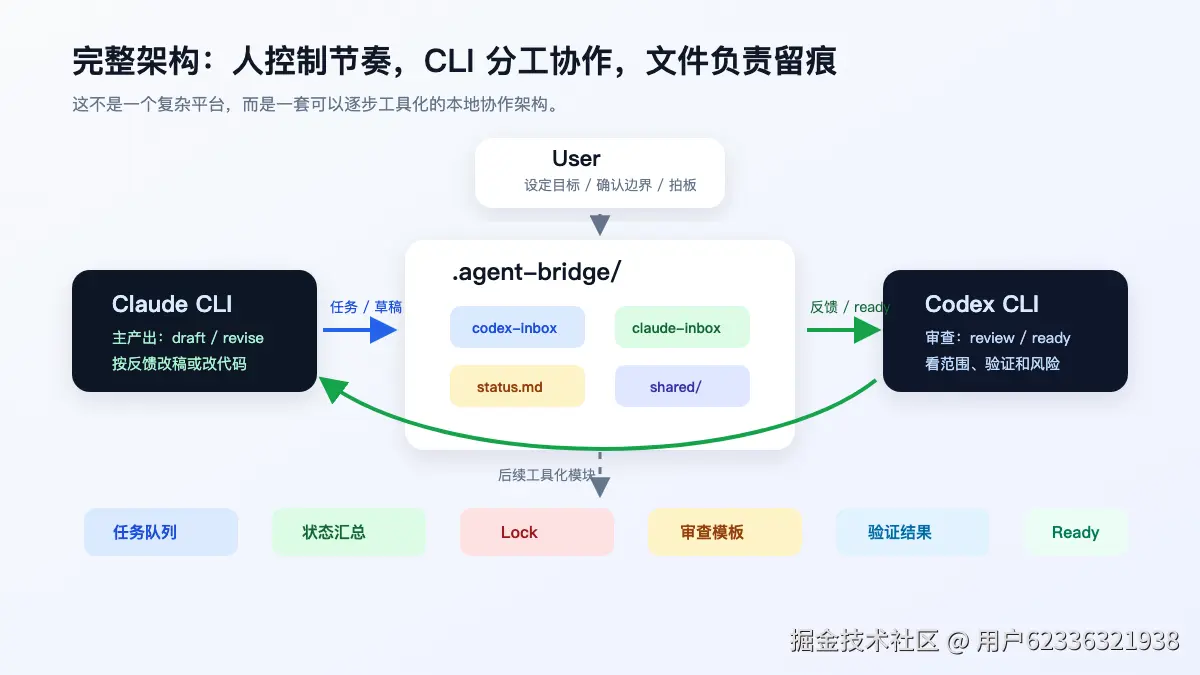
Claude 负责主产出。Codex 负责审查。中间不要靠我复制粘贴来回传,而是让它们通过本地文件交接任务和反馈。
这个想法很朴素:不是让 AI 自主创业,而是让两个 CLI 分别做自己更适合的部分。
跨 CLI 协作真正带来的优势
我现在最看重的优势有四个。
第一,角色更清楚。
当 Claude 是主笔时,我就要求它把事情写完整、写顺、写得像真实开发者复盘。它不用同时扮演严苛审稿人。Codex 拿到稿子后,只做一件事:判断能不能发,哪里有问题,下一轮必须改什么。
这个分工很像真实工作里的作者和 reviewer。作者不需要每句话都停下来怀疑自己,reviewer 也不需要从零写全文。
第二,反馈能留下痕迹。
我用的是文件桥接,所以每一轮都有文件记录:
text
.agent-bridge/
claude-inbox/
codex-inbox/
shared/
status.md一次审稿请求、一次反馈、一次 ready 结论,都会变成一个带日期和版本号的 Markdown 文件。比如:
text
2026-05-18-article-01-review-request.md
2026-05-18-article-01-review-feedback-v1.md
