背景
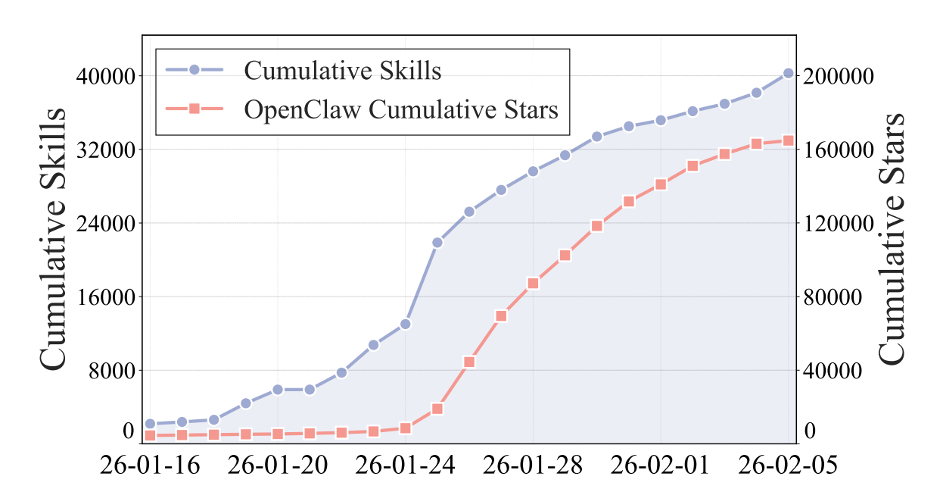
仅靠基础模型的单步生成能力,很难完成真实环境中的复杂目标。同时,智能体的行动常因任务模式和用户要求而重复出现,而每次重新设计提示则具有较大的开销,这促使了智能体技能(skills)的出现。Skills 可以定义为一个可重用的即插即用模块,该模块指定何时调用技能以及如何执行相应的子任务,能把大模型的通用能力转化为可执行、可复用、可组合的行为能力。如下图所示,近几个月来,skills 相关的生态系统迅速扩大 1。这种增长促使人们更仔细地研究现有的技能、如何采用这些技能以及它们可能带来的风险。
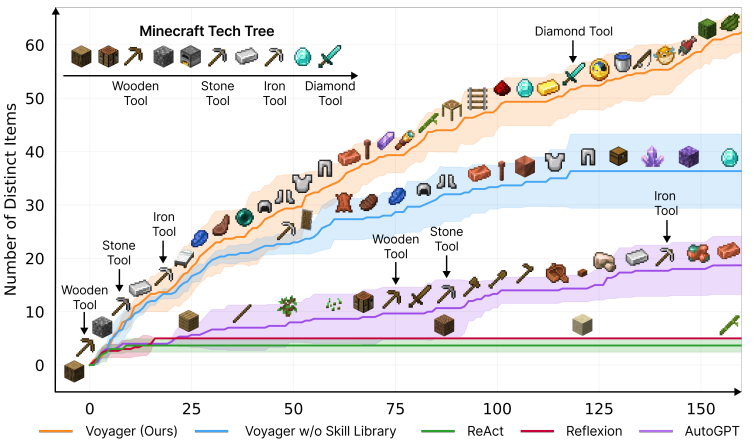
一项较为早期的 skill 研究来自于 Voyager 2。这是 Minecraft 中第一个基于大模型的终身学习智能体。它通过不断探索游戏世界,获得各种 skill。Voyager 由三个关键组成部分组成:1)一个开放式探索的自动课程,2)一个不断增长的可执行代码技能库,用于存储和检索复杂行为,3)一个新的迭代提示机制,使用代码作为动作空间。 Voyager 能够在新的 Minecraft 世界中利用学习到的 skills 从头开始解决新任务,具有较高的可扩展性。
