质量不是检验出来的,而是生产出来的------这句话听起来像老生常谈,却是统计质量控制(Statistical Quality Control,SQC)最核心的信仰。SPC(Statistical Process Control,统计过程控制)是SQC的重要分支,专注于用统计工具实时监控生产过程,在问题真正爆发之前就把它扼杀在摇篮里。
本文从核心概念出发,带你系统理解SQC/SPC的思维框架,并配合Python代码和可视化图表,让抽象的统计学概念变得触手可及。
一、SQC 的全景地图
SQC 是一个"伞形"概念,覆盖了从原材料到成品的全链条质量管理。它大致分为三个层次:
- 描述性统计:用均值、标准差、直方图等工具描述数据分布
- 统计过程控制(SPC):用控制图实时监控过程稳定性
- 验收抽样(Acceptance Sampling):用抽样方案决定一批产品是否放行
三者相辅相成。SPC 是其中最有"动态感"的部分------它不是事后验尸,而是过程中的实时心电图。
二、核心概念精讲
2.1 变异(Variation):一切的起点
生产过程中,没有两个零件是完全相同的。这种差异叫做变异,是SPC研究的对象。变异分两类:
- 普通原因变异(Common Cause Variation):系统固有的随机波动,稳定可预测,就像人的正常心跳有轻微起伏
- 特殊原因变异(Special Cause Variation):由刀具磨损、操作失误、原料批次变化等具体原因引发,是"异常信号"
SPC 的核心任务,就是区分这两种变异。过程只含普通原因变异时,称为统计受控(In Control);一旦出现特殊原因,就需要立即追查。
2.2 控制图(Control Chart):SPC 的灵魂工具
控制图由 Walter Shewhart 在1920年代发明,结构简单却极为强大。它由三条线构成:
UCL=Xˉˉ+3σ
CL=Xˉˉ
LCL=Xˉˉ−3σ
其中 UCL 为控制上限, LCL 为控制下限, CL 为中心线。注意:控制限不是规格限,它们来自过程本身的数据,而非客户要求。
常见控制图类型:
| 控制图类型 | 适用场景 | 监控对象 |
|---|---|---|
| Xˉ-R 图 | 小样本(n=2~10)计量数据 | 均值 + 极差 |
| Xˉ-S 图 | 大样本计量数据 | 均值 + 标准差 |
| I-MR 图 | 单值数据(n=1) | 个体值 + 移动极差 |
| P 图 | 计数数据(不合格率) | 不合格品率 |
| C 图 | 计数数据(缺陷数) | 单位缺陷数 |
2.3 过程能力(Process Capability):能不能做好
过程受控只是第一步,还要看过程能力------即过程满足规格要求的能力。核心指标是 Cp 和 Cpk:
Cp=6σUSL−LSL
Cpk=min(3σUSL−μ, 3σμ−LSL)
- Cp 衡量潜在能力(假设过程对中)
- Cpk 衡量实际能力(考虑均值偏移)
一般要求 Cpk≥1.33,六西格玛水平要求 Cpk≥2.0。
| Cpk 值 | 过程状态 | 不合格率(近似) |
|---|---|---|
| < 1.0 | 能力不足 | > 0.27% |
| 1.0 ~ 1.33 | 勉强合格 | 0.006% ~ 0.27% |
| 1.33 ~ 1.67 | 良好 | < 0.006% |
| ≥ 2.0 | 六西格玛级别 | < 0.0000002% |
2.4 Western Electric 判异规则
仅靠"点出界"来判断失控太过保守。Western Electric(WE)提出了一套更灵敏的判异规则,用于识别非随机模式:
- 规则1:1个点落在3σ之外
- 规则2:连续9点在中心线同侧
- 规则3:连续6点单调递增或递减
- 规则4:连续14点交替上下波动
- 规则5:连续2/3点落在2σ~3σ之间(同侧)
这些规则本质上是在问:这种模式,随机情况下发生的概率有多低?