2026-05-18-article-01-final-review-ready.md这比聊天窗口里翻历史稳定得多。中断了、换会话了、第二天继续,都可以从 status.md 和 inbox 文件恢复。
第三,质量门禁更硬。
Codex 审稿时不是泛泛说"不错"。它会直接给判断:
text
not ready
almost ready
ready
tiny cleanup before ready它会指出具体问题:某个数据没有证据,某个模型名像编造,某段安全边界太宽,某个结尾像运营话术。对代码任务也是同一个思路:改了哪些文件、有没有越界、验证有没有跑、跑不了要说明原因。
这比我自己看一遍更省心,因为它承担的是固定的"挑错角色"。
第四,长任务更容易拆成连续迭代。
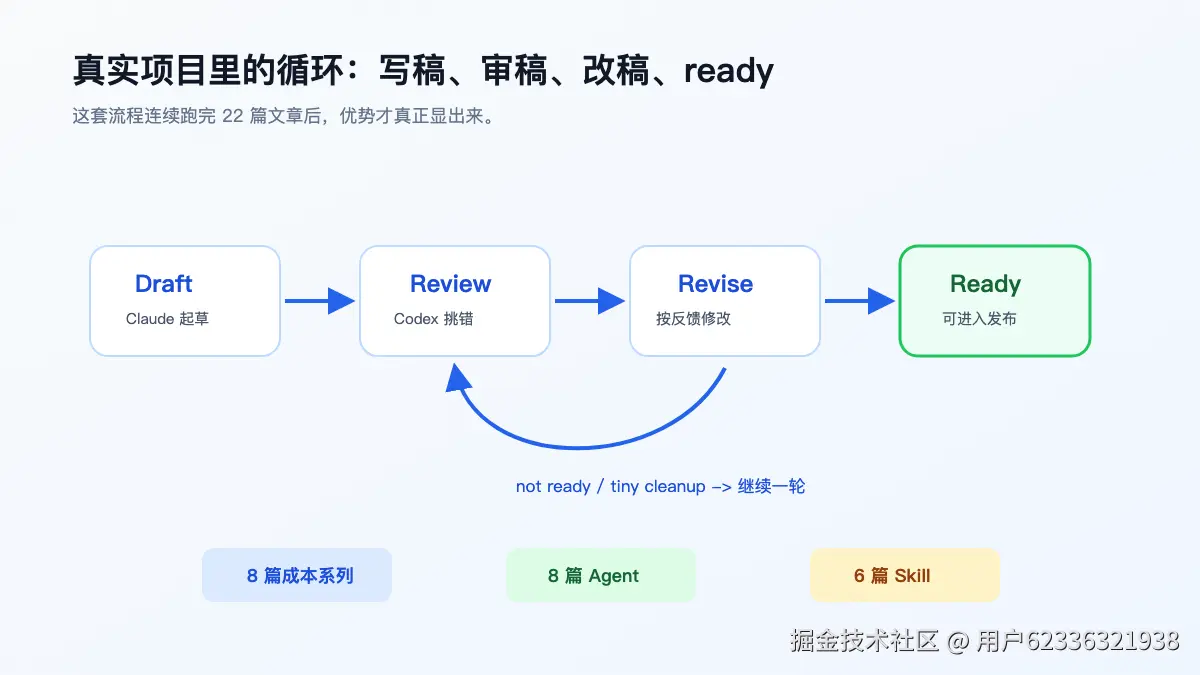
我用这套方式连续做完了三组文章:8 篇上下文成本系列、8 篇 Agent 工作流系列、6 篇 Skill 系列。每篇文章都是 draft -> review -> revise -> final ready。单看一篇文章,这只是多了一层审稿;连续做 22 篇之后,差异就很明显了:系列口径更稳,重复内容更少,风格更一致,后续发布元数据也能继续让另一个 CLI 检查。
这就是跨 CLI 协作的价值:它不是让单次回答更炫,而是让长链路任务更可控。
跨 CLI 协作有哪些方式

我最开始也不是直接选文件。那时我先问了一个更底层的问题:两个已经运行的 CLI,到底怎么通信?
