JVM(六)
本文主要介绍常见的JVM问题及定位解决思路
1、JVM内存溢出
JVM内存溢出,也就是所谓的"OOM"问题。这是一种常见的生产问题,Java内存空间中会有多块区域发生内存溢出,例如堆空间、元空间、栈空间等。
生产环境中一般遇到的都是堆空间内存溢出,通常来说可能导致堆空间溢出的原因大致如下:
- JVM堆大小设置不合理,设置过小,不足以支撑程序正常执行时内存的增长;
- 编写的代码有BUG,导致对象生成的速度远大于GC回收的速度;
- 引入的三方依赖存在内存泄漏的漏洞从来引发OOM;
其中情况②是最容易遇到的,其次是情况③,情况①碰到的概率较小。
1.1、OOM问题如何定位
生产发生OOM问题的排查思路:
- 找运维获取dump文件,一般来说生产服务器都会设置-XX:HeapDumpPath参数(作用:发生OOM会自动生成dump文件),如果没有第一现场的dump文件,只能重启时增加配置,期待尽可能重现现场(绝大数时候都会很快复现);
- 如果实在没有,只能观察内存增长的情况,择机多生成几个dump,结合在一起分析,这种有一定误差,没有第一现场的dump文件精确;
- 拿到dump文件后,下一步就是借助专业工具分析,推荐使用Eclipse MAT;
- 通过dump文件的分析,定位发生内存溢出的位置,结合相应的代码分析具体产生问题原因;
- 根据上一步分析的原因,做相应整改,修改后发布观察问题是否再现,如果再现,重复上诉步骤继续分析整改。
1.2、实际案例
下面介绍两个实际遇到的生产案例,同时介绍如何使用MAT分析dump文件。
1.2.1、案例一
系统A某日收到OOM告警,联系运维获取dump文件,导入MAT 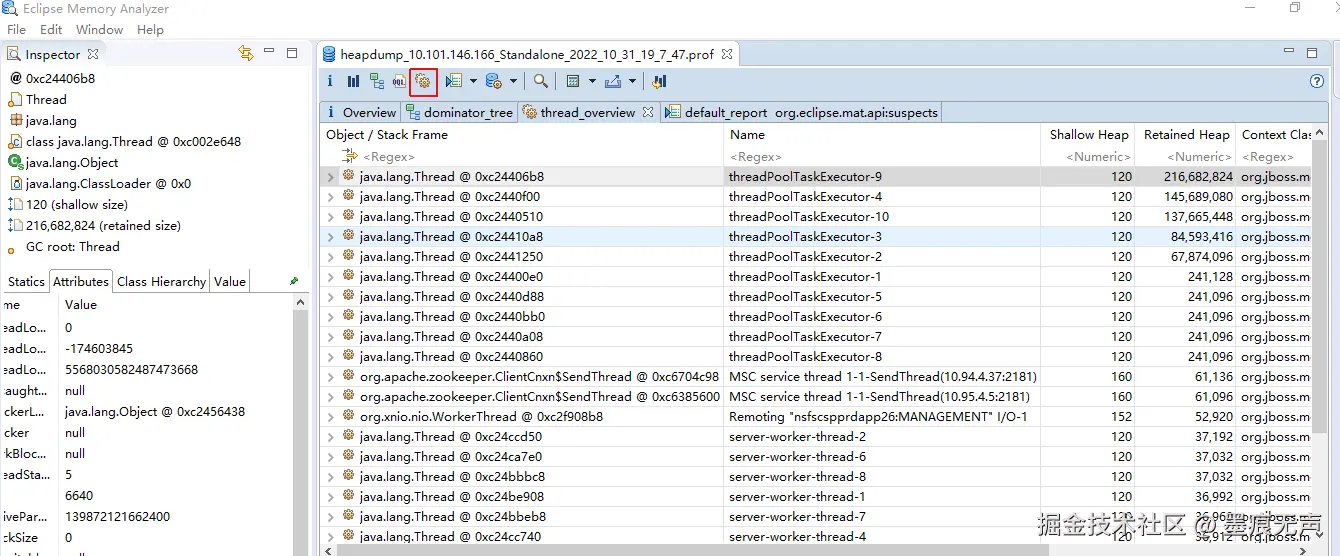 点击上图红框位置,就可以得到按线程概览的内存使用情况。
点击上图红框位置,就可以得到按线程概览的内存使用情况。 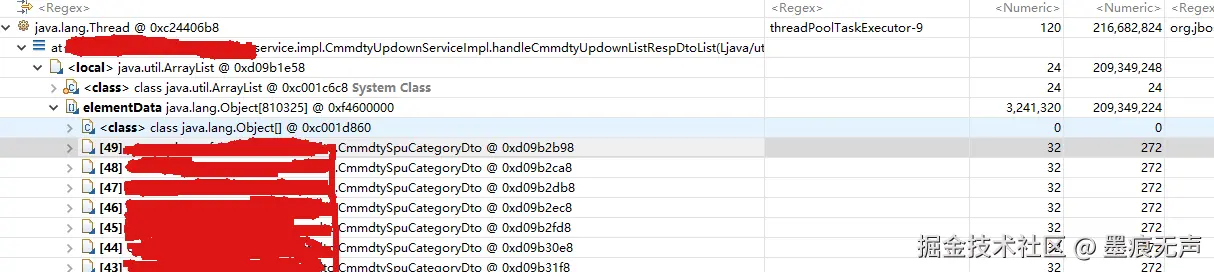 点开占用内存最大的线程,可以很清晰地看到疑似有问题地方法,从上图可以看出在CmmdtyUpdownServiceImpl.handleCmmdtyUpdownListRespDtoList(), 里面有个List,List中塞了一砣子CmmdtySpuCategoryDto对象。基本看到这步基本就可以定位问题的出处了。下一步就是查看下方法里面代码,佐证下判断是否正确。
点开占用内存最大的线程,可以很清晰地看到疑似有问题地方法,从上图可以看出在CmmdtyUpdownServiceImpl.handleCmmdtyUpdownListRespDtoList(), 里面有个List,List中塞了一砣子CmmdtySpuCategoryDto对象。基本看到这步基本就可以定位问题的出处了。下一步就是查看下方法里面代码,佐证下判断是否正确。
整个代码逻辑比较简单,大致业务流程为从上游接收待处理任务数据,然后管理台有个导出excel功能,点击之后从数据库中捞出符合记录数据,按10000条记录一批次一个excel,再将excel上传至文件服务器,完了将excel下载地址通过邮件发给操作人。
java
// 简化的伪代码如下
// 从数据库查询符合记录
// 出问题就在这一步查询,没有limit限制条数,数据量一激增就歇菜。
List<A> list = dao.query();
// 分批生成excel上传文件服务器
// 给操作人发送邮件上诉问题就是典型的DB读表处理不当,一下子产生了太多的对象,导致OOM。
1.2.2、案例二
系统B某日收到OOM告警,联系运维获取dump日志,导入MAT分析 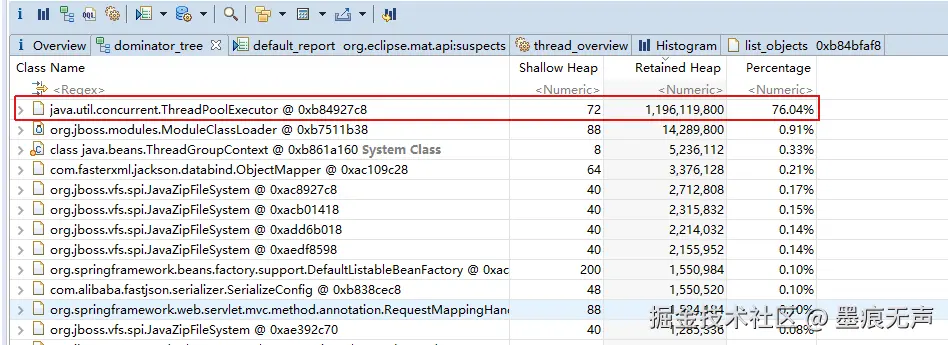
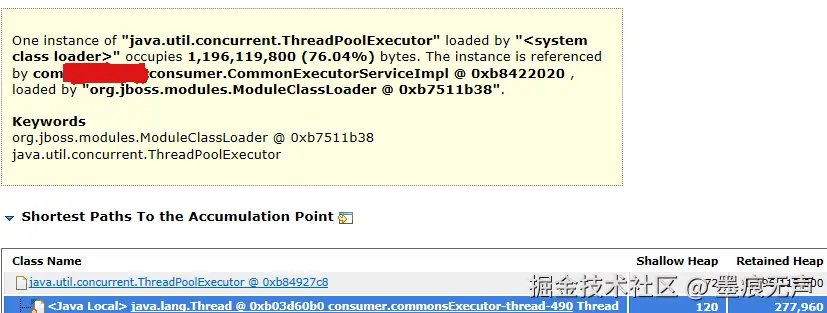 通过上图可以发现是RPC中间件中的线程池中堆积了大量对象,分析中间件源码,发现有这么一段逻辑,大致的伪代码。
通过上图可以发现是RPC中间件中的线程池中堆积了大量对象,分析中间件源码,发现有这么一段逻辑,大致的伪代码。
java
// RPC调用次数
index = 0;
scheduledExecutorService.schedule(() -> {
// isDone() RPC调用已返回结果值
if (!isDone()) {
// timeout = RPC接口超时时间 * 超时重试次数
// requestTimeout RPC接口超时时间
long diff = timeout - requestTimeout;
// index RPC调用的次数
if (index == 0 && diff > 0L) {
scheduledExecutorService.schedule(() -> {
throw new TimeoutException();
}, diff);
}
// execute()为执行RPC的远程调用
commonExecutorService.submit(() -> execute(index + 1));
}
}, requestTimeout);
// 执行RPC远程调用
execute(0);如上诉伪代码可以发现,如果RPC调用超时且对应RPC接口设置了失败重试次数,就会触发向线程池提交任务的逻辑。
刚好隔壁下游系统也收到了因为调用量激增而引发RPC接口异常告警,符合上诉代码逻辑,验证发生OOM的原因。
