p09 2.4 random stochastic environment(可选)
UP主 : 吴恩达-深度学习
时长 : 8:24
链接 : https://www.bilibili.com/video/BV1fdgVzmEhU?p=9
笔记时间: 2026-06-05 10:07:46
强化学习笔记:随机(随机)环境中的状态-动作价值函数
LIST 课程概览
本节课介绍了强化学习中随机环境(Stochastic Environment) 的建模方法,重点讲解了在不确定环境下如何定义期望回报(Expected Return),并推导了适用于随机环境的贝尔曼方程。通过一个六格机器人移动的例子,展示了当动作执行存在失败概率时,如何计算最优策略下的期望回报。
TOC 目录大纲
- 随机环境的定义与示例
- 期望回报的概念与公式推导
- 贝尔曼方程在随机环境中的修改
- Jupyter Notebook 实践示例
NOTE 详细笔记
1. 随机环境的定义与示例
核心知识点:
- 在真实世界中,智能体的动作可能不会总是成功执行,例如机器人滑倒、传感器失灵等。
- 这种不确定性称为"随机性"或"随机环境(stochastic environment)"。
- 智能体在状态 s 执行动作 a 后,下一状态 s' 不是确定的,而是以一定概率分布出现。
重要概念/术语:
- 随机环境(Stochastic Environment) :指智能体执行动作后,下一状态具有概率分布,而非确定性转移。
