🎯 困惑 :AI 圈每天冒出成吨新名词------LLM、Token、RAG、MCP、Agent......
你可能都见过,但它们之间到底什么关系?是平级的,还是上下游?
本文做一件事:把这堆名词串成一条线 。
一端是底层数学运算,一端是能帮你干活的智能体。沿着这条线,你不会迷路。
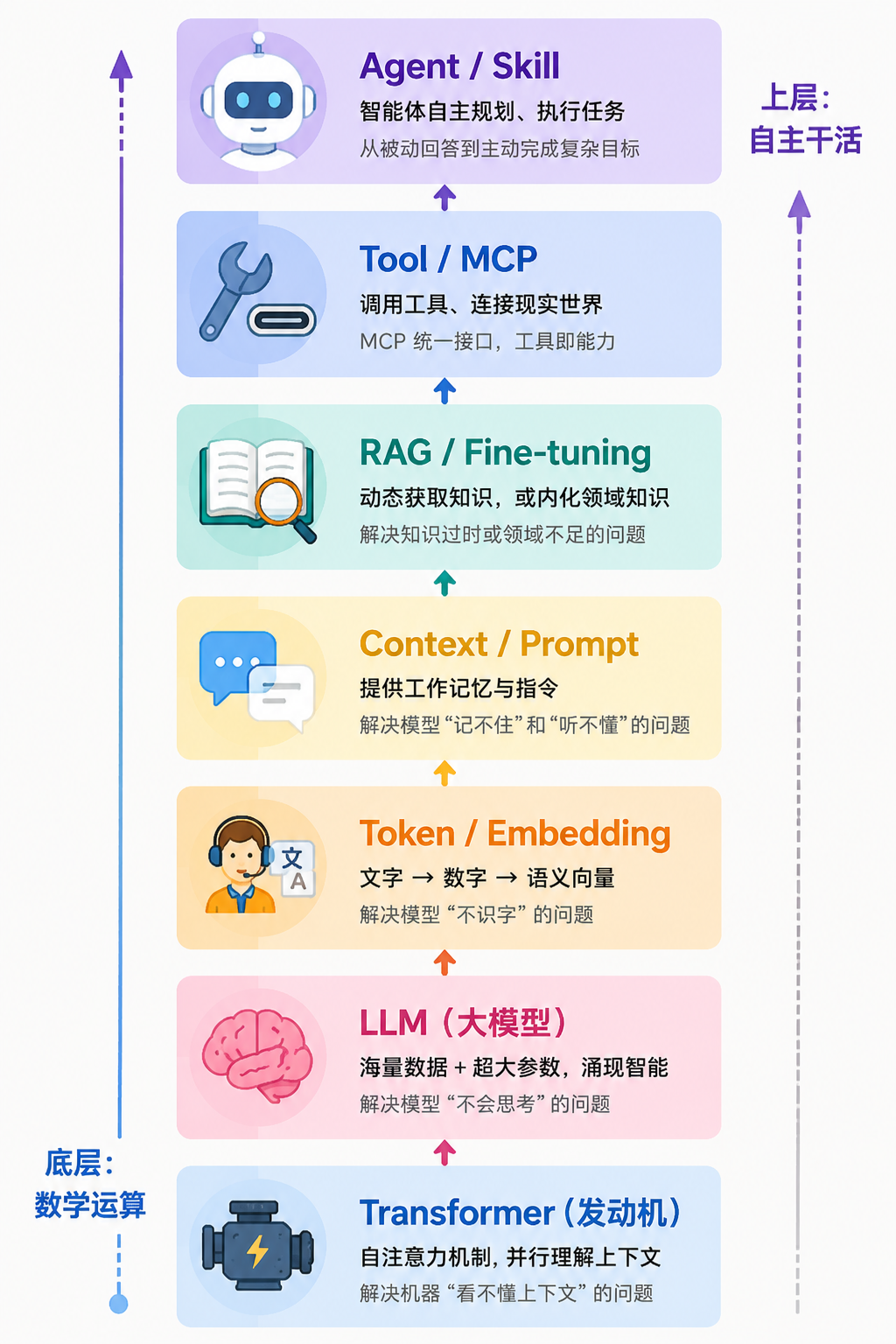
一、底层引擎:模型怎么「理解」文字
Transformer:让机器看到上下文
🎯 矛盾:人类语言模糊------「我喜欢吃苹果」是水果还是手机,你一秒判断,机器不能。
早期方法叫 RNN(循环神经网络)。像一个孩子读课文,一个字一个字往下啃。读到后面前面就忘了。又慢,又容易丢信息。
2017 年,Google 提出了 Transformer。
它的核心叫自注意力机制(Self-Attention)。不再一个字一个字读------一句话全扔进去,每个词同时看其他所有词,找出谁跟自己最相关。就像一个小组讨论:每个人都能听到所有人的发言,再决定自己该说什么。
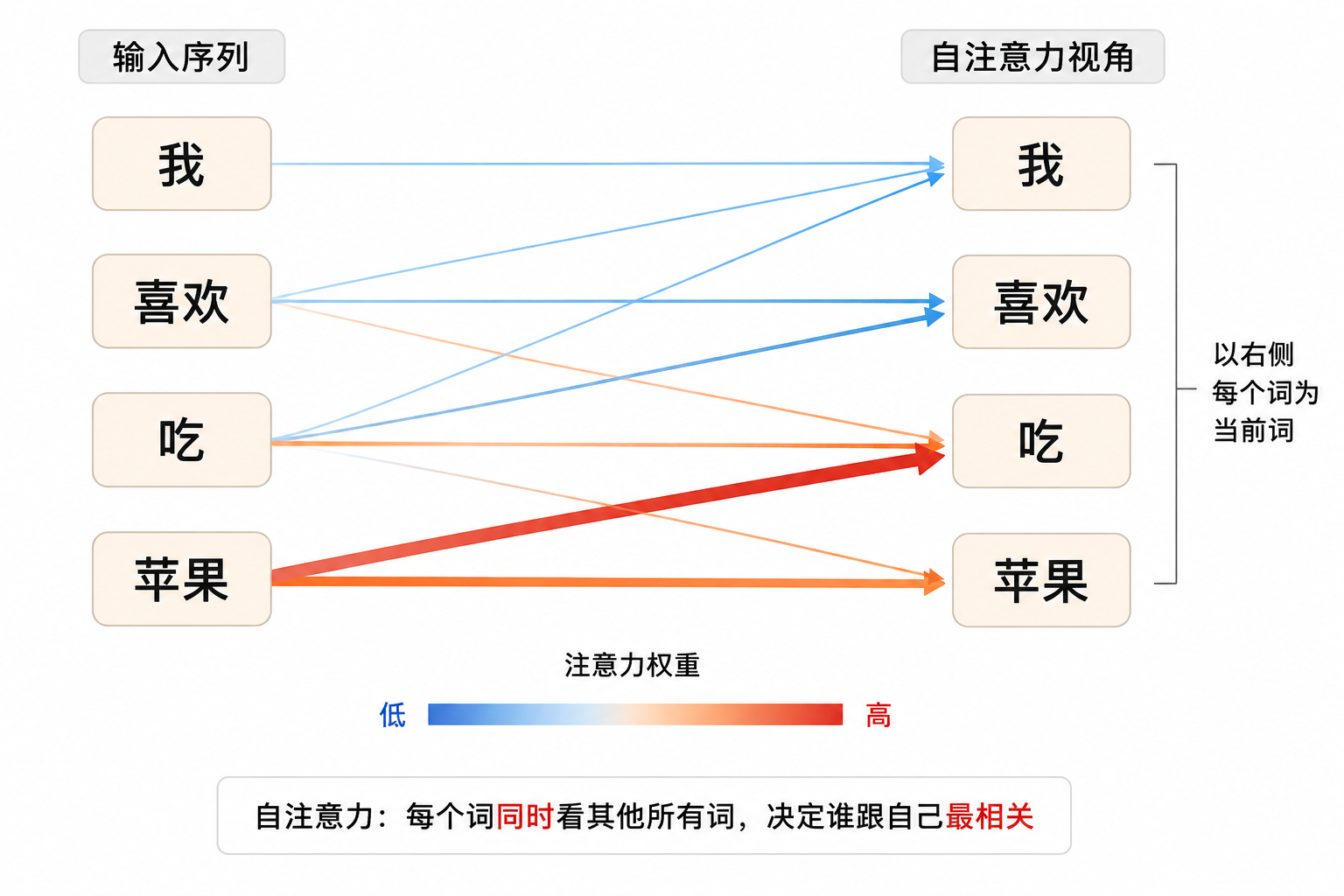
💡 Transformer 是发动机,不是整辆车。GPT、Claude、Gemini、LLaMA------都是用这台发动机造的车。
LLM:文字接龙高手
Large Language Model(大语言模型) 。这个名字太学术了。换个说法:LLM 是一个训练出来的「文字接龙高手」。
- 你写「床前明月」,它接「光」
- 你问「1+1=?」它答「2」
- 你让它写代码,它一行行生成
原理没变------每一步都是预测下一个最合理的词。但当参数量从几百万膨胀到几千亿之后,奇怪的事情发生了:它会推理了,会翻译了,会写诗了,会「举一反三」了。