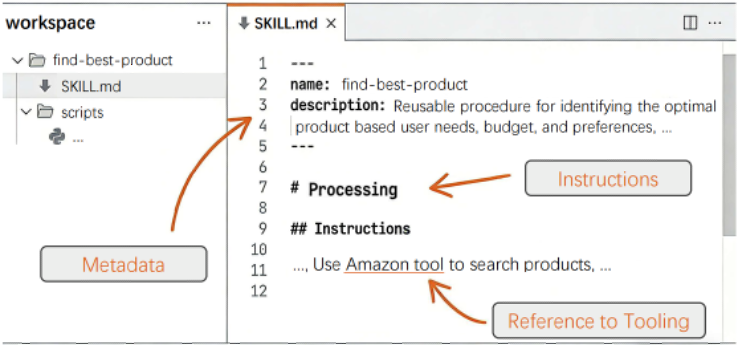
而目前语境下的 skill 模式则主要由 Claude 进行了系统化并推广 1,其内部结构如下图所示。SKILL.md 文件以指定 skill 名称和描述的 YAML 元数据作为开头,用于 skill 查询和选择。后续的 Markdown 部分定义了程序的工作流程以及详细的执行说明,包括对产品搜索 API 等外部工具的引用。这种结构在查询时支持轻量级的语义匹配,并能在调用时支持复杂的工具集成与执行。
Skill 构建与演化
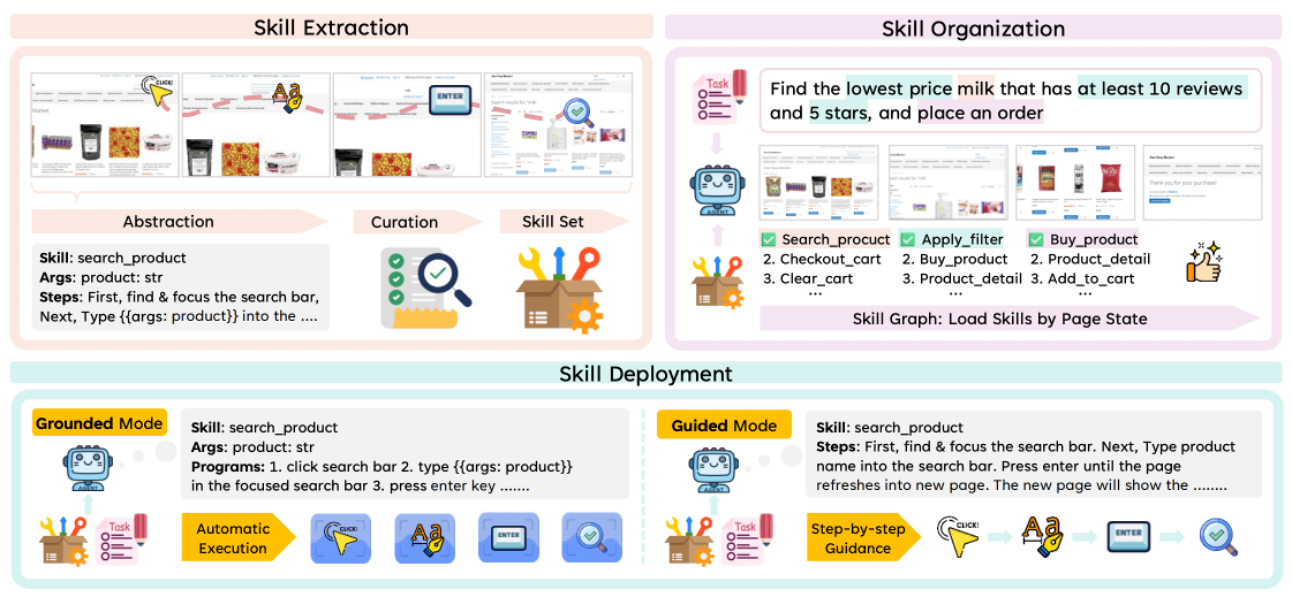
给定一组智能体轨迹T={τ1,...,τN},其中每个轨迹τi记录了智能体为完成、尝试任务而采取的逐步行动,Wang 等人3使用大模型来识别可重用的动作子序列,并将其抽象为技能。具体而言,对每个轨迹τi构建一个结构化的表示,其中包括任务描述、每一步的页面URL、采取的行动(行动类型、可选目标元素和参数)以及智能体的推理。大模型被提示:(1)识别表示连贯、可重用操作的动作子序列(例如,"按关键字搜索产品"),(2)将具体动作值抽象为类型化参数(例如,用query:str参数替换特定搜索查询),以及(3)用自然语言指导注释每个动作步骤,描述其目的和推理。