- 失误概率(Misstep Probability):如视频中提到的 0.1,表示动作执行失败的概率。
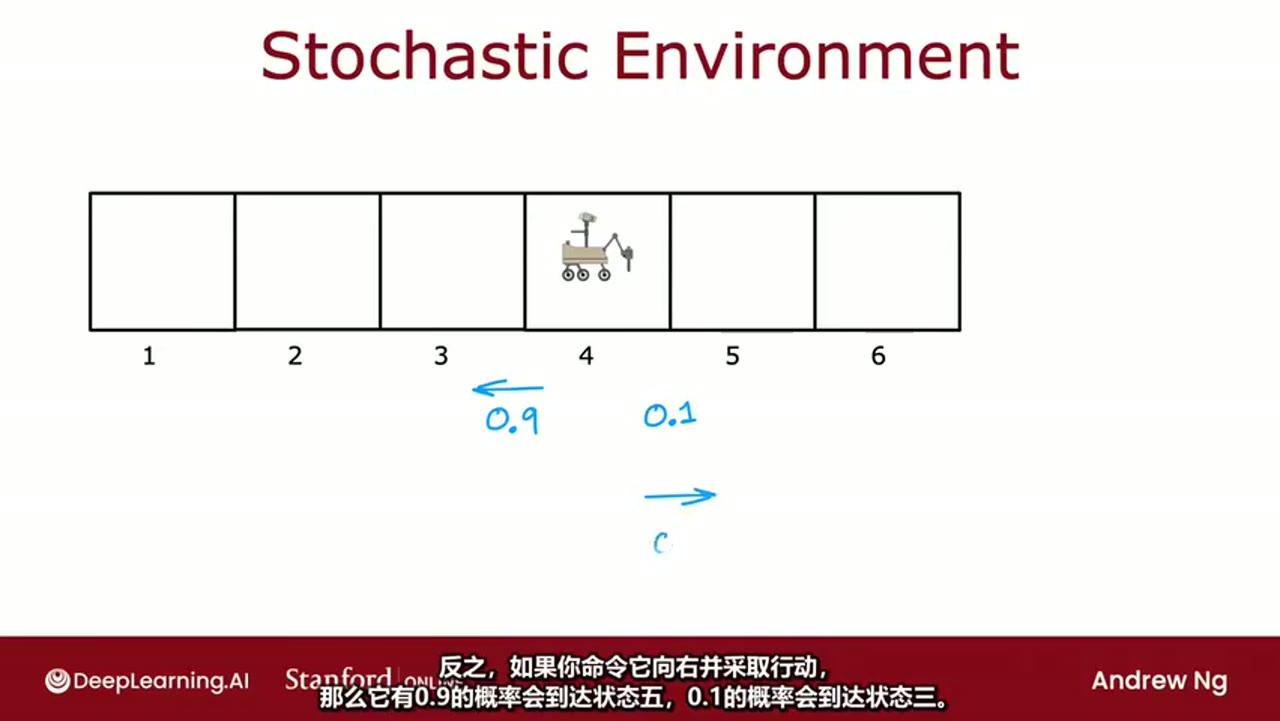
图示说明:

显示了一个六格线性环境,机器人位于状态 4。若命令向左移动:
- 有 0.9 的概率到达状态 3
- 有 0.1 的概率意外滑向状态 5(即反方向)
同样地,若命令向右移动:
- 有 0.9 的概率到达状态 5
- 有 0.1 的概率滑向状态 3
这体现了动作执行的不确定性。
注:从截图可见,状态编号为 1 到 6,机器人初始位置在状态 4。动作结果由箭头和概率标注。
2. 期望回报的概念与公式推导
核心知识点:
- 在随机环境中,每次运行得到的奖励序列是随机的,因此不能直接最大化单次回报。
- 我们的目标是最大化期望回报(Expected Return),即所有可能路径上折现奖励的平均值。
重要概念/术语:
- 期望回报(Expected Return):所有可能轨迹下折现奖励总和的数学期望,记作 \\mathbb{E}\[R_1 + \\gamma R_2 + \\gamma\^2 R_3 + \\cdots\]
- 折现因子(Discount Factor) \\gamma :控制未来奖励的重要性,通常 0 \< \\gamma \< 1
图示与公式推导过程:
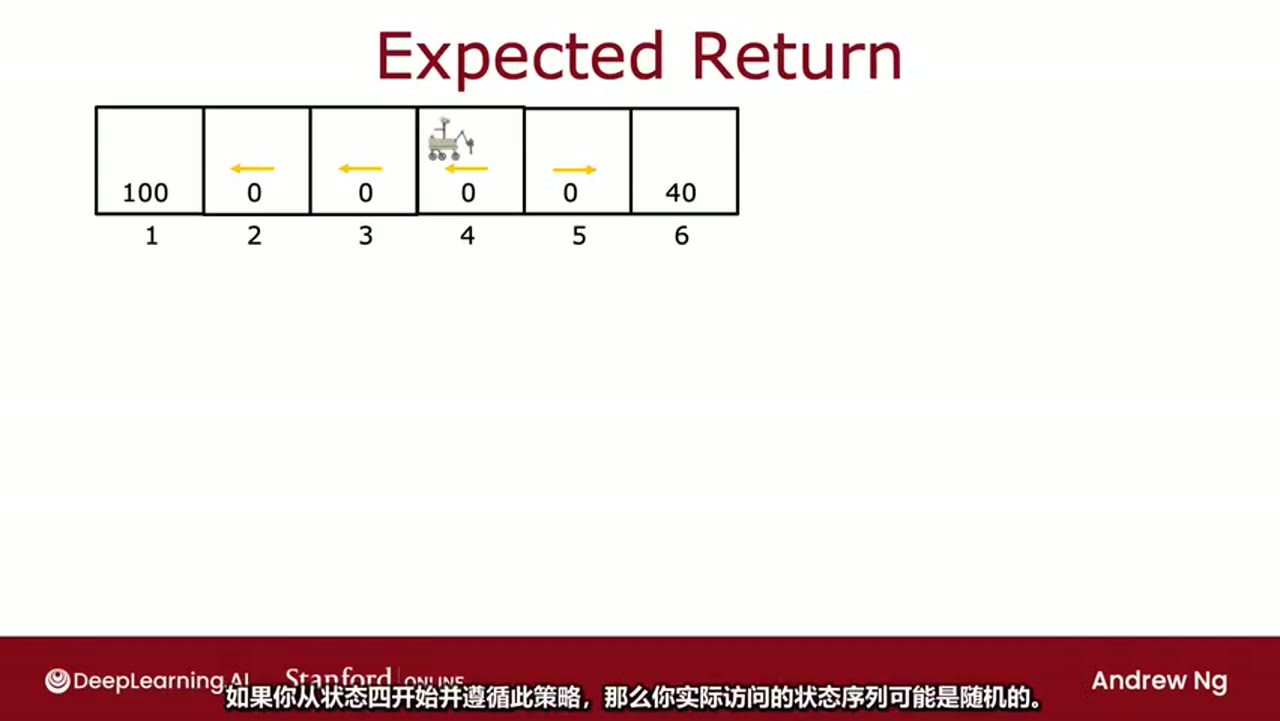