总结下这次OOM的问题就是下游RPC接口超时,引发RPC中间件的超时重试机制,任务提交到线程池中,然而因为下游接口慢,所以会导致线程池工作队列中的队列消耗的很慢。同时不停地有新的用户请求进来,继续触发重试,进而线程池不断有新的任务提交进来,而因为下游接口慢,线程池工作队列中任务就会逐渐积压,最终内存消耗殆尽,导致OOM。
此种情况下,因为有失败重试,所以一次RPC调用,会被放大N倍。
该问题严格来说算作第三方jar BUG导致的OOM有点牵强,中间件的重试机制没有太大的问题,事后综合分析下游系统发生了缓存穿透,导致大量请求打到数据库上,从而接口响应变慢,下游接口没有做限流,上游调用方又没有配置熔断,及时断开有问题的下游接口,最终拖累了自身导致OOM。
1.3、内存溢出小结
生产问题中,最常碰到的就是内存溢出问题。常见的可能导致内存溢出的原因:
- ①、一次性从外部载入过量的数据进入内存,如果DB读表、处理上传文件;
- ②、在大量数据处理场景下使用容器(Map/List/Set)没有及时清理,造成内存紧张GC来不及回收;
- ③、程序中存在死循环或者大量循环,单个循环中又new了很多对象,导致GC跟不上;
- ④、引入的第三方依赖存在BUG,或者使用不当,导致OOM;
- ⑤、程序中存在内存泄漏问题,一直在蚕食内存,GC无法回收,最终引发内存不够,导致OOM;
- ⑥、堆内存设置过小导致OOM(这种一般不会遇到);
2、JVM内存泄漏
2.1、什么是内存泄漏
内存溢出和内存泄漏是两个不同的概念。
内存溢出: 是新生成的对象速度过快,远快于GC回收的速度,导致内存被消耗光,新生成的对象没有空间分配。就像一个往一个有排水口的桶里不停加水,最后水溢出桶;
内存泄漏:是一些对象一旦生成之后就不会释放,一直占用了空间,最终可能导致OOM。类似于在一个有排水口的桶里扔了一块石头,石头占据的空间永远无法被排出去。
2.2、内存泄漏的原因
造成内存溢出的原因一般分两种:
- ①、堆内泄漏:由于代码不合理导致内存泄漏,例如垃圾对象与静态对象相连、未正确关闭外部连接等;
- ②、堆外泄漏:申请buffer流后未释放内存、直接内存中的数据未手动清理。
一般而说内存泄漏很难被发现,通常遇到内存泄漏问题,往往伴随着内存溢出产生,或者其他问题如数据库获取不到连接等。
2.3、实际案例
系统C某日收到redis连接数异常告警,查看监控平台 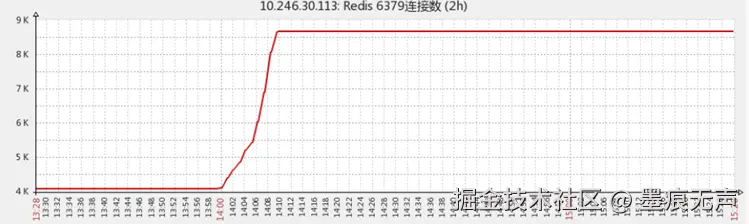 发现redis连接数居然飙到了近9K。查看客户端的连接池配置
发现redis连接数居然飙到了近9K。查看客户端的连接池配置
xml
<poolConfig>
<maxTotal>20</maxTotal>
<maxIdle>10</maxIdle>
<minIdle>5</minIdle>
</poolConfig>发现最大连接也就是20,而且该系统服务器不超过20台,所以正常来说redis连接数应该在小几百。接近9K的连接数必然不太正常,所以只能是程序某处一直占用着连接不释放。检查最近发布提交的代码,发现有这么一段逻辑,代码如下
java
public void batchSetAdd(String key, Set<String> set) {
JedisPipeline p = jedisClient.getJedisPool().getResoure().pipeline();
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
p.sadd(key, iterator.next());
}
p.sync();
}
// jedisClient.getJedisPool().gerResource();
// 这步为中间件jar里面的方法,获得一个jedis实例
// 进一步查看中间件的源码实现
public T getResource() {
try {
// internalPool使用的是Apache Commons Pool2 连接池
return internalPool.borrowObject();
} catch (Exception e) {
......
}
}
// 继续查看Pools连接池对于GenericObjectPool#borrowObject的实现
public T borrowObject(long borrowMaxWaitMillis) throws Exception{
......
// 从连接池获取对象,如果没有则新建
p = (PooledObject) idleObjects.pollFirst();
if (p == null) {
cerate = true;
p = this.create();
}
......
return p.getObject();
}
private PooledObject<T> create() throws Exception {
int localMaxTotal = getMaxTotal();
long newCreateCount = createCount.incrementAndGet();
// 判断连接池中连接数是否已经大于设置的最大连接数,如果没有超过则创建新连接,如果超了则创建新连接失败。
if ((localMaxTotal <= -1 || newCreateCount <= (long) localMaxTotal) && newCreateCount <= Integer.MAX_VALUE ) {
PooledObject p;
try {
p = factory.makeObject();
} catch (Exception e) {
......