这个从量变到质变的过程,研究者称之为 涌现(Emergence)。「大」字不是广告词------它是这个现象的前提。
💡 LLM = Transformer + 海量数据 + 超大参数规模。文字接龙玩出了智能。
📌 本站小结
- Transformer 解决了「如何理解上下文」------发动机
- LLM 用海量数据把这台发动机放大,产生了「涌现智能」------整车
- 但 LLM 不识字------它里面跑的是矩阵乘法,只吃数字
二、翻译层:文字怎么变成模型能算的东西
Token & Tokenizer
🎯 矛盾:模型只吃数字,吐出来的也是数字。它压根不认识「你好」------就像一个只会说二进制的外星人。
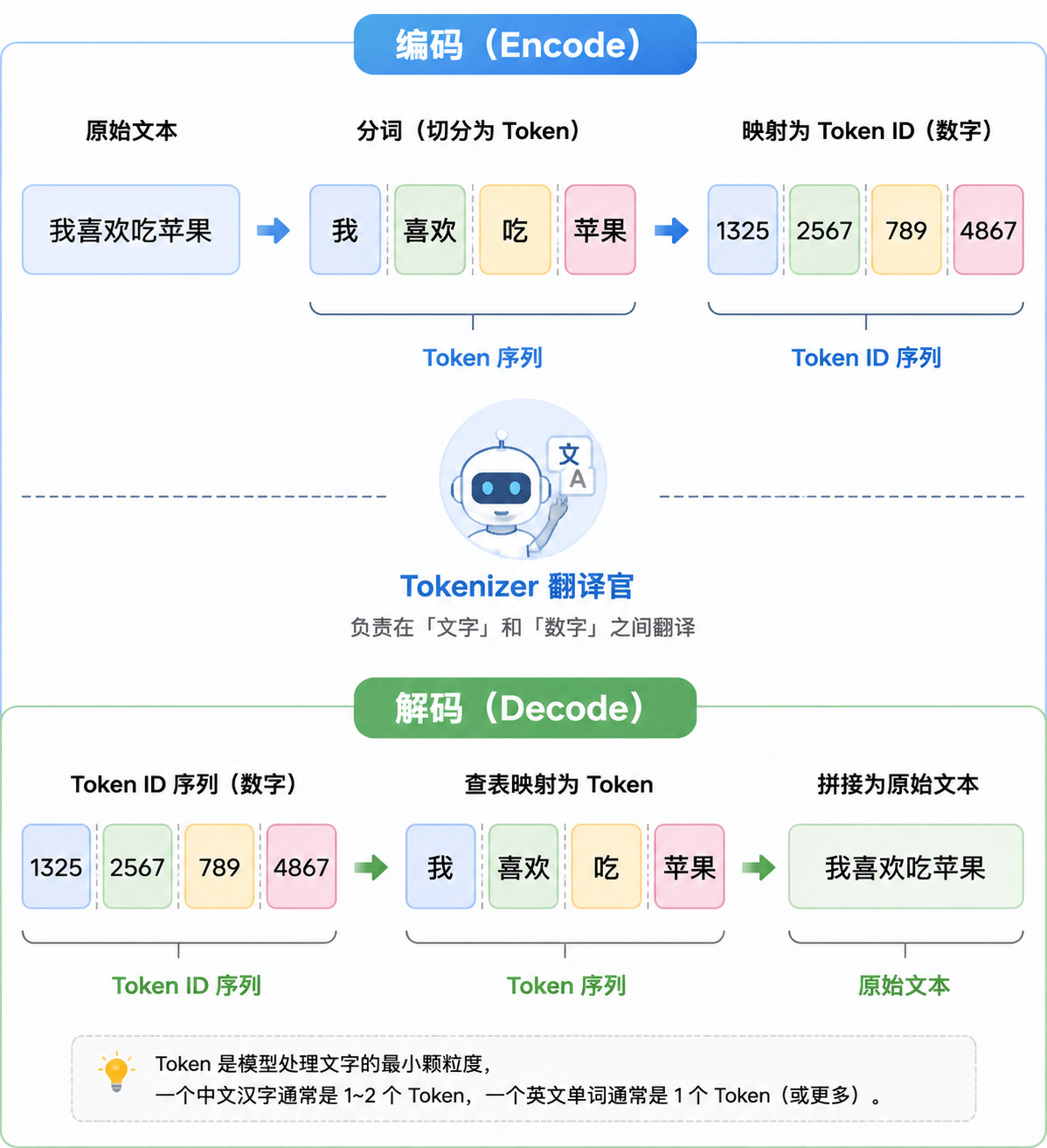
你得在中间架一个翻译官。这就是 Tokenizer(分词器)。
它干两件活:
编码(Encode):文字 → 数字
- 把文字切成小片段------每个片段就是一个 Token
- 每个 Token 去词典里查表,映射成一个数字------Token ID
解码(Decode):数字 → 文字
- 模型每次吐出一个 Token ID
- 反向查表,变回文字片段
- 拼起来,流式输出给你
Token 是大模型处理文字的最小颗粒度。它不是一个「词」------一个英文单词可能被切碎成 2 个 Token
| 语言 | 1 个 Token 约等于 |
|---|---|
| 英文 | 0.75 个单词 |
| 中文 | 1.5 ~ 2 个汉字 |
为什么 GPT 按 Token 计费?因为 Token 就是它的「汽油」------灌进去的每一升,它都得烧。
但 Token ID 只是一个索引号。「猫」= 4867,「狗」= 3291。光看这俩数字,你看不出它们都是宠物。
