你的Agent调了10次工具,7次参数格式错误。
不是夸张。这是我亲眼见过的生产事故:一个数据分析Agent,连续3天在凌晨批量任务里静默失败,原因不是LLM"笨",而是工具描述里一个参数的enum值从"ASC"改成了"asc",LLM还在按旧描述传参,API直接400。
Tool Calling是Agent伸向外部世界的"手"。这只手如果没训练好,Agent就是个只会想不会做的空壳------而且你会在最意想不到的地方断掉。
这篇文章讲四件事:协议差异的坑与MCP的统一之路、Structured Output的质变、工具描述的艺术、工具编排的模式和防御。每一个都是我在生产环境踩过的。
1. Function Calling协议真相:从三家混战到MCP统一
三家格式,三种痛苦
你以为Function Calling是标准化的?天真。
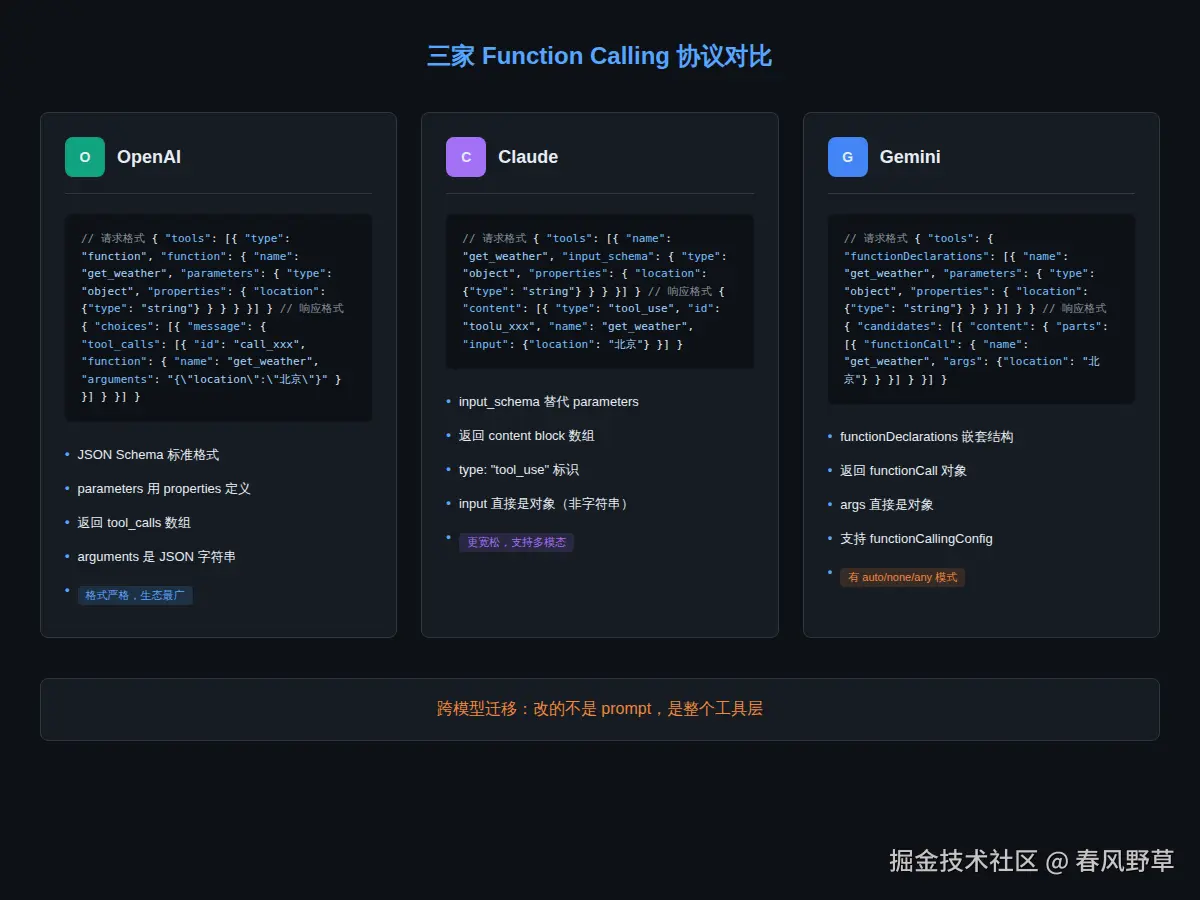
OpenAI、Anthropic、Google三家,Function Calling的协议格式各不相同。不是"大同小异",是"根本性差异"。当你想从OpenAI迁移到Claude,或者想做一个跨模型兼容的Agent框架时,这些差异会咬你。
 (见配图0:三家Function Calling协议差异对比)
(见配图0:三家Function Calling协议差异对比)
OpenAI:JSON Schema风格
python
# OpenAI Function Calling 格式
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,如'北京'、'上海'"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位"
}
},
"required": ["city"]
}
}
}]
# LLM返回的tool_call
# {
# "id": "call_abc123",
# "type": "function",
# "function": {
# "name": "get_weather",
# "arguments": "{\"city\": \"北京\", \"unit\": \"celsius\"}"
# }
# }注意:arguments是一个JSON字符串 ,不是JSON对象。这是第一个坑------你得json.loads()解析它,而LLM偶尔会返回格式错误的JSON。
Anthropic:JSON风格(已统一)
Claude早期用XML格式返回工具调用,这是很多人对Claude的旧印象。现在Claude已经全面切换到JSON格式,和OpenAI的差异大幅缩小:
python
# Anthropic tool 定义格式
tools = [{
"name": "get_weather",
"description": "获取指定城市的天气信息",
"input_schema": { # 注意:不是 parameters,是 input_schema
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["city"]
}
}]
# Claude返回的tool_use block
# content: [
# {
# "type": "tool_use",
# "id": "toolu_abc123",
# "name": "get_weather",
# "input": {"city": "北京", "unit": "celsius"} # 注意:这里是dict,不是字符串
# }
# ]关键差异:
| 差异点 | OpenAI | Claude | Gemini |
|---|---|---|---|
| 工具定义字段 | function.parameters |
input_schema |
parameters(proto) |
| 参数类型系统 | JSON Schema string | JSON Schema string | Proto enum |
| LLM返回格式 | JSON字符串 | dict对象 | Proto结构 |
| 多工具调用 | tool_calls数组 |
tool_use content blocks |
重复function_call |
| 工具结果回传 | tool role message |
tool_result content block |
function_response part |
| 并行调用支持 | ✅ 原生 | ✅ 原生 | ⚠️ 有限 |
| 强制调用某工具 | tool_choice: {function: name} |
tool_choice: {type: "tool", name: name} |
function_calling_config |
好消息:Claude现在支持parallel tool calling,之前最大的短板已经补齐。三家的并行调用基本对齐。
解法:MCP协议
Anthropic发布**MCP(Model Context Protocol)**后,它已成为Agent工具调用的事实标准。
MCP解决的核心问题:工具定义和调用协议的碎片化。
没有MCP之前,每个Agent框架都要写自己的工具适配层------OpenAI格式、Claude格式、Gemini格式各写一套。有了MCP之后:
scss
┌─────────────┐ MCP协议 ┌─────────────┐
│ Agent/LLM │ ←──────────────→ │ MCP Server │
│ (任何模型) │ 标准化JSON-RPC │ (工具提供方) │
└─────────────┘ └─────────────┘MCP的核心设计:
- Server端 :工具提供方实现一个MCP Server,暴露
tools/list和tools/call两个标准接口 - Client端:Agent框架通过MCP Client连接Server,获取工具列表、调用工具
- 协议层:JSON-RPC 2.0,传输层支持stdio和HTTP+SSE
一个最简MCP Server:
python
from mcp.server import Server
from mcp.types import Tool, TextContent
server = Server("weather-server")
@server.list_tools()
async def list_tools() -> list[Tool]:
return [
Tool(
name="get_weather",
description="获取指定城市的天气信息",
inputSchema={