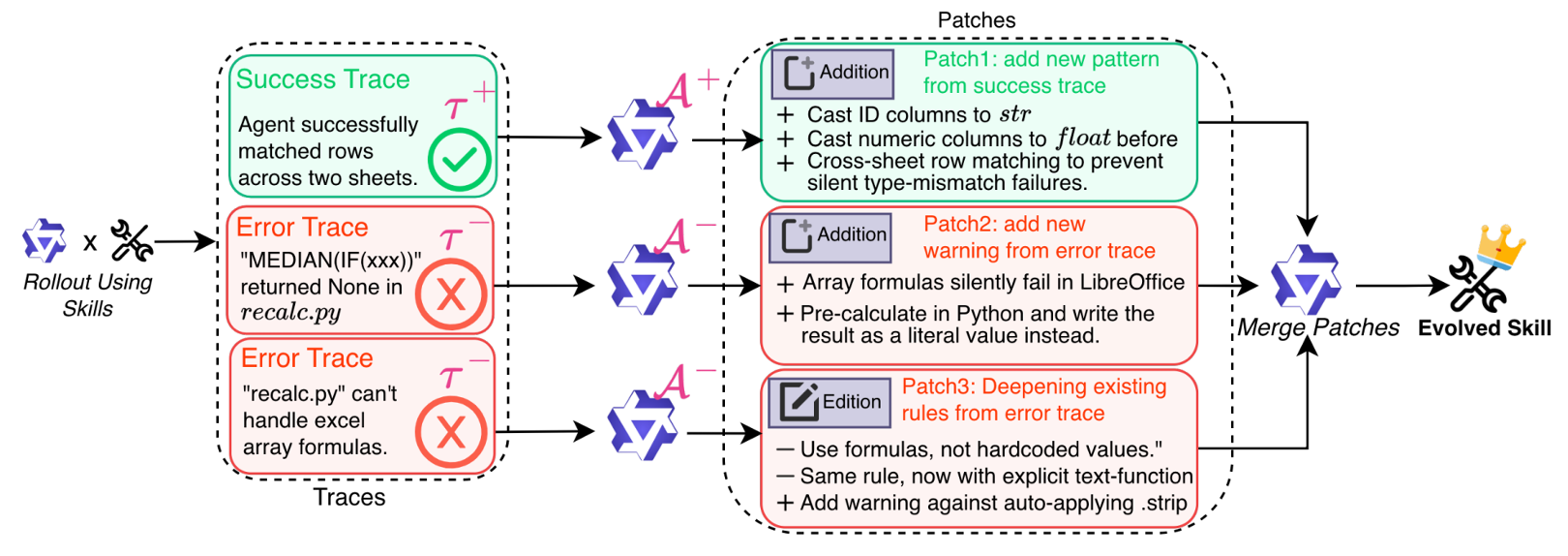
Ni 等人4尝试从从大批 LLM rollouts 中整理经验并实现技能演化。具体而言,作者首先使用冻结的智能体加以初始技能(人工编写或 LLM 起草)在不断演化的数据集上用 ReAct 进行 rollout,生成带标签的轨迹。接着,作者利用并行的错误分析器和成功分析器分别独立处理单条轨迹,并提出技能补丁(skill patches)。每个子智能体最终都会输出一条针对轨迹的修改补丁。最后,作者通过归纳推理并结合程序化冲突预防机制,将所有补丁合并为一次统一的整合更新,得到演化后的技能,从而提升性能与泛化能力。对于补丁里的共性问题,提炼成通用规则。对于偶发的个例内容,则解决补丁之间的矛盾,以及放到附录的参考文件中。
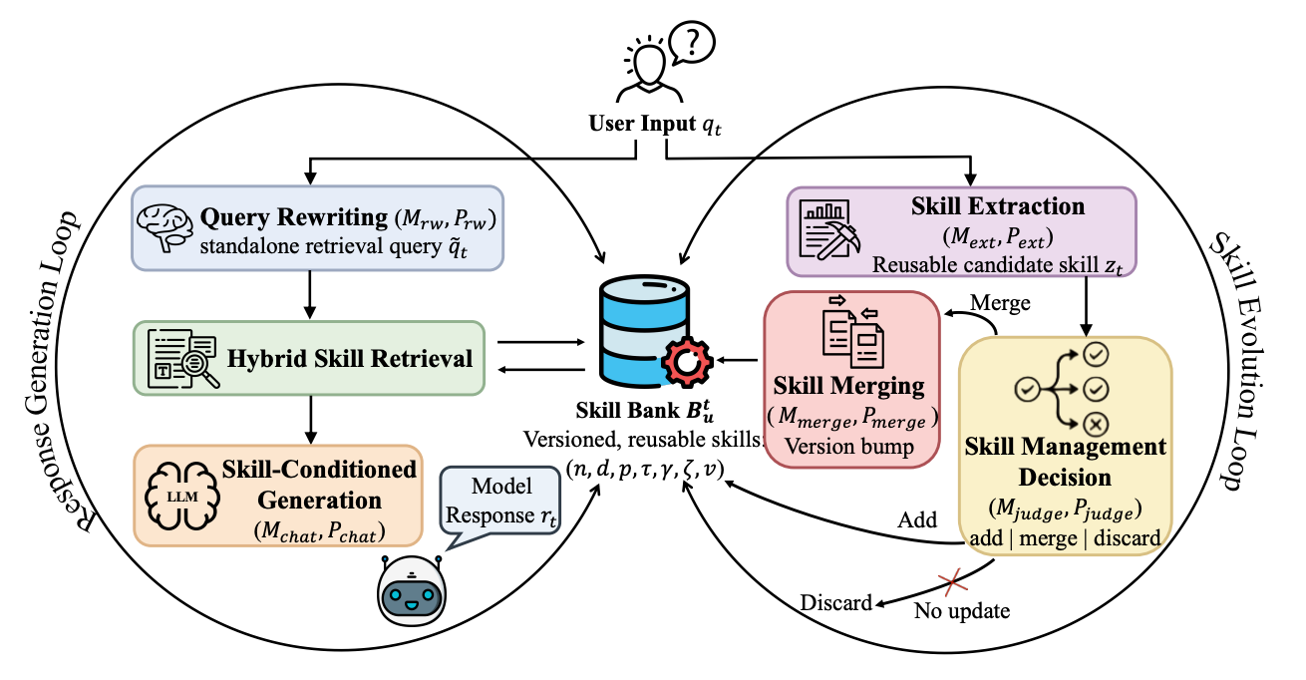
在 5 中,作者从智能体在真实的任务执行和多轮对话中,捕获具有长期复用价值的偏好、约束或操作步骤,同时删除特定于 case 的实体,仅保留可移植的规则。对于新提取到的技能,作者检索最相似的现有技能作为参照。一个专门的判别器选择添加、合并(到最相关的技能)还是丢弃。若判定为合并,则将新观察到的约束、示例、细节集成到更新的技能版本中。在这种情况下,技能可以不断改进,从而跟踪用户对重复任务的不同需求。