Embedding:数字到语义的映射
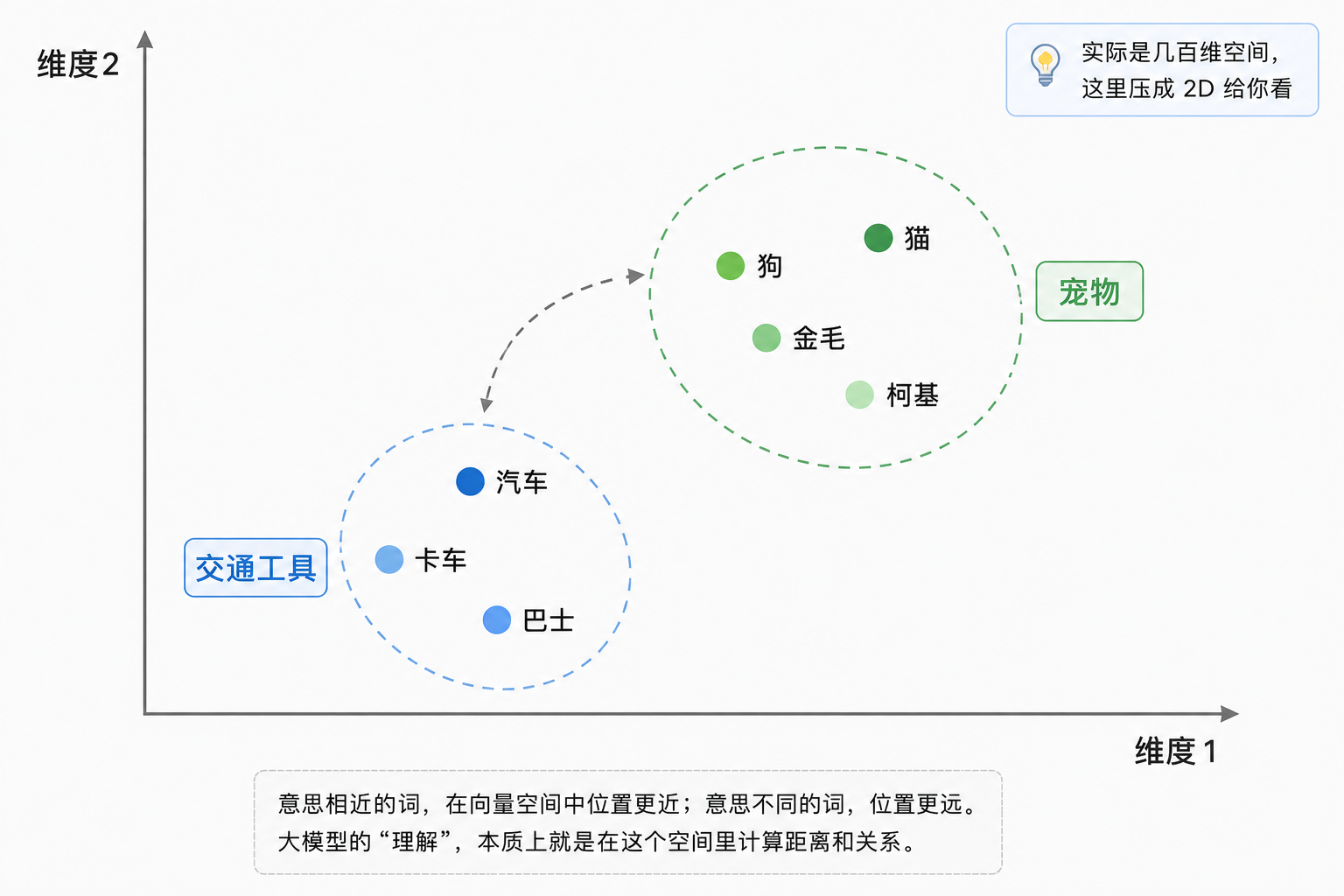
Embedding 干的事:把这个编号,映射成高维空间里的一个坐标。
在这个空间里,意思相近的词位置也近。「猫」离「狗」很近,离「汽车」很远。大模型所有的「理解」,本质上就是在这个向量空间里做加减法。
一个经典到被用烂、但真的很好懂的例子的例子:
- 「国王」-「男人」+「女人」≈「王后」
- 「北京」-「中国」+「日本」≈「东京」
📌 本站小结
- Tokenizer:文字 → 数字(翻译官)
- Embedding:数字 → 有语义的向量(给编号注入意思)
- 模型终于能「看懂」文字了------但它不能只处理当前这句话,它需要记住之前聊了什么
三、工作记忆与使用说明书
Context(上下文)
🎯 矛盾:你跟一个人聊天,他三秒前你说过的话全忘了。这对话能进行下去吗?
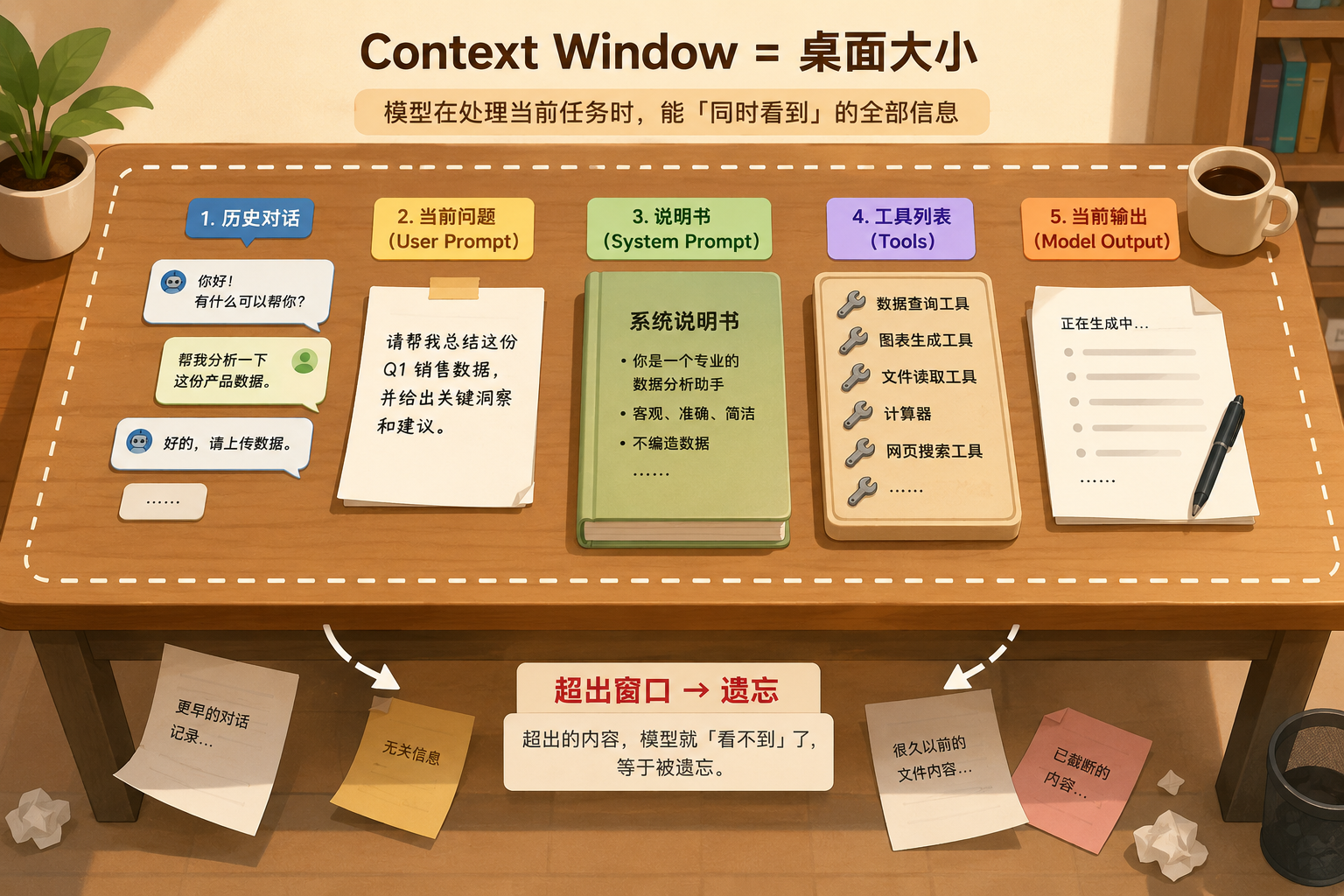
但模型就是这样------它本身没有「记忆」。每次你发消息,平台并不是只把这句话发过去。它会打包一整袋信息一起塞给模型。这袋信息就是 Context(上下文)。
袋子里面装着:
- 你们之前的所有对话记录
- 你刚发的这句话
- 后台给模型定的「人设说明书」(System Prompt)
- 它能用的工具清单
- 它自己已经输出的内容------所以它知道自己说了什么,不会重复
模型读完这袋信息,再决定下一个 Token 是什么。
但这袋子有容量上限。Context Window(上下文窗口) 就是袋子能装的 Token 上限。GPT-4 Turbo 是 128K Token------大约一整本《三体》第一部。超出窗口的对话,模型就「忘干净了」。