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
)
]
@server.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
if name == "get_weather":
city = arguments["city"]
# 实际调用天气API
result = await fetch_weather(city)
return [TextContent(type="text", text=f"{city}:25°C,晴")]
raise ValueError(f"Unknown tool: {name}")MCP为什么重要:
- 写一次,到处用:一个MCP Server可以被Claude、GPT-5.1、Gemini任何模型调用,不需要写三套适配
- 生态爆发:已有数百个开源MCP Server------GitHub、Slack、数据库、文件系统、浏览器......你不需要自己写工具,直接用
- Claude原生支持:Claude Desktop和Claude API直接支持MCP,不需要中间层
- OpenAI跟进:OpenAI也已支持MCP协议
但MCP不是银弹:
- 性能开销:MCP Server是独立进程,通过stdio/HTTP通信,比直接函数调用慢
- 调试复杂:Server进程崩溃、通信超时、JSON-RPC错误------多了一层故障点
- 不是所有场景都适合:如果你的Agent只用3-5个内部工具,直接function calling更简单。MCP适合工具多、需要跨Agent共享工具的场景
跨模型迁移的真实代价
我做过一个项目:从OpenAI迁移到Claude,预计1天搞定,实际花了5天。
但现在做同样的迁移,时间缩短到1天------因为:
- Claude格式已统一为JSON,不再需要XML解析
- Claude支持parallel tool calling,不需要改串行逻辑
- MCP协议让工具定义可以复用
可运行的适配层代码:
python
from abc import ABC, abstractmethod
from dataclasses import dataclass
import json
@dataclass
class ToolCall:
"""统一的工具调用表示"""
id: str
name: str
arguments: dict # 统一为dict,不是JSON字符串
@dataclass
class ToolResult:
"""统一的工具结果表示"""
call_id: str
name: str
output: str
is_error: bool = False
class ToolCallAdapter(ABC):
"""工具调用适配器------抹平三家API差异"""
@abstractmethod
def parse_tool_calls(self, response) -> list[ToolCall]:
"""从LLM响应中提取工具调用"""
pass
@abstractmethod
def format_tool_result(self, result: ToolResult) -> dict:
"""将工具结果格式化为LLM需要的格式"""
pass
@abstractmethod
def format_tool_definitions(self, tools: list[dict]) -> list[dict]:
"""将统一格式的工具定义转为各家格式"""
pass
class OpenAIAdapter(ToolCallAdapter):
def parse_tool_calls(self, response) -> list[ToolCall]:
calls = []
for tc in response.choices[0].message.tool_calls:
try:
args = json.loads(tc.function.arguments)
except json.JSONDecodeError:
args = {"_raw": tc.function.arguments, "_parse_error": True}
calls.append(ToolCall(
id=tc.id,
name=tc.function.name,
arguments=args
))
return calls
def format_tool_result(self, result: ToolResult) -> dict:
return {
"role": "tool",
"tool_call_id": result.call_id,
"content": result.output
}
def format_tool_definitions(self, tools: list[dict]) -> list[dict]:
return [{
"type": "function",
"function": {
"name": t["name"],
"description": t["description"],
"parameters": t["input_schema"]
}
} for t in tools]
class ClaudeAdapter(ToolCallAdapter):
def parse_tool_calls(self, response) -> list[ToolCall]:
calls = []
for block in response.content:
if block.type == "tool_use":
calls.append(ToolCall(
id=block.id,
name=block.name,
arguments=block.input # 直接是dict
))
return calls
def format_tool_result(self, result: ToolResult) -> dict:
return {
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": result.call_id,
"content": result.output,
"is_error": result.is_error
}]
}
def format_tool_definitions(self, tools: list[dict]) -> list[dict]:
return [{
"name": t["name"],
"description": t["description"],
"input_schema": t["input_schema"]