}
......
return p;
} else {
createCount.decrementAndGet();
return null;
}
}
// 按照上诉Pool2连接池的规则,结合配置的最大连接数为20,那么不应该会产生这么连接数才对。
// 再回去查看下redis中间件里面初始化连接池的地方,发现了意外惊喜
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
config.setMaxIdle(poolConfig.getMaxIdle());
// 傻眼了,没有使用配置文件设置的maxTotal,而且直接塞了个Integer.MAX_VALUE
config.setMaxTotal(Integer.MAX_VALUE);
......
// 初始化连接池
......redis中间件客户端正确的使用方式
java
jedisClient.execute(JedisAction<T> action) {
......
Jedis jedis;
try {
// 从连接池中获取jedis对象
jedis = jedisPool.getResource();
// 回调业务方法
action.execute(jedis);
} catch (Exception e) {
......
} finally {
......
jedisPool.retrunResource(jedis);
......
}
......
}跟上诉出问题的写法,最显著的差异就是使用完连接池的连接后,会及时归还给连接池。
综上分析可以发现,有问题的代码,每次都会从连接池中获取连接,并且不会在使用完归还连接,所以会导致连接池中无空闲连接,每次都会新建新连接,再加上中间件设置连接池的地方也有问题,最大连接数=Integer.MAX_VALUE。等于无最大连接上限,所以会不停的创建新连接对象,加入连接池,连接池对象会一直存在,那么其中的连接对象也不会被GC回收。
这就是典型的发生了内存泄漏。除此之外,对于文件流的处理,如果没有释放也可能发生内存泄漏,一般还会伴随大量临时文件占用磁盘的问题。
2.4、内存泄漏小结
常见的发生内存泄漏的原因如下:
- ①、外部临时连接使用后未合理关闭,如DB连接、Socket连接、文件IO流等;
- ②、程序中新建的对象与长生命周期的对象建立引用,完成后未及时清理或者断开连接,导致新对象无法被GC回收,如与静态对象、单例对象连接上了;
- ③、申请堆外的直接内存,使用完后未手动释放或清理内存,从而导致内存泄漏
上诉案例就是同时命中了1、2两点
3、业务线程死锁
3.1、产生死锁的条件
死锁是指两个或两个以上线程,在并发执行过程中,由于每个线程都持有某些资源,同时又在等待其他线程所持有的资源,从而导致所有相关线程都无法继续执行的一种僵持状态。
死锁发生通常满足四个必要条件:
- ①、互斥条件:资源不能被共享,只有由一个线程独占;
- ②、持有并等待:线程持有至少一个资源,并等待获取其他线程占有的资源;
- ③、非抢占条件:已分配给线程的资源不能被强制剥夺,只能由对应线程主动释放;
- ④、循环等待条件:存在一个线程的环形链,每个线程都在等待下一个线程所占有的资源
通俗点说就是,两个或者两个以上线程,持有着资源不放,同时又等待获取其他线程持有的资源,最终僵死在那。
3.2、实际案例
参见《SNSMP死锁问题定位》
3.3、死锁小结
发生死锁问题问题的表象,通常为CPU、内存水位都很正常,但是服务不可用,这时候极可能是发生了死锁;
这时候拿到JavaCore日志, 在其中如果发现deadlock字样,那么仔细分析对应线程栈,找到对应代码,基本都能发现问题,然后针对改造。
4、CPU飙升至100%
线上生产常见问题,除了OOM之外,CPU100%也是常见的问题之一。
4.1、实际案例
4.1.1、案例一
某系统D收到CPU使用率超过90%告警,联系运维,获取相关JavaCore信息。 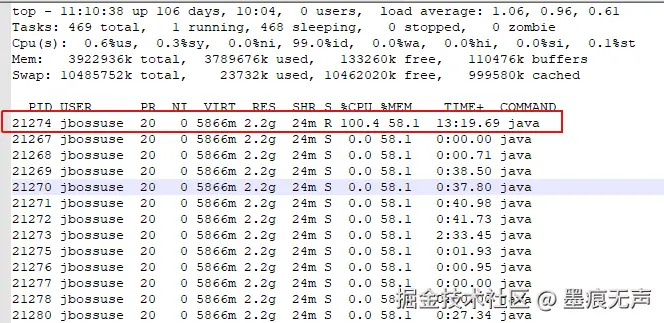 发现进程号21274对应的进程导致CPU使用率100%,并且该进程为jbossUser,为Java进程。
发现进程号21274对应的进程导致CPU使用率100%,并且该进程为jbossUser,为Java进程。
将进程号21274转为16进制=>531a,拿着16进制的进程号,到javacore文件中检索下, 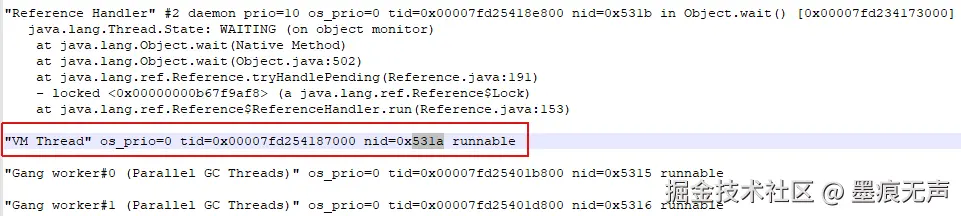 发现其对应的线程为"VM-Thread",这说明导致CPU 100%的线程是JVM自身的而非业务线程。一般来说这类情况,大概率可能是GC线程导致的。
发现其对应的线程为"VM-Thread",这说明导致CPU 100%的线程是JVM自身的而非业务线程。一般来说这类情况,大概率可能是GC线程导致的。
查看下GC日志,印证下猜测是否准确。用GCViewer打开GC日志如下: 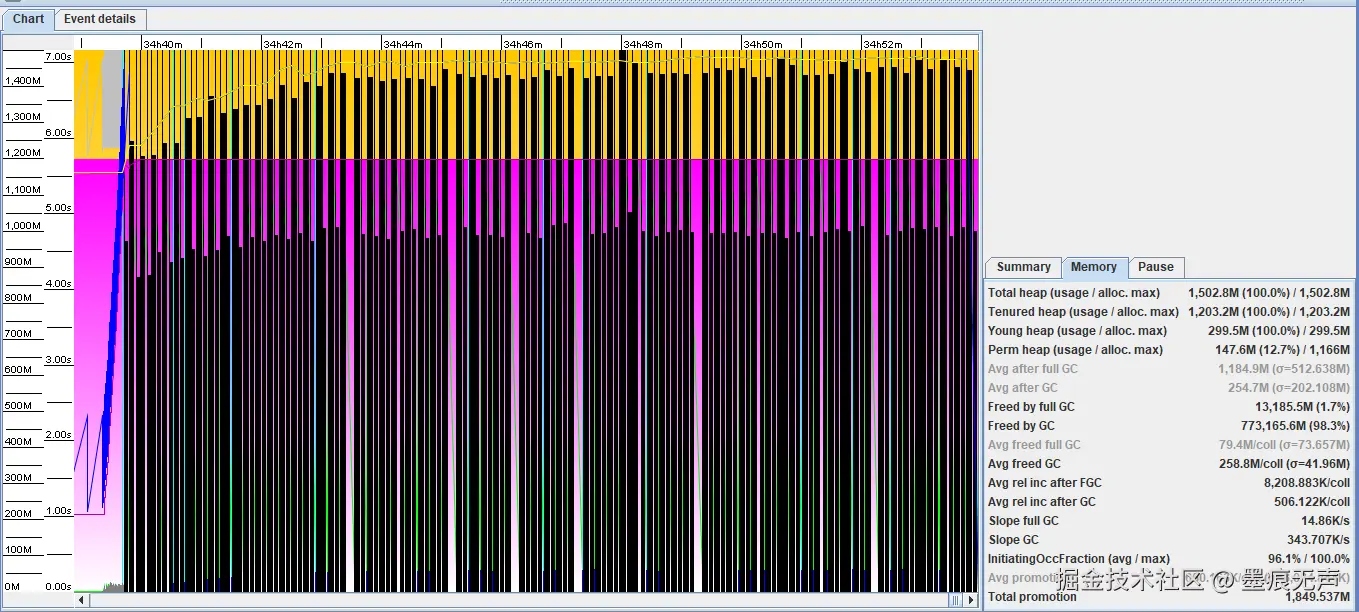 可以明显发现出现密集的黑线(FullGc),并且Tenured heap(老年代)、Young heap均是100%(该系统GC使用CMS)。说明猜测准确,的确是因为发生了大量的Full GC,导致了CPU 100%;那么下一步就是联系运维获取一份dump日志,看看当前堆情况,具体产生了哪些大量对象。分析方式跟OOM分析一样。
可以明显发现出现密集的黑线(FullGc),并且Tenured heap(老年代)、Young heap均是100%(该系统GC使用CMS)。说明猜测准确,的确是因为发生了大量的Full GC,导致了CPU 100%;那么下一步就是联系运维获取一份dump日志,看看当前堆情况,具体产生了哪些大量对象。分析方式跟OOM分析一样。
4.1.2、案例二
某日系统D收到CPU 100%的告警,联系运维获取javacore等信息,发现 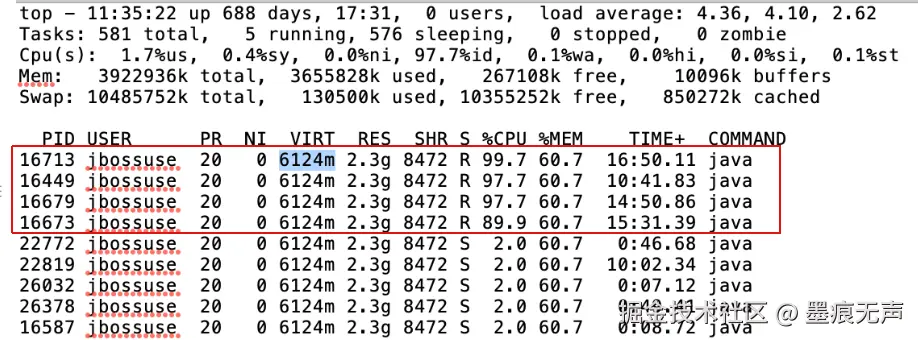 可以发现CPU使用率最高的几个进程,均为jbossuser,说明都是Java应用。将进程号分别转换为16进制,分别为4149、4041、4127、4121。
可以发现CPU使用率最高的几个进程,均为jbossuser,说明都是Java应用。将进程号分别转换为16进制,分别为4149、4041、4127、4121。  将JavaCore线程快照文件到IBM TMDA工具,找到对应线程栈信息,如下
将JavaCore线程快照文件到IBM TMDA工具,找到对应线程栈信息,如下 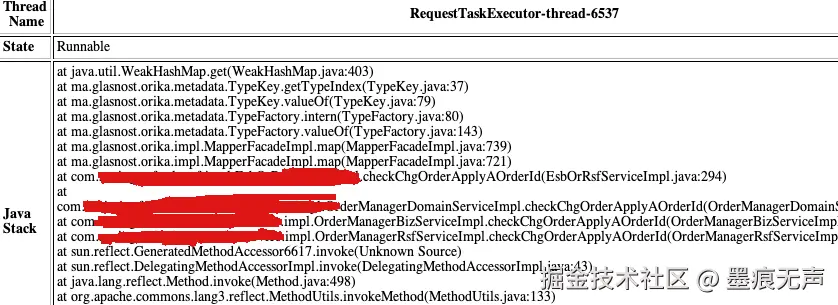 对应代码如下
对应代码如下
java
B b = OrikaMapperFactory.mapper.map(a, B.class);可以发现此处使用Orika框架做bean转换,再结合线程栈信息,Orika框架的TypeKey的getTypeIndex如下 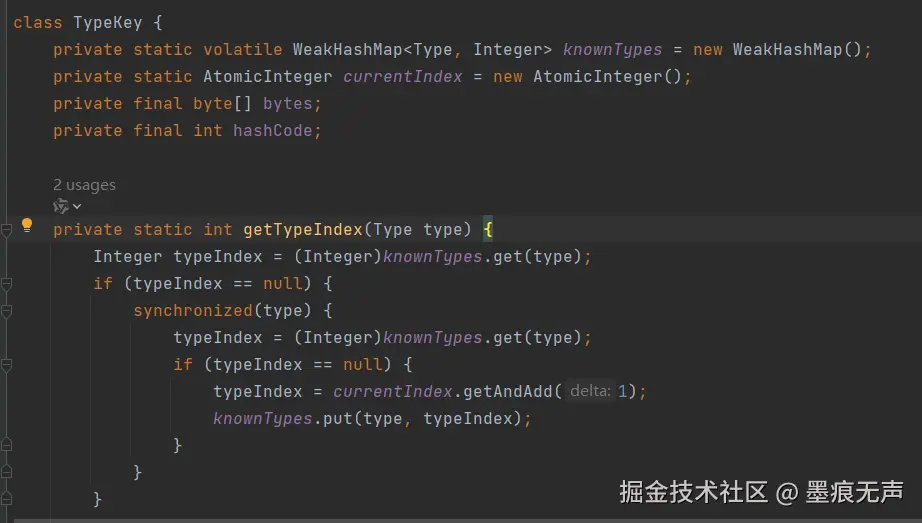 众所周知,1.7的HashMap存在导致CPU 100%的问题,此处的WeakHashMap是不是也是类似的原因导致的?查看WeakHashMap的源码,可以发现1.8版本中的WeakHashMap并没有如HashMap做调整,所以也就是说在多线程环境下,WeakHashMap存在导致CPU 100%的可能性,上诉业务代码中定义的mapper又是一个全局静态变量,所以发生CPU 100%就不足为奇了。
众所周知,1.7的HashMap存在导致CPU 100%的问题,此处的WeakHashMap是不是也是类似的原因导致的?查看WeakHashMap的源码,可以发现1.8版本中的WeakHashMap并没有如HashMap做调整,所以也就是说在多线程环境下,WeakHashMap存在导致CPU 100%的可能性,上诉业务代码中定义的mapper又是一个全局静态变量,所以发生CPU 100%就不足为奇了。
发生问题时,orika的版本为1.4.9,查询网上也有类似的问题,给出的解决方案也简单,升级下版本到1.5.4即可 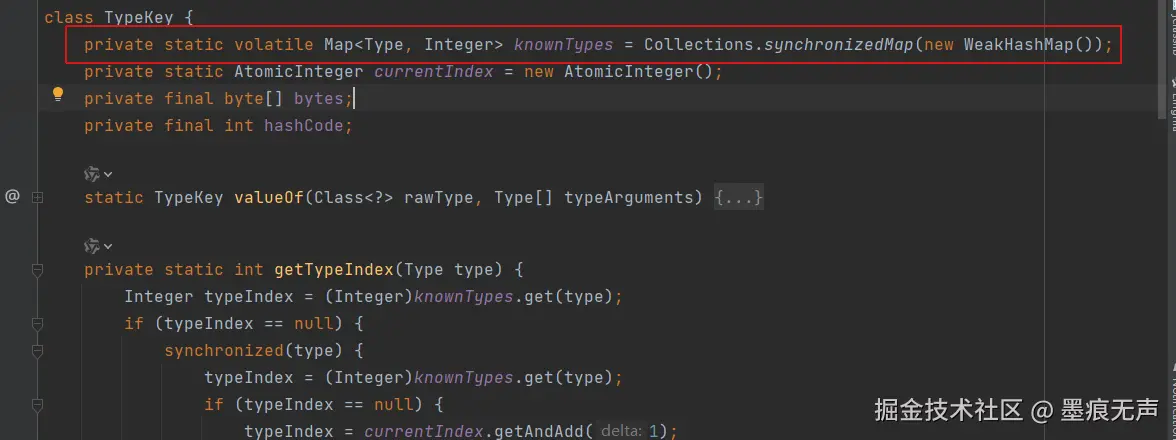 对比两个版本的实现,1.5.4版本改为了线程安全方式使用WeakHashMap。
对比两个版本的实现,1.5.4版本改为了线程安全方式使用WeakHashMap。
4.2、CPU 100%问题小结
CPU 100%问题的排查步骤:
- top指令查看系统后台进程占用情况,确认是否是Java进程导致的;
- 找出CPU占用最高的线程号,将其转换为16进制
- 通过jstack工具导出线程快照文件
- 将前面转换过的16进制进程号,在线程快照文件中检索,找出具体的线程栈信息
- 确认导致CPU 100%的线程为业务线程还是VM线程
- 如果是业务线程则依据线程栈信息查看对应的代码分析排查整改问题;
- 如果是VM线程,则需要进一步分析,一般来说常见的是大多是频繁GC导致,可以通过GCViewer工具查看GC日志进一步分析
CPU飙升问题,常见的原因:
①、业务代码中存在死循环或者大量递归操作;
②、Java应用中创建了太多线程,造成频繁的上下文切换,而消耗CPU资源,这类一般都是线程池使用不合理导致;
③、虚拟机线程导致,一般来说就是频繁GC,或者频繁编译。大多数情况是频繁GC,需要结合dump日志进一步分析找出产生大量对象的位置。
5、频繁Full GC问题
线上环境还有一类常见问题就是频繁GC问题。众所周知Java语言的一大优势就是虚拟机会替你管理垃圾回收,不需要开发人员额外关注废弃对象的回收问题,因此发生GC是正常情况,但是如果频繁出现Full GC,而且GC时间过长的话,那么就不合理了。
下面介绍一个实际案例(兄弟部门遇到的一个实际生产案例,很典型也很特别),看看这类问题如何着手定位。
5.1、实际案例
5.1.1、问题描述
某系统E生产监控发现会出现规律性FullGC(每隔1小时会发生一次),给系统稳定性带来安全隐患。
查看监控平台可以发现,FullGC出现的很规律,大致每隔一小时就会来一次,而且系统集群的所有机器都会发生,并且不管白天业务高峰时,还是夜晚业务低谷时,都会发生,就好比上了闹铃一般,每隔一小时来一次。 
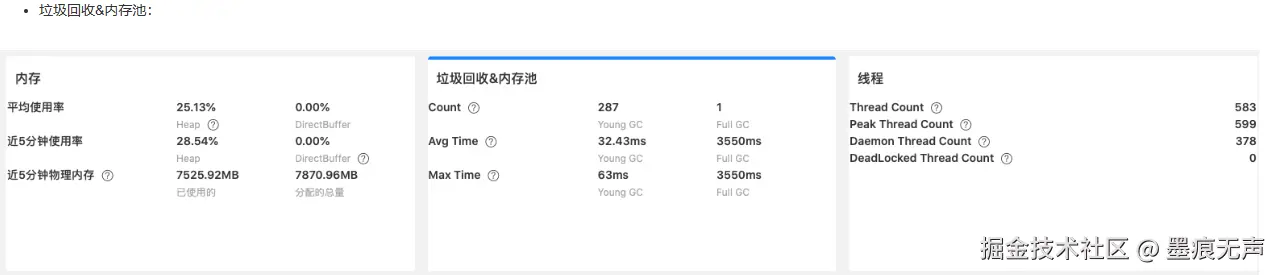 查看监控面板可以发现FullGC的持续时间较长,接近4秒左右,显然是对业务有影响的。
查看监控面板可以发现FullGC的持续时间较长,接近4秒左右,显然是对业务有影响的。
该系统机器JVM核心配置如下:
-Xms4096m
-Xmx4096m
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:+CMSParallelRemarkEnabled
服务器配置为4C8G,JVM堆内存4G,JDK8,新生代使用ParNew垃圾收集器,老年代使用CMS垃圾收集器。
5.1.2、GC原因分析
一般引发FullGC的原因有如下几个:
- ①、新生代空间不足 - 引发YongGC;
- ②、老年代空间不足 - 引发FullGC;
- ③、元空间不足 - 引发FullGC;
- ④、显示调用System.gc() - 引发FullGC;
查下监控面板上发生FullGC时内存使用情况 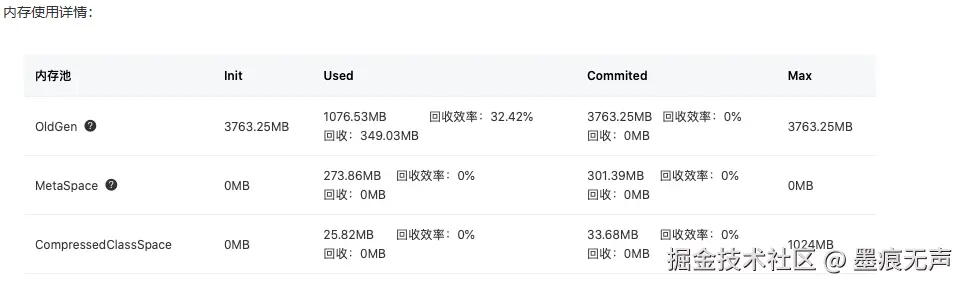 由上图可以发现发生FullGC时
由上图可以发现发生FullGC时
- 老年代空间使用了1076.53MB,空间还很富裕;
- MetaSpace,元空间使用了273.86MB,元空间使用本地物理内存,4G左右,空间也很富裕。
所以综上所述排除上诉原因②、③,剩下的只可能是原因④显示调用了System.gc()。导致就很不可思议,印象中业务代码一般不会有人主动去调用System.gc()!
