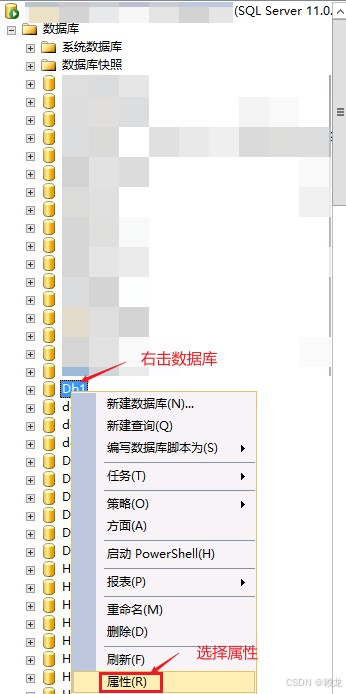
操作过程简单粗暴:修改数据库修复模式为简单------>收缩日志------>恢复数据库修复模式为完整。
如图:
后面是AI生成,想看就看,不看到此结束!
凌晨三点,监控告警突然响起,数据库服务器的磁盘使用率瞬间飙升至 98%。对于很多运维人员和开发者来说,这种场景并不陌生:业务系统运行正常,但数据库的事务日志文件(LDF)却在悄无声息中膨胀到了几十甚至上百 GB,直接占满了磁盘空间。一旦磁盘写满,数据库将立即进入只读或不可用状态,导致前端业务全面阻塞,用户无法登录、订单无法提交,后果不堪设想。
造成这一问题的根源,往往在于数据库长期处于"完整恢复模式"却缺乏定期的日志备份策略。在这种模式下,SQL Server 会保留所有事务日志直到进行备份,以便支持时间点恢复。如果管理员忽略了日志备份,或者业务产生了大量的增删改操作,日志文件就会无限增长。面对这种情况,许多新手容易慌乱中直接删除 LDF 文件,这是绝对禁止的危险操作,会导致数据库损坏甚至无法启动。
正确的处理思路应当是冷静分析、按部就班地执行收缩流程,既要快速释放磁盘空间恢复业务,又要确保数据的一致性和安全性。本文将基于真实的生产环境经验,详细拆解从紧急排查到安全收缩,再到后续预防的全套操作流程。无论你是负责核心系统的 DBA,还是需要临时救火的开发人员,这套方案都能帮助你在不中断服务的前提下,优雅地解决日志暴涨危机。
① 日志文件暴涨引发的业务阻塞场景
当数据库日志文件失控增长时,最直观的表现就是服务器磁盘空间告急。在 Windows 环境下,你可能会发现某个盘符由蓝变红;在 Linux 容器中,则可能表现为挂载卷的使用率达到阈值。此时,数据库引擎会尝试写入新的事务日志,但由于没有可用空间,操作会被挂起。
业务层面的反馈通常非常迅速且剧烈。应用程序端开始出现大量的超时错误,比如"连接超时"、"事务处理失败"或"无法获取锁"。用户侧的表现则是页面加载转圈后报错,或者关键业务流程卡在最后一步。如果是电商大促期间或金融交易高峰期,这种阻塞会在几分钟内引发雪崩效应,导致整个系统瘫痪。
除了直接的业务中断,日志暴涨还会带来严重的性能抖动。即使磁盘尚未完全写满,巨大的日志文件也会导致 I/O 延迟增加,检查点(Checkpoint)进程运行缓慢,进而拖慢整体查询速度。有些时候,你会发现 CPU 和内存资源并未满载,但系统响应却异常迟缓,这往往就是日志文件过大导致的内部碎片化和 I/O 瓶颈在作祟。因此,识别日志文件异常增长的早期信号,是避免生产事故的第一道防线。
② 收缩前的关键备份与状态检查
在执行任何收缩操作之前,必须遵循"数据安全第一"的原则,进行严格的现状检查和备份。首先,我们需要确认当前数据库的恢复模式以及日志文件的具体大小。可以通过以下 SQL 查询快速获取关键信息:
sql
-- 查看数据库名称、恢复模式及日志文件大小
SELECT
name AS DatabaseName,
recovery_model_desc AS RecoveryModel,
size * 8 / 1024 AS LogSizeMB
FROM sys.databases d