} for t in tools]
def create_adapter(provider: str) -> ToolCallAdapter:
adapters = {
"openai": OpenAIAdapter,
"claude": ClaudeAdapter,
}
if provider not in adapters:
raise ValueError(f"Unsupported provider: {provider}")
return adapters[provider]()建议:
- 新项目:直接用MCP。工具定义写一次,所有模型通用
- 老项目迁移:先写适配层,再逐步迁移到MCP
- 纯内部工具:如果工具不超过5个且不跨Agent共享,直接function calling更简单
2. Structured Output:最大的质变
Agent开发者最头疼的问题之一:LLM返回的JSON格式不稳定 。你让它返回{"name": "张三", "age": 25},它可能返回{"name": "张三", "age": "25"}------age从数字变成了字符串。
这个问题已经被Structured Output解决。
什么是Structured Output
Structured Output让LLM严格按你定义的JSON Schema输出 ,不是"尽量遵守",是"100%遵守"。如果Schema说age是integer,LLM就不可能返回string。
OpenAI的实现(GPT-5.1原生支持):
python
from openai import OpenAI
from pydantic import BaseModel
class UserInfo(BaseModel):
name: str
age: int
email: str
client = OpenAI()
response = client.responses.parse(
model="gpt-5.1",
input=[{"role": "user", "content": "张三,28岁,邮箱zhangsan@example.com"}],
text_format=UserInfo, # 直接传Pydantic模型
)
user = response.output_parsed
print(user.name) # "张三"
print(user.age) # 28 (int,不是"28")
print(user.email) # "zhangsan@example.com"Claude的实现(Sonnet 4.6/Opus 4.8支持):
python
import anthropic
from pydantic import BaseModel
class UserInfo(BaseModel):
name: str
age: int
email: str
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-6-20250514",
max_tokens=1024,
tools=[{
"name": "structured_output",
"description": "输出结构化用户信息",
"input_schema": UserInfo.model_json_schema()
}],
tool_choice={"type": "tool", "name": "structured_output"},
messages=[{"role": "user", "content": "张三,28岁,邮箱zhangsan@example.com"}]
)Structured Output对Agent的影响
这不是一个小改进,是质变:
-
工具参数100%格式正确 :之前LLM偶尔返回格式错误的JSON,你需要
json.loads()+try-catch+fallback。现在不需要了。 -
输出解析从"正则匹配"变成"类型安全":之前你用正则从LLM输出中提取结构化信息,现在直接用Pydantic模型接收。
-
多步Agent的可靠性飞跃:Agent的每一步输出都是结构化的,下一步的输入就有保证。整个链条的可靠性从"每步95%"变成"每步99.9%"。
一个真实的对比:
某Agent需要5步工具调用,每步都需要解析上一步的JSON输出。
| 方案 | 单步成功率 | 5步链路成功率 |
|---|---|---|
| 无Structured Output | 95% | 77% (0.95^5) |
| 有Structured Output | 99.9% | 99.5% (0.999^5) |
链路越长,Structured Output的价值越大。
什么时候用Structured Output,什么时候用Function Calling
两者不冲突,但适用场景不同:
| 场景 | 推荐方式 | 理由 |
|---|---|---|
| 调用外部工具/API | Function Calling | 需要执行动作,不只是生成数据 |
| 生成结构化数据 | Structured Output | 不需要执行,只需要格式正确 |
| Agent中间步骤输出 | Structured Output | 保证下一步输入格式正确 |
| 用户意图解析 | Structured Output | 把自然语言转成结构化意图 |
最佳实践:Agent的"思考"用Structured Output保证格式,"行动"用Function Calling执行工具。
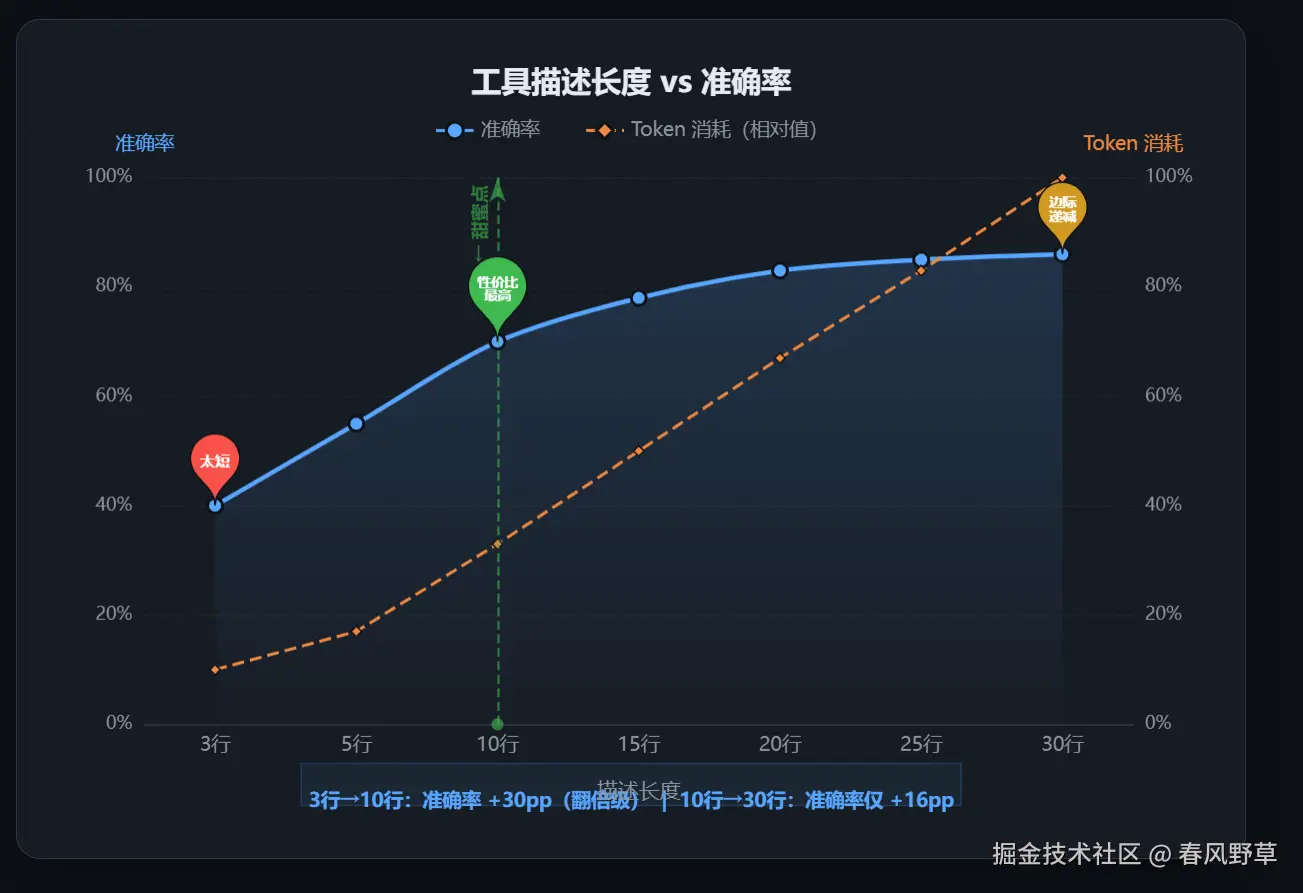
3. 工具描述的艺术:3行描述准确率40%,30行描述准确率85%
工具描述是LLM理解工具的唯一信息源。写得好,LLM精准调用;写得差,LLM瞎猜参数。
这不是理论------我做过实测。
 (见配图1:工具描述长度vs准确率曲线)
(见配图1:工具描述长度vs准确率曲线)
实测数据
我用同一个工具(查询数据库),不同长度的描述,测了100次调用准确率:
3行描述(准确率42%):
python
{
"name": "query_database",
"description": "查询数据库",
"input_schema": {
"type": "object",
"properties": {
"sql": {"type": "string"},
"limit": {"type": "integer"}
},
"required": ["sql"]
}
}LLM的典型错误:
- 传了
"SELECT * FROM users"(没有limit,返回10万行) - 传了
"sql": "查一下最近的订单"(自然语言当SQL) - 没传