联系运维获取对应的GC日志 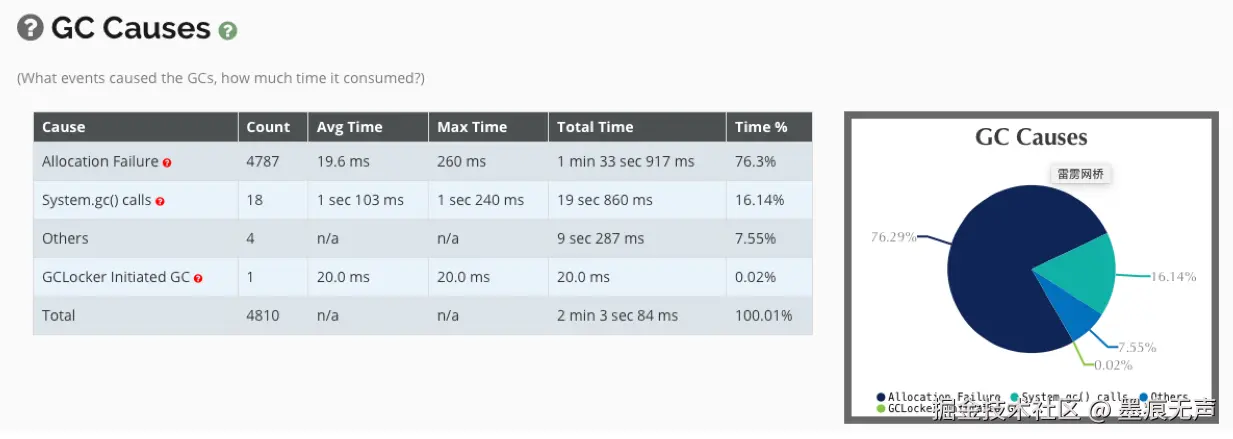 (上图为同事用gceasy.io 分析的结果,也可以用GCViewer工具查看)
(上图为同事用gceasy.io 分析的结果,也可以用GCViewer工具查看)
可以发现真的是System.gc()导致的FullGC。 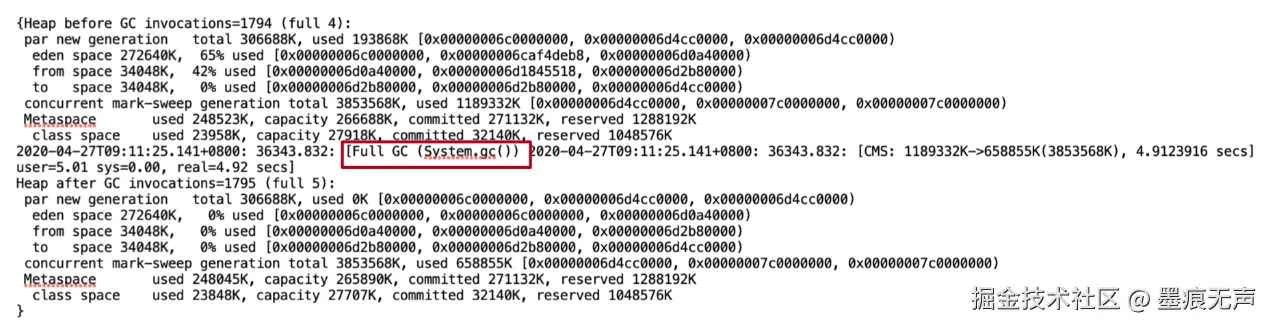
5.1.3、System.gc 触发条件分析
在项目工程里面全局搜索,发现除了jar中有System.gc()调用,业务代码并无System.gc()调用。但是调用System.gc()的jar有一大堆,具体是哪个jar触发的调用,此时依旧无法确认。 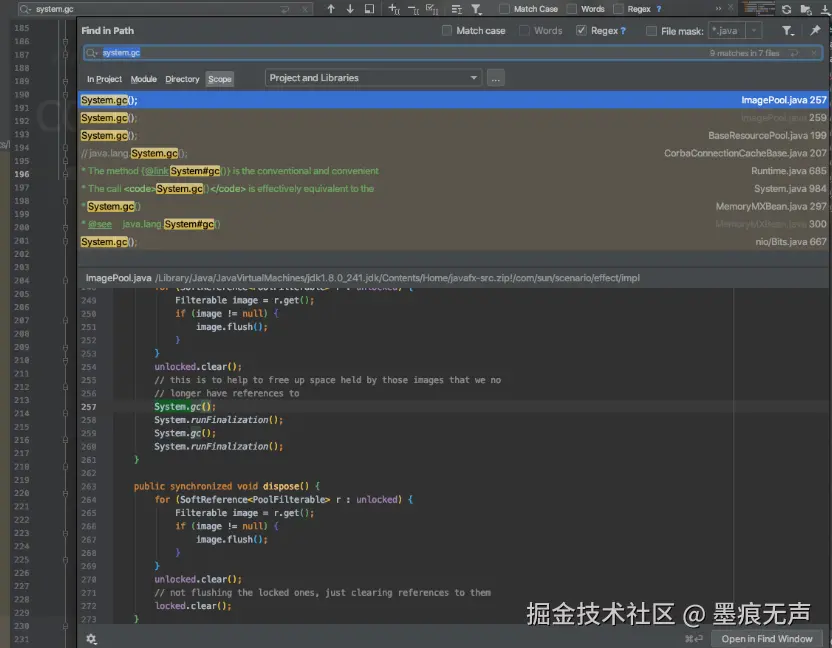 查看对应的JavaCore文件,检索GC字样,如下图所示
查看对应的JavaCore文件,检索GC字样,如下图所示 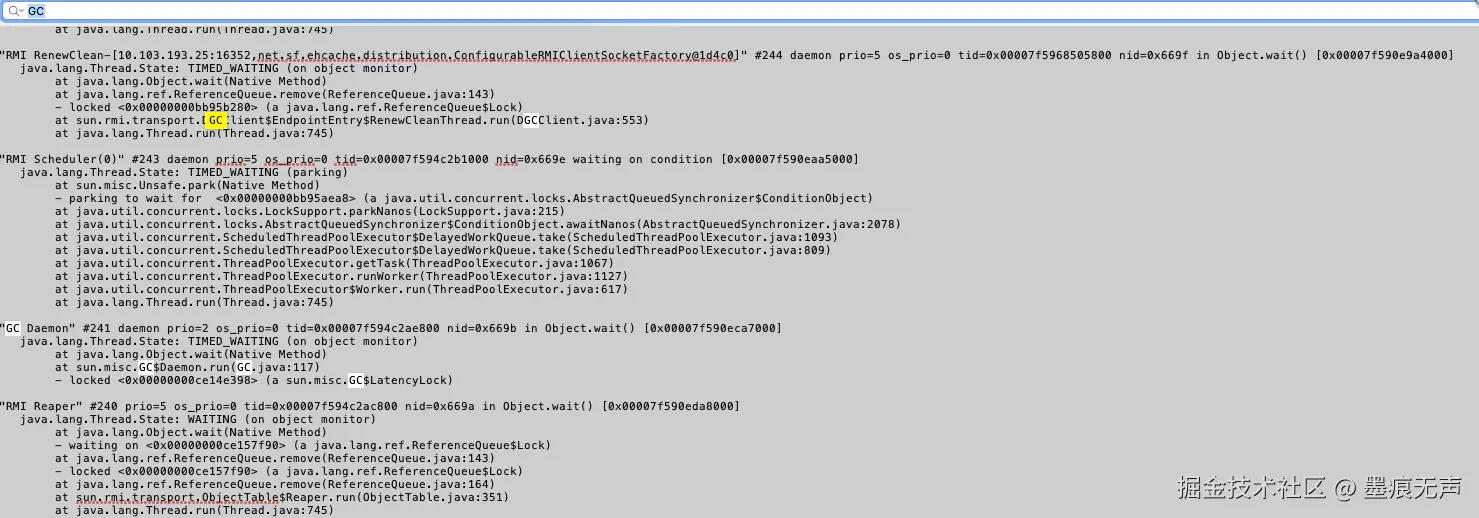 "GC Daemon"、"RMI RenewClean-"两个线程比较可疑。
"GC Daemon"、"RMI RenewClean-"两个线程比较可疑。
5.1.3.1、"GC Daemon"线程分析
java
"GC Daemon" #241 daemon prio=2 os_prio=0 tid=0x00007f594c2ae800 nid=0x669b in Object.wait() [0x00007f590eca7000]
java.lang.Thread.State: TIMED_WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at sun.misc.GC$Daemon.run(GC.java:117)
- locked <0x00000000ce14e398> (a sun.misc.GC$LatencyLock)对照JavaCore线程栈信息,sun.misc.GC为jdk中的类,分析代码可以发现如下逻辑 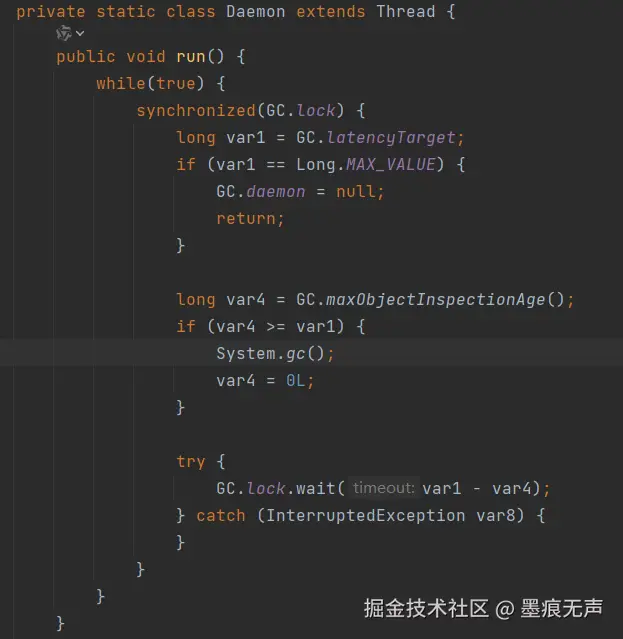 其中GC.maxObjectInspectionAge()返回当前时间和上次堆回收时间戳的差值,GC daemon的作用就是一旦启动,会定期调用System.gc(),来触发垃圾回收,调用链路如下
其中GC.maxObjectInspectionAge()返回当前时间和上次堆回收时间戳的差值,GC daemon的作用就是一旦启动,会定期调用System.gc(),来触发垃圾回收,调用链路如下
5.1.3.2、"RMI RenewClean-"线程分析
java
"RMI RenewClean-[10.103.193.25:16352,net.sf.ehcache.distribution.ConfigurableRMIClientSocketFactory@1d4c0]" #244 daemon prio=5 os_prio=0 tid=0x00007f5968505800 nid=0x669f in Object.wait() [0x00007f590e9a4000]
java.lang.Thread.State: TIMED_WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143)
- locked <0x00000000bb95b280> (a java.lang.ref.ReferenceQueue$Lock)
at sun.rmi.transport.DGCClient$EndpointEntry$RenewCleanThread.run(DGCClient.java:553)
at java.lang.Thread.run(Thread.java:745)查看DGCClient的源码,发现如下代码 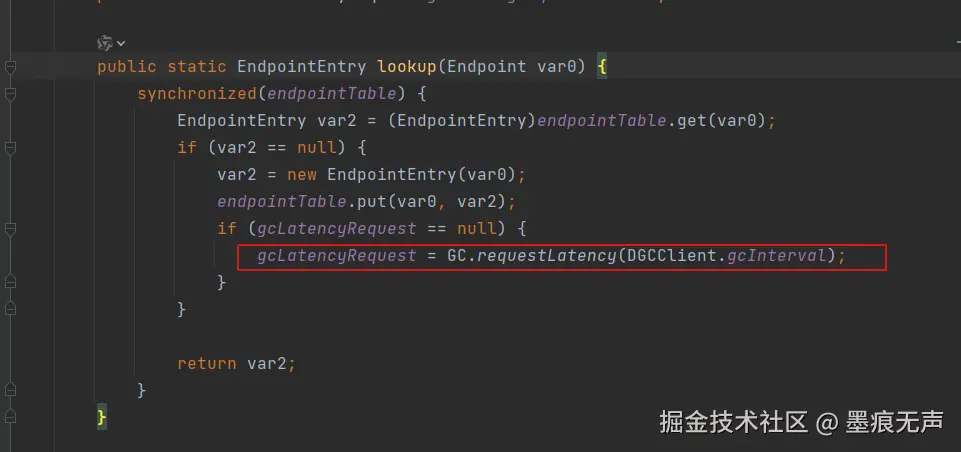
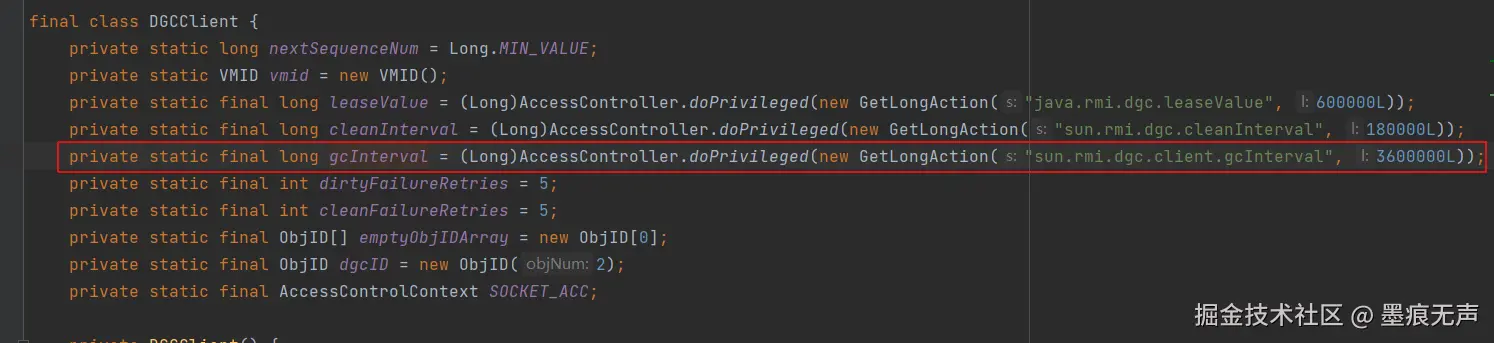 可以发现DGCClient$EndpointEntry#lookup()中,调用了GC.requestLatency(DGCClient.gcInterval)方法,而DGCClient.gcInterval变量恰好设置的是3600秒,一小时。
可以发现DGCClient$EndpointEntry#lookup()中,调用了GC.requestLatency(DGCClient.gcInterval)方法,而DGCClient.gcInterval变量恰好设置的是3600秒,一小时。
看到这步就有点激动了,遇到的FullGC,刚好是每隔一小时触发一次,会不会就是此处导致的问题?
由上诉线程栈推测,Ehcache.jar某个地方触发了GC.requestLatency(long var),并且设置了1小时的GC间隔时间。
那么下一个问题就是找出Ehcache.jar具体在哪步触发了GC.requestLatency()?