这就像你的办公桌------桌面上只能铺开有限的东西。铺不下的收进抽屉,对当下来说等于不存在。
Prompt(提示词)
Prompt = 你给模型的输入。分成两种类型:
| 类型 | 谁写的 | 干什么用 |
|---|---|---|
| System Prompt | 开发者,用户看不到 | 定义模型是谁、什么能做、什么不能做 |
| User Prompt | 你写的 | 具体任务------「帮我翻译」「写段代码」 |
曾经有一段时间,Prompt Engineering 被视为一门手艺------怎么措辞、怎么排列、怎么用「让我们一步一步思考」来引导推理。现在风向变了。不是因为 Prompt 不重要了,而是因为模型变聪明了。你不需要像教小孩一样小心翼翼遣词造句------把需求讲清楚就行。措辞技巧在贬值,思维清晰度在升值。
📌 本站小结
- Context = 模型的工作记忆,窗口大小决定记忆力上限
- Prompt = 你给模型下的「任务书」+ 后台定的「人设」
- 但模型有个死穴:它的知识冻结在训练完成那一天。它不知道「现在发生了什么」
四、知识补丁:让模型知道「现在」
RAG(检索增强生成)
🎯 矛盾:大模型是个博学的古人。它知道训练数据里的一切------但如果训练截止到 2024 年 6 月,它就不知道 2024 年 7 月之后的事。更关键的是,你公司的内部文档、你的个人笔记、你团队的代码规范------它从来没「读」过。
怎么办?两种思路。
第一种思路:考试带小抄。
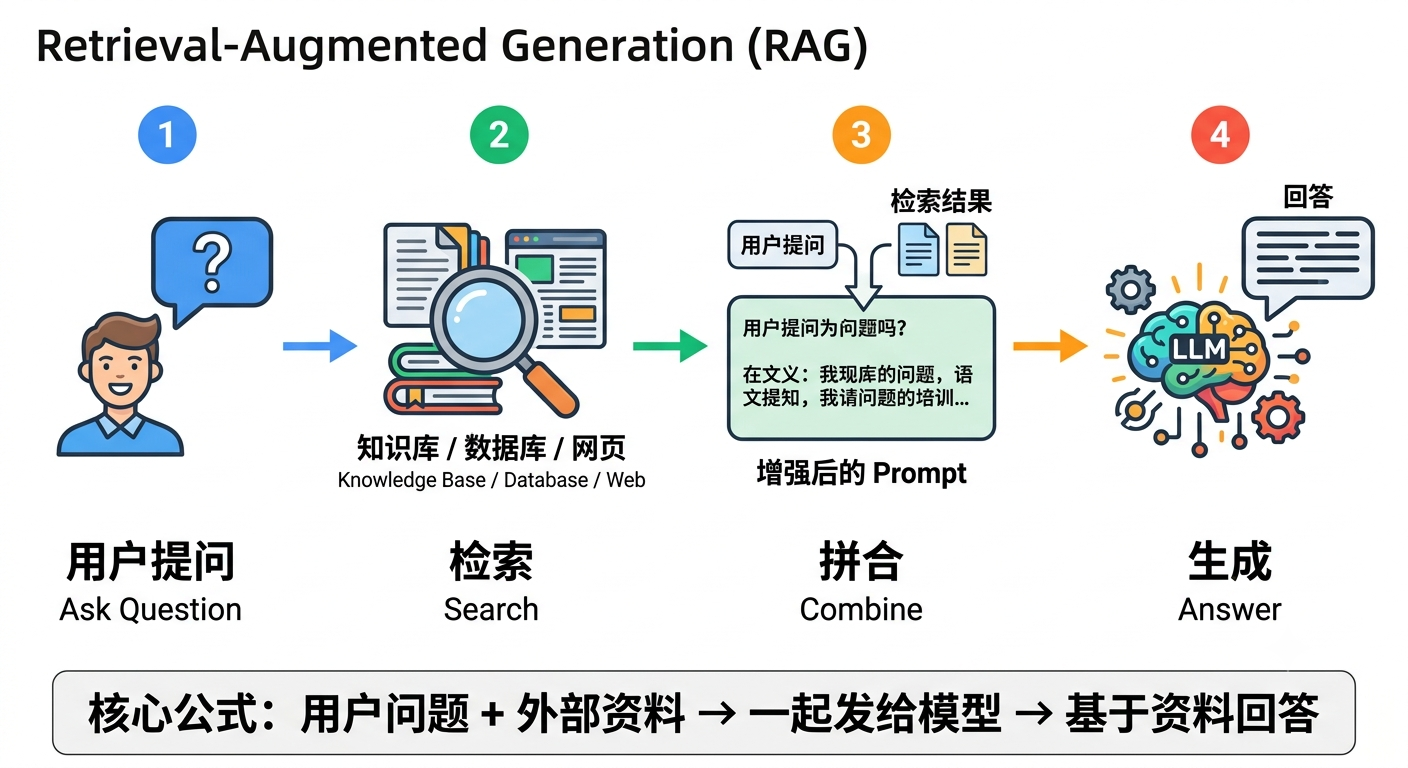
提问时,先到外部知识库(文档、数据库、网页)里翻一圈,把相关内容找出来,贴在你的问题后面------一起发给模型。模型一看:「哦,这是参考资料,我按这个来答。」
