2026年第八届中青杯 A题超详细解题思路
本文将为大家带来A题超详细的解题思路,包含具体每一问的计算结果、求解用到的模型、 创新点、以及论文PDF特征提取后的数据表格。
2026年第八届中青杯全国大学生数学建模竞赛于2026年6月4日17:00至6月7日17:00进行,竞赛时间为3天。竞赛题目分为A、B、C题,其中研究生组、本科生组从A、B题中任选一题完成,专科生组从B、C题中任选一题完成。
A题 数学建模论文智能评估系统
利用AI技术改进教育评价体系,针对数学建模论文的智能评估,建立评分模型、质量预测模型、以及优化策略。
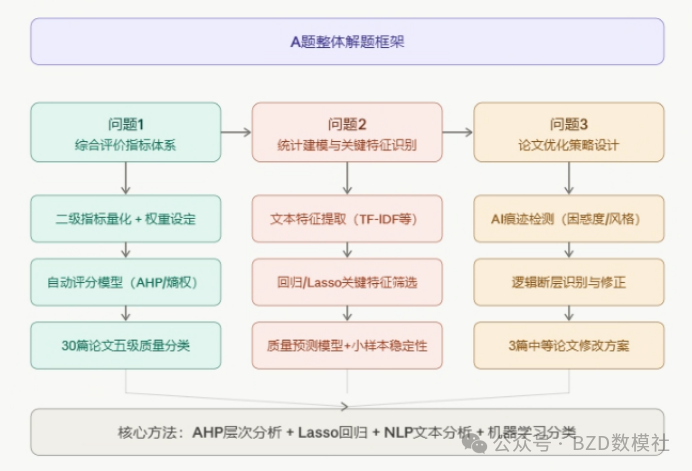
题1:论文质量综合评价指标体系与自动评分模型
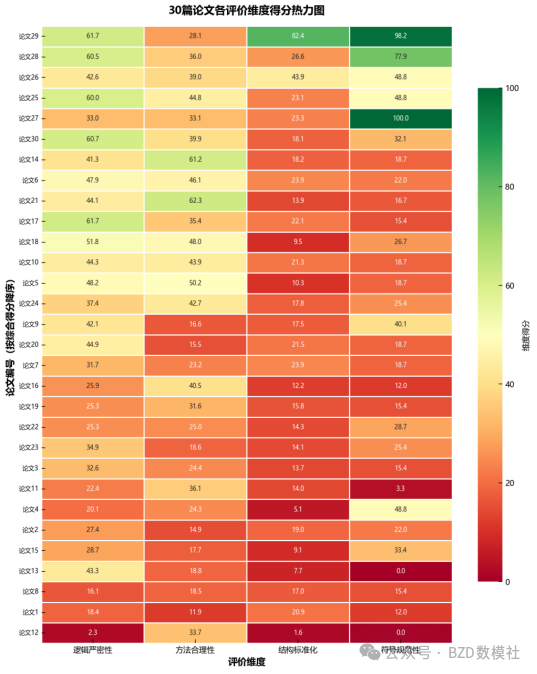
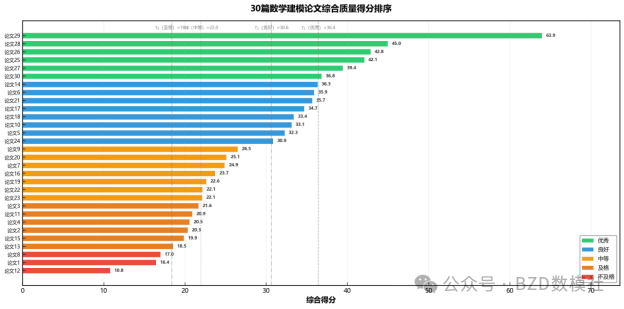
****核心任务:****对30篇参赛论文进行质量分级(优秀、良好、中等、及格、不及格)
关键要求:将"逻辑严密性""方法合理性"等定性指标量化为可自动计算的二级指标
****难点:****指标的选择、权重设定的合理性、分级标准的建立
求解思路
指标体系构建(三维度拆解)
一级指标 二级指标(可量化)
├─ 逻辑严密性
│ ├─ 逻辑连接词密度(文本特征)
│ ├─ 模型假设与问题匹配度(语义相似度)
│ ├─ 问题分析的完整性(各部分字数占比)
│ ├─ 变量定义规范性(符号使用一致性)
│ └─ 逻辑层级合理性(结构熵/树状度)
│
├─ 方法合理性
│ ├─ 建模方法的学术规范性(是否列出核心方法)
│ ├─ 公式推导完整性(公式与文字的关联度)
│ ├─ 参数合理性(参数设置的科学性评估)
│ ├─ 模型假设的多样性(使用假设数量/质量)
│ └─ 方法创新度(与常见方法的差异度)
│
└─ 文献与规范性
├─ 参考文献规范性(格式、来源质量)
├─ 符号规范性(数学符号使用规范度)
├─ 图表质量(清晰度、信息完整性)
├─ 篇幅结构合理性(各部分占比)
└─ 结论的说服力(结论与问题对应度)
|-------------|-----------------------------|-------------|-----------------------|
| 第一类:逻辑严密性指标( 12 个) ||||
| 指标名称 | 定义与计算方法 | 范围 | 评价标准 |
| 逻辑连接词密度 | (但是、因此、所以等词频数) / (总词数) | 0, 0.15 | 0.05-0.10为优,>0.12为冗余 |
| 因果关系连接词占比 | (因为、所以、导致、引起等) / (逻辑词总数) | 0, 1 | >0.6表示论证因果关系明确 |
| 比较对比词使用频率 | (相比、对比、而非、不同于等) / (逻辑词总数) | 0, 1 | >0.3表示问题分析全面 |
