文章目录
- 1、前言
- 2、先给下载结论
-
- [2.1 M4 / 16GB:选 it-4bit](#2.1 M4 / 16GB:选 it-4bit)
- [2.2 M1 Pro / 32GB:优先 it-8bit,稳妥 it-4bit](#2.2 M1 Pro / 32GB:优先 it-8bit,稳妥 it-4bit)
- [3、Gemma 4 12B 是今天的新模型,26B 不是](#3、Gemma 4 12B 是今天的新模型,26B 不是)
- 4、模型名称怎么拆
-
- [4.1 `mlx-community` 是什么](#4.1
mlx-community是什么) - [4.2 `gemma-4-12B` 是什么](#4.2
gemma-4-12B是什么) - [4.3 `it` 是什么](#4.3
it是什么)
- [4.1 `mlx-community` 是什么](#4.1
- 5、后缀逐个讲清楚
-
- [5.1 `bf16`:高精度,不适合普通 Mac 日常常驻](#5.1
bf16:高精度,不适合普通 Mac 日常常驻) - [5.2 `8bit`:32GB Mac 的质量优先选择](#5.2
8bit:32GB Mac 的质量优先选择) - [5.3 `mxfp8`:FP8 格式,可以试,但不是第一选择](#5.3
mxfp8:FP8 格式,可以试,但不是第一选择) - [5.4 `6bit` / `5bit`:中间档,但不是最常用](#5.4
6bit/5bit:中间档,但不是最常用) - [5.5 `4bit`:本地模型的主力版本](#5.5
4bit:本地模型的主力版本) - [5.6 `mxfp4`:新式 FP4,先作为实验项](#5.6
mxfp4:新式 FP4,先作为实验项) - [5.7 `nvfp4`:也是 FP4,但更不要当第一选择](#5.7
nvfp4:也是 FP4,但更不要当第一选择) - [5.8 `assistant`:不是主模型,是 MTP 辅助模型](#5.8
assistant:不是主模型,是 MTP 辅助模型)
- [5.1 `bf16`:高精度,不适合普通 Mac 日常常驻](#5.1
- 6、为什么文件大小不等于运行内存
- [7、在 OMLX 里怎么搜](#7、在 OMLX 里怎么搜)
-
- [7.1 不要只搜 `Gemma4`](#7.1 不要只搜
Gemma4) - [7.2 推荐搜索关键词](#7.2 推荐搜索关键词)
- [7.3 看结果时按这个顺序判断](#7.3 看结果时按这个顺序判断)
- [7.4 命令行下载方式](#7.4 命令行下载方式)
- [7.1 不要只搜 `Gemma4`](#7.1 不要只搜
- 8、一套通用选型规则
-
- [8.1 先看用途:聊天就选 `it`](#8.1 先看用途:聊天就选
it) - [8.2 再看机器:16GB 先 4bit,32GB 可 8bit](#8.2 再看机器:16GB 先 4bit,32GB 可 8bit)
- [8.3 再看上下文:长上下文比模型本体更容易吃爆内存](#8.3 再看上下文:长上下文比模型本体更容易吃爆内存)
- [8.4 最后看新格式:mxfp / nvfp 先当实验项](#8.4 最后看新格式:mxfp / nvfp 先当实验项)
- [8.1 先看用途:聊天就选 `it`](#8.1 先看用途:聊天就选
- 9、结合这次真实选择,再做一次判断
-
- [9.1 第一组:主模型高精度和中高精度](#9.1 第一组:主模型高精度和中高精度)
- [9.2 第二组:主模型低位量化](#9.2 第二组:主模型低位量化)
- [9.3 第三组:assistant 辅助模型](#9.3 第三组:assistant 辅助模型)
- 10、常见坑
-
- [10.1 下载了 `assistant`,发现不能聊天](#10.1 下载了
assistant,发现不能聊天) - [10.2 下载了不带 `it` 的版本,觉得不好用](#10.2 下载了不带
it的版本,觉得不好用) - [10.3 16GB 机器下载了 8bit,加载后卡住](#10.3 16GB 机器下载了 8bit,加载后卡住)
- [10.4 看到 26B 下载量高,就以为是今天新模型](#10.4 看到 26B 下载量高,就以为是今天新模型)
- [10.5 `mxfp4` / `nvfp4` 加载异常](#10.5
mxfp4/nvfp4加载异常) - [10.6 下载成功但加载失败:`gemma4_unified not supported`](#10.6 下载成功但加载失败:
gemma4_unified not supported)
- [10.1 下载了 `assistant`,发现不能聊天](#10.1 下载了
- 11、我的最终选择
- 12、后续升级策略
- 13、参考资料
🍃作者介绍:AI 应用负责人/AI产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、前言
今天在 OMLX 里搜 Gemma 4 12B,我遇到一个很典型的问题:
同一个模型,为什么列表里会出现
bf16、8bit、mxfp8、6bit、5bit、nvfp4、4bit、mxfp4,后面还有一堆assistant?