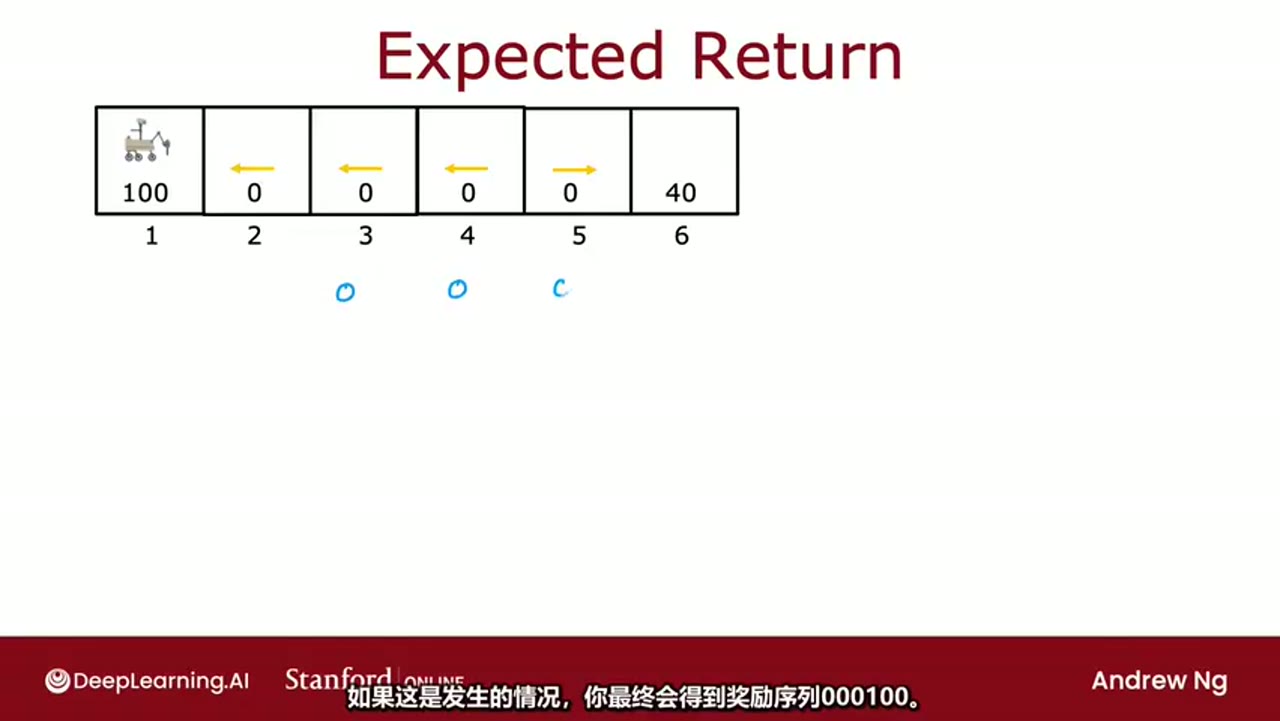
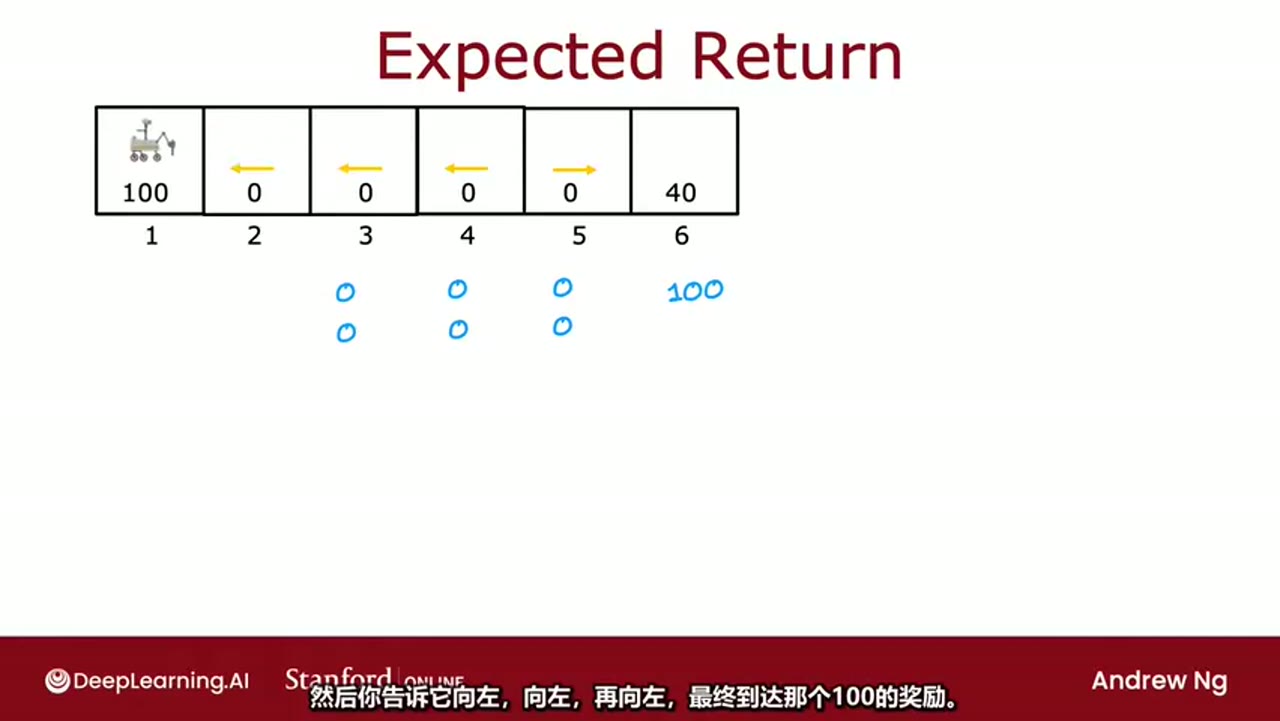
展示了不同路径下的奖励序列:
- 若连续向左移动:奖励序列为
000100→ 回报 = 100\\gamma\^3 - 若先向右再向左:奖励序列为
0040→ 回报 = 40\\gamma\^3
由于路径不确定,我们考虑所有可能路径的平均回报:
Expected Return=ER1+γR2+γ2R3+⋯ \text{Expected Return} = \mathbb{E}R_1 + \\gamma R_2 + \\gamma\^2 R_3 + \\cdots Expected Return=ER1+γR2+γ2R3+⋯
其中 \\mathbb{E}\[\\cdot\] 表示对所有可能路径取期望。

中显示了多个可能的奖励序列,并用蓝色数字标记每一步的奖励值。
显示了期望回报的数学表达式:
Expected Return=ER1+γR2+γ2R3+⋯ \text{Expected Return} = \mathbb{E}R_1 + \\gamma R_2 + \\gamma\^2 R_3 + \\cdots Expected Return=ER1+γR2+γ2R3+⋯

3. 贝尔曼方程在随机环境中的修改
核心知识点:
-
在确定性环境中,贝尔曼方程为:
Q(s,a)=R(s)+γmaxa′Q(s′,a′) Q(s,a) = R(s) + \gamma \max_{a'} Q(s', a') Q(s,a)=R(s)+γa′maxQ(s′,a′)
-
在随机环境中,由于 s' 是概率性的,必须对所有可能的下一个状态求期望。
重要概念/术语:
- 状态-动作价值函数 Q(s,a) :表示在状态 s 执行动作 a 后,遵循最优策略所能获得的期望回报。
- 贝尔曼方程(Bellman Equation):递归定义 Q(s,a) 的基本公式。
公式对比:
| 环境类型 | 贝尔曼方程 |
|---|---|
| 确定性环境 | Q(s,a) = R(s) + \\gamma \\max_{a'} Q(s', a') |
| 随机环境 | $ Q(s,a) = R(s) + \gamma \sum_{s'} P(s' |
注意:虽然截图中未显式写出求和形式,但从上下文可推断出应使用期望运算符替代最大值。
图示说明:

显示了原始贝尔曼方程:
Q(s,a)=R(s)+γmaxa′Q(s′,a′) Q(s,a) = R(s) + \gamma \max_{a'} Q(s', a') Q(s,a)=R(s)+γa′maxQ(s′,a′)

标注了变量含义:
- R(s) :当前状态的即时奖励
- \\gamma :折现因子
- s' :下一个状态(可能是 2 或 4)
- \\max_{a'} Q(s', a') :对下一个状态的最优动作价值取最大
但因环境随机,需改为对所有可能 s' 的期望:
Q(s,a)=R(s)+γEmaxa′Q(s′,a′) Q(s,a) = R(s) + \gamma E\\max_{a'} Q(s', a') Q(s,a)=R(s)+γEa′maxQ(s′,a′)
注:从状态s采取行动a,一旦在最优行为中,总回报等于你立即获得的奖励,也称为即时奖励,加上折扣因子γ,在加上你预期未来回报的平均值。
4. Jupyter Notebook 实践示例
核心知识点:
- 提供了一个交互式代码示例,用于可视化随机环境下的 Q(s,a) 值。
- 可调整参数如奖励、折扣因子、失误概率来观察其影响。
代码片段:
python
import numpy as np
from utils import *
# Do not modify
num_states = 6
num_actions = 2
terminal_left_reward = 100
terminal_right_reward = 40
each_step_reward = 0
# Discount factor
gamma = 0.5
# Probability of going in the wrong direction
misstep_prob = 0.1
generate_visualization(terminal_left_reward, terminal_right_reward, each_step_reward, gamma, misstep_prob)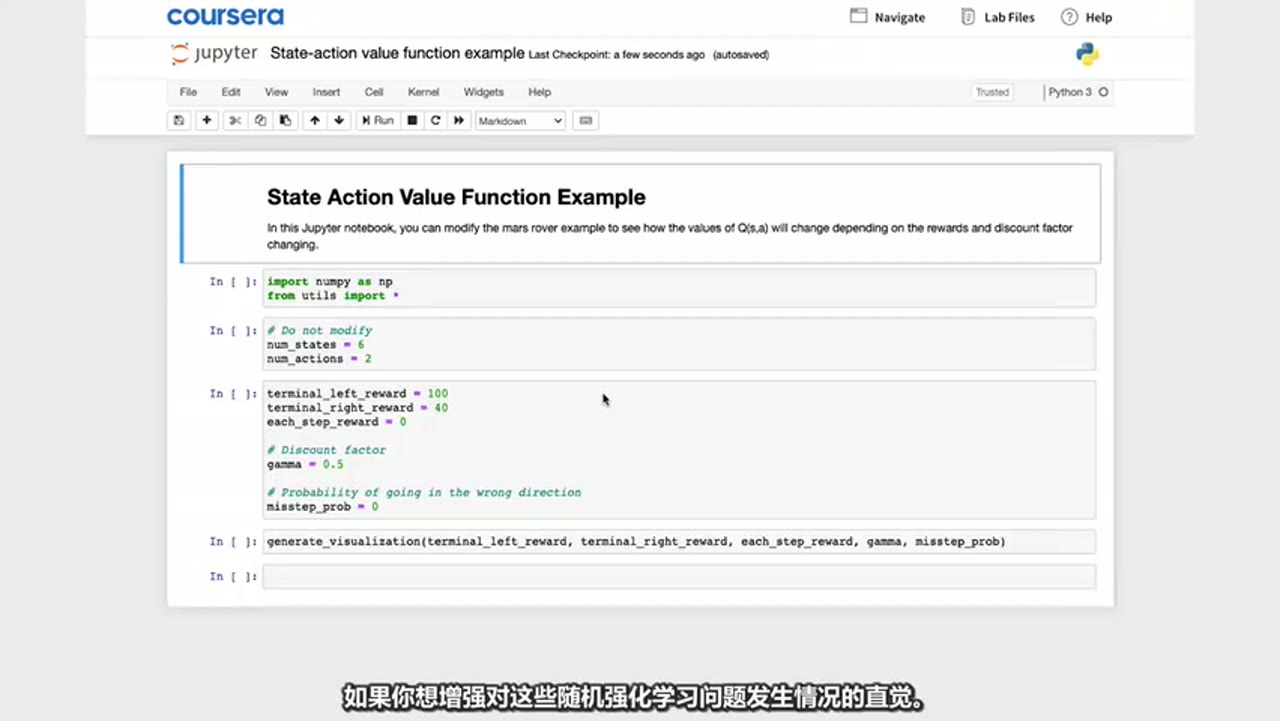