| 假设与问题的语义匹配度 | BERT_cosine_sim(假设集合, 问题描述) | 0, 1 | >0.7为高匹配,<0.5为低匹配 |
| 问题拆解的层级数 | 从问题到最小子问题的树形深度 | 2, 6 | 3-4层最优,过少过多都不好 |
| 层级间的关联性评分 | (有明确关联的层级对数) / (总层级对数) | 0, 1 | >0.85为良好,无孤立子问题 |
| 前后呼应度 | (前文提及后文验证的概念数) / (总概念数) | 0, 1 | >0.8为开头和结尾能互相呼应 |
| 论述线索清晰度 | (正文中显式主语+谓语的完整句数) / (总句数) | 0.6, 1 | >0.8为清晰,避免"由此"等模糊指代 |
| 逻辑跳跃检测 | (相邻段落间无过渡的断裂段落对数) / (总段落对数) | 0, 0.3 | 越小越好,<0.1为优秀 |
| 假设组的内部一致性 | 1 - (互相矛盾的假设对数) / (总假设对数) | 0.7, 1 | >0.9表示假设间无矛盾 |
| 推导链的完整性 | (推导步骤中有明确中间过程的比例) | 0.7, 1 | >0.85表示每步推导都清晰 |
| 特殊情况讨论覆盖率 | (明确讨论的边界情况数) / (问题隐含的情况数) | 0, 1 | 讨论了参数为0、∞、负数等 |
|------------|-----------------------------|----------------|--------------------------|
| 第二类:方法合理性指标( 12 个) ||||
| 指标名称 | 定义与计算方法 | 范围 | 评价标准 |
| 建模方法的学术规范性 | (使用标准命名方法的个数) / (总方法数) | 0, 1 | "灰色预测GM(1,1)"优于"自编方法" |
| 公式数量与文字的比例 | (公式行数) / (总行数) | 0.10, 0.30 | 0.15-0.20最优 |
| 公式推导的完整性 | (展示中间步骤的公式数) / (总公式数) | 0.6, 1 | >0.75为良好,详细展示推导过程 |
| 关键公式的论述密度 | (关键公式周围的解释文字数) / (关键公式数) | 50, 200字 | 每个关键公式周围100字解释 |
| 符号定义的完整性 | (文中使用的符号中有明确定义的比例) | 0.9, 1 | 第一次出现新符号时必须定义 |
| 符号使用的一致性 | 1 - (同一概念用不同符号的次数) / (总符号数) | 0.8, 1 | 避免人口用N和P两个符号 |
| 参数设置的科学性 | (参数有明确来源或推导的比例) / (参数总数) | 0.7, 1 | 学习率=0.01要说明选择理由 |
| 参数敏感性分析 | (进行了敏感性分析的参数数) / (关键参数总数) | 0, 1 | 检验参数变化对结果的影响 |