JOIN sys.master_files f ON d.database_id = f.database_id
WHERE f.type_desc = 'LOG';这条命令能帮你确认目标数据库是否处于 FULL(完整)或 BULK_LOGGED(大容量日志)模式,这两种模式是导致日志不自动截断的主要原因。同时,记录下当前的日志文件大小,以便后续对比收缩效果。
接下来是最关键的一步:备份。虽然我们的目标是释放空间,但在生产环境中,任何对数据文件的修改操作都伴随着潜在风险。务必先执行一次完整的数据库备份或至少是一次事务日志备份。这不仅是为了防止误操作导致的数据丢失,更是为了在收缩过程中发生意外时拥有回滚的底气。
sql
-- 执行事务日志备份(假设备份路径为 D:\Backups)
BACKUP LOG [YourDatabaseName] TO DISK = 'D:\Backups\YourDatabaseName_Log_Truncate.bak'
WITH INIT, NAME = 'Pre-Shrink Log Backup';执行完备份后,再次检查磁盘剩余空间,确保有足够的余地容纳临时操作产生的开销。只有在确认备份成功且状态清晰后,才能进入下一步的收缩操作。切记,跳过备份直接收缩是生产环境的大忌。
③ 切换简单恢复模式释放日志空间
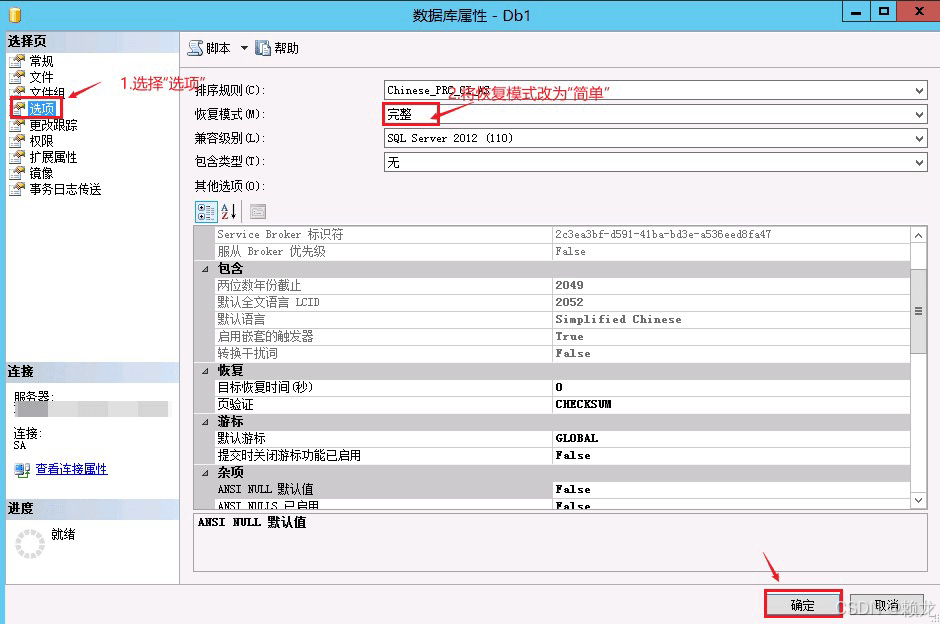
如果数据库当前处于"完整恢复模式",直接执行收缩命令往往效果不佳,因为 SQL Server 会认为这些日志还需要用于未来的时间点恢复,从而拒绝释放空间。为了快速切断日志链并标记无用日志为可重用,我们需要临时将数据库切换到"简单恢复模式"(Simple Recovery Model)。
在简单恢复模式下,数据库引擎会在每个检查点后自动截断不再需要的事务日志,将其标记为空闲空间。这一步操作不会删除数据,只是改变了日志的管理策略,使其不再等待日志备份。执行代码如下:
sql
-- 将数据库切换为简单恢复模式
USE master;
GO
ALTER DATABASE [YourDatabaseName] SET RECOVERY SIMPLE WITH NO_WAIT;
GO执行成功后,建议再次运行一次检查点命令,强制数据库立即清理已提交事务的日志记录:
sql
-- 强制执行检查点,加速日志截断
CHECKPOINT;
GO此时,你会发现逻辑上的日志使用率已经大幅下降,但物理文件的大小(即占据磁盘的空间)暂时还不会改变。这就好比房间里的垃圾已经被清理到了门口,但还没有搬出房子。接下来就需要通过收缩操作,将这些"门口"的空闲空间真正归还给操作系统。需要注意的是,切换恢复模式会中断日志备份链,因此在问题解决后必须尽快还原,否则将无法实现基于时间点的精细恢复。
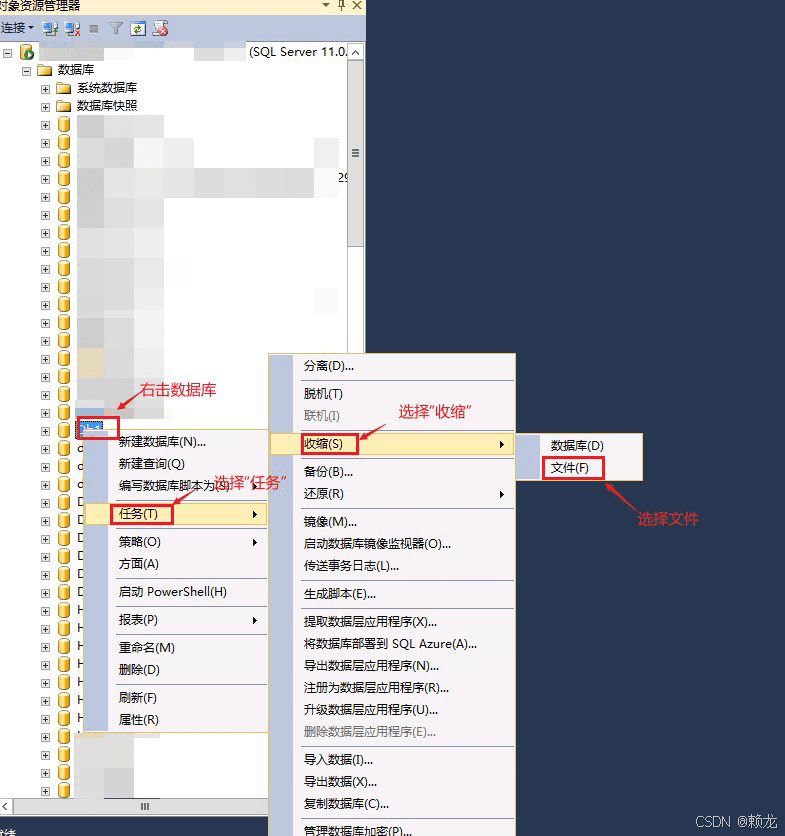
④ 执行 DBCC 命令精准收缩文件
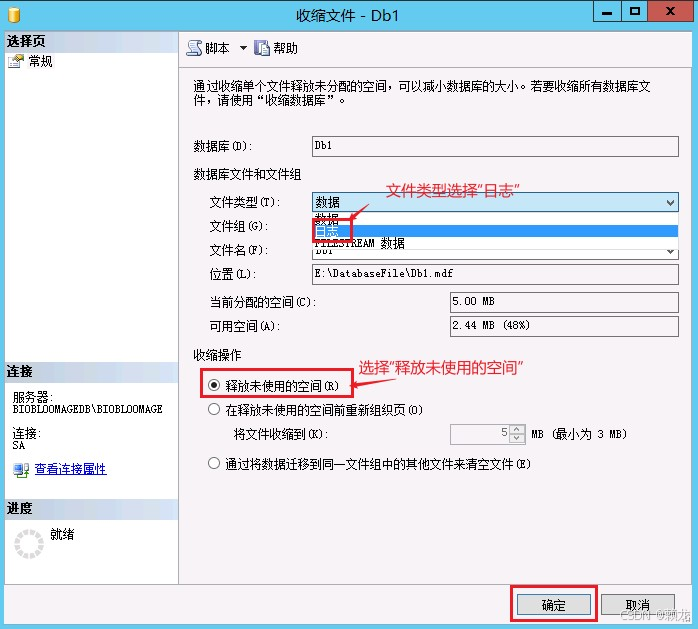
当日志被标记为空闲后,就可以使用 DBCC SHRINKFILE 命令来物理缩小文件了。与 SHRINKDATABASE 不同,SHRINKFILE 允许我们针对特定的日志文件进行操作,更加精准且对性能影响更小。