更麻烦的是,我手上有两台 Mac:
- 一台 M1 Pro,32GB 统一内存;
- 一台 M4,16GB 统一内存。
这两台机器都能跑本地模型,但下载选择完全不同。M4 芯片更新,算力不弱,但 16GB 统一内存是硬边界;M1 Pro 芯片老一点,却有 32GB 内存,反而能尝试更高精度的量化版本。
这篇文章不讲空泛的模型排行榜,而是把 OMLX / Hugging Face 里常见的模型名称后缀讲透。读完你应该能自己判断:
- 哪个是主模型,哪个只是辅助模型;
it、bf16、8bit、4bit分别代表什么;mxfp4、nvfp4这种新式后缀要不要碰;- M4 16GB 和 M1 Pro 32GB 分别该下载哪个版本;
- 在 OMLX 里应该怎么搜,怎么避开错误模型。
先给结论:如果你只是想在 Mac 本地跑 Gemma 4 12B,优先下载 mlx-community/gemma-4-12B-it-4bit 或 mlx-community/gemma-4-12B-it-8bit。
2、先给下载结论
先不绕弯子,直接按设备给选择。
2.1 M4 / 16GB:选 it-4bit
M4 16GB 这台机器,优先下载:
text
mlx-community/gemma-4-12B-it-4bit原因很简单:16GB 统一内存的瓶颈不是模型文件能不能下载,而是加载后还能不能留下足够空间给系统、OMLX 进程、KV Cache、上下文和其它应用。
gemma-4-12B-it-4bit 的大小约 10.2GB,看起来已经不小,但它仍然是 16GB 机器上最合理的第一选择。8bit 约 11.8GB,表面只多 1.6GB,但实际运行时还会叠加 KV Cache 和运行时开销,16GB 上容易变得紧张。
我的建议是:
| 项目 | 建议 |
|---|---|
| 主模型 | mlx-community/gemma-4-12B-it-4bit |
| 上下文 | 先从 4K-8K 开始 |
| 多模态 | 图片、音频、视频输入先保守测试 |
| 不建议 | bf16、8bit、31B、26B-A4B |
如果你打开浏览器、IDE、微信、飞书、Docker 一堆应用后再跑模型,16GB 会明显吃紧。所以 M4 16GB 的策略不是追求最高精度,而是先稳定跑起来。
2.2 M1 Pro / 32GB:优先 it-8bit,稳妥 it-4bit
M1 Pro 32GB 这台机器,优先下载:
text
mlx-community/gemma-4-12B-it-8bit如果你希望更省内存、更快加载,也可以下载:
text
mlx-community/gemma-4-12B-it-4bit32GB 统一内存给了你更大的容错空间。8bit 通常会比 4bit 保留更多模型质量,尤其是在代码、推理、长回答、中文表达稳定性上更值得优先尝试。
我的建议是:
| 项目 | 建议 |
|---|---|
| 质量优先 | mlx-community/gemma-4-12B-it-8bit |
| 速度/省内存优先 | mlx-community/gemma-4-12B-it-4bit |
| 测试用途 | 可以试 mxfp8、6bit |
| 不建议日常用 | bf16 |
bf16 的文件大小约 22.3GB,32GB 机器不是完全不能试,但它不适合日常常驻。加载模型只是第一步,真正推理时还要留空间给上下文、缓存和系统内存压力。

3、Gemma 4 12B 是今天的新模型,26B 不是
这点要先厘清,否则很容易下错方向。
Google 这次新发布的是 Gemma 4 12B Unified。官方发布时间是 2026 年 6 月 3 日,按北京时间看就是 6 月 4 日。Google 在发布页里明确说,它是放在 E4B 和 26B MoE 之间的中等尺寸模型,目标是让本地笔记本也能跑多模态和 Agent 工作流。
而 Gemma 4 26B A4B 不是 Gemma 3,也不是错的模型,它也是 Gemma 4 家族的一员。但它不是这次新增的 12B,而是 Gemma 4 家族早前已经出现的版本。它的重点是 MoE 架构:总参数 26B,但推理时只激活约 4B 参数,所以名字里有 A4B。
简单说:
| 模型 | 是否这次新发 | 定位 |
|---|---|---|
Gemma 4 12B Unified |
是 | 新增中尺寸、本地多模态、原生音频输入 |
Gemma 4 26B A4B |
不是这次新增 | MoE 版本,总参数大,激活参数小 |
Gemma 4 31B |
不是这次新增 | 更大的 dense 版本 |
Gemma 4 E2B / E4B |
不是这次新增 | 更小的端侧版本 |
如果你想体验"今天 Google 新发的 Gemma 4 新模型",目标就应该是 12B,不是 26B。
Google 官方对 12B 的定义有几个关键词:
- Unified:统一多模态架构;
- encoder-free:不再依赖独立视觉/音频编码器;
- native audio input:12B 是中尺寸模型里首次加入原生音频输入;
- local agentic workflows:面向本地 Agent 工作流;
- 16GB consumer laptops:官方定位里明确提到 16GB 级别消费笔记本。
这也是为什么 M4 16GB 这台机器可以考虑 12B 4bit,而不是被迫只能跑 4B 以下模型。
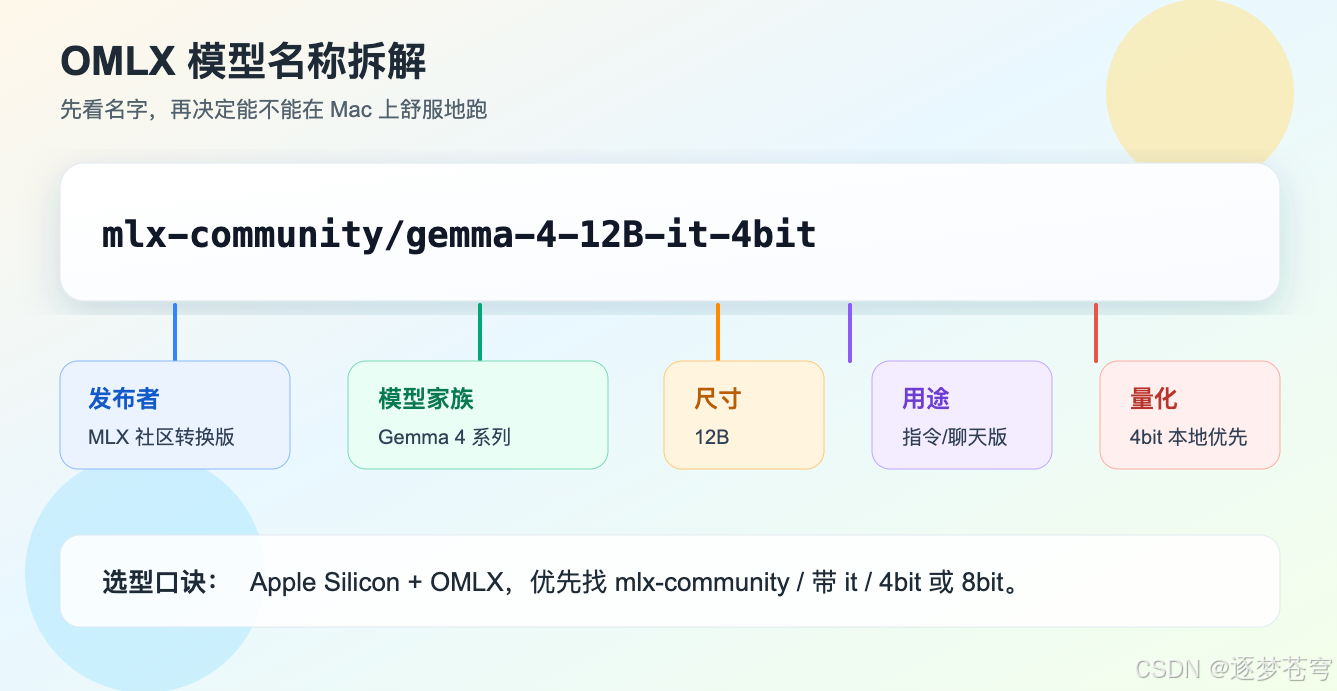
4、模型名称怎么拆