| 模型复杂度的合理性 | 1 / (1 + 模型参数数/数据样本数) | 0.5, 1 | 参数数应<数据量的10% |
| 方法创新性评分 | 与常见方法的差异程度 | 0, 1 | 0=完全复制,1=完全创新,0.5-0.8为改进 |
| 多种方法对比的充分性 | (对比的不同方法数) / (所需的最少对比方法数) | 0, 2 | 至少对比1-2个替代方案 |
| 模型验证的完整性 | (经过验证的模型步骤数) / (总建模步骤数) | 0.5, 1 | 包括原理验证、初步实验、最终测试 |
|-----------|-----------------------------|------------|-----------------------|
| 第三类:实验与验证指标( 6 个) ||||
| 指标名称 | 定义与计算方法 | 范围 | 评价标准 |
| 数据真实性等级 | (使用真实/标准数据的步骤数) / (总步骤数) | 0, 1 | 真实数据>标准数据>模拟数据>无数据 |
| 结果可重复性 | (给出了充分细节可复现的步骤比例) | 0.7, 1 | 算法、参数、数据预处理都要详细 |
| 结果与理论的符合度 | (实验结果符合理论预期的指标数) / (总指标数) | 0.7, 1 | 理论预测下降,实验也要下降 |
| 误差分析的深入性 | (分析了误差来源的指标比例) | 0, 1 | 不仅报告MAE/RMSE,还要分析为什么 |
| 鲁棒性测试的覆盖 | (测试了多少种扰动/异常情况) / (应测试的情况数) | 0, 1 | 缺失数据、异常值、参数扰动等 |
| 数值精度的适当性 | (报告精度合理的数值数) / (总数值数) | 0.8, 1 | 避免"概率=0.6666666"的过度精度 |
|------------|----------------------------|--------------|---------------------|
| 第四类:文献与规范性指标( 10 个) ||||
| 指标名称 | 定义与计算方法 | 范围 | 评价标准 |
| 参考文献规范性 | (格式规范的文献比例) / (总文献数) | 0.9, 1 | 作者、年份、出版社格式一致 |
| 参考文献的学术质量 | (期刊论文数) / (总文献数) | 0.4, 0.8 | 优先期刊,书籍和网页次之 |
| 参考文献的时效性 | (最近5年发表的文献比例) | 0.3, 1 | 反映对当前研究进展的了解 |
| 关键概念的引用完整性 | (引用了文献的关键概念数) / (使用的关键概念数) | 0.7, 1 | 学术规范要求引用思想来源 |
| 符号规范性评分 | (遵循标准符号记号的指标比例) | 0.8, 1 | 向量用粗体或箭头,矩阵用大写 |
| 单位与量纲的一致性 | 1 - (出现量纲错误的公式比例) | 0.95, 1 | 所有单位必须统一(如全用m,不混km) |