这就是 RAG(Retrieval-Augmented Generation,检索增强生成)。
流程:
- 你提问
- 系统先去知识库检索相关内容
- 把检索结果拼进 Context
- 模型基于「外部资料 + 自身知识」生成答案
市面上大部分「AI 知识库」「AI 客服」产品,底层就是 RAG。优点是快、便宜、不碰模型。缺点是检索质量决定回答质量------搜不到就等于没有。
Fine-tuning(微调)
第二种思路:让模型背书。
拿你的领域数据------医学文献、法律合同、产品说明------对模型做额外训练。调整它的一部分参数,让它在特定领域的表现大幅提升。这就是 Fine-tuning(微调)。
通才修一门专业课,变成专才。
| RAG(检索增强) | Fine-tuning(微调) | |
|---|---|---|
| 怎么工作 | 不动模型,外部查资料塞进去 | 改模型本身,内化知识 |
| 类比 | 考试带小抄 | 背书 |
| 优点 | 快、便宜、资料随时更新 | 领域表现更深层、更稳定 |
| 缺点 | 检索质量决定上限 | 贵、慢、更新知识要重新训练 |
两个方案不互斥。很多产品的路径是:先 RAG 快速上线 → 收集真实用户反馈 → 再用 Fine-tuning 深耕。
Hallucination(幻觉)
模型会一本正经地胡说八道。
这不是 bug------这是 LLM 的本质。它不是在「查数据库」,它是在「预测下一个 Token」。每一步选概率最高的那个------但概率高不等于事实正确。当模型缺乏相关知识,被推到知识边界之外,它不会说「我不知道」。它编。编得还很像那么回事。