以最应该下载的版本为例:
text
mlx-community/gemma-4-12B-it-4bit这串名称可以拆成五段:
text
发布者 / 模型家族 - 模型尺寸 - 用途版本 - 量化格式展开就是:
| 片段 | 含义 |
|---|---|
mlx-community |
Hugging Face 上的发布者,表示这是 MLX 社区转换版 |
gemma-4 |
Google Gemma 4 模型家族 |
12B |
约 12B 参数级别的模型 |
it |
instruction-tuned,指令微调版 |
4bit |
4 位量化版本 |
对 OMLX 用户来说,这五段里最关键的是三个:
- 发布者是不是 MLX 相关 :优先
mlx-community,其次lmstudio-community这类明确 MLX 的转换。 - 有没有
it:日常聊天、写代码、问答优先带it。 - 最后的量化后缀:决定能不能在你的 Mac 上跑得舒服。
4.1 mlx-community 是什么
mlx-community 是 Hugging Face 上常见的 MLX 转换模型发布者。MLX 是 Apple 开源的机器学习框架,专门面向 Apple Silicon 和统一内存架构。
OMLX 本质上就是围绕 MLX 生态构建的本地推理服务,所以你在 OMLX 里找模型时,要优先找 MLX 格式,而不是随便下载一个原始 PyTorch 权重或 GGUF 文件。
常见发布者可以这样理解:
| 发布者 | 建议 |
|---|---|
mlx-community |
Apple Silicon / OMLX 优先选择 |
lmstudio-community |
通常也可用,注意看是否写了 MLX |
google |
官方原始模型,适合 Transformers,不一定是 OMLX 最省内存格式 |
| 个人 fork | 谨慎,除非你知道对方做了什么转换 |
截图里出现过 dealignai/...CRACK 这种名字,我不建议作为首选。下载本地模型不是只看"能不能跑",还要看来源可信度、README、许可证、转换方式和社区使用量。
4.2 gemma-4-12B 是什么
gemma-4 表示 Gemma 4 系列,12B 表示这是 12B 级别模型。
Gemma 4 家族现在可以按尺寸理解:
| 版本 | 说明 |
|---|---|
E2B |
端侧小模型,E 表示 effective parameters |
E4B |
更强一点的端侧小模型 |
12B Unified |
这次新增的中尺寸统一多模态模型 |
26B A4B |
MoE 模型,总参数 26B,激活参数约 4B |
31B |
更大的 dense 模型 |
这里有两个容易误解的点。
第一,E2B/E4B 里的 E 不是普通的总参数量,而是 effective parameters,Google 用 Per-Layer Embeddings 这类设计让小模型在端侧更高效。
第二,26B A4B 里的 A4B 是 active parameters,意思是推理时大约只激活 4B 参数。它不是"4B 模型",也不是"26B 全部每步都跑"。这就是 MoE 模型的核心优势。
4.3 it 是什么
it 是 instruction-tuned,也就是指令微调版。
对于大多数人来说,带 it 的模型才是日常应该下载的版本。比如:
text
gemma-4-12B-it-4bit它更适合:
- 聊天问答;
- 写代码;
- 总结文章;
- 分析图片;
- Agent 工具调用;
- 处理自然语言指令。
不带 it 的版本,例如:
text
gemma-4-12B-4bit通常更接近 base / pre-trained 模型。它不是不能用,而是更偏研究、补全、微调、评测场景。你把它当聊天助手用,可能会觉得它"不听话""格式乱""不像助手"。
所以选型口诀是:
text
日常使用选 it,研究微调再考虑 base。5、后缀逐个讲清楚
现在进入最容易混乱的部分:bf16、8bit、mxfp8、6bit、5bit、nvfp4、4bit、mxfp4。
这些后缀基本都在讲一件事:模型权重用什么精度保存。
精度越高,模型质量越稳,但文件更大、内存更吃紧;精度越低,越省内存、越容易本地跑,但模型质量可能有损失。

5.1 bf16:高精度,不适合普通 Mac 日常常驻
bf16 是 bfloat16。你可以把它理解为接近原始高精度推理的版本。
text
mlx-community/gemma-4-12B-it-bf16大小约 22.3GB。
优点:
- 精度最高;
- 最接近原始模型质量;
- 适合做对比评测。
缺点:
- 文件大;
- 加载内存压力大;
- KV Cache 和上下文会继续吃内存;
- 16GB 机器不现实,32GB 机器也不适合日常常驻。
我的建议:M4 16GB 不要下;M1 Pro 32GB 除非做测试,否则也不优先下。
5.2 8bit:32GB Mac 的质量优先选择
8bit 是 8 位量化版本。
在截图里:
text
mlx-community/gemma-4-12B-it-8bit大小约 11.8GB。
它是 M1 Pro 32GB 这台机器的首选,因为它在质量和资源占用之间比较平衡。相比 4bit,8bit 通常更稳,尤其是在这些场景里:
- 代码生成;
- 数学推理;
- 多轮长回答;
- 中文表达;
- 对格式要求严格的任务;
- 需要更少幻觉的问答。