Skill 组织
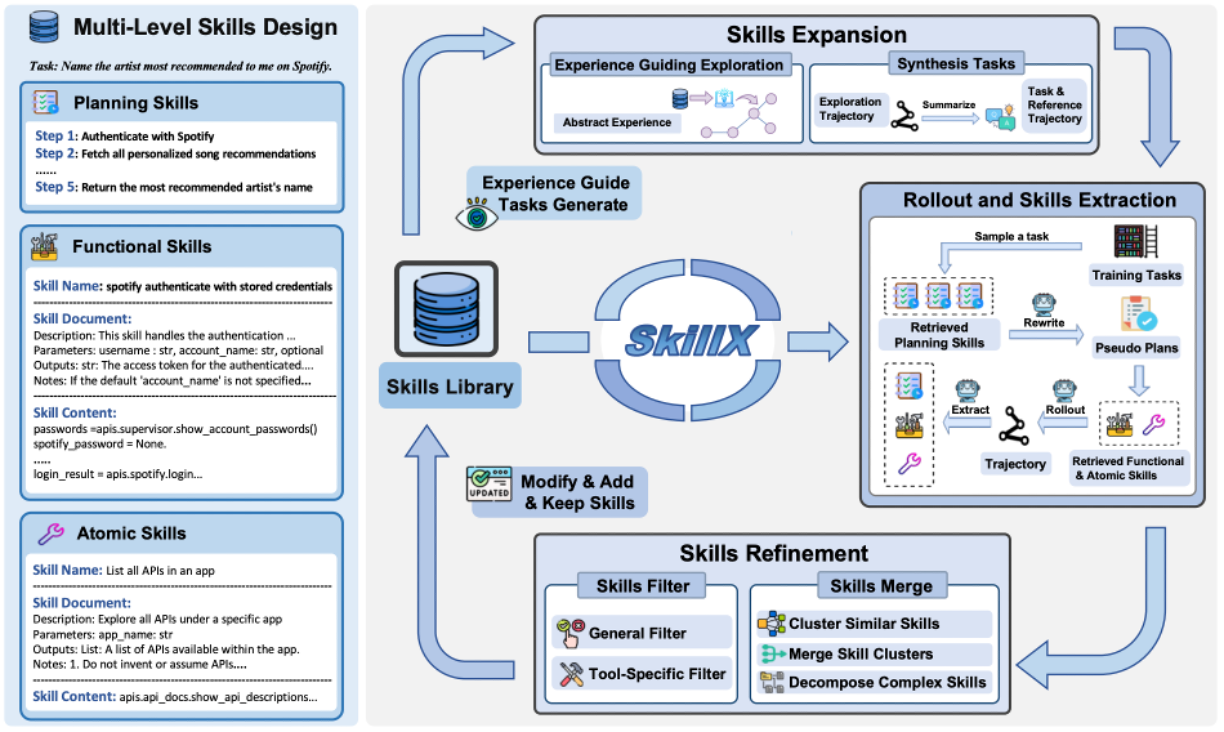
SkillX 6 的技能为三层的组织架构。分别为规划技能(planning skill)、功能技能(function skill)和原子技能(atomic skill)。其中,规划技能与子任务的组织结构(排序、分支等)保持一致,规定如何组合功能技能来解决问题。功能技能则被抽象成为子任务(每个任务可以分解为若干子任务),可以被视为完成子查询的宏操作。原子技能与单个工具对齐,包含更加丰富的描述、约束和使用模式。
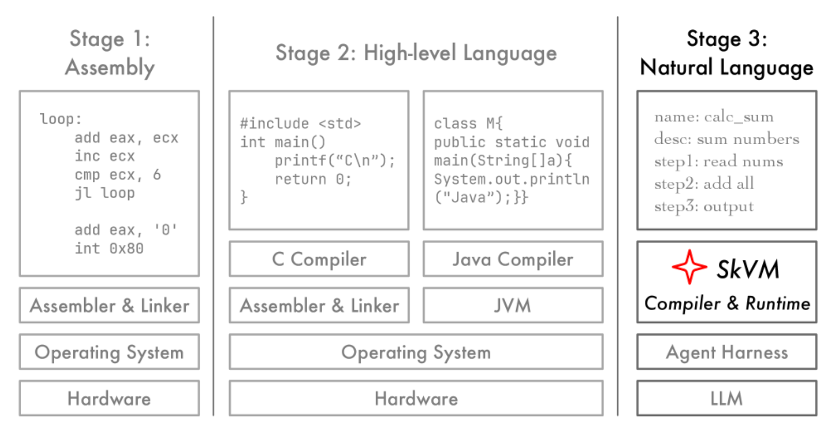
Chen 等人7 认为,当前智能体对技能的支持过于简单,模型在理解和执行技能的能力上存在很大差异。导致这种问题的因素在于:(1)即使加载了技能,模型在执行过程中也可能忽略其指导;(2)即使模型遵循技能,技能对模型能力的假设也可能与模型的实际能力不匹配。因此,作者提出了 SkVM,一个用于技能的编译和运行时系统,可以实现高效的跨模型执行,并为技能执行提供统一的底层支持。当用户首次安装技能时,SkVM 会在技能运行之前根据目标(模型、线束、主机环境)对其进行编译(评估框架下模型的各项能力)。编译器读取原始技能文本,识别目标,生成一个或多个优化的技能变体。尝试缩小技能预期和目标之间的差距。当发现技能指令太复杂,而当前的模型"硬件"不支持,会自动重写和降级技能。