三、Python 完整实现与可视化
下面的代码一次性展示四个核心概念: Xˉ-R 控制图、I-MR 图、过程能力分析,以及 WE 判异规则检测。
python
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.gridspec import GridSpec
from scipy import stats
# ── 全局样式 ──────────────────────────────────────────────
plt.rcParams.update({
'font.family': 'DejaVu Sans',
'axes.spines.top': False,
'axes.spines.right': False,
'axes.grid': True,
'grid.alpha': 0.3,
'grid.linestyle': '--',
'figure.facecolor': '#FAFAFA',
'axes.facecolor': '#FAFAFA',
})
np.random.seed(42)
# ══════════════════════════════════════════════════════════
# 模块 1:X̄-R 控制图
# ══════════════════════════════════════════════════════════
def generate_process_data(n_subgroups=30, subgroup_size=5,
shift_at=None, shift_magnitude=2.0):
"""生成带可选均值漂移的模拟过程数据"""
mu, sigma = 50.0, 1.5
data = []
for i in range(n_subgroups):
mean = mu + (shift_magnitude if shift_at and i >= shift_at else 0)
data.append(np.random.normal(mean, sigma, subgroup_size))
return np.array(data)
def xbar_r_chart(data):
"""计算 X̄-R 图的控制限"""
# A2, D3, D4 系数(子组大小 n=5)
n = data.shape[1]
A2_table = {2: 1.880, 3: 1.023, 4: 0.729, 5: 0.577, 6: 0.483}
D3_table = {2: 0, 3: 0, 4: 0, 5: 0, 6: 0}
D4_table = {2: 3.267, 3: 2.574, 4: 2.282, 5: 2.114, 6: 2.004}
A2, D3, D4 = A2_table[n], D3_table[n], D4_table[n]
xbar = data.mean(axis=1)
ranges = data.max(axis=1) - data.min(axis=1)
xbar_bar = xbar.mean()
r_bar = ranges.mean()
# X̄ 图控制限
ucl_x = xbar_bar + A2 * r_bar
lcl_x = xbar_bar - A2 * r_bar
# R 图控制限
ucl_r = D4 * r_bar
lcl_r = D3 * r_bar
return xbar, ranges, xbar_bar, r_bar, ucl_x, lcl_x, ucl_r, lcl_r
def detect_we_rules(values, cl, ucl, lcl):
"""
检测 Western Electric 判异规则
返回每个点违反的规则编号列表
"""
n = len(values)
sigma = (ucl - cl) / 3
violations = [[] for _ in range(n)]
for i in range(n):
v = values[i]
# 规则1:超出3σ
if v > ucl or v < lcl:
violations[i].append(1)
for i in range(8, n):
# 规则2:连续9点同侧
window = values[i-8:i+1]
if all(w > cl for w in window) or all(w < cl for w in window):
for j in range(i-8, i+1):
if 2 not in violations[j]:
violations[j].append(2)
for i in range(5, n):
# 规则3:连续6点单调
window = values[i-5:i+1]
if all(window[k] < window[k+1] for k in range(5)) or \
all(window[k] > window[k+1] for k in range(5)):
for j in range(i-5, i+1):
if 3 not in violations[j]:
violations[j].append(3)
for i in range(1, n):
# 规则4:连续2/3点在2σ~3σ(同侧)
if i >= 2:
window = values[i-2:i+1]
above_2s = [w > cl + 2*sigma for w in window]
below_2s = [w < cl - 2*sigma for w in window]
if sum(above_2s) >= 2 or sum(below_2s) >= 2:
if 4 not in violations[i]:
violations[i].append(4)
return violations
# ══════════════════════════════════════════════════════════
# 模块 2:过程能力分析
# ══════════════════════════════════════════════════════════
def process_capability(data_flat, lsl, usl):
mu = data_flat.mean()
sigma = data_flat.std(ddof=1)
cp = (usl - lsl) / (6 * sigma)
cpu = (usl - mu) / (3 * sigma)
cpl = (mu - lsl) / (3 * sigma)
cpk = min(cpu, cpl)
return mu, sigma, cp, cpk
# ══════════════════════════════════════════════════════════
# 主绘图函数
# ══════════════════════════════════════════════════════════
def plot_spc_dashboard():
# 生成数据:前25组正常,第25组起均值漂移
data_normal = generate_process_data(n_subgroups=30, subgroup_size=5)
data_shift = generate_process_data(n_subgroups=30, subgroup_size=5,
shift_at=22, shift_magnitude=2.5)
xbar_n, R_n, xbb_n, rb_n, ucl_xn, lcl_xn, ucl_rn, lcl_rn = xbar_r_chart(data_normal)
xbar_s, R_s, xbb_s, rb_s, ucl_xs, lcl_xs, ucl_rs, lcl_rs = xbar_r_chart(data_shift)
# WE 规则检测(对漂移数据)
violations = detect_we_rules(xbar_s, xbb_s, ucl_xs, lcl_xs)
# 过程能力(正常数据)
flat_normal = data_normal.flatten()
lsl, usl = 44.0, 56.0
mu_c, sigma_c, cp, cpk = process_capability(flat_normal, lsl, usl)
# ── 画布布局 ──────────────────────────────────────────
fig = plt.figure(figsize=(18, 14))
fig.suptitle('Statistical Process Control (SPC) --- Core Concepts Dashboard',
fontsize=16, fontweight='bold', y=0.98, color='#2C3E50')
gs = GridSpec(3, 2, figure=fig, hspace=0.45, wspace=0.35)
ax1 = fig.add_subplot(gs[0, 0]) # X̄ 图(正常)
ax2 = fig.add_subplot(gs[1, 0]) # R 图(正常)
ax3 = fig.add_subplot(gs[0, 1]) # X̄ 图(漂移 + WE)
ax4 = fig.add_subplot(gs[1, 1]) # R 图(漂移)
ax5 = fig.add_subplot(gs[2, 0]) # 过程能力
ax6 = fig.add_subplot(gs[2, 1]) # Cp/Cpk 对比条形图
subgroups = np.arange(1, 31)
COLOR_LINE = '#2980B9'
COLOR_UCL = '#E74C3C'
COLOR_LCL = '#E74C3C'
COLOR_CL = '#27AE60'
COLOR_VIOL = '#E74C3C'
COLOR_NORMAL = '#2980B9'
COLOR_WARN = '#F39C12'
def draw_control_chart(ax, values, cl, ucl, lcl, title,
ylabel, violations=None, sigma=None):