这是理解 LLM 最关键的认知:它是一个概率系统,不是一个知识库。
RAG 能减少幻觉(用外部资料把它按住)。更好的 Prompt 能减少幻觉(让它知道边界在哪)。但消除幻觉?目前做不到。
Temperature(温度)
控制模型「脑洞」大小的旋钮。
模型预测下一个 Token 时,并不总是选概率最高的那个。有时候故意选个偏的------答案就会更有「创意」。Temperature 就是调节这个「敢不敢偏」的参数。
- 低温度(趋近 0):保守,每次选最安全的词。输出稳定,但可能干巴。
- 高温度(趋近 1+):冒险,偶尔选小概率词。更有趣,但也更容易跑偏。
写代码 → 低温度。写诗 → 高温度。
📌 本站小结
- 模型知识有截止日期 → RAG 给它「带小抄」
- 通用能力不够专 → Fine-tuning 让它「背书」
- 但模型本质是概率预测,不是数据库 → 幻觉无法根除
- Temperature 调节「保守 vs 创意」的平衡
- 但这些全是认知层面的补丁------模型仍然被困在文字世界里。它没有手脚
五、突破边界:让模型触碰现实
Tool(工具调用)
🎯 矛盾:大模型是「缸中之脑」。它能聊量子力学,但不知道现在几点。它能解释天气原理,但查不了明天的温度。它能分析你贴进去的代码,但读不了你硬盘上的文件。因为你每次喂给它的,只有文字。
要想让它感知和影响外部世界,就得给它装手脚 。这就是 Tool(工具)。
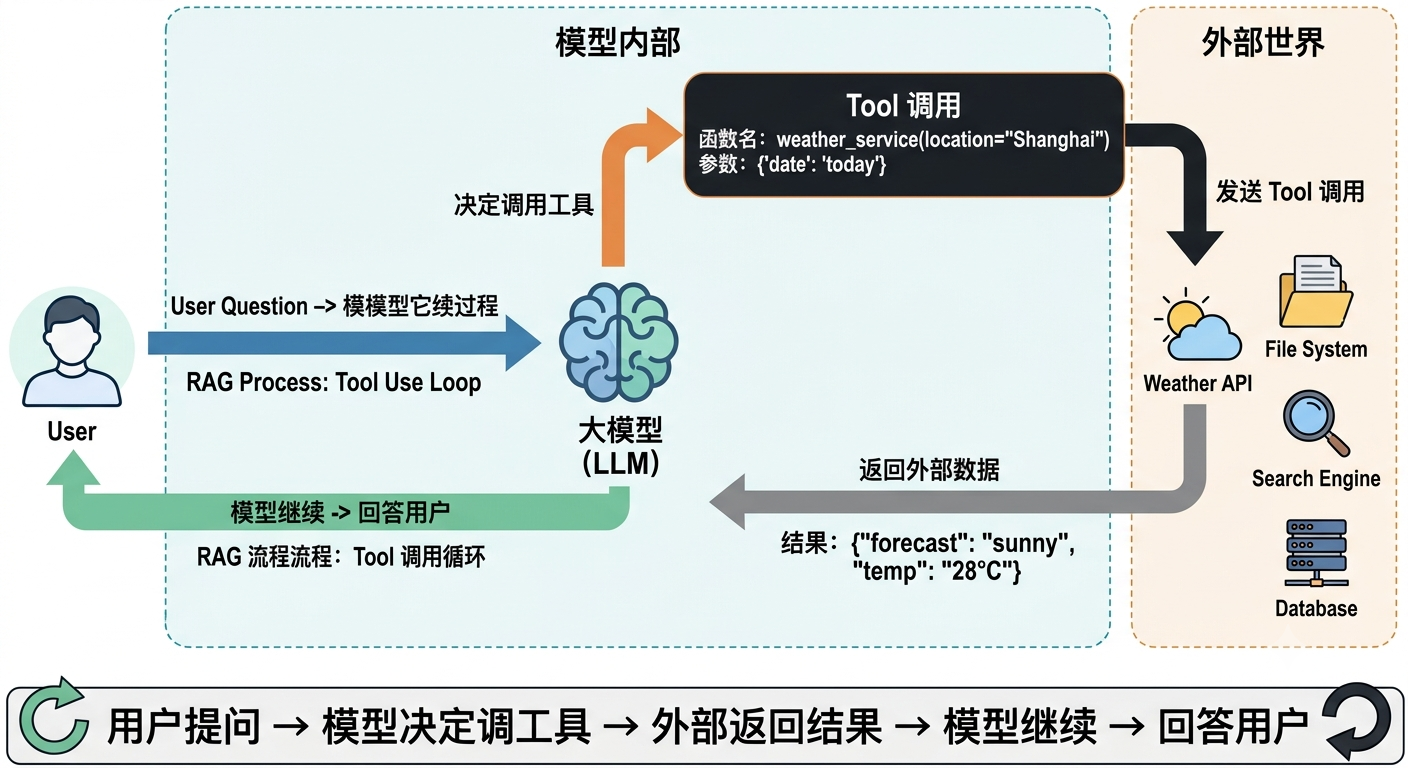
本质上,Tool 就是一个函数(Function) 。模型需要查天气时,它不「猜」天气------它输出一个信号:「我要调用 get_weather 这个函数,参数是城市名。」平台收到信号,执行这个函数,把真实结果(「上海,26°C,多云」)塞回 Context。模型再基于结果继续生成。