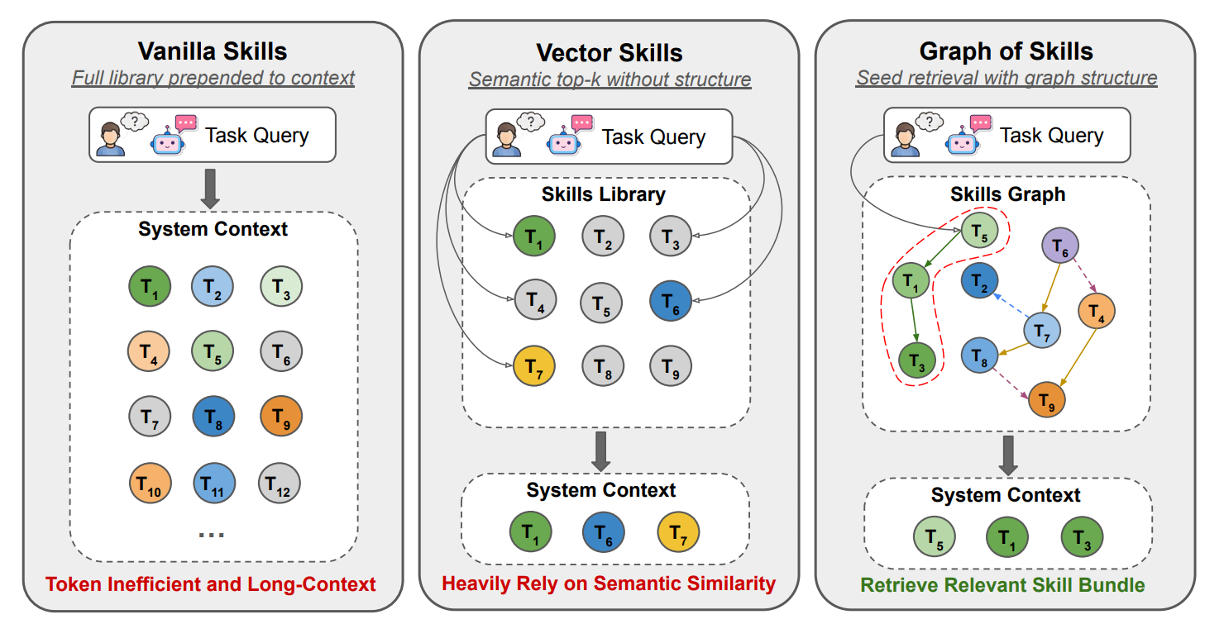
在真实世界的环境中,加载完整的技能集会使上下文窗口饱和,从而推高令牌成本、幻觉和延迟。虽然基于语义相似度检索的方式能提升效率,但语义上的接近并不意味着执行的充分性,例如工程任务中可能会有一些预处理步骤,这些步骤在语义的相似度是较弱的。为此,Liu 等人8提出了技能图(GoS),一个用于大型技能库的推理时结构检索层。GoS离线构建可执行技能图,然后在推理时通过反向加权个性化PageRank来检索有界的、依赖感知的技能包(参考图游走方法)。其中,技能包(Skill packages)在离线阶段会被转化为一个有向多关系图,每一个节点代表一个具体的可执行技能,而节点间的连线表示技能间的结构关系。如基于输入/输出兼容性推导出的前置依赖。
Skill 使用
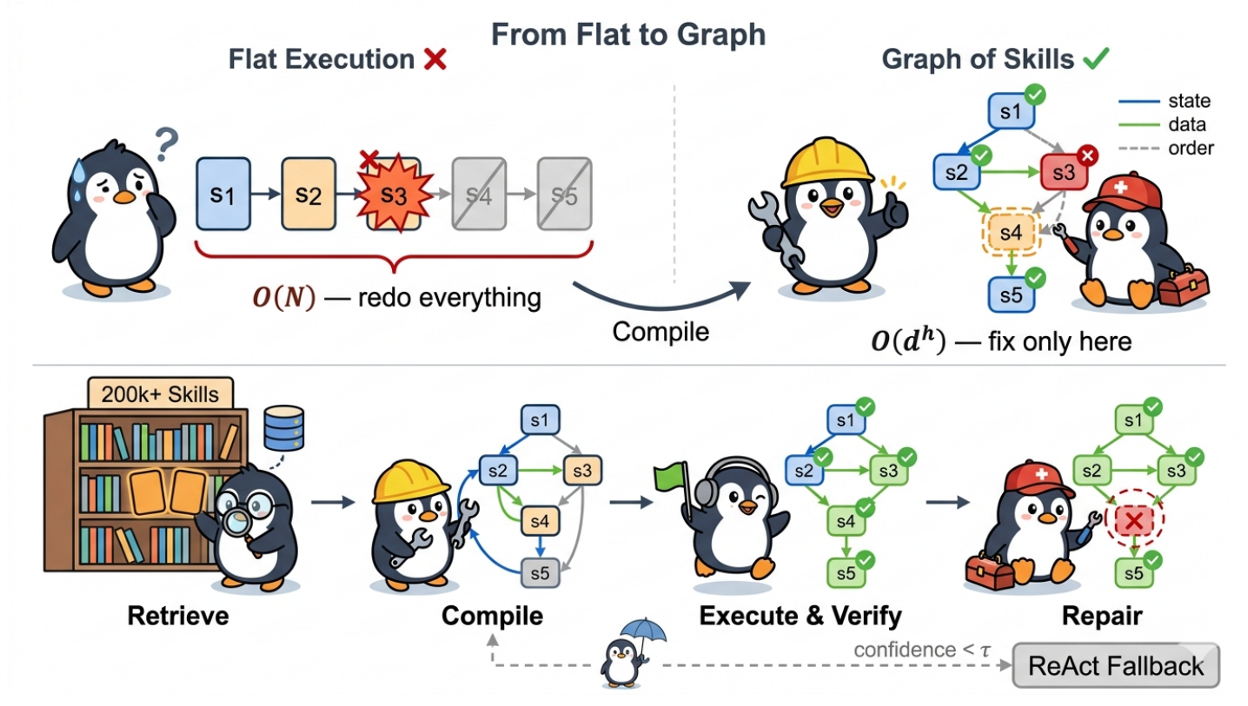
Xia 等人9发现,当前的技能执行存在以下问题:(1)认知过载,大量技能描述挤占上下文,无关技能干扰LLM判断,决策空间指数级上升导致幻觉、参数错误概率飙升。