但对 M4 16GB 来说,8bit 不是完全不能尝试,而是不适合当第一选择。因为 16GB 机器还要留系统内存,稍微开大上下文就可能顶到内存压力。
5.3 mxfp8:FP8 格式,可以试,但不是第一选择
mxfp8 是一种 microscaling FP8 格式。MLX 官方文档里列出了 mxfp4、mxfp8、nvfp4 等量化模式。
它的目标是用更低位宽的浮点格式压缩权重,同时尽量保留动态范围。
但对普通 OMLX 用户来说,我不建议一上来就选 mxfp8。原因不是它一定差,而是:
- 普通
8bit更直观,兼容性预期更清晰; - 新式浮点量化的实际效果更依赖运行时支持;
- 你刚开始排错时,变量越少越好。
所以我的建议是:
text
先跑通 8bit 或 4bit,再测试 mxfp8。5.4 6bit / 5bit:中间档,但不是最常用
6bit 和 5bit 是中间量化档位。
截图里能看到:
text
mlx-community/gemma-4-12B-it-6bit
mlx-community/gemma-4-12B-it-5bit它们看起来很诱人:比 8bit 省内存,又可能比 4bit 质量更好。
但在实际选择上,它们常常不是第一梯队。原因是:
- 16GB 机器通常直接需要
4bit; - 32GB 机器通常可以直接上
8bit; - 中间档适合"8bit 有点紧,但 4bit 又不甘心"的用户。
如果你是 M1 Pro 32GB,发现 8bit 在大上下文下内存压力高,可以试 6bit。如果你是 M4 16GB,我仍然建议优先 4bit,不要绕中间档。
5.5 4bit:本地模型的主力版本
4bit 是大多数本地模型用户最常用的量化版本。
在截图里:
text
mlx-community/gemma-4-12B-it-4bit大小约 10.2GB。
它是 M4 16GB 的首选,也是 M1 Pro 32GB 的稳妥选择。
优点:
- 内存压力低;
- 下载体积相对可控;
- 更容易在 Apple Silicon 上跑起来;
- 适合本地聊天、轻量代码、摘要、知识问答。
缺点:
- 相比 8bit,复杂推理和代码稳定性可能下降;
- 长文本细节保持能力可能弱一点;
- 对格式严格的输出可能更容易犯错。
不过对本地模型来说,能稳定运行往往比纸面质量更重要 。尤其是 16GB 机器,4bit 是让 12B 级别模型真正可用的关键。
5.6 mxfp4:新式 FP4,先作为实验项
mxfp4 是 microscaling FP4 格式。MLX 文档里说明,mx 模式按组量化,mxfp4 使用 FP4 表示和共享 scale。
你可以把它理解为:它也是 4 位左右的低精度格式,但不是普通 affine 4bit 那一路,而是更偏新式浮点量化。
对用户来说,关键不是背格式细节,而是判断要不要下载。
我的建议:
- 如果你第一次下载 Gemma 4 12B,不要先选
mxfp4; - 如果普通
4bit跑通了,可以再下载mxfp4做速度和质量对比; - 如果 OMLX 或 MLX 版本不够新,遇到加载问题,优先退回普通
4bit。
5.7 nvfp4:也是 FP4,但更不要当第一选择
nvfp4 也是一种 4 位浮点量化格式。NVIDIA 技术博客里对 NVFP4 的定位是更高效、误差更低的低精度格式。MLX 也把 nvfp4 列在支持的量化模式里。
但注意,我们现在是在 Apple Silicon + OMLX 上跑模型,不是在 NVIDIA Blackwell 上跑训练或推理。所以不要因为名字里有 nv 就觉得它一定比普通 4bit 更适合你的 Mac。
我的建议:
text
普通用户先选 it-4bit;想折腾再试 it-nvfp4。5.8 assistant:不是主模型,是 MTP 辅助模型
截图第三张里有一堆小模型:
text
mlx-community/gemma-4-12B-it-assistant-bf16
mlx-community/gemma-4-12B-it-assistant-8bit
mlx-community/gemma-4-12B-it-assistant-4bit
mlx-community/gemma-4-12B-it-assistant-mxfp4这些模型很小,几百 MB,看起来像"轻量版 Gemma 4 12B"。但它们不是主模型,不能当普通聊天模型来下载。
assistant 在这里指的是 MTP drafter,也就是 Multi-Token Prediction 的辅助草稿模型。它的作用是在 speculative decoding 里提前猜测几个 token,再由主模型验证,从而降低延迟。
通俗讲:
text
主模型 = 真正回答问题的人
assistant = 先打草稿、帮主模型提速的人所以下载顺序应该是:
- 先下载主模型,例如
gemma-4-12B-it-4bit; - 确认 OMLX 能正常加载和对话;
- 再看 OMLX 是否支持给这个模型配置
assistant; - 支持再下载匹配的
it-assistant-*。
不要一上来只下载 assistant,然后疑惑为什么不能正常聊天。
6、为什么文件大小不等于运行内存
截图里有一个现象很容易误导人:
bf16约 22.3GB;8bit约 11.8GB;4bit约 10.2GB;assistant-4bit只有几百 MB。
很多人会问:既然 4bit 是 4 位量化,为什么还要 10GB?12B 模型 4bit 不是应该约 6GB 吗?
原因是:模型文件大小不是简单的"参数量 × bit 数"。
实际还会包含:
- embedding;
- tokenizer;