流程:用户 → 平台 → 大模型 → 调用工具 → 工具返回结果 → 大模型 → 用户
没有 Tool,模型是图书管理员------只能聊。有了 Tool,模型是你的助理------能查、能写、能发、能改。
但问题又来了。
MCP(模型上下文协议)
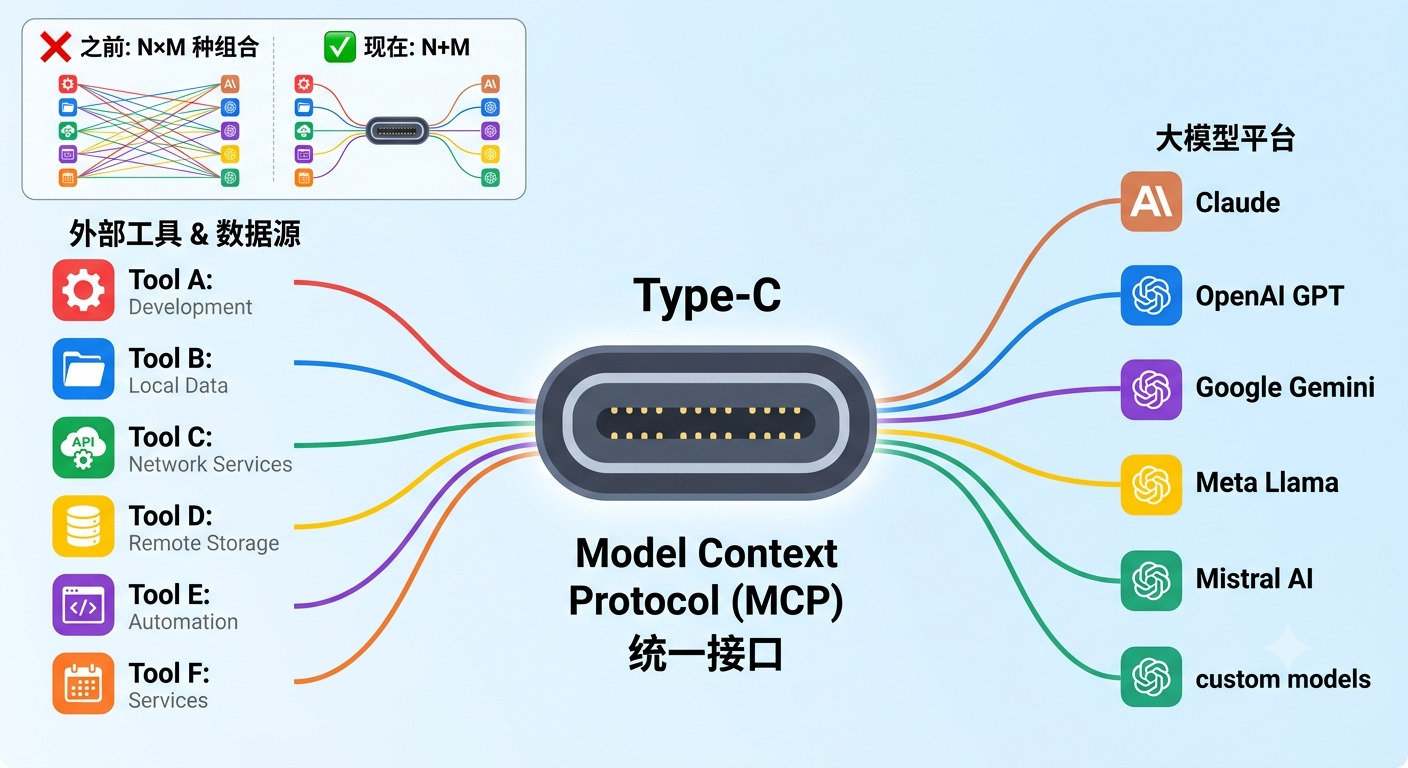
🎯 矛盾:每个平台接入工具的方式都不一样。OpenAI 有一套规范,Anthropic 有一套,Google 又有一套......你写一个工具,想在所有平台跑,得分别适配。工具多了,适配组合指数爆炸------N 个工具 × M 个平台 = N×M 套适配代码。
这是典型的「接口不统一」问题。历史上被解决过很多次。最像的那一次:所有手机充电口统一成 Type-C------之前每家都有自己的充电口,出门带一堆线。统一之后,一根线到处用。
MCP(Model Context Protocol)就是 AI 世界的 Type-C。
Anthropic 在 2024 年底提出的开放协议,定义了工具与 AI 平台之间怎么通信。你按 MCP 写一个服务端,所有支持 MCP 的平台都能直接用。工具开发者不用再为每个平台写适配,平台方不用再为每个工具做集成。这就是协议的力量------把 N×M 的问题变成 N+M。
📌 本站小结
- Tool 给模型装上了手脚,让它触碰现实
- MCP 给 Tool 定了统一接口------Type-C 化了
- 模型有了工具,但它还是被动的------每次都得等你的指令
六、自主层:模型开始「自己干活」
Agent(智能体)
🎯 矛盾:普通聊天模式------你问一句,它答一句。你让它查天气,它返回天气。但如果任务复杂一点呢?