limit,导致超时
10行描述(准确率68%):
python
{
"name": "query_database",
"description": "执行SQL查询并返回结果。仅支持SELECT语句,不支持INSERT/UPDATE/DELETE。查询结果默认限制100行。",
"input_schema": {
"type": "object",
"properties": {
"sql": {
"type": "string",
"description": "要执行的SQL SELECT语句。必须是合法SQL,不支持自然语言。"
},
"limit": {
"type": "integer",
"description": "返回结果的最大行数,默认100。建议不超过1000。"
}
},
"required": ["sql"]
}
}错误减少,但仍有问题:
- 传了
"sql": "SELECT * FROM orders WHERE date > '2024-01-01'"(没考虑时区) - 传了
"limit": 999999("建议不超过1000"只是建议,LLM不一定遵守)
30行描述(准确率85%):
python
{
"name": "query_database",
"description": """执行只读SQL查询,返回结果集。
支持的操作:仅SELECT语句。
禁止的操作:INSERT、UPDATE、DELETE、DROP、ALTER、CREATE。
注意事项:
1. SQL必须是标准SQL语法,不支持自然语言查询
2. 日期格式统一使用 'YYYY-MM-DD',时区为UTC
3. 表名和列名区分大小写,请参考schema信息
4. 大表查询务必使用WHERE条件过滤,避免全表扫描
5. limit参数硬性上限为1000,超过会被截断
6. 查询超时时间为30秒,复杂查询请优化SQL
7. 返回结果为JSON数组,每行一个对象
8. 如果查询失败,会返回error字段和错误信息""",
"input_schema": {
"type": "object",
"properties": {
"sql": {
"type": "string",
"description": "合法的SQL SELECT语句。禁止DDL和DML操作。日期用'YYYY-MM-DD'格式,时区UTC。"
},
"limit": {
"type": "integer",
"description": "结果行数上限。范围1-1000,默认100。超过1000的值会被自动截断为1000。",
"minimum": 1,
"maximum": 1000,
"default": 100
}
},
"required": ["sql"]
}
}50行描述(准确率86%)------边际收益几乎为零,但token消耗增加了67%。
描述的黄金法则
从3行到30行,准确率从42%跳到85%。从30行到50行,只涨了1%。这说明存在一个甜点区。
5条黄金法则:
-
说清楚"做什么"和"不做什么" :LLM不知道边界在哪,除非你明确告诉它。
"仅支持SELECT"比"支持SELECT"更有效。 -
给参数加约束,不要只加描述 :
"minimum": 1, "maximum": 1000比"建议不超过1000"有效10倍。JSON Schema的约束是硬约束,描述里的"建议"是软约束。 -
给反面示例 :
"不支持自然语言查询,如'查一下最近的订单'是无效输入"比"必须是合法SQL"更清晰。 -
说清楚错误行为 :
"超过1000的值会被自动截断为1000"让LLM知道边界在哪,不会试探。 -
控制总长度在15-30行:太短信息不足,太长浪费token且LLM可能忽略关键信息。
法则 :用Structured Output替代描述约束 。之前你需要在描述里写"age必须是整数",现在直接在JSON Schema里定义"type": "integer",LLM 100%遵守。描述只需要关注"语义",不需要关注"格式"。
可运行的描述优化工具:
python
from pydantic import BaseModel, Field
import json
class QueryDatabaseInput(BaseModel):
"""用Pydantic模型生成高质量工具描述"""
sql: str = Field(
...,
description="合法的SQL SELECT语句。禁止DDL和DML操作。日期用'YYYY-MM-DD'格式,时区UTC。",
min_length=10,
)
limit: int = Field(
default=100,
description="结果行数上限。范围1-1000,超过1000自动截断。",
ge=1,
le=1000,
)
def pydantic_to_tool_schema(model: type[BaseModel], description: str) -> dict:
"""将Pydantic模型转为统一的工具描述格式"""
schema = model.model_json_schema()
schema.pop("title", None)
for prop in schema.get("properties", {}).values():
prop.pop("title", None)
return {
"name": model.__name__.replace("Input", "").lower(),
"description": description,
"input_schema": schema
}
# 使用
tool_def = pydantic_to_tool_schema(
QueryDatabaseInput,
description="执行只读SQL查询,返回结果集。仅支持SELECT,禁止DDL/DML。limit上限1000,超时30秒。"
)
print(json.dumps(tool_def, indent=2, ensure_ascii=False))用Pydantic的好处:约束是代码的一部分,不是注释 。ge=1, le=1000既生成JSON Schema约束,又在运行时校验参数------双重保险。
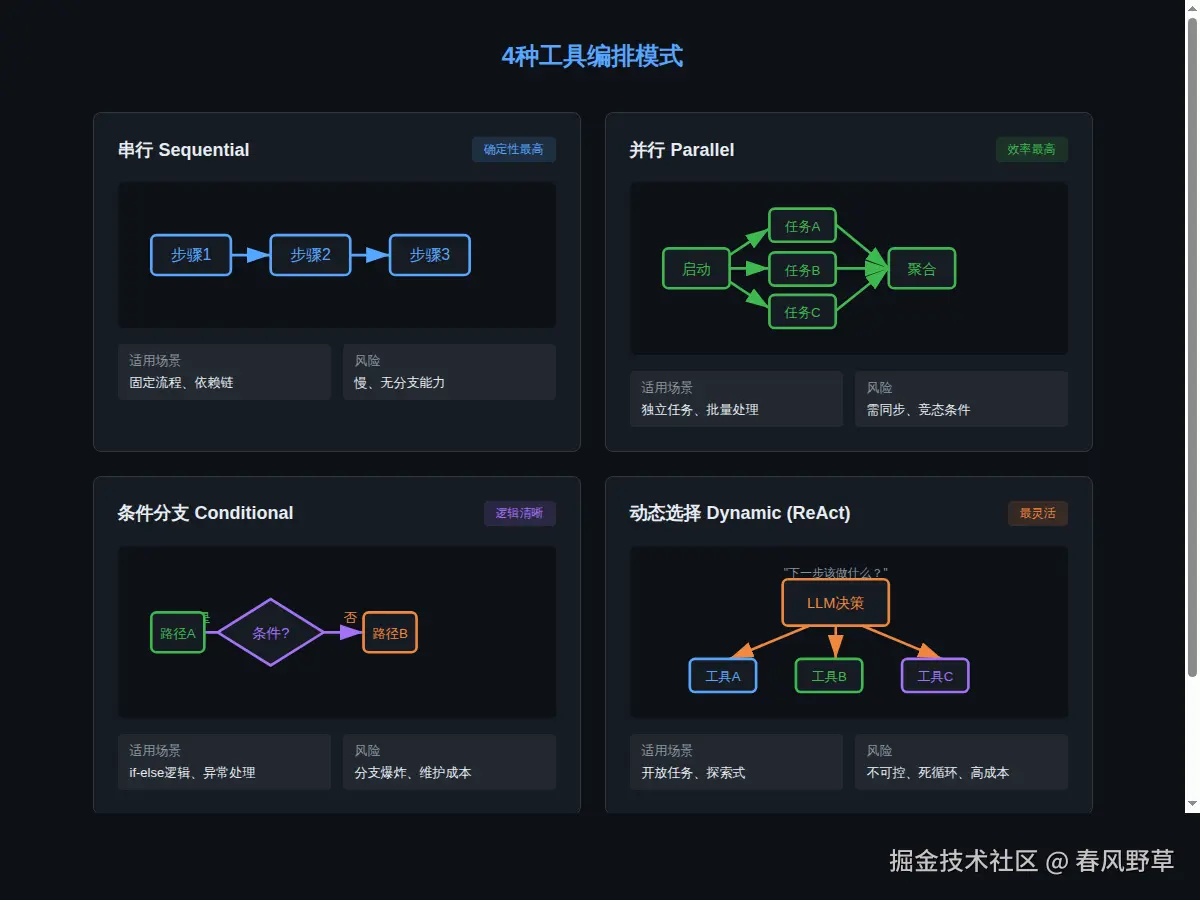
4. 工具编排4种模式:串行/并行/条件分支/动态选择
工具不是调一次就完事。真实场景中,Agent需要编排多个工具的调用顺序、依赖关系和错误处理。
 (见配图2:4种工具编排模式流程图)
(见配图2:4种工具编排模式流程图)
模式1:串行编排(Sequential)
适用场景:步骤之间有严格依赖------上一步的输出是下一步的输入。