(2)因果结构丢失,扁平化执行会导致技能的前置条件、效果和依赖关系被丢弃,没有显式依赖跟踪,单步失败后无法判断影响范围,只能全量重规划,长链路任务几乎必然崩溃。为此,作者把扁平的技能列表变成了带类型的DAG(有向无环图),而节点是实例化的技能调用。DAG的执行阶段按拓扑顺序跑,执行前查前置条件,执行后查后置条件,失败时触发本地修复算子,包括改参数、插入前置步骤、技能替代等。
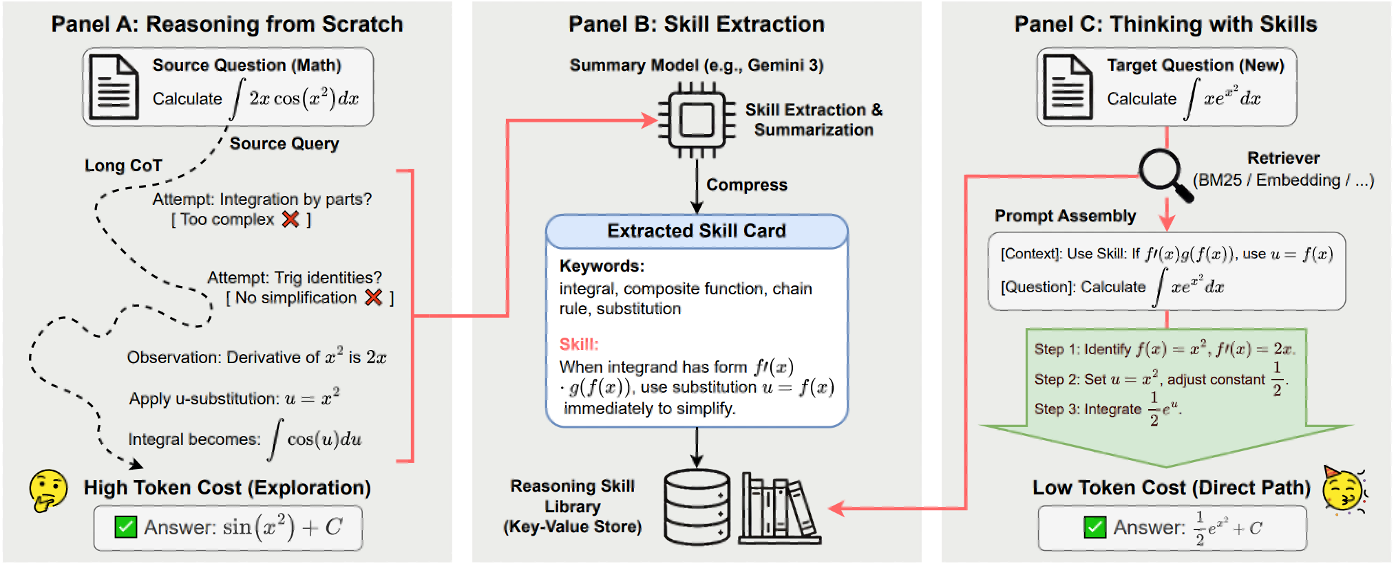
大模型在推理时往往会生成数千个思考token,包括冗余的验证和试错循环,这带来了较大的查询开销和延迟。为此,Zhao 等人10提出了推理技能思维(TRS),一个无需训练、可检索的增强框架,将获取推理逻辑与执行推理分离。离线阶段,作者将长时间的思考轨迹(包括试错)提炼成紧凑、可重用的推理技能,并带有明确的触发因素和陷阱。在线阶段,作者检索新查询的最相关技能并将其注入提示中,引导模型走向有效的解决方案路径。
总结与讨论
本次分享讨论了智能体技能相关的近期工作,包含构建与演化、组织、使用方向。在未来,skill 及存储执行架构的安全性、自我演化能力、过程验证和执行效率仍然是值得研究的角度。
参考文献