- config;
- 多模态投影层;
- 非量化层;
- safetensors 元数据;
- 某些权重没有完全按同一位宽压缩;
- MLX 转换后的存储结构。
更关键的是,文件大小也不等于运行内存。
模型运行时还要额外占用:
| 运行时开销 | 说明 |
|---|---|
| KV Cache | 上下文越长越吃内存 |
| 激活值 | 推理过程中间张量 |
| 批处理开销 | 并发请求会增加内存压力 |
| OMLX 服务进程 | 服务本身和调度器也需要内存 |
| macOS 系统 | 统一内存要和系统、窗口、浏览器共享 |
| 多模态输入 | 图片、音频、视频会带来额外处理开销 |
这就是为什么 M4 16GB 不能只看"文件 10.2GB,好像还能剩 5.8GB"。实际运行时,剩下空间很快会被上下文和系统吃掉。
对 Apple Silicon 来说,还有一个关键点:统一内存不是独立显存。
它的好处是 CPU/GPU 共享,模型不用像传统 PC 那样频繁在内存和显存之间拷贝;缺点是系统、应用、模型、缓存都抢同一池内存。内存压力一高,macOS 开始压缩和交换,推理速度会明显下降。
7、在 OMLX 里怎么搜
OMLX 的 Admin 控制台可以直接搜 Hugging Face 模型。你可以打开:
text
http://localhost:8000/admin进入:
text
Models -> Downloader然后按下面这个思路搜。

7.1 不要只搜 Gemma4
如果只搜:
text
Gemma4结果会非常杂:
- Gemma 4 E2B;
- Gemma 4 E4B;
- Gemma 4 26B;
- Gemma 4 31B;
- base 模型;
- instruct 模型;
- assistant 模型;
- GGUF;
- MLX;
- 各种个人转换版。
这时候你很容易被"热门下载""大小排序""看起来参数更大"带偏。
7.2 推荐搜索关键词
如果目标是今天新发的 12B,就搜:
text
gemma-4-12B如果你要聊天/写代码/日常问答,就继续收窄:
text
gemma-4-12B-it如果你明确要 MLX 4bit,可以搜:
text
gemma-4-12B-it-4bit如果你想找 8bit:
text
gemma-4-12B-it-8bit我的推荐搜索顺序是:
text
gemma-4-12B-it
gemma-4-12B-it-4bit
gemma-4-12B-it-8bit同时勾选 OMLX 里的:
text
仅 MLX7.3 看结果时按这个顺序判断
看到搜索结果后,不要先看下载量,而是按这个顺序判断:
- 名字里有没有
mlx-community; - 模型是不是
gemma-4-12B; - 有没有
it; - 后缀是不是
4bit或8bit; - 是不是
assistant; - 大小是否符合预期。
对这次场景来说,最理想的结果是:
text
mlx-community/gemma-4-12B-it-4bit
mlx-community/gemma-4-12B-it-8bit不是:
text
mlx-community/gemma-4-12B-it-assistant-4bit
mlx-community/gemma-4-12B-bf16
google/gemma-4-12B-it
random-user/gemma-4-12B-xxx7.4 命令行下载方式
如果你不用 OMLX 控制台,也可以用 huggingface-cli 下载到 OMLX 模型目录。
先创建目录:
bash
mkdir -p ~/.omlx/models下载 M4 16GB 推荐版:
bash
huggingface-cli download mlx-community/gemma-4-12B-it-4bit \
--local-dir ~/.omlx/models/mlx-community/gemma-4-12B-it-4bit下载 M1 Pro 32GB 推荐版:
bash
huggingface-cli download mlx-community/gemma-4-12B-it-8bit \
--local-dir ~/.omlx/models/mlx-community/gemma-4-12B-it-8bitOMLX 的 README 里提到,--model-dir 可以指向包含 MLX 格式模型子目录的目录,并且支持两级组织目录。所以保留 mlx-community/模型名 这种结构是可以的。
如果 Hugging Face 访问慢,可以在启动 OMLX 时指定镜像:
bash
omlx serve --model-dir ~/.omlx/models --hf-endpoint https://hf-mirror.com8、一套通用选型规则
这套规则不只适用于 Gemma 4 12B,也适用于你以后在 OMLX 里下载 Qwen、Llama、DeepSeek、GLM 等模型。
8.1 先看用途:聊天就选 it
如果你要做的是:
- 聊天;
- 写代码;
- 总结;
- 翻译;
- Agent;
- RAG 问答;
- 多轮任务规划;
优先找:
text
*-it-*不带 it 的 base 模型,不是不能用,而是不适合作为普通助手。
8.2 再看机器:16GB 先 4bit,32GB 可 8bit
一个简单规则:
| 统一内存 | 推荐 |
|---|---|
| 16GB | 4bit |
| 24GB | 4bit 或 6bit,谨慎 8bit |
| 32GB | 8bit 优先,4bit 稳妥 |
| 64GB+ | 可尝试更大模型、更高精度、更长上下文 |
这不是绝对规则,但对本地模型新手很实用。
8.3 再看上下文:长上下文比模型本体更容易吃爆内存
很多人只关心模型大小,却忽略上下文。
本地推理里,KV Cache 会随着上下文长度增长。你把上下文从 4K 开到 32K,内存压力可能完全不是一个级别。
所以 M4 16GB 跑 12B 4bit 时,建议先用:
text
4K-8K contextM1 Pro 32GB 跑 12B 8bit 时,可以逐步试:
text
8K -> 16K -> 32K如果一开长上下文就卡、变慢、OOM,先别怀疑模型坏了,先把上下文降下来。
8.4 最后看新格式:mxfp / nvfp 先当实验项
mxfp4、mxfp8、nvfp4 这些格式值得关注,但不要让它们变成你第一次跑模型的变量。
我的顺序是:
- 先下普通
4bit或8bit; - 确认 OMLX 能加载;
- 确认对话、代码、图片输入正常;
- 再测试
mxfp4、mxfp8、nvfp4; - 对比速度、内存、回答质量。
这样排错成本最低。
9、结合这次真实选择,再做一次判断
关于oMLX当中搜索到的gemma-4模型,可以分为三组。
9.1 第一组:主模型高精度和中高精度
text
mlx-community/gemma-4-12B-bf16
mlx-community/gemma-4-12B-it-bf16
mlx-community/gemma-4-12B-it-8bit
mlx-community/gemma-4-12B-8bit
mlx-community/gemma-4-12B-it-mxfp8
mlx-community/gemma-4-12B-mxfp8这里面真正适合日常助手的是:
text
mlx-community/gemma-4-12B-it-8bitbf16 太大,不适合这两台机器做日常常驻;不带 it 的版本不是聊天优先;mxfp8 可以作为第二轮测试。
9.2 第二组:主模型低位量化
text
mlx-community/gemma-4-12B-it-6bit
mlx-community/gemma-4-12B-6bit
mlx-community/gemma-4-12B-it-5bit
mlx-community/gemma-4-12B-5bit
mlx-community/gemma-4-12B-it-nvfp4
mlx-community/gemma-4-12B-nvfp4
mlx-community/gemma-4-12B-it-4bit
mlx-community/gemma-4-12B-it-mxfp4
mlx-community/gemma-4-12B-4bit
mlx-community/gemma-4-12B-mxfp4这里面最应该优先下载的是:
text
mlx-community/gemma-4-12B-it-4bit它同时满足三个条件:
- MLX 格式;
- 指令微调版;
- 4bit 低内存量化。
对 M4 16GB 来说,它就是第一选择。
9.3 第三组:assistant 辅助模型
text
mlx-community/gemma-4-12B-it-assistant-bf16
mlx-community/gemma-4-12B-it-assistant-8bit
mlx-community/gemma-4-12B-it-assistant-mxfp8
mlx-community/gemma-4-12B-it-assistant-6bit
mlx-community/gemma-4-12B-it-assistant-5bit
mlx-community/gemma-4-12B-it-assistant-nvfp4
mlx-community/gemma-4-12B-it-assistant-4bit
mlx-community/gemma-4-12B-it-assistant-mxfp4这组先不要下载。它们不是主模型。
如果后续 OMLX 明确支持 Gemma 4 12B 的 MTP / speculative decoding 配置,你可以考虑:
text
主模型:mlx-community/gemma-4-12B-it-4bit
辅助:mlx-community/gemma-4-12B-it-assistant-4bit或者:
text
主模型:mlx-community/gemma-4-12B-it-8bit
辅助:mlx-community/gemma-4-12B-it-assistant-8bit但它不是第一步。
10、常见坑
10.1 下载了 assistant,发现不能聊天
这是正常的,因为 assistant 是 MTP drafter,不是主模型。
正确做法:
text
先下载 gemma-4-12B-it-4bit 或 gemma-4-12B-it-8bit10.2 下载了不带 it 的版本,觉得不好用
不带 it 的 base 模型更偏预训练模型。它不一定会像助手一样遵循你的指令。
正确做法:
text
日常聊天和 Agent 工作流,优先带 it。10.3 16GB 机器下载了 8bit,加载后卡住
这不一定是 OMLX 的问题,而是内存太紧。
解决顺序:
- 换
it-4bit; - 降低上下文长度;
- 关闭占内存的应用;
- 不要同时加载多个模型;
- 暂时不要启用多模态长输入。
10.4 看到 26B 下载量高,就以为是今天新模型