python
import asyncio
from dataclasses import dataclass
@dataclass
class ToolOutput:
success: bool
data: dict
error: str | None = None
async def sequential_orchestration(query: str) -> dict:
"""串行编排:查用户→查订单→查物流"""
# Step 1: 查用户ID
user_result = await call_tool("search_user", {"query": query})
if not user_result.success:
return {"error": f"用户查询失败: {user_result.error}"}
user_id = user_result.data["user_id"]
# Step 2: 查用户订单(依赖Step 1的user_id)
order_result = await call_tool("get_orders", {"user_id": user_id})
if not order_result.success:
return {"error": f"订单查询失败: {order_result.error}"}
order_id = order_result.data["latest_order_id"]
# Step 3: 查物流信息(依赖Step 2的order_id)
tracking_result = await call_tool("get_tracking", {"order_id": order_id})
if not tracking_result.success:
return {"error": f"物流查询失败: {tracking_result.error}"}
return {
"user": user_result.data,
"order": order_result.data,
"tracking": tracking_result.data
}
async def call_tool(name: str, args: dict) -> ToolOutput:
"""模拟工具调用------生产环境替换为真实实现"""
print(f" 🔧 调用工具: {name}({args})")
await asyncio.sleep(0.1)
return ToolOutput(success=True, data={"mock": True, **args})坑:串行编排的延迟是累加的。3个工具各200ms,总延迟600ms+。如果步骤之间没有依赖,不要串行。
模式2:并行编排(Parallel)
适用场景:步骤之间无依赖,可以同时执行。
python
async def parallel_orchestration(user_id: str) -> dict:
"""并行编排:同时查用户资料、订单、积分"""
tasks = [
call_tool("get_user_profile", {"user_id": user_id}),
call_tool("get_orders", {"user_id": user_id}),
call_tool("get_points", {"user_id": user_id}),
]
results = await asyncio.gather(*tasks, return_exceptions=True)
output = {}
for i, (task_name, result) in enumerate(zip(
["profile", "orders", "points"], results
)):
if isinstance(result, Exception):
output[task_name] = {"error": str(result), "available": False}
elif not result.success:
output[task_name] = {"error": result.error, "available": False}
else:
output[task_name] = {**result.data, "available": True}
return output坑 :并行调用要控制并发数。10个工具同时调用可能打爆下游API。用asyncio.Semaphore限流:
python
CONCURRENCY_LIMIT = 3
semaphore = asyncio.Semaphore(CONCURRENCY_LIMIT)
async def call_tool_with_limit(name: str, args: dict) -> ToolOutput:
async with semaphore:
return await call_tool(name, args)
async def parallel_with_limit(user_id: str) -> dict:
tasks = [
call_tool_with_limit("get_user_profile", {"user_id": user_id}),
call_tool_with_limit("get_orders", {"user_id": user_id}),
call_tool_with_limit("get_points", {"user_id": user_id}),
call_tool_with_limit("get_coupons", {"user_id": user_id}),
call_tool_with_limit("get_addresses", {"user_id": user_id}),
]
results = await asyncio.gather(*tasks, return_exceptions=True)
return results模式3:条件分支编排(Conditional)
适用场景:根据上一步的结果决定下一步走哪条路。
python
async def conditional_orchestration(query: str) -> dict:
"""条件分支:根据用户类型走不同路径"""
user_result = await call_tool("get_user", {"query": query})
if not user_result.success:
return {"error": "用户查询失败"}
user = user_result.data
user_type = user.get("type", "normal")