「帮我研究一下 MCP 协议,写一篇综述,发到我的博客上。」
这不是一问一答能解决的。它需要:搜索资料 → 阅读整理 → 撰写文章 → 发布到博客平台。中间可能遇到:链接失效需要换源、文章太长需要分段、发布失败需要重试。
Agent(智能体) 就是能干这种活的系统。你给目标,它自己:
- 拆解成子任务
- 决定每一步调用什么工具
- 根据工具返回的结果,调整下一步计划
- 循环,直到完成
Agent 和普通聊天的核心区别:Agent 有自主决策权。它不是照着脚本跑------它会根据中间结果选路。
两个经典的 Agent 构建框架:
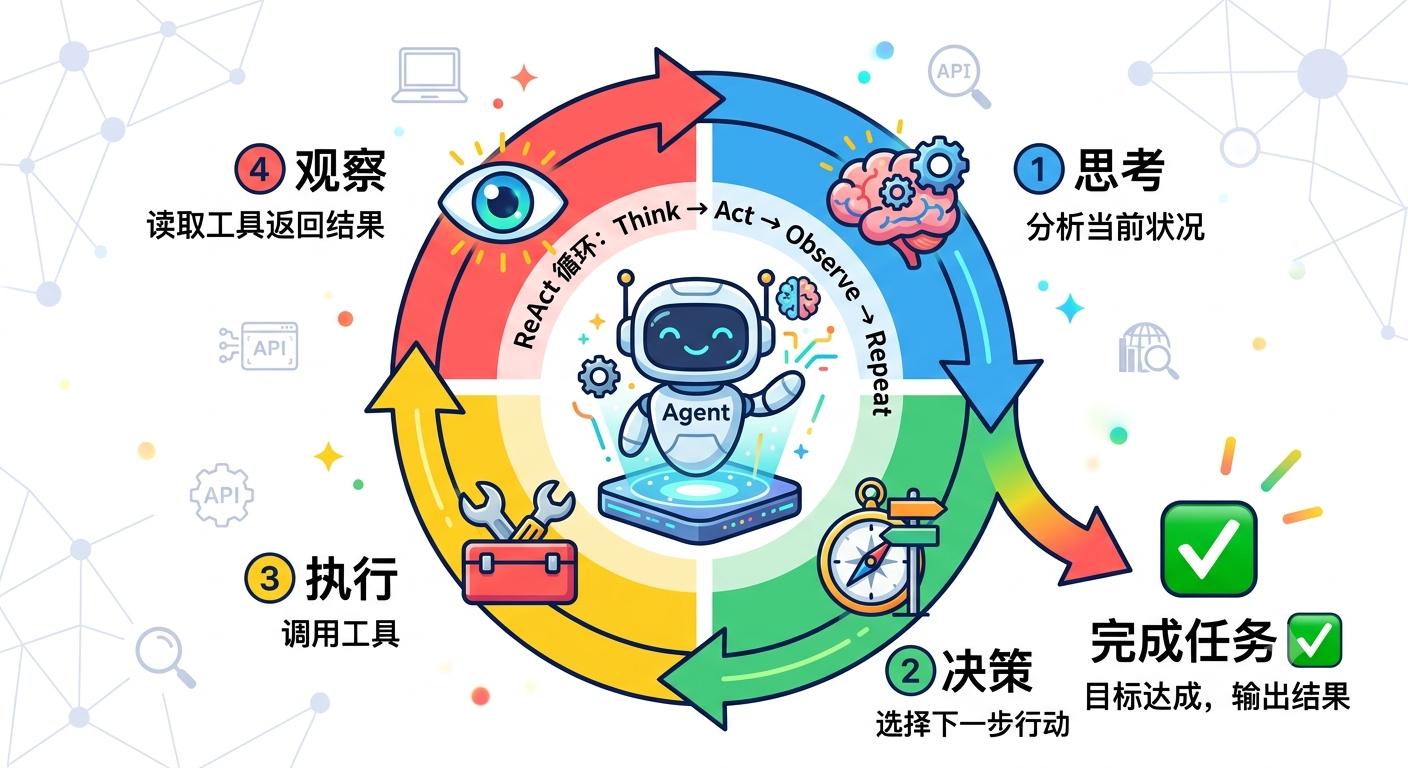
- ReAct(Reasoning + Acting)------「想一步,走一步」。每轮先推理当前状况 → 决定下一步行动 → 执行 → 观察结果 → 再推理......如此循环。
- Plan and Execute------「先画地图,再走路」。先制定完整计划,然后按计划执行。中途发现计划错了,再修正。
知名 Agent 产品:Claude Code、Codex CLI、Gemini CLI、Cursor 的 Agent 模式------2025 年,Agent 正在从概念变成每个开发者都能用的日常工具。
Agent Skill(智能体技能)
一个 Agent 能做的事太多了。你不想每次都把所有能力列出来让它选------Context 窗口本来就紧张。所以需要把常用的能力「打包」:给一个名字、一个触发条件、一套执行步骤。这就是 Skill。
比如一个翻译 Skill:
- 触发条件:用户要求翻译某个文件
- 执行步骤:读取文件 → 按指定语言翻译 → 保持格式 → 保存到指定路径
Skill 和普通 Prompt 的区别:Prompt 是一次性的,Skill 是封装好可复用的。它就像一个 U 盘------写一次,插上就能用,换一台机器照样用。
📌 终点站小结
- Agent 让模型从「被动回答」升级到「主动规划」
- Skill 把 Agent 的能力打包成可插拔的模块
- 从 Transformer 到 Agent Skill,走完了一整条从「数学运算」到「自主干活的 AI」的进化链
好了,感谢你的阅读,祝你有开心的一天!