当时考虑过三种方式。
第一种是 Socket。
Socket 的好处是实时。你可以做一个真正的双向通信服务,两个 CLI 都连进来,消息可以更快同步。
但它适合的是你愿意专门维护一个桥接服务的场景。比如你要做一个长期运行的本地 Agent 控制台,或者要把多个工具接到同一个调度器里。对我当时的需求来说,它有点重:我只是想让两个已经运行的 CLI 协作完成任务,不想先搭一套服务。
第二种是 Pipe 或 TTY。
这个思路更像直接接管进程输入输出。理论上可以把一个 CLI 的输出喂给另一个 CLI。
问题是,pipe 更适合父子进程,或者一开始就设计好的 stdin/stdout 管道。Claude 和 Codex 是两个已经启动的独立 CLI,会话、权限、交互状态都不一样。TTY 注入也不等于稳定协议,出了问题很难追踪。
所以这条路我很快就放弃了。
第三种是 File,也就是共享文件。
这最后成了我采用的方式。
原因很直接:两个 CLI 都能读写同一个工作区。任务写成文件,反馈写成文件,状态写成文件。失败了也不会丢,第二天继续也能看懂。
它不实时,但稳定。
对我这种"人控制节奏、两个 CLI 分工协作"的模式来说,稳定比实时更重要。
简单总结一下:
| 方式 | 更适合什么场景 | 我为什么没选或选择 |
|---|---|---|
| Socket | 长期运行的协作服务、多 Agent 控制台、需要实时通信 | 适合实时双向通信,但当时太重 |
| Pipe / TTY | 预先设计好的命令链、父子进程、一次性自动化 | 对两个独立 CLI 不稳 |
| File | 本地项目协作、长任务留痕、人工控制节奏 | 简单、可恢复、可审计,所以我选它 |
我最开始是怎么尝试的
最早的一步很小:我先让 Claude 尝试和一个已经运行的 Codex 进程通信。
那是一个我已经启动好的 Codex 进程。我先让 Claude 分析能不能直接通信,又让它比较 socket、pipe、file 三种方式。后来我把 Codex 的回答贴给 Claude,Codex 明确建议用共享文件。
于是我建了一个目录:
text
.agent-bridge/
codex-inbox/
claude-inbox/
shared/
status.md然后做 handshake。
Codex 写一个任务给 Claude:
text
请确认你能读取 .agent-bridge/codex-inbox/
并把 ACK 写到 .agent-bridge/shared/Claude 写回 ACK。
这一步很关键。它证明了两件事:
- Claude 能读 Codex 写的任务。
- Claude 能把结果写到双方都能看的目录。
通信通了之后,我才开始让它们做真实任务。
我后来怎么用到实际项目里
最先落地的是内容生产。
我当时在做一个产品的内容推广,需要写一组技术文章。这个任务有几个特点:
- 一篇文章写完不难,难的是连续多篇保持口径一致。
- 文章不能像 AI 生成稿,要像真实开发者复盘。
- 技术判断不能太绝对。
- 涉及产品时不能写成广告。
- 涉及产品能力时,还要注意只讲用户能理解的边界,不展开内部实现细节。
这正好适合拆成两个角色。
Claude 做主笔。它根据项目背景、历史记录和文章大纲起草正文。
Codex 做审稿。它检查主题、结构、事实风险、技术边界、语气和是否 ready。
一轮真实请求大概是这样:
md
# Review Request: Article 01
From: Claude
Article: knowledge-articles/series-ai-context-cost/01-ai-request-cost-and-context-waste.md
Status: Draft v1
请从主题聚焦、叙事结构、逻辑质量、事实风险、可读性、转化点这些维度审查。Codex 的反馈不是泛泛润色,而是会指出具体问题:
- "一半 token 都在浪费"没有证据,要改成更稳的表达。
- "三个工具都往同一个模型发请求"技术上不严谨,要改成同一类 API 预算。
- "本地代理"这类表述容易引发安全误解,要说明这是本机调试场景,不建议随便代理敏感流量。
- 结尾不能出现"转化钩子预告"这种编辑标签。
Claude 按反馈改 v2。Codex 再审。直到 ready。
这个模式后来跑得很顺:文章、系列一致性、发布元数据、B 站视频脚本,都可以沿用同一套流程。
它也可以迁移到开发任务里。比如一个 CLI 负责改代码,另一个 CLI 负责 review diff:
text
执行 CLI:
- 读取需求