if user_type == "vip":
vip_tasks = [
call_tool("get_vip_benefits", {"user_id": user["id"]}),
call_tool("get_vip_agent", {"vip_level": user["vip_level"]}),
]
vip_results = await asyncio.gather(*vip_tasks)
return {
"user": user,
"benefits": vip_results[0].data,
"agent": vip_results[1].data,
"path": "vip"
}
elif user_type == "enterprise":
contract_result = await call_tool("get_enterprise_contract", {
"company_id": user["company_id"]
})
return {
"user": user,
"contract": contract_result.data,
"path": "enterprise"
}
else:
normal_tasks = [
call_tool("get_orders", {"user_id": user["id"]}),
call_tool("get_recommendations", {"user_id": user["id"]}),
]
normal_results = await asyncio.gather(*normal_tasks)
return {
"user": user,
"orders": normal_results[0].data,
"recommendations": normal_results[1].data,
"path": "normal"
}坑:条件分支容易变成"意大利面条代码"。分支超过3层时,考虑用状态机或策略模式重构。
模式4:动态选择编排(Dynamic)
适用场景:LLM根据上下文自主决定调哪个工具、调几次。这是真正的Agent模式。
python
from typing import Any
class DynamicOrchestrator:
"""动态编排:LLM自主决定工具调用序列"""
def __init__(self, llm_client, tools: dict, max_steps: int = 10):
self.llm = llm_client
self.tools = tools
self.max_steps = max_steps
async def run(self, query: str) -> dict:
messages = [{"role": "user", "content": query}]
tool_defs = self._build_tool_definitions()
step = 0
final_answer = None
while step < self.max_steps:
step += 1
response = await self.llm.complete(messages, tools=tool_defs)
if not response.tool_calls:
final_answer = response.content
break
for tool_call in response.tool_calls:
tool_name = tool_call.name
tool_args = tool_call.arguments
print(f" Step {step}: 调用 {tool_name}({tool_args})")
if tool_name not in self.tools:
tool_result = f"错误:未知工具 '{tool_name}'"
else:
try:
tool_result = await self.tools[tool_name](**tool_args)
except Exception as e:
tool_result = f"工具执行错误: {type(e).__name__}: {e}"
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(tool_result)
})
if final_answer is None:
final_answer = "达到最大步数限制,未能完成任务。"
return {
"answer": final_answer,
"steps": step,
"truncated": step >= self.max_steps
}
def _build_tool_definitions(self) -> list[dict]:
return [
{"name": name, "description": func.__doc__ or name, "input_schema": {}}
for name, func in self.tools.items()
]坑 :动态编排最大的风险是失控 ------LLM可能死循环、调无关工具、反复调同一个工具。max_steps是必须的兜底,但不够。后面讲防御性编程。
4种模式的选择指南
| 模式 | 适用场景 | 延迟 | 可控性 | 复杂度 |
|---|---|---|---|---|
| 串行 | 步骤有严格依赖 | 高(累加) | 高 | 低 |
| 并行 | 步骤无依赖 | 低(取最长) | 高 | 低 |
| 条件分支 | 路径依赖上一步结果 | 中 | 中 | 中 |
| 动态选择 | 路径需LLM运行时决定 | 不确定 | 低 | 高 |
原则:能用串行/并行就不用条件分支,能用条件分支就不用动态选择。每多一层"智能",就多一层不可控。
5. 防御性编程:工具失败时Agent不能崩溃
工具调用会失败。API会超时、服务会宕机、参数会错误、权限会不足。
如果你的Agent在工具失败时就崩溃或返回错误,那它不是Agent,是一个脆弱的API调用链。
5.1 重试策略:不是所有错误都值得重试
python
import asyncio
import time
from enum import Enum
from functools import wraps
class RetryCategory(Enum):
TRANSIENT = "transient" # 暂时性错误,值得重试
PERMANENT = "permanent" # 永久性错误,不值得重试
UNKNOWN = "unknown" # 未知错误,保守重试一次
def classify_error(error: Exception) -> RetryCategory:
if isinstance(error, (asyncio.TimeoutError, ConnectionError, OSError)):
return RetryCategory.TRANSIENT
status = getattr(error, "status_code", None) or getattr(getattr(error, "response", None), "status_code", None)
if status:
if status == 429:
return RetryCategory.TRANSIENT
if status in (400, 401, 403, 404, 422):
return RetryCategory.PERMANENT
if status >= 500:
return RetryCategory.TRANSIENT
if isinstance(error, (ValueError, TypeError, KeyError)):
return RetryCategory.PERMANENT
return RetryCategory.UNKNOWN
def resilient_tool_call(
max_retries: int = 3,
base_delay: float = 1.0,
max_delay: float = 30.0,
):
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
last_error = None
for attempt in range(max_retries + 1):
try:
return await func(*args, **kwargs)
except Exception as e:
last_error = e
category = classify_error(e)
if category == RetryCategory.PERMANENT:
print(f" ❌ {func.__name__} 永久性错误,不重试: {e}")
raise
if attempt >= max_retries:
print(f" ❌ {func.__name__} 重试{max_retries}次后仍失败: {e}")
raise
delay = min(base_delay * (2 ** attempt), max_delay)
jitter = delay * 0.1 * (hash(str(time.time())) % 10 / 10)
actual_delay = delay + jitter
print(f" ⚠️ {func.__name__} 第{attempt+1}次失败({category.value}),"
f"{actual_delay:.1f}s后重试: {e}")
await asyncio.sleep(actual_delay)
raise last_error
return wrapper
return decorator
@resilient_tool_call(max_retries=3, base_delay=1.0)
async def call_weather_api(city: str) -> dict:
import random
if random.random() < 0.3:
raise asyncio.TimeoutError("天气API超时")
return {"city": city, "temp": 25, "condition": "晴"}5.2 降级方案:主工具失败时切换备选
python
class ToolWithFallback:
"""带降级方案的工具"""
def __init__(self, primary, fallbacks: list = None, name: str = ""):
self.primary = primary
self.fallbacks = fallbacks or []
self.name = name or primary.__name__
async def __call__(self, **kwargs):
try:
result = await self.primary(**kwargs)
return result
except Exception as e:
print(f" ⚠️ 主工具 {self.name} 失败: {e}")
for i, fallback in enumerate(self.fallbacks):
try:
result = await fallback(**kwargs)
print(f" ✅ 降级方案{i+1}成功")
return result
except Exception as e:
print(f" ⚠️ 降级方案{i+1}也失败: {e}")
print(f" 🔴 所有方案失败,返回兜底结果")
return self._default_result(**kwargs)
def _default_result(self, **kwargs):
return {
"error": "所有数据源不可用",
"fallback": True,
"message": "抱歉,相关服务暂时不可用,请稍后重试"
}5.3 熔断机制:连续失败时停止调用
python
import time
from dataclasses import dataclass, field
@dataclass
class CircuitBreaker:
failure_threshold: int = 5
recovery_timeout: float = 60.0
half_open_max_calls: int = 1
failure_count: int = field(default=0, init=False)
last_failure_time: float = field(default=0.0, init=False)
state: str = field(default="closed", init=False)
half_open_calls: int = field(default=0, init=False)
async def call(self, func, *args, **kwargs):
if self.state == "open":
if time.time() - self.last_failure_time >= self.recovery_timeout:
self.state = "half_open"
self.half_open_calls = 0