26B-A4B 是 Gemma 4 家族里的重要模型,但它不是这次新增的 12B。
如果目标是体验最新发布的 Gemma 4 12B,就不要被 26B 热门排序带偏。
10.5 mxfp4 / nvfp4 加载异常
先换普通:
text
it-4bit或:
text
it-8bit新式格式值得测试,但不适合当排错起点。
10.6 下载成功但加载失败:gemma4_unified not supported
这次我真实遇到的最大坑,不是模型下错了,而是模型太新,OMLX 内置依赖还没跟上。
具体表现是,模型已经出现在 OMLX 的"可用模型"列表里,也能看到大小和状态,但一点加载就报错:
text
VLM load failed: Model type gemma4_unified not supported.
Error: No module named 'mlx_vlm.speculative.drafters.gemma4_unified'
LLM fallback also failed: Model type gemma4_unified not supported.这类错误的关键词是:
text
gemma4_unified not supported
No module named mlx_vlm.models.gemma4_unified
No module named mlx_vlm.speculative.drafters.gemma4_unified根因是:Gemma 4 12B Unified 是新架构,Hugging Face 上的模型 config.json 里写的是 model_type: gemma4_unified;但当时 OMLX 0.4.0 / 0.4.1 内置的 mlx-vlm 0.5.0 还没有这个加载器。
所以这个问题不是:
- 不是模型文件坏了;
- 不是 4bit 量化错了;
- 不是 OMLX 搜索结果假了;
- 也不是 Apple Silicon 不支持。
它只是一个很典型的"新模型发布太快,前端/后端依赖还没同步"的问题。
正确排查顺序是:
- 先升级 OMLX 官方包;
- 再验证 OMLX 内置
mlx-vlm是否支持gemma4_unified; - 如果官方包还没跟上,再临时手动升级内置
mlx-vlm; - 等 OMLX 官方后续版本合并后,再回到纯官方升级路径。
一行验证命令如下:
bash
OMLX_PREFIX="$(brew --prefix jundot/omlx/omlx 2>/dev/null || brew --prefix omlx)"; PY="$OMLX_PREFIX/libexec/bin/python"; "$PY" -c 'import sys, numpy, mlx_vlm; import importlib.metadata as md; import mlx_vlm.models.gemma4_unified; print("python:", sys.executable); print("mlx_vlm import:", getattr(mlx_vlm, "__version__", "unknown")); print("mlx_vlm metadata:", md.version("mlx-vlm")); print("numpy:", numpy.__version__); print("gemma4_unified: OK")'如果成功,应该看到:
text
mlx_vlm import: 0.6.1
mlx_vlm metadata: 0.6.1
numpy: 2.3.5
gemma4_unified: OK如果失败,可以临时这样修:
bash
OMLX_PREFIX="$(brew --prefix jundot/omlx/omlx 2>/dev/null || brew --prefix omlx)"; PY="$OMLX_PREFIX/libexec/bin/python"; brew services stop jundot/omlx/omlx || brew services stop omlx
bash
"$PY" -m pip install --ignore-installed --no-deps --force-reinstall mlx-vlm==0.6.1
bash
find "$OMLX_PREFIX/libexec/lib" -path '*site-packages/mlx_vlm-0.5.0.dist-info' -exec mv {} /tmp/mlx_vlm-0.5.0.dist-info.omlx-backup \; 2>/dev/null || true
bash
"$PY" -m pip install 'numpy==2.3.5'
bash
"$PY" -m pip check
bash
brew services start jundot/omlx/omlx || brew services start omlx这里有两个细节要注意。
第一,brew service restart omlx 是错的,Homebrew 命令是复数:
bash
brew services restart omlx第二,pip install 的输出有时会被旧的 .dist-info 元数据误导。例如它明明安装了 0.6.1,却显示 Successfully installed mlx-vlm-0.5.0。这时不要只看 pip 最后一行,要用上面的 Python 验证命令看真实 import 版本。