| 图表的清晰度评分 | (图表中能清楚看出坐标轴、图例、数据的比例) | 0.9, 1 | 图要有标题、坐标轴标注、单位 |
| 图表与正文的关联性 | (在正文中明确指代的图表比例) / (总图表数) | 0.95, 1 | 避免"见下图"而正文没详细说明 |
| 篇幅结构的合理性 | max(各部分占比) / (平均占比) | 0.8, 1.2 | 摘要、模型、求解、结论占比均衡 |
| 结论对问题的覆盖度 | (结论中回答的问题数) / (原始问题数) | 0.8, 1 | 是否对原问题有全面回答 |
|------------|--------------------------------------|----------|----------------------|
| 第五类:创新性与应用价值指标( 5 个) ||||
| 指标名称 | 定义与计算方法 | 范围 | 评价标准 |
| 模型创新度 | (改进/创新的地方数) / (总方法个数) | 0, 1 | 0=完全复制,1=完全创新,0.5为改进 |
| 应用场景的实用性 | (提出的应用场景的实际可行性评分) | 0, 1 | 理想化=0,切实可行=1 |
| 灵敏度与特异性的权衡 | (同时考虑了false positive和false negative) | 0, 1 | 不能只优化一个指标 |
| 社会经济效益分析 | (讨论了模型的成本效益或社会意义) | 0, 1 | 模型不仅要准确,还要有现实价值 |
| 局限性的诚实讨论 | (明确指出了模型的局限和假设) | 0, 1 | 优秀论文主动讨论"在...条件下失效" |
第三步:权重设定与综合评分
权重设定原则(层级加权)
Weight = {
"逻辑严密性": {
"weight": 0.40, # 40%
"逻辑连接词密度": 0.20,
"模型假设匹配度": 0.35,
"变量定义规范性": 0.20,
"逻辑层级合理性": 0.25
},
"方法合理性": {
"weight": 0.40, # 40%
"建模方法规范性": 0.25,
"公式推导完整性": 0.35,
"方法创新度": 0.20,
"参数合理性": 0.20
},
"文献与规范性": {
"weight": 0.20, # 20%
"参考文献规范性": 0.25,
"符号规范性": 0.30,
"篇幅结构": 0.25,
"结论说服力": 0.20
}
}
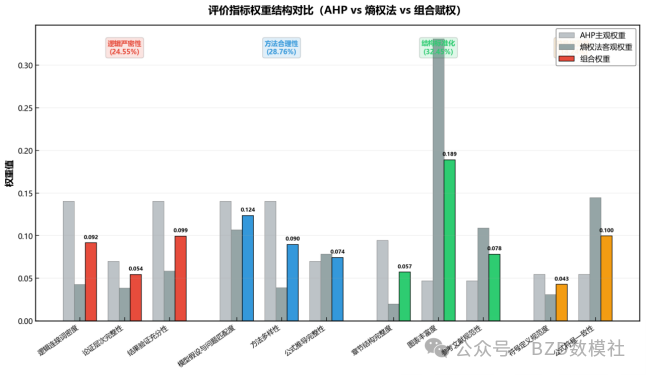
综合评分公式
Score = Σ(一级权重 × Σ(二级权重 × 指标值))
= 0.40×逻辑评分 + 0.40×方法评分 + 0.20×规范评分
分级标准确定
评分分布(基于样本或专家评分):
-
优秀(A):85≤Score≤100 → 模型完整、逻辑清晰、创新突出