首先,我们需要知道日志文件的逻辑名称。可以通过 sp_helpdb 或之前的查询结果获取。假设日志文件的逻辑名为 YourDatabaseName_log,我们可以执行以下命令将其收缩到一个合理的大小,例如 1024 MB(1GB):
sql
-- 收缩日志文件到指定大小(单位:MB)
USE [YourDatabaseName];
GO
DBCC SHRINKFILE (N'YourDatabaseName_log', 1024);
GO这里的第二个参数 1024 代表你希望文件最终保留的大小。SQL Server 会尽可能地将文件收缩到这个数值,但如果文件中包含活跃的事务日志(例如未提交的大事务),则可能无法完全收缩到指定值。在这种情况下,可以适当调大目标值,或者检查是否有长事务阻塞。
如果在执行后发现文件依然很大,可以尝试多次执行该命令,或者先将目标值设得更小一些,让引擎分批次移动数据页。不过要注意,过度频繁的收缩操作会产生大量的碎片,影响后续写入性能。通常情况下,执行一到两次即可看到显著效果。执行完毕后,再次查询 sys.master_files 确认文件大小是否已按预期减少,磁盘空间是否得到释放。
⑤ 还原完整恢复模式保障数据安全
一旦日志文件成功收缩,磁盘危机解除,我们必须立即将数据库恢复模式改回"完整恢复模式"。这是保障数据安全的核心步骤,因为只有在该模式下,数据库才支持完整的事务日志备份和时间点恢复(Point-in-Time Recovery)。如果长期停留在简单恢复模式,一旦发生误删除或数据损坏,只能恢复到最近的一次完整备份,中间的所有数据变更都将丢失。
还原操作的 SQL 语句非常简单:
sql
-- 还原为完整恢复模式
USE master;
GO
ALTER DATABASE [YourDatabaseName] SET RECOVERY FULL WITH NO_WAIT;
GO切换回完整模式后,日志备份链实际上已经断裂。为了让新的日志链生效,必须立即执行一次完整的数据库备份或差异备份。这一步至关重要,它标志着新备份周期的开始。
sql
-- 执行完整备份以重建日志链
BACKUP DATABASE [YourDatabaseName] TO DISK = 'D:\Backups\YourDatabaseName_Full_AfterShrink.bak'
WITH INIT, COMPRESSION, NAME = 'Post-Shrink Full Backup';完成这次备份后,后续的常规日志备份任务就可以照常进行了。至此,我们从紧急切换、收缩文件到恢复策略的闭环操作已经完成,数据库重新回到了安全可控的状态。
⑥ 验证收缩结果与空间回收率
操作完成后,不能想当然地认为一切正常,必须进行严格的验证。首先,再次运行最初的查询语句,对比收缩前后的日志文件大小,计算空间回收率。
sql
-- 验证收缩后的文件大小
SELECT
name AS DatabaseName,
size * 8 / 1024 AS CurrentLogSizeMB,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT) * 8 / 1024 AS UsedSpaceMB