显示了上述代码结构,用户可通过修改参数进行实验。
输出结果:
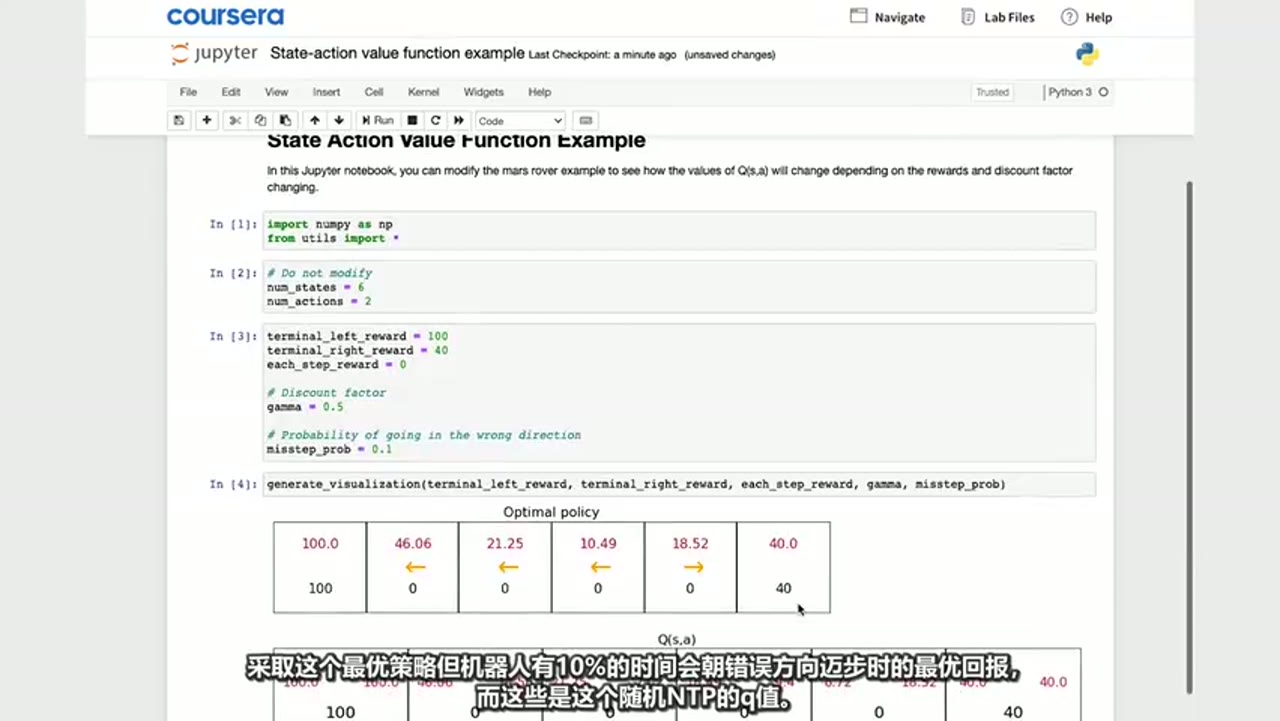
显示了最优策略下的 Q(s,a) 值表:
| 状态 | 左移 Q值 | 右移 Q值 | 最优动作 |
|---|---|---|---|
| 1 | 100.0 | - | 左 |
| 2 | 46.06 | - | 左 |
| 3 | 21.25 | - | 左 |
| 4 | 10.49 | 18.52 | 右 |
| 5 | 18.52 | - | 右 |
| 6 | 40.0 | - | 右 |
说明:即使有 10% 的失误概率,系统仍能计算出最优策略对应的 Q 值。
TIP 重点总结
- 随机环境意味着动作执行不保证成功:智能体可能因外部干扰而偏离预期路径。
- 期望回报是强化学习在随机环境中的目标:因为实际回报是随机变量,必须优化其期望值。
- 期望回报公式为 \\mathbb{E}\[R_1 + \\gamma R_2 + \\gamma\^2 R_3 + \\cdots\] :这是所有可能轨迹的平均折现奖励。
- 贝尔曼方程需引入期望运算:将确定性环境中的 \\max 改为对所有可能下一状态的加权平均。
- Jupyter Notebook 可帮助理解参数影响:如改变 \\gamma 、失误概率等,观察 Q 值变化趋势。
Q 思考题
- 如果失误概率增加到 0.3,会对最优策略产生什么影响?为什么?