1: Ling et al. "Agent Skills: A Data-Driven Analysis of Claude Skills for Extending Large Language Model Functionality." arXiv preprint arXiv:2602.08004 (2026).
2: Wang et al. "Voyager: An Open-Ended Embodied Agent with Large Language Models." arXiv preprint arXiv:2305.16291 (2023).
3: Wang et al. "WebXSkill: Skill Learning for Autonomous Web Agents." arXiv preprint arXiv:2604.13318 (2026).
4: Ni et al. "Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills." arXiv preprint arXiv:2603.25158 (2026).
5: Yang et al. "AutoSkill: Experience-Driven Lifelong Learning via Skill Self-Evolution." arXiv preprint arXiv:2603.01145 (2026).
6: Wang et al. "SkillX: Automatically Constructing Skill Knowledge Bases for Agents." arXiv preprint arXiv:2604.04804 (2026).
7: Chen et al. "SkVM: Compiling Skills for Efficient Execution Everywhere." arXiv preprint arXiv:2604.03088 (2026).
8: Liu et al. "Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills." arXiv preprint arXiv:2604.05333 (2026).
9: Xia et al. "GraSP: Graph-Structured Skill Compositions for LLM Agents." arXiv preprint arXiv:2604.17870 (2026).
10: Zhao et al. "Thinking with Reasoning Skills: Fewer Tokens, More Accuracy." arXiv preprint arXiv:2604.17870 (2026).