此时可以借助Java VisualVM的BTrace插件,通过动态字节码技术,打印指定方法的调用栈,从而确认调用链路。
5.1.3.3、确认Full GC触发条件
BTrace脚本 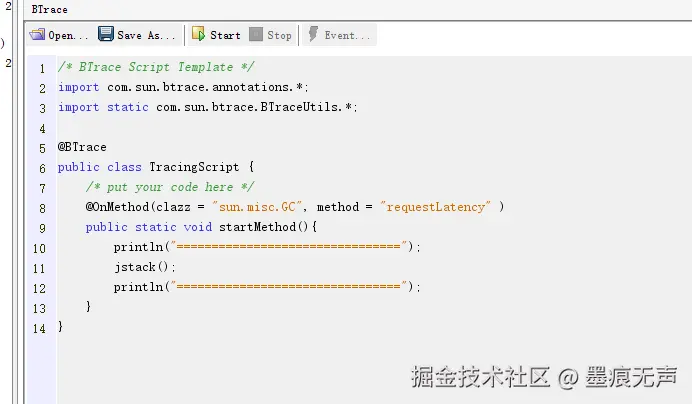 Ehcache配置文件
Ehcache配置文件  测试代码
测试代码
java
@GetMapping("ehcache")
public String ehcache() {
CacheManager cacheManager = CacheManager.create("./src/mian/resources/ehcache.xml");
Cache cache = cacheManager.getCache("test");
cache.put(new Element("key", "value"));
cache.flush();
return "OK";
}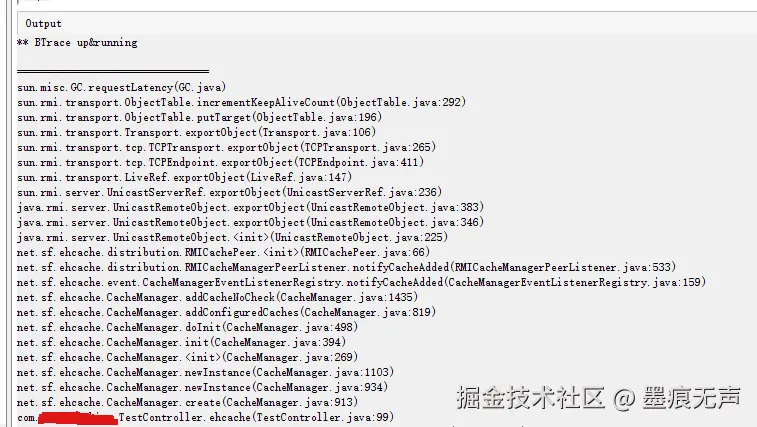 如上图可以发现,CacheManger.create() -> ObjectTable.incrementKeepAliveCount()
如上图可以发现,CacheManger.create() -> ObjectTable.incrementKeepAliveCount() 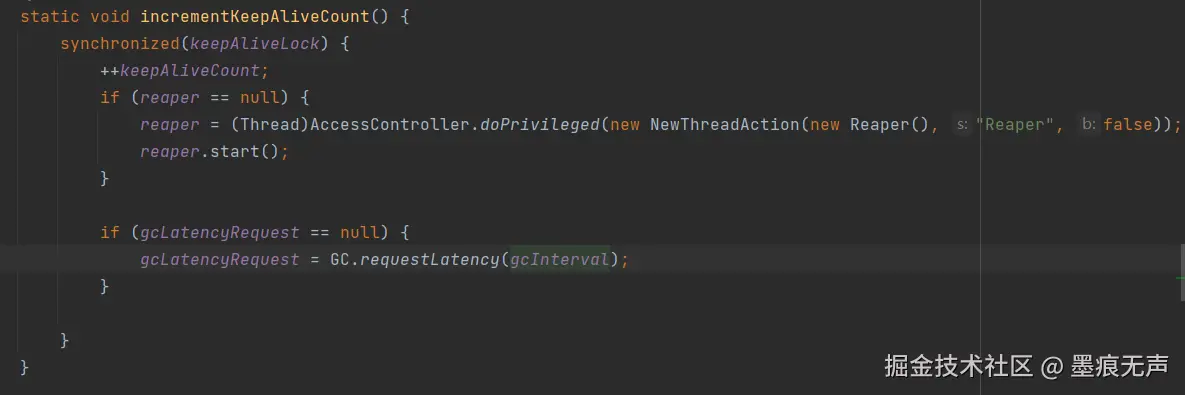
 可以发现ObjectTable也会触发GC.requestLatency(),并且间隔时间也是1小时。
可以发现ObjectTable也会触发GC.requestLatency(),并且间隔时间也是1小时。
到这步基本可以确认一小时一次的规律Full GC,就是Ehcache.jar导致。进一步研读Ehcache中CacheManager.create()方法,可以发现因为Ehcache.xml中配置了集群广播而导致了触发GC.requestLatency(),进而引发了一小时一次的规律Full GC问题。 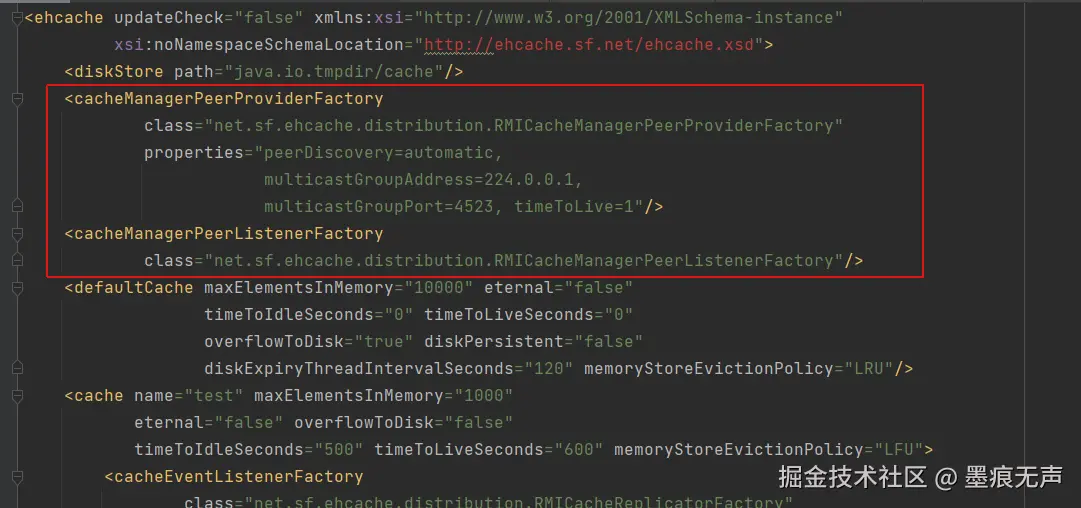
5.1.4、解决方案
该系统是个老系统,很早之前引入了Ehcahe组件,目前也引入了redis,没有必要再使用Ehcahe的集群广播功能,并且Ehcahe的广播方式,本身限制重重,不适合集群环境使用,移除关于Ehcahe集群广播配置即可。
5.2、GC问题排查总结
遇到GC问题的排查思路一般如下:
- ①、先观察GC出现是否有规律,有监控系统辅助可以比较清晰地观察到规律,如果没有监控系统辅助的话,可以找运维获取GC日志,接入GCViewer或者其他工具分析GC日志;
- ②、查看分析GC日志,重点观察Full GC,以及产生GC的原因;
- ③、如果是因为堆空间不够导致的GC,那么需要结合dump文件,查看是否堆对象分配情况,是否存在内存泄漏或者不合理的大对象存在;
- ③、如果是System.gc(),则需要进一步分析,结合JavaCore文件,分析堆栈信息,猜测可能存在的问题;再结合Java VisualVM BTrace插件验证猜测。这类问题不好排除,只能结合蛛丝马迹大胆猜测,然后再验证观察,最终确认问题的根本原因。
6、接口响应变慢
"接口响应变慢"也是常见的生产问题之一,一般来说发现系统接口告警,或者上游反馈接口变慢。这时候拿到的只是个表象,接口响应变慢,但是具体原因是啥,需要具体分析。
6.1、可能导致的原因
综合而言,"接口响应变慢"是个复合型问题。
- Java应用中出现线程阻塞
- TCP连接爆满
- 出现慢SQL
- 硬件机器磁盘/CPU/内存资源紧张出现争抢
- 上游系统流量过大
- 依赖的下游接口出现异常
- 网络IO过大,导致网络带宽过载
- log日志打的太多,IO紧张
- ......
以上原因都有可能导致接口响应变慢。
6.2、问题排查思路
- ①、系统整体响应变慢:
如果是整个系统响应变慢,一般的排查思路
先看下是不是硬件原因(网络/硬件等外在环境因素);
如果不是,则看下是不是上游流量过大导致的压力过大;
还有就是看Java应用的堆空间、CPU、GC情况,看看是不是相关原因导致。 - ②、单个接口响应变慢: 如果是单个接口响应变慢,相对好定位点
查看该接口是否依赖外围服务,如果依赖,那么外围服务是否异常;
其次对应接口是否存在慢SQL;
对应接口是否存在锁,导致阻塞等原因。
此外还需要观察接口变慢是否持续性,还是偶发性的,还是有规律间发性的,针对不同的情况,具体分析。
常见的解决接口慢的方案有:多线程执行、同步响应变异步回调通知、引入缓存、MQ削峰填谷、读写分离、静态分离、集群扩容、增加流控丢车保帅等等