- 为什么在随机环境中不能直接最大化单次回报?
- 如何从理论上推导出随机环境下的贝尔曼方程?
- 若环境完全不可预测(即每个动作都有均匀分布的下一状态),该如何建模?
- 在实际机器人控制中,如何估计"失误概率"这一参数?
PIN 学习建议
✅ 复习建议:
- 重新观看
[00:59  ]至[06:55  ]的动画演示,理解随机性如何影响路径选择。 - 手动计算一个简单例子的期望回报(例如从状态 4 出发,左右各 0.9 和 0.1 概率)。
- 尝试修改 Jupyter Notebook 中的参数,观察 Q 值的变化规律。
📚 延伸阅读方向:
- 马尔可夫决策过程(MDP):正式框架用于建模随机环境。
- Q-learning 算法:一种基于贝尔曼方程的无模型强化学习算法。
- 策略梯度方法:另一种处理随机环境的方法,尤其适用于连续动作空间。
- 深度强化学习:结合神经网络与强化学习,在复杂随机环境中应用。
推荐阅读:Sutton & Barto《Reinforcement Learning: An Introduction》第 3 章 "Model-Based Methods"
AI自检修正
以下为AI自动检查发现的潜在问题,请人工确认:
- 错误 原文:
Q(s,a) = R(s) + \gamma \max_{a'} Q(s', a')→ 应改为:Q(s,a) = R(s) + \gamma \sum_{s'} P(s'|s,a) \max_{a'} Q(s', a')。在随机环境部分,虽然提到了需要对所有可能的下一个状态求期望,但给出的贝尔曼方程仍然是确定性环境下的形式。正确的表达应该包括对所有可能下一状态的概率加权平均。 - 错误 原文: "若连续向左移动:奖励序列为
000100→ 回报 = 100\\gamma\^3 " 和 "若先向右再向左:奖励序列为0040→ 回报 = 40\\gamma\^3 " → 应改为: 根据提供的信息,如果最终目标是到达左边或右边获得奖励,则上述序列中的回报计算似乎忽略了即时奖励与折现因子之间的关系。例如,对于序列000100,实际回报应为100γ5100\gamma^5100γ5(假设从状态4开始),而非100γ3100\gamma^3100γ3;同样地,对于0040,回报应该是40γ240\gamma^240γ2,而不是40γ340\gamma^340γ3。这里假设了每一步都有一个折扣,并且只有在达到特定状态时才会得到非零奖励。 - 澄清建议 在"Jupyter Notebook 实践示例"部分提到的代码片段中,虽然没有直接指出错误,但为了提高清晰度,可以明确说明
generate_visualization函数的作用以及它如何根据给定参数生成可视化结果。此外,关于输出结果表中的解释,建议增加对为何某些状态下仅有一个动作值被列出(如状态1、2、3和6)的解释,这可能是由于这些状态只允许朝一个方向移动或者另一个方向移动会导致立即离开环境。
其余内容看起来准确反映了课程视频中的信息。
补充截图