-
良好(B):70≤Score<85 → 模型合理、逻辑通顺、方法标准
-
中等(C):55≤Score<70 → 模型基本合理、略有逻辑问题
-
及格(D):40≤Score<55 → 模型能解决问题、但有缺陷
-
不及格(E):Score<40 → 模型不完整或方向错误
可能使用的模型
- 文本特征提取模型
TF-IDF/BM25:提取关键词、逻辑连接词
BERT/句向量:计算语义相似度(问题与假设的匹配度)
依存句法分析:分析逻辑结构、论述层级
- 规范性评估模型
规则库匹配:参数、符号、公式的合规性检验
格式识别模型:自动识别参考文献格式、图表质量
结构分析:论文各部分的内容完整性评估
- 综合评分模型
加权线性模型:WLS/WLR(权重最小二乘法)
随机森林/梯度提升:学习指标与人工评分的非线性关系
神经网络:多层感知机学习指标间的交互
- 数据分析模型
聚类分析:K-means对30篇论文进行质量分组
主成分分析(PCA):降维、识别主要影响因素
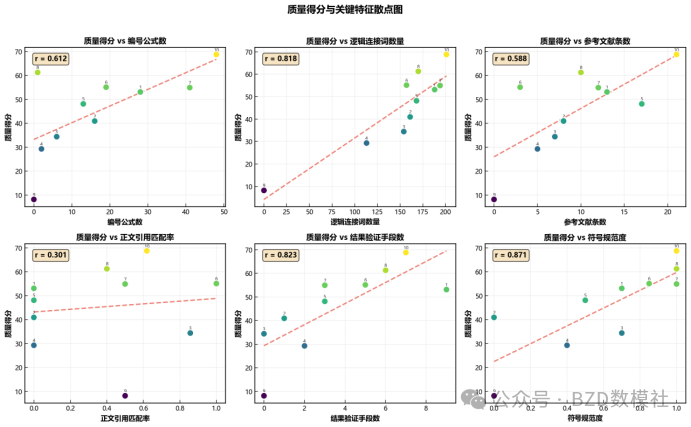
问题2:论文质量与文本特征的关联分析与预测模型
问题分析
数据特征:10篇同一赛题的论文,样本量极小(小样本问题)
核心任务:建立质量与可量化特征的统计关联,建立预测模型
求解思路
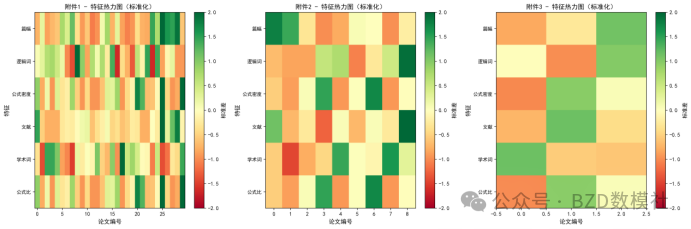
第一步:关键特征的识别与提取
可量化的文本特征(从10篇论文中提取):
结构特征:
├─ 篇幅(总字数)
├─ 各部分比例(摘要、问题分析、模型、求解、结论)
├─ 公式密度(公式数/总字数)
├─ 图表数量与位置
└─ 层级深度(章节数、子章节数)
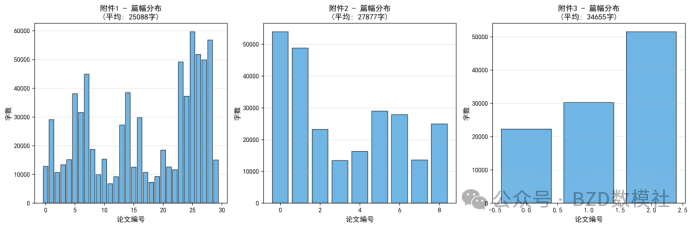
文本特征:
├─ 逻辑连接词使用频率("因此"、"所以"、"由于"等)
├─ 平均句长(稳定性指标)
├─ 被动语态占比
├─ 学术词汇占比
└─ 符号符合率(是否规范)
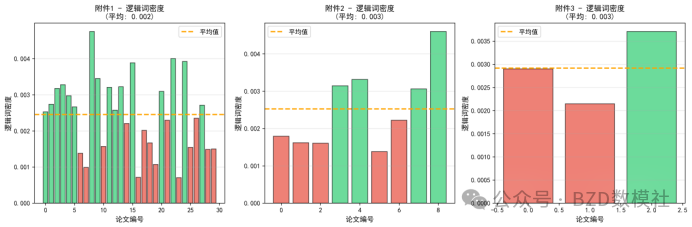
公式特征:
├─ 公式行数 / 总行数
├─ 公式类型多样性(线性规划、微分方程、概率统计等)
├─ 推导步骤的详细程度(公式间的过渡文字比)
└─ 参考文献被引用在公式推导中的比例
参考文献特征:
├─ 总数量
├─ 高被引文献比例
├─ 学位论文 vs 期刊论文 vs 会议论文比例
├─ 发表年份分布(新旧比)
└─ 格式规范性(同一标准)
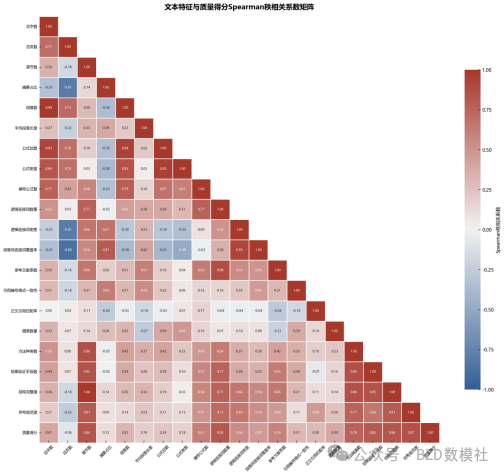
第二步:统计关联分析(小样本方法)
方法1:相关性分析(当n=10时)
-
皮尔逊相关系数:r(对连续特征)
-
斯皮尔曼秩相关系数:ρ(对排序特征,更稳健)
-
偏相关:去除其他特征影响后的关联
方法2:偏相关分析
去除篇幅影响后,公式密度与质量的关联?