如果验证结果是:
text
mlx_vlm import: 0.6.1
mlx_vlm metadata: 0.6.1
gemma4_unified: OK
No broken requirements found就说明修好了。之后再加载:
text
gemma-4-12B-it-4bit11、我的最终选择
结合这两台机器,我会这样下载:
| 机器 | 第一选择 | 第二选择 | 暂不下载 |
|---|---|---|---|
| M4 / 16GB | mlx-community/gemma-4-12B-it-4bit |
it-mxfp4 可测试 |
bf16、8bit、assistant |
| M1 Pro / 32GB | mlx-community/gemma-4-12B-it-8bit |
it-4bit |
bf16、单独 assistant |
如果只想下一个模型,在两台机器之间同步使用,我会选:
text
mlx-community/gemma-4-12B-it-4bit如果 M1 Pro 32GB 是主力本地推理机器,我会额外下载:
text
mlx-community/gemma-4-12B-it-8bit最后再用一句话总结:
text
OMLX 选模型,看四件事:MLX 来源、12B 本体、it 指令版、4bit/8bit 量化。12、后续升级策略
最后说一下后续升级:长期看,正常跟着 OMLX 官方升级就好。
这次手动升级 mlx-vlm,本质上是一个"新模型首发期"的临时补丁。Gemma 4 12B Unified 刚发布时,Hugging Face 模型已经出来了,但 OMLX Homebrew 包里固定的 mlx-vlm 版本还没包含 gemma4_unified 加载器,所以只能临时覆盖内置依赖。
但这不应该成为日常维护方式。
日常升级优先用:
bash
brew update && brew upgrade jundot/omlx/omlx或:
bash
brew update && brew upgrade omlx升级后重启服务:
bash
brew services restart jundot/omlx/omlx || brew services restart omlx然后做一次版本验证:
bash
OMLX_PREFIX="$(brew --prefix jundot/omlx/omlx 2>/dev/null || brew --prefix omlx)"; PY="$OMLX_PREFIX/libexec/bin/python"; "$PY" -c 'import mlx_vlm; import importlib.metadata as md; import mlx_vlm.models.gemma4_unified; print(getattr(mlx_vlm, "__version__", "unknown")); print(md.version("mlx-vlm")); print("gemma4_unified: OK")'这里有一个关键区别:
| 升级方式 | 适合场景 | 风险 |
|---|---|---|
brew upgrade omlx |
日常稳定使用 | 最稳,依赖由 OMLX 官方锁定 |
手动 pip install mlx-vlm==0.6.1 |
新模型刚发、官方包暂未跟上 | 可能被下次 Homebrew 升级覆盖 |
brew reinstall omlx |
想回到纯官方环境 | 会清掉手动覆盖的依赖 |
brew install --HEAD |
想追最新代码 | 适合折腾,不适合稳定生产 |
所以我的建议是:
- 平时只跟官方 Homebrew 升级;
- 遇到新模型架构不支持,再临时升级内置依赖;
- 每次 OMLX 官方升级后都验证一次
gemma4_unified是否还在; - 等官方包内置新
mlx-vlm后,不再需要手动补丁。
如果后续你执行 brew upgrade 后,Gemma 4 12B 又报 gemma4_unified not supported,不要慌,说明 Homebrew 升级把手动补丁覆盖回官方依赖了。重新跑第 10.6 节那几条命令即可。
如果某个新版 OMLX 已经内置 mlx-vlm >= 0.6.1,那就不需要手动处理了,保持官方路径最干净。
13、参考资料
- Google 官方发布页:Introducing Gemma 4 12B
- Google Developers Blog:Bringing Gemma 4 12B to your Laptop
- Hugging Face 官方模型卡:google/gemma-4-12B
- MLX 量化文档:mlx.core.quantize
- OMLX 官网:oMLX --- LLM inference, optimized for your Mac
- OMLX GitHub README:jundot/omlx
- MLX 社区 4bit 模型:mlx-community/gemma-4-12B-it-4bit
- MLX-VLM PyPI 版本:mlx-vlm
|--------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------|
| 🚀 持续探索 AI 与前沿技术 分享大模型应用、软件开发实战与行业洞察。 欢迎关注 【龙哥AI】,加入 7000+ 技术同行的交流圈! 🌟 探索技术边界,让开发更有效率 |  |
|