ax.set_title(title, fontsize=11, fontweight='bold', color='#2C3E50', pad=8)
# 控制区域着色
if sigma:
ax.axhspan(cl - sigma, cl + sigma, alpha=0.06, color='green')
ax.axhspan(cl + sigma, cl + 2*sigma, alpha=0.06, color='yellow')
ax.axhspan(cl - 2*sigma, cl - sigma, alpha=0.06, color='yellow')
ax.axhspan(cl + 2*sigma, ucl, alpha=0.06, color='red')
ax.axhspan(lcl, cl - 2*sigma, alpha=0.06, color='red')
ax.axhline(ucl, color=COLOR_UCL, linewidth=1.5, linestyle='--', label=f'UCL={ucl:.2f}')
ax.axhline(cl, color=COLOR_CL, linewidth=1.5, linestyle='-', label=f'CL={cl:.2f}')
ax.axhline(lcl, color=COLOR_LCL, linewidth=1.5, linestyle='--', label=f'LCL={lcl:.2f}')
# 折线
ax.plot(subgroups, values, color=COLOR_LINE, linewidth=1.2,
marker='o', markersize=4, zorder=3)
# 标记违规点
if violations:
for i, viols in enumerate(violations):
if viols:
color = COLOR_VIOL if 1 in viols else COLOR_WARN
ax.plot(subgroups[i], values[i], 'o',
color=color, markersize=9, zorder=4,
markeredgecolor='white', markeredgewidth=1.5)
rule_str = ','.join(f'R{r}' for r in viols)
ax.annotate(rule_str,
xy=(subgroups[i], values[i]),
xytext=(4, 6), textcoords='offset points',
fontsize=7, color=color, fontweight='bold')
ax.set_xlabel('Subgroup', fontsize=9)
ax.set_ylabel(ylabel, fontsize=9)
ax.legend(fontsize=8, loc='upper left', framealpha=0.7)
ax.set_xlim(0, 31)
# ── 图1:X̄ 图(正常过程)────────────────────────────
draw_control_chart(ax1, xbar_n, xbb_n, ucl_xn, lcl_xn,
'① X̄ Chart --- In-Control Process',
'Subgroup Mean', sigma=(ucl_xn - xbb_n)/3)
# ── 图2:R 图(正常过程)────────────────────────────
draw_control_chart(ax2, R_n, rb_n, ucl_rn, lcl_rn,
'② R Chart --- In-Control Process', 'Range')
# ── 图3:X̄ 图(漂移 + WE 判异)──────────────────────
draw_control_chart(ax3, xbar_s, xbb_s, ucl_xs, lcl_xs,
'③ X̄ Chart --- Process Shift + WE Rules',
'Subgroup Mean', violations=violations,
sigma=(ucl_xs - xbb_s)/3)
ax3.axvline(22.5, color='purple', linewidth=1.5, linestyle=':', alpha=0.7)
ax3.text(23, xbb_s + (ucl_xs - xbb_s)*0.6, 'Shift\nPoint',
color='purple', fontsize=8, ha='left')
# ── 图4:R 图(漂移过程)────────────────────────────
draw_control_chart(ax4, R_s, rb_s, ucl_rs, lcl_rs,
'④ R Chart --- Process Shift', 'Range')
# ── 图5:过程能力分析 ────────────────────────────────
ax5.set_title('⑤ Process Capability Analysis', fontsize=11,