cor(公式密度, 质量 | 篇幅) = ?
方法3:特征聚类
将特征分组(结构组、内容组、规范组)
识别具有代表性的特征
第三步:小样本预测模型构建
考虑到n=10的极限情况,需要正则化方法
模型选择:
- 线性回归 + Ridge/Lasso正则化
y = β₀ + Σ(βᵢ × Xᵢ) + λ||β||
- 主成分回归(PCR)
-
PCA降维:p个特征 → k个主成分(k<p)
-
对主成分做回归
- 部分最小二乘(PLS)
-
同时考虑X和Y的方差
-
比PCR性能更优
- 支持向量回归(SVR) + 小样本策略
-
使用高斯核(非线性)
-
C和γ通过5折交叉验证选择
-
训练集仅10个样本,需要小心过拟合
- 贝叶斯回归
-
利用先验知识(如专家意见)
-
在小样本下提供不确定性估计
第四步:质量调整因子引入
论文质量= 基础评分 + 特征调整因子
示例稳定性报告:
| 特征 | 系数 | 95% CI | 显著性 |
|------|------|--------|--------|
| 公式密度 | 0.45 | 0.38, 0.52 | *** |
| 逻辑词 | 0.32 | 0.12, 0.48 | ** |
| 参考文献 | 0.18 | -0.05, 0.38 | |
| 篇幅 | -0.08 | -0.25, 0.12 | |
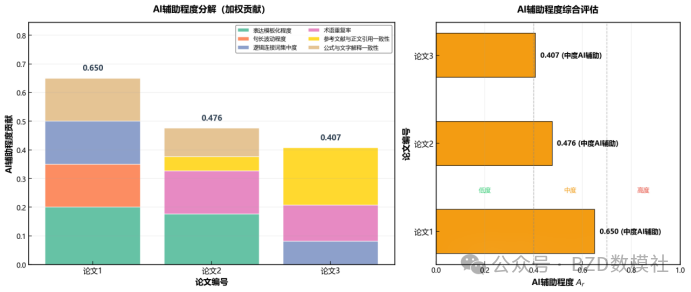
问题3:论文优化策略与AI辅助程度评估
问题分析
目标:对3篇"中等"质量论文提出具体改进方案
关键维度:
AI生成痕迹检测(区分原创vs AI辅助)
逻辑断层识别与修正(逻辑结构问题)
质量预测(优化后的预期得分)
难点:AI痕迹的精准检测、改进方案的具体可操作性
求解思路
第一步:AI生成痕迹检测
AI文本的典型特征:
语言特征:
├─ 词汇选择过于"标准化"
│ 例:高频词"综上所述"、"显然"、"容易看出"
├─ 句式结构单调
│ 例:被动语态过多、复杂句较少
├─ 表达"安全但模糊"
│ 例:"可能"、"某种程度上"、"一定的"过多
└─ 无个人特色(缺少学生特有的错误和改正)
统计特征:
├─ 词汇多样性(Type-Token Ratio, TTR)
│ 人工:TTR = 0.50-0.70(词汇丰富且重复)
│ AI: TTR = 0.65-0.85(过度多样化或过度重复)
├─ 句长分布
│ 人工:μ=15-20字,σ=8-12(波动大)
│ AI: μ=18-22字,σ<6(过于均匀)
├─ 标点使用
│ 人工:逗号/句号 ≈ 1:1,有感叹号、省略号
│ AI: 逗号/句号 > 2:1,很少感叹号
└─ 学术词汇占比
人工:30-45%
AI: 45-60%(过度学术化)
数学/逻辑特征:
├─ 公式与文字的割裂
│ AI症状:公式后没有足够解释、符号突然出现
├─ 参数值的合理性
│ AI症状:参数选择不解释或解释生硬