FROM sys.database_files
WHERE type_desc = 'LOG';通过对比 CurrentLogSizeMB 和之前的数值,你可以直观地看到释放了多少 GB 的磁盘空间。同时,关注 UsedSpaceMB,确保日志的使用量处于合理范围(通常应远小于文件总大小)。如果文件大小依然很大但使用量很小,说明收缩操作可能未完全生效,或者存在虚拟日志文件(VLF)碎片过多的问题。
此外,还要观察业务系统的运行状态。检查应用程序日志,确认之前的超时错误或连接失败是否消失。监控数据库的性能计数器,如"日志字节写入"、"日志刷新延迟"等,确保 I/O 性能恢复正常。如果可能,进行一次小规模的数据写入测试,验证事务提交的流畅度。只有当磁盘空间充裕、业务响应正常且备份策略就绪时,这次应急处理才算真正成功。
⑦ 建立定期维护防止日志再次膨胀
解决眼前的问题只是第一步,更重要的是建立长效机制,防止日志文件再次失控暴涨。最根本的解决方案是实施规律的日志备份策略。在完整恢复模式下,定期的日志备份不仅是为了灾难恢复,更是为了截断日志、释放空间的必要手段。
建议根据业务交易量设置备份频率。对于高并发系统,可以每 15 分钟甚至更短时间备份一次日志;对于低频系统,每小时或每天备份一次也可接受。可以使用 SQL Server Agent 创建自动化作业,确保备份任务按时执行,并配置报警机制,一旦备份失败立即通知管理员。
sql
-- 示例:创建每日完整备份和每小时日志备份的作业逻辑(伪代码示意)
-- 实际需在 SSMS 图形界面或 PowerShell 中配置 Job Step
-- Step 1: BACKUP DATABASE ...
-- Step 2: BACKUP LOG ...除了备份策略,还应监控日志文件的增长趋势。可以设置监控脚本,当日志文件增长率超过阈值或剩余空间低于警戒线时自动发送告警。另外,避免在业务高峰期执行大批量的数据导入或删除操作,如果必须进行,建议分批处理或在临时切换到简单模式(需谨慎评估风险)后进行,以减少对日志空间的瞬时冲击。良好的维护习惯是数据库稳定运行的基石。
⑧ 生产环境操作的风险规避建议
尽管上述流程在理论上成熟可靠,但在生产环境执行时仍需保持高度的敬畏之心。首先,严禁在业务高峰期进行收缩操作。收缩文件是一个高 I/O 消耗的过程,可能会引起短暂的锁竞争或性能抖动,选择在业务低峰期(如深夜)执行是最稳妥的选择。
其次,不要追求将日志文件收缩到极小。日志文件需要一定的预分配空间来应对突发的事务流量。如果将其收缩到几兆字节,随后业务激增导致文件频繁自动增长(Auto-grow),这会严重消耗系统资源并产生大量碎片,反而降低性能。建议根据历史峰值预留 20%-30% 的缓冲空间。
最后,始终保留操作的回滚预案。在执行每一步之前,确保最近的备份是可用的,并且验证过备份文件的完整性。如果在收缩过程中遇到意外报错(如文件被占用、空间不足等),应立即停止操作,排查原因,切勿强行重试。对于核心数据库,建议在测试环境先完整演练一遍流程,熟悉每一个输出信息和潜在坑点后再上手生产。稳健的操作习惯和周全的准备,才是应对生产危机的最大底气。