else:
raise CircuitOpenError(
f"熔断器开启中,剩余{self.recovery_timeout - (time.time() - self.last_failure_time):.0f}s"
)
if self.state == "half_open":
if self.half_open_calls >= self.half_open_max_calls:
raise CircuitOpenError("半开状态试探次数已用完")
self.half_open_calls += 1
try:
result = await func(*args, **kwargs)
self._on_success()
return result
except Exception as e:
self._on_failure()
raise
def _on_success(self):
self.failure_count = 0
if self.state == "half_open":
self.state = "closed"
def _on_failure(self):
self.failure_count += 1
self.last_failure_time = time.time()
if self.state == "half_open":
self.state = "open"
elif self.failure_count >= self.failure_threshold:
self.state = "open"
class CircuitOpenError(Exception):
pass5.4 组合防御:重试 + 降级 + 熔断
生产环境不是三选一,而是三层叠加:
python
class ResilientToolExecutor:
"""弹性工具执行器:重试 + 降级 + 熔断 三层防御"""
def __init__(self, name: str):
self.name = name
self.breaker = CircuitBreaker(failure_threshold=5, recovery_timeout=60)
self.fallbacks: list = []
self.retry_config = {"max_retries": 2, "base_delay": 1.0}
def add_fallback(self, func):
self.fallbacks.append(func)
return self
async def execute(self, func, **kwargs):
# 第1层:熔断检查
try:
# 第2层:重试
result = await self._retry_call(func, **kwargs)
return result
except CircuitOpenError:
pass
except Exception as e:
print(f" ⚠️ {self.name} 主工具失败: {e}")
# 第3层:降级
for i, fallback in enumerate(self.fallbacks):
try:
result = await fallback(**kwargs)
print(f" ✅ {self.name} 降级方案{i+1}成功")
return result
except Exception as e:
print(f" ⚠️ {self.name} 降级方案{i+1}失败: {e}")
return {
"error": f"{self.name} 所有方案不可用",
"suggestion": "请稍后重试或联系人工客服"
}
async def _retry_call(self, func, **kwargs):
last_error = None
for attempt in range(self.retry_config["max_retries"] + 1):
try:
return await self.breaker.call(func, **kwargs)
except CircuitOpenError:
raise
except Exception as e:
last_error = e
category = classify_error(e)
if category == RetryCategory.PERMANENT:
raise
if attempt < self.retry_config["max_retries"]:
delay = self.retry_config["base_delay"] * (2 ** attempt)
print(f" ⚠️ {self.name} 第{attempt+1}次失败,{delay}s后重试")
await asyncio.sleep(delay)
raise last_error防御策略速查表
| 错误类型 | 防御策略 | 示例 |
|---|---|---|
| 网络超时 | 重试(指数退避) | API调用200ms超时 |
| 限流429 | 重试(等待后) | OpenAI rate limit |
| 参数错误400 | 不重试,记录日志 | LLM传了错误参数格式 |
| 服务宕机500 | 重试→降级→熔断 | 下游服务挂了 |
| 权限不足403 | 不重试,走降级 | API key过期 |
| 连续失败 | 熔断,定时试探 | 下游服务持续不可用 |
核心原则 :工具失败是常态,不是异常。你的Agent必须假设工具随时可能失败,并在架构层面做好防御,而不是在每次调用时临时try-catch。
小结
Tool Calling是Agent伸向外部世界的"手"。这只手最容易断,但现在有了更好的接骨术:
- 协议走向统一:MCP协议让工具定义写一次、到处用。Claude格式已统一为JSON,parallel tool calling已支持。跨模型迁移成本从5天降到1天。
- Structured Output是质变:从"尽量遵守格式"到"100%遵守格式"。5步链路成功率从77%提升到99.5%。这是Agent可靠性最大的单一提升。
- 描述仍是关键:3行描述准确率42%,30行85%。用Pydantic生成高质量描述,约束写进代码而不是注释。Structured Output让描述只需关注语义。
- 编排有模式:串行/并行/条件分支/动态选择,从简单到复杂。能用确定性的就不用动态的。
- 防御是必须:重试、降级、熔断三层叠加。工具失败是常态,不是异常。
下一章,我们讨论Agent的"记忆"问题------为什么大多数Agent的记忆系统要么记不住,要么记太多,以及如何设计一个真正好用的记忆架构。