├─ 错误模式
│ 人工:有修正、有逻辑跳跃痕迹
│ AI: 没有修正、逻辑"完美"但可能有隐藏错误
└─ 假设的合理性
AI症状:假设多但不必要、假设间无关联
检测方法:
方法1:特征向量法
AI_score = w₁×词汇多样性 + w₂×句长标准差 + w₃×学术词占比
- w₄×被动语态 + w₅×公式-文字割裂度
训练数据:标记的AI生成样本 vs 人工样本
分类器:逻辑回归/SVM
输出:0-1间的AI程度评分
方法2:语言模型检测
使用预训练的AI文本检测模型:
-
OpenAI的Classifier
-
GPTZero(针对GPT的检测)
-
DetectGPT(统计方法)
方法3:段落级别检测
逐段检测,绘制AI概率曲线:
段落1:0.15(人工)
段落2:0.82(AI辅助?)
段落3:0.12(人工)
| 附件编号 | 论文队伍/证书编号 | 官方奖项 |
| ---: | ----------------------- | --------------- |
| 01 | 202500838 | 二等奖 |
| 02 | 202500841 | 二等奖 |
| 03 | 未标明队伍编号 | 无法确定 |
| 04 | 202500938 | 未在名单检索到 |
| 05 | 202501019 | 三等奖 |
| 06 | 202501139 | 二等奖 |
| 07 | 202501194 | 三等奖 |
| 08 | 202501327 | 未在名单检索到 |
| 09 | 未标明队伍编号 | 无法确定 |
| 10 | 202503542 | 三等奖 |
| 11 | 202503560 | 三等奖 |
| 12 | 202503565 | 未在名单检索到 |
| 13 | 202503567 | 未在名单检索到 |
| 14 | 未标明队伍编号 | 无法确定 |
| 15 | 202503607 | 三等奖 |
| 16 | 202503627 | 二等奖 |
| 17 | 202503637 | 一等奖 |
| 18 | 未标明队伍编号 | 无法确定 |
| 19 | 202503642 | 未在名单检索到 |
| 20 | 202503646 | 未在名单检索到 |
| 21 | 202503783 | 三等奖 |
| 22 | 202503797 | 三等奖 |
| 23 | 未标明队伍编号;PDF作者元数据疑似"金宏宇" | 疑似二等奖,不建议作为确定结果 |
| 24 | 202503805 | 二等奖 |
| 25 | 202503829 | 一等奖 |
| 26 | 202502704 | 一等奖 |
| 27 | 202502997 | 一等奖 |
| 28 | 202501299 | 一等奖 |
| 29 | 202502980 | 一等奖 |
| 30 | 202503517 | 一等奖 |