fontweight='bold', color='#2C3E50', pad=8)
x_range = np.linspace(mu_c - 5*sigma_c, mu_c + 5*sigma_c, 500)
y_norm = stats.norm.pdf(x_range, mu_c, sigma_c)
# 规格外区域填充
x_below = x_range[x_range < lsl]
x_above = x_range[x_range > usl]
ax5.fill_between(x_below, stats.norm.pdf(x_below, mu_c, sigma_c),
alpha=0.5, color='#E74C3C', label='Out of Spec')
ax5.fill_between(x_above, stats.norm.pdf(x_above, mu_c, sigma_c),
alpha=0.5, color='#E74C3C')
ax5.fill_between(x_range[(x_range >= lsl) & (x_range <= usl)],
stats.norm.pdf(x_range[(x_range >= lsl) & (x_range <= usl)],
mu_c, sigma_c),
alpha=0.3, color='#27AE60', label='Within Spec')
ax5.plot(x_range, y_norm, color='#2C3E50', linewidth=2)
ax5.axvline(lsl, color='#E74C3C', linewidth=2, linestyle='--', label=f'LSL={lsl}')
ax5.axvline(usl, color='#E74C3C', linewidth=2, linestyle='--', label=f'USL={usl}')
ax5.axvline(mu_c, color='#2980B9', linewidth=2, linestyle='-', label=f'μ={mu_c:.2f}')
# 标注 ±3σ
for k, ls in [(1,'dotted'), (2,'dashdot'), (3,'dashed')]:
ax5.axvline(mu_c + k*sigma_c, color='gray', linewidth=0.8, linestyle=ls, alpha=0.6)
ax5.axvline(mu_c - k*sigma_c, color='gray', linewidth=0.8, linestyle=ls, alpha=0.6)
ax5.text(mu_c + k*sigma_c, max(y_norm)*0.05, f'+{k}σ',
ha='center', fontsize=7, color='gray')
ax5.text(mu_c - k*sigma_c, max(y_norm)*0.05, f'-{k}σ',
ha='center', fontsize=7, color='gray')
textstr = f'Cp = {cp:.3f}\nCpk = {cpk:.3f}\nμ = {mu_c:.2f}\nσ = {sigma_c:.3f}'
props = dict(boxstyle='round,pad=0.5', facecolor='#EBF5FB', alpha=0.8, edgecolor='#2980B9')
ax5.text(0.02, 0.97, textstr, transform=ax5.transAxes,
fontsize=9, verticalalignment='top', bbox=props, family='monospace')
ax5.set_xlabel('Measurement Value', fontsize=9)
ax5.set_ylabel('Probability Density', fontsize=9)
ax5.legend(fontsize=8, loc='upper right', framealpha=0.7)
# ── 图6:多场景 Cp/Cpk 对比 ──────────────────────────
ax6.set_title('⑥ Cp vs Cpk --- Scenario Comparison', fontsize=11,
fontweight='bold', color='#2C3E50', pad=8)
scenarios = ['Centered\n(Good)', 'Off-Center\n(Moderate)', 'Off-Center\n(Poor)', 'Six Sigma']
cp_vals = [1.50, 1.50, 1.50, 2.00]
cpk_vals = [1.50, 1.20, 0.80, 2.00]
x_pos = np.arange(len(scenarios))
width = 0.35
bars1 = ax6.bar(x_pos - width/2, cp_vals, width, label='Cp',
color='#3498DB', alpha=0.85, edgecolor='white', linewidth=1.2)
bars2 = ax6.bar(x_pos + width/2, cpk_vals, width, label='Cpk',
color='#E67E22', alpha=0.85, edgecolor='white', linewidth=1.2)
# 参考线
ax6.axhline(1.33, color='#E74C3C', linewidth=1.5, linestyle='--',
label='Minimum (1.33)', alpha=0.8)
ax6.axhline(1.00, color='#F39C12', linewidth=1.2, linestyle=':',
label='Borderline (1.00)', alpha=0.8)
for bar in bars1:
ax6.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.03,
f'{bar.get_height():.2f}', ha='center', va='bottom', fontsize=8, fontweight='bold')
for bar in bars2:
color = '#E74C3C' if bar.get_height() < 1.33 else '#27AE60'
ax6.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.03,
f'{bar.get_height():.2f}', ha='center', va='bottom',
fontsize=8, fontweight='bold', color=color)
ax6.set_xticks(x_pos)
ax6.set_xticklabels(scenarios, fontsize=9)
ax6.set_ylabel('Capability Index', fontsize=9)
ax6.set_ylim(0, 2.4)
ax6.legend(fontsize=8, loc='upper right', framealpha=0.7)
plt.savefig('spc_dashboard.png', dpi=150, bbox_inches='tight',
facecolor='#FAFAFA')
plt.show()
print("✅ 图表已保存为 spc_dashboard.png")
# ══════════════════════════════════════════════════════════
# 运行
# ══════════════════════════════════════════════════════════
plot_spc_dashboard()运行上面的代码,你会得到一张包含六个子图的完整仪表盘:
| 子图编号 | 内容 | 核心展示 |
|---|---|---|
| ① | X̄ 图(受控过程) | 正常波动,所有点在控制限内 |
| ② | R 图(受控过程) | 极差稳定,过程一致性良好 |
| ③ | X̄ 图(均值漂移 + WE规则) | 漂移点被 R1/R2 规则标红 |
| ④ | R 图(漂移过程) | 漂移后极差变化情况 |
| ⑤ | 过程能力分析 | 正态分布与规格限的关系,Cp/Cpk 值 |
| ⑥ | Cp vs Cpk 场景对比 | 对中 vs 偏移对能力指数的影响 |
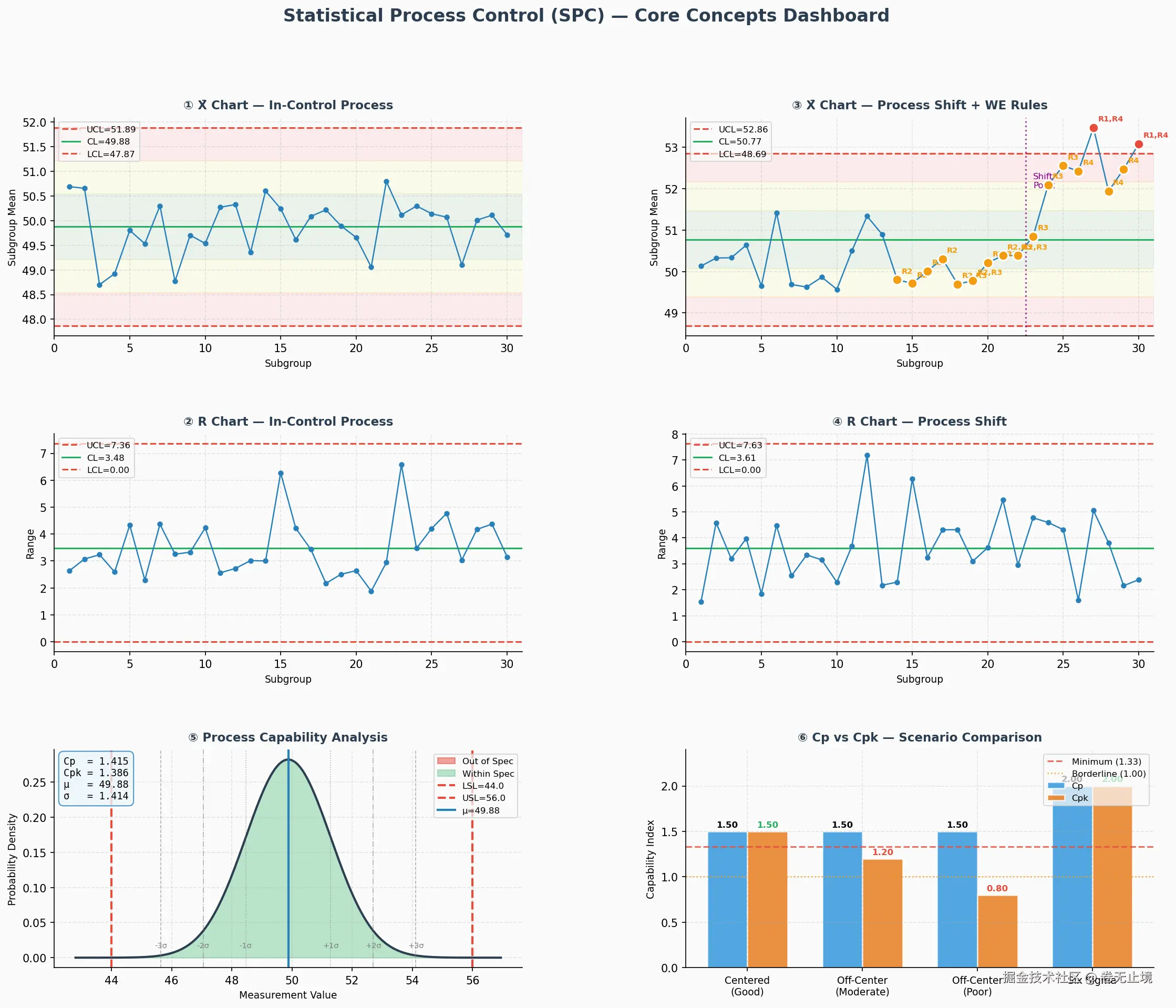
四、读懂图表背后的逻辑
图③是整张仪表盘最值得细看的部分。第22组之后,均值发生了约 2.5σ 的漂移,肉眼看折线似乎还"差不多",但 WE 规则已经开始报警------这正是统计方法的价值所在:人眼容易被"差不多"欺骗,统计规则不会。
图⑥揭示了一个常被忽视的陷阱: Cp 高不代表 Cpk 高。一个过程可以"潜力很大"( Cp=1.5)但因为均值严重偏移,实际能力( Cpk=0.8)完全不合格。这就像一台精度极高的机床,却被安装歪了------能力在那里,但没用对地方。
五、SQC 的现实温度
SPC 不是万能药。它的前提是过程数据服从(近似)正态分布,且子组内变异只来自普通原因。现实中,很多过程是非正态的、有自相关的,这时需要用变换方法或更复杂的控制图(如 EWMA、CUSUM)。
但无论工具如何演进,SQC 的底层哲学始终未变:用数据代替直觉,用预防代替救火。在一个充斥着"感觉差不多"的世界里,这种对数字的执念,反而是最朴素的工程师精神。
参考资料:Montgomery, D.C. --- Introduction to Statistical Quality Control;Wheeler & Chambers --- Understanding Statistical Process Control;AIAG --- Statistical Process Control Reference Manual