- 定位文件
- 修改代码
- 运行允许范围内的验证
- 写出改动摘要
审查 CLI:
- 检查是否改了不该改的文件
- 检查测试/类型检查是否真的执行
- 检查边界条件和回退方案
- 给出是否可合并的判断我现在更愿意把它看成一个本地版的"开发者 + reviewer"组合,而不是两个模型抢着干活。
这个方式最容易踩的坑

跨 CLI 协作不是没有问题。
第一个坑是方向容易搞反。
目录名字必须约定清楚。我的约定是:
text
codex-inbox # Claude 读,里面是 Codex 给 Claude 的内容
claude-inbox # Codex 读,里面是 Claude 给 Codex 的内容刚开始看会有点绕,但只要记住"谁收件谁读"就行。
第二个坑是两个 CLI 不能同时乱改同一批文件。
写文章时问题不大,因为 Claude 负责改正文,Codex 只写反馈。但如果迁移到代码开发,就必须加锁或至少写清当前谁有写权限。否则两个 CLI 同时改一个文件,冲突会很麻烦。
第三个坑是反馈必须结构化。
如果 Codex 只写"建议再优化一下",Claude 下一轮很容易自由发挥。反馈必须写到这种程度:
text
Blocking Issues:
- 哪个文件
- 哪一段
- 为什么有风险
- 建议怎么改
Required Next Output:
- 修改哪个文件
- 写到哪个 review request
- 是否只做 tiny cleanup第四个坑是状态要持续更新。
status.md 不能只在开始时写一下。它要记录当前任务做到哪了、谁在等谁、哪些文件已经 ready。否则一旦 CLI 会话断了,恢复成本会很高。
后续可以往什么方向优化
现在这套方式能用,但还比较手动。
如果继续往下做,我觉得重点不是让它更"智能",而是让这套协作更省心、更少依赖人工翻文件。
第一,任务文件可以自动生成。
现在写 review request 还要手动建 Markdown。后面可以做一个小 CLI:
bash
agent-bridge request \
--to claude \
--task cross-cli-article-review \
--file knowledge-articles/cross-cli/01-claude-codex-cross-cli-collaboration.md它自动生成带日期、版本号、路径和检查项的请求文件。
第二,状态可以自动汇总。
现在 status.md 是人工维护。后面可以让工具扫描 inbox 文件,自动生成:
- 当前待 Claude 处理的任务
- 当前待 Codex 处理的任务
- 哪些任务 ready
- 哪些任务还卡在 v2 / v3
这样恢复会话时不用翻一堆文件。
第三,代码协作需要更明确的 lock。
文章任务可以先不用,但代码任务需要。比如:
text
.agent-bridge/locks/current-task.lock
owner: claude
scope:
- src/settings/UserSettingsPanel.tsx
- src/settings/useSettings.ts另一个 CLI 看到 lock 后只能 review,不能改同一范围。
第四,审稿规则可以模板化。
现在规则散在 .claude/rules、.codex/rules 和 Skill 里。后面可以把不同任务的检查清单做成模板:
- 文章审稿模板
- 代码 diff review 模板
- 发布前安全检查模板
- 对外内容保密检查模板
每次发任务时只指定模板,减少重复描述。
第五,可以做一个轻量的终端面板。
我不需要复杂平台,只需要一个很轻的终端视图:
- 左侧:任务队列
- 中间:当前任务状态
- 右侧:最近反馈和 ready 结论
- 底部:涉及文件和验证结果
这会比手动打开几十个 Markdown 更直观。
我现在对跨 CLI 协作的判断
跨 CLI 协作最有价值的地方,不是"同时调用两个模型"。
表面上看,我是在让 Claude 和 Codex 一起工作。
本质上,我是在把一个长任务拆成几个稳定角色:谁负责产出,谁负责审查,谁记录状态,谁做最终判断。
这个拆分之后,AI 工具不再是一个对话窗口里什么都干的助手,而更像本地开发流程里的几个岗位:
- 一个写
- 一个审
- 一个留痕
- 人来拍板
这也是我觉得 1+1>2 的原因。
不是两个 CLI 叠加出了更强的模型,而是两个 CLI 被放到了更合适的位置上。位置对了,协作才会放大能力。
纯经验干货分享,为了帮助大家节省token使用量,分享给大家一个工具: